Excel Python:飞速搞定数据分析与处理

第四部分 使用 xlwings 对 Excel 应用程序进行编程
第十二章 用户定义函数
前面 3 章展示了如何使用 Python 脚本自动化 Excel,以及如何在 Excel 中一键执行这样的脚本。本章会介绍另一种利用 xlwings 在 Excel 中调用 Python 代码的方法,即用户定义函数 (user-defined function,UDF)。 UDF 是可以用在 Excel 单元格中的 Python 函数,就像使用内置的 SUM 函数和 AVERAGE函数一样。和第 11 章一样,我们首先从 quickstart 命令开始,尝试创建第一个 UDF。然后进入案例研究,学习如何从 Google Trends 上获取和处理数据,以便处理一些更复杂的 UDF:学习如何处理 pandas DataFrame 和图表,以及如何调试 UDF。最后本章会以性能优化为中心深入了解一些高级主题。不幸的是,xlwings 在 macOS 中不支持 UDF,所以本章需要你在 Windows 中运行示例代码。
12.3 高级 UDF 主题
在工作簿中大量使用 UDF 可能会造成性能问题。本节首先会展示一些基础的性能优化技巧,这些技巧与第 9 章中讲到的类似,不过是用在 UDF 上的。然后会介绍缓存,这是另一种可以用在 UDF 上的性能优化技巧。在这个过程中,我们会了解到如何让函数参数以 xlwings range 对象的形式而不是值的形式传递。最后会介绍 xw.sub 装饰器。如果你只在 Windows 中工作的话,那么它可以用来代替 RunPython 调用。
12.3.1 基础性能优化
本节会着眼于两种性能优化技巧:最小化跨应用程序调用 以及使用原始值转换器。
1、 最小化跨应用程序调用
还记得第 9 章中提到过,跨应用程序调用就是指横跨 Excel 和 Python 的调用,相对较慢,所以用到的 UDF 越少越好。因此你应该尽可能地使用数组,而选用支持动态数组的 Excel 肯定会让这部分内容更加轻松。在使用 pandas DataFrame 时没什么可以出错的地方,但是对于某些公式来说你可能无法马上就想到使用数组。考虑图 12-11 中的例子,给定的 Base Fee(基本费用)加上由 Users(用户数量)乘以 Price(价格)决定的可变费用, 最终得到总利润。
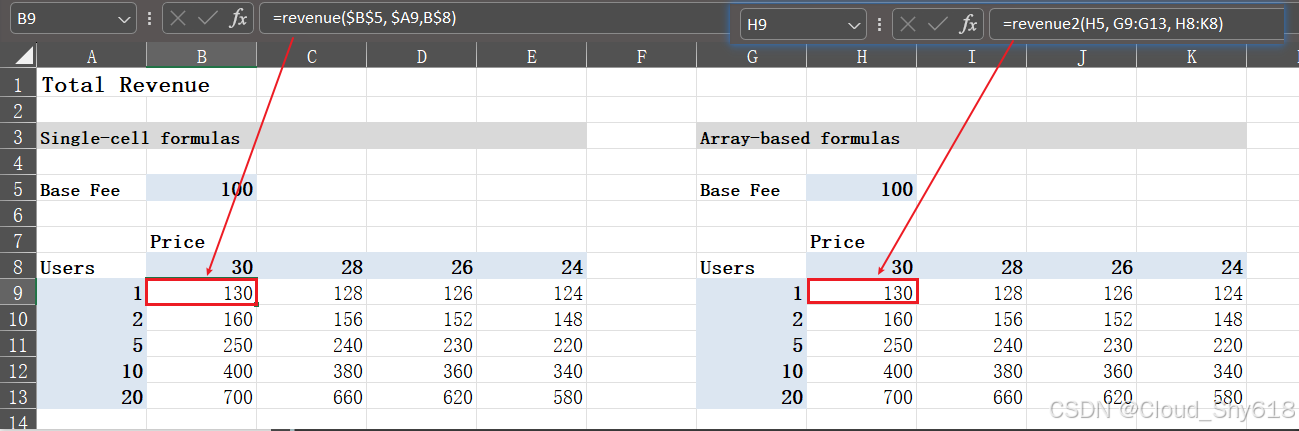
图 12-11:单个单元格公式(左)和基于数组的公式(右)
单个单元格公式:图 12-11 左侧的表格在 B9 单元格中使用了公式 =revenue(B5, A9, B8)。这个公式随后会被应用到整个 B9:E13 区域。这就意味着你会有 20 个调用 revenue 函数的单个单元格公式。
基于数组的公式:图 12-11 右侧的表格使用了公式 =revenue2(H5, G9:G13, H8:K8)。如果你的 Excel 不支持动态数组,那么就需要在 revenue2 函数上加上装饰器 xw.ret(expand="table");或者选中 H9:K13,然后按下 F2 键编辑公式,用快捷键 Ctrl+Shift+Enter 确认以将数组转换为旧式 CSE 数组。与单个单元格公式不同,这个版本只会调用一次 revenue2 函数。
在例 12-5 中可以看到两个 UDF 的 Python 代码,源文件可以在配套代码库的 udfs 目录下的 revenues 文件夹中找到。
例12-5 revenues.py
import numpy as np
import xlwings as xw
@xw.func
def revenue(base_fee, users, price):
return base_fee + users * price
@xw.func
@xw.arg("users", np.array, ndim=2)
@xw.arg("price", np.array)
def revenue2(base_fee, users, price):
return base_fee + users * price如果分别修改 B5 单元格或 H5 单元格中的基本费用,你会发现右边的例子会比左边的快很多。Python 函数中的区别并不大,只有装饰器的参数有区别:基于数组的版本会将 users 和 prices 以 NumPy 数组的形式读入。这里唯一要注意的是,需要在参数装饰器中设置ndim=2 才能将 users 以二维列向量的形式读取。你可能还记得 NumPy 数组类似于 DataFrame,但没有索引或标头,且只有一种数据类型。
2、使用原始值
使用原始值意味着要略过 xlwings 基于 pywin32(xlwings 在 Windows中的依赖项)进行的数据准备和清理工作。举例来说,这就意味着你无法再直接操作 DataFrame,因为 pywin32 不能理解 DataFrame 的数据。但是如果你使用的是列表或者 NumPy 数组,这就不成问题了。要通过原始值使用 UDF,需要在参数装饰器或者返回装饰器中使用字符串 raw 作为 convert 参数的值。这和第 9 章在 xlwings range 对象的 options 方法中使用 raw 转换器是等效的。和之前一样,在执行写入操作时你会得到巨大的速度提升。如果不使用返回装饰器,那么下面的函数在作者的计算机上要慢 1/3:
import numpy as np
import xlwings as xw
@xw.func
@xw.ret("raw")
def randn(i=1000, j=1000):
"""
利用 NumPy 提供的 random.randn 函数生成一个服从正态分布的伪随机数数组,维度为(i, j)
"""
return np.random.randn(i, j)你可以在配套代码库的 udfs 目录下的 raw_values 文件夹中找到对应的例子。在使用 UDF 时,还有一项简单的操作可以获得性能的提升:通过缓存结果来防止重复计算。
12.3.2 缓存
在调用确定型 (deterministic)函数(比如,给定同样的输入总是会返回同样的输出的函数)时,你可以将结果保存在缓存中:这类函数的重复调用不再需要等待缓慢的计算过程,而是可以直接利用在缓存中已经计算好的结果。最好的办法是用一个例子来解释这种机制。基本的缓存机制可以用字典来编写:
In [7]: import time
In [8]: cache = {}
def slow_sum(a, b):
key = (a, b)
if key in cache:
return cache[key]
else:
time.sleep(2) # 休眠两秒
result = a + b
cache[key] = result
return result在第一次调用这个函数时,cache 是空的。此时代码会执行 else 分句并主动休眠两秒来模拟缓慢的运算过程。在运算完成后、返回结果前,它会将结果加入 cache 字典中。在同一个 Python 会话中使用同样的参数再次调用这个函数时,它会在 cache 中查找结果并立即返回,而不必再次执行缓慢的运算过程。根据参数缓存结果也被称为 "记忆" (memoization)。相应地,你可以看到第一次调用函数和第二次调用函数所用的时间差:
In [9]: %%time
slow_sum(1, 2)
Wall time: 2.01 s
Out[9]: 3
In [10]: %%time
slow_sum(1, 2)
Wall time: 0 ns
Out[10]: 3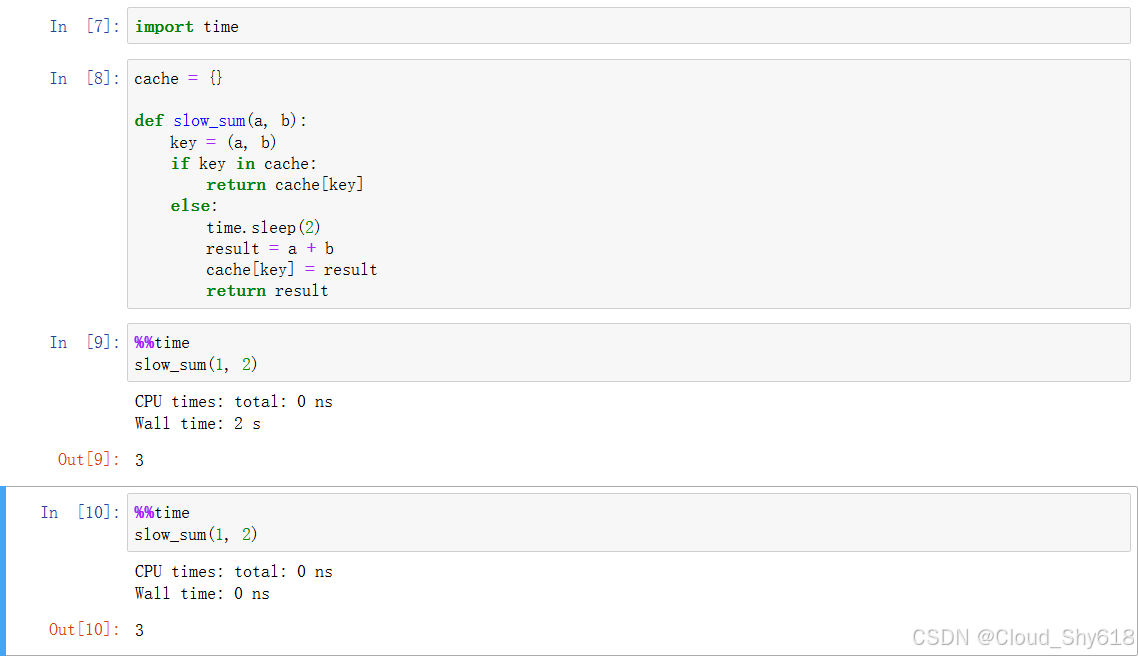
Python 有一个内置的 lru_cache,它能让你的工作轻松不少。lru_cache 是标准库的一部分,你可以从 functools 模块中导入它。lru 代表 **least recently used(最近最少使用)**缓存,这意味着在丢弃存在时间最长的缓存项之前,它最多可以保存 128 个结果(默认为 128 个)。我们可以把它用在上一节的 Google Trends 的例子中。只要是在查询历史值,就可以安全地缓存结果。这不仅会让重复调用更快,也会减少发送至谷歌的请求,从而降低谷歌将我们屏蔽的概率。也就是说,如果你在短时间内发送了大量请求,那么谷歌可能会把你屏蔽。
如果要使用缓存,就需要对 get_interest_over_time 函数进行一些必要的更改。下面是修改后的函数的前几行。
from functools import lru_cache ➊
import pandas as pd
from pytrends.request import TrendReq
import matplotlib.pyplot as plt
import xlwings as xw
@lru_cache ➋
@xw.func(call_in_wizard=False)
@xw.arg("mids", xw.Range, doc="Machine IDs: A range of max 5 cells") ➌
@xw.arg("start_date", doc="A date-formatted cell")
@xw.arg("end_date", doc="A date-formatted cell")
def get_interest_over_time(mids, start_date, end_date):
"""查询Google Trends:在返回值中将常见编程语言的Machine ID (mid)
替换成人类可读的名称,例如,对于Machine ID "/m/05z1_"会返回"Python"
"""
mids = mids.value ➍➊ 导入 lru_cache 装饰器。
➋ 使用装饰器,必须将其放在 xw.func 上面。
➌ 在默认情况下,mids 是一个列表。在本例中这会造成一个问题,因为以列表为参数的函数无法进行缓存。根本的问题在于列表是可变对象,它们无法用作字典的键,可以参见附录 C 了解更多关于可变与不可变对象的内容。使用 xw.Range 转换器可以将 mids 以 xlwings range 对象而不是列表的形式返回,这样就解决了问题。
➍ 为了使剩余部分的代码依然能够工作,现在需要通过 xlwings range 对象的 value 属性来获取值。
**注意:不同Python版本中的缓存 ** 如果你的 Python 版本低于 3.8,则必须在使用装饰器时带上圆括号,就像这 样:@lru_cache()。如果你使用的是 Python 3.9 或者更高的版本,则需要将 @lru_cache 换成 @cache,这和 @lru_cache(maxsize=None) 是一样的,也就是说缓存永远不会丢弃存在时间较长的值。cache 装饰器也需要从 functools 中导入。
具体修改如下图所示:
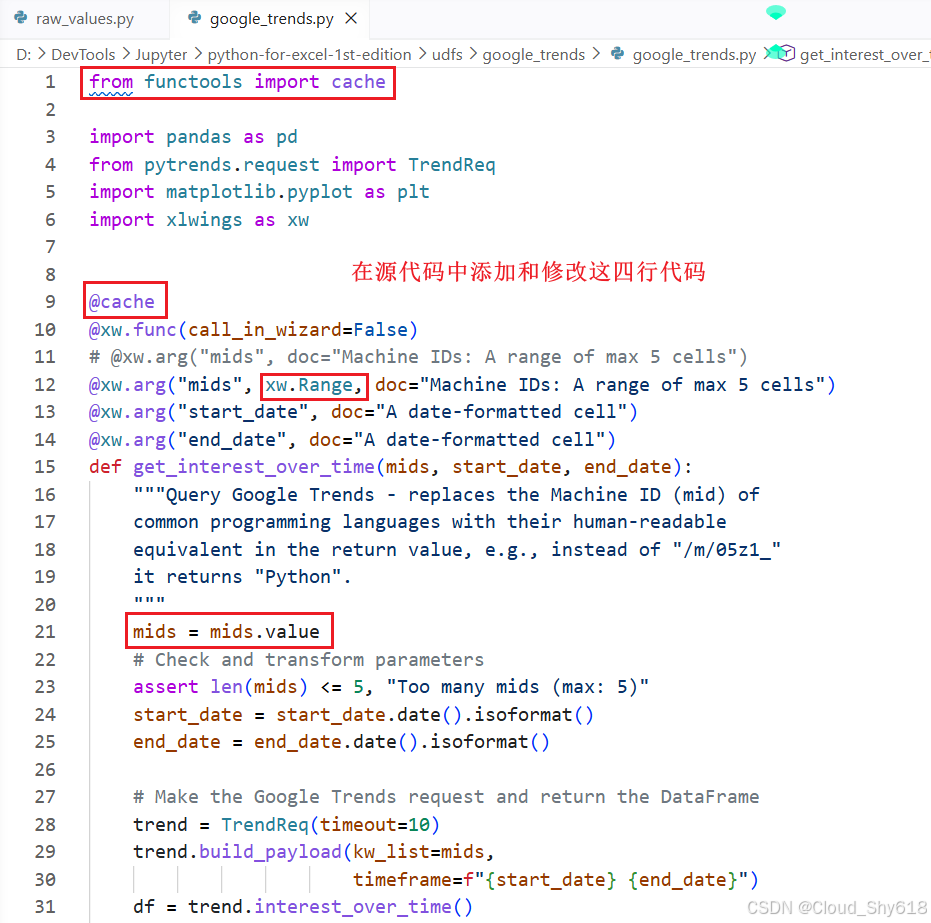
xw.Range 转换器在其他一些场景中也很有用, 比如在你需要获取单元格的公式而不是 UDF 的值的时候。在前面的例子中,你可以用 mids.formula 来获取单元格的公式。你可以在配套代码库的 udfs 目录下的 google_trends_cache 文件夹中找到完整的示例。
现在你已经知道如何优化 UDF 的性能,最后再来介绍一下 xw.sub 装饰器。
12.3.3 sub 装饰器
第 10 章展示过如何通过激活 Use UDF Server 选项来加速 RunPython 调用。如果你只使用 Windows,则可以通过 xw.sub 装饰器来替代 RunPython 和 Use UDF Server 选项。这个装饰器可以将 Python 函数以子程序的形式导入 Excel,而不需要手动编写任何 RunPython 调用。 在 Excel 中,只有子程序才能附加到按钮上,通过 xw.func 装饰器得到的 Excel 函数则不行。为了尝试一下这个装饰器,来创建一个叫作 importsub 的 quickstart 项目。和往常一样,首先通过 cd 命令移动到你想创建项目的目录下:
(base)> xlwings quickstart importsub这里,我们直接在配套代码库中,进入 importsub 文件夹,在 Excel 中打开 importsub.xlsm,在 VS Code 中打开 importsub.py。然后像例 12-6 那样用 @xw.sub 装饰 main 函数。
例 12-6 importsub.py(节选)
import xlwings as xw
@xw.sub
def main():
wb = xw.Book.caller()
sheet = wb.sheets[0]
if sheet["A1"].value == "Hello xlwings!":
sheet["A1"].value = "Bye xlwings!"
else:
sheet["A1"].value = "Hello xlwings!"在 xlwings 插件中点击 Import Functions 按钮,然后按下快捷键 Alt+F8 查看可用的宏:除了使用 RunPython 的 SampleCall,你现在还能看到一个叫作 main 的宏。
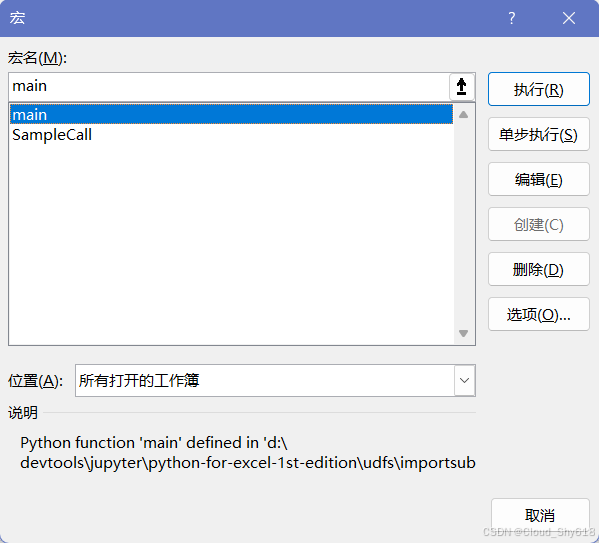
选中它并按下运行按钮后,你可以在 A1 单元格中看到熟悉的问候语 "Hello xlwings!"。现在你可以像第 10 章那样将 main宏指派给一个按钮。虽然 xw.sub 装饰器可以让 Windows 中的工作更轻松,但是要记住:一旦使用了这个装饰器 ,你的工具就不再具备跨平台兼容性了。算上 xw.sub 之后我们就见识到了 xlwings 的所有装饰器,表 12-1 对此进行了总结。

12.4 小结
本章主要讲的是编写 Python 函数并将它们作为 UDF 导入 Excel,从而可以经由单元格公式来调用这些 Python 函数。通过 Google Trends 这个案例研究,我们学习了如何通过 arg 装饰器和 ret 装饰器来改变函数参数和返回值的行为。最后,本章展示了一些性能优化的 技巧,并介绍了 xw.sub 装饰器。如果你只在 Windows 中工作,那么可以通过 xw.sub 装饰器来替代 RunPython。使用 Python 编写 UDF 的好处在于,你可以用更易于理解和维护的 Python 代码来替代冗长且复杂的单元格公式。作者个人比较喜欢的 UDF 用法当然是搭配 pandas DataFrame 和 Excel 新增的动态数组来使用,这种组合在处理 Google Trends 这类数据(行数会动态变化的 DataFrame)时会更加方便。
再见
至此,关于 Python 数据分析基础入门学习笔记系列就全部结束了。博主本人也是第一次较为系统地将这本书《Excel Python:飞速搞定数据分析与处理》的内容从头到尾全部实现出来,并且记录下来分享给感兴趣的小伙伴们。其中不足之处较多,细节尚有欠缺,还望各位海涵不吝赐教。未来,博主还是依然坚持学习新鲜知识,继续分享。好啦,这就是 Cloud_Shy 的小小总结,最后一句共勉之:Don't be shy, dare to share!