《Vanilla Gradient Descent for Oblique Decision Trees》(DTSemNet)的核心贡献是提出了一种新型神经网络架构DTSemNet ,该架构能够在语义上完全等价地表示硬倾斜决策树 ,从而允许使用标准(普通)梯度下降来高效地训练决策树,避免了现有方法中的各种近似问题。
以下是文章主要研究内容的全面总结:
1. 研究背景与挑战
-
决策树的价值:决策树在处理表格数据和非平滑函数方面表现出色,甚至优于神经网络,且具有较好的可解释性。
-
学习困难:学习最优决策树是NP难问题。传统方法包括贪心算法、全局搜索和非贪心优化,但存在性能差或计算成本高的问题。
-
现有梯度方法的局限:
-
软决策树:使用Sigmoid等激活函数使树可微,但产生的是概率性的"软"决策,硬化后会损失精度。
-
DGT/ICCT等:使用直通估计器近似梯度,引入误差,尤其在大型数据集或强化学习任务中误差会累积。
-
2. 核心贡献:DTSemNet架构
DTSemNet是一种将硬倾斜决策树 编码为神经网络的新方法,具有以下关键特性:
-
语义等价性:理论上证明,对于任意输入,DTSemNet输出的类别与对应的硬决策树完全相同(定理1)。
-
完全可微:仅使用ReLU激活函数和线性操作,无需任何近似即可进行梯度计算。
-
参数一一对应 :网络中可训练的权重(
A_i,b_i)与决策树内部节点的决策参数完全对应,其他权重固定。 -
支持非平衡树:可处理任意结构的决策树,不仅限于平衡树。
3. 针对不同任务的扩展
-
分类任务:通过最后的MaxPool层和argmax操作,将多个叶子节点映射到类别,实现语义等价的分类。
-
回归任务 :在每个叶子节点引入线性回归器 (参数
θ_j,α_j),使树能进行分段线性回归,从而具备泛化能力。为此,仅在最终的argmax操作处使用一次STE近似。 -
强化学习任务:可直接替换RL框架(如PPO)中的策略网络,用于离散动作(分类版本)和连续动作(回归版本)空间。
4. 实验评估
作者在分类、回归和RL任务上进行了大量实验,与CART、TAO、DGT、ICCT、CRO-DT、VIPER等方法对比:
分类任务
-
小树(深度≤4) :在14个UCI数据集上,DTSemNet全部取得最佳结果,平均错误率比DGT降低0.85%,比非梯度方法降低5.5%。
-
大树(深度≤10) :在8个基准(包括MNIST)上,DTSemNet全部取得最佳,平均优势比TAO高1%,比DGT高1.4%。在Letter数据集上错误率相对降低14%。
-
训练时间:与DGT相近,远快于TAO和CRO-DT(例如MNIST上比TAO快4倍,比CRO-DT快15倍)。
-
泛化能力 :通过损失景观可视化,DTSemNet的损失景观比DGT平坦得多,表明其泛化能力更好。
回归任务
-
带线性回归器的版本 :在7个数据集上,DTSemNet在4个数据集上最佳 ,3个数据集上第二(仅次于TAO-linear)。
-
优势来源:相比DGT(仅标量叶子),DTSemNet的优势约2/3来自线性回归器,1/3来自减少的近似误差。
-
对近似敏感的数据集:在CTSlice上,DTSemNet比DGT-linear的RMSE低23%。
强化学习任务
-
离散动作 :在4个环境(CartPole, Acrobot, LunarLander, Zerglings)上,DTSemNet全部优于DGT、ICCT和VIPER。在复杂的LunarLander和Zerglings上领先优势显著(≥28%和≥39%)。
-
连续动作:在Continuous Lunar Lander和Bipedal Walker上,DTSemNet与Deep RL性能相当,并优于DGT和ICCT。线性回归器版本对性能提升至关重要。
-
稳定性:DTSemNet在不同树高下性能稳定,而DGT和ICCT随高度变化剧烈波动,证明近似方法损害了训练的稳定性。
5. 主要优点总结
-
无近似训练(分类):首次实现了真正的、无近似的硬倾斜决策树梯度下降学习。
-
高精度:在几乎所有分类基准上达到最先进水平。
-
高效:训练速度远快于非梯度方法。
-
泛化能力强:通过叶子回归器和平坦的损失景观,在回归和RL任务中表现出良好的泛化性。
-
即插即用:可直接嵌入现有深度RL框架,无需特殊修改。
6. 局限性与未来工作
-
局限性:作为决策树架构,不适合高维输入(如图像),因为需要大量叶子节点,会失去其优势。
-
未来工作:
-
开发完全无需STE近似的回归架构。
-
引入可微的树剪枝和自适应生长方法,自动确定树的结构(而非作为超参数固定)。
-
文章 提出了DTSemNet,一个能将硬倾斜决策树精确编码为神经网络的新型架构,从而首次实现了使用普通梯度下降 进行无近似的端到端训练,在分类、回归和强化学习任务上显著提升了精度、训练效率和泛化能力。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

官方项目主页地址在这里,如下所示:
项目地址在这里,如下所示:
摘要
决策树(DTs)构成了主要的非线性AI模型之一,其价值体现在例如处理表格数据的效率上。然而,学习准确的DT,尤其是倾斜DT,是很复杂的,并且需要很长的训练时间。此外,DT还存在过拟合问题,例如,在回归任务中,DT通常被认为"不能泛化"。最近,一些工作提出了使(倾斜)DT可微的方法。这使得能够使用高效的梯度下降算法来学习DT。它还通过在树中的决策同时学习叶子节点的回归器来实现泛化能力。先前使DT可微的方法要么依赖于树内部节点的概率近似(软DT),要么依赖于内部节点梯度计算的近似(量化梯度下降)。在这项工作中,我们提出了DTSemNet,一种新颖的、语义等价的、可逆的将(硬、倾斜)DT编码为神经网络的方法,该方法使用标准的普通梯度下降。在各种分类和回归基准上的实验表明,使用DTSemNet学习的倾斜DT比使用最先进技术学习的类似大小的倾斜DT更准确。此外,DT的训练时间显著减少。我们还通过实验证明,在具有物理输入(维度 ≤ 32)的强化学习设置中,DTSemNet学习DT策略的效率与学习神经网络策略一样高。
1 引言
DT在多个领域被广泛采用,例如医学领域13。包括近期研究18在内的多项研究表明,由于DT倾向于学习非平滑函数的归纳偏置,其在表格数据集上的分类性能非常好,甚至优于NN。然而,为给定任务学习DT是一项复杂的任务:由于在树的每个节点上进行分支决策的选择存在组合爆炸,学习最优DT是一个NP难问题25。
当前学习DT的方法大致可以分为四类:(a) 贪心优化,使用分裂准则(如分类与回归树(CART)10)生长树;(b) 非贪心优化,在全局目标下联合优化决策节点,如树交替优化(TAO)12, 45;(c) 全局搜索,以混合整数规划(MIP)6或进化算法(EA)15等形式呈现;(d) 通过使树可微进行梯度下降21, 43, 44。贪心优化技术通常学习性能较差的树44, 2,当可能的树配置数量很大时,全局搜索计算成本高昂7, 15,而非贪心方法虽然计算上更好,但仍然比基于梯度的方法计算成本更高2。此外,在强化学习环境中不使用梯度下降进行训练非常具有挑战性,因为没有现成的数据集:智能体从环境中收集的经验中学习。一种变通方法是首先使用梯度下降学习一个NN,然后使用CART等贪心策略将NN(视为一个预言机)模仿成一个(分类)DT,这对于具有小(最多 ≈6 个特征)离散动作空间的简单RL问题效果尚可4。另一方面,最近基于梯度的方法的结果表明,在训练时间和准确性方面,对于分类和回归任务都非常高效2。此外,它能够在具有连续动作的RL设置中直接学习(回归)DT策略31。
虽然非贪心方法在计算上更好,但仍比基于梯度的方法更昂贵2。此外,在RL设置中不使用梯度下降进行训练非常具有挑战性,因为没有数据集:智能体从环境中收集的经验中学习。一种变通方法是首先使用梯度下降学习一个NN,然后使用CART等贪心策略将NN(视为一个预言机)模仿成一个(分类)DT,这对于具有小(最多 ≈6 个特征)离散动作空间的简单RL问题效果尚可4。另一方面,最近基于梯度的方法的结果表明,在训练时间和准确性方面,对于分类和回归任务都非常高效2。此外,它能够在具有连续动作的RL设置中直接学习(回归)DT策略31。
为了在DT的训练阶段应用梯度下降,大多数先前的工作采用"软"决策(例如,使用Sigmoid激活函数)来使树可微26, 9, 44, 21。然而,这样得到的树不提供"硬"决策,而是"软"的,即概率性的。从软DT可以获得硬DT,但准确性会下降。最近的一些研究,如密集梯度树(DGT)2和可解释连续控制树(ICCT)31,引入了一种替代方法,使用直通估计器(STE)5, 22在反向传播期间近似计算梯度,以获得硬DT。这种近似可能会妨碍DT训练,尤其是在大型数据集或RL中,误差可能在许多训练步骤中累积。
在这项工作中,我们提出了一种强大的新颖的将倾斜DT编码为NN的方法,即DTSemNet架构,它克服了上述缺点。它使用ReLU激活函数和线性操作,使其可微,并允许应用梯度下降来学习其结构。该编码在语义上等价于一个(硬)倾斜DT架构,使得DT中的决策(权重)与NN中的可训练权重一一对应。架构中的其他权重是固定的(不可训练的)。DTSemNet的主要用途是作为分类器;也就是说,它通过使用典型的argmax操作为给定输入选择与最高输出关联的类别来提供相关联的类别。我们在定理1中证明DTSemNet完全等价于一个DT;也就是说,对于每个输入向量,DTSemNet产生的输出类别与DT产生的输出类别相同。它在许多不同的上下文中具有学习DT的潜力。与DGT2和ICCT31(两者都需要多次STE调用)相比,DTSemNet使用ReLU和标准梯度下降,无需STE近似。我们为回归任务提出了一个简单的DTSemNet扩展,它需要一个STE调用来将值的选择与叶子的选择相结合。每个叶子都与一个回归器相关联,其参数与DT决策通过(标准)梯度下降同时学习。
这个过程产生了能够泛化的DT,这得益于叶子节点的回归器,类似于31, 45。
我们在各种基准上对DTSemNet进行了实验,包括分类和回归任务,并针对产生硬DT的不同方法比较了其性能:基于梯度下降的DGT2,非贪心算法TAO12, 45,全局搜索的CRO-DT15以及作为贪心算法标准的CART。分类和回归任务主要涉及表格数据集,除了MNIST(一个小尺寸图像数据集)。特征数量从4到780(MNIST是异常值),类别数量从2到26。对于分类任务,DTSemNet在每个数据集上都取得了最佳性能,展示了我们提出的无近似方法的有效性。对于回归任务,DTSemNet要么表现最佳,要么排名第二(例如,被TAO超越)。这种差异的一个可能原因是用于回归任务的STE近似,该近似用于结合树中的决策和在节点处计算的值。这种近似有时会损害效率,而在分类任务中没有这种近似,从而获得了最优性能。在这两种情况下,使用梯度下降的DT学习时间远短于竞争解决方案。
最后,我们阐述了如何在RL环境中部署DTSemNet来学习DT策略,包括离散动作空间(DTSemNet分类)和连续动作空间(DTSemNet回归)。我们只需在RL学习流程(例如PPO35)中用DTSemNet架构替换NN架构,即可获得与NN性能相当的DT策略。在不同大小(最多10个动作和32个输入维度)的离散动作空间RL环境上的实验表明,DTSemNet与NN相匹配。此外,在更复杂的基准上,它显著优于产生DT策略的竞争解决方案,无论是通过在编码DT的架构上进行梯度下降获得,还是通过对NN进行模仿学习获得。对于连续动作空间,只要输入维度有限,ICCT已经通过使用回归器31提供了与NN匹配的性能,尽管它生成表达性较差的轴对齐DT。这表明当可以在DT的叶子节点使用回归器时,内部节点的精确决策就不那么重要了。我们通过实验验证了在具有连续动作空间的两个环境中:与离散动作一样,DTSemNet优于竞争解决方案,但架构对性能的影响较小。
主要贡献如下:
我们引入了DTSemNet架构,并证明其在语义上等价于DT。使用标准梯度下降学习一个DTSemNet(分类)完全对应于学习一个DT,而不需要借助任何近似,这与竞争方法不同。实验上,这使得DTSemNet成为分类任务中最有效的DT。我们将DTSemNet扩展到回归任务,使用一次STE近似来将二元决策与输出回归相结合:实验上,DTSemNet回归有时是最佳方法,有时(非常接近地)排名第二。我们解释了如何在RL设置中使用DTSemNet,再次在实验上产生了最佳的DT策略,对于离散动作(DTSemNet分类)有大幅领先,对于连续动作空间(DTSemNet回归)有小幅领先。
2 相关工作
非基于梯度的DT训练: 有许多不依赖梯度来学习DT的方法。CART10(及其扩展)是一种众所周知的训练(轴对齐)DT的方法,它基于在每個節點使用某些度量(如熵或基尼不纯度)对数据集进行分割。关于以这种方式学习倾斜DT,已经提出了一些方法,例如Oblique Classifier 1 (OC1)30或GUIDE29。由于学习倾斜DT比学习轴对齐DT困难得多,它们通常不能产生性能良好的倾斜DT。TAO是目前一种最先进的方法,可用于学习倾斜DT。它通过交替微调特定深度的节点参数来增强CART(或给定深度的随机DT)获得的DT性能12, 45。
关于MIP公式6, 7或基于全局EA的搜索方法,如CRO-DT15,它们通过在DT的各种结构上进行搜索来学习DT,但计算成本很高,对于大型DT和数据集不切实际。所提出的DTSemNet通过使用梯度下降来降低训练时间,克服了这些挑战,我们通过与CRO-DT15的比较证实了这一点。CRO-DT提出了一种(倾斜)DT的矩阵编码,以加快与以前基于EA的方法相比的训练速度,并产生轴对齐的DT。
基于梯度的DT训练: 大量工作提出将DT近似为软DT,以便使用梯度下降学习DT,其中决策节点通常使用Sigmoid函数44, 21, 43, 17, 38, 9, 37, 16, 33, 19, 24, 11, 42。硬化软DT,即通过离散化概率将其转换为硬DT,会导致严重的不准确性31。与我们工作更相关的是DGT2,它使用(不可微的)符号激活函数将(倾斜)DT表示为NN架构,利用训练二值化NN的原理22,采用量化梯度下降进行学习。具体来说,在前向传播过程中,节点使用0-1阶跃函数,而在反向传播过程中,节点使用分段线性函数或某些可微近似(参见22)。类似地,ICCT31使用带有Sigmoid激活函数和STE的NN学习(轴对齐)DT。在所有这些工作中,所产生的硬DT与通过梯度下降优化的DT(软DT或使用STE的DT)存在(轻微)差异。相比之下,使用ReLU激活函数的DTSemNet架构允许执行标准梯度下降,并且DTSemNet分类输出的DT与通过梯度下降优化的函数完全相同,没有近似。实验证实,它在实践中更准确,对于分类任务尤其显著。
在RL设置中训练DT策略: 硬或软DT策略可以通过模仿学习1获得,即从专家策略(通常是预训练的NN4, 23, 28, 8, 34, 39, 40, 14)中学习。例如,VIPER4通过从收集的样本中创建数据集,并使用CART训练DT来模仿Q网络(或策略网络),并根据Q值分配样本权重。相比之下,DTSemNet直接在RL中学习硬倾斜DT(使用PPO35)。其他工作,如ProLoNet36,在RL框架内学习软DT,目标是从人类专家初始化权重。相比之下,DTSemNet学习硬DT。ICCT31提出了一种基于STE的方法,使用梯度下降学习轴对齐DT。相比之下,我们可以处理倾斜树,它们比轴对齐DT更具表达性和准确性,尤其是在处理离散动作时。
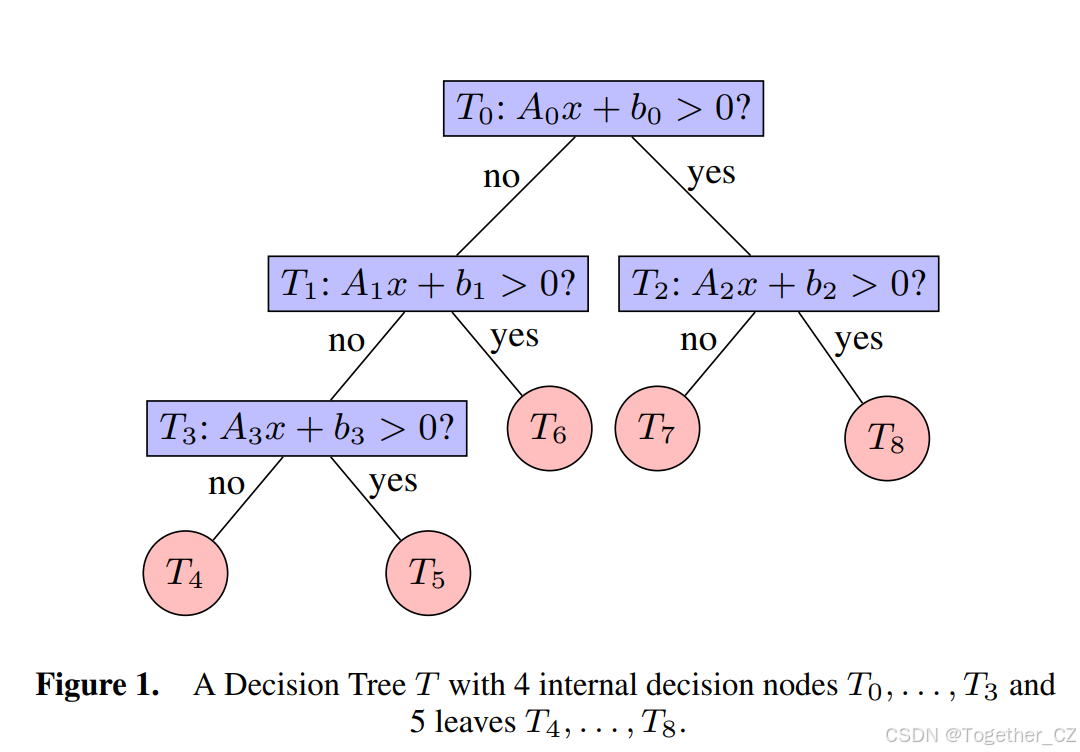
3 DTSemNet 架构
现在,我们描述我们的主要贡献,即 DTSemNet。它以语义等价的方式将决策树(DT)编码为深度神经网络(DNN)。我们将在随后的定理1中证明这种语义等价性。


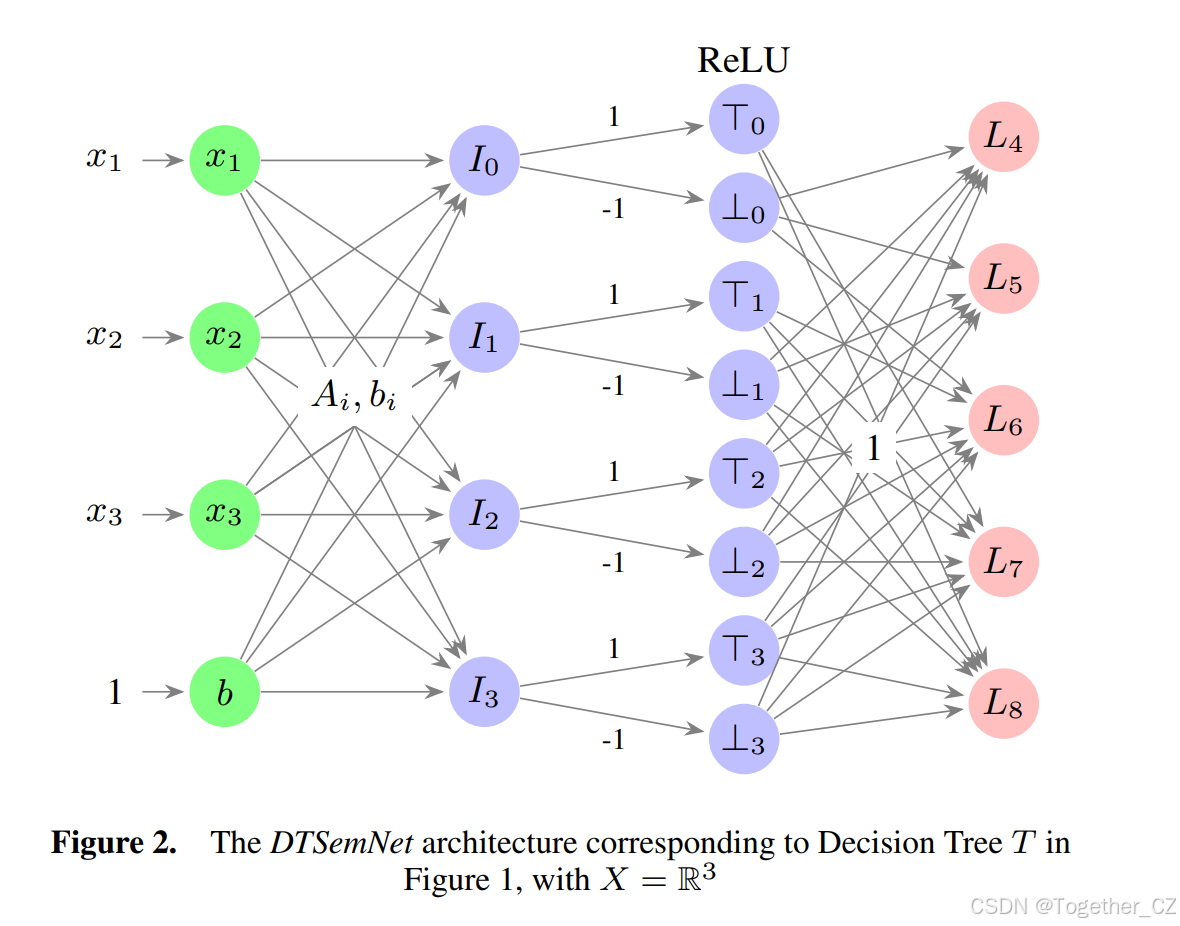


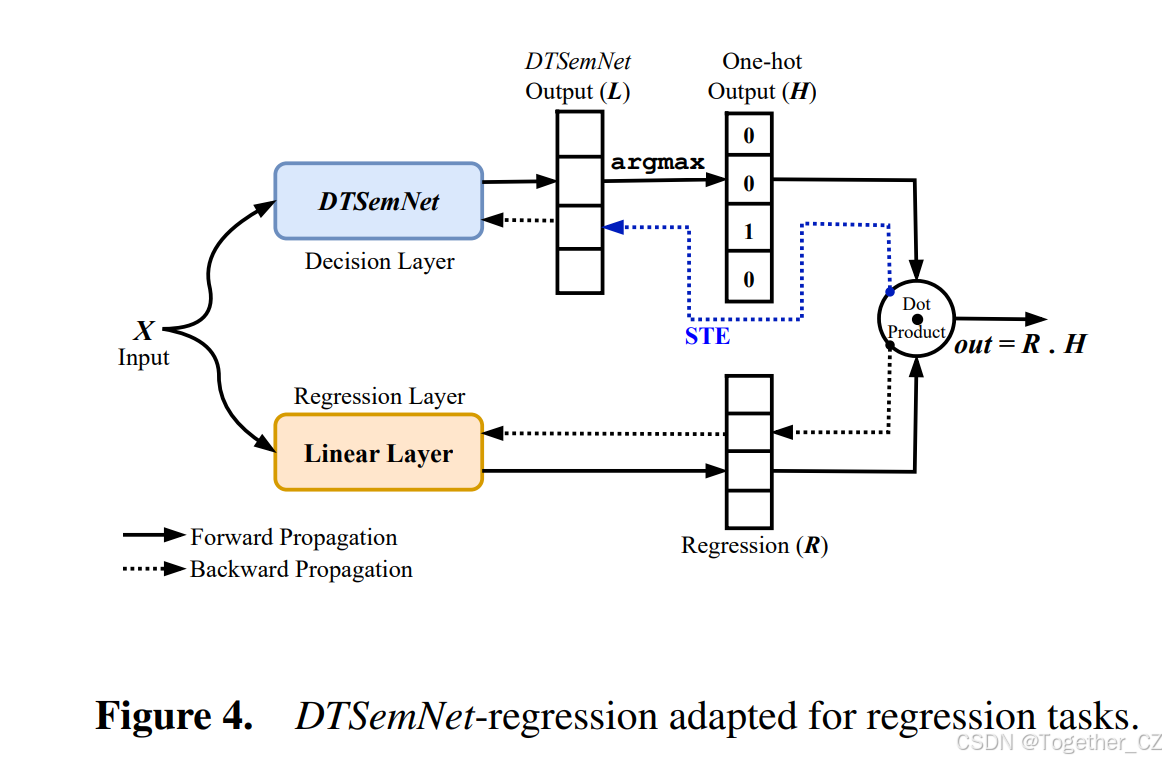


用于强化学习的 DTSemNet: 为了处理强化学习任务,我们使用标准的深度强化学习框架(例如 PPO 35),只需用 DTSemNet 架构替换神经网络,然后运行强化学习框架的梯度下降。对于具有离散动作空间的环境,我们使用 DTSemNet-分类,每个动作对应一个类别。对于具有连续动作空间的环境,我们使用 DTSemNet-回归,每个动作维度对应一个线性回归(例如,对于连续动作的 Lunar Lander,有 2 个维度,分别用于水平和垂直引擎)。
与其他将决策树编码为神经网络的方法比较: DGT 2 在每一层使用 Sign 激活函数来产生(硬)倾斜决策树。由于 Sign 没有梯度(与 DTSemNet 中使用的 ReLU 不同),DGT 诉诸量化梯度下降,在每个节点处使用 STE 近似过程。在回归任务中,DGT 为每个叶子节点产生一个标量,而不是 DTSemNet-回归中的线性回归。ICCT 架构 31 通过将通向该叶子节点的边的权重相乘(在对数空间中处理以避免显式乘法)来为强化学习任务生成轴对齐决策树。在每个决策上使用 Sigmoid 激活,导致将决策近似为软决策树。软决策树在强化学习过程的每个步骤中被"硬化"成一个硬(轴对齐)决策树,使用 STE 来反向传播通过不可微函数(Heaviside 阶跃函数),而 DTSemNet-分类则避免了这一点。
4 实验评估
在本节中,我们将评估DTSemNet的性能,并将其与学习硬DT的竞争方法进行比较。首先,我们考虑使用多个基准多类分类和回归数据集的监督学习设置,在这些数据集上,我们将测试数据的准确性与最先进的非贪心方法TAO12, 45、最先进的基于梯度下降的方法DGT2(两者都学习倾斜DT),以及用于全局搜索的CRO-DT15和作为贪心算法标准的CART(两者都学习轴对齐DT)进行比较。对于有可用数据的基准,我们报告了相对训练时间(请注意,我们无法在我们的硬件上运行TAO,因为它不公开可用)。此外,为了理解不同架构使用梯度下降对泛化能力的影响,我们利用了损失景观27的见解。
最后,我们考虑了离散动作和连续动作空间的强化学习环境。我们将DTSemNet与DGT(两者都生成倾斜DT策略)和ICCT(生成轴对齐DT策略)进行比较,这三种方法都通过梯度下降学习,以及与VIPER(通过模仿由深度RL生成的NN策略来学习轴对齐DT策略)进行比较,我们也将深度RL策略作为基线报告。
我们使用Python和PyTorch实现了DTSemNet并进行了所有实验。我们的测试平台拥有8个CPU核心(AMD 75F3,Zen 3架构)、128 GB RAM和一块2 GB GPU(NVIDIA Quadro P620)。补充材料32提供了关于数据集、训练-测试分割、超参数等的额外结果和详细信息。我们的源代码公开可用:https://github.com/CPS-research-group/dtsemnet。
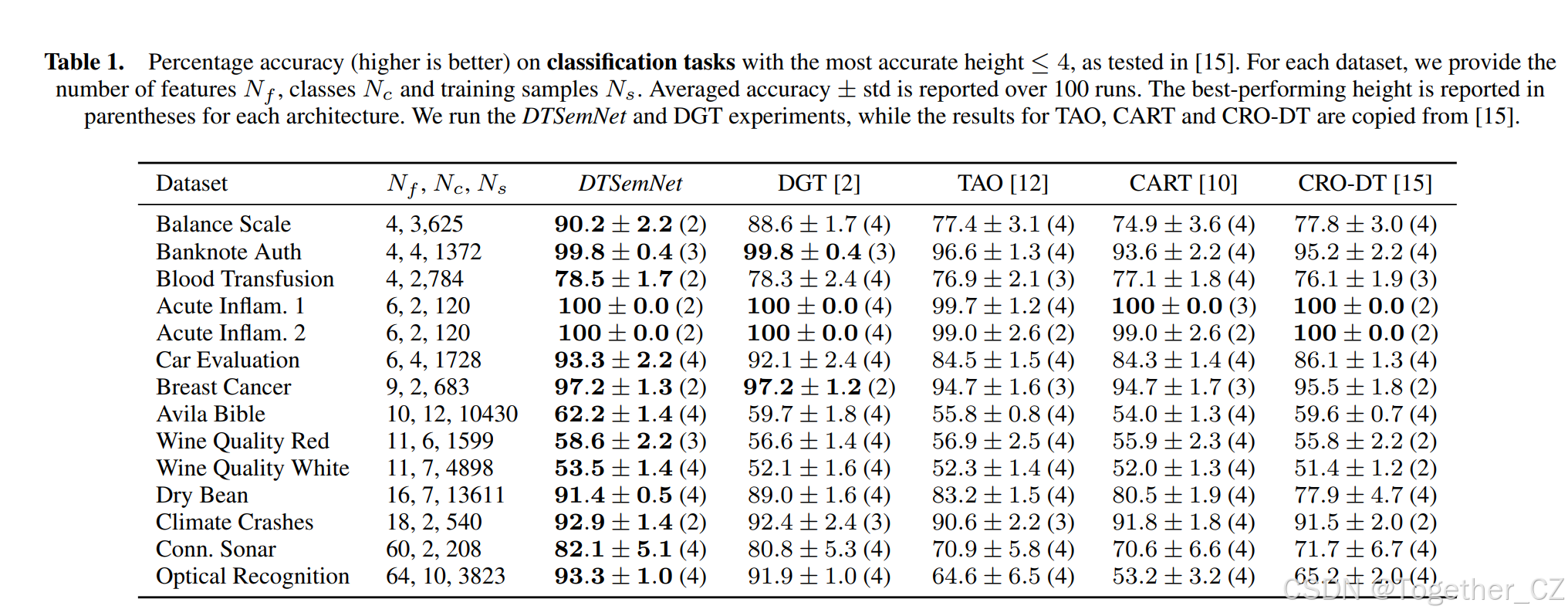
分类任务(小型DT): 我们首先考虑CRO-DT15中使用的14个分类表格数据集。全局搜索方法如CRO-DT15仅对小型DT(这里深度为4,即32个节点)有效。我们按特征数量对基准进行排序,因为特征越多,决策就越具挑战性,尤其是在使用小型DT时。我们在表1中报告了(平均)得分,基于使用不同随机种子学习的100个DT,针对最高准确度的深度(最高4)。
在每一个基准中,DTSemNet都产生了最准确的DT,最大的差异出现在Dry Beans数据集上,将分类错误从 11% 降低到 8.6%。DGT是第二好的,除了在两个葡萄酒质量基准中,TAO优于它。DGT通常接近DTSemNet,这并不奇怪,因为它们的想法相似,尽管所使用的近似(STE,量化梯度下降)使得DGT的性能平均比DTSemNet差 0.85%。有趣的是,在特征最多的4个基准(最难的任务)上,优势增长到 1.3%。此外,DGT需要比DTSemNet更大的树才能获得最佳结果(在14个基准中有6个)。与基于非梯度的方法相比,DTSemNet的优势非常明显,平均高出 5.5%,在特征最多的4个基准上增长到 12%。最大的差异出现在Optical Recognition数据集上,将分类错误从 34.8% 降低到仅仅 6.7%。
表 2. 训练时间(秒,越低越好)和(平均准确率%,越高越好)。非公开可用的TAO在MNIST上的训练时间引自12,而我们在类似的计算配置上训练其他架构。MNIST的树高为8,DryBean的树高为4。
| 数据集 | DTSemNet | DGT 2 | TAO 3 | CRO-DT 15 |
|---|---|---|---|---|
| MNIST | 306 (96.1) | 288 (94.0) | 1200 (95.0) | 4659 (58.2) |
| DryBean | 4.4 (91.4) | 3.8 (89.0) | NA (83.2) | 1300 (77.9) |
分类任务(更深DT): 我们现在考虑TAO12中报告的原始8个分类任务,并在2中再次使用。它们使用表格数据集,但MNIST除外,它是一个小尺寸的图像数据集。我们使用了12中指定的固定树高(也在2中重复使用)。我们首先在表2中报告了MNIST架构的训练时间,因为12报告了TAO的这个数字。我们在可比较的计算配置上训练其他架构。我们提供了参考用的准确率数字。我们还为更简单的DryBean报告了训练时间,但TAO没有这个数据。首先,CRO-DT在MNIST上的训练时间(世代数设置为默认的4000)比其他架构长得多,同时准确率非常低(<60% 对比 >90%),这就是为什么我们不将其用于这些更深DT的基准(15确实没有报告这些基准的CRO-DT结果)。由于架构相似,DGT和DTSemNet的训练时间几乎相同。正如预期的那样,观察到基于梯度的训练方法明显快于非梯度学习方法。
我们按DT的高度对基准进行排序,这是任务复杂性的一个良好指标。
表 3. 针对12中报告的数据集的分类任务百分比准确率(越高越好)。对于每个数据集,我们提供特征数量 Nf、类别数量 Nc 和训练样本数量 Ns。所有方法都使用2中固定的树高(CART除外,它没有预定义的高度)。报告的是10次运行的平均准确率 ±± 标准差。DGT和CART的结果来自2,TAO的结果来自12。
| 数据集 | Nf, Nc, Ns | 高度 | DTSemNet | DGT 2 | TAO 12 | CART 10 |
|---|---|---|---|---|---|---|
| Protein | 357, 3, 14895 | 4 | 68.60 ± 0.22 | 67.80 ± 0.40 | 68.41 ± 0.27 | 57.53 ± 0.00 |
| SatImages | 36, 6, 3104 | 6 | 87.55 ± 0.59 | 86.64 ± 0.95 | 87.41 ± 0.33 | 84.18 ± 0.30 |
| Segment | 19, 7, 1478 | 8 | 96.10 ± 0.53 | 95.86 ± 1.16 | 95.01 ± 0.86 | 94.23 ± 0.86 |
| Pendigits | 16, 10, 5995 | 8 | 97.02 ± 0.32 | 96.36 ± 0.25 | 96.08 ± 0.34 | 89.94 ± 0.34 |
| Connect4 | 126, 3, 43236 | 8 | 82.03 ± 0.39 | 79.52 ± 0.24 | 81.21 ± 0.25 | 74.03 ± 0.60 |
| MNIST | 780, 10, 48000 | 8 | 96.16 ± 0.14 | 94.00 ± 0.36 | 95.05 ± 0.16 | 85.59 ± 0.06 |
| SensIT | 100, 3, 63058 | 10 | 84.29 ± 0.11 | 83.67 ± 0.23 | 82.52 ± 0.15 | 78.31 ± 0.00 |
| Letter | 16, 26, 10500 | 10 | 89.19 ± 0.29 | 86.13 ± 0.72 | 87.41 ± 0.41 | 70.13 ± 0.08 |
表 4. 回归任务的平均RMSE结果(越低越好),± 10次运行的标准差。为每个数据集提供了特征数量 Nf 和训练样本数量 Ns。DGT-linear是我们从DGT2修改实现的,以在叶子节点添加回归器。前5个数据集来自45。对于叶子节点带有回归器的DT(DTSemNet, DGT-Linear, TAO-linear),高度按照45固定为Height。DGT在叶子节点使用固定标量而不是回归器,因此需要更深的DT才能达到合理的准确度 - 2中使用的深度在括号内给出,而CART的高度不固定。最后两个数据集来自2,TAO-linear的结果不可用。DGT和CART的报告结果取自2;TAO-Linear的结果取自45。
讨论: 与表1一样,DTSemNet在每个基准中都产生了最准确的DT。对于更深的树,TAO的性能有所恢复,它在5次中排名第二,而DGT在3次中排名第二。DTSemNet相对于TAO的平均优势为 1%,在树更深的4个基准上增长到 1.4%。最大的差异出现在Letter数据集上,将分类错误从 12.6% 降低到 10.8%,以及在Pendigits上从 3.9% 降低到 3%。DTSemNet相对于DGT的平均优势为 1.4%,在树更深的4个基准上增长到 2.1%,比表1中小型树的优势更大。最大的差异出现在Letter数据集上,将分类错误从 13.9% 降低到 10.8%,以及在MNIST上从 6% 降低到 3.9%。在所有分类基准上的Friedman-Nemenyi检验,显著性水平为0.05,显示DTSemNet显著优于所有其他方法,平均排名为:DTSemNet 1.11,DGT 2.25,TAO 2.86,CRO-DT 3.60,CART 3.77。
为了理解DGT中使用的近似(量化梯度下降和STE)的影响,我们考虑了损失景观27,它展示了架构选择对泛化能力的影响。
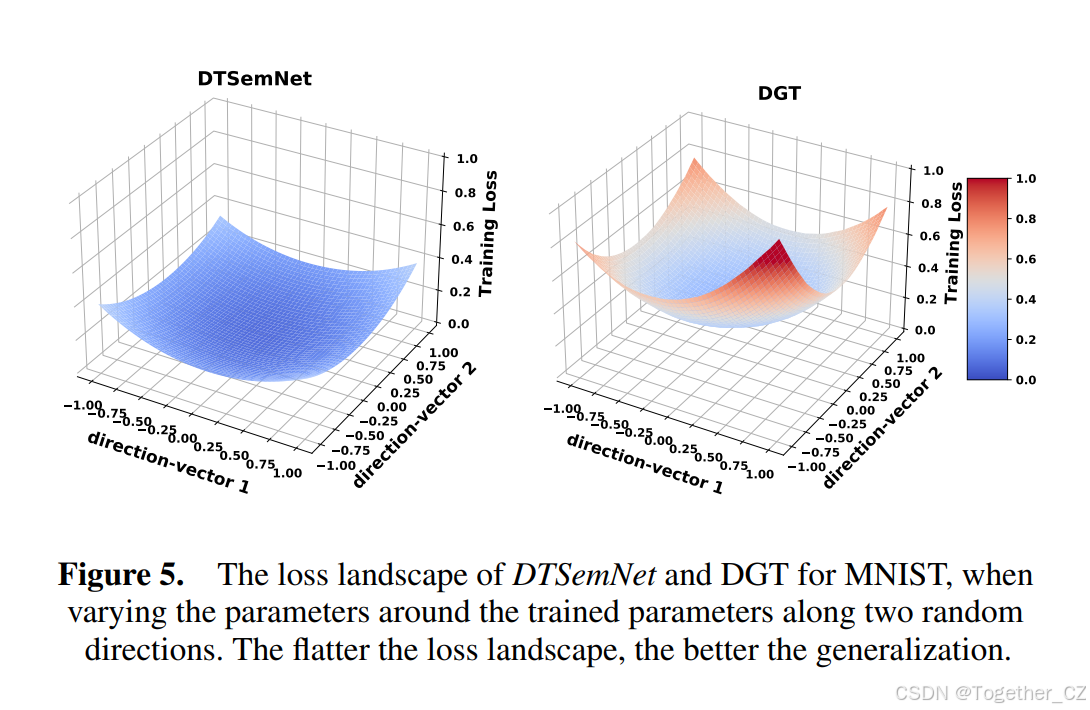
图 5. MNIST上DTSemNet和DGT的损失景观,当参数在训练好的参数附近沿两个随机方向变化时。损失景观越平坦,泛化能力越好。
我们考虑MNIST,在该数据集上DGT的分类错误比DTSemNet多得多。图5显示了沿两个随机向量方向在最终训练参数周围的损失景观。更平坦的损失景观表明更好的泛化能力27。如图5所示,与DGT相比,DTSemNet的损失景观非常平坦。这表明(无近似的)DTSemNet在分类任务上比DGT具有更好的泛化能力。
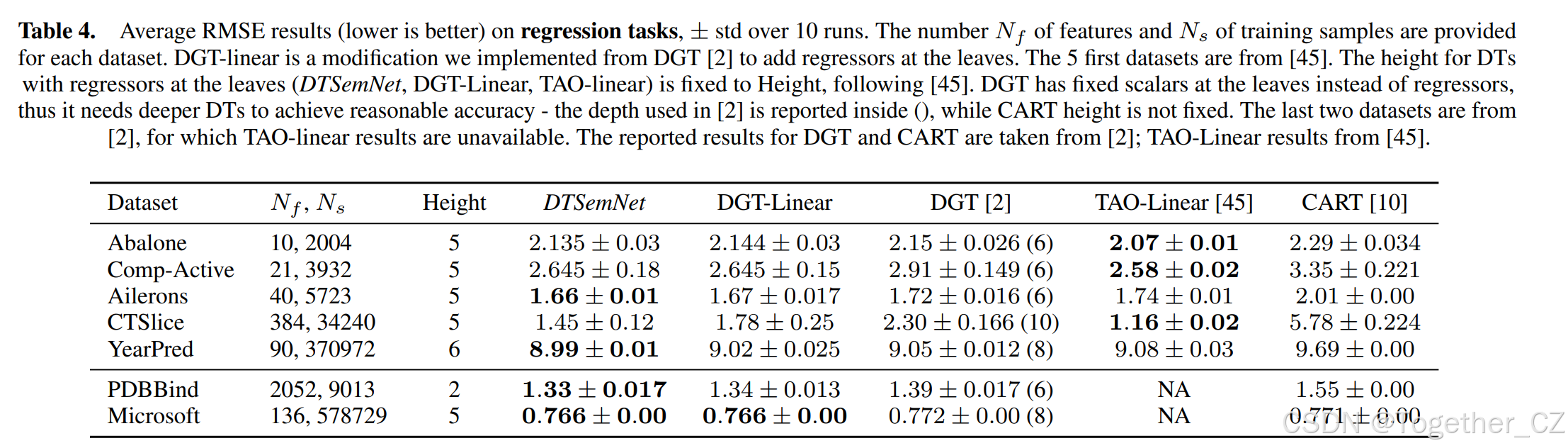
回归任务: 我们考虑了来自45的5个回归数据集,以及来自2的另外两个(TAO-linear的结果不可用)。TAO-linear45生成的DT在叶子节点带有回归器,类似于DTSemNet,允许它们泛化,而DGT2仅在叶子节点学习标量,类似于CART,因此效率较低(且无法泛化),需要更深的DT才能达到可接受的准确度。为了理解叶子节点回归器的影响,我们实现了DGT-linear,这是DGT的一个修改版本,在叶子节点使用回归器,方式与DTSemNet和ICCT31相同。在叶子节点带有回归器的架构,即DTSemNet(回归)、DGT-linear和TAO-linear,使用相同的固定高度(遵循45),而DGT(无回归器)使用更深的树(如2中报告的),CART不受限制。回归数据集的结果呈现在表4中。
DTSemNet-回归有时仅次于TAO-linear(3个基准),并在其他4个基准上表现最佳。DTSemNet在所有7个基准上平均比(原始)DGT的RMSE好 10%,在CTslice上甚至好 50%,尽管DTSemNet使用的(硬倾斜)DT比DGT小。与在叶子节点带有回归器的DGT-linear(我们的改编)相比,DTSemNet仍然一致地优于或持平,但优势缩小到在所有7个基准上平均RMSE的 3.7%,最优时好 23%(CTSlice)。DTSemNet相对于DGT的优势有三分之二可归因于叶子节点的回归器,但仍有有意义的三分之一优势可归因于减少了近似,DTSemNet-回归只用了1次STE调用,而DGT和DGT-linear用了 n 次STE调用,其中 n 是DT的高度。
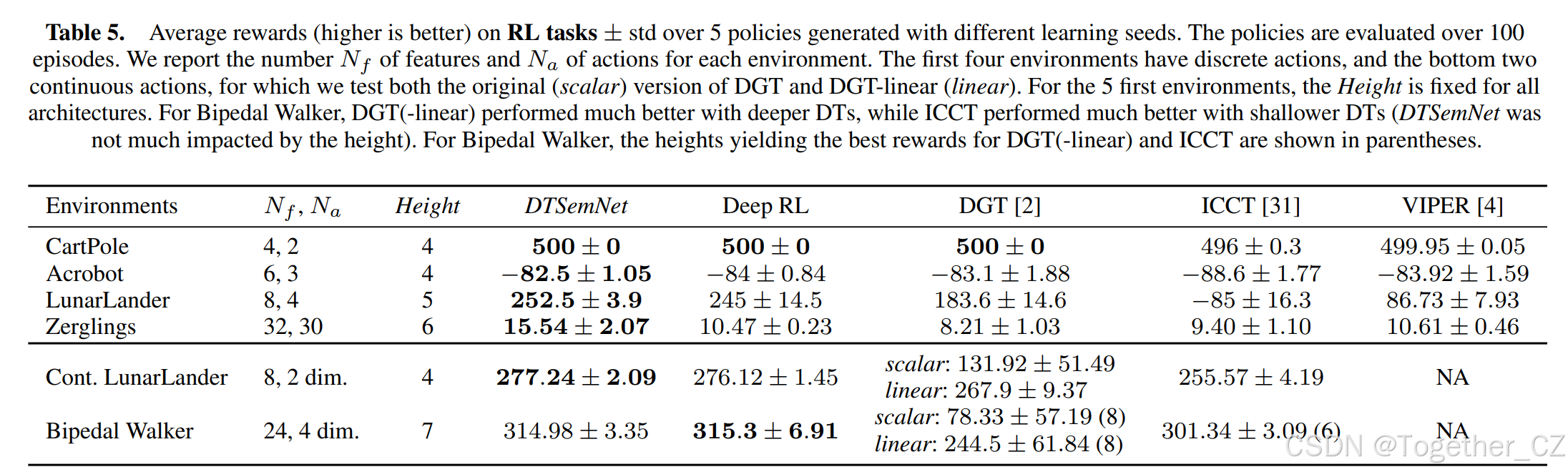
表 5. 强化学习任务上的平均奖励(越高越好),± 基于5个不同学习种子生成的策略的标准差。这些策略在100个 episodes 上进行评估。我们为每个环境报告特征数量 Nf 和动作数量 Na。前四个环境具有离散动作,后两个具有连续动作,对于这两个环境,我们测试了DGT的原始(标量)版本和DGT-linear(线性)版本。对于前5个环境,所有架构的高度都是固定的。对于Bipedal Walker,DGT(-linear) 在更深DT时表现更好,而ICCT在更浅DT时表现更好(DTSemNet受高度影响不大)。对于Bipedal Walker,DGT(-linear) 和ICCT获得最佳奖励的高度在括号中显示。
强化学习任务: 我们实验了四个具有离散动作的物理环境,且物理特征数量有限(≤32):三个来自OpenAI Gym的环境,即CartPole(4个特征,2个动作)、Acrobot(6个特征,3个动作)和LunarLander(8个特征,4个动作),以及一个更大的SC-II环境,即FindandDestroyZerglings(32个特征,30个动作)41。我们还实验了两个具有连续动作的OpenAI环境,即Lunar Lander的连续版本(8个特征,2个动作维度------水平和垂直推进器)和Bipedal Walker(24个特征,4个动作维度)。
我们固定了不同架构学习的DT的高度,并与具有相同数量学习参数的深度RL(使用NN)进行比较,后者也作为VIPER4执行模仿学习的专家。ICCT和VIPER生成(硬)轴对齐DT策略,而DTSemNet和DGT生成(硬)倾斜DT策略。此外,对于连续动作空间,使用每个架构的回归版本,DGT有2个变体:原始的在叶子节点使用标量,以及我们的带有线性回归的修改(类似于DTSemNet和ICCT)。请注意,VIPER不处理连续动作空间。
我们为每种情况训练了5个策略,使用不同的环境随机种子。我们使用来自StableBaseline3库的标准PPO35处理离散动作,使用SAC20处理连续动作。我们在相同的100个种子上运行每个策略以评估策略并计算平均奖励。表5报告了每个架构5个不同策略的平均奖励值。
总的来说,在这些状态维度有限(≤32)的环境中,DTSemNet与生成NN策略的深度RL具有竞争力。此外,DTSemNet一致地生成了最高效的DT策略。环境越复杂,领先优势越大:
• 在最简单的CartPole(Nf=4)上,并列第一。
• 在Acrobot(Nf=6)上,领先几个百分点。
• 在(离散动作)LunarLander(Nf=8)上,相比其他DT架构有非常大的领先优势(≥28%)。请注意,VIPER可以表现得与DTSemNet更接近(奖励 > 200),但它需要非常大的DT(>1300个叶子节点),而DTSemNet只需要32个叶子节点。
• 在Zerglings(Nf=32)上,领先优势甚至更大(≥39%)。
连续动作空间比离散情况更容易处理:对于Lunar Lander,在连续情况下,每个在叶子节点带有回归器的架构的平均奖励都高于离散版本,这是预料之中的,因为它可以访问两个维度上的精确连续动作,而不是在4个离散动作之间进行粗略选择。此外,架构之间的奖励更为相似,这证实了在连续版本中架构不如在离散版本中重要,因为策略可以对输入状态使用线性致动器,而不是像离散版本那样使用固定动作。即使是轴对齐DT也接近DTSemNet,而它们在离散版本中表现极差。再次,我们对DGT的线性改编比2中的原始版本准确得多,尽管DTSemNet在Bipedal Walker上的差距仍然显著。
关于DGT和ICCT使用的不同近似的影响,它们都使用STE。ICCT中使用的Sigmoid(和乘法)在Lunar Lander上效率低下,特别是在离散动作变体中。量化梯度下降(由于不可微的Sign函数导致的DGT)在Zerglings环境和Bipedal Walker上特别低效,其结果甚至比ICCT生成的表达能力较差的轴对齐DT还要差。此外,对于Bipedal Walker,我们观察到DGT和ICCT的性能随树深变化而显著波动,而DTSemNet则不然,其在深度6、7、8时始终保持在 > 300:DGT-linear在深度6、7、8的性能分别为112、163、244,它需要更深的DT。对于ICCT,在深度6、7、8的性能分别为301、177、112,随着深度增加而严重下降,这不应该发生,这进一步证明了近似会损害准确性。
5 结论
我们介绍了DTSemNet,一个在语义上等价于倾斜DT的架构。该架构使得能够使用普通梯度下降来学习倾斜DT。我们在监督分类和回归数据集以及RL任务上展示了其性能。DTSemNet一致地生成比使用梯度下降学习DT的竞争架构更准确(或在简单基准上同样准确)的DT。这是因为DTSemNet-分类不使用近似,而它的竞争对手使用,并且因为DTSemNet-回归使用较少的近似。此外,与用于学习DT的非基于梯度的方法(贪心、非贪心和全局搜索)相比,DTSemNet明显更快。DTSemNet-分类优于这些方法中最好的,在较难的分类任务上将错误率降低了 >10%,而DTSemNet-回归的准确性与最先进水平具有竞争力。
局限性: DTSemNet是一个DT,因此不适合高维输入,如图像,因为DT难以处理复杂形状并且需要许多叶子节点,这会抵消其优势。
未来工作: 对于DTSemNet,DT高度的选择被视为一个超参数,类似于NN中层数的选择,这与方法(例如CART10)生长树的高度形成对比。在未来工作中,我们将考虑开发不依赖STE近似的回归架构,并引入用于树剪枝和自适应生长的可微方法。