摘要
我们展示了 DeepSeek-V4 系列的预览版本,包括两个强大的混合专家(MoE)语言模型------DeepSeek-V4-Pro(总参数量 1.6T,激活参数量 49B)和 DeepSeek-V4-Flash(总参数量 284B,激活参数量 13B)------两者均支持一百万令牌的上下文长度。DeepSeek-V4 系列在架构和优化方面融合了多项关键升级:(1)一种结合了压缩稀疏注意力(CSA)和重度压缩注意力(HCA)的混合注意力架构,以提高长上下文效率;(2)流形约束超连接(mHC),增强了传统的残差连接;(3)以及 Muon 优化器,以实现更快的收敛和更高的训练稳定性。我们在超过 32T 的多样化、高质量令牌上对这两个模型进行了预训练,随后进行了一个全面的后训练流程,以解锁并进一步增强其能力。DeepSeek-V4-Pro-Max 是 DeepSeek-V4-Pro 的最大推理努力模式,它重新定义了开放模型的最先进水平,在核心任务上优于其前代模型。同时,DeepSeek-V4 系列在长上下文场景中非常高效。在百万令牌上下文设置下,与 DeepSeek-V3.2 相比,DeepSeek-V4-Pro 仅需 27%27\%27% 的单令牌推理 FLOPs 和 10%10\%10% 的 KV 缓存。这使得我们能够常规性地支持百万令牌上下文,从而使长期任务和进一步的测试时扩展更加可行。模型检查点可在 https://huggingface.co/collections/deepseek-ai/deepseek-v4 获取。
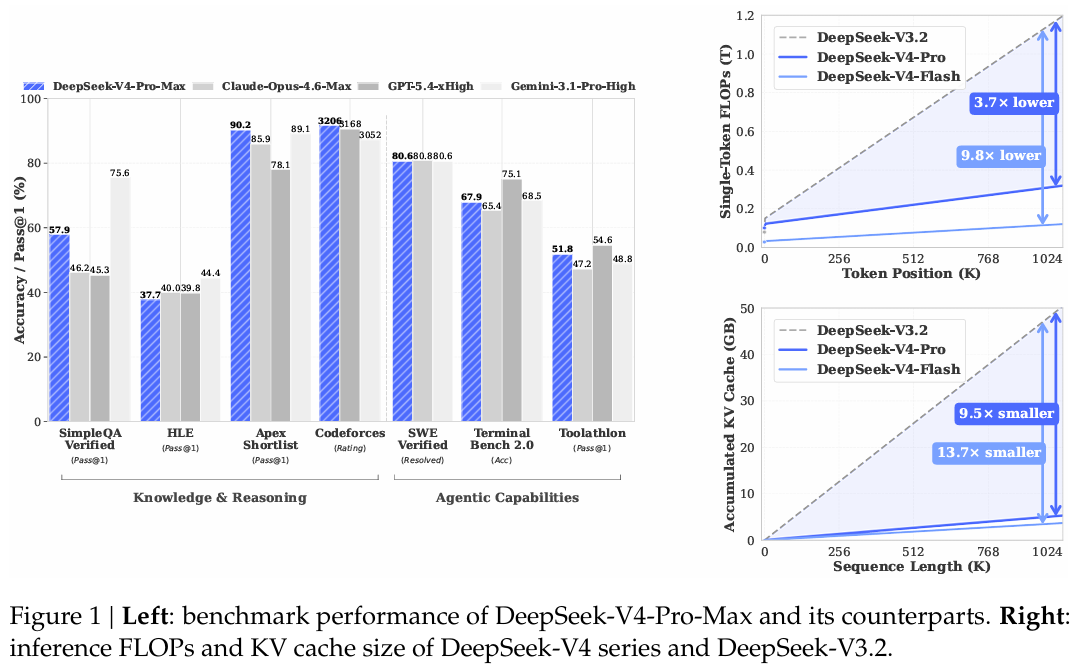
图 1 | 左图:DeepSeek-V4-Pro-Max 及其对标模型的基准性能。右图:DeepSeek-V4 系列和 DeepSeek-V3.2 的推理 FLOPs 和 KV 缓存大小。
1. 引言
推理模型的出现(DeepSeek-AI,2025;OpenAI,2024c)建立了一种新的测试时扩展范式,推动了大语言模型(LLM)的性能大幅提升。然而,这种扩展范式从根本上受到普通注意力机制(Vaswani 等人,2017)的二次计算复杂度的限制,这为超长上下文和推理过程造成了难以承受的瓶颈。与此同时,长期场景和任务的出现------从复杂的智能体工作流到大规模的跨文档分析------也使得对超长上下文的高效支持对未来进展至关重要。虽然最近的开源努力(Bai 等人,2025a;DeepSeek-AI,2024;MiniMax,2025;Qwen,2025)已经推进了通用能力,但在处理超长序列方面的核心架构效率低下仍然是一个关键障碍,限制了测试时扩展的进一步收益,并阻碍了对长期场景和任务的进一步探索。
为了打破超长上下文中的效率障碍,我们开发了 DeepSeek-V4 系列,包括 DeepSeek-V4-Pro(总参数量 1.6T,激活参数量 49B)和 DeepSeek-V4-Flash(总参数量 284B,激活参数量 13B)的预览版本。通过架构创新,DeepSeek-V4 系列在处理超长序列的计算效率方面实现了巨大飞跃。这一突破使得高效支持百万令牌上下文成为可能,为下一代 LLM 开启了百万长度上下文的新时代。我们相信,我们高效处理超长序列的能力解锁了测试时扩展的下一个前沿,为深入研究长期任务铺平了道路,并为探索在线学习等未来范式奠定了必要的基础。
与 DeepSeek-V3 架构(DeepSeek-AI,2024)相比,DeepSeek-V4 系列保留了 DeepSeekMoE 框架(Dai 等人,2024)和多令牌预测(MTP)策略,同时在架构和优化方面引入了若干关键创新。为了增强长上下文效率,我们设计了一种结合了压缩稀疏注意力(CSA)和重度压缩注意力(HCA)的混合注意力机制。CSA 沿着序列维度压缩 KV 缓存,然后执行 DeepSeek 稀疏注意力(DSA)(DeepSeek-AI,2025),而 HCA 对 KV 缓存应用更激进的压缩,但保持密集注意力。为了增强建模能力,我们引入了流形约束超连接(mHC)(Xie 等人,2026),它升级了传统的残差连接。此外,我们将 Muon(Jordan 等人,2024;Liu 等人,2025)优化器引入到 DeepSeek-V4 系列的训练中,从而实现了更快的收敛和更高的训练稳定性。
为了实现 DeepSeek-V4 系列的高效训练和推理以及高效开发,我们引入了若干基础设施优化。首先,我们为 MoE 模块设计并实现了一个单一融合核函数,完全重叠了计算、通信和内存访问。其次,我们采用了 TileLang(Wang 等人,2026),一种领域特定语言(DSL),以平衡开发生产力和运行时效率。第三,我们提供了高效的批量不变和确定性核函数库,以确保训练和推理之间的按位可重现性。第四,我们将 FP4 量化感知训练集成到 MoE 专家权重和索引器 QK 路径中,以减少内存和计算。第五,对于训练框架,我们通过张量级检查点扩展了自动梯度框架,以实现细粒度的重计算控制;并且通过用于 Muon 优化器的混合 ZeRO 策略、通过重计算和融合核函数实现的具有成本效益的 mHC 实现,以及用于管理压缩注意力的两阶段上下文并行,提高了训练效率。最后,对于推理框架,我们设计了一种异构的 KV 缓存结构及磁盘存储策略,以实现高效的共享前缀重用。
通过采用混合的 CSA 和 HCA,以及对计算和存储的精度优化,与 DeepSeek-V3.2 相比,DeepSeek-V4 系列在推理 FLOPs 和 KV 缓存大小方面实现了显著降低,尤其是在长上下文设置下。图 1 的右侧部分展示了 DeepSeek-V3.2 和 DeepSeek-V4 系列的估计单令牌推理 FLOPs 和累积 KV 缓存大小。在 1M 令牌上下文场景中,即使是具有更大激活参数量的 DeepSeek-V4-Pro,其单令牌 FLOPs(以等效 FP8 FLOPs 衡量)也仅达到 DeepSeek-V3.2 的 27%27\%27%,KV 缓存大小仅为 DeepSeek-V3.2 的 10%10\%10%。此外,具有更小激活参数量的 DeepSeek-V4-Flash 进一步提升了效率:在 1M 令牌上下文设置中,其单令牌 FLOPs 仅达到 DeepSeek-V3.2 的 10%10\%10%,KV 缓存大小仅为 DeepSeek-V3.2 的 7%7\%7%。另外,对于 DeepSeek-V4 系列,路由专家参数使用 FP4 精度。虽然在现有硬件上,FP4 ×\times× FP8 操作的峰值 FLOPs 目前与 FP8 ×\times× FP8 相同,但在未来硬件上理论上可以将其效率提高 1/31/31/3,这将进一步提升 DeepSeek-V4 系列的效率。
在预训练期间,我们分别用 32T 令牌训练了 DeepSeek-V4-Flash,用 33T 令牌训练了 DeepSeek-V4-Pro。预训练后,这两个模型可以原生且高效地支持 1M 长度上下文。在我们的内部评估中,DeepSeek-V4-Flash-Base 凭借其更具参数效率的设计,已经在大多数基准测试上超越了 DeepSeek-V3.2-Base。DeepSeek-V4-Pro-Base 进一步扩展了这一优势,为 DeepSeek 基础模型设定了新的性能标准,在推理、编码、长上下文和世界知识任务上实现了全面优越性。
DeepSeek-V4 系列的后训练流程采用两阶段范式:首先独立培养领域特定专家,然后通过同策略蒸馏(Lu and Lab,2025)进行统一模型整合。初始阶段,对于每个目标领域(如数学、编码、智能体和指令跟随),分别独立训练一个专家模型。基础模型首先在高质量、领域特定的数据上进行监督微调(SFT),以建立基础能力。随后,使用组相对策略优化(GRPO)(DeepSeek-AI,2025)应用强化学习(RL),该算法根据针对特定成功标准定制的奖励模型,进一步优化模型以实现领域对齐的行为。此阶段产生一组多样化的专业专家,每个专家在其各自领域都表现出色。最后,为了整合这些不同的专业技能,通过同策略蒸馏训练一个单一的统一模型,其中统一模型作为学生,学习优化与教师模型的反向 KL 散度损失。
核心评估结果总结
- 知识:在对广泛世界知识的评估中,DeepSeek-V4-Pro-Max 是 DeepSeek-V4-Pro 的最大推理努力模式,在 SimpleQA (OpenAI, 2024d) 和 Chinese-SimpleQA (He et al., 2024) 基准测试上显著优于领先的开源模型。关于教育知识------通过 MMLU-Pro (Wang et al., 2024b)、HLE (Phan et al., 2025) 和 GPQA (Rein et al., 2023) 评估------DeepSeek-V4-Pro-Max 相比其开源对手显示出微弱优势。DeepSeek-V4-Pro-Max 显著缩小了与领先的专有模型 Gemini-3.1-Pro 的差距,尽管在这些基于知识的评估中仍落后于它。
- 推理:通过扩展推理令牌,DeepSeek-V4-Pro-Max 在标准推理基准上显示出相对于 GPT-5.2 和 Gemini-3.0-Pro 的优越性能。尽管如此,其性能略微落后于 GPT-5.4 和 Gemini-3.1-Pro,表明其发展轨迹大约落后前沿模型 3 到 6 个月。此外,DeepSeek-V4-Flash-Max 实现了与GPT-5.2 和 Gemini-3.0-Pro 相当的性能,为复杂的推理任务建立了一个极具成本效益的架构。
- 智能体:在公共基准上,DeepSeek-V4-Pro-Max 与领先的开源模型(如 Kimi-K2.6 和 GLM-5.1)持平,但略逊于前沿的闭源模型。在我们的内部评估中,DeepSeek-V4-Pro-Max 优于 Claude Sonnet 4.5,并接近 Opus 4.5 的水平。
- 长上下文:DeepSeek-V4-Pro-Max 在百万令牌上下文窗口的合成任务和实际用例上均取得了强劲的结果,在学术基准上甚至超越了 Gemini-3.1-Pro。
- DeepSeek-V4-Pro 与 DeepSeek-V4-Flash :由于其较小的参数规模,DeepSeek-V4-Flash-Max 在知识评估中表现较低。然而,当分配更大的思考预算时,它在推理任务上取得了相当的结果。在智能体评估中,虽然 DeepSeek-V4-Flash-Max 在若干基准上与 DeepSeek-V4-Pro-Max 性能相当,但在更复杂、高难度的任务上仍然落后于其更大的对手。
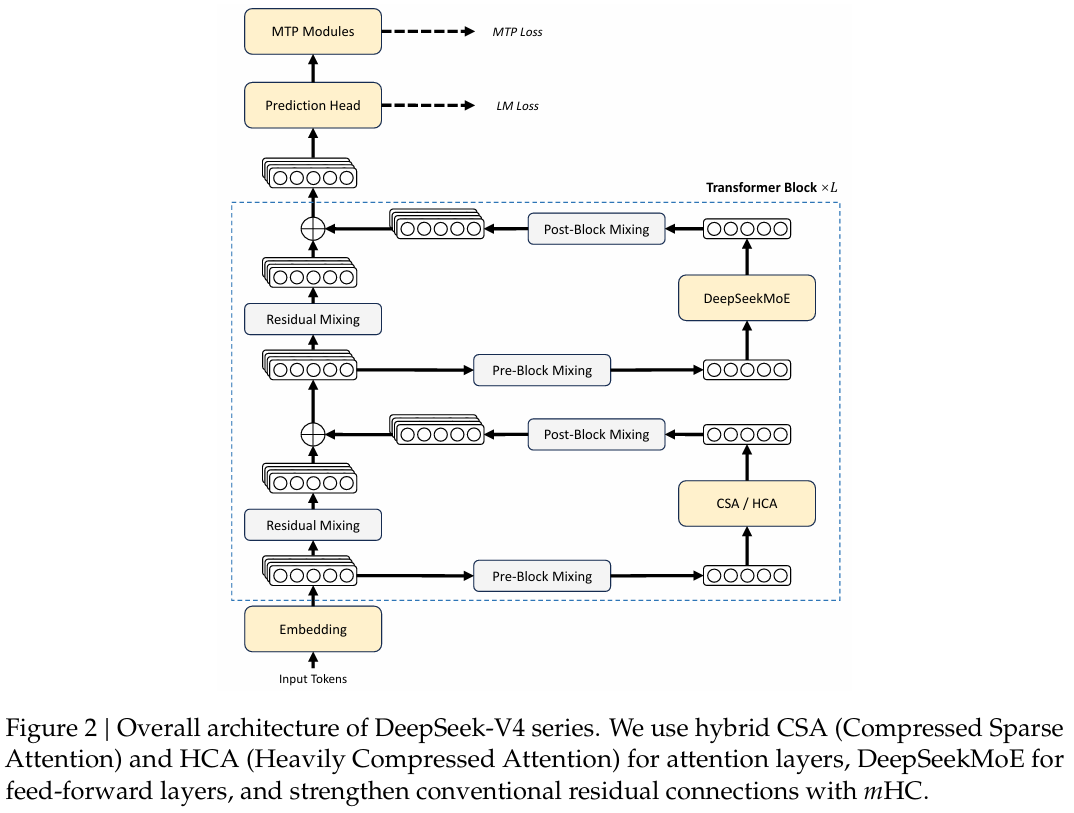
图 2 | DeepSeek-V4 系列的整体架构。我们在注意力层使用混合的 CSA(压缩稀疏注意力)和 HCA(重度压缩注意力),在前馈层使用 DeepSeekMoE,并通过 mHC 加强传统的残差连接。 ## 2. 架构
总的来说,DeepSeek-V4 系列保留了 Transformer(Vaswani 等人,2017)架构和多令牌预测(MTP)模块(DeepSeek-AI,2024;Gloeckle 等人,2024),同时引入了对 DeepSeek-V3 的若干关键升级:(1)首先,我们引入了流形约束超连接(mHC)(Xie 等人,2026)以加强传统的残差连接;
(2)其次,我们设计了一种混合注意力架构,通过压缩稀疏注意力和重度压缩注意力极大地提高了长上下文效率。
(3)第三,我们采用 Muon(Jordan 等人,2024;Liu 等人,2025)作为优化器。对于混合专家(MoE)组件,我们仍然采用 DeepSeekMoE(Dai 等人,2024)架构,仅对 DeepSeek-V3 进行了微小调整。多令牌预测(MTP)(DeepSeek-AI,2024;Gloeckle 等人,2024;Li 等人,2024;Qi 等人,2020)配置与 DeepSeek-V3 保持一致。所有其他未指定的细节遵循 DeepSeek-V3(DeepSeek-AI,2024)中建立的设置。图 2 展示了 DeepSeek-V4 的整体架构,细节描述如下。
2.1. 从 DeepSeek-V3 继承的设计
混合专家 。与之前的 DeepSeek 系列模型(DeepSeek-AI,2024;DeepSeek-AI,2024)一样,DeepSeek-V4 系列在前馈网络(FFN)中也采用了 DeepSeekMoE 范式(Dai 等人,2024),该范式设置了细粒度的路由专家和共享专家。与 DeepSeek-V3 不同,我们将计算亲和度分数的激活函数从 Sigmoid(⋅)(\cdot)(⋅) 改为 Sqrt(Softplus(⋅)(\cdot)(⋅))。对于负载均衡,我们也采用了无辅助损失策略(DeepSeek-AI,2024;Wang 等人,2024a),并辅以一个轻微的序列级均衡损失,以防止单个序列内的极端不平衡。对于 DeepSeek-V4,我们取消了对路由目标节点数量的限制,并仔细重新设计了并行策略以保持训练效率。此外,与 DeepSeek-V3 相比,我们将前几个 Transformer 块中的密集 FFN 层替换为使用哈希路由(Roller 等人,2021)的 MoE 层。哈希路由策略根据关于输入令牌 ID 的预定义哈希函数确定每个令牌的目标专家。
多令牌预测。与 DeepSeek-V3 一样,DeepSeek-V4 系列也设置了 MTP 模块和目标。鉴于 MTP 策略已在 DeepSeek-V3 中得到验证,我们对其不加修改地用于 DeepSeek-V4 系列。
2.2. 流形约束超连接
如图 2 所示,DeepSeek-V4 系列集成了流形约束超连接(mHC)(Xie 等人,2026),以加强相邻 Transformer 块之间的传统残差连接。与朴素的超连接(HC)(Zhu 等人,2025)相比,mHC 的核心思想是将残差映射约束到特定的流形上,从而增强跨层信号传播的稳定性,同时保持模型表达能力。本小节简要介绍标准的 HC,并描述我们如何设计用于稳定训练的 mHC。
标准超连接 。标准的 HC 将残差流的宽度扩展了 nhcn_{\mathrm{hc}}nhc 倍。具体来说,残差流的形状从 Rd\mathbb{R}^dRd 扩展到 Rnhc×d\mathbb{R}^{n_{\mathrm{hc}}\times d}Rnhc×d,其中 ddd 是实际层输入的隐藏大小。令 Xl=xl,1,...;xl,nhcT∈Rnhc×dX_{l} = \\mathbf{x}_{l,1},\\ldots ;\\mathbf{x}_{l,n_{\\mathrm{hc}}}^{T}\in \mathbb{R}^{n_{\mathrm{hc}}\times d}Xl=xl,1,...;xl,nhcT∈Rnhc×d 为第 lll 层之前的残差状态。HC 引入了三个线性映射:输入映射 Al∈R1×nhcA_{l}\in \mathbb{R}^{1\times n_{\mathrm{hc}}}Al∈R1×nhc,残差变换 Bl∈Rnhc×nhcB_{l}\in \mathbb{R}^{n_{\mathrm{hc}}\times n_{\mathrm{hc}}}Bl∈Rnhc×nhc,以及输出映射 Cl∈Rnhc×1C_{l}\in \mathbb{R}^{n_{\mathrm{hc}}\times 1}Cl∈Rnhc×1。残差状态的更新公式如下:
Xl+1=BlXl+ClFl(AlXl),(1)X_{l + 1} = B_{l}X_{l} + C_{l}\mathcal{F}{l}(A{l}X_{l}), \quad (1)Xl+1=BlXl+ClFl(AlXl),(1)
其中 Fl\mathcal{F}{l}Fl 表示第 lll 层(例如,一个 MoE 层),其输入和输出形状均为 Rd\mathbb{R}^dRd。注意,实际的层输入 AlXl∈RdA{l}X_{l}\in \mathbb{R}^{d}AlXl∈Rd 也是 ddd 维的,因此扩展的残差
===== 第 8 页 =====
宽度不会影响内层设计。HC 将残差宽度与实际隐藏大小解耦,提供了一个计算开销最小的互补缩放轴,因为 nhcn_{\mathrm{hc}}nhc 通常远小于隐藏大小 ddd。然而,尽管 HC 已被证明具有提升模型性能的潜力,但我们发现当堆叠多层时,训练经常会出现数值不稳定性,这阻碍了 HC 的扩展。
流形约束残差映射 。mHC 的核心创新是将残差映射矩阵 BlB_{l}Bl 约束到双随机矩阵(Birkhoff 多胞形)的流形 M\mathcal{M}M 上,从而增强跨层信号传播的稳定性:
Bl∈M≔{M∈Rn×n∣M1n=1n,1nTM=1nT,M⩾0}.(2)B_{l}\in \mathcal{M}\coloneqq \{M\in \mathbb{R}^{n\times n}\mid M\mathbf{1}{n} = \mathbf{1}{n},\mathbf{1}{n}^{T}M = \mathbf{1}{n}^{T},M\geqslant 0\} . \quad (2)Bl∈M:={M∈Rn×n∣M1n=1n,1nTM=1nT,M⩾0}.(2)
此约束确保了映射矩阵的谱范数 ∥Bl∥2\| B_{l}\|{2}∥Bl∥2 以 1 为界,因此残差变换是非扩张的,这增加了前向传播和反向传播过程中的数值稳定性。此外,集合 M\mathcal{M}M 在乘法下是封闭的,这保证了在深度堆叠 mHC 的场景下的稳定性。另外,输入变换 AlA{l}Al 和输出变换 ClC_{l}Cl 也被约束为非负的,并通过 Sigmoid 函数进行有界化,以避免信号抵消的风险。
动态参数化 。三个线性映射的参数是动态生成的,它们被分解为一个动态(输入相关)组件和一个静态(输入无关)组件。给定输入 Xl∈Rnhc×dX_{l}\in \mathbb{R}^{n_{\mathrm{hc}}\times d}Xl∈Rnhc×d,首先将其展平并归一化:X^l=RMSNorm(vec(Xl))∈R1×nhcd\hat{X}{l} = \mathrm{RMSNorm}(\mathrm{vec}(X{l}))\in \mathbb{R}^{1\times n_{\mathrm{hc}}d}X^l=RMSNorm(vec(Xl))∈R1×nhcd。然后,我们遵循传统的 HC 生成无约束的原始参数 A~l∈R1×nhc\tilde{A}{l}\in \mathbb{R}^{1\times n{\mathrm{hc}}}A~l∈R1×nhc,B~l∈Rnhc×nhc\tilde{B}{l}\in \mathbb{R}^{n{\mathrm{hc}}\times n_{\mathrm{hc}}}B~l∈Rnhc×nhc 和 C~l∈Rnhc×1\tilde{C}{l}\in \mathbb{R}^{n{\mathrm{hc}}\times 1}C~l∈Rnhc×1:
A~l=αlpre⋅(X^lWlpre)+Slpre,B~l=αlres⋅Mat(X^lWlres)+Slres,C~l=αlpost⋅(X^lWlpost)T+Slpost,(5)\begin{array}{rl} & {\tilde{A}{l} = \alpha{l}^{\mathrm{pre}}\cdot (\hat{X}{l}W{l}^{\mathrm{pre}}) + S_{l}^{\mathrm{pre}},}\\ & {\tilde{B}{l} = \alpha{l}^{\mathrm{res}}\cdot \mathrm{Mat}(\hat{X}{l}W{l}^{\mathrm{res}}) + S_{l}^{\mathrm{res}},}\\ & {\tilde{C}{l} = \alpha{l}^{\mathrm{post}}\cdot (\hat{X}{l}W{l}^{\mathrm{post}})^{T} + S_{l}^{\mathrm{post}},} \end{array} \quad (5)A~l=αlpre⋅(X^lWlpre)+Slpre,B~l=αlres⋅Mat(X^lWlres)+Slres,C~l=αlpost⋅(X^lWlpost)T+Slpost,(5)
其中 Wlpre,Wlpost∈Rnhcd×nhcW_{l}^{\mathrm{pre}},W_{l}^{\mathrm{post}}\in \mathbb{R}^{n_{\mathrm{hc}}d\times n_{\mathrm{hc}}}Wlpre,Wlpost∈Rnhcd×nhc 和 Wlres∈Rnhcd×nhc2W_{l}^{\mathrm{res}}\in \mathbb{R}^{n_{\mathrm{hc}}d\times n_{\mathrm{hc}}^{2}}Wlres∈Rnhcd×nhc2 是用于生成动态组件的可学习参数;Mat(⋅)\mathrm{Mat}(\cdot)Mat(⋅) 将大小为 1×nhc21\times n_{\mathrm{hc}}^{2}1×nhc2 的向量重塑为大小为 nhc×nhcn_{\mathrm{hc}}\times n_{\mathrm{hc}}nhc×nhc 的矩阵;Slpre∈R1×nhcS_{l}^{\mathrm{pre}}\in \mathbb{R}^{1\times n_{\mathrm{hc}}}Slpre∈R1×nhc,Slpost∈Rnhc×1S_{l}^{\mathrm{post}}\in \mathbb{R}^{n_{\mathrm{hc}}\times 1}Slpost∈Rnhc×1 和 Slres∈Rnhc×nhcS_{l}^{\mathrm{res}}\in \mathbb{R}^{n_{\mathrm{hc}}\times n_{\mathrm{hc}}}Slres∈Rnhc×nhc 是可学习的静态偏置;αlpre,αlres,αlpost∈R\alpha_{l}^{\mathrm{pre}},\alpha_{l}^{\mathrm{res}},\alpha_{l}^{\mathrm{post}}\in \mathbb{R}αlpre,αlres,αlpost∈R 是可学习的门控因子,初始化为小值。
应用参数约束 。在获得无约束原始参数 A~l,B~l,C~l\tilde{A}{l},\tilde{B}{l},\tilde{C}_{l}A~l,B~l,C~l 之后,我们对它们应用先前描述的约束以增强数值稳定性。具体来说,对于输入和输出映射,我们采用 Sigmoid 函数 σ(⋅)\sigma (\cdot)σ(⋅) 来确保它们的非负性和有界性:
Al=σ(A~l),Cl=2σ(C~l).(6)\begin{array}{r}A_{l} = \sigma (\tilde{A}{l}),\\ C{l} = 2\sigma (\tilde{C}_{l}). \end{array} \quad (6)Al=σ(A~l),Cl=2σ(C~l).(6)
至于残差映射 B~l\tilde{B}{l}B~l,我们将其投影到双随机矩阵流形 M\mathcal{M}M 上。这通过 Sinkhorn-Knopp 算法实现,该算法首先对 B~l\tilde{B}{l}B~l 应用指数函数以确保正性,得到 M(0)=exp(B~l)M^{(0)} = \exp (\tilde{B}_{l})M(0)=exp(B~l),然后迭代执行列和行归一化:
M(t)=Tr(Tc(M(t−1))),(8)M^{(t)} = \mathcal{T}{r}(\mathcal{T}{c}(M^{(t - 1)})), \quad (8)M(t)=Tr(Tc(M(t−1))),(8)
其中 Tr\mathcal{T}{r}Tr 和 Tc\mathcal{T}{c}Tc 分别表示行归一化和列归一化。此迭代收敛到一个受约束的双随机矩阵 Bl=M(tmax)B_{l} = M^{(t_{\mathrm{max}})}Bl=M(tmax)。我们选择 tmax=20t_{\mathrm{max}} = 20tmax=20 作为实际值。
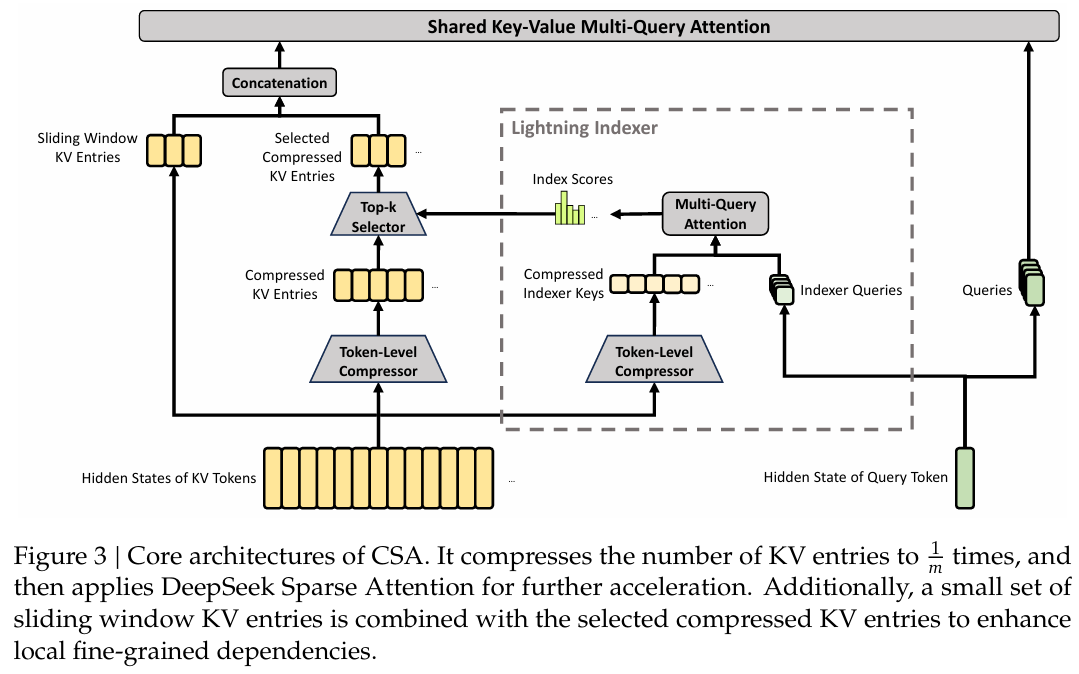
图 3 | CSA 的核心架构。它将 KV 条目数量压缩到原来的 \\frac{1}{m},然后应用 DeepSeek 稀疏注意力进行进一步加速。此外,一小部分滑动窗口 KV 条目与选定的压缩 KV 条目结合,以增强局部细粒度依赖关系。
2.3. 结合 CSA 和 HCA 的混合注意力
当上下文长度达到极端规模时,注意力机制成为模型中的主要计算瓶颈。对于 DeepSeek-V4,我们设计了两种高效的注意力架构------压缩稀疏注意力(CSA)和重度压缩注意力(HCA)------并采用它们的交错混合配置,这显著降低了长文本场景中注意力的计算成本。CSA 结合了压缩和稀疏注意力策略:它首先将每 mmm 个令牌的键值(KV)缓存压缩为一个条目,然后应用 DeepSeek 稀疏注意力(DSA)(DeepSeek-AI,2025),其中每个查询令牌仅关注 kkk 个压缩的 KV 条目。HCA 旨在通过将每 m′m'm′(≫m\gg m≫m)个令牌的 KV 缓存合并为一个条目来实现极端压缩。CSA 和 HCA 的混合架构显著提高了 DeepSeek-V4 系列的长上下文效率,使百万令牌上下文在实践中成为可能。本小节描述我们混合注意力架构的核心技术,并且我们还提供了一个开源实现1 以明确指定更多细节。
2.3.1. 压缩稀疏注意力
CSA 的核心架构如图 3 所示,它首先将每 mmm 个令牌的 KV 缓存压缩为一个条目,然后应用 DeepSeek 稀疏注意力进行进一步加速。
压缩的键值条目 。令 H∈Rn×dH \in \mathbb{R}^{n \times d}H∈Rn×d 为输入隐藏状态序列,其中 nnn 是序列长度,ddd 是隐藏大小。CSA 首先计算两个系列的 KV 条目 Ca,Cb∈Rn×cC^a, C^b \in \mathbb{R}^{n \times c}Ca,Cb∈Rn×c 及其对应的压缩权重 Za,Zb∈Rn×cZ^a, Z^b \in \mathbb{R}^{n \times c}Za,Zb∈Rn×c,其中 ccc 是头维度:
Ca=H⋅WaKV,Cb=H⋅WbKV,Za=H⋅WaZ,Zb=H⋅WbZ,(9)\begin{array}{rcl}{C^a = H\cdot W^{aKV},} & {C^b = H\cdot W^{bKV},}\\ {Z^a = H\cdot W^{aZ},} & {Z^b = H\cdot W^{bZ},} \end{array} \quad (9)Ca=H⋅WaKV,Za=H⋅WaZ,Cb=H⋅WbKV,Zb=H⋅WbZ,(9)
其中 WaKV,WbKV,WaZ,WbZ∈Rd×cW^{aKV},W^{bKV},W^{aZ},W^{bZ}\in \mathbb{R}^{d\times c}WaKV,WbKV,WaZ,WbZ∈Rd×c 是可训练参数。接下来,CaC^aCa 和 CbC^bCb 中的每 mmm 个 KV 条目将根据其压缩权重和可学习的位置偏置 Ba,Bb∈Rm×cB^a,B^b\in \mathbb{R}^{m\times c}Ba,Bb∈Rm×c 被压缩成一个条目,产生 CComp∈Rnm×cC^{\mathrm{Comp}}\in \mathbb{R}^{\frac{n}{m}\times c}CComp∈Rmn×c。每个压缩条目 CiComp∈RcC_i^{\mathrm{Comp}}\in \mathbb{R}^cCiComp∈Rc 通过下式计算:
Smi:m(i+1)−1a,Sm(i−1):mi−1b=Softmaxrow({Zmi:m(i+1)−1a+Ba;Zm(i−1):mi−1b+Bb}),CiComp=∑j=mim(i+1)−1Sja⊙Cja+∑j=m(i−1)mi−1Sjb⊙Cjb,(12)\begin{array}{r l} & {S_{m i:m(i + 1) - 1}\^{a},S_{m(i - 1):m i - 1}\^{b} = \mathrm{Softmax}{\mathrm{row}}(\{Z{m i:m(i + 1) - 1}^{a} + B^{a};Z_{m(i - 1):m i - 1}^{b} + B^{b}\}),}\\ & {\qquad C_{i}^{\mathrm{Comp}} = \sum_{j = m i}^{m(i + 1) - 1}S_{j}^{a}\odot C_{j}^{a} + \sum_{j = m(i - 1)}^{m i - 1}S_{j}^{b}\odot C_{j}^{b},} \end{array} \quad (12)Smi:m(i+1)−1a,Sm(i−1):mi−1b=Softmaxrow({Zmi:m(i+1)−1a+Ba;Zm(i−1):mi−1b+Bb}),CiComp=∑j=mim(i+1)−1Sja⊙Cja+∑j=m(i−1)mi−1Sjb⊙Cjb,(12)
其中 ⊙\odot⊙ 表示哈达玛积;Softmaxrow(⋅)\mathrm{Softmax}{\mathrm{row}}(\cdot)Softmaxrow(⋅) 表示沿行维度的 softmax 操作,它对来自 ZaZ^aZa 和 ZbZ^bZb 的总共 2m2m2m 个元素进行归一化。当 i=0i = 0i=0 时,Zm(i−1):mi−1bZ{m(i - 1):m i - 1}^{b}Zm(i−1):mi−1b 用负无穷填充,Cm(i−1):mi−1bC_{m(i - 1):m i - 1}^{b}Cm(i−1):mi−1b 用零填充。注意,每个 CiCompC_i^{\mathrm{Comp}}CiComp 来自 2m2m2m 个 KV 条目,但用于 CiCompC_i^{\mathrm{Comp}}CiComp 的 CbC^bCb 索引和用于 Ci−1CompC_{i - 1}^{\mathrm{Comp}}Ci−1Comp 的 CaC^aCa 索引是重叠的。因此,CSA 实际上将序列长度压缩到了原来的 1m\frac{1}{m}m1。
用于稀疏选择的闪电索引器 。获得压缩的 KV 条目 CCompC^{\mathrm{Comp}}CComp 后,CSA 应用 DSA 策略为每个注意力核心选择 top-kkk 个压缩 KV 条目。首先,CSA 执行与用于 CCompC^{\mathrm{Comp}}CComp 相同的压缩操作,以获得压缩的索引器键 KComp∈Rnm×clK^{\mathrm{Comp}}\in \mathbb{R}^{\frac{n}{m}\times c^l}KComp∈Rmn×cl,其中 clc^lcl 是索引器头维度。然后,对于查询令牌 ttt,我们以低秩方式生成索引器查询 {qt,1l;qt,2l;... ;qt,nhll}\{\mathbf{q}{t,1}^{l};\mathbf{q}{t,2}^{l};\dots;\mathbf{q}{t,n{h}^{l}}^{l}\}{qt,1l;qt,2l;...;qt,nhll}:
ctQ=ht⋅WDQ,qtI;qt,2I;... ;qt,nhII=qtI=ctQ⋅WIUQ,(14)\begin{array}{r}\mathbf{c}_t^Q = \mathbf{h}t\cdot W^{DQ},\\ \mathbf{q}t^I;\mathbf{q}{t,2}^I;\dots;\mathbf{q}{t,n_h^I}^I = \mathbf{q}_t^I = \mathbf{c}_t^Q\cdot W^{IUQ}, \end{array} \quad (14)ctQ=ht⋅WDQ,qtI;qt,2I;...;qt,nhII=qtI=ctQ⋅WIUQ,(14)
其中 ht∈Rd\mathbf{h}_t\in \mathbb{R}^dht∈Rd 是查询令牌 ttt 的输入隐藏状态;ctQ∈Rdc\mathbf{c}t^Q\in \mathbb{R}^{d_c}ctQ∈Rdc 是查询的压缩潜在向量;dcd_cdc 表示查询压缩维度;nhIn_h^InhI 表示索引器查询头的数量;WDQ∈Rd×dcW^{DQ}\in \mathbb{R}^{d\times d_c}WDQ∈Rd×dc 和 WIUQ∈Rdc×clnhIW^{IUQ}\in \mathbb{R}^{d_c\times c^l n_h^I}WIUQ∈Rdc×clnhI 分别是索引器查询的下投影和上投影矩阵。接下来,查询令牌 ttt 和前面的压缩块 sss(s<Floor(tm)s< \mathrm{Floor}(\frac{t}{m})s<Floor(mt))之间的索引分数 It,s∈RI{t,s}\in \mathbb{R}It,s∈R 通过下式计算:
wt,1I;wt,2I;... ;wt,nhII=wtI=ht⋅Ww,It,s=∑h=1nhIwt,hI⋅ReLU(qt,hI⋅KsComp),(16)\begin{array}{r l} & {w_{t,1}\^{I};w_{t,2}\^{I};\\dots ;w_{t,n_{h}\^{I}}\^{I} = \mathbf{w}{t}^{I} = \mathbf{h}{t}\cdot W^{w},}\\ & {\qquad I_{t,s} = \sum_{h = 1}^{n_{h}^{I}}w_{t,h}^{I}\cdot \mathrm{ReLU}\left(\mathbf{q}{t,h}^{I}\cdot K{s}^{\mathrm{Comp}}\right),} \end{array} \quad (16)wt,1I;wt,2I;...;wt,nhII=wtI=ht⋅Ww,It,s=∑h=1nhIwt,hI⋅ReLU(qt,hI⋅KsComp),(16)
其中 Ww∈Rd×nhIW^{w}\in \mathbb{R}^{d\times n_h^I}Ww∈Rd×nhI 是一个可学习矩阵;wt,hI∈Rw_{t,h}^{I}\in \mathbb{R}wt,hI∈R 是第 hhh 个索引器头的权重。对于查询令牌 ttt,给定其索引分数 It,sI_{t,s}It,s,我们采用一个 top-kkk 选择器来选择性地保留一部分压缩 KV 条目 CtSprsCompC_t^{\mathrm{SprsComp}}CtSprsComp 用于随后的核心注意力:
CtSprsComp={CsComp∣It,s∈Top−k(It,s)}.(17)C_t^{\mathrm{SprsComp}} = \left\{C_s^{\mathrm{Comp}}\mid I_{t,s}\in \mathrm{Top - k}(I_{t,s})\right\} . \quad (17)CtSprsComp={CsComp∣It,s∈Top−k(It,s)}.(17)
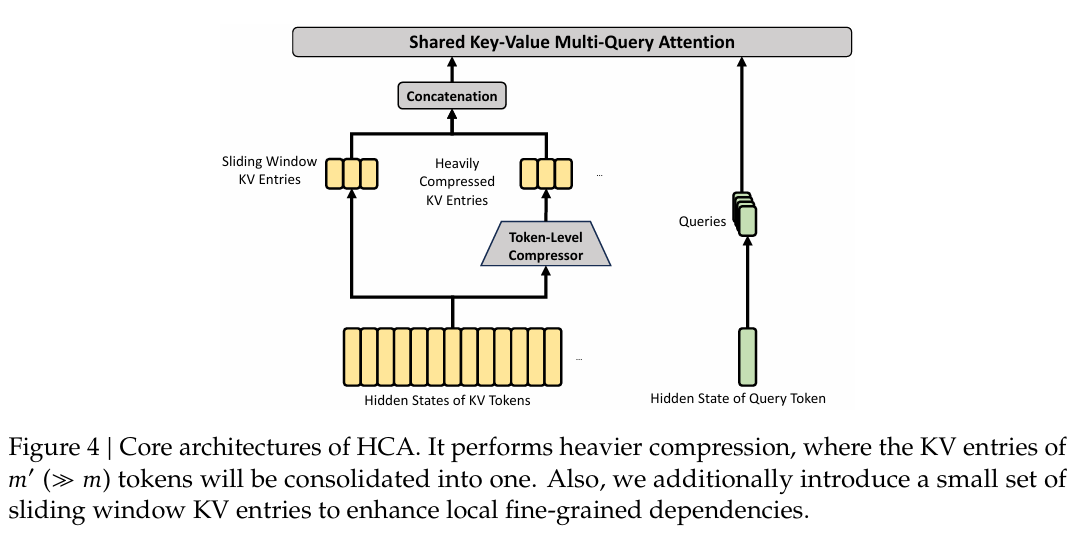
图 4 | HCA 的核心架构。它执行更重的压缩,其中 m\^{\\prime}(\\gg m)个令牌的 KV 条目将被合并为一个。此外,我们额外引入了一小部分滑动窗口 KV 条目来增强局部细粒度依赖关系。
共享键值 MQA 。选择稀疏 KV 条目后,CSA 然后以多查询注意力(MQA)(Shazeer,2019)的方式执行核心注意力,其中 CtSprsCompC_{t}^{\mathrm{SprsComp}}CtSprsComp 中的每个压缩 KV 条目同时作为注意力键和值。具体来说,对于查询令牌 ttt,我们首先从压缩潜在向量 ctQ\mathbf{c}t^QctQ 生成注意力查询 {qt,1;qt,2;... ;qt,nh}\{\mathbf{q}{t,1}; \mathbf{q}{t,2}; \dots ; \mathbf{q}{t,n_h}\}{qt,1;qt,2;...;qt,nh}:
qt,1;qt,2;... ;qt,nh=qt=ctQ⋅WUQ,(18)\\mathbf{q}_{t,1}; \\mathbf{q}_{t,2}; \\dots ; \\mathbf{q}_{t,n_h} = \mathbf{q}_t = \mathbf{c}_t^Q \cdot W^{UQ}, \quad (18)qt,1;qt,2;...;qt,nh=qt=ctQ⋅WUQ,(18)
其中 nhn_hnh 表示查询头的数量;WUQ∈Rdc×cnhW^{UQ} \in \mathbb{R}^{d_c \times cn_h}WUQ∈Rdc×cnh 是查询的上投影矩阵。注意,潜在查询向量 ctQ\mathbf{c}t^QctQ 与用于索引器查询的向量共享。接下来,我们在 {qt,i}\{\mathbf{q}{t,i}\}{qt,i} 和 CtSprsCompC_{t}^{\mathrm{SprsComp}}CtSprsComp 上执行 MQA:
ot,i=CoreAttn(qquery=qt,i,key=CtSprsComp,value=CtSprsComp),(19)\mathbf{o}{t,i} = \mathrm{CoreAttn}\left(\mathbf{q}{\mathrm{query}} = \mathbf{q}{t,i},\mathbf{key} = C{t}^{\mathrm{SprsComp}},\mathrm{value} = C_{t}^{\mathrm{SprsComp}}\right), \quad (19)ot,i=CoreAttn(qquery=qt,i,key=CtSprsComp,value=CtSprsComp),(19)
其中 ot,i∈Rc\mathbf{o}_{t,i} \in \mathbb{R}^cot,i∈Rc 是第 ttt 个令牌的第 iii 个头的核心注意力输出;CoreAttn(⋅)\mathrm{CoreAttn}(\cdot)CoreAttn(⋅) 表示核心注意力操作。
分组输出投影 。在 DeepSeek-V4 的配置中,cnhcn_hcnh 非常大。因此,直接将核心注意力操作的输出 ot,1;ot,2;... ;ot,nh=ot∈Rcnh\\mathbf{o}_{t,1}; \\mathbf{o}_{t,2}; \\dots ; \\mathbf{o}_{t,n_h} = \mathbf{o}t \in \mathbb{R}^{cn_h}ot,1;ot,2;...;ot,nh=ot∈Rcnh 投影到 ddd 维隐藏状态将带来巨大的计算负担。为了减轻这种成本,我们设计了一种分组输出投影策略。具体来说,我们首先将 nhn_hnh 个输出分成 ggg 组,然后对于每组输出 ot,iG∈Rcnhg\mathbf{o}{t,i}^G \in \mathbb{R}^{c \frac{n_h}{g}}ot,iG∈Rcgnh,我们将其投影到一个 dgd_gdg 维的中间输出 ot,iG′∈Rdg\mathbf{o}_{t,i}^{G'} \in \mathbb{R}^{d_g}ot,iG′∈Rdg,其中 dg<cnhgd_g < c \frac{n_h}{g}dg<cgnh。最后,我们将中间输出 ot,1G′;ot,2G′;... ;ot,gG′∈Rdgg\\mathbf{o}_{t,1}\^{G'};\\mathbf{o}_{t,2}\^{G'};\\dots;\\mathbf{o}_{t,g}\^{G'} \in \mathbb{R}^{d_g g}ot,1G′;ot,2G′;...;ot,gG′∈Rdgg 投影到最终的注意力输出 o^t∈Rd\hat{\mathbf{o}}_t \in \mathbb{R}^do^t∈Rd。
2.3.2. 重度压缩注意力
HCA 的核心架构如图 4 所示,它以更重的方式压缩 KV 缓存,但不采用稀疏注意力。
压缩的键值条目 。总的来说,HCA 的压缩策略与 CSA 相似,但采用了更大的压缩率 m′m'm′(≫m\gg m≫m)并且不执行重叠
===== 第 12 页 =====
压缩。令 H∈Rn×dH\in \mathbb{R}^{n\times d}H∈Rn×d 为输入隐藏状态序列,HCA 首先计算原始 KV 条目 C∈Rn×cC\in \mathbb{R}^{n\times c}C∈Rn×c 及其对应的压缩权重 Z∈Rn×cZ\in \mathbb{R}^{n\times c}Z∈Rn×c。
C=H⋅WKV,Z=H⋅WZ,(20)\begin{array}{r}C = H\cdot W^{KV},\\ Z = H\cdot W^Z, \end{array} \quad (20)C=H⋅WKV,Z=H⋅WZ,(20)
其中 WKV,WZ∈Rd×cW^{KV},W^{Z}\in \mathbb{R}^{d\times c}WKV,WZ∈Rd×c 是可训练参数。接下来,CCC 中的每 m′m^{\prime}m′ 个 KV 条目将根据压缩权重和可学习的位置偏置 B∈Rm′×cB\in \mathbb{R}^{m^{\prime}\times c}B∈Rm′×c 被压缩成一个条目,产生 CComp∈Rnm′×cC^{\mathrm{Comp}}\in \mathbb{R}^{\frac{n}{m^{\prime}}\times c}CComp∈Rm′n×c。每个压缩条目 CiComp∈RcC_{i}^{\mathrm{Comp}}\in \mathbb{R}^{c}CiComp∈Rc 通过下式计算:
Sm′i:m′(i+1)−1=SoftmaxKrow(Zm′i:m′(i+1)−1+B),CiComp=∑j=m′im′(i+1)−1Sj⊙Cj.(22)\begin{array}{r}S_{m^{\prime}i:m^{\prime}(i + 1) - 1} = \mathrm{Softmax}{\mathrm{Krow}}(Z{m^{\prime}i:m^{\prime}(i + 1) - 1} + B),\\ C_{i}^{\mathrm{Comp}} = \sum_{j = m^{\prime}i}^{m^{\prime}(i + 1) - 1}S_{j}\odot C_{j}. \end{array} \quad (22)Sm′i:m′(i+1)−1=SoftmaxKrow(Zm′i:m′(i+1)−1+B),CiComp=∑j=m′im′(i+1)−1Sj⊙Cj.(22)
通过这种压缩操作,HCA 将序列长度压缩到了原来的 1m′\frac{1}{m^{\prime}}m′1。
共享键值 MQA 和分组输出投影 。HCA 也采用了与 CSA 相同的共享 KV MQA 和分组输出投影策略。在 KV 压缩之后,对于查询令牌 ttt,HCA 首先以低秩方式生成注意力查询 {qt,1;qt,2;... ;qt,nh}\{\mathbf{q}{t,1}; \mathbf{q}{t,2}; \dots ; \mathbf{q}_{t,n_h}\}{qt,1;qt,2;...;qt,nh}:
ctQ=ht⋅WDQ,qt,1;qt,2;... ;qt,nh=qt=ctQ⋅WUQ,(25)\begin{array}{r}\mathbf{c}_t^Q = \mathbf{h}_t\cdot W^{DQ},\\ \\mathbf{q}_{t,1}; \\mathbf{q}_{t,2}; \\dots ; \\mathbf{q}_{t,n_h} = \mathbf{q}_t = \mathbf{c}_t^Q\cdot W^{UQ}, \end{array} \quad (25)ctQ=ht⋅WDQ,qt,1;qt,2;...;qt,nh=qt=ctQ⋅WUQ,(25)
其中 ht∈Rd\mathbf{h}t\in \mathbb{R}^dht∈Rd 是查询令牌 ttt 的输入隐藏状态;nhn_hnh 表示查询头的数量;WDQ∈Rd×dcW^{DQ}\in \mathbb{R}^{d\times d_c}WDQ∈Rd×dc 和 WUQ∈Rdc×cnhW^{UQ}\in \mathbb{R}^{d_c\times cn_h}WUQ∈Rdc×cnh 分别是查询的下投影和上投影矩阵。接下来,我们在 {qt,i}\{\mathbf{q}{t,i}\}{qt,i} 和 CCompC^{\mathrm{Comp}}CComp 上执行 MQA。
ot,i=CoreAttn(query=qt,i,key=CComp,value=CComp),(26)\mathbf{o}{t,i} = \mathrm{CoreAttn}\left(\mathrm{query} = \mathbf{q}{t,i},\mathrm{key} = C^{\mathrm{Comp}},\mathrm{value} = C^{\mathrm{Comp}}\right), \quad (26)ot,i=CoreAttn(query=qt,i,key=CComp,value=CComp),(26)
其中 ot,i∈Rc\mathbf{o}{t,i}\in \mathbb{R}^cot,i∈Rc 是第 ttt 个令牌的第 iii 个头的核心注意力输出。接下来,像 CSA 一样,HCA 将 nhn_hnh 个输出分成 ggg 组,对于每组输出 ot,iG∈Rnhg\mathbf{o}{t,i}^G\in \mathbb{R}^{\frac{n_h}{g}}ot,iG∈Rgnh,HCA 将其投影到一个 dgd_gdg 维的中间输出 ot,iG′∈Rdg\mathbf{o}_{t,i}^{G^{\prime}}\in \mathbb{R}^{d_g}ot,iG′∈Rdg,其中 dg<cnhgd_g< c\frac{n_h}{g}dg<cgnh。最后,HCA 将中间输出 ot,iG′;ot,iG′;... ;ot,gG′∈Rdgg\\mathbf{o}_{t,i}\^{G\^{\\prime}};\\mathbf{o}_{t,i}\^{G\^{\\prime}};\\dots;\\mathbf{o}_{t,g}\^{G\^{\\prime}}\in \mathbb{R}^{d_g g}ot,iG′;ot,iG′;...;ot,gG′∈Rdgg 投影到最终的注意力输出 o^t∈Rd\hat{\mathbf{o}}_t\in \mathbb{R}^do^t∈Rd。
2.3.3. 其他细节
除了上述 CSA 和 HCA 的核心架构外,我们的混合注意力还包含其他几种技术。为了写作清晰,我们在上述介绍中省略了这些附加技术,并将在本小节中简要描述。此外,本小节仅关注它们的核心思想,为简洁起见可能省略一些微小的细节。我们鼓励读者参考我们的开源实现以获取明确的细节。
查询和键值条目归一化。对于 CSA 和 HCA,在核心注意力操作之前,我们对查询的每个头和压缩 KV 条目的唯一头执行额外的 RMSNorm 操作。这种归一化可以避免注意力 logits 爆炸,并可能提高训练稳定性。
部分旋转位置嵌入 。对于 CSA 和 HCA,我们部分地将旋转位置嵌入(RoPE)(Su 等人,2024)应用于注意力查询、KV 条目和核心注意力输出。具体来说,对于 CSA 和 HCA 中使用的每个查询向量和 KV 条目向量,我们将其最后 64 维应用 RoPE。由于 KV 条目同时作为注意力的键和值,朴素的核心注意力输出 {ot,i}\{\mathbf{o}{t,i}\}{ot,i} 将携带绝对位置嵌入,这些嵌入来自 KV 条目的加权和。作为对策,我们还在每个 ot,i\mathbf{o}{t,i}ot,i 的最后 64 维上应用位置为 −i- i−i 的 RoPE。这样,核心注意力的输出也将携带相对位置嵌入------每个 KV 条目对核心注意力输出的贡献也将与查询和 KV 条目之间的距离相关。
滑动窗口注意力的附加分支 。为了在 CSA 和 HCA 中严格保持因果性,每个查询只关注前面的压缩 KV 块。因此,查询无法访问其自身压缩块内其他令牌的信息。同时,在语言建模中,最近的令牌通常与查询令牌具有更大的相关性。出于这些原因,我们以滑动窗口的方式为 CSA 和 HCA 引入了一个补充的注意力分支,以更好地建模局部依赖关系。具体来说,对于每个查询令牌,我们额外生成对应于最近 nwinn_{\mathrm{win}}nwin 个令牌的 nwinn_{\mathrm{win}}nwin 个未压缩 KV 条目。在 CSA 和 HCA 的核心注意力中,这些滑动窗口中的 KV 条目将与压缩的 KV 条目一起使用。
注意力汇聚 。在 CSA 和 HCA 的核心注意力中,我们采用了注意力汇聚的技巧(OpenAI,2025;Xiao 等人,2024)。具体来说,我们设置了一系列可学习的汇聚 logits {z1′,z2′,...,znh′}\{z_{1}^{\prime},z_{2}^{\prime},\dots,z_{n_{h}}^{\prime}\}{z1′,z2′,...,znh′}。对于第 hhh 个注意力头,Exp(zh′)\mathrm{Exp}(z_{h}^{\prime})Exp(zh′) 将被加到注意力分数的分母中:
sh,i,j=Exp(zh,i,j)∑kExp(zh,i,k)+Exp(zh′),(27)s_{h,i,j} = \frac{\mathrm{Exp}(z_{h,i,j})}{\sum_{k}\mathrm{Exp}(z_{h,i,k}) + \mathrm{Exp}(z_{h}^{\prime})}, \quad (27)sh,i,j=∑kExp(zh,i,k)+Exp(zh′)Exp(zh,i,j),(27)
其中 sh,i,j,zh,i,j∈Rs_{h,i,j},z_{h,i,j}\in \mathbb{R}sh,i,j,zh,i,j∈R 表示第 hhh 个注意力头在第 iii 个查询令牌和第 jjj 个前面的令牌或压缩块之间的注意力分数和注意力 logits。这种技术允许每个查询头调整其总注意力分数不等于 1,甚至接近于 0。
2.3.4. 效率讨论
由于采用了混合的 CSA 和 HCA,以及低精度计算和存储,DeepSeek-V4 系列的注意力模块在注意力 FLOPs 和 KV 缓存大小方面实现了显著的效率,尤其是在长上下文场景中。首先,我们对 KV 条目采用混合存储格式:旋转位置嵌入(RoPE)维度使用 BF16 精度,而其余维度使用 FP8 精度。与纯 BF16 存储相比,这种混合表示将 KV 缓存大小减少了近一半。其次,闪电索引器内的注意力计算以 FP4 精度执行,这在极长上下文下加速了注意力操作。第三,相对于 DeepSeek-V3.2,在 DeepSeek-V4 系列中选择了更小的注意力 top-kkk,从而提高了模型在短文本和中长文本上的效率。最后,也是最重要的,压缩注意力和混合注意力技术显著减少了 KV 缓存大小和计算 FLOPs。
以 BF16 GQA8(Ainslie 等人,2023)且头维度为 128 作为基线------这是 LLM 注意力常见的配置之一------在 1M 上下文设置下,DeepSeek-V4 系列的 KV 缓存大小可以 dramatically reduced to approximately 2%2\%2% times of that baseline。
1: 对于每个训练步骤 $t$ 执行
2: 对于每个逻辑上独立的权重 $W \in \mathbb{R}^{n \times m}$ 执行
3: $G_{t} = \nabla_{W} \mathcal{L}_{t}(W_{t - 1})$ // 计算梯度
4: $M_{t} = \mu M_{t - 1} + G_{t}$ // 累积动量缓冲区
5: $O_{t}^{\prime} = \text{HybridNewtonSchulz}(\mu M_{t} + G_{t})$ // Nesterov 技巧和混合 Newton-Schulz
6: $O_{t} = O_{t}^{\prime} \cdot \sqrt{\max(n, m)} \cdot \gamma$ // 重缩放更新矩阵的 RMS
7: $W_{t} = W_{t - 1} \cdot (1 - \eta \lambda) - \eta O_{t}$ // 执行权重衰减并更新
8: 结束
9: 结束此外,即使与已经是高效基线的 DeepSeek-V3.2(DeepSeek-AI,2025)相比,DeepSeek-V4 系列在效率上仍显示出显著优势。它们的推理 FLOPs 和 KV 缓存大小的比较见图 1 的右侧部分。
2.4. Muon 优化器
由于 Muon(Jordan 等人,2024;Liu 等人,2025)优化器具有更快的收敛速度和更高的训练稳定性,我们将其用于 DeepSeek-V4 系列中的大部分模块。我们的 Muon 优化算法的完整内容总结在算法 1 中。
基本配置。我们为嵌入模块、预测头模块、mHC 模块的静态偏置和门控因子以及所有 RMSNorm 模块的权重保留 AdamW(Loshchilov and Hutter,2017)优化器。所有其他模块都使用 Muon 更新。遵循 Liu 等人(2025)的方法,我们也对 Muon 参数应用权重衰减,使用 Nesterov(Jordan 等人,2024;Nesterov,1983)技巧,并重缩放更新矩阵的根均方(RMS)以重用我们的 AdamW 超参数。与它们不同的是,我们使用混合 Newton-Schulz 迭代进行正交化。
混合 Newton-Schulz 迭代 。对于给定矩阵 MMM,令其奇异值分解(SVD)为 M=UΣVTM = U \Sigma V^{T}M=UΣVT。Newton-Schulz 迭代旨在将 MMM 近似正交化为 UVTUV^{T}UVT。通常,MMM 将首先被归一化为 M0=M/∣∣M∣∣FM_{0} = M / ||M||_{F}M0=M/∣∣M∣∣F,以确保其最大奇异值不超过 1。然后,每次 Newton-Schulz 迭代执行以下操作:
Mk=aMk−1+b(Mk−1Mk−1T)Mk−1+c(Mk−1Mk−1T)2Mk−1.(28)M_{k} = a M_{k - 1} + b(M_{k - 1}M_{k - 1}^{T})M_{k - 1} + c(M_{k - 1}M_{k - 1}^{T})^{2}M_{k - 1}. \quad (28)Mk=aMk−1+b(Mk−1Mk−1T)Mk−1+c(Mk−1Mk−1T)2Mk−1.(28)
我们的混合 Newton-Schulz 在两个不同阶段执行 10 次迭代。在前 8 步中,我们使用系数 (a,b,c)=(3.4445,−4.7750,2.0315)(a, b, c) = (3.4445, - 4.7750, 2.0315)(a,b,c)=(3.4445,−4.7750,2.0315) 以驱动快速收敛,使奇异值接近 1。在最后 2 步中,我们切换到系数 (a,b,c)=(2,−1.5,0.5)(a, b, c) = (2, - 1.5, 0.5)(a,b,c)=(2,−1.5,0.5),这将奇异值精确地稳定在 1。
避免注意力 Logits 爆炸。DeepSeek-V4 系列的注意力架构允许我们直接将 RMSNorm 应用于注意力查询和 KV 条目,这有效地防止了注意力 logits 爆炸。因此,我们在 Muon 优化器中不采用 QK-Clip 技术(Liu 等人,2025)。
3. 通用基础设施

图 5 | 我们与相关工作的 EP 方案示意图。Comet(Zhang 等人,2025b)将 Dispatch 与 Linear-1 重叠,并将 Linear-2 与 Combine 分别重叠。我们的 EP 方案通过将专家分割并调度成 wave,实现了更细粒度的重叠。理论加速比是在 DeepSeek-V4-Flash 架构的配置下评估的。 ### 3.1. 专家并行中的细粒度通信-计算重叠
混合专家(MoE)可以通过专家并行(EP)加速。然而,EP 需要复杂的节点间通信,并对互连带宽和延迟提出了很高的要求。为了缓解 EP 中的通信瓶颈并在较低的互连带宽需求下实现更高的端到端性能,我们提出了一种细粒度的 EP 方案,该方案将通信和计算融合到一个单一的流水线核函数中,以实现通信-计算重叠。
通信延迟可以被隐藏。我们 EP 方案的关键洞见是,在 MoE 层中,通信延迟可以有效地隐藏在计算之下。如图 5 所示,在 DeepSeek-V4 系列中,每个 MoE 层主要可以分解为四个阶段:两个通信受限阶段(Dispatch 和 Combine),以及两个计算受限阶段(Linear-1 和 Linear-2)。我们的性能分析显示,在单个 MoE 层内,通信总时间小于计算总时间。因此,在将通信和计算融合到一个统一的流水线之后,计算仍然是主要的瓶颈,这意味着系统可以容忍较低的互连带宽而不会降低端到端性能。
细粒度 EP 方案。为了进一步降低互连带宽需求并放大重叠的好处,我们引入了一种更细粒度的专家划分方案。受许多相关工作(Aimuyo 等人,2025;Zhang 等人,2025b)的启发,我们将专家分割并调度成 wave。每个 wave 由一小部分专家组成。一旦 wave 中的所有专家完成其通信,计算就可以立即开始,而无需等待其他专家。在稳定状态下,当前 wave 的计算、下一个 wave 的令牌传输以及已完成专家的结果发送都同时进行,如图 5 所示。这在专家之间形成了一个细粒度的流水线,使整个 wave 过程中的计算和通信保持连续。基于 wave 的调度加速了在极端情况下的性能,例如强化学习(RL)rollout,这通常会遇到长尾小批量。
性能与开源 Mega-Kernel 。我们在 NVIDIA GPU 和华为昇腾 NPU 平台上验证了细粒度 EP 方案。与强大的非融合基线相比,它在一般推理工作负载上实现了 1.50∼1.73×1.50 \sim 1.73 \times1.50∼1.73× 的加速,在 RL rollout 和高速智能体服务等延迟敏感场景下实现了高达 1.96×1.96 \times1.96× 的加速。我们已经开源了基于 CUDA 的 mega-kernel 实现,名为 MegaMoE 2^22,作为 DeepGEMM 的一个组件。
观察与建议。我们分享内核开发中的观察和经验,并向硬件供应商提出一些建议,希望能有助于高效的硬件设计并实现更好的软硬件协同设计:
- 计算-通信比 。完全的通信-计算重叠取决于计算-通信比,而不仅仅是带宽。设峰值计算吞吐量为 CCC,互连带宽为 BBB,当 C/B≪Vcomp/VcommC / B \ll V_{\mathrm{comp}} / V_{\mathrm{comm}}C/B≪Vcomp/Vcomm 时,通信可以被完全隐藏,其中 VcompV_{\mathrm{comp}}Vcomp 表示计算量,VcommV_{\mathrm{comm}}Vcomm 表示通信量。对于 DeepSeek-V4-Pro,每个令牌-专家对需要 6hd FLOPs(SwiGLU 门控、上投影和下投影),但只需要 3h 字节的通信(FP8 Dispatch + BF16 Combine),这简化为:
CB⩽2d=6144FLOPs/Byte.\frac{C}{B}\leqslant 2d = 6144\mathrm{FLOPs / Byte}.BC⩽2d=6144FLOPs/Byte.
也就是说,每 GBps 的互连带宽足以隐藏 6.1 TFLOP/s 的计算。一旦带宽达到这个阈值,它就不再是瓶颈,将额外的硅片面积用于进一步提高带宽会带来递减的回报。我们鼓励未来的硬件设计以此类平衡点为目标,而不是无条件地扩展带宽。
- 功耗预算。极端的核函数融合会同时使计算、内存和网络处于高负载状态,使得功耗限制成为关键的性能限制因素。我们建议未来的硬件设计为此类完全并发的负载提供足够的功率余量。
- 通信原语。我们采用基于拉取的方法,即每个 GPU 主动从远程 GPU 读取数据,避免了细粒度推送所伴随的高通知延迟。具有更低延迟跨 GPU 信令的未来硬件将使推送成为可行,并实现更自然的通信模式。
- 激活函数 。我们建议将 SwiGLU 替换为一种低成本的逐元素激活函数,该函数不涉及指数或除法运算。这直接减轻了 GEMM 后处理的负担,并且在相同参数预算下,移除门控投影会增大中间维度 ddd,从而进一步放宽带宽要求。
3.2. 使用 TileLang 进行灵活高效的核函数开发
在实践中,我们精细的模型架构将导致数百个细粒度的 Torch ATen 算子。我们采用 TileLang(Wang 等人,2026)开发了一组融合核函数来替换其中的绝大多数,以最小的努力提供最佳性能。
它还使我们能够在验证期间快速原型化像注意力变体这样的算子。这些核函数在模型架构开发、大规模训练以及最终的推理服务生产部署中扮演着关键角色。作为一种领域特定语言(DSL),TileLang 平衡了开发效率与运行时效率,支持在同一个代码库中进行快速开发,同时支持深度、迭代的优化。此外,我们与 TileLang 社区紧密合作,以培育更敏捷、高效和稳定的核函数开发工作流。
通过主机代码生成减少调用开销。随着加速器性能的不断提升,CPU 端的编排开销变得越来越突出。对于小型、高度优化的核函数,这种固定的主机开销很容易限制利用率和吞吐量。这种开销的一个常见来源是主机端逻辑(如运行时合约检查)通常为了灵活性而用 Python 编写,因此会带来固定的每次调用成本。
我们通过主机代码生成(Host Codegen)来减轻这种开销,它将大部分主机端逻辑移动到生成的主机代码中。具体来说,我们首先在 IR(中间表示)级别共同生成设备核函数和一个轻量级的主机启动器,嵌入从语言前端解析的必要元数据------例如数据类型、秩/形状约束和步长/布局假设。然后,该启动器被降级为构建在 TVM-FFI(Chen 等人,2018)框架之上的主机源代码,其紧凑的调用约定和零拷贝张量互操作共同最小化了主机端开销。在运行时,此生成的主机代码执行验证和参数封送处理,将所有每次调用的检查移出 Python 执行路径。我们的测量显示,CPU 端验证开销从几十或几百微秒下降到每次调用不到一微秒。
SMT 求解器辅助的形式整数分析。TileLang 核函数涉及复杂的张量索引算术,这需要强大的形式整数分析能力。在布局推断、内存危险检测和边界分析等编译过程中,编译器必须验证整数表达式是否满足特定属性才能启用相应的优化。因此,更强的形式分析能力可以解锁更高级和更复杂的优化机会。
为此,我们将 Z3 SMT 求解器(De Moura and Bjorner,2008)集成到 TileLang 的代数系统中,为张量程序中的大多数整数表达式提供形式分析能力。我们通过将 TileLang 的整数表达式转换为 Z3 的无量词非线性整数算术(QF_NIA),在计算开销和形式表达能力之间取得平衡。基于整数线性规划(ILP)求解器,QF_NIA 可以无缝解决内核中常见的标准线性整数表达式。此外,其固有的非线性推理能力有效地解决了诸如可变张量形状上的向量化等高级挑战。在合理的资源限制下,Z3 提升了整体优化性能,同时将编译时间开销限制在几秒钟内。这种影响在多个编译阶段(包括向量化、屏障插入和代码简化)都是巨大的。
数值精度和按位可重现性。在生产环境中,数值正确性和可重现性与原始吞吐量同样重要。因此,我们默认优先考虑精度:在编译器级别禁用快速数学优化,并且影响精度的近似值仅作为显式的、可选的前端算子提供(例如,T.__exp、T.__log 和 T.__sin)。相反,当需要严格的 IEEE-754 语义时,TileLang 提供了符合 IEEE 标准且带有显式舍入模式的内联函数(例如,T.ieee_fsqrt、T.ieee_fdiv 和 T.ieee_add),使开发者能够精确指定数值行为。
我们还以按位可重现性为目标,用于验证内核与手写 CUDA 基线的正确性。我们使 TileLang 的代数简化和降级规则与主流 CUDA 工具链(例如 NVCC)保持一致,以避免引入意外位级差异的转换。布局注释(例如,T.annotate_layout)进一步允许用户固定布局相关的降级决策,使评估和累积顺序与参考 CUDA 实现保持一致,从而在需要时实现位相同输出。
我们的评估表明,这些以精度和可重现性为导向的设计选择不会牺牲性能:在保守的默认设置下,TileLang 内核保持竞争力,同时提供旋钮以选择性地放松数值约束以获得更高的速度。
3.3. 高性能批量不变和确定性核函数库
为了实现高效训练和推理,我们开发了一套全面的高性能计算内核。除了基本功能和最大化硬件利用率之外,另一个关键设计目标是确保训练的可重现性以及预训练、后训练和推理流水线之间的按位对齐。因此,我们实现了端到端的、按位批量不变和确定性的内核,且性能开销极小。这些内核有助于调试、稳定性分析和一致的后训练行为。
批量不变性。批量不变性确保任何给定令牌的输出保持按位相同,无论其在批次中的位置如何。为了实现批量不变性,主要挑战如下:
- 注意力 。为了实现批量不变性,我们不能使用 split-KV 方法(Dao 等人,2023),该方法将单个序列的注意力计算分配到多个流式多处理器(SM)上以平衡 SM 的负载。然而,放弃这种技术将导致严重的波量化问题3,这可能对 GPU 利用率产生不利影响。为了解决这个问题,我们开发了一种用于批量不变解码的双内核策略。第一个内核在单个 SM 内计算整个序列的注意力输出,确保满载波的高吞吐量。第二个内核为了最小化最终部分填充波的延迟从而减轻波量化,使用多个 SM 处理单个序列。为了这两个内核的按位一致性,我们仔细设计了第二个内核的计算路径,以确保其累积顺序与第一个内核相同。此外,第二个内核利用线程块集群内的分布式共享内存4,实现跨 SM 的高速数据交换。这种双内核方法有效地将批量不变解码的开销限制在可忽略的水平。
- 矩阵乘法。传统的 cuBLAS 库(NVIDIA Corporation,2024)无法实现批量不变性。因此,我们端到端地将其替换为 DeepGEMM(Zhao 等人,2025)。此外,对于非常小的批量大小,传统实现通常采用 split-k(Osama 等人,2023)技术来提高性能。不幸的是,split-k 技术无法保证批量不变性,而这是 DeepSeek-V4 中的一个关键特性。
因此,我们在大多数场景中放弃了 split-k,但这可能会导致性能下降。为了解决这个问题,我们引入了一组优化,使我们实现的矩阵乘法在大多数主要场景中能够匹配甚至超越标准 split-k 的性能。
确定性。确定性训练对于调试硬件或软件问题非常有益。此外,当训练出现异常(如损失尖峰)时,确定性使研究人员能够更容易地查明数值原因并进一步改进模型设计。训练中的非确定性通常源于非确定的累积顺序,这通常是由于使用了原子加法指令。这个问题主要发生在反向传播过程中,尤其是在以下部分:
- 注意力反向传播 。在稀疏注意力反向传播的传统实现中,我们使用
atomicAdd来累积 KV 令牌的梯度。由于浮点加法的非结合性,这引入了非确定性。为了解决这个问题,我们为每个 SM 分配单独的累积缓冲区,然后对所有缓冲区进行全局确定性求和。 - MoE 反向传播。当来自不同排名的多个 SM 同时向接收排名上的同一缓冲区写入数据时,协商写入位置也会引入非确定性。为了解决这个问题,我们在每个单独排名内设计了一种令牌顺序预处理机制,并结合跨排名的缓冲区隔离。该策略确保了专家并行的发送结果以及 MoE 反向传播中累积顺序的确定性。
- mHC 中的矩阵乘法。mHC 涉及输出维度仅为 24 的矩阵乘法。对于非常小的批量大小,我们被迫使用 split-k(Osama 等人,2023)算法,其朴素实现会导致非确定性。为了克服这个问题,我们分别输出每个拆分部分,并在随后的内核中执行确定性归约,从而同时保持性能和确定性。
3.4. FP4 量化感知训练
为了在部署时实现推理加速和内存节省,我们在后训练阶段引入了量化感知训练(QAT)(Jacob 等人,2018),使模型能够适应量化引入的精度下降。我们将 FP4(MXFP4)量化(Rouhani 等人,2023)应用于两个组件:(1)MoE 专家权重,这是 GPU 内存占用的主要来源(OpenAI,2025),以及(2)CSA 索引器中的查询-键(QK)路径,其中 QK 激活完全以 FP4 格式缓存、加载和相乘,从而加速长上下文场景中的注意力分数计算。此外,我们在此 QAT 过程中进一步将索引分数 I::I_{::}I:: 从 FP32 量化为 BF16。这种优化为 top-kkk 选择器实现了 2×2\times2× 的加速,同时保持了 99.7%99.7\%99.7% 的 KV 条目召回率。
对于 MoE 专家权重,遵循 QAT 的常见做法,优化器维护的 FP32 主权重首先被量化为 FP4,然后反量化为 FP8 进行计算。值得注意的是,我们的 FP4 到 FP8 的反量化是无损的。这是因为与 FP4(E2M1)相比,FP8(E4M3)有 2 个额外的指数位,提供了更大的动态范围。因此,只要每个 FP8 量化块(128×128128\times 128128×128 块)内 FP4 子块(1×321\times 321×32 块)的最大和最小缩放因子之间的比率不超过某个阈值,细粒度的缩放信息就可以被 FP8 扩展的动态范围完全吸收。我们凭经验验证当前权重满足此条件。这使得整个 QAT 流水线能够完全重用现有的 FP8 训练框架,而无需任何修改。在反向传播中,梯度是相对于前向传播中相同的 FP8 权重计算的,并直接传播回 FP32 主权重,这相当于通过量化操作应用了直通估计器(STE)。这也避免了对转置权重进行重新量化的需要。
在推理和 RL 训练的 rollout 阶段(这些阶段不涉及反向传播),我们直接使用真实的 FP4 量化权重,而不是模拟量化。这确保了采样期间的模型行为与在线部署完全一致,同时减少了内核内存加载以实现实际加速,并显著降低了内存消耗。我们类似地处理 CSA 索引器中的 QK 路径。
3.5. 训练框架
我们的训练框架建立在我们为 DeepSeek-V3(DeepSeek-AI,2024)开发的可扩展且高效的基础设施之上。在训练 DeepSeek-V4 时,我们继承了这一坚实的基础,同时引入了若干关键创新,以适应其新颖的架构组件------特别是 Muon 优化器、mHC 和混合注意力机制------同时保持高训练效率和稳定性。
3.5.1. Muon 的高效实现
Muon 优化器需要完整的梯度矩阵来计算参数更新,这在与零冗余优化器(ZeRO)(Rajbhandari 等人,2020)结合时带来了挑战。传统的 ZeRO 是为 AdamW 等逐元素优化器设计的,其中单个参数矩阵可以跨多个排名进行分区和更新。为了解决这一冲突,我们为 Muon 设计了一种混合的 ZeRO 桶分配策略。
对于密集参数,我们限制了 ZeRO 并行的最大大小,并采用背包算法将参数矩阵分配给这些排名,确保每个排名管理大致平衡的负载。每个排名上的桶被填充以匹配跨排名最大桶的大小,从而促进高效的 reduce-scatter 操作。在我们的设置中,这种填充通常会产生不到 10%10\%10% 的内存开销,其中每个排名管理不超过五个参数矩阵。当数据并行的总体大小超过 ZeRO 的限制时,我们跨额外的数据并行组冗余计算 Muon 更新,以计算换取减少的总桶内存。
对于 MoE 参数,我们独立优化每个专家。我们首先展平所有层中所有专家的 SwiGLU(Shazeer,2020)中的所有下投影矩阵,然后是展平的上投影矩阵和门控矩阵。然后,我们填充展平的向量,以确保我们可以将此向量均匀地分布到所有排名,而不会拆分任何逻辑上独立的矩阵。给定专家数量庞大,我们不对 MoE 参数施加 ZeRO 并行的限制,并且填充开销也可忽略不计。
此外,在每个排名上,相同形状的连续参数将被自动合并,从而实现 Newton-Schulz 迭代的批处理执行,以获得更好的硬件利用率。此外,我们观察到 Muon 中的 Newton-Schulz 迭代在使用 BF16 矩阵乘法计算时保持稳定。利用这一点,我们进一步以随机舍入方式将要跨数据并行排名同步的 MoE 梯度量化为 BF16 精度,从而将通信量减半。为了避免低精度加法器引入的累积误差,我们用两阶段方法替换了传统的基于树或环的 reduce-scatter 集合。首先,一个 all-to-all 操作跨排名交换局部梯度,然后每个排名以 FP32 执行局部求和。这种设计保持了数值的稳健性。
3.5.2. 经济高效且内存高效的 mHC 实现
与传统的残差连接相比,mHC 的引入增加了激活内存消耗以及流水线阶段之间的通信量。为了减轻这些成本,我们实施了多种优化策略。
首先,我们为训练和推理精心设计并实现了 mHC 的融合核函数。其次,我们引入了一种重计算策略,选择性地检查点中间张量。具体来说,我们重计算层之间的大部分隐藏状态和所有归一化层输入,同时避免重计算计算密集型操作。这在内存节省和计算开销之间取得了平衡。第三,我们调整了 DualPipe 1F1B 重叠方案,以适应增加的流水线通信,并实现 mHC 中某些操作的并发执行。
总的来说,这些优化将 mHC 的挂钟时间开销限制在重叠的 1F1B 流水线阶段的 6.7%6.7\%6.7%。有关工程优化的更多详细信息,请参见专门的 mHC 论文(Xie 等人,2026)。
3.5.3. 长上下文注意力的上下文并行
传统的上下文并行(CP)沿着序列维度进行划分,每个排名维护连续的 sss 个令牌。这给我们的压缩注意力机制(即 CSA 和 HCA)带来了两个挑战。一方面,训练样本由多个序列打包而成,每个序列独立地按因子 mmm(或 m′m'm′)压缩,任何少于 mmm 的尾部令牌被丢弃。因此,压缩后的 KV 长度通常小于 sm\frac{s}{m}ms,并且跨排名变化。另一方面,压缩需要 mmm 个连续的 KV 条目,这些条目可能跨越两个相邻 CP 排名之间的边界。
为了解决这些挑战,我们设计了一种两阶段通信方法。在第一阶段,每个排名 iii 将其最后 mmm 个未压缩的 KV 条目发送给排名 i+1i + 1i+1。然后,排名 i+1i + 1i+1 将接收到的部分条目与其本地的 sss 个未压缩 KV 条目一起压缩,产生固定长度为 sm+1\frac{s}{m} +1ms+1 的压缩条目,其中存在一些填充条目。在第二阶段,一个跨所有 CP 排名的 all-gather 操作收集本地压缩的 KV 条目。然后,一个融合的 select-and-pad 操作符将它们重新组织成完整的压缩 KV 条目集,总长度为 cp_size⋅sm\mathrm{cp\_size}\cdot \frac{s}{m}cp_size⋅ms。任何填充条目都放在尾部。对于 HCA 和 CSA 中的索引器,每个查询令牌可见的压缩 KV 条目范围可以通过规则预先计算。对于 CSA 中的稀疏注意力,top-kkk 选择器为每个查询明确指定了可见压缩 KV 条目的索引。
3.5.4. 用于灵活激活检查点的扩展自动微分
传统的激活检查点实现在整个模块的粒度上操作,决定在反向传播期间是保留还是重计算其输出激活。这种粗粒度通常导致重计算成本和激活内存占用之间的次优权衡。另一种方法是手动实现整个层的前向和反向逻辑,显式地管理张量检查点状态。虽然这种方法实现了细粒度的控制,但它失去了自动微分框架的便利性,大大增加了开发复杂性。
为了在不牺牲编程效率的情况下实现细粒度控制,我们实现了一种支持自动微分的张量级激活检查点机制。使用这种机制,开发者只需实现前向传播,并选择性地注释单个张量以进行自动检查点和重计算。我们的框架利用 TorchFX(Reed 等人,2022)来追踪完整的计算图。对于每个注释的张量,它执行反向遍历以识别其重计算所需的最小子图。我们将这些最小子图定义为重计算图,并在相应的梯度计算之前将其插入到反向逻辑中。
与手动实现相比,这种设计在训练期间没有引入额外的开销。该框架中的重计算是通过直接释放注释张量的 GPU 内存并重用重计算张量的存储指针来实现的,无需任何 GPU 内存复制。此外,由于图追踪会具体执行模型,我们可以追踪每个张量的底层存储指针,这使得能够自动去重共享存储的张量(例如,reshape 操作的输入和输出)的重计算。这使开发者在注释重计算时无需考虑底层内存细节。
3.6. 推理框架
我们的推理框架在很大程度上继承了 DeepSeek-V3 的框架,但在 KV 缓存管理方面存在一些差异。
3.6.1. KV 缓存结构与管理
为了有效管理由 DeepSeek-V4 中的混合注意力机制产生的异构 KV 缓存,我们设计了一种定制的 KV 缓存布局。该布局如图 6 所示,我们将在下面详细阐述。
DeepSeek-V4 中的异构 KV 条目 。DeepSeek-V4 系列中的混合注意力机制引入了多种类型的 KV 条目,它们具有不同的键值(KV)缓存大小和更新规则。用于稀疏选择的闪电索引器向 KV 缓存引入了额外的维度,这些维度具有与主注意力中不同的嵌入大小。CSA 和 HCA 中采用的压缩技术将序列长度分别减少了 1m\frac{1}{m}m1 和 1m′\frac{1}{m'}m′1 倍,从而减小了总体 KV 缓存大小。因此,不同层的 KV 缓存大小各不相同。此外,滑动窗口注意力(SWA)层也以不同的 KV 缓存大小以及单独的缓存命中与驱逐策略运行。在压缩分支中,每 mmm 个令牌生成一个 KV 条目。当剩余令牌数量不足以进行压缩时,所有待处理的令牌及其相关的隐藏状态必须保留在缓冲区中,直到可以执行压缩操作。这些缓冲的令牌代表由位置上下文决定的序列状态,也在 KV 缓存框架内进行管理。
管理混合注意力 KV 缓存的挑战。混合注意力机制违反了 PagedAttention 及其变体的基本假设。尽管最近的混合 KV 缓存管理算法(例如,Jenga(Zhang 等人,2025a)、Hymba(Dong 等人,2025))针对通用的混合注意力模型或特定结构,但有两个主要障碍阻碍了在 PagedAttention 框架下跨所有层整合 KV 缓存:
- 不同的缓存策略,例如滑动窗口注意力中使用的策略。
- 高性能注意力内核施加的限制,包括对齐要求。
为了 DeepSeek-V4 的高效 KV 缓存管理,我们设计了相应的策略来克服这两个挑战。
用于 SWA 和未压缩尾部令牌的状态缓存。为了解决第一个障碍,我们采用了一种替代的缓存管理机制。由于 SWA 旨在有限的 KV 缓存大小下提升性能,因此将其与压缩分支中的未压缩尾部令牌一起视为一个状态空间模型是合理的。相应的 KV 缓存因此可以被视为一个仅依赖于当前位置的序列特定状态。因此,我们预先分配了一个固定大小有限的池子用于状态缓存,并将其动态分配给每个序列。
稀疏注意力内核协同设计 。关于第二个障碍,传统的高性能注意力内核通常假设每个块有固定数量 BBB 个令牌来优化性能,这对应于 CSA 中的 B⋅mB \cdot mB⋅m 个原始令牌和 HCA 中的 B⋅m′B \cdot m'B⋅m′ 个令牌。通过采用高性能的稀疏注意力内核,不同层可以容纳可变数量的每块令牌而不会导致性能下降。实现这一点需要协同设计 KV 缓存布局和稀疏注意力内核。例如,填充块以使其与缓存行对齐可以提高性能。因此,对于压缩比为 mmm 的 CSA 和压缩比为 m′m'm′ 的 HCA,每个块的原始令牌数可以是这两个压缩比的最小公倍数 lcm(m,m′)\mathrm{lcm}(m, m')lcm(m,m′) 的任意倍数。

图 6 | DeepSeek-V4 的 KV 缓存布局示意图。KV 缓存被组织成两个主要部分:一个用于 CSA/HCA 的经典 KV 缓存,以及一个用于 SWA 和 CSA/HCA 中尚未准备好压缩的令牌的状态缓存。在状态缓存中,每个请求被分配一个固定大小的缓存块。在该块内,SWA 段存储对应最近 n_{\\mathrm{win}} 个令牌的 KV 条目,而 CSA/HCA 段存储尚未准备好进行压缩的未压缩尾部状态。在经典 KV 缓存中,我们为每个请求分配多个块。每个缓存块覆盖 \\mathrm{lcm}(m,m') 个原始令牌,产生 k_{1} = \\frac{\\mathrm{lcm}(m,m')}{m} 个 CSA 压缩令牌和 k_{2} = \\frac{\\mathrm{lcm}(m,m')}{m'} 个 HCA 压缩令牌。 #### 3.6.2. 磁盘 KV 缓存存储
在服务 DeepSeek-V4 时,我们利用磁盘 KV 缓存存储机制来消除共享前缀请求的重复预填充。对于 CSA/HCA 中的压缩 KV 条目和滑动窗口注意力(SWA)中的未压缩 KV 条目,我们设计了单独的存储管理解决方案。对于 CSA 和 HCA,我们简单地将所有压缩的 KV 条目存储到磁盘。当请求命中存储的前缀时,我们读取并重用与前缀对应的压缩 KV 条目,直到最后一个完整的压缩块。特别是,对于尾部不完整块中的前缀令牌,我们仍然需要重新计算它们以恢复未压缩的 KV 条目,因为 CSA 和 HCA 中的未压缩 KV 条目不会被存储。
对于 SWA KV 条目,由于它们没有被压缩并且存在于每一层,其体积大约是压缩后的 CSA 和 HCA KV 条目的 8 倍。为了高效地处理这些大量的 SWA KV 条目,我们提出并实现了三种不同的磁盘 SWA KV 条目管理策略,每种策略在存储开销和计算冗余之间提供了不同的权衡:
- 全量 SWA 缓存 。此策略存储所有令牌的完整 SWA KV 条目,确保计算零冗余。在此策略下,只需读取该前缀中最后 nwinn_{\mathrm{win}}nwin 个令牌的磁盘缓存,即可重建命中前缀的 SWA KV 条目。尽管计算零冗余,但此策略对于基于现代 SSD 的存储系统效率低下------每次命中请求只会访问存储的 SWA KV 缓存的一小部分,这导致了不平衡的写密集型访问模式。
- 周期性检查点 。此策略每 ppp 个令牌检查点化最后 nwinn_{\mathrm{win}}nwin 个令牌的 SWA KV 条目,其中 ppp 是一个可调参数。对于命中前缀,我们加载最近的检查点状态,然后重新计算剩余的尾部令牌。通过调整 ppp,此策略实现了存储和计算之间的按需权衡。
- 零 SWA 缓存 。此策略不存储任何 SWA KV 条目。对于命中前缀,我们需要执行更多的重计算来恢复 SWA KV 条目。具体来说,在每个注意力层中,每个令牌的 SWA KV 条目仅依赖于前一层中最近 nwinn_{\mathrm{win}}nwin 个令牌的 SWA KV 条目。因此,利用缓存的 CSA 和 HCA KV 条目,重新计算最后 nwin⋅Ln_{\mathrm{win}} \cdot Lnwin⋅L 个令牌足以恢复一个 LLL 层模型的最后 nwinn_{\mathrm{win}}nwin 个 SWA KV 条目。
根据具体的部署场景,我们选择最合适的策略来实现存储和计算之间的期望权衡。
4. 预训练
4.1. 数据构建
在 DeepSeek-V3 预训练数据的基础上,我们努力构建一个更多样化、更高质量、具有更长有效上下文的训练语料库。我们不断完善我们的数据构建流程。对于网络来源的数据,我们实施了过滤策略,以去除批处理自动生成和模板化的内容,从而减轻模型崩溃的风险(Zhu 等人,2024)。数学和编程语料库仍然是我们训练数据的核心组成部分,我们通过在中期训练阶段融入智能体数据,进一步增强了 DeepSeek-V4 系列的编码能力。对于多语言数据,我们为 DeepSeek-V4 构建了更大的语料库,提高了其捕捉不同文化中长尾知识的能力。对于 DeepSeek-V4,我们特别强调长文档数据的整理,优先考虑科学论文、技术报告以及其他反映独特学术价值的材料。综合以上所有,我们的预训练语料库包含超过 32T 个令牌,涵盖数学内容、代码、网页、长文档和其他高质量类别。
对于预训练数据,我们在很大程度上遵循了 DeepSeek-V3 的相同预处理策略。对于分词,在 DeepSeek-V3 分词器的基础上,我们引入了一些用于上下文构建的特殊令牌,并仍然保持词汇表大小为 128K。我们还继承了 DeepSeek-V3 的令牌拆分(DeepSeek-AI,2024)和中间填充(FIM)(DeepSeek-AI,2024)策略。受 Ding 等人(2024)的启发,我们将来自不同来源的文档打包到适当的序列中,以最小化样本截断。与 DeepSeek-V3 不同,我们在预训练期间采用了样本级注意力掩码。
4.2. 预训练设置
4.2.1. 模型设置
DeepSeek-V4-Flash 。我们将 Transformer 层数设置为 43,隐藏维度 ddd 设置为 4096。对于前两层,我们使用纯滑动窗口注意力。对于后续层,CSA 和 HCA 交错使用。对于 CSA,我们设置压缩率 mmm 为 4,索引器查询头数量 nhln_h^lnhl 为 64,索引器头维度 clc^lcl 为 128,为稀疏注意力选择的 KV 条目数量(即注意力 top-kkk)为 512。对于 HCA,我们设置压缩率 m′m'm′ 为 128。对于 CSA 和 HCA,我们都设置查询头数量 nhn_hnh 为 64,头维度 ccc 为 512,查询压缩维度 dcd_cdc 为 1024。输出投影组数 ggg 设置为 8,每个中间注意力输出的维度 dgd_gdg 设置为 1024。对于滑动窗口注意力的附加分支,窗口大小 nwinn_{\mathrm{win}}nwin 设置为 128。我们在所有 Transformer 块中都使用 MoE 层,但对前 3 个 MoE 层使用哈希路由策略。每个 MoE 层包含 1 个共享专家和 256 个路由专家,每个专家的中间隐藏维度为 2048。在路由专家中,每个令牌将激活 6 个专家。多令牌预测深度设置为 1。对于 mHC,扩展因子 nhcn_{\mathrm{hc}}nhc 设置为 4,Sinkhorn-Knopp 迭代次数 tmaxt_{\mathrm{max}}tmax 设置为 20。在此配置下,DeepSeek-V4-Flash 包含 284B 总参数,其中每个令牌激活 13B 参数。
DeepSeek-V4-Pro 。我们将 Transformer 层数设置为 61,隐藏维度 ddd 设置为 7168。对于前两层,我们使用 HCA。对于后续层,CSA 和 HCA 交错使用。对于 CSA,我们设置压缩率 mmm 为 4,索引器查询头数量 nhln_h^lnhl 为 64,索引器头维度 clc^lcl 为 128,为稀疏注意力选择的 KV 条目数量(即注意力 top-kkk)为 1024。对于 HCA,我们设置压缩率 m′m'm′ 为 128。对于 CSA 和 HCA,我们都设置查询头数量 nhn_hnh 为 128,头维度 ccc 为 512,查询压缩维度 dcd_cdc 为 1536。输出投影组数 ggg 设置为 16,每个中间注意力输出的维度 dgd_gdg 设置为 1024。对于滑动窗口注意力的附加分支,窗口大小 nwinn_{\mathrm{win}}nwin 设置为 128。我们在所有 Transformer 块中都使用 MoE 层,但对前 3 个 MoE 层使用哈希路由策略。每个 MoE 层包含 1 个共享专家和 384 个路由专家,每个专家的中间隐藏维度为 3072。在路由专家中,每个令牌将激活 6 个专家。多令牌预测深度设置为 1。对于 mHC,扩展因子 nhcn_{\mathrm{hc}}nhc 设置为 4,Sinkhorn-Knopp 迭代次数 tmaxt_{\mathrm{max}}tmax 设置为 20。在此配置下,DeepSeek-V4-Pro 包含 1.6T 总参数,其中每个令牌激活 49B 参数。
4.2.2. 训练设置
DeepSeek-V4-Flash 。我们对大多数参数采用 Muon 优化器(Jordan 等人,2024;Liu 等人,2025),但对嵌入模块、预测头模块以及所有 RMSNorm 模块的权重使用 AdamW 优化器(Loshchilov and Hutter,2017)。对于 AdamW,我们设置其超参数 β1=0.9\beta_{1} = 0.9β1=0.9,β2=0.95\beta_{2} = 0.95β2=0.95,ϵ=10−20\epsilon = 10^{- 20}ϵ=10−20,以及 weight_decay =0.1= 0.1=0.1。对于 Muon,我们设置动量为 0.95,权重衰减为 0.1,并将每个更新矩阵的均方根(RMS)重缩放为 0.18,以重用 AdamW 学习率。我们在 32T 令牌上训练 DeepSeek-V4-Flash,并且与 DeepSeek-V3 一样,我们采用了一种批次大小调度策略,将批次大小(以令牌数计)从小值增加到 75.5M,然后在大部分训练期间保持在 75.5M。学习率在前 2000 步中线性预热,在大部分训练期间保持在 2.7×10−42.7 \times 10^{- 4}2.7×10−4。在训练接近尾声时,我们最终按照余弦调度将学习率衰减到 2.7×10−52.7 \times 10^{- 5}2.7×10−5。训练从序列长度 4K 开始,我们逐渐将训练序列长度扩展到 16K、64K 和 1M。至于稀疏注意力的设置,我们首先在前 1T 令牌的密集注意力下预热模型,然后在序列长度达到 64K 时引入稀疏注意力,并在剩余的训练中保持稀疏注意力。在引入注意力稀疏性时,我们首先设置一个短阶段来预热 CSA 中的闪电索引器,然后在大部分训练中使用稀疏注意力训练模型。对于无辅助损失的负载均衡,我们将偏置更新速度设置为 0.001。对于均衡损失,我们将其损失权重设置为 0.0001,以避免单个序列内的极端不平衡。MTP 损失权重在大部分训练中设置为 0.3,在学习率衰减开始时设置为 0.1。
DeepSeek-V4-Pro 。除了超参数的特定值外,DeepSeek-V4-Pro 的训练设置与 DeepSeek-V4-Flash 基本一致。我们对大多数参数采用 Muon 优化器,但对嵌入模块、预测头模块以及所有 RMSNorm 模块的权重使用 AdamW 优化器。AdamW 和 Muon 的超参数与 DeepSeek-V4-Flash 相同。我们在 33T 令牌上训练 DeepSeek-V4-Pro,并采用批次大小调度策略,最大批次大小为 94.4M 令牌。学习率调度策略与 DeepSeek-V4-Flash 基本相同,但峰值学习率设置为 2.0×10−42.0 \times 10^{- 4}2.0×10−4,最终学习率设置为 2.0×10−52.0 \times 10^{- 5}2.0×10−5。训练也从序列长度 4K 开始,然后逐渐扩展到 16K、64K 和 1M。与 DeepSeek-V4-Flash 相比,DeepSeek-V4-Pro 从更长的密集注意力阶段开始,引入稀疏注意力的策略与 DeepSeek-V4-Flash 相同,遵循两阶段训练方法。对于无辅助损失的负载均衡,我们将偏置更新速度设置为 0.001。对于均衡损失,我们将其损失权重设置为 0.0001,以避免单个序列内的极端不平衡。MTP 损失权重在大部分训练中设置为 0.3,在学习率衰减开始时设置为 0.1。
4.2.3. 缓解训练不稳定性
训练数万亿参数的 MoE 模型带来了显著的稳定性挑战,DeepSeek-V4 系列也不例外。我们在训练中遇到了显著的不稳定性挑战。虽然简单的回滚可以暂时恢复训练状态,但事实证明它们不是长期的解决方案,因为它们不能防止损失尖峰的再次发生。根据经验,我们发现尖峰的出现始终与 MoE 层中的异常值有关,并且路由机制本身似乎会加剧这些异常值的出现。因此,我们试图从两个维度解决这个问题:打破路由引发的恶性循环,以及直接抑制异常值。幸运的是,我们发现了两种实用的技术,可以有效地保持训练稳定性。尽管对其潜在机制的理论理解目前仍是一个悬而未决的问题,但我们公开分享它们,以促进社区的进一步探索。
预期路由 。我们发现将骨干网络和路由网络的同步更新解耦显著提高了训练稳定性。因此,在步骤 ttt,我们使用当前的网络参数 θt\theta_tθt 进行特征计算,但是使用历史网络参数 θt−Δt\theta_{t - \Delta t}θt−Δt 计算和应用路由索引。在实践中,为了避免加载两次模型参数的开销,我们在步骤 t−Δtt - \Delta tt−Δt 时提前获取步骤 ttt 的数据。我们"预期地"计算并缓存稍后在步骤 ttt 使用的路由索引,这就是我们将此方法命名为预期路由的原因。我们还在基础设施层面对此进行了大量优化。首先,鉴于预计算路由索引只需要对数据进行一次前向传播,我们精心安排了流水线执行以及计算与专家并行(EP)通信的重叠,成功地将预期路由的额外挂钟时间开销限制在大约 20%20\%20%。其次,我们引入了一种自动检测机制,仅在发生损失尖峰时触发短暂回滚并激活预期路由;在此模式下运行一段时间后,系统恢复到标准训练。最终,这种动态应用使我们能够避免损失尖峰,且总体额外训练开销微乎其微,同时不影响模型性能。
SwiGLU 钳位 。在之前的文献中(Bello 等人,2017;Riviere 等人,2024),钳位已被明确用于约束数值范围,从而提高训练稳定性。在我们实际的训练运行中,我们凭经验发现应用 SwiGLU 钳位(OpenAI,2025)可以有效消除异常值,并极大地帮助稳定训练过程,且不影响性能。在 DeepSeek-V4-Flash 和 DeepSeek-V4-Pro 的整个训练过程中,我们将 SwiGLU 的线性分量钳位在 −10,10- 10,10−10,10 范围内,同时将门控分量的上界限制在 10。
4.3. 评估
4.3.1. 评估基准
对于基础模型的评估,我们考虑了涵盖四个关键维度的基准:世界知识、语言理解与推理、编码与数学以及长上下文处理。
世界知识基准包括 AGIEval(Zhong 等人,2023)、C-Eval(Huang 等人,2023)、CMMLU(Li 等人,2023)、MMLU(Hendrycks 等人,2020)、MMLU-Redux(Gema 等人,2024)、MMLU-Pro(Wang 等人,2024b)、MMMLU(OpenAI,2024a)、MultiLoKo(Hupkes and Bogoychev,2025)、Simple-QA verified(Haas 等人,2025)、SuperGPQA(Du 等人,2025)、FACTS Parametric(Cheng 等人,2025)和 TriviaQA(Joshi 等人,2017)。
语言理解与推理基准包括 BigBench Hard (BBH)(Suzgun 等人,2022)、DROP(Dua 等人,2019)、HellaSwag(Zellers 等人,2019)、CLUEWSC(Xu 等人,2020)和 WinoGrande(Sakaguchi 等人,2019)。
编码与数学基准包括 BigCodeBench(Zhuo 等人,2025)、HumanEval(Chen 等人,2021)、GSM8K(Cobbe 等人,2021)、MATH(Hendrycks 等人,2021)、MGSM(Shi 等人,2023)和 CMath(Wei 等人,2023)。
长上下文基准包括 LongBench-V2(Bai 等人,2025b)。
表 1 | DeepSeek-V3.2-Base、DeepSeek-V4-Flash-Base 和 DeepSeek-V4-Pro-Base 之间的比较。所有模型均在我们的内部框架中评估,并共享相同的评估设置。差距不超过 0.3 的分数视为同一水平。每行的最高分以粗体显示,第二名以下划线显示。
| 基准 (指标) | # Shots | DeepSeek-V3.2 Base | DeepSeek-V4-Flash Base | DeepSeek-V4-Pro Base |
|---|---|---|---|---|
| 架构 | - | MoE | MoE | MoE |
| # 激活参数量 | - | 37B | 13B | 49B |
| # 总参数量 | - | 671B | 284B | 1.6T |
| AGIEval (EM) | 0-shot | 80.1 | 82.6 | 83.1 |
| MMLU (EM) | 5-shot | 87.8 | 88.7 | 90.1 |
| MMLU-Redux (EM) | 5-shot | 87.5 | 89.4 | 90.8 |
| MMLU-Pro (EM) | 5-shot | 65.5 | 68.3 | 73.5 |
| MMMLU (EM) | 5-shot | 87.9 | 88.8 | 90.3 |
| C-Eval (EM) | 5-shot | 90.4 | 92.1 | 93.1 |
| CMMLU (EM) | 5-shot | 88.9 | 90.4 | 90.8 |
| MultiLoKo (EM) | 5-shot | 38.7 | 42.2 | 51.1 |
| Simple-QA verified (EM) | 25-shot | 28.3 | 30.1 | 55.2 |
| SuperGQA (EM) | 5-shot | 45.0 | 46.5 | 53.9 |
| FACTS Parametric (EM) | 25-shot | 27.1 | 33.9 | 62.6 |
| TriviaQA (EM) | 5-shot | 83.3 | 82.8 | 85.6 |
| BBH (EM) | 3-shot | 87.6 | 86.9 | 87.5 |
| DROP (F1) | 1-shot | 88.2 | 88.6 | 88.7 |
| HellaSwag (EM) | 0-shot | 86.4 | 85.7 | 85.7 |
| WinoGrande (EM) | 0-shot | 78.9 | 79.5 | 81.5 |
| CLUEWSC (EM) | 5-shot | 83.5 | 82.2 | 85.2 |
| BigCodeBench (Pass@1) | 3-shot | 63.9 | 56.8 | 59.2 |
| HumanEval (Pass@1) | 0-shot | 62.8 | 69.5 | 76.8 |
| GSM8K (EM) | 8-shot | 91.1 | 90.8 | 92.6 |
| MATH (EM) | 4-shot | 60.5 | 57.4 | 64.5 |
| MGSM (EM) | 8-shot | 81.3 | 85.7 | 84.4 |
| CMath (EM) | 3-shot | 92.6 | 93.6 | 90.9 |
| 长上下文 | ||||
| LongBench-V2 (EM) | 1-shot | 40.2 | 44.7 | 51.5 |
4.3.2. 评估结果
在表 1 中,我们详细比较了 DeepSeek-V3.2、DeepSeek-V4-Flash 和 DeepSeek-V4-Pro 的基础模型,所有模型均在统一的内部框架下使用严格一致的设置进行评估。
比较 DeepSeek-V4-Flash-Base 和 DeepSeek-V3.2-Base 揭示了一个引人注目的效率故事。尽管激活参数量和总参数量都大幅减少,DeepSeek-V4-Flash-Base 在广泛的基准测试中仍优于 DeepSeek-V3.2-Base。这种优势在世界知识任务和具有挑战性的长上下文场景中尤为明显。这些结果强调,DeepSeek-V4-Flash-Base 中的架构改进、数据质量提升和训练优化即使在更紧凑的参数预算下也能产生卓越的性能,在大多数评估中有效超越了更大的 DeepSeek-V3.2-Base。
此外,DeepSeek-V4-Pro-Base 展示了进一步的决定性能力飞跃,在 DeepSeek-V3.2-Base 和 DeepSeek-V4-Flash-Base 上建立了近乎全面的优势。在几乎所有类别中都有所改进,DeepSeek-V4-Pro-Base 在最具挑战性的基准上达到了 DeepSeek 基础模型中的新性能高点。
5. 后训练
在知识密集型评估中,它带来了巨大的提升,同时也显著推进了长上下文理解。在大多数推理和代码基准上,DeepSeek-V4-Pro-Base 也超越了这两个之前的模型。这种全面的提升证实了 DeepSeek-V4-Pro-Base 是 DeepSeek 系列中最强大的基础模型,在知识、推理、编码和长上下文能力方面全面优于其前代模型。
5. 后训练
5.1. 后训练流程
预训练之后,我们进行了后训练阶段,以生成 DeepSeek-V4 系列的最终模型。虽然训练流程在很大程度上与 DeepSeek-V3.2 相似,但进行了一个关键的方法替换:混合强化学习(RL)阶段被完全替换为同策略蒸馏(OPD)。
5.1.1. 专家训练
领域专家的开发是通过调整 DeepSeek-V3.2 的训练流程进行的。具体来说,每个模型通过初始的微调阶段和随后的、由领域特定提示和奖励信号引导的强化学习(RL)依次进行优化。对于 RL 阶段,我们实施了组相对策略优化(GRPO)算法,其超参数与我们先前的研究(DeepSeek-AI,2025;DeepSeek-AI,2025)保持高度一致。
推理努力 。众所周知,模型在推理任务上的性能从根本上取决于所投入的计算努力。因此,我们在不同的 RL 配置下训练了不同的专家模型,以促进针对不同推理能力进行优化的模型的开发。如表 2 所示,DeepSeek-V4-Pro 和 DeepSeek-V4-Flash 都支持三种特定的推理努力模式。对于每种模式,我们在 RL 训练期间应用不同的长度惩罚和上下文窗口,这导致推理输出令牌长度的变化。为了整合这些不同的推理模式,我们利用由 <think> 和 </think> 标记分隔的专门响应格式。此外,对于"Think Max"模式,我们在系统提示的开头添加一个特定的指令来指导模型的推理过程,如表 3 所示。
生成式奖励模型。通常,易于验证的任务可以使用简单的基于规则的验证器或测试用例进行有效优化。相比之下,难以验证的任务传统上依赖于基于人类反馈的强化学习(RLHF),这需要大量的人工注释来训练一个标量奖励模型。然而,在 DeepSeek-V4 系列的后训练阶段,我们摒弃了这些传统的基于标量的奖励模型。相反,为了解决难以验证的任务,我们策划了基于规则的 RL 数据,并采用生成式奖励模型(GRM)来评估策略轨迹。关键的是,我们直接将 RL 优化应用于 GRM 本身。在这种范式下,演员网络原生地充当 GRM,使得模型的评估(判断)能力与其标准生成能力能够联合优化。通过统一这些角色,模型的内在推理能力被固有地融合到其评估过程中,从而产生高度鲁棒的评分。此外,这种方法仅用最少量的多样化人工注释就能实现卓越的性能,因为模型利用其自身的逻辑在复杂任务上进行泛化。
表 2 | 三种推理模式的比较
| 推理模式 | 特点 | 典型用例 | 响应格式 |
|---|---|---|---|
| 非思考 | 快速、基于习惯或简单规则的直觉反应。 | 日常任务、紧急反应、低风险决策。 | </think> 摘要 |
| 高思考 | 有意识的逻辑分析,较慢但更准确。 | 复杂问题解决、规划、中等风险决策。 | <think> 思考令牌 </think> 摘要 |
| 最大思考 | 将推理推向极致。缓慢但强大。 | 探索模型推理能力的边界。 | 1. 开头的特殊系统提示。2. <think> 思考令牌 </think> 摘要 |
表 3 | 为"最大思考"模式注入系统提示的指令。
| 注入的指令 |
|---|
| 推理努力:绝对最大,不允许走捷径。 |
| 你必须非常透彻地思考,全面分解问题以解决根本原因,严格压力测试你的逻辑,考虑所有潜在路径、边缘情况和对抗性场景。 |
| 明确写出你的整个思考过程,记录每一个中间步骤、考虑过的替代方案和被拒绝的假设,以确保没有任何假设被忽略。 |
工具调用模式和特殊令牌 。与我们之前的版本一致,我们使用专用的 <think></think> 标签来 delineate the reasoning path。在 DeepSeek-V4 系列中,我们引入了一种新的工具调用模式,该模式采用特殊的"|DSML|"令牌,并使用基于 XML 的格式进行工具调用,如表 4 所示。我们的实验表明,XML 格式有效地缓解了转义失败并减少了工具调用错误,为模型-工具交互提供了更健壮的接口。
交错思考。DeepSeek-V3.2 引入了一种上下文管理策略,该策略在工具结果轮次之间保留推理轨迹,但在新用户消息到达时丢弃它们。虽然有效,但这在复杂的智能体工作流中仍然造成了不必要的令牌浪费------每个新的用户轮次都会清空所有累积的推理内容,迫使模型从头重建其问题解决状态。利用 DeepSeek-V4 系列扩展的 1M 令牌上下文窗口,我们进一步完善了这一机制,以在智能体环境中最大化交错思考的有效性:
- 工具调用场景。如图 7(a) 所示,所有推理内容在整个对话过程中被完全保留。与 DeepSeek-V3.2(在每个新用户轮次时丢弃思考轨迹)不同,DeepSeek-V4 系列在包括用户消息边界在内的所有轮次中保留完整的推理历史。这允许模型在长期智能体任务中保持连贯、累积的思维链。
- 通用对话场景。如图 7(b) 所示,原始策略被保留:当新用户消息到达时,前几轮的推理内容被丢弃,以在持久推理轨迹收益有限的场景中保持上下文简洁。
与 DeepSeek-V3.2 一样,通过用户消息模拟工具交互的智能体框架(例如 Terminus)可能不会触发工具调用上下文路径,因此可能无法从增强的推理持久性中受益。对于此类架构,我们继续推荐非思考模型。
表 4 | DeepSeek-V4 系列的工具调用模式。
| 工具调用模式 |
|---|
| ## 工具 |
| 你可以使用一组工具来帮助回答用户的问题。你可以通过编写如下所示的"< |
| < |
字符串参数应按原样指定,并设置 string='true'。对于所有其他类型(数字、布尔值、数组、对象),请以 JSON 格式传递值并设置 string='false'。 |
如果启用了思考模式(由 <think> 触发),你必须在任何工具调用或最终响应之前,在 <think>...</think> 内输出完整的推理过程。 |
否则,在 </think> 之后直接输出工具调用或最终响应。 |
| ## 可用工具模式 |
| {工具定义...} |
| 你必须严格遵循上述定义的工具名称和参数模式来调用工具。 |
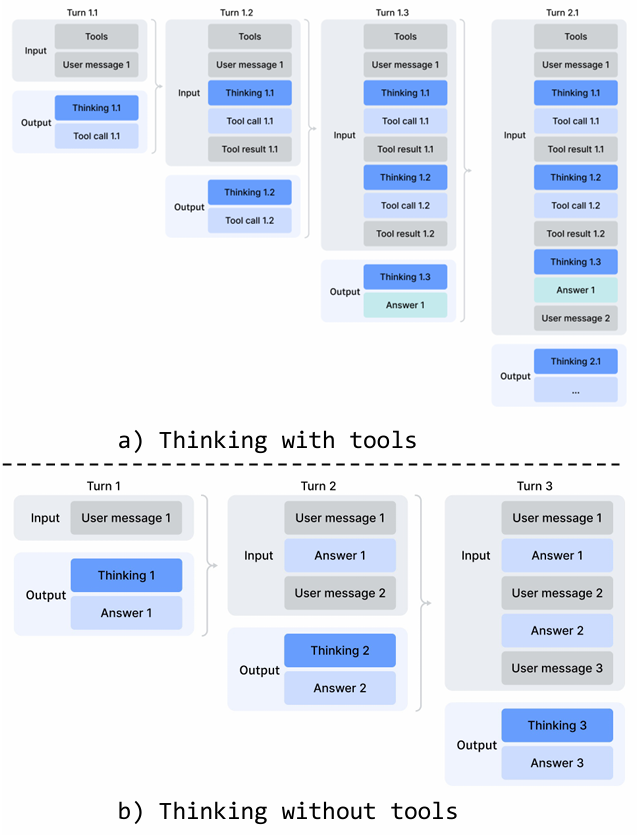
图 7 | DeepSeek-V4 系列的思考管理。
快速指令。在聊天机器人场景中,在生成响应之前必须执行许多辅助任务(例如,确定是否触发网络搜索、意图识别等)。传统上,这些任务由一个单独的小模型处理,由于无法重用现有的 KV 缓存,需要进行冗余的预过滤。为了克服这一限制,我们引入了快速指令。我们将一组专用的特殊令牌直接附加到输入序列中,其中每个令牌对应一个特定的辅助任务。通过直接重用已计算的 KV 缓存,这种机制完全避免了冗余的预过滤,并允许某些任务(例如生成搜索查询、确定权威性和领域)并行执行。因此,这种方法显著减少了用户感知的首令牌时间(TTFT),并消除了维护和迭代额外小模型的工程开销。支持的快速指令令牌总结在表 5 中。
5.1.2. 同策略蒸馏
在通过专门的微调和强化学习训练了多个领域特定专家后,我们采用多教师同策略蒸馏(OPD)作为将专家能力合并到最终模型的主要技术。OPD 已成为一种有效的后训练范式,用于将领域专家的知识和能力高效地转移到一个统一的模型中。这是通过让学生模型在其自身生成的轨迹上学习教师模型的输出分布来实现的。形式上,给定一组 NNN 个专家模型{πE1,πE2,...,πEN}\{\pi_{E1}, \pi_{E2}, . . . , \pi_{EN}\}{πE1,πE2,...,πEN},OPD 目标函数定义为:
LOPD(θ)=∑i=1Nwi⋅DKL(πθ∥πEi).(29) L_{\text{OPD}}(\theta) = \sum_{i=1}^{N} w_i \cdot D_{\text{KL}} \left( \pi_{\theta} \| \pi_{Ei} \right). \tag{29} LOPD(θ)=i=1∑Nwi⋅DKL(πθ∥πEi).(29)
表 5 | 用于辅助任务的快速指令特殊令牌。
| 特殊令牌 | 描述 | 格式 |
|---|---|---|
| `< | action | >` |
| `< | title | >` |
| `< | query | >` |
| `< | authority | >` |
| `< | domain | >` |
| `< | extracted_url | > < |
在此公式中,wiw_iwi 代表分配给每个专家的权重,通常由专家的相对重要性决定。计算反向 KL 散度 DKL(πθ∥πEi)D_{\text{KL}} \left( \pi_{\theta} \| \pi_{Ei} \right)DKL(πθ∥πEi) 需要从学生模型 πθ\pi_{\theta}πθ 中采样训练轨迹以保持同策略学习。其基本原理确保统一策略 πθ\pi_{\theta}πθ 根据当前任务上下文选择性地从相关专家那里学习(例如,对于数学推理任务与数学专家对齐,对于编程任务与编码专家对齐)。通过这种机制,来自物理上不同的专家权重的知识通过 logits 级别的对齐被整合到一个统一的参数空间中,实际上规避了在传统的权重合并或混合 RL 技术中经常遇到的性能下降。在此阶段,使用覆盖多个领域的十多个教师模型来蒸馏一个单一的学生模型。
在处理上述 OPD 目标时,先前的工作通常将全词汇 KL 损失简化为每个令牌位置的令牌级 KL 估计,并通过将 sg(logπEi(yt∣x,y<t)πθ(yt∣x,y<t))\text{sg}\left( \log \frac{\pi_{Ei}(y_t|x,y_{<t})}{\pi_{\theta}(y_t|x,y_{<t})} \right)sg(logπθ(yt∣x,y<t)πEi(yt∣x,y<t))(sg\text{sg}sg 表示停止梯度操作)作为策略损失计算中的每个令牌优势估计来重用 RL 框架。尽管这种方法资源效率高,但它会导致梯度估计的高方差,并常常引起训练不稳定。因此,我们在 OPD 中采用全词汇 logit 蒸馏。保留完整的 logit 分布以计算反向 KL 损失,可以产生更稳定的梯度估计,并确保教师知识的忠实蒸馏。在下一小节中,我们将描述使全词汇 OPD 大规模可行的工程努力。
5.2. RL 和 OPD 基础设施
我们的后训练基础设施建立在为 DeepSeek-V3.2 开发的可扩展框架之上。具体来说,我们集成了第 3.5 节中描述的相同分布式训练栈以及先前引入的用于高效自回归采样的 rollout 引擎。在此基础之上,我们在当前工作中引入了以下主要增强功能。这些设计使得能够高效执行涉及超过十个不同教师模型的超长上下文 RL 和 OPD 合并任务,从而显著加快模型发布的迭代周期。
5.2.1. FP4 量化集成
我们应用 FP4(MXFP4)量化来加速 rollout 和所有仅推理的前向传播,包括教师模型和参考模型的前向传播,从而减少内存流量和采样延迟。如第 3.4 节所述,我们在 rollout 和推理阶段直接使用原生 FP4 权重。对于训练步骤,FP4 量化通过无损的 FP4 到 FP8 反量化步骤进行模拟,允许无缝重用现有的 FP8 混合精度框架和 FP32 主权重,且无需修改反向传播流水线。
5.2.2. 用于全词汇 OPD 的高效教师调度
我们的框架支持全词汇同策略蒸馏(OPD),且教师数量可 effectively unbounded,每个教师可能包含数万亿参数。为了实现这一点,所有教师权重都被卸载到中央分布式存储,并在教师前向传播期间按需加载,使用类似 ZeRO 的参数分片来缓解 I/O 和 DRAM 压力。此外,对所有教师 naive 地 materializing 词汇量大小 ∣V∣>100k|V| > 100k∣V∣>100k 的 logits 是 prohibitive 的,即使 spooled to disk。我们通过在前向传播期间仅在中央缓冲区中缓存教师的最后一层隐藏状态来解决这个问题。在训练时,这些缓存的状态被检索并传递通过相应的预测头模块,以即时重建完整的 logits。这种设计引入了可忽略的重计算开销,同时完全规避了与显式 logits materialization 相关的内存负担。为了减轻教师预测头的 GPU 内存占用,我们在数据分发期间按教师索引对训练样本进行排序。这种安排确保每个不同的教师头在每个小批量中仅加载一次,并且任何时候最多有一个教师头驻留在设备内存中。所有参数和隐藏状态的加载/卸载操作都在后台异步进行,不会阻塞关键路径上的计算。最后,教师和学生 logits 之间的精确 KL 散度使用专用的 TileLang 内核计算,这加速了计算并减少了动态内存分配。
5.2.3. 可抢占且容错的 Rollout 服务
为了最大化 GPU 资源利用率,同时为高优先级任务实现快速硬件配置,我们的 GPU 集群采用了集群范围的可抢占任务调度器,其中任何正在运行的任务都可能随时被抢占。此外,在大规模 GPU 集群中硬件故障很常见。为此,我们为 RL/OPD rollout 实现了一个可抢占且容错的 LLM 生成服务。
具体来说,我们为每个生成请求实现了一个令牌粒度的预写日志(WAL)。每当为请求生成一个新令牌时,我们立即将其附加到该请求的 WAL 中。在抢占期间,我们暂停推理引擎并保存未完成请求的 KV 缓存。恢复后,我们使用持久化的 WAL 和保存的 KV 缓存继续解码。即使发生致命的硬件错误,我们也可以使用 WAL 中持久化的令牌重新运行预填充阶段,以重建 KV 缓存。
重要的是,从头开始重新生成未完成的请求在数学上是不正确的,因为这引入了长度偏差。因为较短的响应更有可能在中断中幸存下来,从头重新生成会使模型在发生中断时更容易产生较短的序列。如果推理栈是批量不变且确定性的,这个正确性问题也可以通过使用为采样器中的伪随机数生成器生成一致的种子进行重新生成来解决。然而,这种方法仍然会带来重新运行解码阶段的额外成本,使其效率远低于我们的令牌粒度 WAL 方法。
5.2.4. 为百万令牌上下文扩展 RL 框架
我们引入了针对百万令牌序列上高效 RL 和 OPD 的针对性优化。在 rollout 阶段,我们采用了第 5.2.3 节中详细描述的可抢占且容错的 rollout 服务。对于推理和训练阶段,我们将 rollout 数据格式分解为轻量级元数据和每令牌的重度字段。在数据分发期间,可以加载整个 rollout 数据的元数据以执行全局混洗和打包布局计算。每令牌的重度字段通过共享内存数据加载器加载,以消除节点内数据冗余,并在以小批量粒度消费后立即释放,从而显著减轻 CPU 和 GPU 内存压力。设备上小批次的数量根据工作负载动态确定,从而在计算吞吐量和 I/O 重叠之间实现高效权衡。
5.2.5. 用于智能体 AI 的沙箱基础设施
为了满足后训练和评估期间智能体 AI 的多样化执行需求,我们构建了一个生产级沙箱平台 DeepSeek Elastic Compute (DSec)。DSec 包含三个 Rust 组件------API 网关 (Apiserver)、每主机代理 (Edge) 和集群监控器 (Watcher)------它们通过自定义 RPC 协议互连,并在 3FS 分布式文件系统 (DeepSeek-AI, 2025) 之上水平扩展。在生产环境中,单个 DSec 集群管理着数十万个并发沙箱实例。
DSec 的设计基于四个观察:(1) 智能体工作负载高度异构,涵盖轻量级函数调用到具有不同操作系统和安全要求的完整软件工程流水线;(2) 环境镜像数量众多且体积庞大,但必须快速加载并支持迭代定制;(3) 高密度部署要求高效的 CPU 和内存利用率;(4) 沙箱生命周期必须与 GPU 训练计划协调,包括抢占和基于检查点的恢复。基于这些观察,我们接下来分别阐述 DSec 的四个核心设计。
统一接口背后的四个执行底层 。DSec 暴露一个单一的 Python SDK (libdsec),它抽象了四个执行底层。函数调用将无状态调用分派到预热的容器池,消除了冷启动开销。容器完全兼容 Docker,并利用 EROFS(Gao 等人,2019)按需加载以实现高效的镜像组装。microVM 基于 Firecracker(Agache 等人,2020),为安全敏感、高密度部署增加了 VM 级隔离。fullVM 基于 QEMU(Bellard,2005),支持任意客户操作系统。所有四个共享一个共同的 API 表面------命令执行、文件传输和 TTY 访问------并且在它们之间切换仅需更改参数。
通过分层存储实现快速镜像加载 。DSec 通过分层的按需加载协调快速启动与庞大且不断增长的环境镜像语料库。对于容器,基础镜像和文件系统提交作为 3FS 支持、只读的 EROFS 层存储,直接挂载到 overlay 的 lowerdirs 中。我们在挂载时使文件元数据在本地磁盘上立即可用;同时,数据块在请求时从 3FS 获取。对于 microVM,DSec 使用 overlaybd(Li 等人,2020)磁盘格式:只读基础层位于 3FS 上以跨实例共享,而写入则进入本地的写时复制层。此类快照是可链接的,有助于高效版本控制和毫秒级恢复。
大规模并发下的密度优化 。为了容纳每个集群数十万个沙箱,DSec 解决了两个资源瓶颈。首先,它减轻了虚拟化环境中重复的页缓存占用,并应用内存回收以实现安全超卖。其次,它减轻了容器运行时中的自旋锁争用,从而降低了每个沙箱的 CPU 开销,显著提高了每主机的打包密度。
轨迹日志记录和可抢占安全恢复。DSec 为每个沙箱维护一个全局有序的轨迹日志,持久记录每个命令调用及其结果。该轨迹有三个目的:(1) 客户端快进------当训练任务被抢占时,沙箱资源仍然保留;恢复后,DSec 为先前完成的命令重放缓存的结果,加速任务恢复,同时也防止因重新执行非幂等操作而导致的错误;(2) 细粒度溯源------每个状态变化的来源和相应结果都是可追溯的;(3) 确定性重放------任何历史会话都可以从其轨迹忠实地重现。
5.3. 标准基准评估
5.3.1. 评估设置
知识与推理。知识与推理数据集包括 MMLU-Pro(Wang 等人,2024b)、GPQA(Rein 等人,2023)、Human Last Exam(Phan 等人,2025)、Simple-QA Verified(Haas 等人,2025)、Chinese-SimpleQA(He 等人,2024)、LiveCodeBench-v6(Jain 等人,2024)、CodeForces(内部基准)、HMMT 2026 Feb、Apex(Balunović 等人,2025)、Apex Shortlist(Balunović 等人,2025)、IMOAnswerBench(Luong 等人,2025)和 PutnamBench(Tsoukalas 等人,2024)。
对于代码,我们在 LiveCodeBench-v6 和一个内部 Codeforces 基准上评估 DeepSeek-V4 系列。对于 Codeforces,我们收集了 14 场 Codeforces Division 1 比赛,包含 114 个问题(2025年5月 - 2025年11月)。Elo 评分计算如下。对于每场比赛,我们为每个问题生成 32 个候选解。对于每个问题独立地,我们从这些解中无放回地抽取 10 个,并将它们随机排序以形成提交序列。每个提交都根据领域专家构建的测试套件进行评判。一个已解决问题的得分遵循 OpenAI(2025)的罚分方案:模型获得与解决了同一问题且先前失败尝试次数相同的人类参与者的中位数得分。这会为每个采样的提交序列产生一个比赛总分,然后将其转换为比赛排名,并通过标准的 Codeforces 评分系统进一步转换为估计的评分。比赛级别的预期评分定义为该估计评分在所有可能的 10 个提交的随机选择和排序上的期望。模型的整体评分是所有 14 场比赛中这些上下文级别预期评分的平均值。
对于推理和知识任务,我们将温度设置为 1.0,并为非思考、高和最大模式分别将上下文窗口设置为 8K、128K 和 384K 个令牌。对于数学任务(例如 HMMT、IMOAnswerBench、Apex 和 HLE),我们使用以下模板进行评估:"{问题}\n请逐步推理,并将最终答案放在 \boxed{} 中。" 对于 DeepSeek-V4-Pro-Max 在数学任务上,我们使用以下模板来激发更深入的推理:"解决以下问题。问题可能要求你证明一个陈述,或寻求一个答案。如果需要找到答案,你应该提出答案,并且你的最终解决方案也应该是该答案有效的严格证明。\n\n{问题}"。
对于形式数学任务,我们在 Lean v4.28.0-rcl(Moura and Ullrich,2021)上的智能体环境中进行评估,可以访问 Lean 编译器和语义战术搜索引擎,最多运行 500 次工具调用,并采用最大推理努力。此外,我们评估了一个计算更密集的流水线,其中首先生成候选的自然语言解决方案并通过自我验证(Shao 等人,2025)进行过滤,然后将保留的解决方案作为指导提供给形式智能体,以证明相应的 Lean 语句。该设计使用非形式推理来改进探索,同时通过形式验证保持严格正确性。只有在两种设置下,严格的验证器 Comparator 都接受该提交时,才将其计为正确。
对于 K2.6 和 GLM-5.1,我们留下了一些空白条目,因为它们的 API 太忙,无法响应我们的查询。
1M 令牌上下文。由于 DeepSeek-V4 系列支持 1M 令牌上下文,我们通过选择 OpenAI MRCR(OpenAI,2024b)和 CorpusQA(Lu 等人,2026)作为基准,在长上下文场景中评估模型性能。我们在这些任务上重新评估了 Claude Opus 4.6 和 Gemini 3.1 Pro,目标是标准化所有模型的配置。我们没有评估 GPT-5.4,因为其 API 未能响应我们的大部分查询。
智能体。智能体数据集包括 Terminal Bench 2.0(Merrill 等人,2026)、SWE-Verified(OpenAI,2024e)、SWE Multilingual(Yang 等人,2025)、SWE-Pro(Deng 等人,2025)、BrowseComp(Wei 等人,2025)、MCPAtlas 的公共评估集(Bandi 等人,2026)、GDPval-AA(AA,2025;Patwardhan 等人,2025)和 Tool-Decathlon(Li 等人,2025)。
对于代码智能体任务(SWE-Verified、Terminal-Bench、SWE-Pro、SWE Multilingual),我们使用内部开发的评估框架评估 DeepSeek-V4 系列。该框架提供了一组最少的工具------一个 bash 工具和一个文件编辑工具。最大交互步数设置为 500,最大上下文长度设置为 512K 个令牌。关于 Terminal-Bench 2.0,我们承认 GLM-5.1 指出的环境相关问题。尽管如此,我们为了保持一致性,在原始的 Terminal-Bench 2.0 数据集上报告我们的性能。在 Terminal-Bench 2.0 Verified 子集上,DeepSeek-V4-Pro 得分约为 72.0。
对于搜索智能体任务(BrowseComp、带工具的 HLE),我们也使用带有网络搜索和 Python 工具的内部测试平台,并将最大交互步数设置为 500,最大上下文长度设置为 512K 个令牌。对于 BrowseComp,我们使用与 DeepSeek-V3.2 相同的丢弃所有上下文管理策略(DeepSeek-AI,2025)。
5.3.2. 评估结果
表 6 | DeepSeek-V4-Pro-Max 与闭源/开源模型之间的比较。"Max"、"xHigh"和"High"表示推理努力。最佳结果以粗体突出显示;第二佳结果以下划线显示。
| 基准 (指标) | Opus-4.6 | GPT-5.4 | Gemini-3.1-Pro | K2.6 Thinking | GLM-5.1 | DS-V4-Pro Max |
|---|---|---|---|---|---|---|
| Max | Max xHigh | |||||
| MMLU-Pro (EM) | 89.1 | 87.5 | 91.0 | 87.1 | ||
| SimpleQA-Verified (Pass@1) | 46.2 | 45.3 | 75.6 | 36.9 | ||
| Chinese-SimpleQA (Pass@1) | 76.4 | 76.8 | 85.9 | 75.9 | ||
| GPQA Diamond (Pass@1) | 91.3 | 93.0 | 94.3 | 90.5 | ||
| HLE (Pass@1) | 40.0 | 39.8 | 44.4 | 36.4 | ||
| LiveCodeBench (Pass@1) | 88.8 | - | 91.7 | 89.6 | ||
| Codeforces (Rating) | - | 3168 | 3052 | - | ||
| HMMT 2026 Feb (Pass@1) | 96.2 | 97.7 | 94.7 | 92.7 | ||
| IMOAnswerBench (Pass@1) | 75.3 | 91.4 | 81.0 | 86.0 | ||
| Apex (Pass@1) | 34.5 | 54.1 | 60.9 | 24.0 | ||
| Apex Shortlist (Pass@1) | 85.9 | 78.1 | 89.1 | 75.5 | ||
| MRCR 1M (MMR) | 92.9 | - | 76.3 | - | ||
| CorpusQA 1M (ACC) | 71.7 | - | 53.8 | - | ||
| Terminal Bench 2.0 (Acc) | 65.4 | 75.1 | 68.5 | 66.7 | ||
| SWE Verified (Resolved) | 80.8 | - | 80.6 | 80.2 | ||
| SWE Pro (Resolved) | 57.3 | 57.7 | 54.2 | 58.6 | ||
| SWE Multilingual (Resolved) | 77.5 | - | - | 76.7 | ||
| BrowseComp (Pass@1) | 83.7 | 82.7 | 85.9 | 83.2 | ||
| HLE w/ tools (Pass@1) | 53.1 | 52.0 | 51.6 | 54.0 | ||
| GDPval-AA (Elo) | 1619 | 1674 | 1314 | 1482 | ||
| MCPAtlas Public (Pass@1) | 73.8 | 67.2 | 69.2 | 66.6 | ||
| Toolathlon (Pass@1) | 47.2 | 54.6 | 48.8 | 50.0 |
DeepSeek-V4-Pro-Max 与其他闭源/开源模型的比较呈现在表 6 中。此外,我们评估了 DeepSeek-V4-Flash 和 DeepSeek-V4-Pro 的不同模式,结果见表 7。
知识。在通用世界知识的评估中,DeepSeek-V4-Pro-Max(DeepSeek-V4-Pro 的最大推理努力模式)在开源大语言模型中建立了新的最先进水平。如 SimpleQA-Verified 所示,DeepSeek-V4-Pro-Max 显著优于所有现有的开源基线,领先幅度达 20 个绝对百分点。尽管取得了这些进步,它目前仍落后于领先的专有模型 Gemini-3.1-Pro。在教育知识和推理领域,DeepSeek-V4-Pro-Max 在 MMLU-Pro、GPQA 和 HLE 基准上略微优于 Kimi 和 GLM,尽管仍落后于领先的专有模型。总的来说,DeepSeek-V4-Pro-Max 在增强开源模型的世界知识能力方面标志着一个重要的里程碑。
此外,在基于知识的任务上,DeepSeek-V4-Flash 和 DeepSeek-V4-Pro 之间存在显著的性能差距;这是预期的,因为更大的参数数量有助于在预训练期间保留更多知识。值得注意的是,当分配更高的推理努力时,两个模型在知识基准上都显示出改进的结果。
表 7 | DeepSeek-V4 系列不同规模和模式之间的比较。"非思考"、"高"和"最大"表示推理努力。
| 基准 (指标) | DeepSeek-V4-Flash | DeepSeek-V4-Pro |
|---|---|---|
| 非思考 | 高 | |
| MMLU-Pro (EM) | 83.0 | 86.4 |
| SimpleQA-Verified (Pass@1) | 23.1 | 28.9 |
| Chinese-SimpleQA (Pass@1) | 71.5 | 73.2 |
| GPQA Diamond (Pass@1) | 71.2 | 87.4 |
| HLE (Pass@1) | 8.1 | 29.4 |
| LiveCodeBench (Pass@1-COT) | 55.2 | 88.4 |
| Codeforces (Rating) | - | 2816 |
| HMMT 2026 Feb (Pass@1) | 40.8 | 91.9 |
| IMOAnswerBench (Pass@1) | 41.9 | 85.1 |
| Apex (Pass@1) | 1.0 | 19.1 |
| Apex Shortlist (Pass@1) | 9.3 | 72.1 |
| MRCR 1M (MMR) | 37.5 | 76.9 |
| CorpusQA 1M (ACC) | 15.5 | 59.3 |
| Terminal Bench 2.0 (Acc) | 49.1 | 56.6 |
| SWE Verified (Resolved) | 73.7 | 78.6 |
| SWE Pro (Resolved) | 49.1 | 52.3 |
| SWE Multilingual (Resolved) | 69.7 | 70.2 |
| BrowseComp (Pass@1) | - | 53.5 |
| HLE w/ tools (Pass@1) | - | 40.3 |
| MCPAtlas Public (Pass@1) | 64.0 | 67.4 |
| GDPval-AA (Elo) | - | - |
| Toolathlon (Pass@1) | 40.7 | 43.5 |
推理。DeepSeek-V4-Pro-Max 在推理基准上优于所有先前开放模型,并在许多指标上与最先进的闭源模型持平,而较小的 DeepSeek-V4-Flash-Max 在代码和数学推理任务上也超越了先前最好的开源模型 K2.6-Thinking。同时,DeepSeek-V4-Pro 和 DeepSeek-V4-Flash 在编程竞赛中表现出色。根据我们的评估,它们的性能与 GPT-5.4 相当,这是开放模型首次在此任务上匹配闭源模型。在 Codeforces 排行榜上,DeepSeek-V4-Pro-Max 目前在人类参与者中排名第 23 位。DeepSeek-V4 在智能体设置和计算密集型设置下的形式数学任务上也表现出强劲的性能。在智能体设置下,它取得了最先进的结果,如图 8 所示,优于先前的模型,如 Seed Prover(Chen 等人,2025)。使用计算更密集的流水线,性能进一步提高,超越了包括 Aristotle(Achim 等人,2025)在内的系统,并匹配了此设置下的最佳已知结果。
智能体。DeepSeek-V4 系列在评估中表现出强大的智能体性能。对于代码智能体任务,DeepSeek-V4-Pro 取得了与 K2.6 和 GLM-5.1 相当的结果,尽管所有这些开放模型仍然落后于它们的闭源对手。DeepSeek-V4-Flash 在编码任务上的表现不如 DeepSeek-V4-Pro,尤其是在 Terminal Bench 2.0 上。在其他智能体评估中也观察到类似的趋势。值得注意的是,DeepSeek-V4-Pro 在 MCPAtlas 和 Toolathlon 上表现良好,这两个评估测试集包含范围广泛的工具和 MCP 服务,表明我们的模型具有出色的泛化能力,并不仅仅在内部框架上表现良好。

图 8 | 实践和前沿制度下的形式推理。左图:Putnam-200 Pass@8 评估了 PutnamBench(Tsoukalas 等人,2024)的一个固定随机子集,遵循 Seed-Prover 引入的设置;所有模型都在相同的问题集上测试。我们遵循 Seed-Prover 协议,但将专有搜索工具替换为开源的 LeanExplore(Asher,2025),产生了一个具有最少智能体工具和有界采样的轻量级设置。右图:Putnam-2025 探测了规模化混合形式-非形式制度下的数学推理前沿,其中非形式推理与形式验证相结合以暴露差距并提高严谨性;DeepSeek-V4 达到了 120/120 的完美证明。
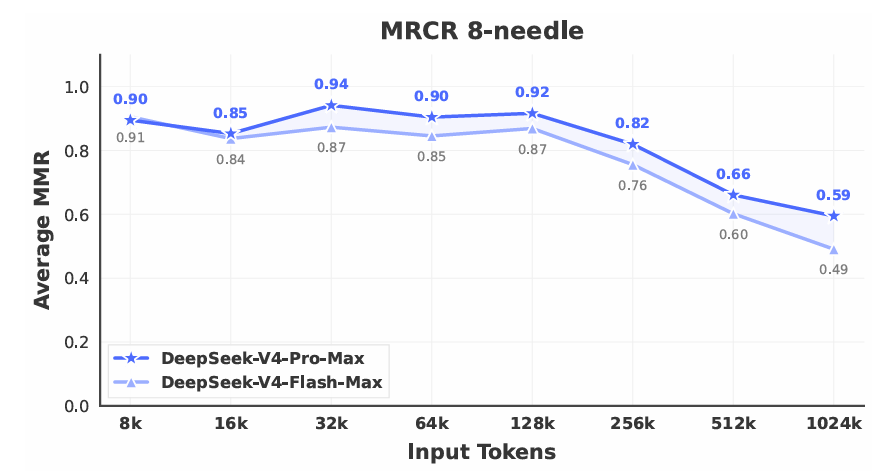
图 9 | DeepSeek-V4 系列在 MRCR 任务上的性能。
1M 令牌上下文。DeepSeek-V4-Pro 在衡量上下文内检索的 MRCR 任务上优于 Gemini-3.1-Pro,但仍落后于 Claude Opus 4.6。如图 9 所示,在 128K 上下文窗口内检索性能保持高度稳定。虽然在 128K 标记之后性能下降变得可见,但该模型在 1M 令牌处的检索能力与专有和开源对手相比仍然非常强大。与 MRCR 不同,CorpusQA 更类似于真实场景。评估结果也表明 DeepSeek-V4-Pro 优于 Gemini-3.1-Pro。
推理努力。如表 7 所示,在 RL 中采用更长上下文和减少长度惩罚的最大模式,在最具挑战性的任务上优于高模式。图 10 展示了 DeepSeek-V4-Pro、DeepSeek-V4-Flash 和 DeepSeek-V3.2 在代表性推理和智能体任务上的性能和成本比较。通过扩展测试时计算,DeepSeek-V4 系列比其前代模型实现了显著改进。此外,在 HLE 等推理任务上,DeepSeek-V4-Pro 展现出比DeepSeek-V3.2 更高的令牌效率。
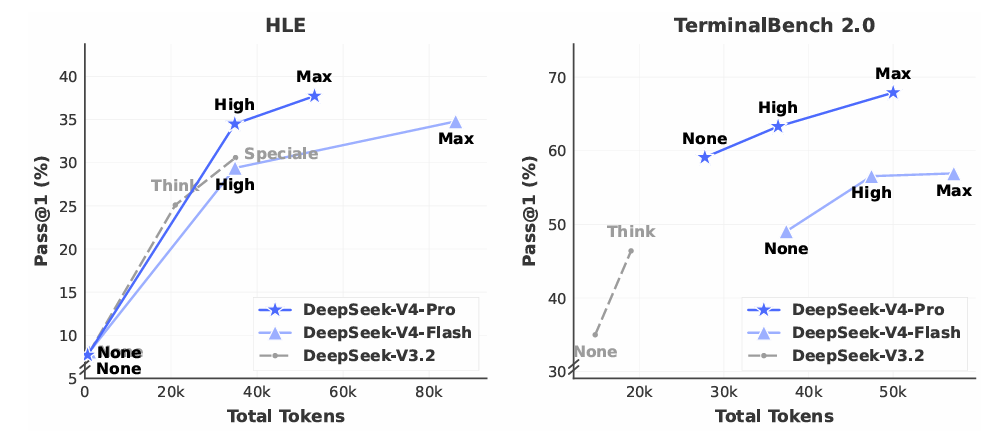
图 10 | 按推理努力划分的 HLE 和 Terminal Bench 2.0 性能。"None"表示非思考模式,"Speciale"表示 DeepSeek-V3.2-Speciale 模型。
5.4. 真实世界任务性能
标准化基准通常难以捕捉多样化真实世界任务的复杂性,在测试结果和实际用户体验之间产生了差距。为了弥合这一差距,我们开发了专有的内部指标,优先考虑真实世界使用模式而非传统基准。这种方法确保我们的优化转化为切实的好处。我们的评估框架专门针对 DeepSeek API 和 Chatbot 的主要用例,使模型性能与实际需求保持一致。
5.4.1. 中文写作
DeepSeek 的主要用例之一是中文写作。我们对功能写作和创意写作进行了严格的评估。表 12 展示了 DeepSeek-V4-Pro 和 Gemini-3.1-Pro 在功能写作任务上的成对比较。这些任务包括常见的日常写作查询,其中提示通常简洁明了。Gemini-3.1-Pro 被选为基线,因为在我们评估中,它是在中文写作方面表现最好的外部模型。结果表明,DeepSeek-V4-Pro 以 62.7%62.7\%62.7% 对比 34.1%34.1\%34.1% 的总体胜率优于基线;这主要是因为 Gemini 有时会允许其固有的风格偏好覆盖用户在中文写作场景中的明确要求。
表 13 展示了创意写作比较,它沿着两个轴进行评估:指令遵循和写作质量。与 Gemini-3.1-Pro 相比,DeepSeek-V4-Pro 在指令遵循上达到了 60.0%60.0\%60.0% 的胜率,在写作质量上达到了 77.5%77.5\%77.5%,表明在指令遵循上有边际改进,在写作质量上有显著提升。尽管 DeepSeek-V4-Pro 在总体用户案例分析中产生了更优的结果,但仅对最具挑战性的提示(特别是那些涉及高复杂度约束或多轮场景的提示)进行的评估显示,Claude Opus 4.5 相对于 DeepSeek-V4-Pro 仍然保持着性能优势。如表 14 所示,Claude Opus 4.5 达到了 52.0%52.0\%52.0% 的胜率,而 DeepSeek-V4-Pro 为 45.9%45.9\%45.9%。
5.4.2. 搜索
搜索增强的问答是 DeepSeek 聊天机器人的核心能力。在 DeepSeek 网页和应用上,"非思考"模式采用检索增强搜索(RAG),而"思考"模式利用智能体搜索。
检索增强搜索。我们对 DeepSeek-V4-Pro 和 DeepSeek-V3.2 在客观和主观问答类别上进行了成对评估。如表 11 所示,DeepSeek-V4-Pro 以显著优势优于 DeepSeek-V3.2,在两个类别上均表现出持续的优势。最显著的提升出现在单值搜索和规划与策略任务上,表明 DeepSeek-V4-Pro 擅长从检索到的上下文中定位精确的事实答案和综合结构化计划。然而,DeepSeek-V3.2 在比较和推荐任务上仍然相对具有竞争力,表明 DeepSeek-V4-Pro 在需要对搜索结果进行平衡、多视角推理的场景中还有改进空间。
智能体搜索。与标准 RAG 不同,智能体搜索使模型能够迭代地调用每个查询的搜索和获取工具,从而显著提高整体搜索性能。对于 DeepSeek-Chat 中的思考模式,我们优化了智能体搜索功能,以在预定义的"思考预算"内最大化响应准确性。如表 9 所示,智能体搜索始终优于 RAG,尤其是在复杂任务上。此外,其成本仍然非常高效,智能体搜索仅比标准 RAG 略贵(见表 10)。
5.4.3. 白领任务
为了严格评估模型在复杂企业生产力场景中的效用,我们构建了一个包含 30 个高级中文专业任务的综合套件。这些工作流程故意包含高层次的认知需求,包括深入的信息分析、全面的文档生成和细致的文档编辑,跨越了 13 个关键行业(如金融、教育、法律和科技)的多样化领域。评估是在一个内部智能体工具平台上进行的,该平台配备了基本工具,包括 Bash 和网络搜索。
鉴于这些任务的开放性,自动化指标通常无法捕捉到高质量响应的细微差别。因此,我们进行了人工评估,比较 DeepSeek-V4-Pro-Max 和 Opus-4.6-Max 的性能。注释者盲目地评估模型输出的四个维度:
- 任务完成度:核心问题是否成功解决。
- 指令遵循:是否遵守特定约束和指令。
- 内容质量:事实准确性、逻辑连贯性和专业语气。
- 格式美观度:布局可读性和视觉呈现。
如图 11 所示,DeepSeek-V4-Pro-Max 在多样的中文白领任务上优于 Opus-4.6-Max,实现了令人印象深刻的 63%63\%63% 非损失率,并在分析、生成和编辑任务上展现出持续的优势。图 12 所示的详细维度得分突显了该模型在任务完成度和内容质量方面的主要优势。具体来说,DeepSeek-V4-Pro-Max 通过频繁提供补充见解和自我验证步骤,主动预判用户的隐含意图。它还在生成长文本方面表现出色,提供深入、连贯的叙述,而不是依赖 Opus-4.6-Max 经常产生的过于简单的要点。此外,该模型严格遵守正式的专业惯例,例如标准的中文层级编号。然而,在指令遵循方面,它偶尔会忽略特定的格式约束,略微落后于 Opus。此外,该模型不太擅长将冗长的文本输入提炼为简洁的摘要。最后,其格式美观度在演示幻灯片的整体视觉设计方面仍有很大的改进空间。图 13、14 和 15 展示了几个测试案例;由于某些输出长度过长,仅显示部分页面。
图 11 | 分析、生成、编辑任务以及整体性能的胜率比较。 图 12 | 详细维度得分,包括任务完成度、内容质量、格式美观度和指令遵循。 图 13 | 一个需要为知名珍珠奶茶品牌和北京地铁起草联合营销提案的任务输出示例。
5.4.4. 代码智能体
为了对我们的代码智能体能力进行基准测试,我们从真实的内部研发工作负载中策划了任务。我们从 50+50+50+ 名内部工程师那里收集了 ∼200\sim 200∼200 个具有挑战性的任务,涵盖功能开发、错误修复、重构和诊断,涉及多种技术栈,包括 PyTorch、CUDA、Rust 和 C++\mathbb{C} + +C++。每个任务都附有其原始仓库、相应的执行环境以及人工注释的评分标准;经过严格的质量过滤后,保留了 30 个任务作为评估集。如表 8 所示,DeepSeek-V4-Pro 显著优于 Claude Sonnet 4.5,并接近 Claude Opus 4.5 的水平。
表 8 | 研发编码基准比较(包含外部模型仅用于评估目的)。
| 模型 | Haiku 4.5 | Sonnet 4.5 | DeepSeek-V4-Pro-Max | Opus 4.5 | Opus 4.5 Thinking | Opus 4.6 Thinking |
|---|---|---|---|---|---|---|
| 通过率 (%) | 13 | 47 | 67 | 70 | 73 | 80 |
在一项对 DeepSeek 开发者和研究人员(N=85N = 85N=85)的调查中------他们都有在日常工作中使用 DeepSeek-V4-Pro 进行智能体编码的经验------询问与其他前沿模型相比,DeepSeek-V4-Pro 是否已准备好作为他们的默认和主要编码模型,52%52\%52% 回答是,39%39\%39% 倾向于肯定,不到 9%9\%9% 回答否。受访者发现 DeepSeek-V4-Pro 在大多数任务上都能提供令人满意的结果,但指出存在琐碎的错误、对模糊提示的误解以及偶尔的过度思考。
6. 结论、局限性与未来方向
在这项工作中,我们展示了 DeepSeek-V4 系列的预览版本,旨在打造突破超长上下文处理效率障碍的下一代大语言模型。通过结合集成 CSA 和 HCA 的混合注意力架构,DeepSeek-V4 系列在长序列效率方面实现了巨大飞跃。架构创新与广泛的基础设施优化相结合,实现了对百万令牌上下文的高效原生支持,并为未来的测试时扩展、长期任务以及在线学习等新兴范式奠定了必要的基础。评估结果表明,DeepSeek-V4-Pro-Max(DeepSeek-V4-Pro 的最大推理努力模式)重新定义了开放模型的最先进水平。它在知识基准上显著优于先前的开源模型,实现了接近前沿专有模型的卓越推理性能,并提供了具有竞争力的智能体能力。同时,DeepSeek-V4-Flash-Max 在保持高度成本效益架构的同时,取得了与领先闭源模型相当的推理性能。我们相信 DeepSeek-V4 系列为开放模型开启了百万长度上下文的新时代,并为实现更高的效率、规模和智能铺平了道路。
在追求极致长上下文效率的过程中,DeepSeek-V4 系列采用了大胆的架构设计。为了最小化风险,我们保留了许多经过初步验证的组件和技巧,虽然有效,但也使得架构相对复杂。在未来的迭代中,我们将进行更全面、更原则性的研究,将架构提炼到最核心的设计,使其在不牺牲性能的前提下更加优雅。同时,尽管预期路由和 SwiGLU 钳位已被证明能有效缓解训练不稳定性,但其基本原理仍未得到充分理解。我们将积极研究训练稳定性的基础性问题,并加强内部指标监控,旨在实现更原则性、更具预测性的大规模稳定训练。
此外,除了 MoE 和稀疏注意力架构,我们还将主动探索新的维度上的模型稀疏性------例如更稀疏的嵌入模块(Cheng 等人,2026)------以在不影响能力的情况下进一步提高计算和内存效率。我们还将持续研究低延迟架构和系统技术,使长上下文的部署和交互响应更快。此外,我们认识到长期、多轮智能体任务的重要性和实用价值,并将继续朝这个方向迭代和探索。我们也在努力将多模态能力整合到我们的模型中。最后,我们致力于开发更好的数据策划和合成策略,以持续增强模型在日益广泛的场景和任务中的智能性、鲁棒性和实用可用性。