写在前面
这篇文章并不是"为了讲 Flow API"而写。
而是一次真实团队讨论后的总结。
前段时间,我在看其他团队代码时,发现他们的 Data 层里存在类似这样的设计:
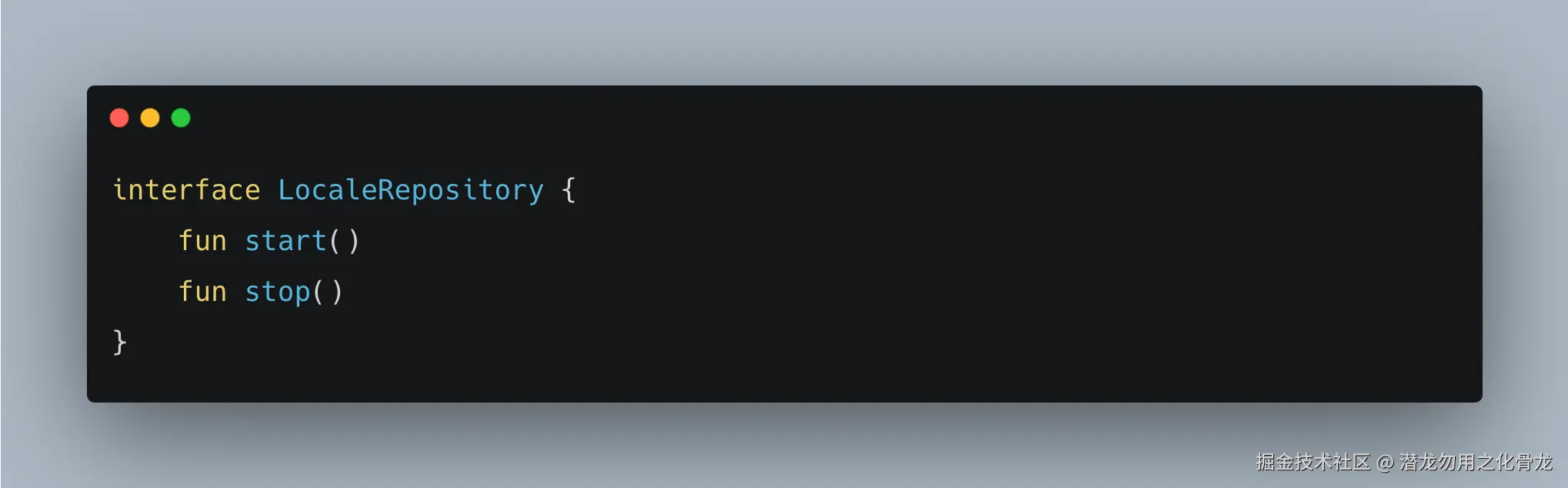
内部通过:
start()注册系统广播stop()反注册广播
来监听系统状态变化。
我当时就指出
- 生命周期边界开始变得模糊
- stop 是否一定调用很难保证
- 多页面共享后并发状态容易错乱
- 调用链越来越依赖人为约定
于是我们围绕这个问题聊了很久。
原本只是一次普通 Code Review,最后却逐渐演变成:
- Data 层职责边界
- 结构化生命周期
- Flow 的真正价值
- 资源自动收敛
这些更底层的架构问题。
后来回头看,我发现:
很多项目里的生命周期 Bug,
本质上都来自"资源脱离了结构化管理"。
我后来还意识到:
很多所谓"生命周期问题",
其实并不是生命周期本身复杂。
而是资源生命周期没有被结构化托管。
这也是为什么:
- 协程强调 Structured Concurrency
- Flow 强调 collect/cancel
- Compose 强调 Composition 生命周期
本质上都在解决同一件事:
让资源生命周期能够自动收敛。
于是才有了这篇文章。
背景
在 Repository 中监听系统广播(例如系统语言变化)时,很多项目会这样设计:
内部:
start()->registerReceiver(...)stop()->unregisterReceiver(...)
这种模式看起来直观,但在真实工程里,往往会逐渐演变成:
- 生命周期难以统一
- 调用链复杂
- stop 漏调导致资源泄漏
- 并发状态容易错乱
- 边界情况下出现异常崩溃
尤其当页面越来越多、协程越来越复杂时:
"谁负责 stop()"
往往会变成一个长期隐患。
更深层的问题:它破坏了结构化生命周期
很多人第一次看到这个问题时,会觉得:
"不就是记得调用 stop() 吗?"
但真正的问题并不只是"容易忘"。
而是:
start/stop让资源生命周期脱离了结构化作用域管理。
什么叫"结构化"
结构化并发(Structured Concurrency)最核心的思想其实不是协程。
而是:
生命周期必须被父作用域托管。
也就是说:
- 谁创建资源
- 谁持有资源
- 谁取消资源
- 谁释放资源
都应该是:
可追踪、可收敛的。
例如协程里:
kotlin
viewModelScope.launch { ... }当 ViewModel 销毁时:
- 子协程自动 cancel
- 生命周期自动结束
- 不需要手动 stop
这就是:
生命周期跟随作用域自动收敛。
而 start/stop 恰恰破坏了这一点
生命周期开始依赖:
- 人为约定
- 调用顺序
- 外部记忆力
这本质上属于:
非结构化资源管理
为什么不建议 Data 层对外暴露 stop()
1)职责不纯:Data 层不应该暴露资源控制细节
Data 层应该回答的是:
"数据是什么"
而不是:
"你什么时候来 start/stop 我"
当 Repository 暴露:
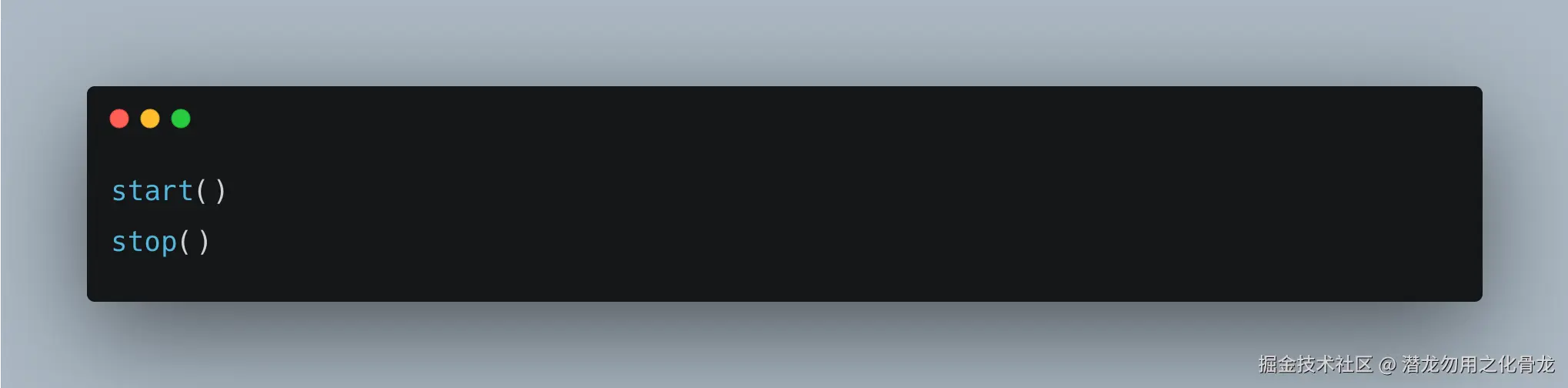
实际上意味着:
- 上层必须理解内部资源模型
- 必须知道什么时候注册
- 必须知道什么时候释放
- 必须知道 stop 是否必须成对调用
这说明:
内部生命周期细节已经泄漏到了外部。
而更好的抽象应该是:

调用方只需要:
"我订阅数据即可。"
至于内部:
- 是广播
- 是 callback
- 是 ContentObserver
- 还是系统 API
都应该被 Data 层屏蔽。
2)调用契约脆弱:系统稳定性依赖"记忆力"
start/stop 模型,本质上依赖调用方保证:
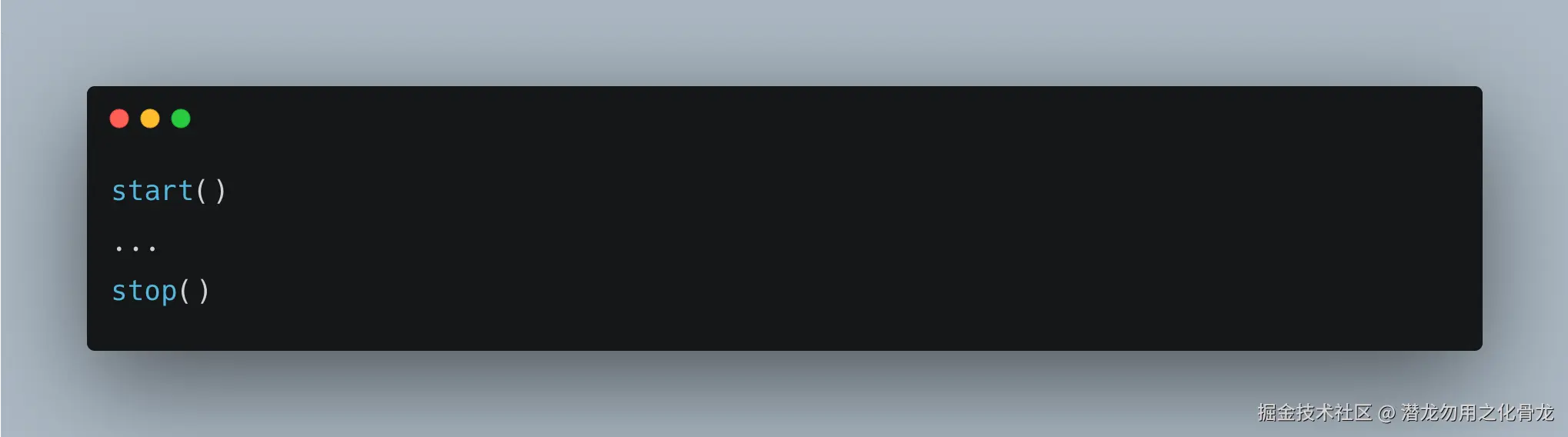
必须严格成对。
但真实项目里:
- 页面跳转
- 生命周期中断
- 协程取消
- 异常提前 return
- 多页面共享
都可能导致 stop() 被遗漏。
最终带来的问题包括:
- Receiver 泄漏
- 重复注册
- 状态错位
- Context 泄漏
Receiver not registered崩溃
系统稳定性开始依赖:
"调用方有没有记得 stop()"
这是非常脆弱的架构设计。
3)并发复杂度高:共享状态容易失控
很多 start/stop 实现还会维护:

但在并发场景下:
- A 协程调用
start() - B 协程几乎同时调用
stop() - 标志位更新顺序与系统调用顺序错位
很容易出现:
- 重复注册
- 重复反注册
- 状态与真实资源不一致
问题本质在于:
isRegistered变成了额外维护的"生命周期真相源(Source of Truth)"。
而多个线程同时修改它时,复杂度会迅速上升。
推荐方案
使用:

核心思想:
- collect 开始时注册资源
- collect 结束时自动释放资源
- 生命周期跟随订阅关系自动开关
而不是:
"依赖外部手动 stop()"
Flow 方案为什么更结构化
看这个:
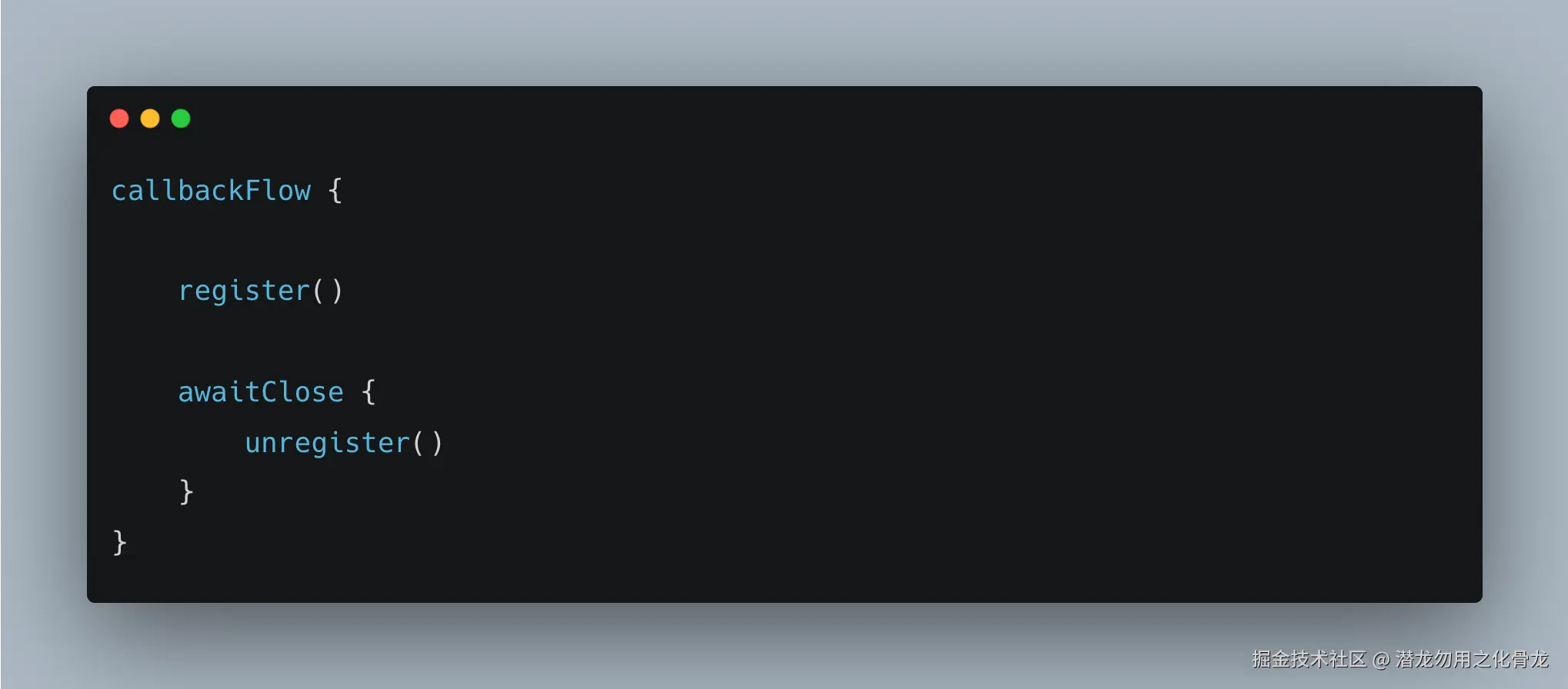
这里其实形成了一个非常清晰的结构:
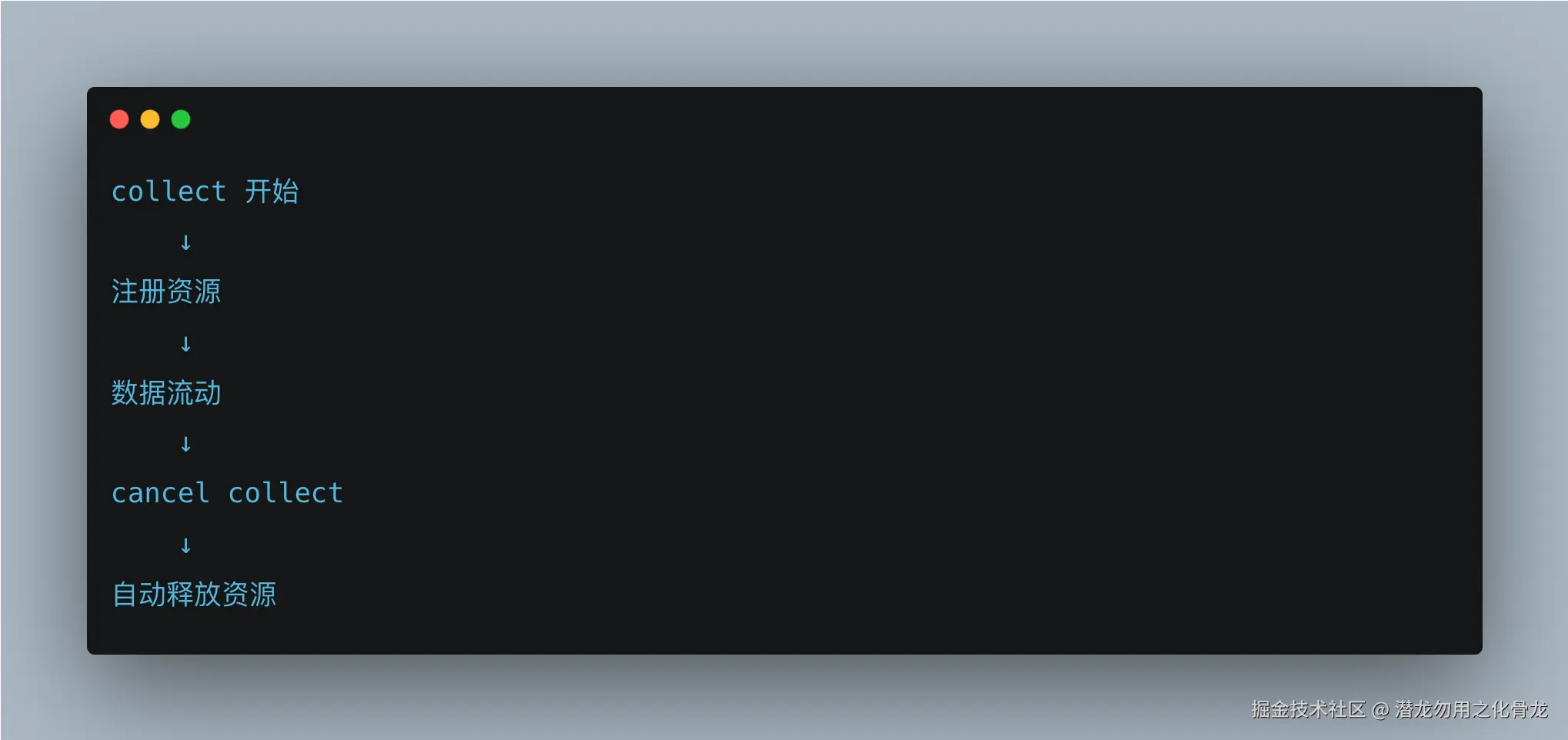
生命周期完全绑定在:

这条链路里。
因此:
- 不需要外部 stop
- 不需要共享状态
- 不需要额外生命周期同步
资源生命周期天然被协程作用域托管。
这其实就是:
结构化资源管理
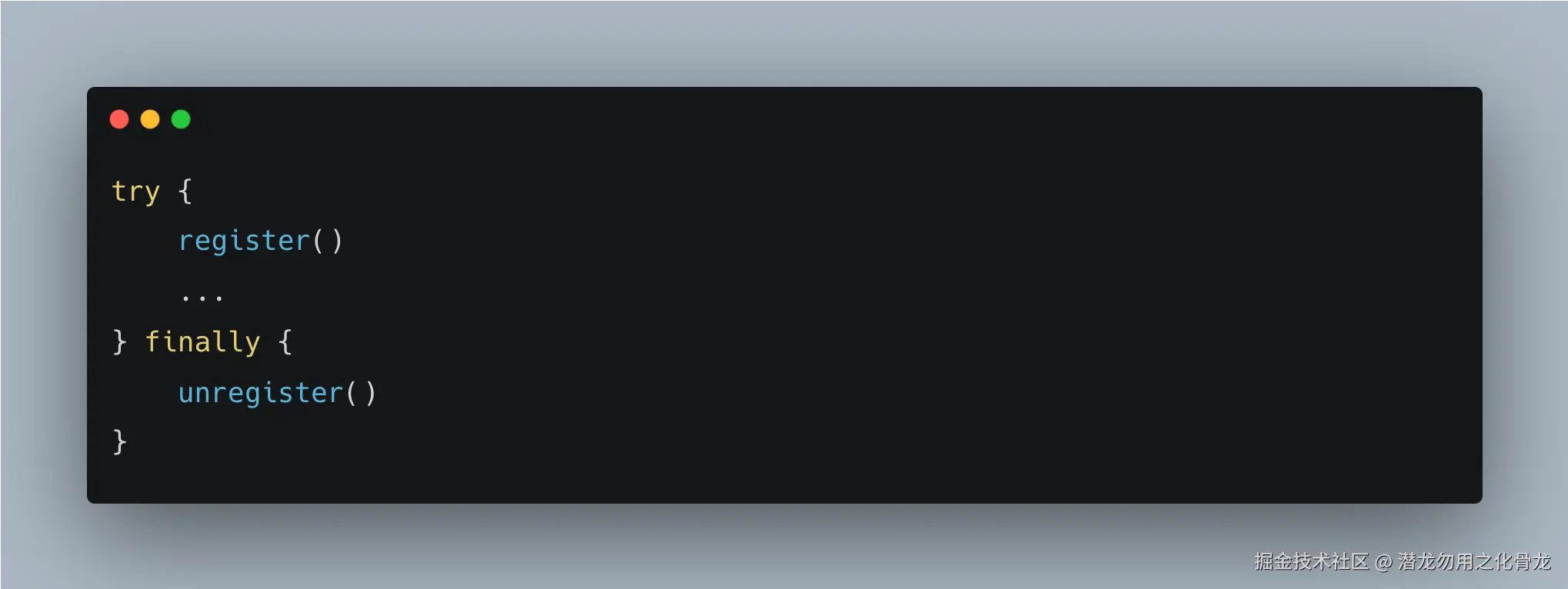
它本质上很像 try/finally
这个类比非常重要。
本质上类似:
而:
更像:
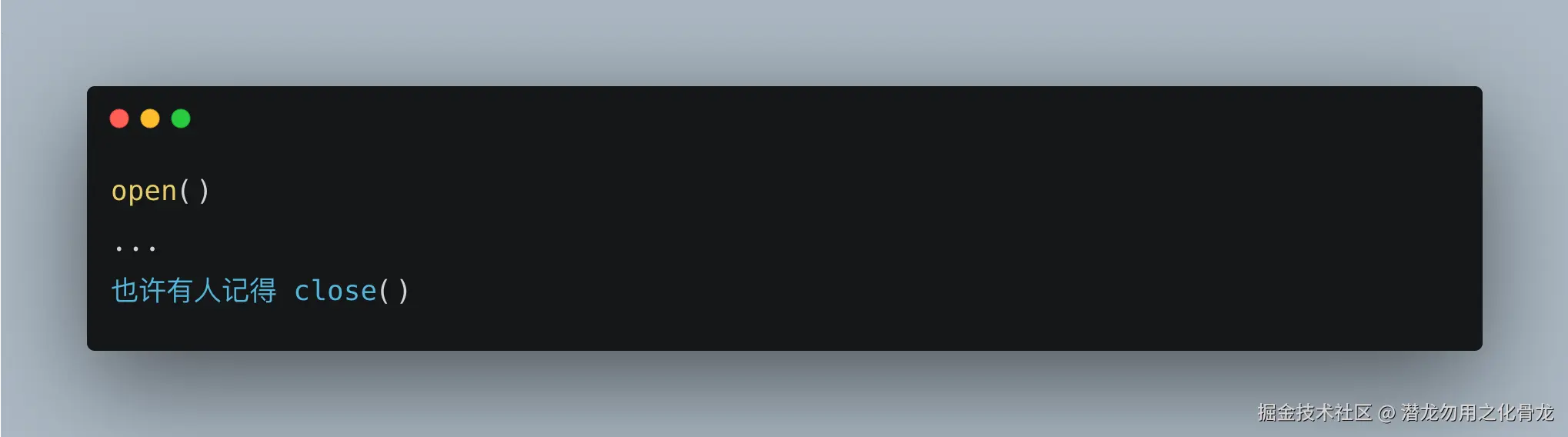
区别非常大。
为什么这不仅是"代码更优雅"
很多人第一次接触 callbackFlow 时,会觉得:
"只是把 register/unregister 写到了 awaitClose 里。"
但真正重要的并不是代码写法变化。
而是:
资源生命周期从"人为管理",变成了"订阅关系驱动"。
这会直接影响:
- 稳定性
- 并发复杂度
- API 设计
- 团队协作成本
这样设计的工程收益
1)稳定性收益:减少"漏 stop"导致的线上故障
传统模型里:
资源释放依赖人为调用。
而 Flow 模型里:
生命周期跟随订阅自动结束。
改成 callbackFlow + awaitClose 后:
- collect 开始自动注册
- collect 结束自动释放
- 不再依赖调用方记忆 stop
因此:
- 生命周期边界统一
- 泄漏概率显著下降
- 大量边界状态问题被消灭
包括:
- Receiver 泄漏
- Context 泄漏
- 重复 unregister
Receiver not registered
2)架构收益:Data 层职责更纯
Data 层只负责:
"输出数据流"
而不再暴露资源控制行为。
因此:
- API 更清晰
- 分层边界更稳定
- 上层不感知内部实现
- 后续实现更容易替换
例如未来从:
- BroadcastReceiver 切换成:
- callback API
- ContentObserver
- 系统监听器
上层几乎无需改动。
这会大幅降低:
"改一个 Repo,多个 ViewModel 跟着改"
的连锁成本。
3)并发收益:天然降低状态竞争
在 Flow 模型里:
"订阅关系本身,就是真实生命周期状态。"
因此:
- 不再需要
isRegistered - 不再需要共享布尔状态
- 不再维护额外生命周期真相源
生命周期直接由:
kotlin
collect / cancel驱动。
这会天然降低并发状态竞争。
5)协作收益:降低团队心智负担
新同学看到:

会天然知道:
"collect 即可。"
但如果看到:
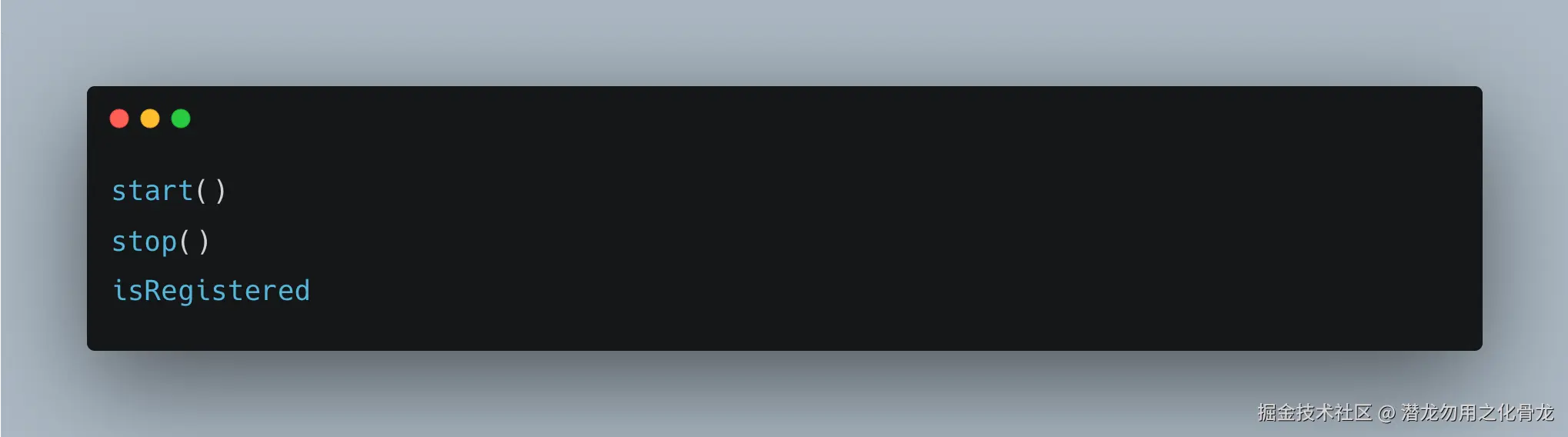
则必须继续追踪:
- 生命周期
- 调用链
- 边界状态
- 是否允许重复调用
团队整体理解成本会明显升高。
统一 Flow 风格后:
- API 更一致
- Code Review 更聚焦
- 故障边界更集中
- 协作效率更高
示例实现(系统语言变化监听)
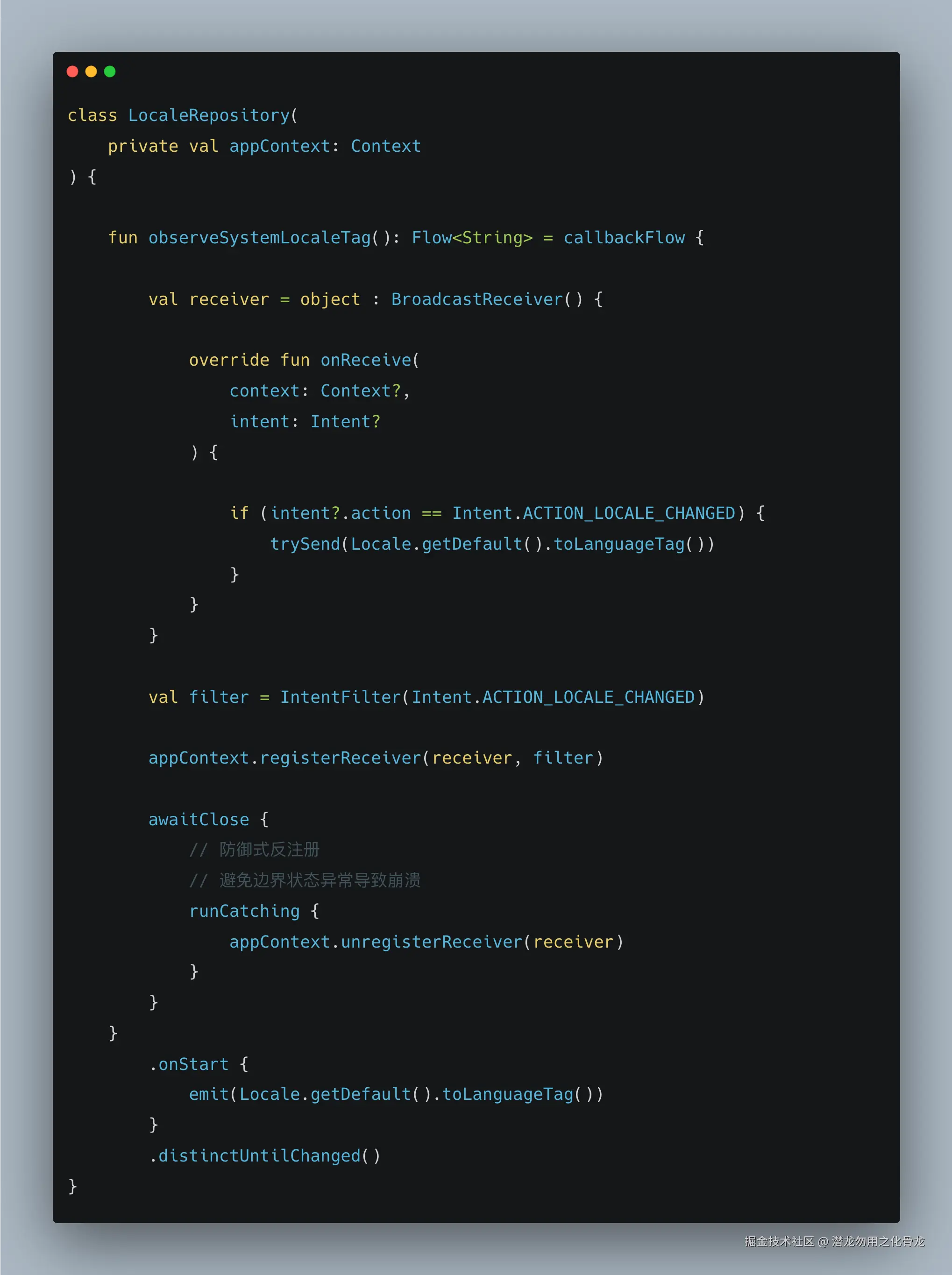 当然你也可以先把数据发出去一次,我这里只是示例
当然你也可以先把数据发出去一次,我这里只是示例
上层使用建议
推荐在 ViewModel 中共享:
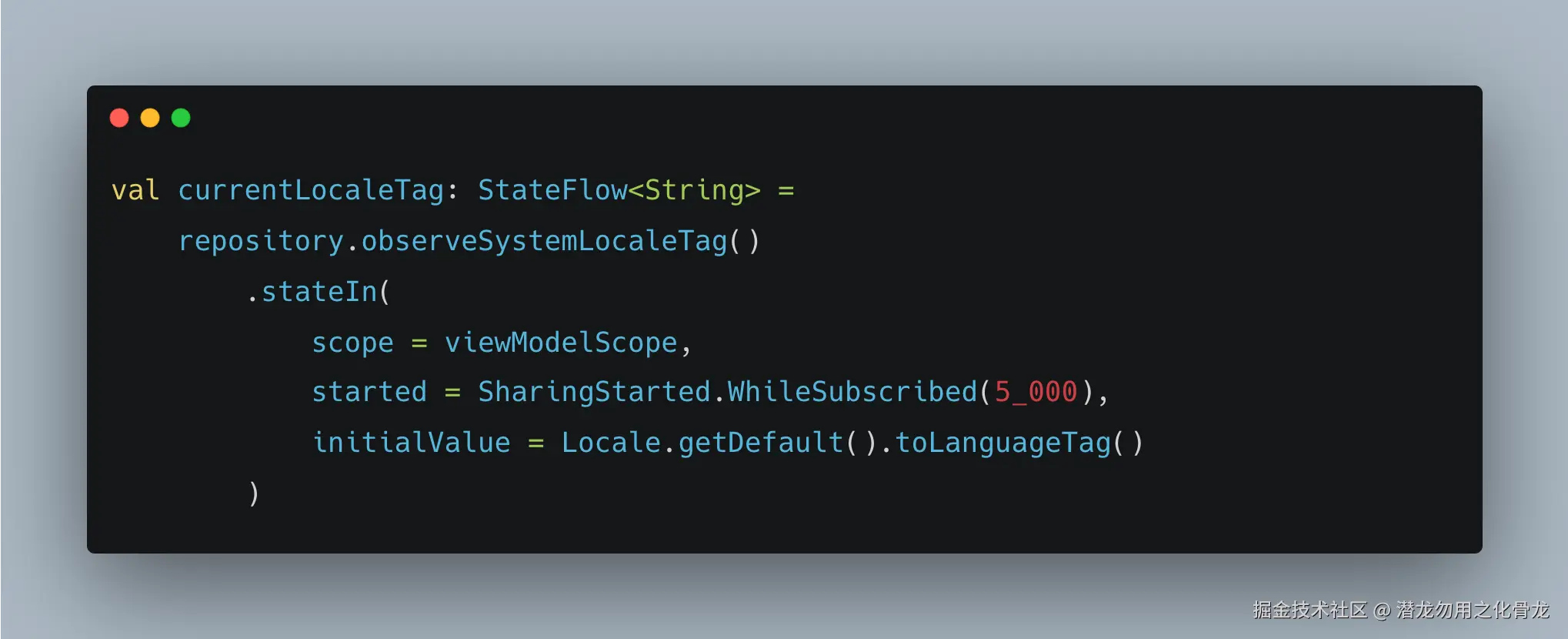
这样还有两个额外收益:
1)UI 重建后立即恢复最新状态
StateFlow 会缓存最后一个值。
因此:
- 页面重建无需等待广播
- UI 不会出现空白状态
2)减少频繁注册/反注册抖动
kotlin
WhileSubscribed(5_000)可以避免:
- 页面短暂切后台
- 配置切换
- Compose 重组
导致广播频繁注册/释放。
这是非常重要的工程优化点。
Code Review 检查清单(建议落地团队规范)
Data 层
- 是否仍对外暴露
start/stop - 是否泄漏内部生命周期控制细节
Flow 构建
- 是否使用
callbackFlow - 是否在
awaitClose中释放资源 - 是否使用
Application Context - 是否存在重复注册风险
迁移步骤
1)新增 Flow 接口
例如:
kotlin
observeSystemLocaleTag()2)删除 stop 依赖
逐步移除:
kotlin
start()
stop()3)上层改为按生命周期 collect
例如:
kotlin
repeatOnLifecycle(...)4)旧接口过渡废弃
先:
kotlin
@Deprecated稳定一版后再彻底删除。
结论
传统 start()/stop() 模型,本质上是:
"由调用方负责资源生命周期。"
而 callbackFlow + awaitClose 的本质则是:
"由订阅关系驱动资源生命周期。"
这两种设计最大的区别,不在于代码多少。
而在于:
- 生命周期是否结构化
- 资源是否能自动收敛
- 并发状态是否容易失控
- API 是否容易被误用
当 Data 层直接暴露 Flow<T> 后:
- 上层只需要收集数据
- 不再需要记忆何时
start() - 也不再需要担心遗漏
stop()
资源会随着订阅自动开启与释放。
这意味着:
- 更少泄漏
- 更少竞态
- 更少生命周期 Bug
- 更稳定的线上行为
- 更低的团队协作成本
很多人以为:
Flow 的价值只是"替代 callback"。
但在工程实践里,Flow 更大的意义其实是:
用声明式订阅关系,统一异步数据与资源生命周期。
过去:
- callback
- listener
- receiver
- observer
这些机制最大的痛点,并不仅仅只是"回调地狱"。
而是:
生命周期分散且容易失控。
而 Flow 把:
- 数据流动
- 生命周期
- 取消传播
- 资源释放
统一进了一套模型里。
这才是它真正强大的地方。