引言
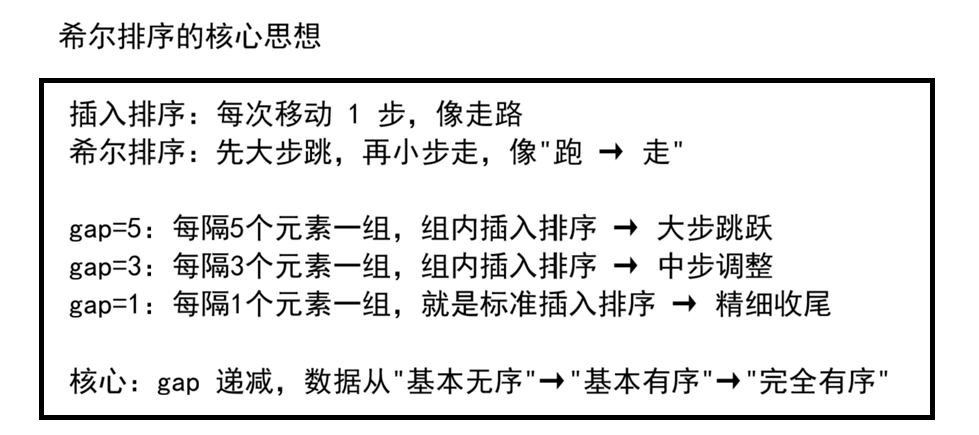
前面我们学习了插入排序------它对于基本有序的数据效率极高,接近 O(n)。但对于乱序数据,插入排序每次只能移动一个位置,效率骤降到 O(n²)。
希尔排序 (Shell Sort)正是抓住了这个痛点:它让元素大步跳跃,先让数组"基本有序",最后再用插入排序收尾。这种"分组跳跃 + 逐步精细"的策略,让希尔排序突破了 O(n²) 的瓶颈,时间复杂度可达 O(n^1.3) ~ O(n^1.5)。
第一部分:算法思想
一、为什么插入排序在基本有序时很快

二、分组插入的过程

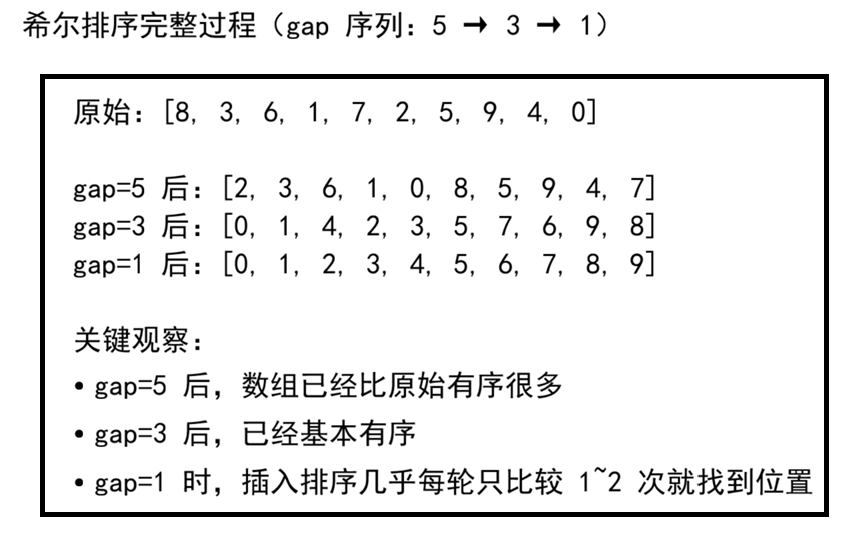
三、完整排序过程
第二部分:代码实现
一、单次分组插入(Shell 函数)
cpp
// 以 gap 为增量,对各组进行插入排序
void Shell(int arr[], int len, int gap) {
// i 从 gap 开始:每组第一个元素视为已排序
// i++ 表示依次处理各组的下一个元素
for (int i = gap; i < len; i++) {
int tmp = arr[i]; // 待插入元素
int j = i - gap; // 同组前一个元素的位置
// 在同组内向前找插入位置
for (; j >= 0; j -= gap) {
if (arr[j] > tmp) {
arr[j + gap] = arr[j]; // 比 tmp 大的后移 gap 位
} else {
break;
}
}
arr[j + gap] = tmp; // 插入到正确位置
}
}二、指定 gap 序列的希尔排序
cpp
// 使用预定义的 gap 序列
void Shell_Sort(int arr[], int len) {
int gap[] = {5, 3, 1};
int len_gap = sizeof(gap) / sizeof(gap[0]);
for (int i = 0; i < len_gap; i++) {
Shell(arr, len, gap[i]);
}
}三、动态生成 gap 序列的版本(更常用)
cpp
// gap 从 len/2 开始,每次折半
void Shell_Sort_V2(int arr[], int len) {
for (int gap = len / 2; gap > 0; gap /= 2) {
// 内层就是标准的 gap 插入排序
for (int i = gap; i < len; i++) {
int tmp = arr[i];
int j = i;
for (; j >= gap; j -= gap) {
if (arr[j - gap] > tmp) {
arr[j] = arr[j - gap];
} else {
break;
}
}
arr[j] = tmp;
}
}
}两种方式的对比:
| 方式 | 优点 | 缺点 |
|---|---|---|
| 指定序列 {5,3,1} | 可精细控制,适合固定数据量 | 不够通用 |
| 动态折半 len/2 | 通用,任何数据量都能用 | gap 序列不是最优 |
第三部分:完整测试代码
cpp
#include <stdio.h>
// 希尔排序(gap 从 len/2 折半递减)
void Shell_Sort(int arr[], int len) {
for (int gap = len / 2; gap > 0; gap /= 2) {
for (int i = gap; i < len; i++) {
int tmp = arr[i];
int j = i;
for (; j >= gap; j -= gap) {
if (arr[j - gap] > tmp)
arr[j] = arr[j - gap];
else
break;
}
arr[j] = tmp;
}
}
}
void printArray(int arr[], int len, const char* msg) {
printf("%s", msg);
for (int i = 0; i < len; i++) printf("%d ", arr[i]);
printf("\n");
}
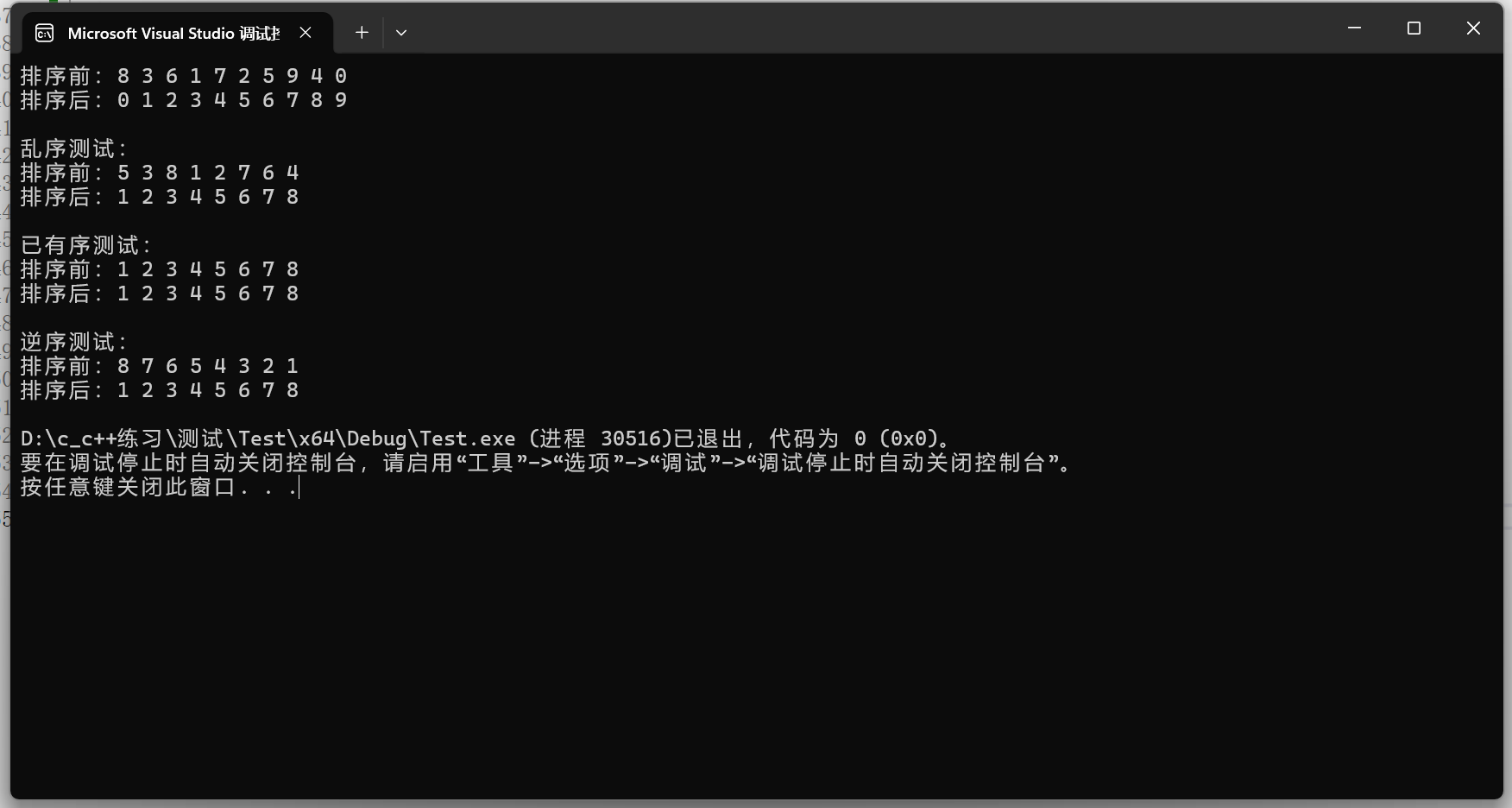
int main() {
int arr1[] = {8, 3, 6, 1, 7, 2, 5, 9, 4, 0};
int len1 = sizeof(arr1) / sizeof(arr1[0]);
printArray(arr1, len1, "排序前:");
Shell_Sort(arr1, len1);
printArray(arr1, len1, "排序后:");
int arr2[] = {5, 3, 8, 1, 2, 7, 6, 4};
int len2 = sizeof(arr2) / sizeof(arr2[0]);
printf("\n乱序测试:\n");
printArray(arr2, len2, "排序前:");
Shell_Sort(arr2, len2);
printArray(arr2, len2, "排序后:");
int arr3[] = {1, 2, 3, 4, 5, 6, 7, 8};
int len3 = sizeof(arr3) / sizeof(arr3[0]);
printf("\n已有序测试:\n");
printArray(arr3, len3, "排序前:");
Shell_Sort(arr3, len3);
printArray(arr3, len3, "排序后:");
int arr4[] = {8, 7, 6, 5, 4, 3, 2, 1};
int len4 = sizeof(arr4) / sizeof(arr4[0]);
printf("\n逆序测试:\n");
printArray(arr4, len4, "排序前:");
Shell_Sort(arr4, len4);
printArray(arr4, len4, "排序后:");
return 0;
}运行结果:
第四部分:算法分析
一、时间复杂度
| 情况 | 时间复杂度 | 说明 |
|---|---|---|
| 最好 | O(n log n) | 取决于 gap 序列 |
| 最坏 | O(n²) | gap 序列不好时(如只有 gap=1) |
| 平均 | O(n^1.3) ~ O(n^1.5) | 比 O(n²) 好很多 |
不同 gap 序列的影响:
| gap 序列 | 最坏时间复杂度 |
|---|---|
| 折半递减(n/2, n/4, ...) | O(n²) |
| Hibbard 序列(1, 3, 7, 15, ..., 2^k - 1) | O(n^1.5) |
| Sedgewick 序列(1, 5, 19, 41, 109, ...) | O(n^1.3) |

二、空间复杂度
O(1) ,只用了临时变量 tmp 和 j。
三、稳定性
希尔排序是不稳定的。因为分组跳跃式交换,相等元素可能被换到不同组,改变相对顺序。

第五部分:希尔排序 vs 插入排序 vs 快速排序
| 对比项 | 插入排序 | 希尔排序 | 快速排序 |
|---|---|---|---|
| 最好时间 | O(n) | O(n log n) | O(n log n) |
| 最坏时间 | O(n²) | O(n²) | O(n²) |
| 平均时间 | O(n²) | O(n^1.3) | O(n log n) |
| 空间 | O(1) | O(1) | O(log n) |
| 稳定性 | ✅ | ❌ | ❌ |
| 代码量 | 最少 | 少 | 中等 |
希尔排序的定位 :比 O(n²) 的排序快很多,比 O(n log n) 的排序简单很多,是一种性价比极高的中等规模排序算法
总结
一、核心要点
| 要点 | 内容 |
|---|---|
| 算法思想 | 分组跳跃 + 插入排序。大 gap 让元素大步移动,小 gap 精细调整 |
| 时间复杂度 | 取决于 gap 序列,平均 O(n^1.3) ~ O(n^1.5) |
| 空间复杂度 | O(1) |
| 稳定性 | ❌ 不稳定 |
| gap 选择 | Hibbard 序列优于折半递减,Sedgewick 序列最优 |
二、代码框架记忆
cpp
Shell_Sort:
for (gap = n/2; gap > 0; gap /= 2)
for (i = gap; i < n; i++)
tmp = arr[i]
j = i
while (j >= gap && arr[j-gap] > tmp)
arr[j] = arr[j-gap]
j -= gap
arr[j] = tmp三、一句话记忆
希尔排序是插入排序的升级版,用递减的 gap 对数组分组进行插入排序。大 gap 让元素大步跳跃快速消除逆序,小 gap 精细调整最终有序。gap 序列的选择决定性能,Hibbard 和 Sedgewick 序列比折半递减更优。