2.6 大模型的推理策略
大语言模型的输出是一个 token 接着一个 token 逐步生成的 。在最终决定输出哪个 token 时,模型主要衍生出了以下几种经典的推理策略 :
2.6.1 贪心解码 (Greedy Decoding)
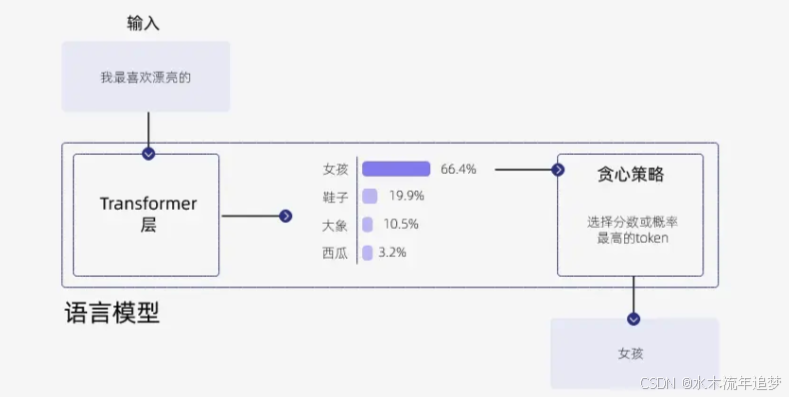
核心逻辑: 在生成的每一步,直接选择概率最高的那个单词 。例如,如果"女孩"的概率是 66.4%,"鞋子"是 19.9%,模型就会无脑选择"女孩" 。
优缺点: 这种方法非常简单高效,但致命的缺点是容易导致生成的文本过于单调、死板,并且极易出现重复的废话 。
2.6.2 集束搜索 (Beam Search)
集束搜索是对贪心策略的一种有效改进 。
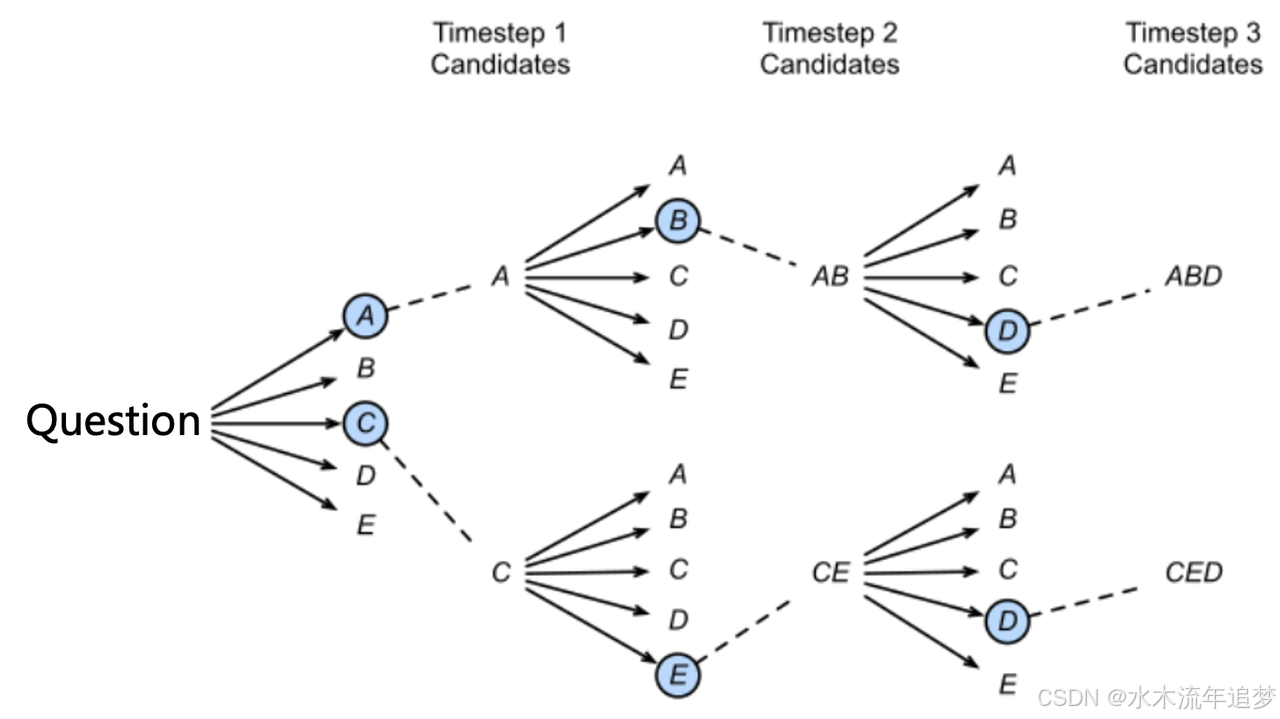
核心逻辑: 它的思路是稍微放宽考察的范围 。在每一个时间步,不再像贪心解码那样只保留当前分数最高的 1 个输出,而是同时保留 num_beams 个候选序列
特点: 当 num_beams=1 时,集束搜索实际上就退化成了贪心搜索 。
Beam Search 算法示例代码:
python
import torch
def beam_search(decoder,
sos_token,
eos_token,
vocab_size,
hidden_size,
k=3,
max_length=50):
"""
Beam Search(束搜索)算法实现,用于序列生成任务
与贪心搜索只保留最佳候选不同,束搜索保留top-k个最佳候选,平衡了性能和计算成本
参数:
decoder: 解码器模型,输入为(prev_words, hidden),输出为(outputs, hidden)
sos_token: 序列开始符号的ID
eos_token: 序列结束符号的ID
vocab_size: 词汇表大小
hidden_size: 解码器隐藏层维度大小
k: beam size(束大小),每次保留的候选序列数量
max_length: 最大序列长度,防止生成无限长序列
"""
# 初始化:每个beam序列都以SOS(开始符号)开头
# 创建形状为(k, 1)的张量,填充sos_token
k_prev_words = torch.full((k, 1), sos_token, dtype=torch.long) # (k, 1)
# 初始化序列集合,一开始每个序列都只包含SOS
seqs = k_prev_words # (k, 1)
# 初始化每个候选序列的分数为0
top_k_scores = torch.zeros(k, 1)
# 存储已完成的序列(包含EOS的序列)及其对应的分数
complete_seqs = []
complete_seqs_scores = []
# 记录当前解码步骤
step = 1
# 初始化解码器隐藏状态,形状为(1, k, hidden_size)
# 第一个维度是LSTM层数*方向数,这里用1表示单层单向
hidden = torch.zeros(1, k, hidden_size)
# 解码循环,直到所有序列完成或达到最大长度
while True:
# 将上一步的词和隐藏状态输入解码器,得到输出和新的隐藏状态
# outputs形状: (k, seq_len, vocab_size)
# hidden形状: (1, k, hidden_size)
outputs, hidden = decoder(k_prev_words, hidden)
# 取最后一个时间步的输出,即当前步的预测结果
# 形状变为(k, vocab_size)
next_token_logits = outputs[:, -1, :]
# 将输出转换为对数概率,避免数值下溢
log_probs = torch.log_softmax(next_token_logits, dim=1)
if step == 1:
# 第一步特殊处理:初始时只有一个有效序列(全部是SOS)
# 从第一个序列的预测结果中取top-k个词
top_k_scores, top_k_words = log_probs[0].topk(k, dim=0, largest=True, sorted=True)
# 所有候选都来自第0个初始序列
prev_word_inds = torch.zeros(k, dtype=torch.long)
else:
# 后续步骤:需要合并历史分数和当前分数
# 累加log概率(相当于概率相乘)
cumulative_scores = top_k_scores + log_probs
# 展平分数张量,以便全局选取top-k
flat_scores = cumulative_scores.view(-1)
# 选取全局top-k个最高分及其索引
top_k_scores, top_k_indices = flat_scores.topk(k, 0, True, True)
# 计算这些候选来自哪个beam(前一个词的索引)
prev_word_inds = (top_k_indices // vocab_size).long() # (k)
# 计算当前预测的词索引
top_k_words = (top_k_indices % vocab_size).long() # (k)
# 确保索引在有效范围内,防止越界错误
prev_word_inds = torch.clamp(prev_word_inds, 0, seqs.size(0) - 1)
# 更新序列:将前序序列与新预测的词拼接起来
# 形状从(k, step)变为(k, step+1)
seqs = torch.cat([seqs[prev_word_inds], top_k_words.unsqueeze(1)], dim=1)
# 区分已完成和未完成的序列
incomplete_inds = [] # 未完成序列的索引
complete_inds = [] # 已完成序列的索引
# 检查每个新预测的词是否是EOS
for ind, next_word in enumerate(top_k_words):
if next_word == eos_token:
# 如果是EOS,标记为已完成序列
complete_inds.append(ind)
else:
# 否则,继续保留为未完成序列
incomplete_inds.append(ind)
# 处理已完成的序列:加入到完成序列列表中
if len(complete_inds) > 0:
# 将完成的序列转换为列表并添加到集合中
complete_seqs.extend(seqs[complete_inds].tolist())
# 保存对应的分数
complete_seqs_scores.extend(top_k_scores[complete_inds])
# 更新beam size:减去已完成的序列数量
k -= len(complete_inds)
# 终止条件:所有序列都已完成,或达到最大长度
if k == 0 or step >= max_length:
break
# 准备下一轮迭代的数据:只保留未完成的序列
seqs = seqs[incomplete_inds]
# 更新隐藏状态,只保留未完成序列对应的隐藏状态
hidden = hidden[:, prev_word_inds[incomplete_inds], :]
# 更新分数,只保留未完成序列的分数
top_k_scores = top_k_scores[incomplete_inds].unsqueeze(1)
# 更新下一轮的输入词
k_prev_words = top_k_words[incomplete_inds].unsqueeze(1)
# 步骤加1
step += 1
# 如果没有任何完成的序列(都没生成EOS)
if not complete_seqs:
if len(seqs) > 0:
# 从剩余序列中选择分数最高的一个
max_score_idx = torch.argmax(top_k_scores).item()
return seqs[max_score_idx].tolist()
else:
# 极端情况:返回一个最小序列[SOS, EOS]
return [sos_token, eos_token]
# 从完成的序列中选择分数最高的序列作为结果
max_score_idx = complete_seqs_scores.index(max(complete_seqs_scores))
return complete_seqs[max_score_idx]
# 示例解码器类(用于测试beam search)
class SimpleDecoder:
def __call__(self, input_ids, hidden):
"""
简单的解码器实现,仅用于测试
在实际应用中,这应该是真实的神经网络解码器
"""
batch_size, seq_len = input_ids.shape
# 简单起见,假设hidden_size等于vocab_size
vocab_size = hidden.size(-1)
# 生成随机输出(实际中应该是模型的预测结果)
outputs = torch.randn(batch_size, seq_len, vocab_size)
# 简单更新隐藏状态(实际中应该是LSTM/Transformer的输出)
new_hidden = hidden + torch.randn_like(hidden) * 0.1
return outputs, new_hidden
# 使用示例
if __name__ == "__main__":
# 配置参数
SOS_TOKEN = 0 # 开始符号ID
EOS_TOKEN = 1 # 结束符号ID
VOCAB_SIZE = 100 # 词汇表大小
HIDDEN_SIZE = 128# 隐藏层大小
BEAM_SIZE = 5 # beam大小
MAX_LENGTH = 20 # 最大序列长度
# 初始化解码器(实际应用中替换为真实模型)
decoder = SimpleDecoder()
# 执行beam search生成序列
generated_sequence = beam_search(
decoder=decoder,
sos_token=SOS_TOKEN,
eos_token=EOS_TOKEN,
vocab_size=VOCAB_SIZE,
hidden_size=HIDDEN_SIZE,
k=BEAM_SIZE,
max_length=MAX_LENGTH
)
print("生成的序列:", generated_sequence)
2.6.3 Top-K 采样
Top-K 采样是对贪心策略的另一种优化 。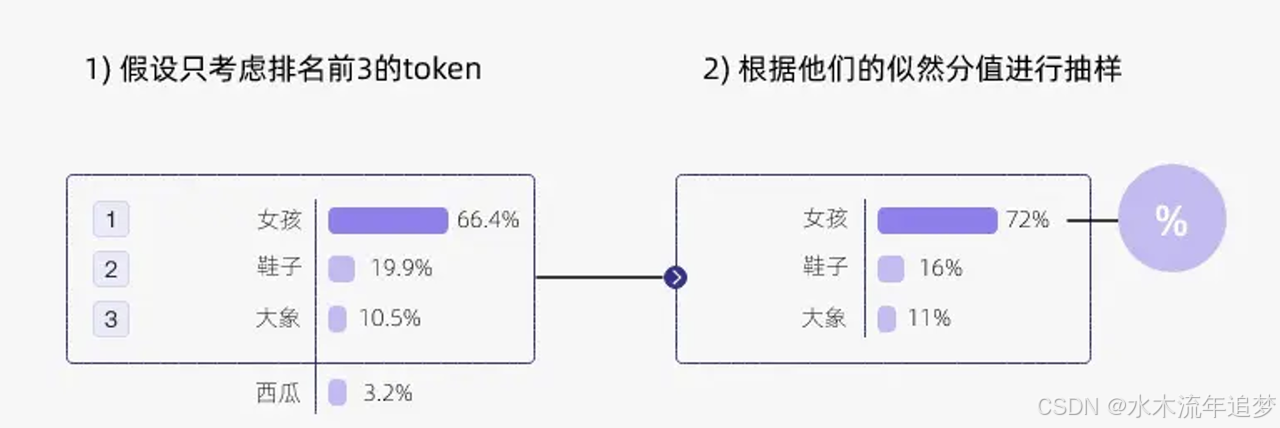
核心逻辑: 在生成 token 的每一步,只从概率排名前 K 的单词中进行随机采样,而不考虑其他排名靠后的低概率单词 。例如当 K=3 时,模型只会在概率前三的词汇中进行随机抽取 。
优势: 这种抽样带来的随机性不仅允许概率较高的其他 token 有机会被选中,避免了采样到不合适或不相关的单词,同时还能保留一些有趣或有创意的表述 。
2.6.4 Top-P 采样 (核采样)
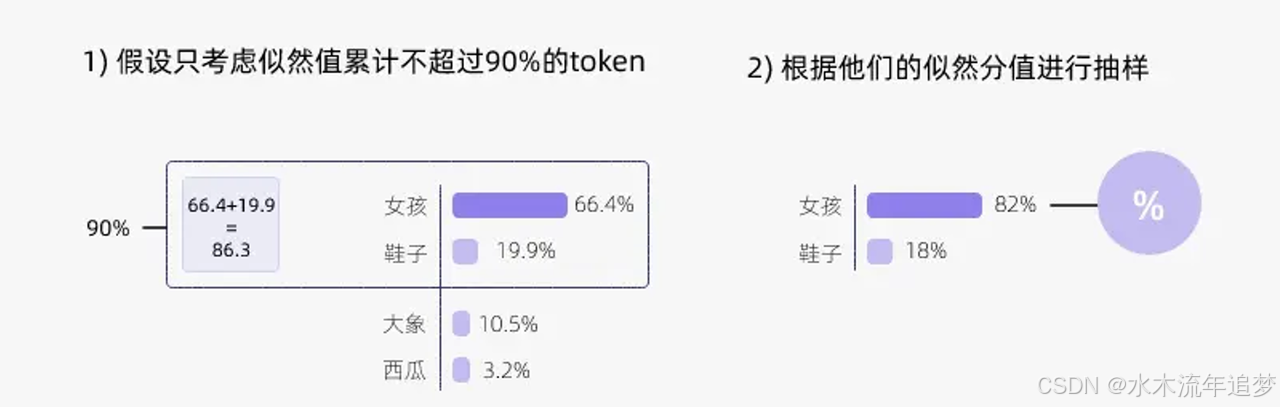
痛点: Top-K 有一个明显的缺陷,那就是"K 值取多少才是最优的?"非常难确定 。
核心逻辑: 于是出现了动态设置 token 候选列表大小的策略 。Top-P 的具体做法是在每一步,按照概率从高到低排序累加,只从累积概率超过某个指定阈值(P)的最小单词集合中进行随机采样 。
优势: 比如设置 P=0.9,模型就会过滤掉累积概率在 0.9 以外的尾部低概率词 。这种方法只关注概率分布的核心部分,从而既增加了输出的多样性,又避免了低质量内容的产生 。
2.6.5 Temperature (温度)
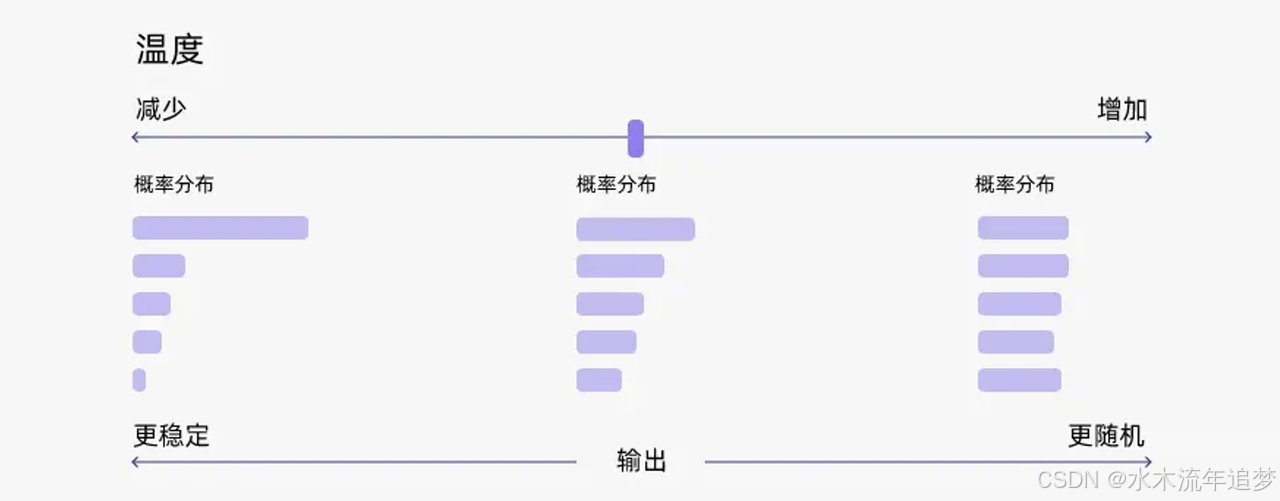
温度参数用于告诉模型如何在"生成质量"和"多样性"之间进行权衡 :
低温度 (< 1,如 0.2 或 0.5): 意味着更高的质量 。它使模型更具信心,将大部分概率集中在最有可能的下一个词上,结果输出更连贯、重复性更高,但创造力或探索性较低 。当 Temperature 设置为 0 时,模型总是选择最高概率分数的 token(即退化为贪心策略) 。
高温度 (> 1): 意味着更高的多样性 。它让 token 的概率分布变得更加平滑和均匀,使模型的预测更加分散和"不确定",从而更频繁地从低概率词中采样,生成更具创造性、探索性和"惊喜"的输出 。
本质认知: 很多人以为温度直接等同于"创造力",但其实温度的本质仅仅是调整了单词的概率分布 。其宏观效果是:低温度下模型更具确定性,高温度下则不那么确定 。
2.6.6 Frequency Penalty & Presence Penalty
这两种惩罚机制是另一种平衡质量和多样性的利器 :
频率惩罚 (Frequency Penalty): 让 token 每次在文本中出现都受到惩罚,且惩罚会进行累计 。
存在惩罚 (Presence Penalty): 如果一个 token 已经在文本中出现过,就会受到一次固定惩罚 。
与温度的区别: Temperature 是通过改变全局的概率分布来实现多样性,而这两个参数则是对"旧的和过度使用的 token"施加精准打击,使其被再次选中的几率降低,从而逼迫模型选择更新颖的 token 。
2.6.7 参数协同与实战调参
在实际应用中,我们通常会将 Top-K、Top-P、Temperature 联合起来使用 。它们在底层执行的先后顺序通常是:Top-K -> Top-P -> Temperature 。
- 例如:首先使用 Top-K 选取概率前 50 的 token -> 然后使用 Top-P 保留概率累计和达到 0.7 的单词 -> 最后使用 Temperature=0.7 或 1.5 重新归一化分布并采样 。
实战调参指南:
-
追求精准答案: 对于每个提示语只需要单个标准答案时,可将 Temperature、频率惩罚和存在惩罚全部设置为 0 。若需要发散、多样的回答,则将其设为大于 0 的值 。
-
解决胡言乱语: 如果模型输出了太多无意义的垃圾内容或产生幻觉,应当降低 temperature 并降低 top-p/top-k 。
-
解决回答死板: 如果 temperature 已经调得很高,但模型输出的多样性依然很低,应当尝试增加 top-p/top-k 。
-
提升话题发散度: 为了获得更多样化的主题,应当增加 存在惩罚 (Presence Penalty) 。为了获得重复内容更少的输出,应当增加频率惩罚 (Frequency Penalty) 。
-
终极融合: 在一些复杂的序列生成任务中,还可以在 Beam Search 的基础上叠加以上策略,生成多个序列后再择优输出 。