学习来源:labuladong算法教程
AI写代码的效果,核心取决于两大关键:LLM大模型本身的能力上限,以及围绕模型构建的Agent工程实现成熟度。前者决定"智商",后者决定"执行力",二者结合才能产出高质量代码。
一、核心概念区分:LLM与AI编程Agent
1. LLM(大语言模型)
代表模型:Qwen、Claude、Deepseek等,是AI的"大脑",负责语言理解、逻辑推理与文本生成。
2. AI编程Agent(智能体)
代表工具:Cursor、Antigravity、Claude Code等,是LLM的"手脚"。
本质是"LLM+工具调用+循环决策"的工程化产物,能自主完成读文件、写代码、跑测试、排错等全流程任务。
二、LLM底层原理:不是"理解",是精准的概率匹配
1. 核心本质:概率预测模型
LLM的核心逻辑是根据已有文本,预测下一个token(字/词)出现的概率,属于统计意义上的模式匹配,并非真正"理解"语义。
- 规模效应:参数量越大、训练数据越海量(涵盖文本、代码等),概率预测越精准,表现越像"能理解";
- 推理特性:直接给答案易出错,先写推理过程、再给结论,准确率大幅提升(相当于"打草稿")。
2. 关键参数:控制输出的"确定性"与"创造性"
(1)Temperature(温度)
- 作用:控制模型选字的随机程度;
- 温度=0:每次选概率最大的token,输出最确定、最保守(适合写代码、严谨任务);
- 温度调高:倾向选低概率token,输出更有创意、更不可控(适合文案、创意写作)。
(2)Context(上下文)
-
定义:模型预测下一个token时依赖的所有文本(输入问题、对话历史、系统设定);
-
窗口限制:上下文有固定长度(窗口),超出会"遗忘"早期内容;
-
压缩技巧:将早期对话总结为摘要,保留关键信息、丢弃细节,节省窗口空间。
3. 模型进化:从Base到Instruct,再到RLHF
(1)Base模型(基础模型)
- 功能:纯概率预测,做文本补全(输入半句话,续后半句);
- 缺陷:无法理解指令,不能直接回答问题。
(2)Instruct模型(指令模型)
- 升级:在Base模型基础上,用指令-回答数据对微调,再经RLHF优化;
- 能力:能识别指令、回答问题,效果质的飞跃,训练成本远低于预训练。
(3)RLHF(人类反馈强化学习)
- 流程:模型对同一问题生成多个回答→人类打分排序→模型根据打分调整策略;
- 价值:让模型明确"用户输入是指令,不是待续写文本",输出更贴合人类需求。
4. 推理加速:思维链(CoT)与思考强度
(1)CoT(思维链)
- 本质:用更多计算量换更高准确率,强制模型输出分步推理过程;
- 效果:每一步中间结果成为后续输入,逻辑更严谨,代码错误率降低。
(2)思考强度参数
- 作用:单一模型内调节推理深度;
- 强度高:反复推演、多步骤验证,准确率高但耗token;
- 强度低:直接给答案,速度快、省token;
- 优势:无需切换模型,一个API调用按需调档。
三、Agent工程核心:让LLM"动起来"的关键技术
Agent的核心是LLM+Tool Use(工具调用)放入循环,智能来自两方面:模型推理能力(想对下一步)+工具能力(把想法变行动)。
1. Tool Use(工具调用):LLM的"外接能力"
- 本质:LLM输出结构化工具调用请求(如JSON),外围程序解析并执行,结果返回上下文;
- 关键:模型不直接调用API,只输出"调用意图",执行靠代码,结果靠上下文流转;
- 价值:让LLM突破"纯文本限制",能读文件、跑命令、查数据、改代码。
2. System Prompt:定义Agent的"行为规则"
- 作用:设定模型不可绕过的规则(如"只写Python代码""代码必须加注释");
- 地位:Agent的"行为准则",直接决定输出风格与合规性。
3. ReAct模式:Agent的"思考-行动"循环
- 流程:思考(Reasoning)→行动(Acting)→观察结果→再思考,循环往复直到任务完成;
- 案例:写代码→跑测试→发现报错→分析原因→改代码→再测试,全流程自主闭环。
4. Skills:可复用的"工作流程SOP"
- 本质:把复杂任务流程写成文档(如"代码审查流程""PR处理流程"),Agent按文档分步执行;
- 价值:无需重复指令,一次定义、多次复用,降低使用成本;
- 渐进式披露:启动时只给Skill名称+简介,任务相关时再加载完整内容,节省上下文。
5. MCP(模型上下文协议):工具互通的"标准化接口"
由Anthropic推出,核心解决工具碎片化、适配成本高的问题,堪称AI界的"USB-C接口"。
MCP完整协议流程:
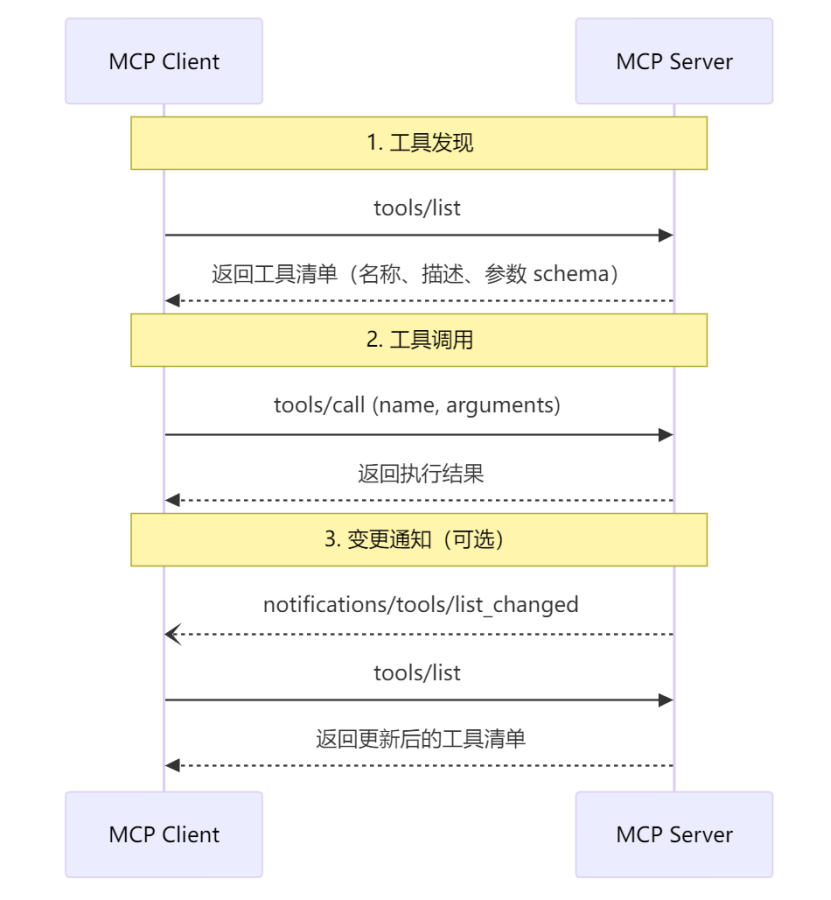
(1)核心架构:Client-Server
- Server:封装工具/认证信息,暴露标准化接口(如文件读写、数据库查询);
- Client:Agent(Claude Code、Cursor)内置客户端,自动发现并调用Server工具。
(2)三大核心能力
- Tools:可执行函数(如跑命令、改代码);
- Resources:只读数据(如文件、文档);
- Prompts:可复用提示模板。
(3)价值
- 标准化:M个Agent适配N个工具,复杂度从M×N降至M+N;
- 易扩展:无需重复开发接口,直接接入生态工具(如GitHub私有库、公司内部文档)。
四、上下文管理:Agent性能的"决胜关键"
模型能力固定时,上下文塞什么、怎么塞、塞多少,直接决定Agent表现。
核心矛盾:有限窗口内,最大化信息利用率。
1. 最佳实践
- 单窗口单任务:一个上下文只聚焦一个问题,新问题开新窗口,避免信息混杂;
- 精简输入:只保留核心指令、必要参考代码,删除冗余对话;
- 结果压缩:工具返回结果后,提炼关键信息再喂回上下文,减少token消耗。
2. 常见误区
- 上下文越长越好:过长会导致"信息稀释",模型抓不住重点,且成本飙升;
- 重复指令:反复强调同一要求,占用窗口空间,无实际收益。
五、高级技巧:多Agent协作与自定义Agent
1. Sub Agent(子智能体):分工提效
- 用法:主Agent指令"用Sub Agent分别调研需求、写代码、做测试,再汇总";
- 优势:分工明确、并行处理,复杂任务效率更高;
- 成本:每个Sub Agent有独立上下文,token消耗随数量增加,需权衡性价比。
2. 自定义Agent:沉淀高频流程
- 场景:重复代码审查、PR处理、部署流程;
- 做法:把固定流程+规则封装成自定义Agent,一次配置、终身复用,无需每次重复说明。
六、实践:Deepseek API调用
1. 基础调用(curl)
接口格式其实只是一种约定。
AI对话,本质其实就是往一个接口发一个JSON数组。
bash
OpenAI格式:
CMD版本:
curl -H "Content-Type: application/json" -H "Authorization: Bearer sk-" -d "{\"model\":\"deepseek-v4-flash\",\"messages\":[{\"role\":\"system\",\"content\":\"你是一个友好的助手。\"},{\"role\":\"user\",\"content\":\"你好。\"}],\"thinking\":{\"type\":\"disabled\"}}" https://api.deepseek.com/chat/completions
PowerShell版本:
curl 'https://api.deepseek.com/chat/completions' `
-H 'Content-Type: application/json' `
-H 'Authorization: Bearer sk-XXXXXXXXXXXXXXXXXXXXXX' `
-d '{
"model": "deepseek-v4-flash",
"messages": [
{"role": "system", "content": "你是一个友好的助手。"},
{"role": "user", "content": "你好。"}
],
"thinking": {"type": "disabled"}
}'
JSON返回:
{
"id":"61c33487-bb99-40d7-b3b2-b857dce1a517",
"object":"chat.completion",
"created":1777447577,
"model":"deepseek-v4-flash",
"choices":[
{
"index":0,
"message":{
"role":"assistant",
"content":"你好!很高兴见到你。有什么我可以帮你的吗?"
},
"logprobs":null,
"finish_reason":"stop"
}
],
"usage":{
"prompt_tokens":11,
"completion_tokens":12,
"total_tokens":23,
"prompt_tokens_details":{
"cached_tokens":0
},
"prompt_cache_hit_tokens":0,
"prompt_cache_miss_tokens":11
},
"system_fingerprint":"fp_058df29938_prod0820_fp8_kvcache_20260402"
}
Anthropic格式:
CMD:
curl https://api.deepseek.com/anthropic/v1/messages -H "Content-Type: application/json" -H "x-api-key: sk-XXXXXXXXXXXXXXXXXXX" -H "anthropic-version: 2023-06-01" -d "{\"model\":\"deepseek-v4-flash\",\"max_tokens\":256,\"system\":\"你是一个友好的助手。\",\"messages\":[{\"role\":\"user\",\"content\":\"你好。\"}],\"thinking\":{\"type\":\"disabled\"}}"
PowerShell:
curl https://api.deepseek.com/anthropic/v1/messages `
-H "Content-Type: application/json" `
-H "x-api-key: sk-XXXXXXXXXXXXXXXXXXXX" `
-H "anthropic-version: 2023-06-01" `
-d '{
"model": "deepseek-v4-flash",
"max_tokens": 256,
"system": "你是一个友好的助手。",
"messages": [
{"role": "user", "content": "你好。"}
],
"thinking": {"type": "disabled"}
}'
返回JSON:
{
"id":"aa417bfd-df5f-4efa-8136-071db8ecf0ec",
"type":"message",
"role":"assistant",
"model":"deepseek-v4-flash",
"content":[
{"type":"text","text":"你好!很高兴见到你。今天有什么我可以帮忙的吗?"}
],
"stop_reason":"end_turn",
"stop_sequence":null,
"usage":{
"input_tokens":11,
"cache_creation_input_tokens":0,
"cache_read_input_tokens":0,
"output_tokens":12,
"service_tier":"standard"
}
}2. 流式传输(SSE)
- 作用:逐字输出、防超时,适合长代码生成;
- 注意:流式不生效时,检查数据到达节奏 与缓冲层位置,排查网络或代理问题。
七、总结
AI写代码的本质,是**概率模型(LLM)+工程化执行(Agent)**的组合:
- LLM决定上限:靠规模、CoT、RLHF提升推理能力;
- Agent决定下限:靠Tool Use、MCP、上下文管理保障执行力;
- 核心决胜点:有限上下文内,高效组织信息、精准调用工具。