
◆ 博主名称: 小此方-CSDN博客 大家好,欢迎来到小此方的博客。
⭐️Linux系列个人专栏: 【主题曲】Linux
⭐️此方的GitHub: github_此方
⭐️ Re系列专栏:我们思考 (Rethink) · 我们重建 (Rebuild) · 我们记录 (Record)
文章目录
- 概要&序論
- [一、 进程切换与 CPU 寄存器原理](#一、 进程切换与 CPU 寄存器原理)
-
- [1.1 死循环进程如何运行?------深入理解时间片](#1.1 死循环进程如何运行?——深入理解时间片)
-
- [1.1.1 现代操作系统的公平调度](#1.1.1 现代操作系统的公平调度)
- [1.2 聊聊 CPU 寄存器与临时数据](#1.2 聊聊 CPU 寄存器与临时数据)
-
- [1.2.1 寄存器的诞生背景与核心作用](#1.2.1 寄存器的诞生背景与核心作用)
- [1.2.2 常见的核心寄存器分类](#1.2.2 常见的核心寄存器分类)
- [1.3 核心结论:区分"空间"与"内容"](#1.3 核心结论:区分“空间”与“内容”)
-
- [1.3.1 寄存器(盒子 / 空间)](#1.3.1 寄存器(盒子 / 空间))
- [1.3.2 寄存器里面的数据(内容 / 答案)](#1.3.2 寄存器里面的数据(内容 / 答案))
- [二、 进程上下文与切换机制](#二、 进程上下文与切换机制)
-
- [2.1 什么是进程上下文(Process Context)?](#2.1 什么是进程上下文(Process Context)?)
-
- [2.1.1 进程上下文的核心组成](#2.1.1 进程上下文的核心组成)
- [2.2 进程切换的"当兵留籍"故事](#2.2 进程切换的“当兵留籍”故事)
-
- [2.2.1 角色映射表](#2.2.1 角色映射表)
- [2.2.2 一次完整的切换流程](#2.2.2 一次完整的切换流程)
- [2.3 硬件上下文的具体保存与恢复实现](#2.3 硬件上下文的具体保存与恢复实现)
-
- [2.3.1 进程 A 与进程 B 的交替运行机制](#2.3.1 进程 A 与进程 B 的交替运行机制)
- [2.4 内核源码审视:上下文存在哪里?](#2.4 内核源码审视:上下文存在哪里?)
-
- [2.4.1 任务状态段(TSS, Task State Segment)与 task_struct](#2.4.1 任务状态段(TSS, Task State Segment)与 task_struct)
- [2.4.2 内核中的current指针](#2.4.2 内核中的current指针)
- [2.5 衍生思考:全新进程 vs 已调度过的进程](#2.5 衍生思考:全新进程 vs 已调度过的进程)
-
- [2.5.1 如何区分?](#2.5.1 如何区分?)
- [2.6 补充:分时操作系统与实时操作系统](#2.6 补充:分时操作系统与实时操作系统)
- 三、O(1)调度算法与调度队列
-
- [3.1 进程调度的核心诉求与优先级数组](#3.1 进程调度的核心诉求与优先级数组)
- [3.2 查找下一个进程:从 O(N) 遍历到位图优化](#3.2 查找下一个进程:从 O(N) 遍历到位图优化)
-
- [3.2.1 传统的顺序遍历困境](#3.2.1 传统的顺序遍历困境)
- [3.2.2 性能破局:引出位图技术](#3.2.2 性能破局:引出位图技术)
- [3.3 活跃队列与过期队列](#3.3 活跃队列与过期队列)
- 3.4周边问题
概要&序論
Hello大家好,我是此方。本文将硬核拆解 Linux 内核,深入剖析进程切换的上下文保护与硬件级恢复,并透彻解析经典 O(1) 调度算法的双阵列架构与位图加速机制,带你直击操作系统底层的运行本质。
一、 进程切换与 CPU 寄存器原理
1.1 死循环进程如何运行?------深入理解时间片
在多任务操作系统中,我们经常会遇到或写出"死循环"程序。一个不加限制的死循环进程,是否会死死卡住 CPU,导致整个系统瘫痪,让其他进程动弹不得呢?
答案是:绝对不会!
1.1.1 现代操作系统的公平调度
当我们的进程被加载到 CPU 并开始运行时,它并不能无限期地独占 CPU 资源。现代操作系统(如 Linux)普遍采用**时间片(Time Slice)**轮转的调度机制:
- 单次运行受限:一个进程在跑的时候,跑完一个指定的时间片,就必须得停下来。
- 重回队列排队:被剥夺 CPU 使用权的进程会被操作系统重新放入运行队列的末尾进行排队,等待下一次轮到它。
- 保护系统响应:依靠这种高频的轮转切换,即使某个进程内部是死循环,操作系统也能保证其他进程获得 CPU 资源,绝不会让其他进程卡死。
1.2 聊聊 CPU 寄存器与临时数据
当进程在 CPU 上运行时,它需要执行大量的算术、逻辑运算以及内存访问。这就引出了操作系统中极其核心的概念------寄存器。
1.2.1 寄存器的诞生背景与核心作用
我们的 PCB被加载进 CPU 后,CPU 的控制器需要根据进程的执行状态,去取得该进程所指向的代码和数据。
- 临时存储的刚需 :CPU 从内存中取出来的、或者在运算过程中产生的各种高频变化的数据,必须有一个极度高速的临时存储场所,于是寄存器诞生了。
- 寄存器的定义 :寄存器就是 CPU 内部的临时存储空间,专门用来存储正在运行的进程的临时数据(包括变量值、指令地址、状态标志等)。
1.2.2 常见的核心寄存器分类
不同的硬件架构(如 x86、ARM)以及不同的系统,其寄存器的个数和具体类型会有所不同,但通常都包含以下几类核心寄存器:
- 程序计数器(PC / EIP):存放 CPU 即将执行的下一条指令的内存地址。
- 栈指针寄存器(EBP / ESP):维护管理函数调用栈的边界与空间。
- 通用寄存器(如 EAX, EBX, ECX, EDX / RAX...):用于暂存各类运算过程中的操作数和临时结果。
- 段寄存器(CS, DS, ES, SS, FG, GS):在寻址时用于指示不同的内存段。
- 标志寄存器(EFLAGS):记录当前运算的状态信息(如是否溢出、是否为负数、进位等)。
- 控制寄存器(CR0 ~ CR4):决定 CPU 的工作模式以及控制虚拟内存分页等控制核心。
1.3 核心结论:区分"空间"与"内容"
为了彻底理解后续的"进程上下文切换",我们需要厘清一个极其关键的认知误区:
核心结论:寄存器 ≠ \neq = 寄存器里面的数据
1.3.1 寄存器(盒子 / 空间)
寄存器本身是固化在 CPU 内部的硬件电路。
- 物理空间的唯一性 :对于一个单核 CPU 而言,其内部的寄存器硬件只有 1 份。
- 概念类比:它就像是办公桌上的一个"固定的公用文件盒"。
1.3.2 寄存器里面的数据(内容 / 答案)
寄存器内部填充的数值,是随着当前运行的进程不断发生剧烈变化的。
-
数据的多份与流动 :虽然盒子(寄存器)只有一份,但每一个进程在运行到某一行代码时,它往盒子里塞进去的"账单数据"是变化的、多份的。
-
示例代码说明 :
cppint a = 10; // 此时寄存器中临时存入 10 a = 20; // 寄存器中的数据被刷新覆盖为 20 b = a; // 从寄存器中读取 20 赋给 b
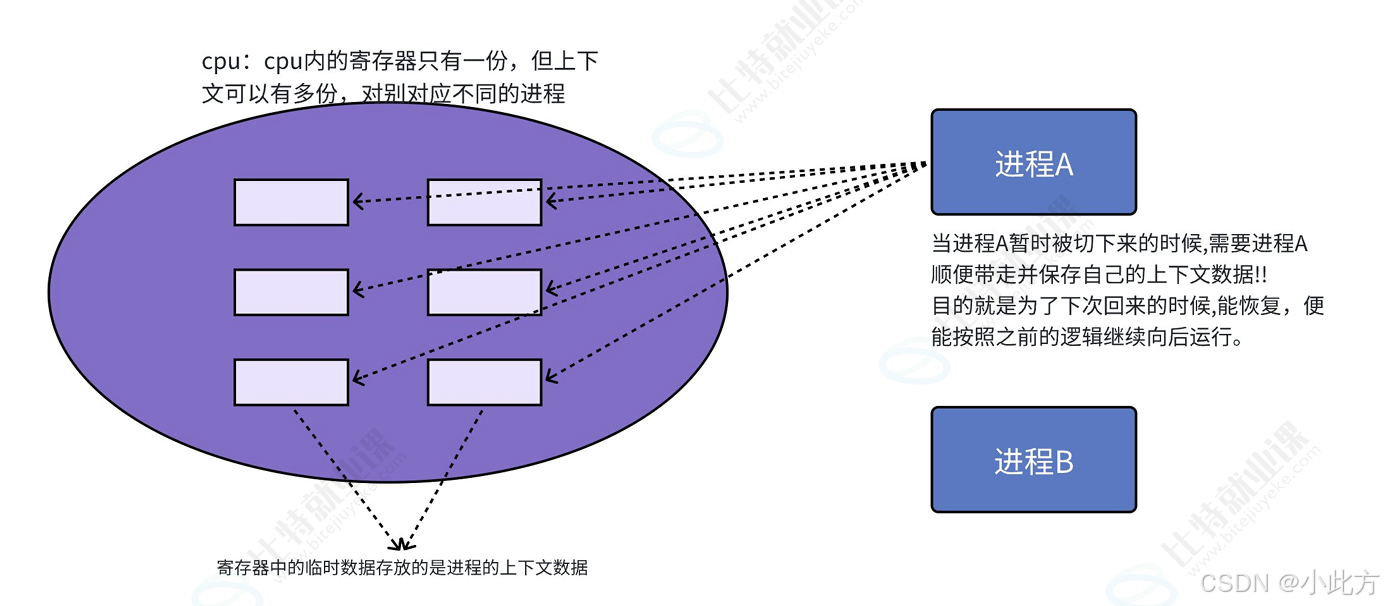
当进程 A 的时间片到了被切走,进程 B 进来运行时,B 就会覆盖这个"文件盒"里的内容。因此,在进程切换时,如何安全地保护和恢复这唯一的"文件盒"里的多份临时数据,就是我们下一部分要深入探讨的上下文切换(Context Switch)机制。
二、 进程上下文与切换机制
2.1 什么是进程上下文(Process Context)?
当一个进程在分时操作系统中运行、暂退、再恢复时,操作系统必须确保它能无缝衔接。这就需要引入进程上下文 的概念。从逻辑层面来看,它描述的是一个进程执行时所需的整个环境。
2.1.1 进程上下文的核心组成
一个完整的进程上下文主要由以下三个层次构成:
- 用户级上下文:包含进程的虚拟地址空间环境,如代码段、数据段、用户栈以及共享内存等。
- 寄存器级上下文(硬件上下文):即 CPU 内部各个寄存器(PC, EFLAGS, ESP, 通用寄存器等)在某一瞬间的特定数值。这部分直接决定了 CPU 当前的运行状态。
- 系统级上下文 :操作系统为了管理该进程而维护的各种内核数据,包括进程控制块(PCB/
task_struct)、页表、打开的文件描述符表、内核栈以及信号处理状态等。
作用:进程上下文的存在,保证了进程在被重新调度时,不仅 CPU 状态(寄存器)能完全恢复,连同内存映射、文件访问权限和内核资源等都能退回到中断发生前的那一瞬间。
2.2 进程切换的"当兵留籍"故事
为了生动地理解进程是如何切换的,我们可以听一个通俗易懂的故事。
2.2.1 角色映射表
- 学校 → \rightarrow → CPU(提供学习和运行的场所)
- 导员(辅导员) → \rightarrow → 调度器(决定谁来、谁走、什么时候走)
- 你 → \rightarrow → 进程(在学校里接受培养的主体)
- 学籍 / 成绩单 → \rightarrow → 硬件上下文数据(你在学校某一时刻的所有表现和状态记录,即寄存器里的内容)
2.2.2 一次完整的切换流程
假设你在大学读到大二,突然想响应国家号召去当兵:
- 去当兵(进程被剥夺 CPU):你必须暂时离开学校。
- 保留学籍(保存上下文) :离开前,导员把你大一和大二的所有期末成绩、学分等信息打包塞进档案袋,存入学校的教务系统。这就是把 CPU 寄存器里面的临时数据保存起来的过程。
- 退役复学(重新获得 CPU):两年后你当兵回来了,想要继续读大三。
- 恢复学籍(恢复上下文) :导员从档案袋里调出你当年的成绩单,重新同步到当前的教学系统中,你才能无缝衔接大三的课程,而不是从大一重头读起。这就是把保存的数据重新恢复到 CPU 寄存器里的过程。
核心结论 :一次硬件上下文的保存与恢复,就对应着一次进程的切换。
2.3 硬件上下文的具体保存与恢复实现
在具体的工程实现中,多进程(如进程 A 和进程 B)的轮转正是通过高频的"清音留存"来实现的。
2.3.1 进程 A 与进程 B 的交替运行机制
- 进程 A 运行满一个时间片 :
- 此时 CPU 寄存器(如
EIP = 100行,EAX = 10)存满了 A 的临时数据。 - 操作系统介入,将这些硬件上下文数据保存一份清单到 A 专属的存储区域,随后 A 带着它的数据回到运行队列中排队。
- 此时 CPU 寄存器(如
- 进程 B 开始执行 :
- B 进驻 CPU,覆盖硬件寄存器,并在其时间片内运行。B 运行满一个时间片后,同样把自己的硬件上下文保存一份清单,回队列排队。
- 进程 A 再次被调度 :
- 操作系统把 A 刚才记录在清单中的数据重新写入/恢复到 CPU 对应的寄存器当中。
- 此时,CPU 的
EIP重新变回100行,EAX重新变回10。A 就能完美地从历史位置和状态继续向下运行,由此周而复始。
2.4 内核源码审视:上下文存在哪里?
那么,当前运行进程的硬件上下文,在被切走时究竟脱水保存到了哪里呢?
2.4.1 任务状态段(TSS, Task State Segment)与 task_struct
在早期的 Linux 内核(例如初代 Linux 内核源码)设计中,硬件上下文是依赖特定的硬件数据结构 TSS(任务状态段) 来管理的:

c
// 早期 Linux 内核中关于任务状态段的结构定义
struct tss_struct {
long back_link;
long esp0, ss0;
long esp1, ss1;
long esp2, ss2;
long cr3;
long eip; // 报错 A 进程断点指令位置的寄存器数据
long eflags; // 保存标志位
long eax, ecx, edx, ebx; // 保存通用寄存器数据
long esp, ebp;
long esi, edi;
long es, cs, ss, ds;
// ...
};- 钥匙与保险箱 :在初代内核中,每个进程的
struct task_struct(PCB)内部包含了一个struct tss_struct,或者包含了一个可以获取该硬件上下文的"钥匙"(指针/段选择子),通过它去 TSS 中获取或写入对应的硬件上下文内容。 - 现代内核的演进 :在新版本的 Linux 内核中,为了追求更高的切换效率和架构平台的可移植性,这种强依赖硬件 TSS 的机制已经被剥离和优化,转而直接在内核栈(Kernel Stack)或
task_struct的特定字段(如thread_struct)中通过轻量级汇编指令进行手动保存。
2.4.2 内核中的current指针
在 Linux 内核源码(如 sched.h)中,有一个非常高频使用的全局/宏变量:
c
extern struct task_struct *current; // 当前进程结构指针变量 这个指针永远指向当前正占有 CPU 运行的那个进程的 PCB 。当调度器决定切换进程时,就是以 current 指针指向的进程作为源头,把当前寄存器里的值打包抽离出来的。

2.5 衍生思考:全新进程 vs 已调度过的进程
在整个切换生命周期中,调度器需要面对两种形态的进程:
- 已经调度过的进程:之前运行过,其中途断点和寄存器数据已经保存在 PCB 或内核栈中,再次调度时直接走"恢复上下文"流程。
- 全新进程 :刚被
fork出来,从来没有在 CPU 上运行过。
2.5.1 如何区分?
为了让调度器不至于接手一个全新进程时手忙脚乱,操作系统在设计 PCB 时通常会引入一个状态标记:
c
struct task_struct {
/* ... 各种硬编码的进程信息 ... */
long state; // -1 unrunnable, 0 runnable, >0 stopped
int is_running; // 状态标记位:是否属于已经运行过的进程
// ...
};- 首次调度的伪装 :对于全新进程,操作系统在
fork创建它时,会在内核栈里为它手动伪造一个初始的上下文环境 (例如把它的EIP指向进程的入口函数main,把相关寄存器清零或赋初值)。 - 统一调度逻辑:这样一来,全新进程在第一次被调度时,就能假装自己是一个"被切走过的老进程",同样通过统一的"恢复上下文"代码顺利跑起来!
2.6 补充:分时操作系统与实时操作系统
我们上述讨论的时间片轮转切换,主要适用于我们日常接触的分时操作系统(Time-sharing OS) ,如 Linux、Windows、macOS。它的核心目标是公平 与高并发吞吐 ,让每个用户、每个进程感觉自己都在独占计算机。
但在某些特定领域,如智能驾驶汽车 的刹车控制、航天飞机引导、工业自动化生产流水线 等,则必须使用实时操作系统(RTOS, Real-Time OS)。
- 实时性的本质 :实时操作系统不强调绝对的"时间片公平轮转",它强调的是任务响应的确定性与极限死线 。如果一个高优先级紧急任务(如自动驾驶发现障碍物需要紧急制动)到达,即使当前进程的时间片没到,系统也必须在微秒级内完成强行上下文切换,绝对不能允许排队等待。
大部分操作系统都支持实时操作系统,但是这一部分在非应用领域基本用不到,所以一般在编译的时候会被注释掉。
三、O(1)调度算法与调度队列
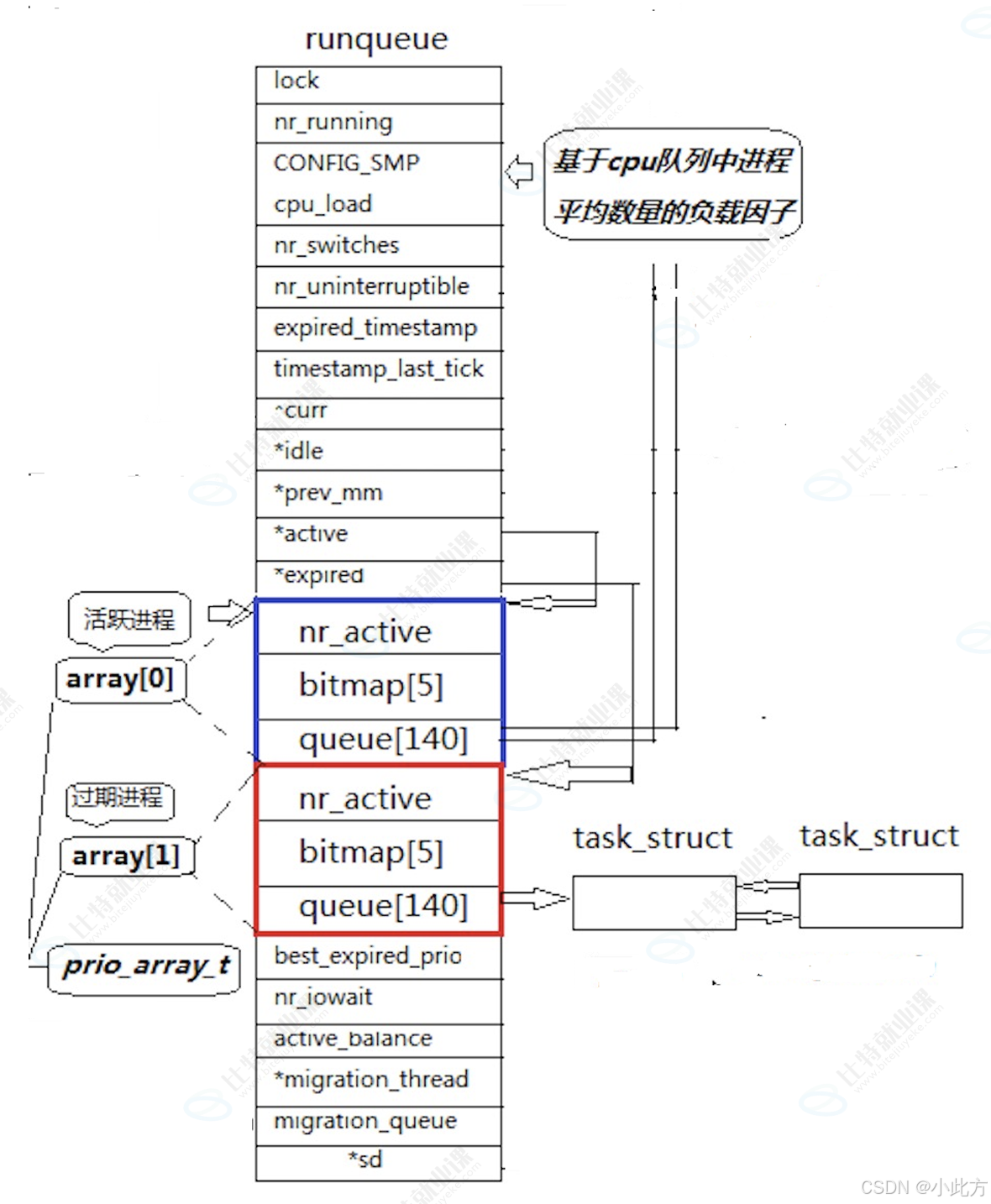
如上,是整一个调度队列的简化示意图,我们接下来慢慢来了解它。
3.1 进程调度的核心诉求与优先级数组
当系统中存在大量处于就绪状态的进程时,调度器面临的核心问题是:下一次该把 CPU 分配给谁?
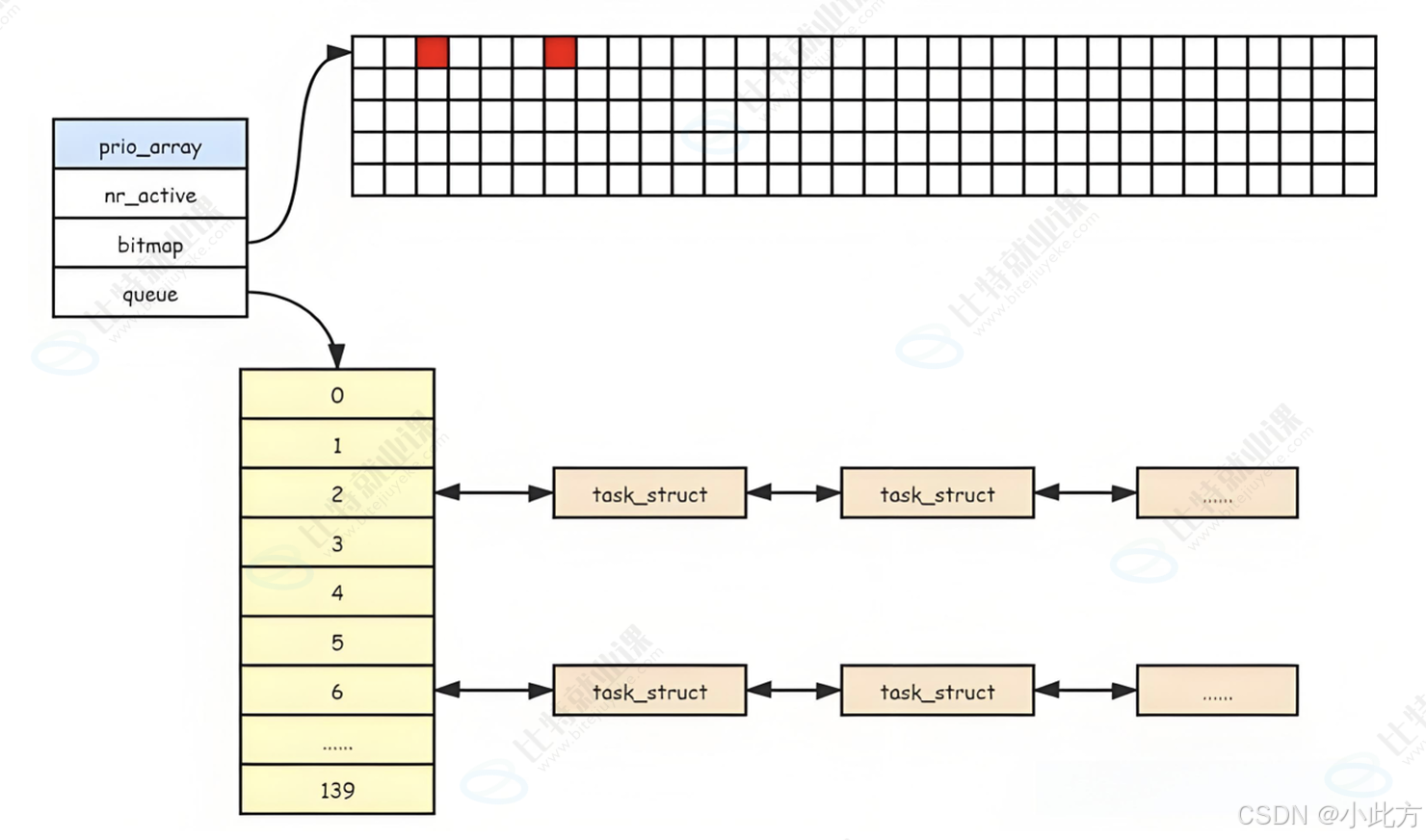
为了满足不同进程对响应速度的差异化需求,Linux 引入了优先级的概念。在底层的实现中,内核并没有采用单一的无序链表,而是设计了优先级数组 。例如,内核会维护一个指针数组(如 task_struct *queue140),数组的下标直接对应着进程的优先级(0-139)。每一个数组元素都是一个链表的头指针,挂载着所有该优先级下的就绪进程。
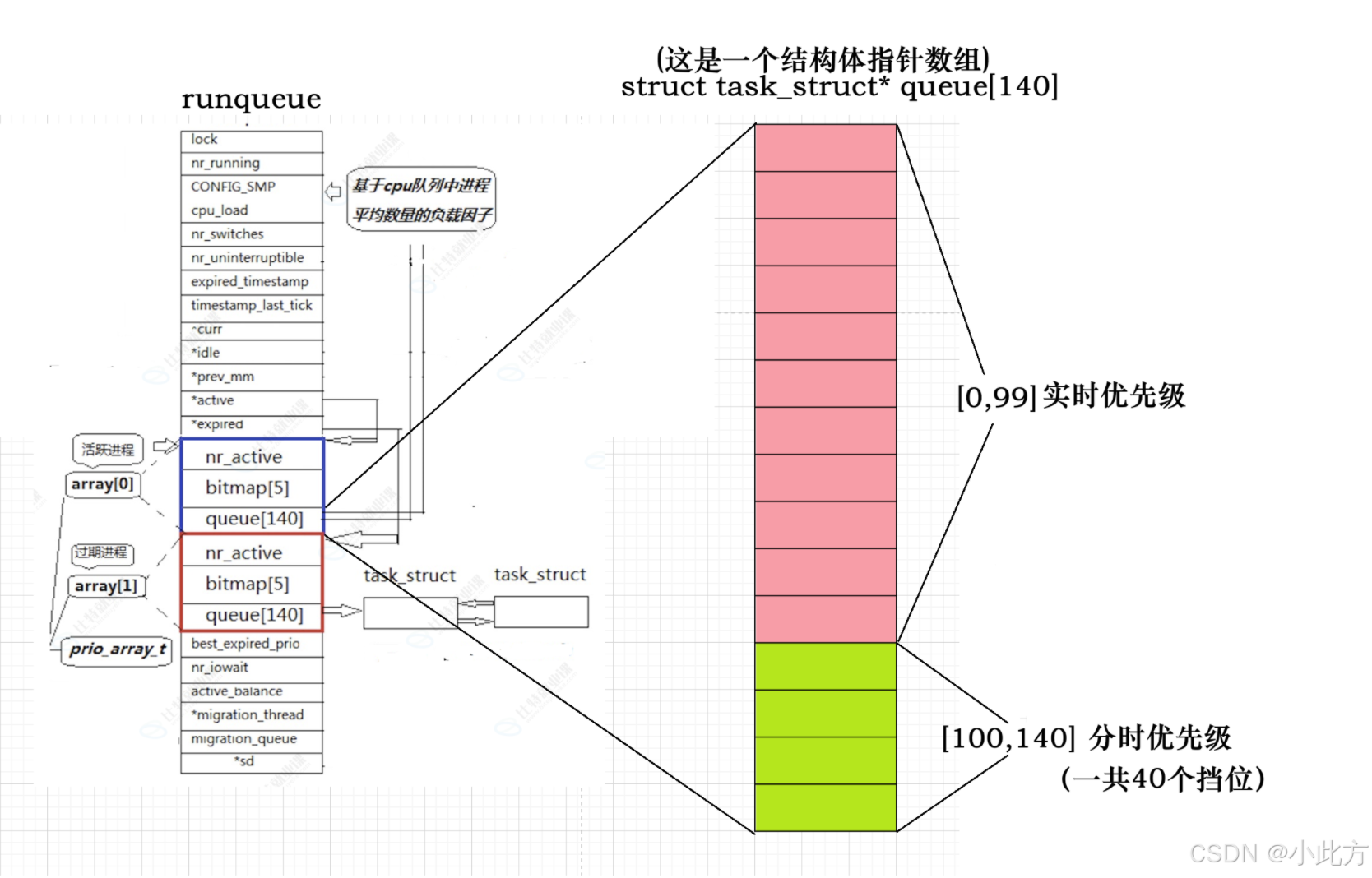
3.1.1优先级映射方法
- 实时进程 :
- 优先级范围:0 ~ 99(数值越小,优先级越高)。
- 映射规则 :这部分进程的优先级直接原样映射到多级就绪队列的 0 ~ 99 下标位置。
- 普通进程 :
- 优先级范围:100 ~ 139(由经典的 nice 值动态计算而来)。
- nice 值与优先级转换 :普通进程的 nice 值范围是 -20 到 19 。内核通过以下公式将其转换为 100 ~ 139 的纯数字优先级:
P r i o r i t y = N i c e + 120 Priority = Nice + 120 Priority=Nice+120 - 映射规则 :计算出来的优先级别数值,同样直接对应 多级就绪队列中 100 ~ 139 的数组下标。
3.2 查找下一个进程:从 O(N) 遍历到位图优化
有了优先级队列,当我们想要挑选下一个最高优先级的进程来运行时,就需要去查找这个队列数组中,哪一个是第一个非空的队列。这就是经典 Linux 调度算法(如 O(1) 调度器)必须攻克的核心性能关。
3.2.1 传统的顺序遍历困境
假设我们有一个简化的优先级队列数组 int queue100; 以及一个用于指向当前查找位置的变量 int index; 。
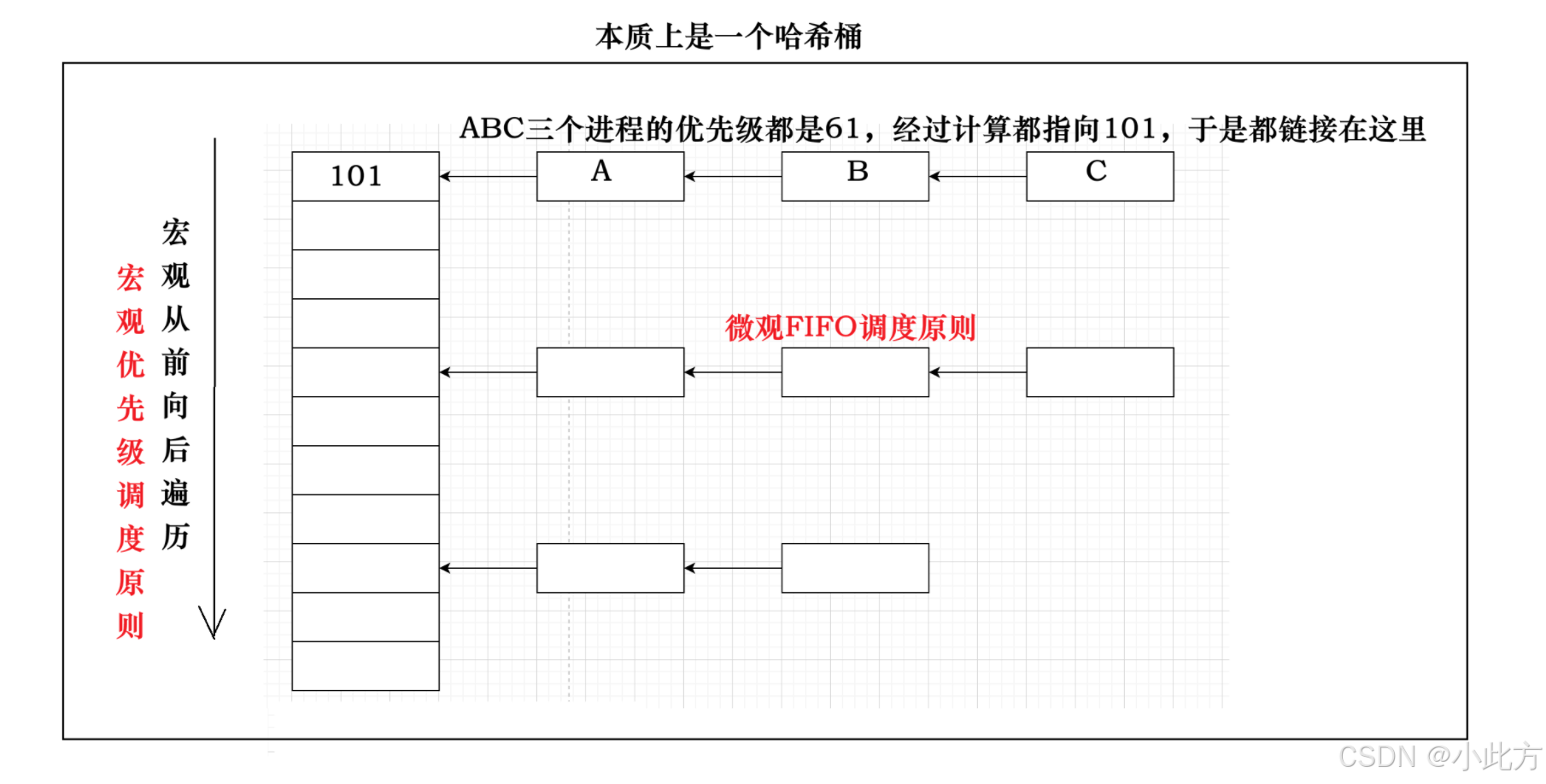
如果按照最朴素的思维:
- 我们怎么找? 最直接的办法就是写一个 for 循环,按顺序去遍历这个数组。
- 致命的性能瓶颈 :如果我们的队列长度不是 100,而是 1000?10000? 这种时间复杂度为 O(N) 的线性查找在操作系统底层是绝对无法容忍的。因为进程调度极其频繁,如果每次挑选进程都要经历漫长的遍历,系统性能将受到严重拖累。
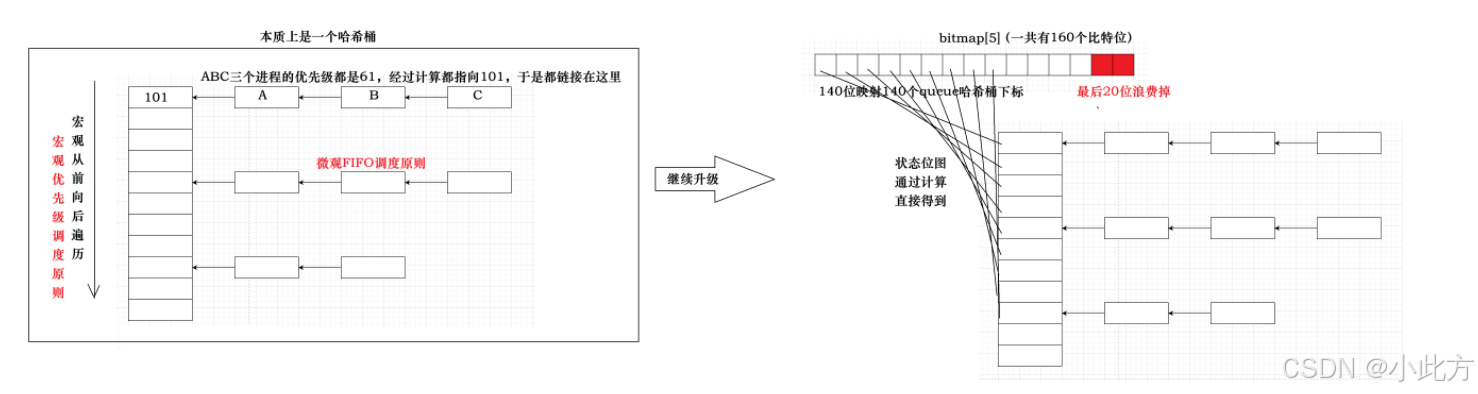
3.2.2 性能破局:引出位图技术
为了打破 O(N) 的魔咒,实现 O(1) 的超高效率,Linux 内核**引出了位图(Bitmap)**结构来辅助查找。
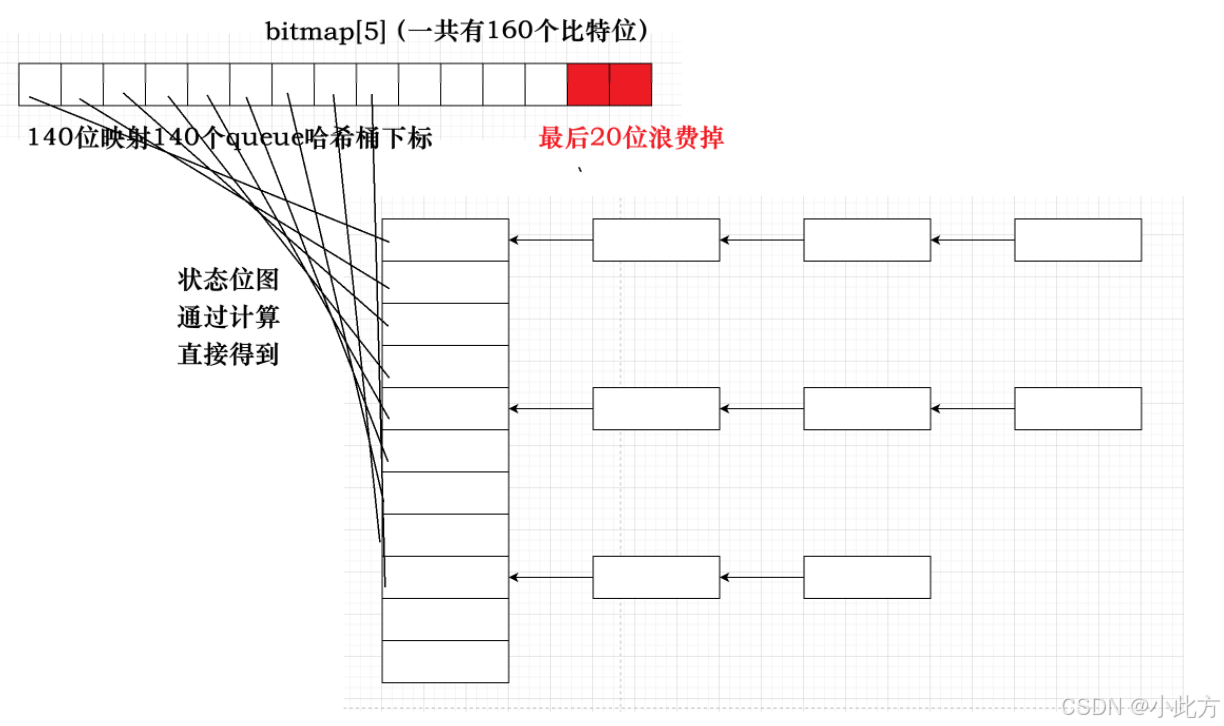
- 位图的映射原理 :系统使用一段连续的比特位(bit)来映射对应的队列是否为空。例如,使用一个长整型数组 long bitmap5; (在 32 位系统中,5 * 32 = 160 个 bit,足以覆盖 140 个优先级队列)。
- 0 与 1 的状态 :如果第 0 个队列有进程排队,那么位图的第 0 个 bit 就被置为 1 ;如果队列为空,对应 bit 就是 0。
- 硬件级指令查找 :如果想找 1 对应的队列呢? 现代 CPU 都提供了专门的硬件指令(如 x86 的 bsf / bsr 指令),可以在一个 CPU 时钟周期内,直接计算出一个整数中最低位或最高位的 1 在哪里。借助这种硬件指令,操作系统瞬间就能知道哪个优先级队列里有进程,实现了真正的 O(1) 查找时间复杂度!
3.3 活跃队列与过期队列
活跃队列和过期队列都放在一个数组里面。
即使解决了查找效率问题,传统的单队列模型还会遇到一个问题:高优先级的进程如果不断产生,低优先级的进程就会遭遇饥饿 ,永远分不到时间片。为了解决这个问题,经典 O(1) 调度算法在运行队列(runqueue )中引入了两个核心的队列集合:
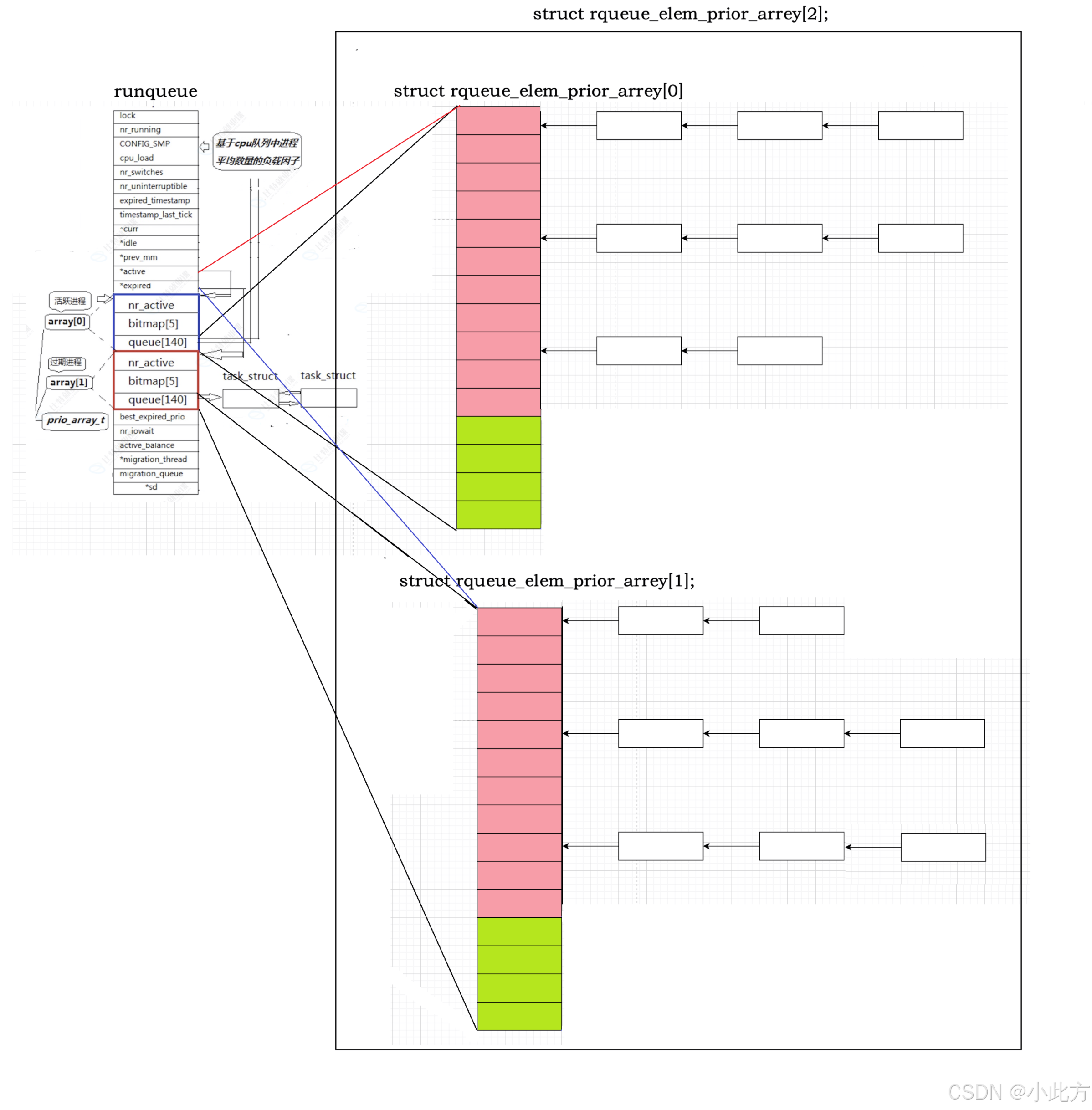
3.3.1 活跃队列(Active Array)
这里面存放的是当前时间片还没有用完的进程。
- 调度器每次都从活跃队列的最高优先级链表中取出一个进程投入运行。
- 当这个进程在 CPU 上跑完它的时间片后,它就失去了继续待在活跃队列的资格。
3.3.2 过期队列(Expired Array)
当活跃队列中的某个进程耗尽了时间片,调度器会为它重新计算下一次的优先级和时间片,然后将其直接放入过期队列中。
3.3.3指针交换
随着时间推移,活跃队列里的进程越来越少,最终会被清空。(使用一个nr_active来记录进程数量,为0时交换指针)此时,过期队列里则装满了重新洗牌后等待运行的进程。
当活跃队列为空的瞬间,调度器不需要做任何复杂的数据搬移操作,只需要互换一下活跃队列和过期队列的两个指针:
- 曾经的过期队列瞬间变成了新的活跃队列。
- 曾经空掉的活跃队列变成了新的过期队列。
3.3.4完整梳理
上一个进程的时间片结束,系统会先通过nr_active查看当前进程数量,数量>0.则调用bitmap查找下一个进程的所在位置。
调取queue找到进程位置,然后将头部的结点取出。将它的PCB链接到current指针指向。
current指针将其指向的进程加载到CPU中,使用调度算法。CPU开始运行
3.4周边问题
3.4.1新进程来了怎么办
古人的做法 :将新进程链接到过期队列里面,这个时候就是操作系统宏观的就绪状态。但是Linux没有分的这么明确,活跃队列和过期队列都是运行队列。
但是现代的一些做法:进程支持抢占,就是说,把新的进程按照优先级插入到活跃队列中抢占了活跃队列中后面进程的时间。除此之外对于新进程还有很多的设计方案可以了解。
3.4.2调度队列其他元素了解
cpu_load CPU负载因子: 主要服务于多CPU并发的情况,一个新进程来的时候首先要通过cpu_load查看多个CPU的负载状态,找到负载低的那CPU插入。
nr_switches 切换次数:衡量一个CPU有多忙的一个指标
3.4.3优先级与调度算法的关系
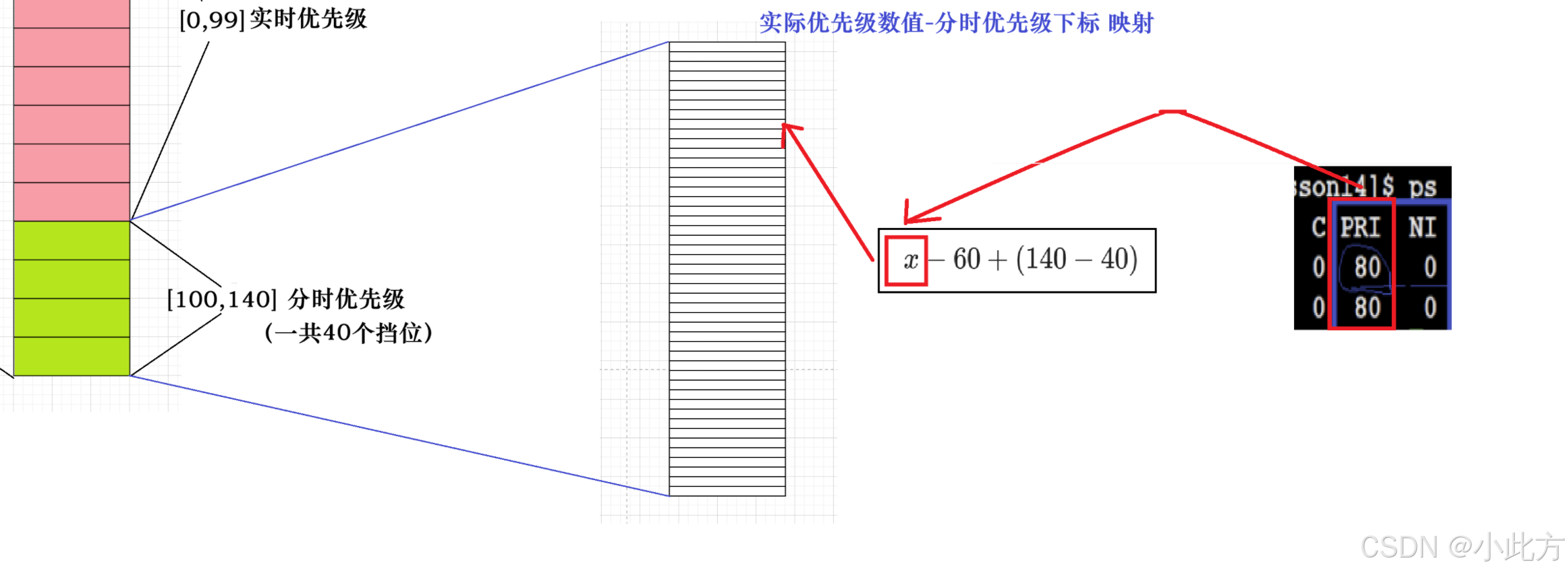
回来看我们之前留下的问题 :为什么修改优先级不直接在PRI上修改,而要加上一个NI值?
(我们下面的A队列默认是指活跃队列,D队列默认是过期队列 )
如果直接修改PRI会遇到两个问题:把这个进程的优先级修改了(如果在A队列中),就要在这个队列中重新链入到指定位置。那么到底是A队列的指定位置还是D队列的指定位置?
我们不知道,但是不论是A还是D都不好。那么不链入呢?又又点奇怪:我的优先级是60,但是我在80的位置。
于是加入了NI值,我们修改优先级就是修改NI的值,这个进程的NI值被修改了,于是这一轮我把这个进程运行完之后,在链入D队列中的时候,把这个进程按照这个NI值重新定位到新的位置,接下运行进程的时候就以新的优先级运行。
好的本期内容就到这里,如果对你有帮助,还不要忘记点赞三联支持。我是此方,我们下期再见。bye!