YOLOv11 模型架构深度梳理
YOLO 系列作为目标检测领域最经典的 one-stage 方法,经历了从 v1 到 v11 的持续演进。每一次迭代都在速度-精度权衡上做出改进:
- YOLOv8(2023):引入 C2f 模块取代 C3,解耦头(Decoupled Head),Anchor-Free
- YOLOv9(2024):提出 PGI(Programmable Gradient Information)和 GELAN 架构,解决信息瓶颈问题
- YOLOv10(2024):提出 NMS-Free 训练,引入一致匹配度量,消除对 NMS 的后处理依赖
- YOLOv11 (2024):在 v8 基础上进一步精简结构------用 C3k2 替代 C2f,新增 C2PSA 注意力模块,优化 Neck 路径,在同等参数量下取得更好的精度
YOLOv11 的设计哲学可以概括为:回归简洁。它没有像 v9/v10 那样引入复杂的训练策略(PGI、NMS-Free),而是在 v8 的成熟框架上做"减法"------简化模块、优化结构、提升效率。
下面我们从每个基础模块入手,逐层拆解 YOLOv11 的网络设计。
二、基础模块详解
Conv层
卷积层是 YOLOv11 中最基本的构建单元。与 YOLOv8 一致,采用 Conv + BatchNorm + SiLU 的三段式结构:
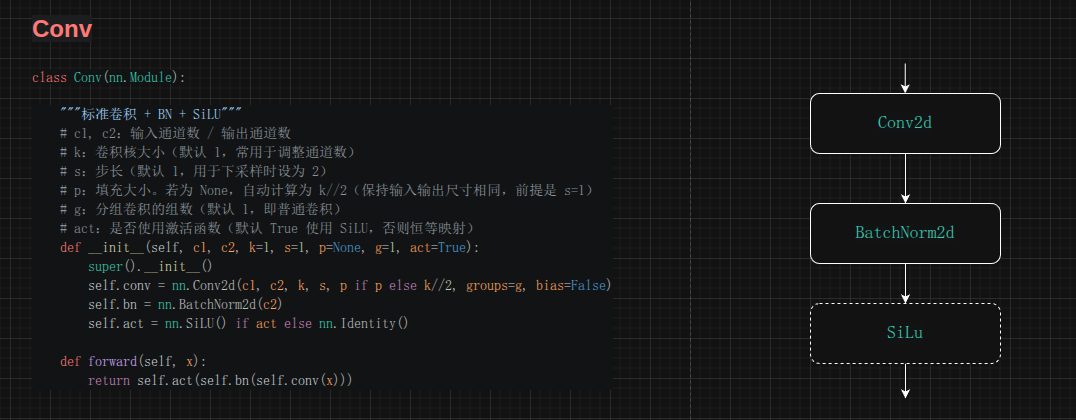
设计要点:
- SiLU 激活函数 :f(x)=x⋅σ(x)f(x) = x \cdot \sigma(x)f(x)=x⋅σ(x),相比 ReLU 的硬截断,SiLU 在负半轴有平滑的非零梯度,有利于梯度流动。虽然计算量略高于 ReLU,但在深层网络中通常能带来更好的收敛效果
- Bias=False :卷积层后紧跟 BN,BN 本身带有可学习的缩放(γ\gammaγ)和偏移(β\betaβ),卷积层的 bias 是冗余的,去掉可以节省参数
- 自动 Padding :
p = k // 2保证 stride=1 时输入输出尺寸不变,这是典型的 "same" 填充策略
Conv 在 YOLOv11 中承担两个角色:特征提取 (k=3, s=1)和下采样(k=3, s=2),以及通道数调整(k=1, s=1)。
C3k2层
C3k2 是 YOLOv11 最核心的模块,它替代了 YOLOv8 中的 C2f。从命名上可以看出:"C3" 表示 CSP 结构的第三个变体,"k2" 表示可以选用 2 种不同的内部模块。
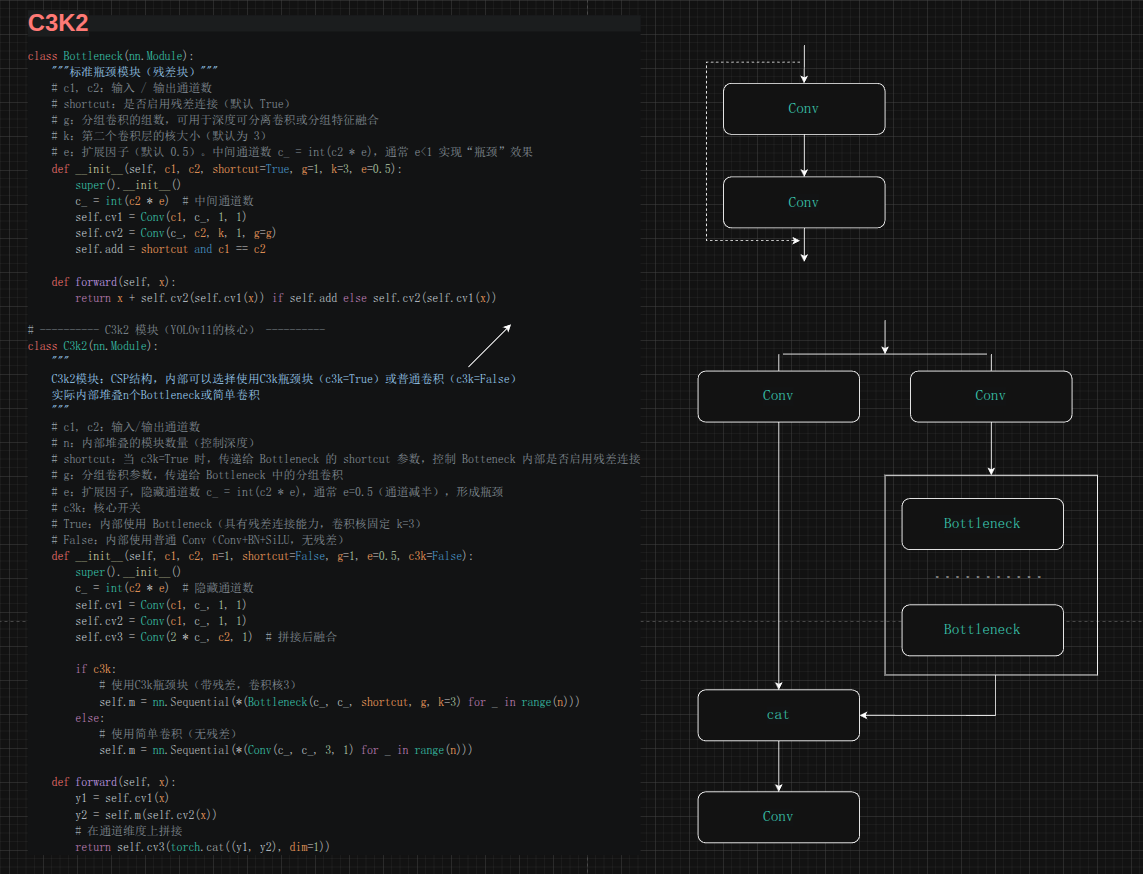
C2f vs C3k2 的关键区别:
| 特性 | C2f (v8) | C3k2 (v11) |
|---|---|---|
| 内部结构 | 固定为 Bottleneck | 可选 Bottleneck(c3k=True)或 Conv(c3k=False) |
| Bottleneck 数量 | 由 n 控制,输入输出通道均分 | 由 n 控制,输入输出通道均分 |
| shortcut | 默认 True | 默认 False |
| 灵活性 | 单一模式 | 双模式,可灵活配置 |
为什么默认 shortcut=False?
在 C2f 中,Bottleneck 默认启用残差连接。但 C3k2 的多数场景下(c3k=False),内部使用普通的 Conv 而非 Bottleneck,此时本身就无残差概念。即便是 c3k=True 时,也只在某些特定层(如 b3、b7)启用残差连接,避免不必要的梯度路径。
c3k 开关的设计意图:
- c3k=True:用于 Backbone 中较深的层(b3: P3/8, b7: P5/32),这些层需要更强的特征提取能力,Bottleneck 的残差结构有助于训练更深网络
- c3k=False:用于 Neck 和 Backbone 中的中间层,使用普通 Conv 堆叠,计算量更小,适合特征融合阶段的轻量处理
SPPF(快速空间金字塔池化)
SPPF 是 SPP(Spatial Pyramid Pooling)的快速版本,位于 Backbone 的最后一层(b8),用于扩大感受野。
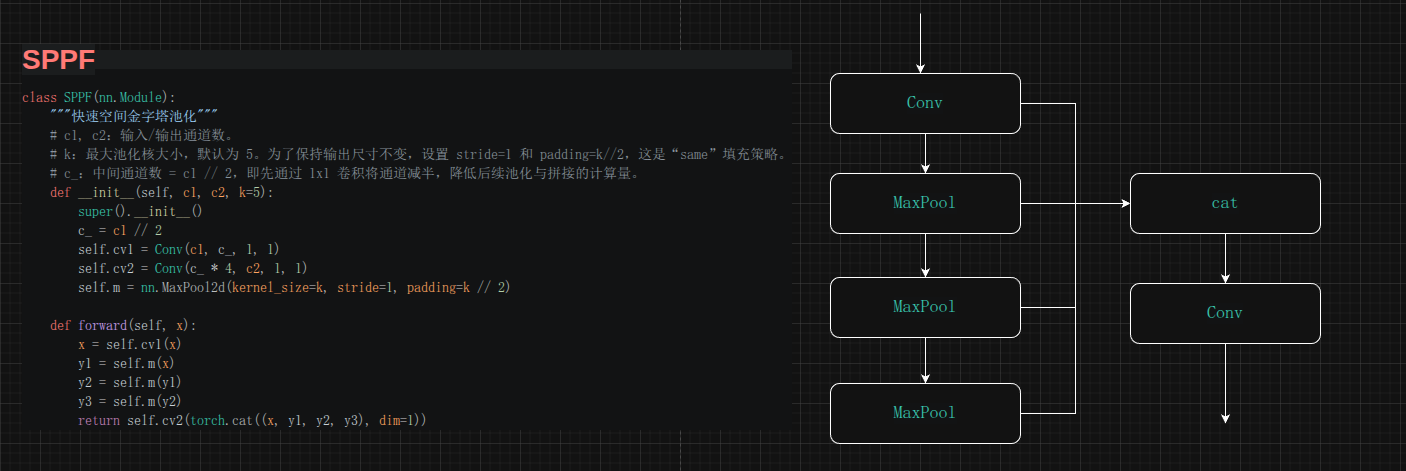
核心思想:通过多个串联的 MaxPool2d(k=5) 获得不同感受野的特征,再将它们拼接起来。
为什么是串联而不是并联?
传统 SPP 使用并联的多个不同 kernel 大小的池化,计算量较大。SPPF 采用串联方式,感受野计算如下:
- 一次池化:感受野 5x5
- 两次池化:感受野 9x9(等效于 5 + 5 - 1 = 9)
- 三次池化:感受野 13x13(等效于 9 + 5 - 1 = 13)
串联池化的计算量约为并联的 1/31/31/3,但效果等价。
通道处理流程:
cv1:C→C/2C \rightarrow C/2C→C/2,先降维减少后续计算量- 三次串联 MaxPool:输出通道数不变,均为 C/2C/2C/2
- 拼接:C/2×4=2CC/2 \times 4 = 2CC/2×4=2C
cv2:2C→C2C \rightarrow C2C→C,恢复原始通道数
C2PSA(部分空间注意力)
C2PSA 是 YOLOv11 新增的模块,将空间注意力机制融入 C2 结构,位于 Backbone 的最后一层(b9),接在 SPPF 之后。
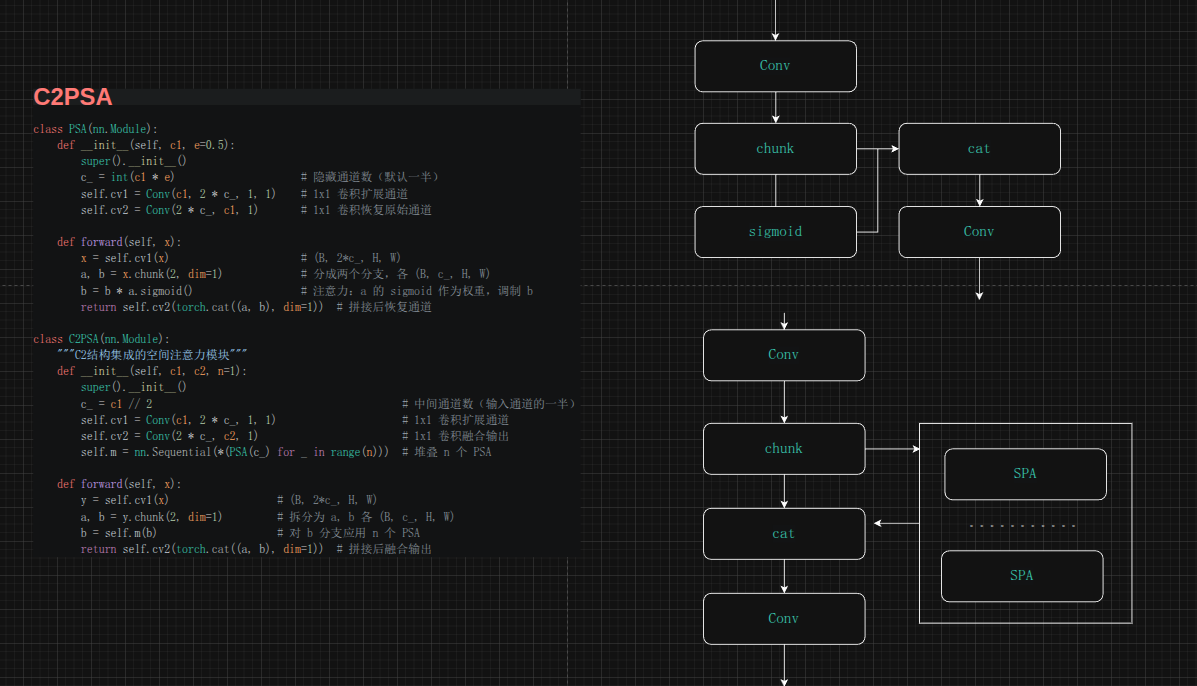
PSA 内部机制:
PSA(Partial Spatial Attention)的核心操作是特征门控(feature gating):
- 1x1 卷积将通道扩展为 2c2c2c,然后拆分为 a,ba, ba,b 两个分支
- 对 aaa 做 sigmoid 得到注意力权重:weight=σ(a)\text{weight} = \sigma(a)weight=σ(a)
- 用权重调制 bbb:b′=b⋅σ(a)b' = b \cdot \sigma(a)b′=b⋅σ(a)
- 拼接 a,b′a, b'a,b′ 后通过 1x1 卷积恢复通道
这里的 aaa 分支相当于"注意力生成器",bbb 分支相当于"特征携带者"。aaa 的 sigmoid 输出值在 (0,1) 范围内,作为软门控调制 bbb 的特征响应。
C2PSA 的 C2 结构:
C2PSA 沿用了 C2 的 split 设计:输入通道一分为二,一半直接传递(shortcut),另一半经过 PSA 处理,最后再拼接融合。这种设计保证了梯度可以从两个路径传播,训练更加稳定。
三、网络整体架构
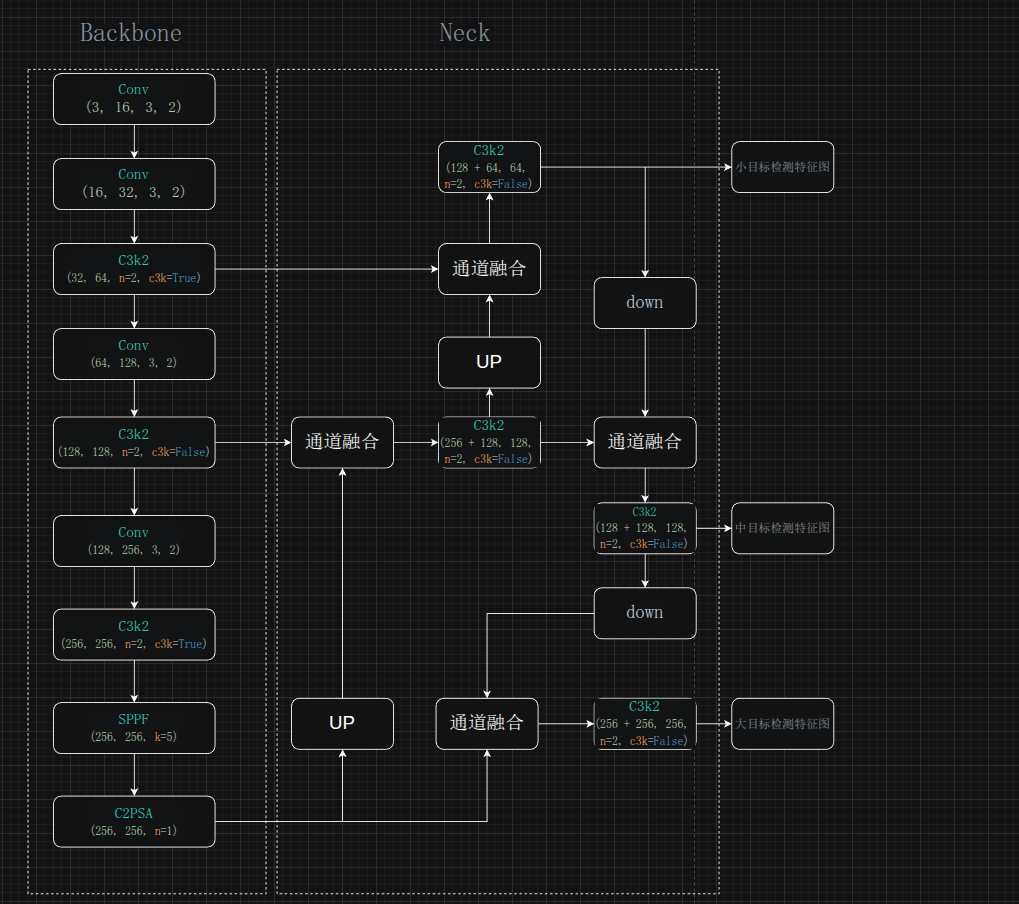
YOLOv11 延续了 Backbone + Neck + Head 的三段式设计,整体结构如下:
Backbone(特征提取网络)
| 层 | 模块 | 通道 | 输出尺寸 | 说明 |
|---|---|---|---|---|
| b1 | Conv k=3 s=2 | 3→16 | 320x320 | P1/2 下采样 |
| b2 | Conv k=3 s=2 | 16→32 | 160x160 | P2/4 下采样 |
| b3 | C3k2 n=2 c3k=True | 32→64 | 80x80 | P3/8 特征提取 |
| b4 | Conv k=3 s=2 | 64→128 | 40x40 | 下采样 |
| b5 | C3k2 n=2 c3k=False | 128→128 | 40x40 | P4/16 特征提取 |
| b6 | Conv k=3 s=2 | 128→256 | 20x20 | 下采样 |
| b7 | C3k2 n=2 c3k=True | 256→256 | 20x20 | P5/32 特征提取 |
| b8 | SPPF | 256→256 | 20x20 | 感受野扩大 |
| b9 | C2PSA | 256→256 | 20x20 | 空间注意力 |
三点值得注意的设计:
- C3k2 的交替配置:b3 和 b7 使用 c3k=True(瓶颈残差块),b5 使用 c3k=False(简单卷积)。这是因为 b3 和 b7 分别位于 P3 和 P5 这两个关键检测层之前,需要更强的特征提取能力
- C2PSA 的位置:放在 SPPF 之后而不是之前,因为 SPPF 已经扩大了感受野,PSA 可以在更大的感受野上做空间注意力,效果更好
- 通道数策略:YOLOv11n 的通道数较小(最大 256),而 v8n 最大为 256,实际参数量相当。但对更大的模型(s/m/l/x),v11 的通道数配置有所不同
Neck(特征融合网络)
Neck 采用 FPN + PAN 结构,即先上采样再下采样的双向融合路径:
上采样路径(自顶向下):
up1→cat(d9, d5)→n1(C3k2):大目标特征与中层特征融合,输出 40x40up2→cat(x1, d3)→n2(C3k2):融合后输出 80x80,得到 P3 检测特征图(小目标)
下采样路径(自底向上):
down1→cat(x2, x1)→n3(C3k2):输出 40x40,得到 P4 检测特征图(中目标)down2→cat(x3, d9)→n4(C3k2):输出 20x20,得到 P5 检测特征图(大目标)
与 YOLOv8 Neck 的区别:
YOLOv8 的 Neck 在上下采样路径中使用 C2f 模块,且通道数较多。YOLOv11 的 Neck 全部使用 c3k=False 的 C3k2,计算量更轻,且下采样路径中的拼接源不同------v11 将下采样结果与 Backbone 的原始输出(d9)拼接,保留了更多原始信息。
Head(检测头)
检测头接收三个尺度的特征图(P3: 80x80, P4: 40x40, P5: 20x20),输出分类和回归结果。
每个检测层包含两个分支:
cv2:生成中间特征(64通道),用于后续的框回归(Regression)cv3:生成分类 + 框回归的原始输出(4 + nc 通道)
注意 :上述代码是简化版本。实际 YOLOv11 的检测头使用 DFL(Distribution Focal Loss) 进行框回归,输出通道为 reg_max * 4 = 16 * 4 = 64,而非简单的 4。分类分支使用 nc 个通道并通过 sigmoid 激活。完整实现可参考 ultralytics 源码。
四、损失函数与训练(概述)
YOLOv11 的训练流程与 v8 基本一致,主要包括:
损失函数三件套:
- 分类损失(BCE Loss):二值交叉熵损失,每个类别独立做二分类
- 框回归损失(CIoU / DFL Loss):DFL 将边框坐标建模为离散分布,通过 softmax 输出分布概率,再加权求和得到坐标值。CIoU 考虑重叠面积、中心点距离和宽高比
- 置信度损失(BCE Loss):控制 objectness 分数
数据增强:
- Mosaic(前 10 个 epoch):将 4 张图拼接为一张,增强小目标检测能力
- MixUp(仅在较大模型中使用)
- HSV 颜色抖动、随机缩放、平移、翻转
训练策略:
- 训练 500 epoch
- Cosine LR Scheduler,初始 lr=0.01
- EMA(Exponential Moving Average)平滑权重
- 自动混合精度(AMP)训练
五、总结
YOLOv11 的核心改进可以概括为三点:
- 模块精简:C3k2 取代 C2f,统一了内部结构,通过 c3k 开关灵活切换 Conv/Bottleneck,代码更简洁,部署更友好
- 注意力增强:C2PSA 模块的引入提供了空间注意力机制,在不大幅增加计算量的前提下提升了特征表示能力
- 结构优化:Neck 路径的简化,下采样路径中与 Backbone 原始输出的拼接,保持了信息流的高效传递
与 v8 相比,YOLOv11 在 COCO 上的 mAP 有约 0.5-1.0 的提升,而推理速度几乎不变。这得益于其"做减法"的设计思路------不是堆砌复杂的模块,而是让每个模块都发挥最大效用。
对于实际工程部署,YOLOv11 的简洁架构使其更容易导出为 ONNX/TensorRT,且量化友好,是一个在精度和效率之间取得优秀平衡的目标检测方案。
完整代码实现
下面是一个 YOLOv11n 最小实现,主要用来看一代模型结构,包含了所有上述模块:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
# ---------- 辅助模块 ----------
class Conv(nn.Module):
"""标准卷积 + BN + SiLU"""
# c1, c2:输入通道数 / 输出通道数
# k:卷积核大小(默认 1,常用于调整通道数)
# s:步长(默认 1,用于下采样时设为 2)
# p:填充大小。若为 None,自动计算为 k//2(保持输入输出尺寸相同,前提是 s=1)
# g:分组卷积的组数(默认 1,即普通卷积)
# act:是否使用激活函数(默认 True 使用 SiLU,否则恒等映射)
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, p if p else k//2, groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class Bottleneck(nn.Module):
"""标准瓶颈模块(残差块)"""
# c1, c2:输入 / 输出通道数
# shortcut:是否启用残差连接(默认 True)
# g:分组卷积的组数,可用于深度可分离卷积或分组特征融合
# k:第二个卷积层的核大小(默认为 3)
# e:扩展因子(默认 0.5)。中间通道数 c_ = int(c2 * e),通常 e<1 实现"瓶颈"效果
def __init__(self, c1, c2, shortcut=True, g=1, k=3, e=0.5):
super().__init__()
c_ = int(c2 * e) # 中间通道数
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, k, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
# ---------- C3k2 模块(YOLOv11的核心) ----------
class C3k2(nn.Module):
"""
C3k2模块:CSP结构,内部可以选择使用C3k瓶颈块(c3k=True)或普通卷积(c3k=False)
实际内部堆叠n个Bottleneck或简单卷积
"""
# c1, c2:输入/输出通道数
# n:内部堆叠的模块数量(控制深度)
# shortcut:当 c3k=True 时,传递给 Bottleneck 的 shortcut 参数,控制 Botteneck 内部是否启用残差连接
# g:分组卷积参数,传递给 Bottleneck 中的分组卷积
# e:扩展因子,隐藏通道数 c_ = int(c2 * e),通常 e=0.5(通道减半),形成瓶颈
# c3k:核心开关
# True:内部使用 Bottleneck(具有残差连接能力,卷积核固定 k=3)
# False:内部使用普通 Conv(Conv+BN+SiLU,无残差)
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, c3k=False):
super().__init__()
c_ = int(c2 * e) # 隐藏通道数
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # 拼接后融合
if c3k:
# 使用C3k瓶颈块(带残差,卷积核3)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=3) for _ in range(n)))
else:
# 使用简单卷积(无残差)
self.m = nn.Sequential(*(Conv(c_, c_, 3, 1) for _ in range(n)))
def forward(self, x):
y1 = self.cv1(x)
y2 = self.m(self.cv2(x))
# 在通道维度上拼接
return self.cv3(torch.cat((y1, y2), dim=1))
# ---------- SPPF 模块(空间金字塔池化) ----------
class SPPF(nn.Module):
"""快速空间金字塔池化"""
# c1, c2:输入/输出通道数。
# k:最大池化核大小,默认为 5。为了保持输出尺寸不变,设置 stride=1 和 padding=k//2,这是"same"填充策略。
# c_:中间通道数 = c1 // 2,即先通过 1x1 卷积将通道减半,降低后续池化与拼接的计算量。
def __init__(self, c1, c2, k=5):
super().__init__()
c_ = c1 // 2
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
y1 = self.m(x)
y2 = self.m(y1)
y3 = self.m(y2)
return self.cv2(torch.cat((x, y1, y2, y3), dim=1))
# ---------- C2PSA 模块(部分空间注意力) ----------
class PSA(nn.Module):
def __init__(self, c1, e=0.5):
super().__init__()
c_ = int(c1 * e) # 隐藏通道数(默认一半)
self.cv1 = Conv(c1, 2 * c_, 1, 1) # 1x1 卷积扩展通道
self.cv2 = Conv(2 * c_, c1, 1) # 1x1 卷积恢复原始通道
def forward(self, x):
x = self.cv1(x) # (B, 2*c_, H, W)
a, b = x.chunk(2, dim=1) # 分成两个分支,各 (B, c_, H, W)
b = b * a.sigmoid() # 注意力:a 的 sigmoid 作为权重,调制 b
return self.cv2(torch.cat((a, b), dim=1)) # 拼接后恢复通道
class C2PSA(nn.Module):
"""C2结构集成的空间注意力模块"""
def __init__(self, c1, c2, n=1):
super().__init__()
c_ = c1 // 2 # 中间通道数(输入通道的一半)
self.cv1 = Conv(c1, 2 * c_, 1, 1) # 1x1 卷积扩展通道
self.cv2 = Conv(2 * c_, c2, 1) # 1x1 卷积融合输出
self.m = nn.Sequential(*(PSA(c_) for _ in range(n))) # 堆叠 n 个 PSA
def forward(self, x):
y = self.cv1(x) # (B, 2*c_, H, W)
a, b = y.chunk(2, dim=1) # 拆分为 a, b 各 (B, c_, H, W)
b = self.m(b) # 对 b 分支应用 n 个 PSA
return self.cv2(torch.cat((a, b), dim=1)) # 拼接后融合输出
# ---------- 检测头(简化版) ----------
class Detect(nn.Module):
"""YOLOv11的检测头(简化,仅展示结构)"""
def __init__(self, nc=80, ch=()):
super().__init__()
self.nc = nc # 类别数
self.nl = len(ch) # 检测层数(一般为3)
self.stride = torch.tensor([8., 16., 32.]) # 相对于原图的步长
# 每个检测层都需要预测:框回归(4) + 类别(nc) + 置信度(1)
c_out = 4 + nc # 注意:实际YOLO使用DFL,这里简化
self.cv2 = nn.ModuleList(nn.Conv2d(ch[i], 64, 3, 1, 1) for i in range(self.nl))
self.cv3 = nn.ModuleList(nn.Conv2d(ch[i], c_out, 3, 1, 1) for i in range(self.nl))
def forward(self, x):
# x 是三个特征图列表
results = []
for i in range(self.nl):
# 先经过一些小卷积提取特征
box = self.cv2[i](x[i]) # 中间特征(可进一步回归)
cls = self.cv3[i](x[i]) # 类别+框原始输出
results.append(cls)
return results
# ---------- 完整的 YOLOv11n 网络 ----------
class YOLOv11n(nn.Module):
"""
基于yolo11n.yaml配置的最小化实现
"""
def __init__(self, nc=80):
super().__init__()
# -------- Backbone(类似ResNet,逐步下采样) --------
self.b1 = Conv(3, 16, 3, 2) # P1/2
self.b2 = Conv(16, 32, 3, 2) # P2/4
self.b3 = C3k2(32, 64, n=2, c3k=True) # P3/8 (输出80x80)
self.b4 = Conv(64, 128, 3, 2) # 下采样
self.b5 = C3k2(128, 128, n=2, c3k=False) # P4/16 (输出40x40)
self.b6 = Conv(128, 256, 3, 2) # 下采样
self.b7 = C3k2(256, 256, n=2, c3k=True) # P5/32 (输出20x20)
self.b8 = SPPF(256, 256, k=5) # SPPF
self.b9 = C2PSA(256, 256, n=1) # C2PSA(最后加入注意力)
# -------- Neck(类似UNet,特征融合) --------
self.up1 = nn.Upsample(scale_factor=2, mode='nearest')
self.n1 = C3k2(256 + 128, 128, n=2, c3k=False) # 融合P4
self.up2 = nn.Upsample(scale_factor=2, mode='nearest')
self.n2 = C3k2(128 + 64, 64, n=2, c3k=False) # 融合P3
# 下采样路径(可选,用于增强大目标)
self.down1 = Conv(64, 128, 3, 2)
self.n3 = C3k2(128 + 128, 128, n=2, c3k=False) # 融合P4
self.down2 = Conv(128, 256, 3, 2)
self.n4 = C3k2(256 + 256, 256, n=2, c3k=False) # 融合P5
# -------- Head(三个检测头) --------
# 三个输出特征图通道数:64, 128, 256
self.detect = Detect(nc=nc, ch=(64, 128, 256))
def forward(self, x):
# Backbone
d1 = self.b1(x) # 160x160
d2 = self.b2(d1) # 80x80
d3 = self.b3(d2) # 80x80 → 用于小目标检测
d4 = self.b4(d3) # 40x40
d5 = self.b5(d4) # 40x40 → 用于中目标检测
d6 = self.b6(d5) # 20x20
d7 = self.b7(d6) # 20x20
d8 = self.b8(d7) # SPPF
d9 = self.b9(d8) # C2PSA → 用于大目标检测
# Neck
x1 = self.up1(d9) # 40x40
x1 = torch.cat([x1, d5], dim=1) # 拼接
x1 = self.n1(x1) # 40x40
x2 = self.up2(x1) # 80x80
x2 = torch.cat([x2, d3], dim=1) # 拼接
x2 = self.n2(x2) # 80x80 → 小目标检测特征图P3
x3 = self.down1(x2) # 40x40
x3 = torch.cat([x3, x1], dim=1)
x3 = self.n3(x3) # 40x40 → 中目标检测特征图P4
x4 = self.down2(x3) # 20x20
x4 = torch.cat([x4, d9], dim=1)
x4 = self.n4(x4) # 20x20 → 大目标检测特征图P5
# Head
out = self.detect([x2, x3, x4]) # 三个尺度的预测结果
return out
# ---------- 测试网络 ----------
if __name__ == "__main__":
# 创建模型
model = YOLOv11n(nc=80) # 80类(COCO)
print(f"总参数量: {sum(p.numel() for p in model.parameters()):,}")
# 模拟输入(batch=1, 3通道, 640x640)
x = torch.randn(1, 3, 640, 640)
out = model(x)
print(f"输出个数: {len(out)}")
for i, o in enumerate(out):
print(f"尺度{i+1}: {o.shape}") # 应为 [1, 84, 80, 80] 等(84=4+80)参考:
deepseek