问题
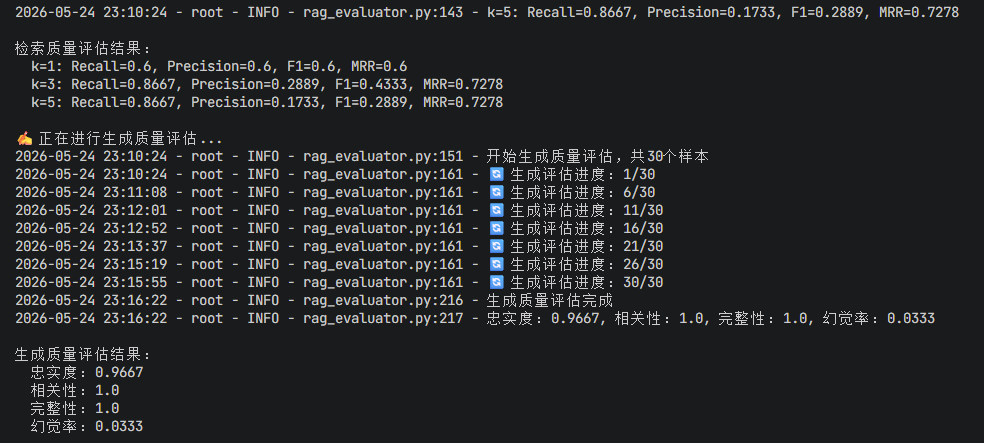
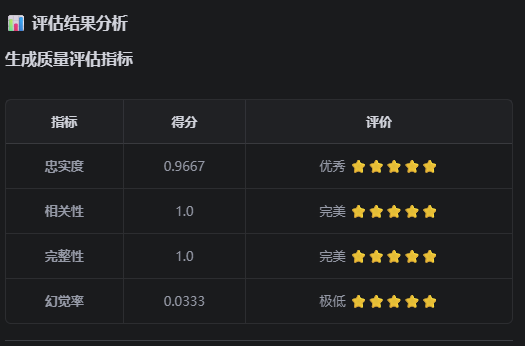
检索质量评估结果为0
说明检索没有找到相关文档!问题可能是:
-
评估数据集生成时的chunk_id与实际向量数据库不匹配
-
文档内容与问题不相关
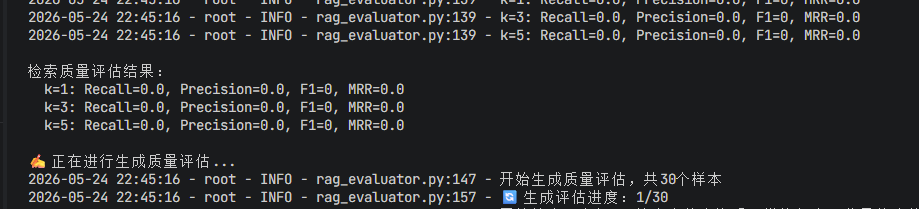
原因
向量数据库中的ID有两种:
-
Chroma内部UUID : 8e5d606e-896c-4117-83a6-31d3ca4638d9 (自动生成)
-
Metadata中的chunk_id : rag_guide_md_0 (文档处理器生成)
评估数据集记录的是:
- d6dc2ed0-448d-4b4b-8de2-73e81a3dc2fe (Chroma的UUID)
检索器返回的文档中:
- chunk_id 字段是 rag_guide_md_0 (自定义格式)
评估器比较的是:
- 把检索结果的 chunk_id (如 rag_guide_md_0 )与评估数据集的 relevant_chunk_ids (如 d6dc2ed0-448d-4b4b-8de2-73e81a3dc2fe )进行比较。
这两种ID完全不同!所以无法匹配,导致Recall全为0。
评估数据集生成时:
python
all_ids = self.retriever.vector_store.get()["ids"] # 获取的是 Chroma 内部UUID
...
"relevant_chunk_ids": [chunk_id] # 保存的是UUID,如 `d6dc2ed0-448d-4b4b-8de2-73e81a3dc2fe`评估时比较的是:
python
retrieved_ids = set([doc.metadata["chunk_id"] for doc in retrieved_docs]) # 取的是metadata中的chunk_id,如 `rag_guide_md_0`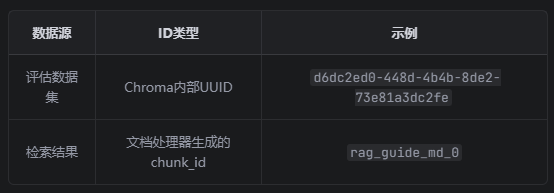
修复
修改 core/rag_evaluator.py :
python
# 修复前:使用Chroma内部UUID
all_ids = self.retriever.vector_store.get()["ids"]
# 修复后:使用metadata中的chunk_id
chunk_id = metadata.get("chunk_id", metadata.get("id", str(hash(chunk_content))))