Java 后端开发者如何理解大模型应用架构
过去一两年,很多 Java 后端开发者都开始接触大模型应用。
一开始我们很容易觉得,大模型应用好像就是"调一个 API":用户发来一句话,后端把这句话转发给 OpenAI、通义千问、DeepSeek、智谱或者其他模型服务,再把模型返回的内容展示给用户。
这个理解不能说错,但它只看到了最表层的一步。
真正把大模型能力接入后端系统时,你会发现难点并不只是"怎么调用模型",而是:
- 怎么组织 Prompt
- 怎么管理上下文
- 怎么控制输出格式
- 怎么接入业务数据
- 怎么降低幻觉
- 怎么记录日志和成本
- 怎么让模型调用系统里的工具
- 怎么把它从一个聊天接口演进成可落地的 AI 应用
这也是本系列文章想解决的问题:不从模型训练、Attention 公式、GPU 推理优化这些底层细节讲起,而是站在 Java 后端开发者的视角,从大模型 API 调用开始,一步步走向 RAG 知识库、Tool Calling 和 Agent 工程实践。
1. 大模型应用不是简单的聊天接口
对 Java 后端开发者来说,传统业务系统的核心逻辑通常比较确定。
比如一个订单查询接口:
text
用户请求
→ Controller 接收参数
→ Service 校验业务规则
→ Repository 查询数据库
→ 组装 DTO
→ 返回 JSON这个过程的特点是:输入、处理逻辑、输出格式都相对可控。
但是大模型应用不一样。
一个最简单的大模型问答接口,看起来可能是这样:
text
用户输入问题
→ 后端构造 Prompt
→ 调用大模型 API
→ 模型生成回答
→ 后端处理结果
→ 返回给用户这里多了一个非常特殊的组件:大模型。
它不是普通的规则引擎,也不是传统意义上的数据库查询接口。它更像是一个"基于上下文进行概率生成的能力组件"。你给它什么上下文,它就基于这些上下文生成一个看起来合理的答案。
这带来了很强的能力,也带来了新的不确定性。
它可以理解自然语言,可以总结文档,可以生成代码,可以分析问题,也可以根据工具返回的结果继续推理。但同时,它也可能误解意图、编造事实、返回不稳定格式,甚至在业务场景里给出不应该给出的建议。
所以,大模型应用开发的重点,不是"把用户输入转发给模型"。
真正的重点是:后端系统如何把模型变成一个可控、可观测、可集成的能力模块。
2. Java 后端在大模型应用里负责什么
有些人会误以为,做 AI 应用就意味着后端的重要性下降了。
实际正好相反。
大模型越强,后端系统越需要承担"边界、控制和工程化"的角色。
在一个真实的大模型应用里,Java 后端至少要负责这些事情:
text
1. 接收用户请求
2. 校验用户身份和权限
3. 获取业务数据或知识库内容
4. 构造 Prompt 和上下文
5. 调用大模型或 Embedding 模型
6. 处理模型返回结果
7. 控制输出格式
8. 记录日志、Token 用量、延迟和错误
9. 对接数据库、缓存、消息队列和业务系统
10. 在必要时限制模型能做什么、不能做什么换句话说,大模型不是来替代后端的,而是成为后端系统中的一个新型能力。
以前后端主要调用数据库、缓存、搜索引擎、第三方 HTTP API。
现在后端还会调用大模型 API、Embedding API、向量数据库、Rerank 模型,以及各种工具执行接口。
从系统架构角度看,大模型应用依然是一个后端工程问题。
只不过它引入了一种新的"不确定性组件",这要求我们重新思考接口设计、数据流、异常处理、测试方式和系统边界。
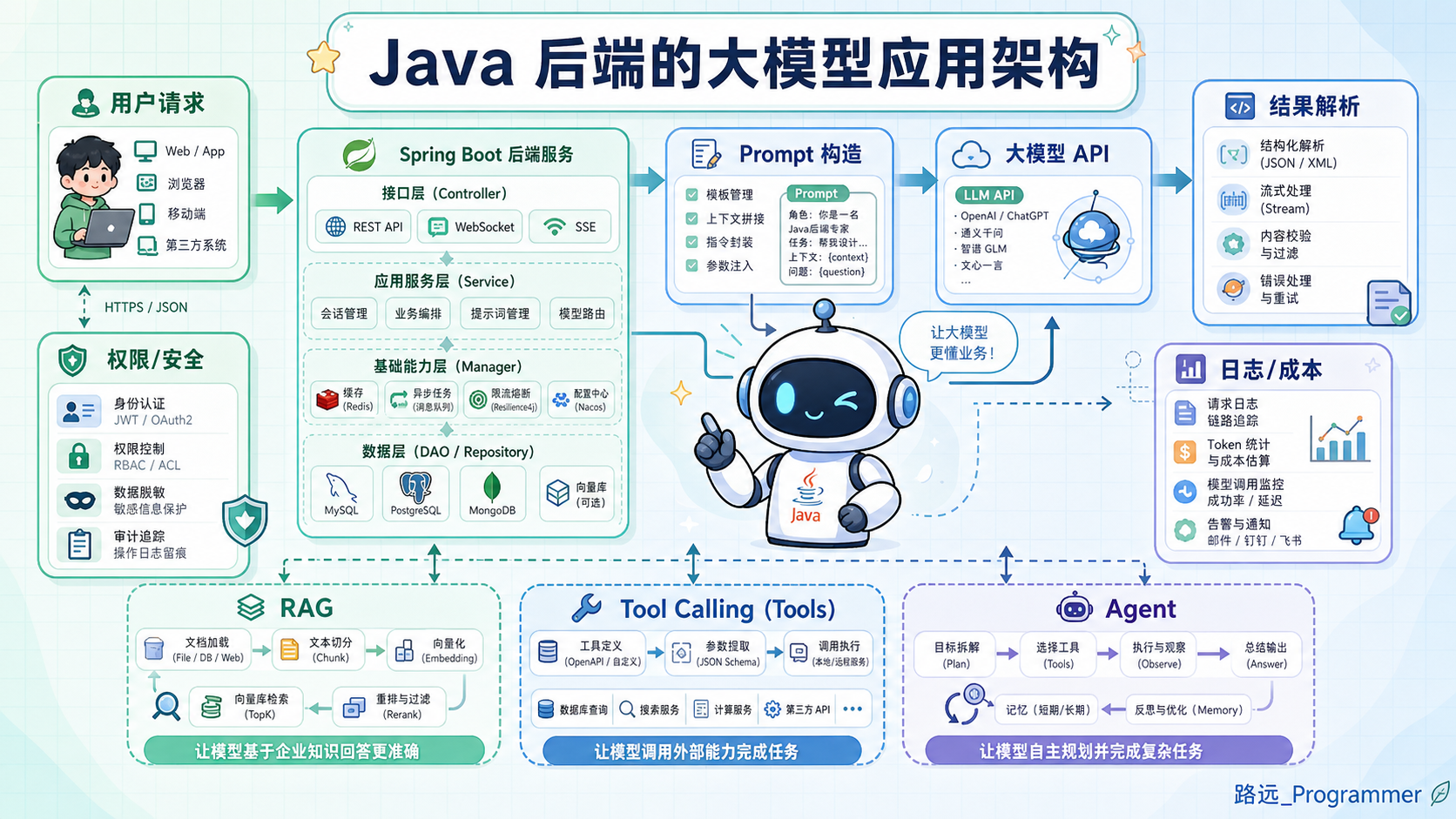
3. 一个最小 AI 应用的架构
先看一个最小可用的大模型应用架构:
text
前端页面
↓
Java 后端接口
↓
Prompt 构造层
↓
大模型 API
↓
结果解析层
↓
返回用户如果用 Spring Boot 来实现,大概会拆成这些模块:
text
ChatController
接收 HTTP 请求
↓
ChatService
处理对话业务逻辑
↓
PromptBuilder
构造模型输入
↓
ModelClient
调用大模型接口,或者使用 Spring AI 的 ChatClient
↓
ResponseParser
处理模型输出
↓
ChatLogRepository
记录调用日志、用户输入、模型输出、Token 用量等很多入门 Demo 会直接在 Controller 里调用模型,但真实项目里不建议这么做。
原因很简单:一旦你开始加入 Prompt 模板、上下文管理、异常处理、结构化输出、审计日志和限流,这个接口会很快变复杂。
从第一天开始,就应该把"大模型调用"当成后端服务的一部分来设计,而不是当成一次临时 HTTP 请求。
4. Prompt 是后端组装出来的输入
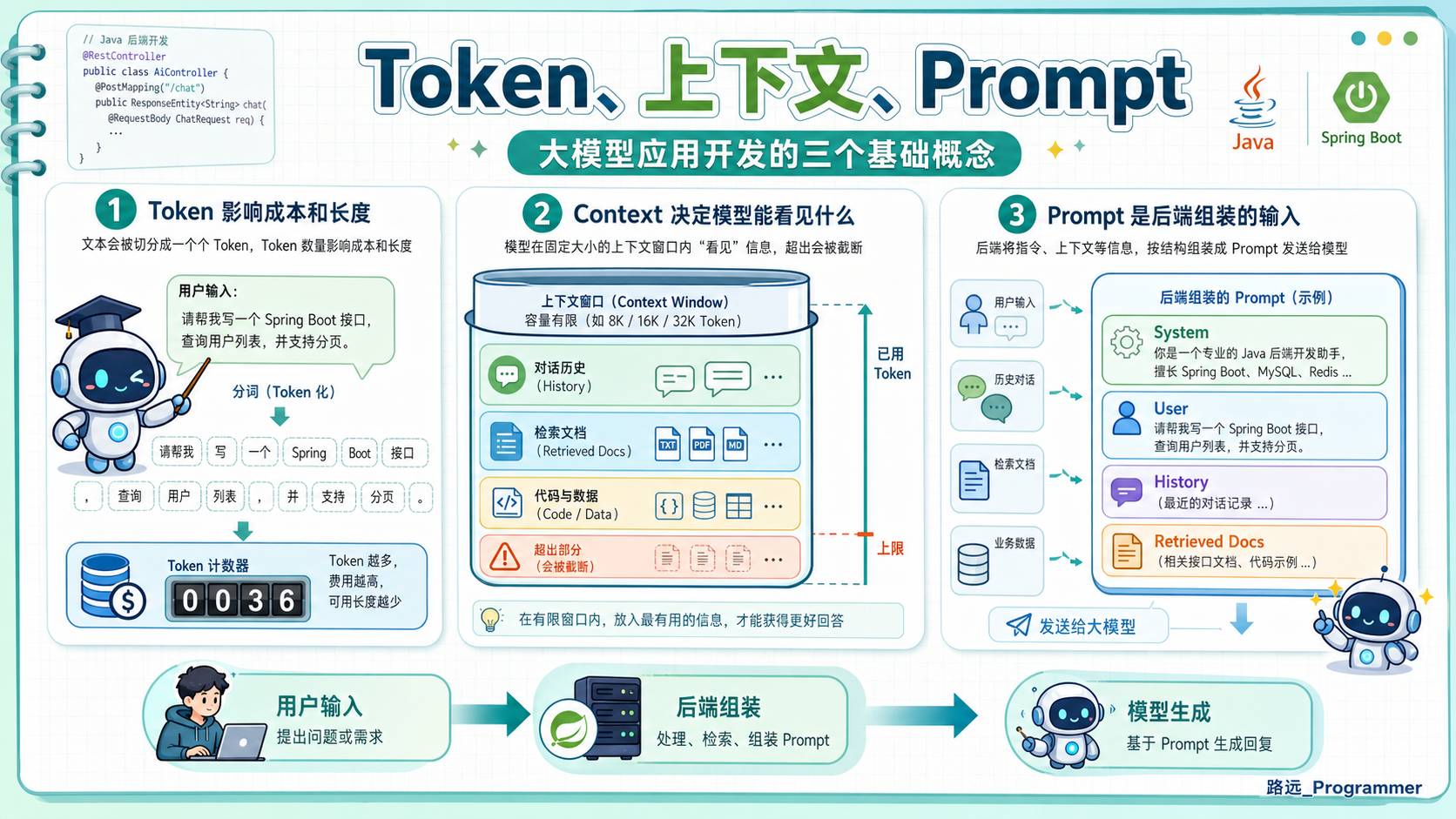
很多人一开始会把 Prompt 理解成"用户输入的一句话"。
但在后端应用里,Prompt 往往不是用户原始输入,而是后端系统组装出来的一段完整上下文。
比如用户问:
text
RAG 是什么?后端真正发给模型的内容可能是:
text
你是一个面向 Java 后端开发者的 AI 技术助手。
请用通俗但准确的方式回答问题。
回答时优先结合工程实践,不要只讲抽象概念。
用户问题:
RAG 是什么?以后引入 RAG 后,这个 Prompt 里还会包含检索到的知识片段:
text
请基于下面的资料回答用户问题。
如果资料中没有答案,请明确说明不知道。
资料:
1. ...
2. ...
3. ...
用户问题:
...这说明一个关键点:Prompt 设计本质上是后端上下文工程。
它不只是"写一句提示词",而是要决定:
- 模型应该扮演什么角色
- 哪些业务数据可以放进上下文
- 哪些内容不能放进去
- 输出应该遵循什么格式
- 当资料不足时模型应该如何处理
这些问题都和后端系统设计密切相关。
5. 为什么不能只依赖模型自己的知识
大模型训练时已经学到了大量知识,但这并不意味着它天然知道你的业务系统。
它不知道你公司的内部文档,不知道你的订单状态,不知道用户刚刚上传的文件,也不知道数据库里最新的数据。
如果你直接问模型:
text
我们公司最新的报销流程是什么?模型很可能会编一个看起来合理的答案。
这就是大模型应用里最常见的问题之一:幻觉。
幻觉不一定是模型"故意乱说",而是因为它在缺少可靠上下文时,仍然会尝试生成一个自然语言答案。
要解决这个问题,就不能只依赖模型自身的参数知识,而要把外部知识接入进来。
这就是后面要重点讲的 RAG。
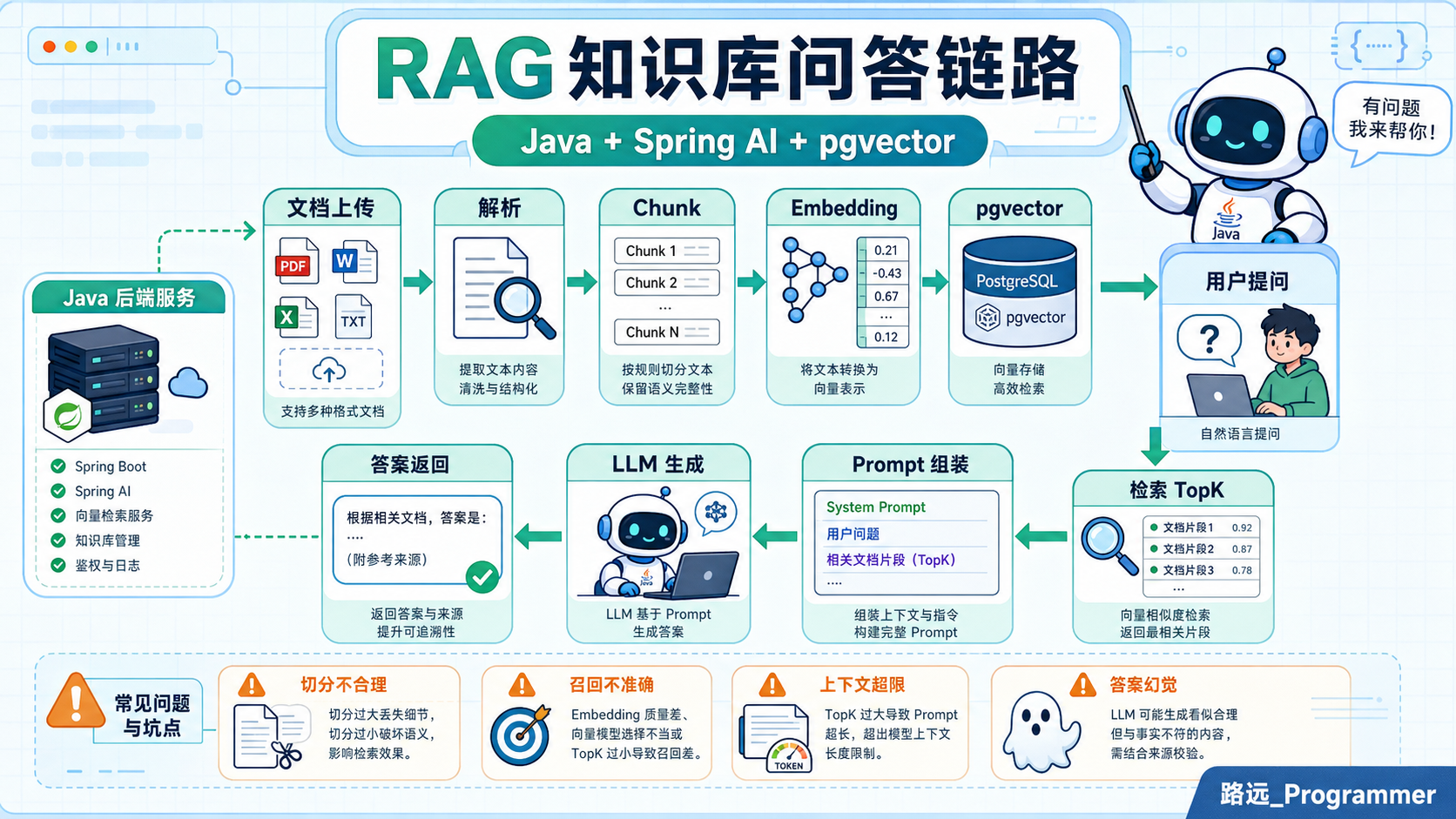
RAG 的核心思想可以简单理解为:
text
先从知识库里检索相关资料
再把资料和用户问题一起交给大模型
让模型基于资料生成回答对于 Java 后端开发者来说,RAG 不只是一个 AI 概念,它其实是一条完整的数据链路:
text
文档上传
→ 文档解析
→ 文本切分
→ Embedding 向量化
→ 向量入库
→ 用户提问
→ 向量检索
→ Prompt 组装
→ 大模型生成
→ 返回答案这条链路里的大部分工作,都是典型的后端工程问题。
6. 从 RAG 到 Agent
当我们解决了"让模型基于知识库回答问题"之后,下一步自然会遇到另一个问题:
如果用户不只是想问问题,而是想让 AI 帮他完成任务呢?
比如:
text
帮我查一下这个用户最近 3 笔订单,并总结有没有异常。这个时候,模型光靠生成文本是不够的。
它需要能够调用后端系统里的工具:
text
查询用户信息
查询订单列表
查询支付状态
生成总结这就是 Tool Calling 和 Agent 要解决的问题。
Tool Calling 可以理解为:后端把一组可调用的工具描述给模型,模型根据用户意图选择是否调用工具,以及调用哪个工具。
Agent 则是在此基础上进一步扩展:它不仅能调用一次工具,还可以围绕一个目标进行多步推理、多次调用工具,并根据中间结果继续决策。
不过,Agent 听起来很酷,落地时却非常考验工程能力。
因为你需要控制:
- 模型能调用哪些工具
- 工具参数是否安全
- 调用次数是否有限制
- 失败后如何重试
- 结果是否需要人工确认
- 整个过程如何记录和追踪
所以本系列不会一上来就讲复杂 Agent,而是先从最基础的大模型调用开始,再进入 RAG,最后再讨论 Agent。
这条路线更适合 Java 后端开发者循序渐进地掌握 AI 应用工程。
7. 本系列会怎么推进
接下来这个系列会围绕一个逐步演进的项目展开:AI 知识库助手。
最开始,它只是一个普通的 AI 问答接口。
然后我们会给它加上文档上传、文档解析、向量检索和 RAG 问答能力。
再往后,我们会让它支持 Tool Calling,能够调用后端接口查询业务数据。
最后,我们会把它演进成一个简单 Agent:既能查知识库,也能调用工具完成任务。
技术栈会以 Java 后端为主:
text
Java 21
Spring Boot 3.x
Spring AI
PostgreSQL + pgvector
Docker Compose这个选择不是为了追新,而是因为它贴近很多 Java 后端开发者真实的技术环境。
我们不需要为了做 AI 应用就立刻切到 Python 技术栈。Python 生态当然很强,但对于 Java 后端开发者来说,更重要的是把 AI 能力接进自己熟悉的工程体系里。
8. 小结
对 Java 后端开发者来说,理解大模型应用架构的第一步,不是研究模型怎么训练出来的,而是搞清楚大模型在系统里到底扮演什么角色。
它不是数据库,不是搜索引擎,也不是传统规则引擎。
它更像是一个可以理解上下文、生成自然语言、辅助决策和调用工具的智能能力组件。
而后端系统要做的,是把这个组件放进一个可控的工程结构里:
text
用 Prompt 管理输入
用 RAG 接入知识
用结构化输出约束结果
用 Tool Calling 连接业务系统
用日志、评测和权限保证可落地从下一篇开始,我们会先补齐三个最基础但非常重要的概念:
text
Token
上下文窗口
Prompt理解它们之后,再看 RAG 和 Agent,就不会觉得这些概念是凭空冒出来的了。