摘要
本文深入介绍了线性回归模型的优化求解方法正规方程法与以及简单的引入了梯度下降法。在一元线性回归部分,通过身高体重预测案例推导了损失函数对参数的偏导,并解出了最优权重与截距。在多元线性回归部分,将问题转化为矩阵形式,利用矩阵求导推导出正规方程解,同时指出了该方法可能面临的计算量大及矩阵不可逆的问题。随后,文章详细阐述了梯度下降法的基本原理与迭代公式,以单变量函数为例演示了参数更新过程,并讨论了学习率的选择与停止策略。本文为理解线性回归的参数学习机制提供了完整的数学推导与算法对比。
Abstract
This article introduces the normal equation method for linear regression optimization and briefly covers gradient descent. Using a height-weight prediction example, it derives the partial derivatives of the loss function and solves for the optimal parameters in simple linear regression. For multiple linear regression, the problem is transformed into matrix form to derive the normal equation solution, along with a discussion of its computational cost and matrix invertibility issues. The article then explains the basic principle and iterative formula of gradient descent, demonstrates parameter updates with a univariate example, and discusses learning rate selection and stopping criteria. It provides a complete mathematical derivation and algorithm comparison for understanding linear regression parameter learning.
一.正规方程法
1.一元线性回归
接着上一篇,我们知道损失函数是用来衡量真实值与预测值之间的差异,为优化指明方向。
对于身高与体重之间的关系,我们得到的损失函数如下:
简化下公式如下:
其中和
与前面一样分别表示预测值和真实值,i表示第几个样本。
为了求得损失函数的最小值,则就要先求得损失函数最小值时,对应的k与b的取值,所以这里就对损失函数分别对于k和b求偏导。便得到如下公式:
再对得到的k与b的偏导进行化简并令其等于0,便得到如下公式:
接着就将之前已知的五组身高与体重的数据带入求解k和b。
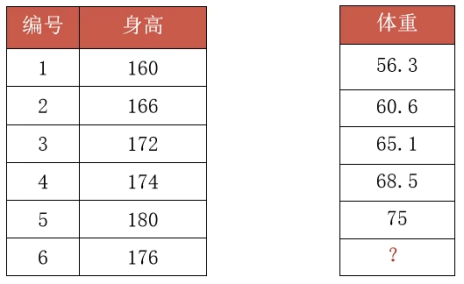

接着根据上图中的①式与②式得到k=0.0397,b=60.7615,从而就可以对第六组数据进行预测,得到176身高对应体重为67kg。
以上就是对于一元线性回归的正规方程解法。
2.多元线性回归
我们前面已知多元线性回归方程如下:
对应的数据集其中模型权重w是一个向量
,代表特征数。
现在我们再看多元线性回归方程的损失函数,先看第一个样本的预测值,其公式如下:
所以第一个样本的损失如下:
如此,要使n个样本损失最小,就相当于第1个样本损失+第2个样本损失+...+第n个样本的损失。所以多元线性回归的损失函数如下:
其中i代表第i个样本,j代表当前样本的每j列特征。所以要使Loss(W)取得最小值时,此时的权重W(w就是一个向量)就是最优解。
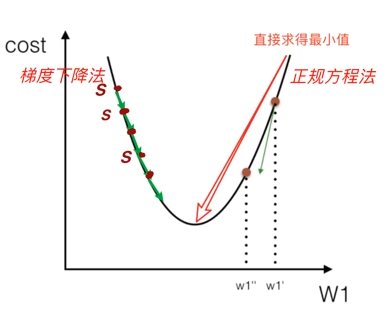
而求解最优解的方法有两个一个就是解矩阵方程(也就是正规方程)另一个就是通过梯度下降法求解。
在求解之前先补充下矩阵求导公式的前置知识:
-
线性项求导:
(a 是常数向量)
-
二次项求导:
通过正规方程法的求解如下:
首先将损失函数不同方式转化成矩阵方式:
从而对损失函数拆开括号并进行求导,同时令其等于0:
这个过程中就是要假定的逆存在,否则上面就不成立。
所以通过上面我们可以了解到正规方程法存在的问题:
1.如果运算量过大,可能造成内存溢出
2.如果的逆不存在,则解就不是唯一
二.梯度下降法
先简单的回顾下梯度下降法,其输入是初始位置S,每步距离a,输出是从位置S到最低点的方向。过程如下:
步骤1:令初始化位置为山的任意位置S
步骤2:在当前位置环顾四周,如果四周都要比S高,则返回S,否则执行步骤3
步骤3:在当前位置环顾四周,寻找坡度最陡的方向,令其为x方向
步骤4:沿着x方向往下走,长度为a,到达新的位置S'
步骤5:在S'位置环顾四周,如果四周都要比S'高,则返回S',否则转到步骤3
梯度下降的公式:
其中指学习率(步长),不能过小或过大,机器学习中在0.001~0.01范围中。梯度是上升最快的方向,我们需要的是下降所以这里加负号。这个过程就是循环迭代当前点的梯度,更新当前的权重参数。
就以单变量梯度下降举个例子:
假设函数为,求当
为何值时,函数值最小(初始化起点为1,学习率
为0.4),则梯度下降的迭代计算过程如下:
第一步:θ=1
第二步:θ=1-0.4(2*1)=0.2
第三步:θ=0.2-0.4(2*0.2)=0.04
第四步:θ=0.04-0.4(2*0.04)=0.008
......
第N步:θ已经极其接近0,J(θ)也接近最小值
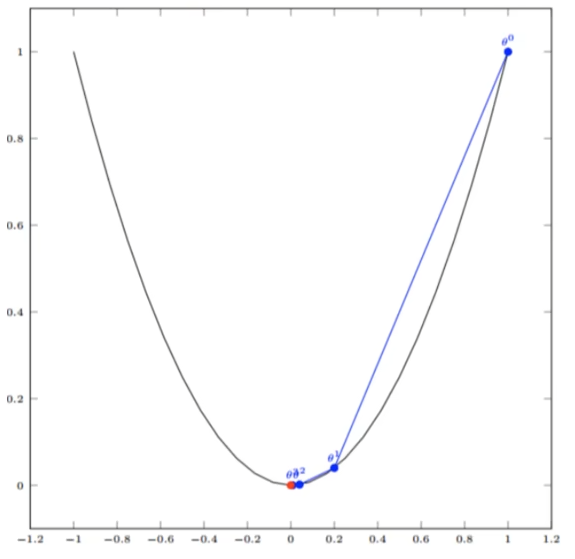
通过上面其实基本可以发现,经过四次运算,基本达到了函数的最低点。
对于何时停止进行梯度下降运算,我们可以设置计算次数的上限(也就是向下走的步数),或者给最后的结果设一个阈值,如果最后的结果达到了阈值就结束运算。
总结
本文系统讲解了线性回归参数求解的两种核心方法。正规方程法通过矩阵运算直接求解最优参数,具有一步到位、无需迭代的优点,但在特征维度较高时计算成本大,且要求可逆。梯度下降法通过迭代沿负梯度方向更新参数,适用于大规模数据,但需要合理选择学习率和迭代次数。文中从一元线性回归的偏导推导到多元线性回归的矩阵表达,再到梯度下降的直观示例,层层递进地揭示了两种方法的数学本质与应用场景。理解这两种优化方法,是掌握线性回归乃至更复杂机器学习模型训练过程的关键。