写在前面

欢迎大家关注Rocky的知乎:Rocky Ding
AIGC算法工程师/开发工程师面试面经秘籍分享:WeThinkIn/Interview-for-Algorithm-Engineer欢迎大家Star~
AIGC时代的 《三年面试五年模拟》AI算法工程师/开发工程师求职面试秘籍独家资源: 【三年面试五年模拟】AI算法工程师面试秘籍
Rocky最新撰写AI Agent(AI智能体)的深入浅出全维度解析文章: 深入浅出完整解析AI Agent(AI智能体)的核心基础知识
AIGC算法岗/开发岗面试面经交流社群 (涵盖AI Agent、AIGC图像创作、AI视频、LLM大模型、AI多模态、数字人、传统深度学习、具身智能等AIGC面试干货资源)欢迎大家加入:https://t.zsxq.com/33pJ0
大家好,我是Rocky。
核心导读
LCM 这篇论文的表层问题是"如何让 Stable Diffusion 在 1 到 4 步内生成高质量图像",但它真正回答的是一个更底层的问题:扩散模型的采样过程,能不能从一个反复迭代的数值求解过程,变成一个可学习的一致性映射?
Rocky认为,LCM 的本质价值不在于又提出一个加速 trick,而在于它把"扩散采样的时间成本"重新定义成"对 PF-ODE 轨迹解的学习问题"。过去我们靠 DDIM、DPM-Solver 这类数值求解器减少步数,本质上还是沿着轨迹一步一步走;LCM 则试图让模型直接学会:无论你在这条轨迹的哪个时间点,都应该映射回同一个干净 latent 原点。这个思路一旦成立,少步生成就不再只是更快的 sampler,而是一个可以被蒸馏、微调、组合进产品工作流的基础能力。

图 1 展示了 LCM 在 CFG scale ω = 8.0 \omega=8.0 ω=8.0 下的 1-step、2-step、4-step 图像生成效果。论文声称,LCM 可以从任意预训练 Stable Diffusion 蒸馏而来,例如将 Dreamer-V7 版本的 SD 仅用 4,000 个训练 step、约 32 A100 GPU hours 蒸馏成可在 2-4 步甚至 1 步生成 768×768 图像的模型。这里的核心不是"少几步",而是"少步之后还能保留足够的图像质量和文本对齐"。
问题背景:作者到底想解决什么
扩散模型的优势很清楚:训练稳定、图像质量高、可控性强,已经成为文生图的主流路线。但它的硬伤也同样清楚:生成过程慢。传统扩散采样需要沿着反向扩散过程逐步去噪,从高噪声状态一步步回到清晰图像。即使 DDIM、DPM-Solver、DPM-Solver++ 已经把采样步数压到 10-20 步,在实时生成、交互式创作、端侧部署和大规模推理成本面前,这个速度仍然不够。
Consistency Models 提供了一个很有启发的方向:如果一个样本沿着 probability flow ODE 轨迹从噪声走向数据,那么轨迹上不同时间点应该对应同一个"源点"。于是我们可以学习一个 consistency function,把任意时间点的样本直接映射回轨迹起点。这样就不必每一步都沿着轨迹慢慢走。
但原始 Consistency Models 主要在像素空间和较低分辨率图像任务上验证,比如 ImageNet 64×64、LSUN 256×256。它没有直接解决高分辨率文生图的两个关键问题:一是如何放到 Stable Diffusion 这类 latent diffusion 的 latent 空间里;二是如何处理 classifier-free guidance,因为 CFG 是 Stable Diffusion 图像质量和文本对齐的重要来源。
LCM 的目标就是把 consistency model 推进到真实的高分辨率文生图场景:在 latent 空间中蒸馏预训练 Stable Diffusion,支持 CFG,引入 skipping-step 加速训练收敛,并提出 Latent Consistency Fine-tuning,让 LCM 能够适配 Pokemon、Simpsons 这类自定义风格数据集。
从行业视角看,这篇论文站在 AIGC 中场的一个关键节点上:当"会生成图像"变成基础能力之后,真正的竞争不再只是生成质量,而是生成能力能否以更低延迟、更低成本、更高交互频率进入产品。LCM 解决的正是这个系统问题。
核心思路:用一句主线串起来
LCM 的主线可以概括为一句话:把 Stable Diffusion 的 guided reverse diffusion 视为一个 augmented probability flow ODE,在 latent 空间训练一个 consistency function,使它直接预测 ODE 轨迹的解,从而把传统多步采样压缩到 1-4 步。
这句话里有三层机制。
第一,LCM 不在像素空间做 consistency learning,而是在 Stable Diffusion 的 latent 空间做。这样它继承了 latent diffusion 的高分辨率效率优势,不需要在原始像素空间里承受巨大计算量。
第二,LCM 不只是蒸馏无条件或普通条件扩散模型,而是把 classifier-free guidance 纳入 distillation。论文把 guided reverse diffusion process 写成 augmented PF-ODE,然后让 consistency function 同时条件于 latent、文本条件、时间和 CFG scale ω \omega ω。
第三,LCM 不是只提出训练目标,还提出 skipping-step。普通 consistency distillation 若只对相邻时间点做一致性约束,两个点太接近,loss 信号弱、收敛慢;LCM 让模型学习从 t n + k t_{n+k} tn+k 到 t n t_n tn 的跨步一致性,在主实验中设置 k = 20 k=20 k=20,把 1000 步级别的训练时序压缩成更粗、更有效的学习信号。
方法展开:沿着论文原始逻辑拆解
从扩散模型到 PF-ODE:少步生成要先换一个视角
扩散模型的常见直觉是"加噪再去噪"。给定数据分布 p d a t a ( x ) p_{\mathrm{data}}(x) pdata(x),前向过程逐步把数据变成噪声;反向过程则从噪声生成数据。连续时间下,前向过程可以写成 SDE:
d x t = f ( t ) x t d t + g ( t ) d w t , x 0 ∼ p d a t a ( x 0 ) \mathrm{d}\boldsymbol{x}_t=f(t)\boldsymbol{x}_t\mathrm{d}t+g(t)\mathrm{d}\boldsymbol{w}_t,\quad \boldsymbol{x}0\sim p{\mathrm{data}}(\boldsymbol{x}_0) dxt=f(t)xtdt+g(t)dwt,x0∼pdata(x0)
其中 f ( t ) f(t) f(t) 和 g ( t ) g(t) g(t) 由噪声调度 α ( t ) , σ ( t ) \alpha(t),\sigma(t) α(t),σ(t) 决定:
f ( t ) = d log α ( t ) d t , g 2 ( t ) = d σ 2 ( t ) d t − 2 d log α ( t ) d t σ 2 ( t ) f(t)=\frac{\mathrm{d}\log\alpha(t)}{\mathrm{d}t},\quad g^2(t)=\frac{\mathrm{d}\sigma^2(t)}{\mathrm{d}t}-2\frac{\mathrm{d}\log\alpha(t)}{\mathrm{d}t}\sigma^2(t) f(t)=dtdlogα(t),g2(t)=dtdσ2(t)−2dtdlogα(t)σ2(t)
关键转折在于,反向 SDE 可以对应一个 probability flow ODE。这个 ODE 与 SDE 有相同边缘分布,但采样可以通过 ODE 求解完成:
d x t d t = f ( t ) x t − 1 2 g 2 ( t ) ∇ x log q t ( x t ) \frac{\mathrm{d}\boldsymbol{x}_t}{\mathrm{d}t} =f(t)\boldsymbol{x}t-\frac{1}{2}g^2(t)\nabla{\boldsymbol{x}}\log q_t(\boldsymbol{x}_t) dtdxt=f(t)xt−21g2(t)∇xlogqt(xt)
实际扩散模型里,score function 通常由噪声预测模型 ϵ θ \epsilon_\theta ϵθ 近似,于是经验 PF-ODE 可以写成:
d x t d t = f ( t ) x t + g 2 ( t ) 2 σ t ϵ θ ( x t , t ) \frac{\mathrm{d}\boldsymbol{x}_t}{\mathrm{d}t} =f(t)\boldsymbol{x}t+\frac{g^2(t)}{2\sigma_t}\boldsymbol{\epsilon}\theta(\boldsymbol{x}_t,t) dtdxt=f(t)xt+2σtg2(t)ϵθ(xt,t)
这个视角很重要。传统 sampler 是在数值求解这个 ODE;LCM 则要学习这个 ODE 解的映射。Rocky认为,这就是 LCM 的认知跃迁:它不是单纯"减少采样步数",而是把"求解路径"压缩成"学会路径的终点"。
Consistency Model:学习轨迹上任意点到同一原点的映射
Consistency Model 的核心是一个 consistency function:
f : ( x t , t ) ↦ x ϵ \boldsymbol{f}:(\boldsymbol{x}t,t)\mapsto \boldsymbol{x}\epsilon f:(xt,t)↦xϵ
它希望满足 self-consistency:
f ( x t , t ) = f ( x t ′ , t ′ ) , ∀ t , t ′ ∈ ϵ , T \boldsymbol{f}(\boldsymbol{x}t,t)=\boldsymbol{f}(\boldsymbol{x}{t'},t'),\quad \forall t,t'\in\\epsilon,T f(xt,t)=f(xt′,t′),∀t,t′∈ϵ,T
也就是说,同一条 PF-ODE 轨迹上的不同点,经过 consistency function 后都应该回到同一个轨迹原点。为了保证边界条件 f θ ( x , ϵ ) = x f_\theta(x,\epsilon)=x fθ(x,ϵ)=x,模型被参数化为:
f θ ( x , t ) = c s k i p ( t ) x + c o u t ( t ) F θ ( x , t ) \boldsymbol{f}\theta(\boldsymbol{x},t) =c{\mathrm{skip}}(t)\boldsymbol{x}+c_{\mathrm{out}}(t)\boldsymbol{F}_\theta(\boldsymbol{x},t) fθ(x,t)=cskip(t)x+cout(t)Fθ(x,t)
其中 c s k i p ( ϵ ) = 1 c_{\mathrm{skip}}(\epsilon)=1 cskip(ϵ)=1, c o u t ( ϵ ) = 0 c_{\mathrm{out}}(\epsilon)=0 cout(ϵ)=0。训练时维护一个 EMA target model θ − \theta^- θ−,并用 consistency loss 约束当前模型与 target model 在相邻轨迹点上的预测一致:
L ( θ , θ − ; Φ ) = E x , t d ( f θ ( x t n + 1 , t n + 1 ) , f θ − ( x \^ t n ϕ , t n ) ) \mathcal{L}(\theta,\theta^-;\Phi) =\mathbb{E}_{\boldsymbol{x},t} \left d\\left( \\boldsymbol{f}_{\\theta}(\\boldsymbol{x}_{t_{n+1}},t_{n+1}), \\boldsymbol{f}_{\\theta\^-}(\\hat{\\boldsymbol{x}}_{t_n}\^{\\phi},t_n) \\right) \\right L(θ,θ−;Φ)=Ex,td(fθ(xtn+1,tn+1),fθ−(x\^tnϕ,tn))
原始 Consistency Model 已经证明这种思路可以让生成从多步迭代走向一步/少步,但它还没有解决 Stable Diffusion 级别的文本条件、高分辨率、latent 空间和 CFG 结合问题。LCM 的贡献就是把这套思想迁移到 LDM 的工程现实里。
Latent Consistency Distillation:把一致性学习放进 Stable Diffusion 的 latent 空间
在 Stable Diffusion 中,图像 x x x 先由 autoencoder 编码为 latent z = E ( x ) z=\mathcal{E}(x) z=E(x),再由 decoder D ( z ) \mathcal{D}(z) D(z) 还原成图像。扩散过程发生在 latent 空间而非像素空间。LCM 也沿用这个空间,把 consistency distillation 放到 latent 中完成。
在 latent 空间,条件扩散的 PF-ODE 写成:
d z t d t = f ( t ) z t + g 2 ( t ) 2 σ t ϵ θ ( z t , c , t ) , z T ∼ N ( 0 , σ ~ 2 I ) \frac{\mathrm{d}\boldsymbol{z}_t}{\mathrm{d}t} =f(t)\boldsymbol{z}t+ \frac{g^2(t)}{2\sigma_t} \boldsymbol{\epsilon}\theta(\boldsymbol{z}_t,\boldsymbol{c},t), \quad \boldsymbol{z}_T\sim\mathcal{N}(\boldsymbol{0},\tilde{\sigma}^2\boldsymbol{I}) dtdzt=f(t)zt+2σtg2(t)ϵθ(zt,c,t),zT∼N(0,σ~2I)
LCM 引入 consistency function:
f θ : ( z t , c , t ) ↦ z 0 \boldsymbol{f}_\theta:(\boldsymbol{z}_t,\boldsymbol{c},t)\mapsto \boldsymbol{z}_0 fθ:(zt,c,t)↦z0
并用噪声预测模型参数化它:
f θ ( z , c , t ) = c s k i p ( t ) z + c o u t ( t ) ( z − σ t ϵ ^ θ ( z , c , t ) α t ) \boldsymbol{f}\theta(\boldsymbol{z},\boldsymbol{c},t) =c{\mathrm{skip}}(t)\boldsymbol{z} +c_{\mathrm{out}}(t) \left( \frac{\boldsymbol{z}-\sigma_t\hat{\boldsymbol{\epsilon}}_\theta(\boldsymbol{z},\boldsymbol{c},t)} {\alpha_t} \right) fθ(z,c,t)=cskip(t)z+cout(t)(αtz−σtϵ^θ(z,c,t))
这个式子可以理解为:LCM 仍然借用 Stable Diffusion 的 noise prediction 结构,但输出目标不再是一步一步预测下一个 latent,而是直接构造对 z 0 \boldsymbol{z}_0 z0 的一致性预测。ODE solver Ψ \Psi Ψ 只在训练/蒸馏时用于估计轨迹上的相邻点,推理时不再依赖这些多步 solver。
LCM 的基础 consistency distillation loss 为:
L C D ( θ , θ − ; Ψ ) = E z , c , n d ( f θ ( z t n + 1 , c , t n + 1 ) , f θ − ( z \^ t n Ψ , c , t n ) ) \mathcal{L}{\mathcal{CD}}(\theta,\theta^-;\Psi) =\mathbb{E}{\boldsymbol{z},\boldsymbol{c},n} \left d\\left( \\boldsymbol{f}_{\\theta}(\\boldsymbol{z}_{t_{n+1}},\\boldsymbol{c},t_{n+1}), \\boldsymbol{f}_{\\theta\^-}(\\hat{\\boldsymbol{z}}_{t_n}\^{\\Psi},\\boldsymbol{c},t_n) \\right) \\right LCD(θ,θ−;Ψ)=Ez,c,nd(fθ(ztn+1,c,tn+1),fθ−(z\^tnΨ,c,tn))
其中 z ^ t n Ψ \hat{\boldsymbol{z}}{t_n}^{\Psi} z^tnΨ 是用 ODE solver 从 t n + 1 t{n+1} tn+1 演化到 t n t_n tn 的估计:
z ^ t n Ψ − z t n + 1 ≈ Ψ ( z t n + 1 , t n + 1 , t n , c ) \hat{\boldsymbol{z}}{t_n}^{\Psi}-\boldsymbol{z}{t_{n+1}} \approx \Psi(\boldsymbol{z}{t{n+1}},t_{n+1},t_n,\boldsymbol{c}) z^tnΨ−ztn+1≈Ψ(ztn+1,tn+1,tn,c)
从产品角度看,LCD 的意义是:它不是为某个 sampler 手工调参,而是把少步采样能力蒸馏到模型权重里。模型一旦学会这个映射,推理时就可以用极少步数换取接近原扩散模型的质量。
One-Stage Guided Distillation:把 CFG 纳入同一个 ODE 问题
Stable Diffusion 的图像质量高度依赖 classifier-free guidance。CFG 的噪声预测是条件预测与无条件预测的线性组合:
ϵ ~ θ ( z t , ω , c , t ) = ( 1 + ω ) ϵ θ ( z t , c , t ) − ω ϵ θ ( z t , ∅ , t ) \tilde{\boldsymbol{\epsilon}}_\theta(\boldsymbol{z}t,\omega,\boldsymbol{c},t) =(1+\omega)\boldsymbol{\epsilon}\theta(\boldsymbol{z}t,\boldsymbol{c},t) -\omega\boldsymbol{\epsilon}\theta(\boldsymbol{z}_t,\varnothing,t) ϵ~θ(zt,ω,c,t)=(1+ω)ϵθ(zt,c,t)−ωϵθ(zt,∅,t)
过去的 Guided-Distill 路线使用两阶段蒸馏,成本高且可能累计误差。LCM 的处理方式更直接:既然 CFG 改变了 reverse process,那就把 guided reverse diffusion 写成 augmented PF-ODE:
d z t d t = f ( t ) z t + g 2 ( t ) 2 σ t ϵ ~ θ ( z t , ω , c , t ) \frac{\mathrm{d}\boldsymbol{z}_t}{\mathrm{d}t} =f(t)\boldsymbol{z}t+ \frac{g^2(t)}{2\sigma_t} \tilde{\boldsymbol{\epsilon}}\theta(\boldsymbol{z}_t,\omega,\boldsymbol{c},t) dtdzt=f(t)zt+2σtg2(t)ϵ~θ(zt,ω,c,t)
然后训练一个 augmented consistency function:
f θ : ( z t , ω , c , t ) ↦ z 0 \boldsymbol{f}_{\theta}:(\boldsymbol{z}_t,\omega,\boldsymbol{c},t)\mapsto \boldsymbol{z}_0 fθ:(zt,ω,c,t)↦z0
对应的 loss 为:
L C D ( θ , θ − ; Ψ ) = E z , c , ω , n d ( f θ ( z t n + 1 , ω , c , t n + 1 ) , f θ − ( z \^ t n Ψ , ω , ω , c , t n ) ) \mathcal{L}{\mathcal{CD}}(\theta,\theta^-;\Psi) =\mathbb{E}{\boldsymbol{z},\boldsymbol{c},\omega,n} \left d\\left( \\boldsymbol{f}_{\\theta}(\\boldsymbol{z}_{t_{n+1}},\\omega,\\boldsymbol{c},t_{n+1}), \\boldsymbol{f}_{\\theta\^-}(\\hat{\\boldsymbol{z}}_{t_n}\^{\\Psi,\\omega},\\omega,\\boldsymbol{c},t_n) \\right) \\right LCD(θ,θ−;Ψ)=Ez,c,ω,nd(fθ(ztn+1,ω,c,tn+1),fθ−(z\^tnΨ,ω,ω,c,tn))
其中 ω \omega ω 从 ω min , ω max \\omega_{\\min},\\omega_{\\max} ωmin,ωmax 均匀采样。 z ^ t n Ψ , ω \hat{\boldsymbol{z}}_{t_n}^{\Psi,\omega} z^tnΨ,ω 则由条件 solver 和无条件 solver 的线性组合近似:
z ^ t n Ψ , ω − z t n + 1 ≈ ( 1 + ω ) Ψ ( z t n + 1 , t n + 1 , t n , c ) − ω Ψ ( z t n + 1 , t n + 1 , t n , ∅ ) \hat{\boldsymbol{z}}{t_n}^{\Psi,\omega}-\boldsymbol{z}{t_{n+1}} \approx (1+\omega)\Psi(\boldsymbol{z}{t{n+1}},t_{n+1},t_n,\boldsymbol{c}) -\omega\Psi(\boldsymbol{z}{t{n+1}},t_{n+1},t_n,\varnothing) z^tnΨ,ω−ztn+1≈(1+ω)Ψ(ztn+1,tn+1,tn,c)−ωΨ(ztn+1,tn+1,tn,∅)
这一步是 LCM 与"只做 consistency distillation"的关键差别。它不是训练一个固定 CFG scale 的少步模型,而是把 guidance scale 作为输入条件学习进去。后面 Figure 4 和 Figure 5 的消融也证明,LCM 能够在不同 ω \omega ω 下工作,并体现出 CLIP 和 FID 的典型 trade-off。
Skipping-Step:为什么 k = 20 k=20 k=20 这么重要
Stable Diffusion 的训练时序通常有 1000 个 time steps。如果直接对相邻 t n + 1 → t n t_{n+1}\to t_n tn+1→tn 做 consistency distillation,两个点太接近,模型预测本来就相近,loss 信号很弱。这会导致收敛慢。
LCM 的做法是引入 skipping-step:不再约束相邻步,而是约束 t n + k → t n t_{n+k}\to t_n tn+k→tn。论文主实验使用 k = 20 k=20 k=20。修改后的 loss 为:
L C D ( θ , θ − ; Ψ ) = E z , c , ω , n d ( f θ ( z t n + k , ω , c , t n + k ) , f θ − ( z \^ t n Ψ , ω , ω , c , t n ) ) \mathcal{L}{\mathcal{CD}}(\theta,\theta^-;\Psi) =\mathbb{E}{\boldsymbol{z},\boldsymbol{c},\omega,n} \left d\\left( \\boldsymbol{f}_{\\theta}(\\boldsymbol{z}_{t_{n+k}},\\omega,\\boldsymbol{c},t_{n+k}), \\boldsymbol{f}_{\\theta\^-}(\\hat{\\boldsymbol{z}}_{t_n}\^{\\Psi,\\omega},\\omega,\\boldsymbol{c},t_n) \\right) \\right LCD(θ,θ−;Ψ)=Ez,c,ω,nd(fθ(ztn+k,ω,c,tn+k),fθ−(z\^tnΨ,ω,ω,c,tn))
对应估计为:
z ^ t n Ψ , ω ← z t n + k + ( 1 + ω ) Ψ ( z t n + k , t n + k , t n , c ) − ω Ψ ( z t n + k , t n + k , t n , ∅ ) \hat{\boldsymbol{z}}{t_n}^{\Psi,\omega} \leftarrow \boldsymbol{z}{t_{n+k}} +(1+\omega)\Psi(\boldsymbol{z}{t{n+k}},t_{n+k},t_n,\boldsymbol{c}) -\omega\Psi(\boldsymbol{z}{t{n+k}},t_{n+k},t_n,\varnothing) z^tnΨ,ω←ztn+k+(1+ω)Ψ(ztn+k,tn+k,tn,c)−ωΨ(ztn+k,tn+k,tn,∅)
这里的工程直觉很朴素:步子太小,学不到有效差异;步子太大,solver 近似误差会变大。 k = 20 k=20 k=20 是论文实验里相对稳妥的折中。Figure 3 也显示,DDIM 在 k = 1 k=1 k=1 时收敛明显慢, k = 5 , 10 , 20 k=5,10,20 k=5,10,20 更快;而 DPM / DPM++ 对较大 skip 更鲁棒。
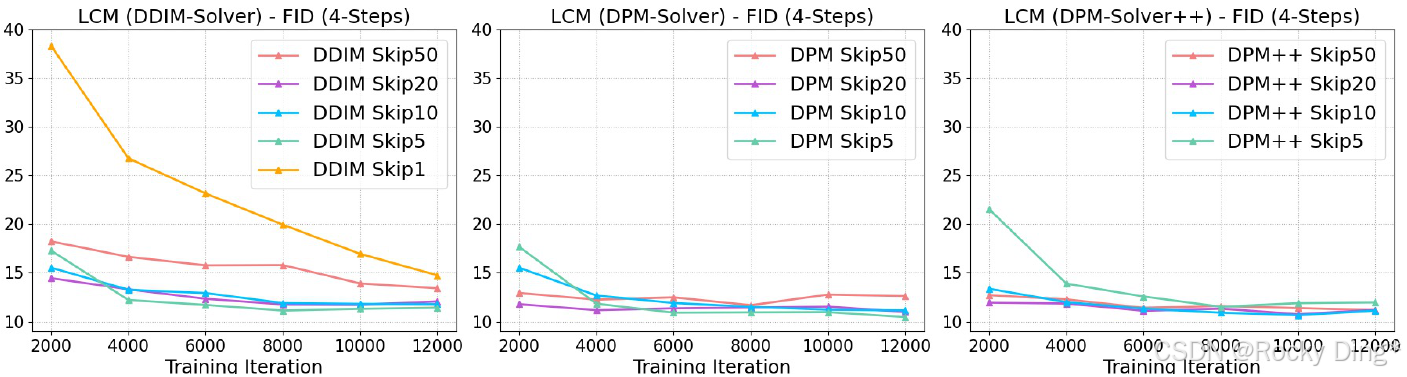
图 3 的价值不只是告诉我们"k=20 好用",而是说明 LCM 的训练效率来自两个层面:一致性目标改变了学习对象,skipping-step 改变了学习信号的有效尺度。Rocky认为,这类技巧对后续少步生成研究很重要,因为模型压缩和采样压缩常常不是单点算法问题,而是训练信号设计问题。
LCM Sampling:少步不是传统多步采样的简单缩短
LCM 推理时的多步采样与传统扩散不同。传统扩散是从 z t z_t zt 预测 z t − 1 z_{t-1} zt−1,沿着时间轴一步步走;LCM 是直接预测 augmented PF-ODE trajectory 的 origin z 0 z_0 z0。如果使用多步 LCM sampling,它会在每一轮对上一次预测结果重新注入噪声,回到某个较晚时间点 τ n \tau_n τn,再用 consistency function 预测 z 0 z_0 z0。
简化理解就是:
- 从高斯噪声 z ^ T \hat{z}T z^T 出发,直接预测一次 z = f θ ( z ^ T , ω , c , T ) z=f\theta(\hat{z}_T,\omega,c,T) z=fθ(z^T,ω,c,T)。
- 若要提升质量,在后续少数步骤里,把当前 z z z 加噪到 τ n \tau_n τn,再预测回 z 0 z_0 z0。
- 最后用 decoder D ( z ) \mathcal{D}(z) D(z) 得到图像。
这个过程解释了为什么论文里 2-step、4-step 通常明显优于 1-step:第一步给出粗结果,后续少数"加噪-回归原点"迭代提供修正空间。但它仍然不是传统扩散的几十步 denoising,而是围绕一致性映射做少数次 refinement。
Latent Consistency Fine-tuning:让少步模型适配小数据风格
LCM 还提出 Latent Consistency Fine-tuning (LCF),用于把预训练 LCM 适配到自定义小数据集。LCF 的重要点在于:它不依赖一个已经在目标数据集上训练好的 teacher diffusion model,而是直接对预训练 LCM 做 consistency fine-tuning。
LCF 随机选择两个相隔 k k k 的时间点 t n t_n tn 和 t n + k t_{n+k} tn+k,用同一个噪声 ϵ \epsilon ϵ 构造:
z t n + k = α ( t n + k ) z + σ ( t n + k ) ϵ , z t n = α ( t n ) z + σ ( t n ) ϵ \boldsymbol{z}{t{n+k}}=\alpha(t_{n+k})\boldsymbol{z}+\sigma(t_{n+k})\boldsymbol{\epsilon}, \quad \boldsymbol{z}_{t_n}=\alpha(t_n)\boldsymbol{z}+\sigma(t_n)\boldsymbol{\epsilon} ztn+k=α(tn+k)z+σ(tn+k)ϵ,ztn=α(tn)z+σ(tn)ϵ
然后直接用 consistency loss 约束这两个时间点的输出一致。这使得 LCF 可以在 Pokemon、Simpsons 这类只有数百张图的自定义数据集上微调,并保持 few-step inference。

图 6 展示 LCF 之后的风格化生成。这里真正值得关注的是 fine-tuning 范式:如果少步生成模型可以像 LoRA 或 DreamBooth 那样适配小数据风格,那么 LCM 不只是一个基础采样加速器,还可能成为个性化图像模型的快速推理层。
实验与证据:结果能支撑到什么程度
数据与训练设置
论文使用 LAION-5B 的两个子集:512×512 实验使用 LAION-Aesthetics-6+,包含约 12M text-image pairs;768×768 实验使用 LAION-Aesthetics-6.5+,包含约 650K text-image pairs。512 分辨率 teacher 是 Stable Diffusion-V2.1-Base,采用 ϵ \epsilon ϵ-prediction;768 分辨率 teacher 是 Stable Diffusion-V2.1,采用 v v v-prediction。
LCM 训练 100K iterations。512 设置 batch size 为 72,768 设置 batch size 为 16,学习率为 8 e − 6 8e^{-6} 8e−6,EMA rate 为 μ = 0.999943 \mu=0.999943 μ=0.999943。主实验使用 DDIM-Solver 与 skipping step k = 20 k=20 k=20,CFG scale 范围为 2 , 14 2,14 2,14。
评测上,论文从测试集 10K text prompts 生成 30K 张图像,每个 prompt 生成 3 张,使用 FID 和 CLIP score 衡量质量、多样性和图文相关性。Baseline 包括 DDIM、DPM、DPM++ 和 Guided-Distill。
512×512:LCM 在 1-4 步区域明显领先
| Model (512×512) | FID 1 Step ↓ | FID 2 Steps ↓ | FID 4 Steps ↓ | FID 8 Steps ↓ | CLIP 1 Step ↑ | CLIP 2 Steps ↑ | CLIP 4 Steps ↑ | CLIP 8 Steps ↑ |
|---|---|---|---|---|---|---|---|---|
| DDIM | 183.29 | 81.05 | 22.38 | 13.83 | 6.03 | 14.13 | 25.89 | 29.29 |
| DPM | 185.78 | 72.81 | 18.53 | 12.24 | 6.35 | 15.10 | 26.64 | 29.54 |
| DPM++ | 185.78 | 72.81 | 18.43 | 12.20 | 6.35 | 15.10 | 26.64 | 29.55 |
| Guided-Distill | 108.21 | 33.25 | 15.12 | 13.89 | 12.08 | 22.71 | 27.25 | 28.17 |
| LCM | 35.36 | 13.31 | 11.10 | 11.84 | 24.14 | 27.83 | 28.69 | 28.84 |
Table 1 的结论非常直接:在 512×512 下,LCM 在 1-step 到 4-step 区间显著领先。尤其 1-step,DDIM / DPM / DPM++ 的 FID 都在 180 左右,Guided-Distill 为 108.21,LCM 降到 35.36;CLIP score 也从 baseline 的低值提升到 24.14。到 4-step 时,LCM FID 为 11.10,已经超过多种 8-step baseline。
这说明 LCM 真正有效的区间不是"无限追求一步",而是 2-4 步。1 步可以生成,但质量和稳定性仍有限;2-4 步则是速度与质量的甜点区。
768×768:高分辨率下仍保持少步优势
| Model (768×768) | FID 1 Step ↓ | FID 2 Steps ↓ | FID 4 Steps ↓ | FID 8 Steps ↓ | CLIP 1 Step ↑ | CLIP 2 Steps ↑ | CLIP 4 Steps ↑ | CLIP 8 Steps ↑ |
|---|---|---|---|---|---|---|---|---|
| DDIM | 186.83 | 77.26 | 24.28 | 15.66 | 6.93 | 16.32 | 26.48 | 29.49 |
| DPM | 188.92 | 67.14 | 20.11 | 14.08 | 7.40 | 17.11 | 27.25 | 29.80 |
| DPM++ | 188.91 | 67.14 | 20.08 | 14.11 | 7.41 | 17.11 | 27.26 | 29.84 |
| Guided-Distill | 120.28 | 30.70 | 16.70 | 14.12 | 12.88 | 24.88 | 28.45 | 29.16 |
| LCM | 34.22 | 16.32 | 13.53 | 14.97 | 25.32 | 27.92 | 28.60 | 28.49 |
Table 2 显示,在 768×768 下,LCM 仍然在 1-4 步区域优势明显。1-step FID 为 34.22,远低于 Guided-Distill 的 120.28;4-step FID 为 13.53,也优于 Guided-Distill 的 16.70 和 DPM/DPM++ 的 20 左右。
但 8-step 时,DPM / DPM++ 的 FID 略优于 LCM。这说明 LCM 的优势区间很明确:它是少步推理的强方法,不一定在较多 step 下始终碾压 solver。对于产品落地,这反而不是缺点,因为 LCM 的目标场景就是低延迟生成。

图 2 是定性结果,对比了 2-step 和 4-step LCM 的图像质量。它支撑的不是单一审美结论,而是少步生成的可用性:在极少推理步数下,图像仍然具有细节、构图和文本语义响应。
CFG scale 消融:更强指导带来质量,也带来多样性代价
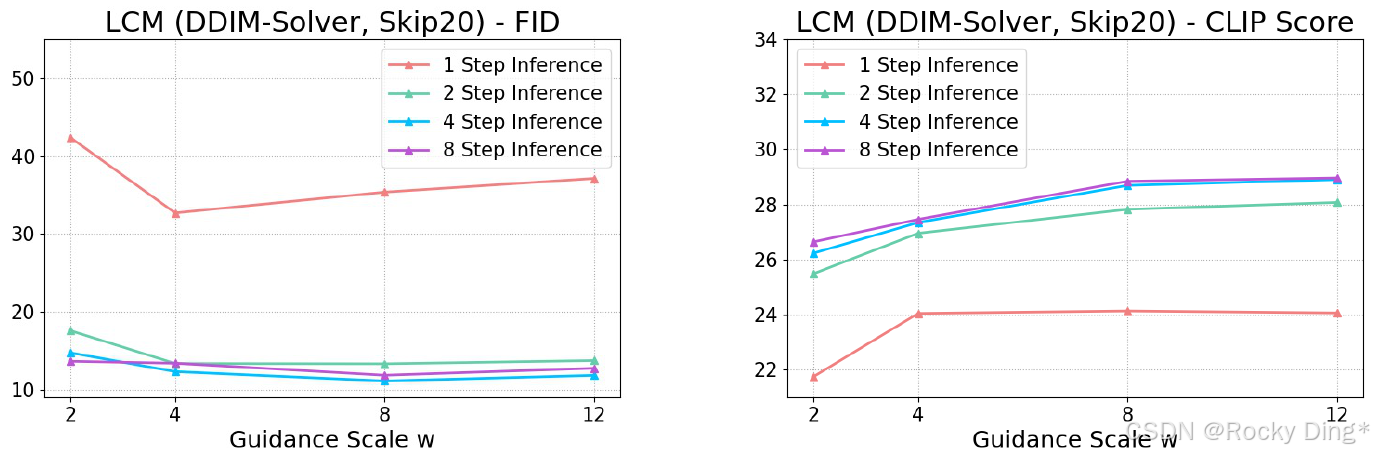
图 4 展示不同 classifier-free guidance scale ω \omega ω 对 LCM 的影响。论文结论符合扩散模型常识:更大的 ω \omega ω 通常提高 CLIP score,也就是图文对齐和视觉质量感更强;但过大的 ω \omega ω 可能牺牲多样性,使 FID 变差。
值得注意的是,2-step、4-step、8-step 之间的 performance gap 很小,说明 LCM 在 2-8 步区间比较稳定;但 1-step 与多步之间仍有明显差距。这再次说明,LCM 的现实最优不是盲目追求一步,而是把少步生成稳定在 2-4 步。

图 5 从视觉上对应 Figure 4 的指标变化。较大的 ω \omega ω 会让图像更"像 prompt 想要的结果",但也可能带来更强风格收敛。对产品来说,这意味着 LCM 仍然需要给用户或系统保留 guidance scale 调节空间,而不是固定一个全局最优值。
扩展生成结果:2 步与 4 步是更真实的产品区间


Figure 7 和 Figure 8 展示附录中的 4-step 与 2-step 结果。论文强调,这些结果同样来自对 Dreamer-V7 版 SD 的 4,000 step 蒸馏。对于行业读者,这里可以看到一个关键产品信号:LCM 不是为了跑 benchmark 才存在,而是为"快速预览-快速迭代-快速创作"这种交互模式服务。
Rocky认为,AIGC 产品里很多时候并不需要每一步都云端慢速生成最终图。用户需要的是一秒内多次试错、快速筛方向、再把高价值结果交给更强模型精修。LCM 这类少步模型恰好可以成为这样的中间层。
这篇工作的边界与可复现性
第一,LCM 的少步优势很强,但 1-step 仍不是完美答案。实验中 1-step 已经比 baseline 好很多,但与 2-step、4-step 仍有明显差距。真实产品中,如果追求稳定质量,2-4 步更现实。
第二,LCM 依赖预训练 teacher model。它不是从零训练出强大文生图模型,而是把已有 Stable Diffusion 的能力蒸馏成少步 consistency function。也就是说,LCM 的上限仍然受 teacher model、数据分布、文本编码器和 VAE 表达能力影响。
第三,评测指标仍有限。FID 和 CLIP 是必要指标,但无法完整覆盖 prompt 遵循、复杂空间关系、计数、文字渲染、多主体组合、审美偏好、多轮编辑等真实需求。论文展示了定性图,但没有系统评估复杂工作流。
第四,训练仍需要不小资源。虽然 32 A100 GPU hours 相比 Guided-Distill 的高成本非常轻,但这仍不是零成本。完整实验中 100K iterations、8 A100、LAION 子集训练,对于个人开发者并不轻。
第五,LCF 的小数据适配有潜力,但论文只展示 Pokemon 和 Simpsons 两类风格数据集。它能否稳定适配更复杂的人物身份、商品图、品牌视觉、专业设计风格,还需要更大范围验证。
第六,LCM 与后来的 LCM-LoRA、SDXL Turbo、SDXL-Lightning、DMD、Rectified Flow 等路线之间的关系,需要放在更长周期里看。LCM 的思想已经进入后续生态,但单篇论文不是所有少步生成路线的终点。
如果继续研究/落地,应该关注什么
对研究者来说,LCM 后续最值得推进的是"少步生成的可控性评测"。少步模型的风险不是不会生成,而是生成太快之后,错误也会更快进入交互。需要评测文本遵循、条件控制、局部编辑、多轮一致性、身份保持、风格保持,而不是只看 FID/CLIP。
对算法工程团队来说,LCM 的关键不是照搬公式,而是理解少步蒸馏的几个工程旋钮:teacher model 选择、prediction parameterization、CFG scale 编码、ODE solver 选择、skipping-step k k k、EMA rate、loss metric、训练数据分辨率。这些都会影响最终速度和质量。
对产品团队来说,LCM 最适合的位置不是"替代所有高质量生成",而是成为低延迟创作层。比如实时预览、草图探索、局部方案快速试错、低成本批量候选生成,再配合慢速高质量模型做最终增强。这种分层工作流,比单纯追求某个模型全能更接近商业现实。
对创业者和投资人来说,要看到 LCM 的行业含义:模型加速本身很快会被基础模型和推理框架吸收,单纯"我集成了 LCM"不是护城河。真正的机会在于谁能把少步生成嵌入工作流,形成用户数据、交互闭环、专业场景模板和分发渠道。
Rocky认为,LCM 是 AIGC 中场的一类代表性技术:它不直接创造一个全新应用品类,却改变了生成模型的交互成本结构。当生成从 30 步、50 步变成 2 步、4 步,产品从"等待结果"变成"连续试错",用户行为会改变,创作流程会改变,商业模型也会改变。
术语与概念速查
| 术语 | 解释 |
|---|---|
| LCM | Latent Consistency Model,在 latent 空间学习 consistency mapping,使高分辨率文生图可用 1-4 步生成。 |
| LDM | Latent Diffusion Model,在压缩 latent 空间而非像素空间进行扩散生成,Stable Diffusion 是代表。 |
| PF-ODE | Probability Flow ODE,与扩散 SDE 共享边缘分布,可用于把采样过程转化为 ODE 求解。 |
| Consistency Function | 把 ODE 轨迹上任意时间点映射回同一轨迹原点的函数。 |
| Self-Consistency | 同一轨迹不同时间点经过 consistency function 后输出应一致的性质。 |
| LCD | Latent Consistency Distillation,把预训练 Stable Diffusion 蒸馏成 latent consistency model。 |
| CFG | Classifier-Free Guidance,通过条件/无条件噪声预测组合增强文本对齐和视觉质量。 |
| Augmented PF-ODE | 把 CFG scale ω \omega ω 纳入 reverse diffusion 过程后的 PF-ODE。 |
| Skipping-Step | 用 t n + k → t n t_{n+k}\to t_n tn+k→tn 而非相邻时间点做一致性训练,加速收敛。 |
| LCF | Latent Consistency Fine-tuning,在自定义小数据集上微调预训练 LCM,保持少步推理。 |
| DDIM / DPM / DPM++ | 常见扩散 ODE solver,可减少采样步数,也可在 LCM 训练中用于估计轨迹点。 |
| FID | 衡量生成分布与真实分布差异的指标,越低越好。 |
| CLIP Score | 衡量图文匹配程度的指标,越高通常表示文本对齐更强。 |
拓展思考:值得继续扩展研究与思考的创新点
第一,少步模型会成为多模型工作流的"实时层"。未来 AIGC 产品可能不再是一个模型从头到尾完成所有任务,而是少步模型负责实时探索,大模型负责精修,控制模型负责结构约束,后处理模型负责局部增强。
第二,consistency distillation 可以扩展到视频、3D、音频和多模态交互。只要一个生成过程可以被视为某种轨迹求解,就可能存在学习轨迹原点映射的空间。当然,视频和 3D 的时空一致性会让问题更难。
第三,LCF 代表了个性化少步生成的方向。未来如果 LCM-LoRA、LCF、DreamBooth 类方法结合得足够好,用户可以在小数据上快速得到个性化模型,并保持低延迟生成,这对内容创作者和品牌视觉工具很有价值。
第四,少步生成需要新的产品指标。FID、CLIP 只能说明图像质量的一部分,低延迟交互还需要看用户试错次数、prompt 修改频率、候选保留率、局部编辑成功率、最终产出转化率。这些才是产品里的真实指标。
第五,少步生成会改变推理成本结构。对于平台型产品,模型从 30-50 步降到 2-4 步,意味着同样算力可以支持更多生成请求,也意味着更低的用户等待时间和更高的交互密度。技术变化最终会反映到商业模型上。
最后回到这篇论文的本质:LCM 不是简单让 Stable Diffusion "跑快一点",而是把扩散模型的采样过程重新表述为可学习的一致性映射。这个范式的长期价值,在于它让生成模型从"慢速结果机器"向"实时创作基础设施"靠近。工具红利会被吸收,但对技术机制、产品交互和商业闭环的判断会长期复利。
推荐阅读
Rocky一直在运营技术交流群(WeThinkIn-技术交流群),这个群的初心主要聚焦于技术话题的讨论与学习,包括但不限于算法,开发,竞赛,科研以及工作求职等。群里有很多人工智能行业的大牛,欢迎大家入群一起学习交流~(请添加小助手微信Jarvis8866,拉你进群~)
1. 深入浅出完整解析AI Agent(AI智能体)的核心基础知识
2025年可以说是AI Agent全面落地应用的元年,因此Rocky在持续撰写对AI Agent的全维度解析文章:深入浅出完整解析AI Agent(AI智能体)的核心基础知识
2. 深入浅出完整解析扩散模型DDPM、DDIM、Classifier/Classifier-Free Guidance、Rectified Flow核心基础知识
和Rocky一起学习探究扩散模型的本质原理与和核心基础知识,同时不断跟进扩散模型的最新发展。Rocky在本文中对扩散模型的本质做了全面系统的梳理与讲解:深入浅出完整解析扩散模型DDPM、DDIM、SDE、Classifier/Classifier-Free Guidance、Rectified Flow核心基础知识
3. 深入浅出完整解析FLUX.2、Seedream(即梦)、Z-image、GLM-Image核心基础知识
https://zhuanlan.zhihu.com/p/1975174691049189562
4. 深入浅出完整解析FLUX.1 Kontext和FLUX.1 Krea核心基础知识
深入浅出完整解析FLUX.1 Kontext和FLUX.1 Krea核心基础知识
5. 深入浅出完整解析DeepSeek系列核心基础知识
6、Sora等AI视频大模型的核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用AI视频大模型,从0到1训练自己的AI视频大模型,AI视频大模型性能测评,AI视频领域未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Sora等AI视频大模型文章地址:深入浅出完整解析Sora、Wan2.1、AnimateDiff、CogVideoX等AI视频大模型核心基础知识
7、Stable Diffusion 3和FLUX.1核心原理,核心基础知识,网络结构,从0到1搭建使用Stable Diffusion 3和FLUX.1进行AI绘画,从0到1上手使用Stable Diffusion 3和FLUX.1训练自己的AI绘画模型,Stable Diffusion 3和FLUX.1性能优化等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion 3和FLUX.1文章地址:深入浅出完整解析Stable Diffusion 3(SD 3)和FLUX.1系列核心基础知识
8、Stable Diffusion XL核心基础知识,网络结构,从0到1搭建使用Stable Diffusion XL进行AI绘画,从0到1上手使用Stable Diffusion XL训练自己的AI绘画模型,AI绘画领域的未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion XL文章地址:深入浅出完整解析Stable Diffusion XL(SDXL)核心基础知识
9、Stable Diffusion 1.x-2.x核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用Stable Diffusion进行AI绘画,从0到1上手使用Stable Diffusion训练自己的AI绘画模型,Stable Diffusion性能优化等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion文章地址:深入浅出完整解析Stable Diffusion(SD)核心基础知识
10、ControlNet核心基础知识,核心网络结构,从0到1使用ControlNet进行AI绘画,从0到1训练自己的ControlNet模型,从0到1上手构建ControlNet商业变现应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
ControlNet文章地址:深入浅出完整解析ControlNet核心基础知识
11、LoRA系列模型核心原理,核心基础知识,从0到1使用LoRA模型进行AI绘画,从0到1上手训练自己的LoRA模型,LoRA变体模型介绍,优质LoRA推荐等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
LoRA文章地址:深入浅出完整解析LoRA(Low-Rank Adaptation)模型核心基础知识
12、深入浅出完整解析AIGC时代Transformer核心基础知识
在AIGC时代中,Transformer为AI行业带来了深刻的变革。Transformer架构正在一步一步重构所有的AI技术方向,成为AI技术架构大一统与多模态整合的关键核心基座,大有一统"AI江湖"之势。Rocky也对Transformer模型进行持续的深入浅出梳理与解析:
Transformer文章地址:深入浅出完整解析AIGC时代Transformer核心基础知识
13、最全面的AIGC面经《手把手教你成为AIGC算法工程师,斩获AIGC算法offer!(2024年版)》文章正式发布!
码字不易,欢迎大家多多点赞:
AIGC面经文章地址:手把手教你成为AIGC算法工程师,斩获AIGC算法offer!
14、50万字大汇总《"三年面试五年模拟"之算法工程师的求职面试"独孤九剑"秘籍》文章正式发布!
码字不易,欢迎大家多多点赞:
算法工程师三年面试五年模拟文章地址:https://zhuanlan.zhihu.com/p/545374303
《三年面试五年模拟》github项目地址(希望大家能多多star):https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer
15、Stable Diffusion WebUI、ComfyUI、Fooocus三大主流AI绘画框架核心知识,从0到1搭建AI绘画框架,从0到1使用AI绘画框架的保姆级教程,深入浅出介绍AI绘画框架的各模块功能,深入浅出介绍AI绘画框架的高阶用法等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
AI绘画框架文章地址:深入浅出完整解析主流AI绘画框架(ComfyUI、Stable Diffusion WebUI、Fooocus)核心基础知识
16、GAN网络核心基础知识,网络架构,GAN经典变体模型,经典应用场景,GAN在AIGC时代的商业应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
GAN网络文章地址:https://zhuanlan.zhihu.com/p/663157306
17. AI算法工程师的《三年面试五年模拟》求职秘籍
18. AIGC产业的深度思考与分析
2023年3月21日,微软创始人比尔·盖茨在其博客文章《The Age of AI has begun》中表示,自从1980年首次看到图形用户界面(graphical user interface)以来,以OpenAI为代表的科技公司发布的AIGC模型是他所见过的最具革命性的技术进步。
Rocky也认为,AIGC及其生态,会成为AI行业重大变革的主导力量。AIGC会带来一个全新的红利期,未来随着AIGC的全面落地和深度商用,会深刻改变我们的工作、生活、学习以及交流方式,各行各业都将被重新定义,过程会非常有趣。
那么,在此基础上,我们该如何更好的审视AIGC的未来?我们该如何更好地拥抱AIGC引领的革新?Rocky准备从技术、产品、商业模式、长期主义等维度持续分享一些个人的核心思考与观点,希望能帮助各位读者对AIGC有一个全面的了解: