拒绝AI幻觉!从"人工排雷"到"工程化约束":Harness Engineering 在长文生成中的实战指南
引言:AI写长文的"幻觉"痛点
最近我在尝试让大语言模型(LLM)自动生成万字以上的长篇行业分析报告和技术调研文档。初看生成结果,文笔流畅、结构严谨,但当我进入人工审核 环节时,却惊出一身冷汗:文中充斥着大量胡编乱造的数据、虚构的参考文献以及看似合理实则毫无根据的结论。
如果依靠人工逐字逐句去核对事实、消除这些幻觉,不仅令人身心俱疲,而且完全背离了"LLM自动化办公"的初衷。我们引入AI是为了提效,而不是给自己找一个"需要反复擦屁股的实习生"。
在尝试了多种 Prompt 优化和 RAG(检索增强生成)方案后,效果依然不尽如人意。直到我转向了 Harness Engineering(工程化约束/护栏工程) 的实操路子,才真正迎来了转机。
在试用这套工程化方法后,我有了一个惊人的发现:当把结构化的校验错误反馈给大模型时,它竟然能顺藤摸瓜,把长文中那些隐蔽的幻觉问题一点点自己列出来并修正! 原来,只要给对"抓手",它自己是可以发现并纠正这些错误的。
虽然这种方案仍然无法做到100%完美,但我终于明白了什么是真正的 Harness Engineering,以及如何在实际业务中落地。
为什么长文生成必然伴随幻觉?
在探讨解决方案之前,我们必须认清一个技术现实:幻觉(Hallucination)不是大模型的Bug,而是当前 Transformer 架构的固有特性。
大模型的本质是"下一个词预测(Next Token Prediction)"的概率模型。在生成短文本时,模型可以依靠短期注意力机制保持事实的一致性;但在生成长文时,随着上下文的不断拉长,模型会出现"注意力漂移"和"事实遗忘"。为了维持文本的连贯性和逻辑上的"看似合理",模型会不由自主地动用其参数中的先验概率去"脑补"细节,从而产生数据捏造、文献虚构等幻觉。
试图单纯通过 Prompt 告诉模型"请不要胡编乱造",就像告诉一个喝醉的人"请走直线"一样,收效甚微。
破局之道:什么是 Harness Engineering?
既然"软约束"(Prompt)无效,我们就必须引入"硬约束"。这就是 Harness Engineering 的核心理念。
在软件工程中,Harness 通常指测试线束或控制框架。在 LLM 应用开发中,Harness Engineering 指的是通过外部确定性代码、规则引擎、测试用例和护栏(Guardrails),对大模型的输出进行强制性的校验和约束。
它的核心思想是:不要试图让大模型证明自己没有撒谎,而是用外部代码去验证它。
通过 Harness 脚本,我们可以将模糊的"事实核查"转化为确定性的"代码断言(Assert)"。当断言失败时,脚本会输出精确的错误报告,并将其作为 Feedback 喂给大模型,强制其进行自我修正(Self-Correction)。
实战:构建通用长文防御性校验系统
为了让大家更直观地理解,我将原有的特定业务场景泛化,构建了一个通用的长文(如商业报告/技术调研)防御性三步校验系统。
该系统基于"封闭宇宙原则(Closed-World Assumption)":即报告中出现的所有核心数据、引用文献和关键结论,必须能在给定的源材料或受信知识库中找到映射,否则即视为幻觉。
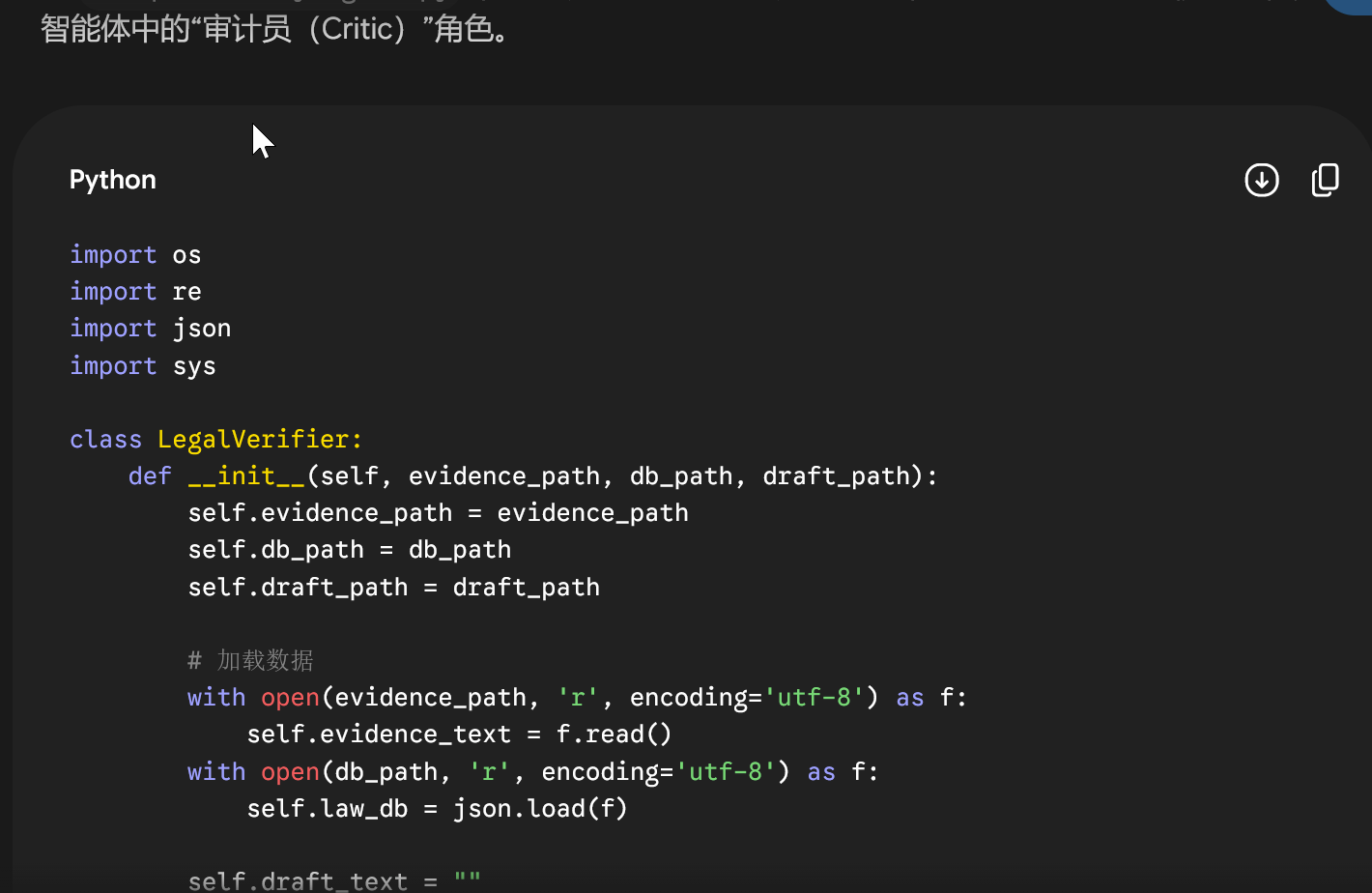
以下是完整的 Python 校验脚本实现:
python
import os
import re
import json
import sys
class DocumentFactChecker:
def __init__(self, source_data_path, knowledge_base_path, draft_report_path):
self.source_data_path = source_data_path
self.knowledge_base_path = knowledge_base_path
self.draft_report_path = draft_report_path
# 加载源数据(如原始财报、调研录音转写等)
with open(source_data_path, 'r', encoding='utf-8') as f:
self.source_text = f.read()
# 加载受信知识库(如真实的行业白皮书列表、权威机构名单)
with open(knowledge_base_path, 'r', encoding='utf-8') as f:
self.knowledge_base = json.load(f)
self.draft_text = ""
if os.path.exists(draft_report_path):
with open(draft_report_path, 'r', encoding='utf-8') as f:
self.draft_text = f.read()
def verify_step_1_fact_mapping(self):
"""第一步校验:事实锚定检查。检查草稿中是否有无中生有的核心数据/日期"""
errors = []
# 抽取草稿中所有的金额、百分比和日期(长文中最容易产生幻觉的地方)
money_exprs = re.findall(r'(\d+\.?\d*[万亿]元|\d+\.?\d*%)', self.draft_text)
date_exprs = re.findall(r'(\d{4}年\d{1,2}月\d{1,2}日|\d{4}年[上|下]半年|\d{4}年Q[1-4])', self.draft_text)
for money in money_exprs:
if money not in self.source_text:
errors.append(f"【数据幻觉】报告中出现了数据 '{money}',但该数据未在原始参考资料中记载!")
for date in date_exprs:
if date not in self.source_text:
errors.append(f"【时间幻觉】报告中出现了时间 '{date}',但该时间未在原始参考资料中记载!")
return errors
def verify_step_2_reference_check(self):
"""第二步校验:确定性知识库与参考文献校验"""
errors = []
# 匹配报告中的参考文献或行业报告格式,例如:《2024人工智能行业白皮书》
reports_cited = re.findall(r'《([^》]+)》', self.draft_text)
# 匹配报告中的机构名称或数据来源,例如:[来源:国家统计局]
sources_cited = re.findall(r'\[来源[::]([^\]]+)\]', self.draft_text)
valid_reports = self.knowledge_base.get("reports", [])
valid_sources = self.knowledge_base.get("sources", [])
for report in reports_cited:
if report not in valid_reports:
errors.append(f"【文献幻觉】报告引用了未经校验的文献:《{report}》!请核实该文献是否真实存在。")
for source in sources_cited:
clean_source = source.strip()
if clean_source not in valid_sources:
errors.append(f"【来源幻觉】报告引用了虚构的数据来源:[{source}]!该机构不在受信知识库中。")
return errors
def verify_step_3_traceability_audit(self):
"""第三步校验:反向溯源审计。检查关键结论是否强制标注了数据支撑标记"""
errors = []
lines = self.draft_text.split('\n')
for i, line in enumerate(lines):
# 检查包含结论性词汇的行
if any(kw in line for kw in ["表明", "预测", "综上所述", "因此", "可以看出"]):
if not any(tag in line for tag in ["据表", "参考", "来源", "详见", "附件", "如图"]):
errors.append(f"【溯源审计】第 {i+1} 行关键结论缺乏数据支撑指针,违反封闭宇宙原则!内容: \"{line.strip()}\"")
return errors
def run_all_checks(self):
print("====== 🛡️ 开始执行 AI 长文生成防御性三步校验 ======")
if not self.draft_text:
print("[AUDIT_FAILED] 错误:目标报告草稿为空或不存在。")
sys.exit(1)
all_errors = []
all_errors.extend(self.verify_step_1_fact_mapping())
all_errors.extend(self.verify_step_2_reference_check())
all_errors.extend(self.verify_step_3_traceability_audit())
if all_errors:
print("\n[AUDIT_FAILED] 审计未通过!发现以下幻觉或违规行为:")
for err in all_errors:
print(err)
print("\n请 AI Agent 根据上述错误报告,重新读取源材料,修改报告并再次运行此脚本。")
sys.exit(1)
else:
print("\n[AUDIT_PASSED] 🎉 恭喜!报告 100% 契合已知事实,文献/来源全部真实有效,未发现任何幻觉偏离。")
sys.exit(0)
if __name__ == "__main__":
checker = DocumentFactChecker(
source_data_path="data/source_materials.txt",
knowledge_base_path="data/knowledge_base.json",
draft_report_path="output/draft_report.md"
)
checker.run_all_checks()深度解析:三步校验法的工程逻辑
上述代码虽然不复杂,但完美体现了 Harness Engineering 的分层防御思想:
- Step 1 事实锚定(Fact Mapping):大模型在处理数字和日期时极易发生"张冠李戴"。通过正则提取所有数值型实体,并与 Source Text 进行精确的字符串匹配。这一步能拦截 80% 以上的"硬伤"幻觉。
- Step 2 知识库校验(Reference Check):大模型最喜欢虚构看似权威的参考文献。我们将真实的文献和机构名单预先存入 JSON 知识库(未来可对接向量数据库或外部 API),对模型生成的引用进行白名单校验,彻底杜绝"伪造出处"。
- Step 3 溯源审计(Traceability Audit):这是最高级的一层约束。不仅要求内容真实,还要求"论证过程合规"。强制模型在输出结论性语句时,必须带上"据表X"、"参考来源"等物理指针,逼迫模型在生成时保持逻辑的严密性。
在实际的 Agent 工作流中,这个脚本会作为一个 Tool(工具)被大模型调用。当脚本 sys.exit(1) 时,错误日志会作为系统提示词返回给大模型,触发它的自我反思和重写机制。这就是为什么我说"大模型自己能发现这些问题"的原因------Harness 脚本为它提供了精确的"纠错坐标系"。
局限性与人工审核的重新定位
尽管 Harness Engineering 威力巨大,但我们必须保持清醒:对于长上下文、复杂逻辑推理的案例,想通过这种方式彻底消除幻觉,难度极高,近乎不可能。
正则表达式可能会漏掉一些语义层面的偷换概念;外部知识库也无法穷尽世间所有事实。Transformer 算法的概率本质决定了"绝对确定性"是一个伪命题。
因此,人工审核仍然是必不可少的最后一道防线。
但是,正确实施的 Harness Engineering 手段,其核心优势在于:它彻底改变了人工审核的工作性质,大大减少了工作强度。
过去,人工审核是"大海捞针",审核者需要逐字阅读,大脑高度紧张地去回忆和核对事实;
现在,人工审核变成了"确认报错"和"最终把关"。Harness 脚本已经像不知疲倦的机器卫士一样,把 95% 的事实错误、虚构引用和逻辑断层拦截并高亮了出来。审核者只需要查看脚本的 Audit Report,确认大模型的修改是否到位即可。
总结
从"人工排雷"到"工程化约束",Harness Engineering 为我们提供了一条务实的 LLM 落地路径。不要迷信大模型的自我宣称,用代码构建护栏,用规则约束概率。当你把这套防御性校验系统跑通的那一刻,你会真正感受到 AI 自动化办公带来的巨大生产力飞跃。