目录
[1. ZSet 解决了什么问题](#1. ZSet 解决了什么问题)
[2. ZSet 底层数据结构](#2. ZSet 底层数据结构)
[2.1. listpack紧凑列表](#2.1. listpack紧凑列表)
[2.2. dict+skiplist哈希表和跳表](#2.2. dict+skiplist哈希表和跳表)
[3. 典型应用场景](#3. 典型应用场景)
[3.1 游戏/积分排行榜](#3.1 游戏/积分排行榜)
[3.2 优先级队列](#3.2 优先级队列)
[3.3 在线用户活跃时间](#3.3 在线用户活跃时间)
[4. Go-Redis 相关 ZSet 示例代码](#4. Go-Redis 相关 ZSet 示例代码)
[5. 总结](#5. 总结)
1. ZSet 解决了什么问题
ZSet,全称 Sorted Set,也就是有序集合。它可以理解为 Redis 在 Set 的基础上增加了一个排序分值。
普通 Set 只能保证元素唯一,不能按业务权重排序;List 可以保持顺序,但不擅长按分数动态调整位置;Hash 能快速按 key 查询,但不支持排名和范围查询。ZSet 正好解决了这些问题。
ZSet 的核心模型如下:
XML
key -> [(member, score), (member, score), ...]-
member: 集合成员,必须唯一,例如用户 ID、任务 ID、连接 ID。
-
score: 排序分值,Redis 根据 score 从小到大维护顺序,例如积分、时间戳、优先级。
ZSet 主要解决四类问题:
第一,解决唯一成员的动态排序问题。比如游戏用户的积分会不断变化,用户本身不能重复,但排名要随着积分实时调整。使用 ZSet 后,只需要更新用户对应的 score,Redis 会自动维护排序
第二,解决 Top N 查询问题。比如积分榜前 100 名、最近活跃的 50 个用户、优先级最高的 10 个任务,都可以通过 ZSet 的范围查询快速获取
第三,解决按分数区间筛选问题。比如查询某个时间窗口内的活跃用户、查询已经到期的任务、清理过期数据,都可以把时间戳作为 score,然后按 score 范围查询或删除
第四,解决排名查询问题。比如用户想知道自己当前排第几名,使用 ZRANK 或 ZREVRANK 可以直接查询指定 member 的排名
常见命令可以按能力分类:
| 能力 | REDIS 命令 | 说明 |
|---|---|---|
| 添加或更新成员 | ZADD | 写入 member 和 score;member 已存在时更新 score |
| 增加分数 | ZINCRBY |
对已有成员累加分数,适合积分变化 |
| 查询分数 | ZSCORE |
查询指定 member 的 score |
| 查询排名 | ZRANK / ZREVRANK |
查询成员正序或倒序排名 |
| 查询范围 | ZRANGE / ZREVRANGE |
按排名范围查询 |
| 按分数查询 | ZRANGEBYSCORE |
查询指定 score 区间内的成员 |
| 删除成员 | ZREM |
删除指定 member |
| 按分数删除 | ZREMRANGEBYSCORE |
删除某个 score 区间内的成员 |
需要注意的是,ZSet 并不是所有操作都是O(1)。比如 ZADD、ZINCRBY、ZRANK 通常是 O(logN);范围查询通常是 O(logN+M),其中M是返回的元素数量。
2. ZSet 底层数据结构
ZSet 的底层实现不是单一结构,而是根据数据规模选择不同编码。
2.1. listpack紧凑列表
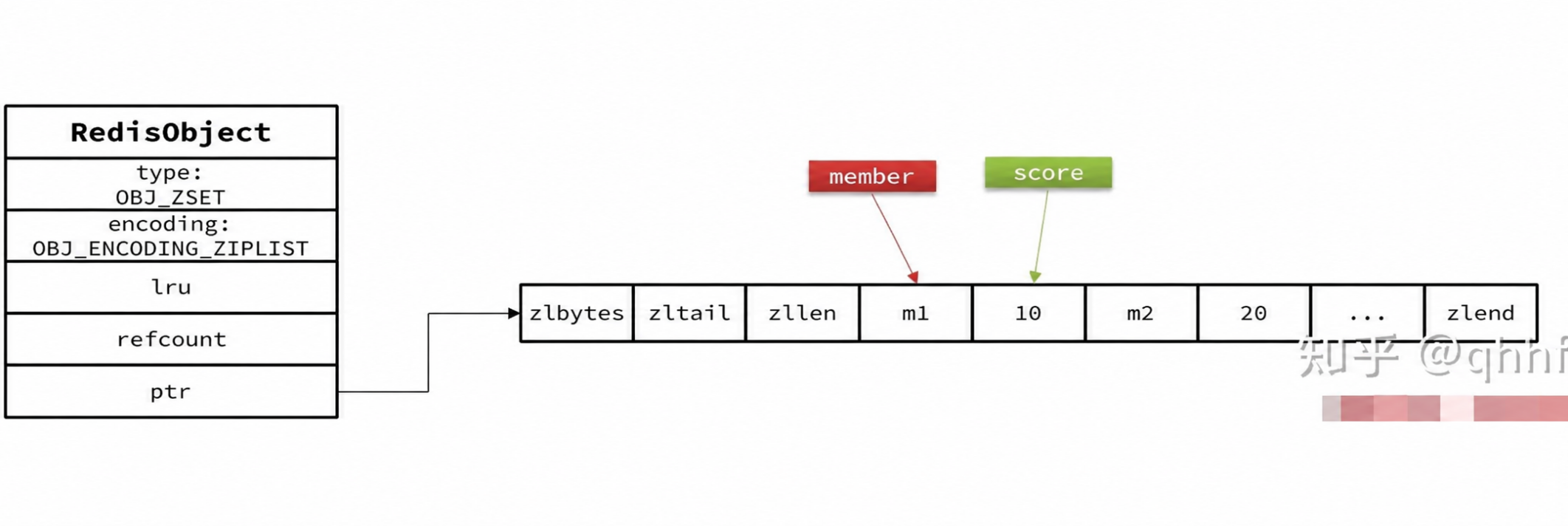
Redis ZSet 的底层实现为跳跃列表和哈希表两种,跳跃列表保证了元素的排序和快速的插入性能,哈希表则提供了快速查找的能力。然而当元素数量不多时,hashtable和skiplist的优势不明显,而且更耗内存。因此zset还会采packist (redis7.0版本之前称为ziplist压缩列表) 结构来节省内存,不过需要同时满足两个条件:
- 元素数量小于zset_max_packlist_entries,默认值128
- 每个元素都小于zset_max_packlist_value字节,默认值64
packlist本身没有排序功能,而且没有键值对的概念,因此zset把 member 和 score 按照固定格式紧凑地存放在一段连续内存中来实现键值对和排序功能:
- packlist是连续内存,因此score和element是紧挨在一起的两个entry, member在前, score在后
- score越小越接近队首,score越大越接近队尾,按照score值升序排列
底层结构如下图:
2.2. dict+skiplist哈希表和跳表
核心结构:多层有序链表:
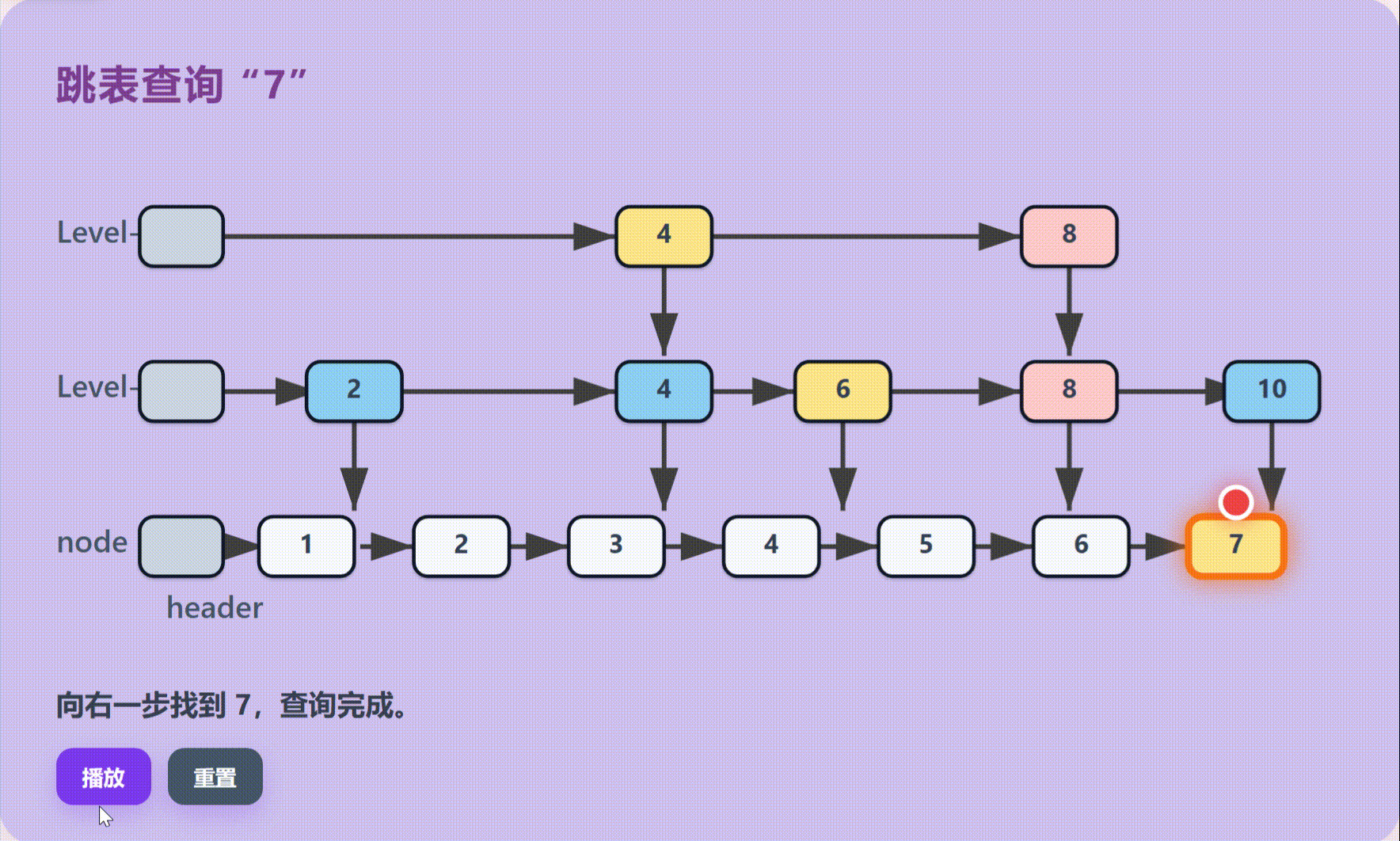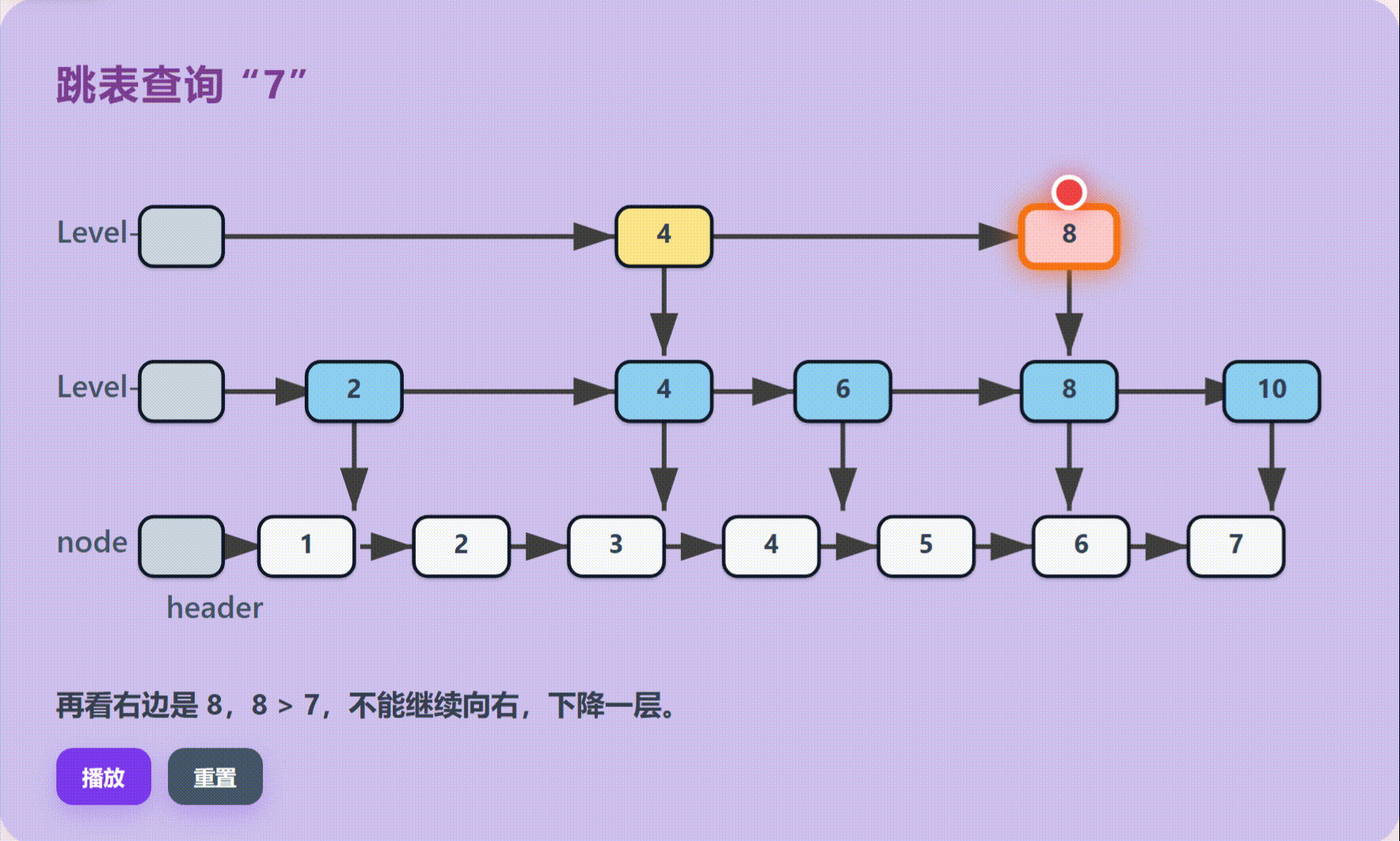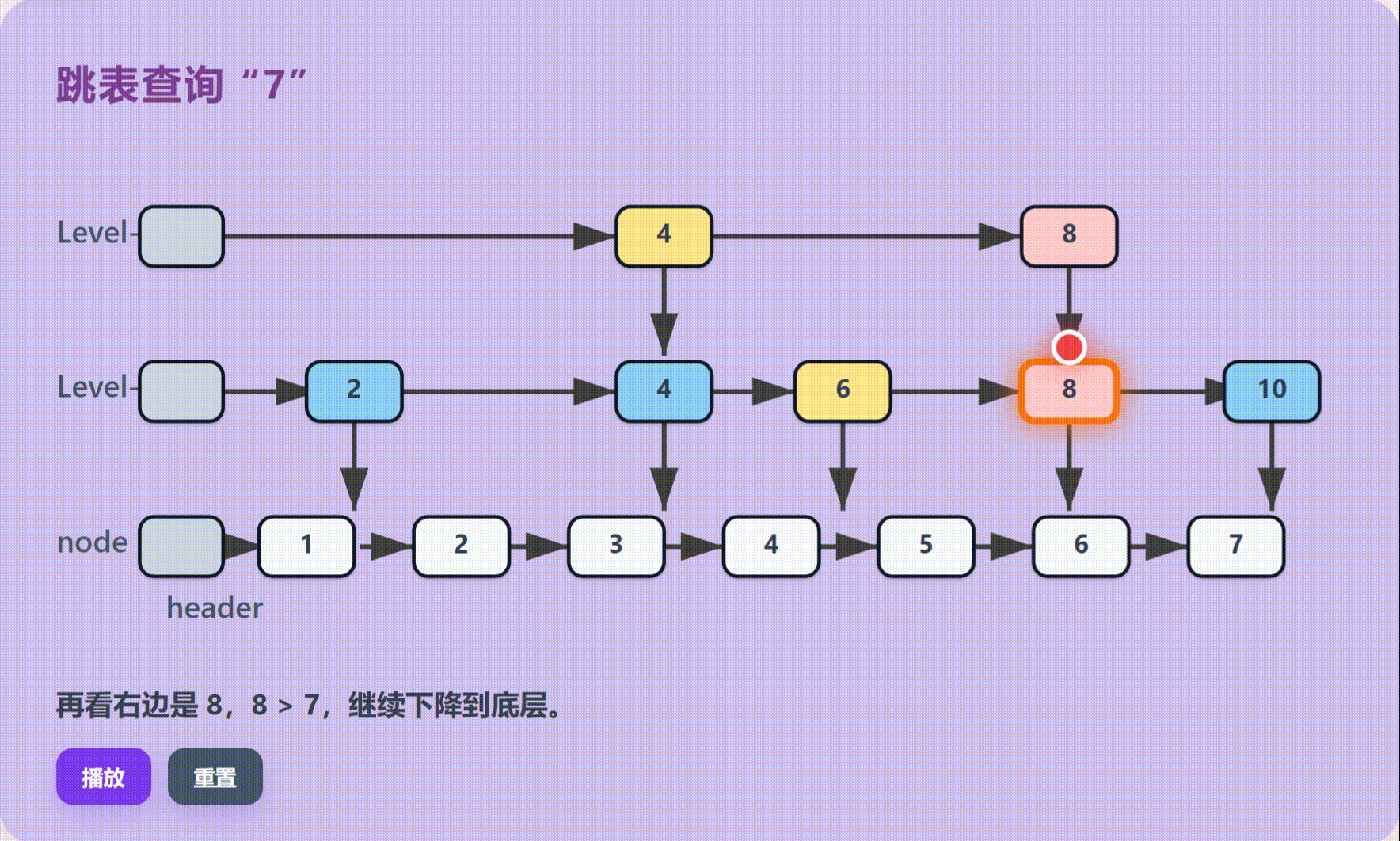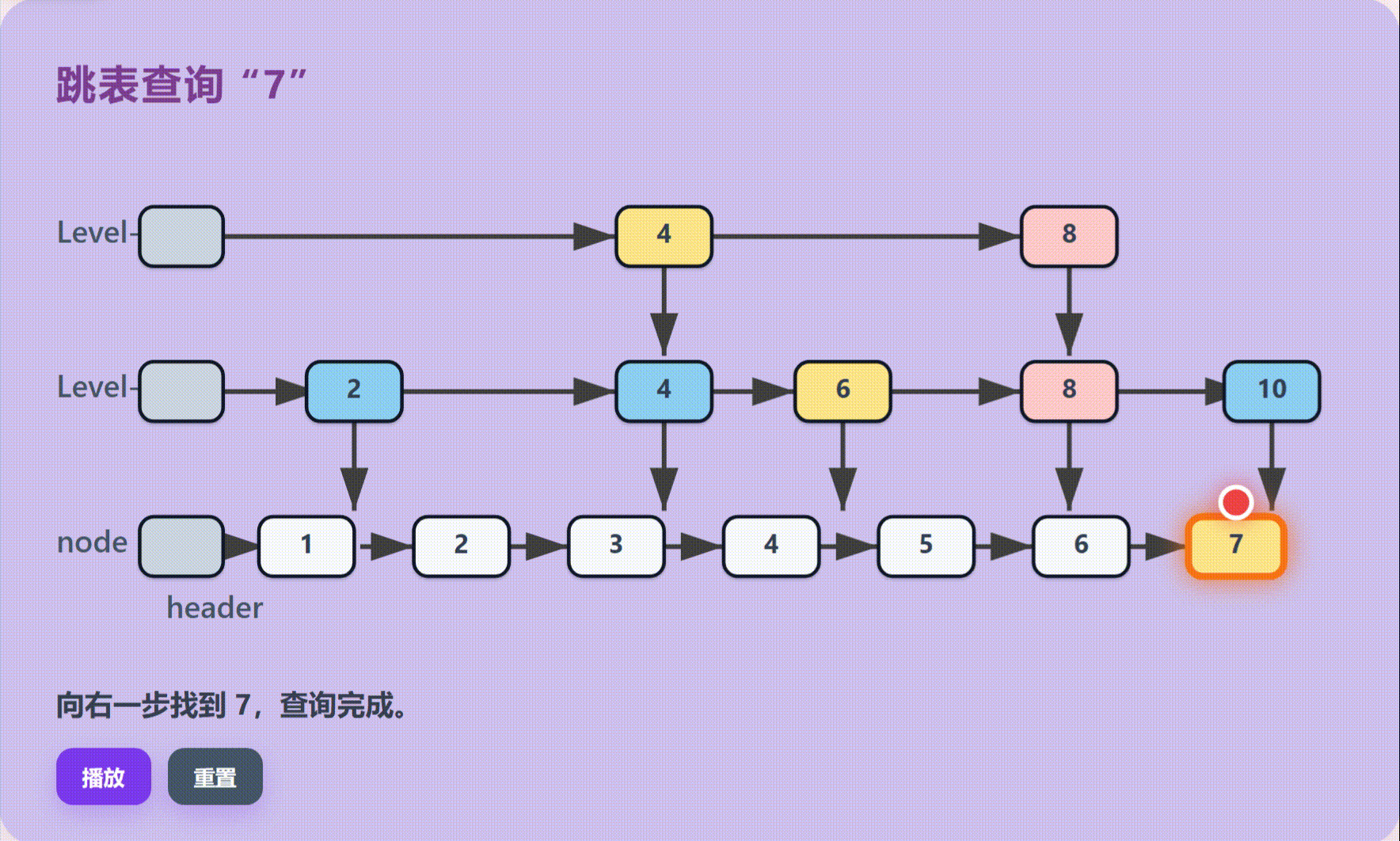
跳表由多层结构组成,最底层是包含所有元素的完整有序链表;上层则是稀疏的索引层,每一层都是下一层的子集,像快捷通道一样存在。
执行流程:分层跳跃查找:
不同于单链表的逐个遍历,跳表采用高层定位,低层查找的策略。在当前层无法前进时退回上一节点并向下一层移动,重复此过程直到底层,最后进行线性确认。
技术优势:平衡树级效率:
通过空间换时间的策略,跳表在保持链表插入删除灵活性的同时,大幅提升了查询效率,避免了传统链表O(N)的线性开销。
所以当 ZSet 元素数量较少或元素长度较短(member数<128或member的长度>64 字节)采用listpack。它的优点是节省内存;
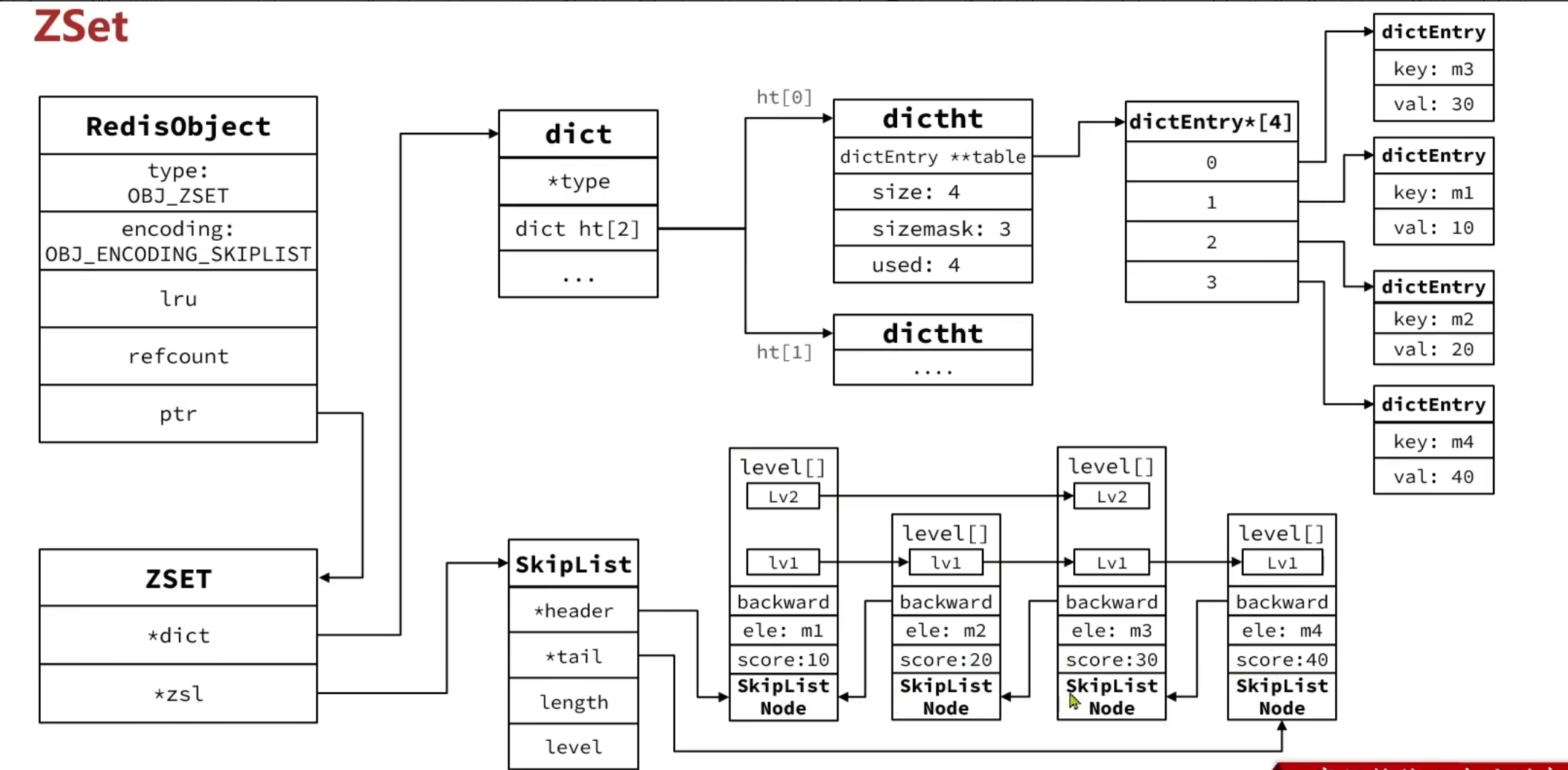
当数据规模突破预设阈值时Redis 会自动升级为双结构组合模式。
可以把它理解成两套索引服务于同一批数据:
-
dict: 哈希表,负责根据 member 快速找到 score,适合 ZSCORE、判断 member 是否存在、更新指定 member。
-
skiplist: 跳表,负责根据 score 维护有序关系,适合排名查询、范围查询、Top N 查询。
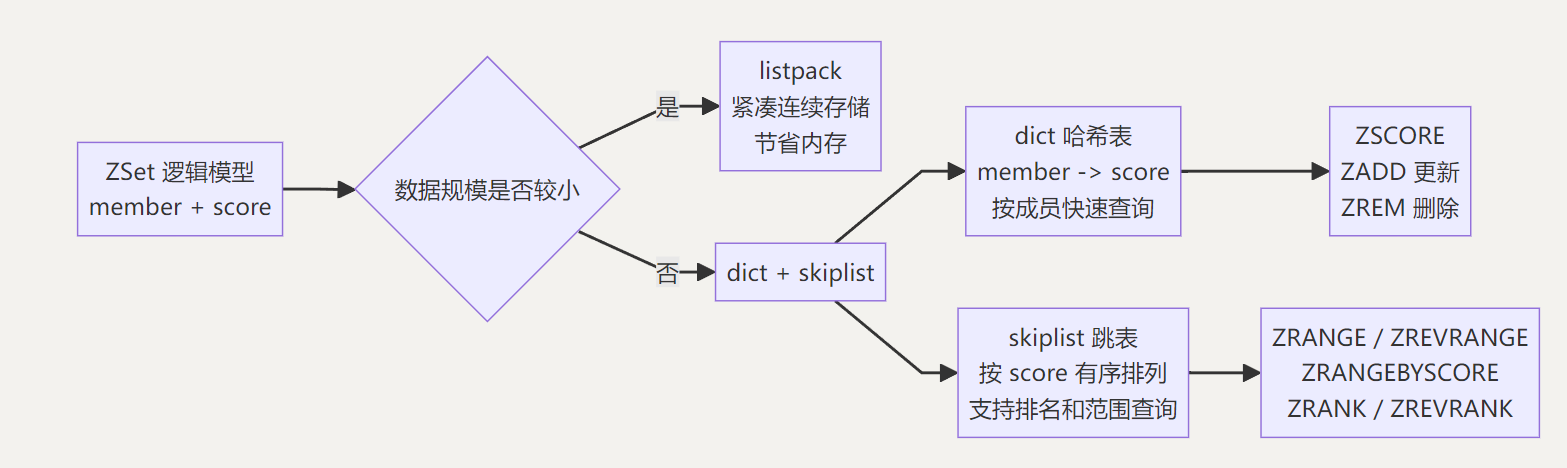
为什么 Redis 不只用哈希表?
因为哈希表虽然可以快速根据 member 找到 score,但它本身不维护 score 的有序关系。如果只用哈希表,要查排行榜前 100 名,就需要把所有元素取出来再排序,成本很高。
为什么 Redis 不只用跳表?
因为跳表适合有序查询,但如果每次都要根据 member 查找对应 score,只靠跳表也不够直接。ZSet 需要频繁判断 member 是否存在、更新指定 member 的分数,所以需要哈希表辅助。
因此,大数据量 ZSet 使用 dict和skiplist 是一种空间换时间的设计:多维护一份索引,换来成员查询、范围查询、排名查询都比较高效。
跳表可以理解为多层链表。底层保存完整有序数据,上层保存稀疏索引。查找时先从高层快速跳跃,再逐层下降,避免从头节点一个个遍历。
3. 典型应用场景
3.1 游戏/积分排行榜
排行榜是 ZSet 最典型的场景
设计方式:
XML
key = game:rank:daily:2026-05-22
member = userID
score = 用户积分常用操作:
-
用户获得积分时,用 ZINCRBY 增加分数
-
查询前 N 名时,用 ZREVRANGE 或 ZREVRANGEWITHSCORES,因为积分通常越高排名越靠前
-
查询用户个人排名时,用 ZREVRANK
-
日榜、周榜、赛季榜可以使用不同 Key,并设置合理过期时间
需要注意:
-
如果用户量很大,不建议所有榜单都塞进一个永久 key
-
日榜、周榜适合按时间分片,例如 game:rank:daily:2026-05-22
-
如果积分相同,Redis 会按 member 字典序排序;如果业务要求严格并列名次,需要应用层额外处理
3.2 优先级队列
ZSet 可以实现轻量级优先级队列。关键思路是用 score 表示优先级或执行时间。
如果是优先级队列:
XML
key = queue:priority:payment
member = taskID
score = priority如果是延迟队列:
XML
key = queue:delay:order
member = taskID
score = executeAt Unix 时间戳常用操作:
-
写入任务时,用 ZADD
-
获取到期任务时,用 ZRANGEBYSCORE queue -inf now LIMIT 0 N
-
删除已取出的任务时,用 ZREM
高并发消费者场景下,不能简单地先 ZRANGEBYSCORE 再 ZREM,因为多个消费者可能同时拿到同一个任务。更稳妥的方式是用 Lua 脚本把查询到期任务和删除任务封装成一个原子操作。
需要注意:
-
ZSet 队列适合轻量调度,不等同于 Kafka、RabbitMQ 这类完整消息队列
-
如果任务执行失败,需要设计重试机制,比如重新写回 ZSet 并更新下一次执行时间
-
member 通常只放 taskID,任务详情建议放数据库或 Hash,避免 ZSet member 过大
3.3 在线用户活跃时间
在线用户或最近活跃用户也适合用 ZSet 建模。核心思路是把最后活跃时间作为 score
设计方式:
Go
key = user:active:last_seen
member = userID
score = lastSeen Unix 时间戳常用操作:
-
用户发生心跳、请求接口、发送消息时,用 ZADD 更新活跃时间
-
查询最近活跃用户时,用 ZREVRANGE
-
查询某段时间内活跃用户时,用 ZRANGEBYSCORE
-
清理长时间不活跃用户时,用 ZREMRANGEBYSCORE key -inf expireBefore
这个场景的好处是,ZSet 同时记录了谁活跃和什么时候活跃。相比只用 Hash,它可以很方便地做最近活跃排序和过期清理。
需要注意:
-
高频心跳会带来大量写入,需要控制更新频率,例如 30 秒或 60 秒更新一次
-
如果在线用户规模很大,可以按业务、地区、房间、租户拆分 key
-
判断在线通常不是只看 Redis 中有没有 member,而是看最后活跃时间是否在窗口。
4. Go-Redis 相关 ZSet 示例代码
Go
package zsetdemo
import (
"context"
"strconv"
"time"
"github.com/redis/go-redis/v9"
)
// AddGameScore 给游戏用户增加积分
func AddGameScore(
ctx context.Context,
rdb *redis.Client,
rankKey string,
userID string,
delta float64,
) (float64, error) {
return rdb.ZIncrBy(ctx, rankKey, delta, userID).Result()
}
// GetGameTopN 查询游戏积分排行榜前 N 名
// 1. 积分榜通常按分数从高到低展示,所以使用 ZREVRANGE
// 2. WithScores 表示同时返回用户 ID 和积分
// 3. Redis range 的 stop 是闭区间,所以前 N 名对应 0 到 n-1
func GetGameTopN(ctx context.Context, rdb *redis.Client, rankKey string, n int64) ([]redis.Z, error) {
return rdb.ZRevRangeWithScores(ctx, rankKey, 0, n-1).Result()
}
// GetGameUserRank 查询指定用户在游戏积分榜中的排名
// 1. 使用 ZREVRANK 按分数从高到低查询排名
// 2. Redis 返回的排名从 0 开始
// 3. 对外展示时通常加 1,转成从第 1 名开始
func GetGameUserRank(ctx context.Context, rdb *redis.Client, rankKey string, userID string) (int64, error) {
rank, err := rdb.ZRevRank(ctx, rankKey, userID).Result()
if err != nil {
return 0, err
}
return rank + 1, nil
}
// AddPriorityTask 写入一个优先级任务
// 1. 使用 ZADD 写入任务 ID 和优先级
// 2. score 越小表示优先级越高时,消费者可以从最小 score 开始取
// 3. 如果 taskID 已存在,ZADD 会更新该任务的优先级
func AddPriorityTask(ctx context.Context, rdb *redis.Client, queueKey string, taskID string, priority float64) error {
return rdb.ZAdd(ctx, queueKey, redis.Z{
Score: priority,
Member: taskID,
}).Err()
}
// AddDelayTask 写入一个延迟任务
// 1. 使用任务执行时间作为 score
// 2. member 只保存 taskID,任务详情建议保存在数据库或 Redis Hash 中
// 3. 消费者通过当前时间查询已经到期的任务
func AddDelayTask(ctx context.Context, rdb *redis.Client, queueKey string, taskID string, executeAt time.Time) error {
return rdb.ZAdd(ctx, queueKey, redis.Z{
Score: float64(executeAt.Unix()),
Member: taskID,
}).Err()
}
// GetDueTasks 查询已经到期但尚未删除的任务
// 1. 使用 ZRANGEBYSCORE 查询 score 小于等于当前时间的任务
// 2. Limit 控制单次拉取数量,避免一次返回过多任务
// 3. 这个函数只查询不删除,多消费者场景需要配合 Lua 原子删除
func GetDueTasks(ctx context.Context, rdb *redis.Client, queueKey string, now time.Time, limit int64) ([]string, error) {
return rdb.ZRangeByScore(ctx, queueKey, &redis.ZRangeBy{
Min: "-inf",
Max: strconv.FormatInt(now.Unix(), 10),
Offset: 0,
Count: limit,
}).Result()
}
var popDueTasksScript = redis.NewScript(`
local tasks = redis.call("ZRANGEBYSCORE", KEYS[1], "-inf", ARGV[1], "LIMIT", 0, ARGV[2])
if #tasks == 0 then
return tasks
end
redis.call("ZREM", KEYS[1], unpack(tasks))
return tasks
`)
// PopDueTasks 原子获取并删除已经到期的任务
// 1. 使用 Lua 脚本把查询到期任务和删除任务合并为一个原子操作
// 2. 避免多个消费者同时拿到同一批 taskID
// 3. 返回的任务需要由业务层继续加载详情并执行
func PopDueTasks(ctx context.Context, rdb *redis.Client, queueKey string, now time.Time, limit int64) ([]string, error) {
result, err := popDueTasksScript.Run(
ctx,
rdb,
[]string{queueKey},
now.Unix(),
limit,
).StringSlice()
if err != nil {
return nil, err
}
return result, nil
}
// UpdateUserActiveTime 更新用户最后活跃时间
// 1. 使用 Unix 时间戳作为 score
// 2. member 使用用户 ID,保证每个用户只保留一条最后活跃记录
// 3. 用户再次活跃时,ZADD 会覆盖旧 score
func UpdateUserActiveTime(ctx context.Context, rdb *redis.Client, activeKey string, userID string, activeAt time.Time) error {
return rdb.ZAdd(ctx, activeKey, redis.Z{
Score: float64(activeAt.Unix()),
Member: userID,
}).Err()
}
// GetRecentlyActiveUsers 查询最近活跃的用户
// 1. 最后活跃时间越大,说明用户越近活跃
// 2. 使用 ZREVRANGE 按 score 从大到小查询
// 3. 返回 score 方便业务层展示最后活跃时间
func GetRecentlyActiveUsers(ctx context.Context, rdb *redis.Client, activeKey string, n int64) ([]redis.Z, error) {
return rdb.ZRevRangeWithScores(ctx, activeKey, 0, n-1).Result()
}
// GetActiveUsersInWindow 查询指定时间窗口内活跃过的用户
// 1. 使用时间窗口的开始和结束时间作为 score 范围
// 2. 查询结果是该窗口内有过活跃行为的用户 ID
// 3. 如果结果可能很大,生产环境建议增加分页参数
func GetActiveUsersInWindow(ctx context.Context, rdb *redis.Client, activeKey string, start time.Time, end time.Time) ([]string, error) {
return rdb.ZRangeByScore(ctx, activeKey, &redis.ZRangeBy{
Min: strconv.FormatInt(start.Unix(), 10),
Max: strconv.FormatInt(end.Unix(), 10),
}).Result()
}
// RemoveInactiveUsers 清理长时间不活跃的用户
// 1. expireBefore 表示活跃时间早于该时间的用户已经过期
// 2. 使用 ZREMRANGEBYSCORE 按 score 范围批量删除
// 3. 返回值表示被清理的用户数量
func RemoveInactiveUsers(ctx context.Context, rdb *redis.Client, activeKey string, expireBefore time.Time) (int64, error) {
return rdb.ZRemRangeByScore(
ctx,
activeKey,
"-inf",
strconv.FormatInt(expireBefore.Unix(), 10),
).Result()
}上面的代码可以组合成三个完整业务流程:
排行榜流程:
用户完成任务 -> AddGameScore 增加积分 -> GetGameTopN 查询榜单 -> GetGameUserRank 查询个人排名
优先级队列流程:
业务创建任务 -> AddPriorityTask 或 AddDelayTask 写入 ZSet -> PopDueTasks 原子取出任务 -> 业务执行任务
在线活跃流程:
用户请求或心跳 -> UpdateUserActiveTime 更新活跃时间 -> GetRecentlyActiveUsers 查询最近活跃用户 -> RemoveInactiveUsers 清理过期用户
5. 总结
Zset虽然功能强大,但在实际使用中也藏着不少问题与限制:
-
大 key 风险:单个 ZSet 存储千万级数据时,内存、查询延迟、迁移成本都会上升
-
score 精度:score 是双精度浮点数,业务上建议优先使用整数,例如积分、毫秒时间戳、秒级时间戳
-
原子性:查询后删除这类组合操作在并发场景下容易重复消费,需要 Lua 脚本或事务
-
数据角色:ZSet 更适合做排序索引、缓存、队列辅助结构,核心业务数据仍建议落数据库
Zset的魅力可以用两句话概括:高效排序与范围查询的完美结合,动态高频场景的理想选择。它通过跳表和哈希表的巧妙设计,实现了O(log N)的插入、查询和删除性能,同时支持丰富的范围操作(如ZRANGEBYSCORE和ZREMRANGEBYRANK)。无论是实时更新积分排行,还是按时间调度任务,Zset都能快速响应,且内存占用相对可控。这种快而稳的特性,让它在中小规模数据场景中无可替代。