目录
[<1> 不含字段](#<1> 不含字段)
[<2> 包含一个字段](#<2> 包含一个字段)
[<3> 包含多个字段](#<3> 包含多个字段)
[<4> 指定别名](#<4> 指定别名)
[<5> 去重](#<5> 去重)
[14、group by](#14、group by)
[<1> union](#<1> union)
[<2> union all](#<2> union all)
前言
MySQL中,对表的增删改查(CURD)是最基础、也是最频繁的操作,几乎每一个数据库业务,最终都会落到对数据库的INSERT、SELECT、UPDATE、DELETE这几种操作上。增删改查往往都离不开索引,索引能够将随机全表扫描变为有序快速查找,从而提升查找效率。本文将围绕数据库表的增删查改(CURD)展开介绍,随后深入介绍索引的相关概念及原理,索引内部通过B+树快速定位到目标数据所在的数据页,从而将查询时间复杂度从线性降为对数级,这正是索引最核心的价值所在。理解和掌握表的CRUD操作、索引各自的作用,可以在设计表结构时做出更合理的选择。
一、增删改查
1、create
sql
create table if not exists t30(
id int unsigned primary key auto_increment,
num int not null unique comment '学号',
name varchar(20) not null,
qq varchar(20)
);create table用于创建一张表,create table if not exists t30定义了一张名为t30的表,包含了四个字段:id int unsigned primary key auto_increment,id作为无符号整数自增主键,num int not null unique comment '学号',num作为不可重复且非空的整数学号,name varchar(20) not null,name作为非空的20位字符串姓名,qq varchar(20),以及可为空的20位字符串qq号。
2、insert
(1)单行数据+全列插入
模板:

sql
insert into t30 values (101,10001,'张三','11111');
insert into t30 values (100,10000,'唐三藏',NULL);
insert into t30 values (101,10001,'张三','11111'),insert into t30 values (100,10000,'唐三藏',NULL),使用insert into插入两条记录,value_list数量必须和定义表的列的数量及顺序一致。这里在插入的时候,也可以不用指定id,mysql会使用默认的值进行自增。
sql
select * from t30;select * from t30,通过select查看插入结果:
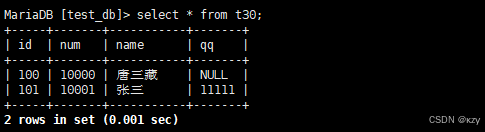
(2)多行数据+指定列插入
sql
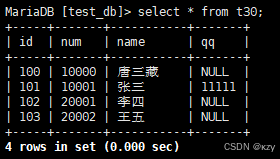
insert into t30(id,num,name) values (102,20001,'李四'),(103,20002,'王五');insert into t30(id,num,name) values (102,20001,'李四'),(103,20002,'王五'),使用insert插入两条记录,value_list数量必须和指定列数量及顺序一致。

sql
select * from t30;select * from t30,通过select查看插入结果:
(3)插入或者更新
由于主键或者唯一键对应的值已经存在而导致插入失败:
sql
insert into t30(id,num,name) values(100,10010,'赵六');
insert into t30(num,name) values(20001,'田七');insert into t30(id,num,name) values(100,10010,'赵六'),主键id=100在t30中已存在,将导致插入失败,insert into t30(num,name) values(20001,'田七'),唯一键num=20001在t30中已存在,也将导致插入失败。

可以选择性的进行同步更新操作:

sql
insert into t30(id,num,name) values(100,10010,'赵六') on duplicate key update num=10010,name='赵六';insert into t30(id,num,name) values(100,10010,'赵六') on duplicate key update num=10010,name='赵六',on duplicate key update 作用为如果字段不存在,则插入新记录。如果id重复或num重复,则更新num=10010、name='赵六'。
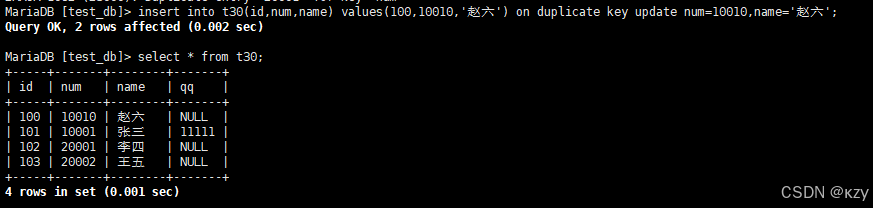
0 row affected,表示表中有冲突数据,但冲突数据的值和update的值相等,1 row affected,表示表中没有冲突数据,数据被插入,2 row affected表示表中有冲突数据,并且数据已经被更新。
3、replace
sql
replace into t30 (num,name) values(20001,'田七');replace用于替换,若主键或者唯一键没有冲突,则直接插入,若主键或者唯一键冲突,则删除后再插入:
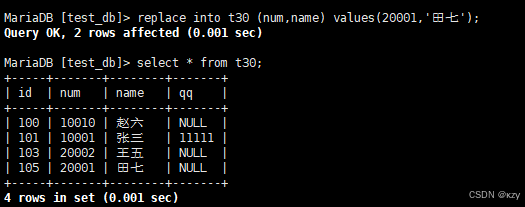
1 row affected表示表中没有冲突数据,数据被插入,2 row affected表示表中有冲突数据,删除后重新插入。
4、select
通过select可对数据进行查询。
模板:

(1)全列查询
sql
select * from t30;select * from t30,对表的数据进行全列查询,结果如下:
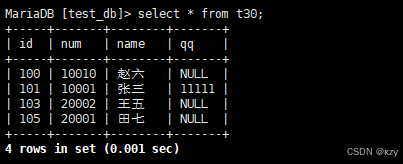
一般情况下不建议使用*进行全列查询,查询的列越多,意味着需要传输的数据量越大,可能会影响到索引的使用。
(2)指定列查询
sql
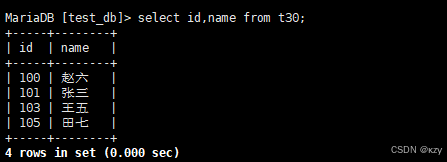
select id,name from t30;select id,name from t30,查询id、name两个指定列,指定列的顺序不需要按定义表的顺序来。
(3)查询表达式
<1> 不含字段
sql
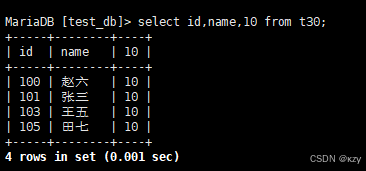
select id,name,10 from t30;select id,name,10 from t30,10不包含字段,查询结果如下所示:
<2> 包含一个字段
sql
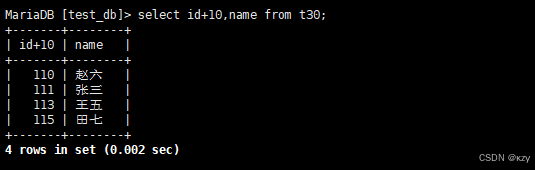
select id+10,name from t30;select id+10,name from t30,id+10表达式包含了一个字段id,查询结果如下所示:
<3> 包含多个字段
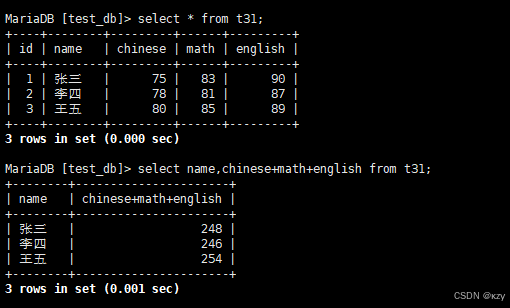
sql
select name,chinese+math+english from t31;select name,chinese+math+english from t31,chinese+math+english表达式包含了多个字段,查询结果如下所示:
<4> 指定别名
模板:

sql
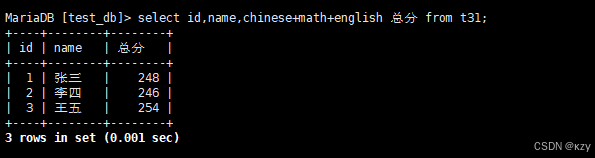
select id,name,chinese+math+english 总分 from t31;select id,name,chinese+math+english 总分 from t31,chinese+math+english指定别名为总分,查询结果如下:
<5> 去重
sql
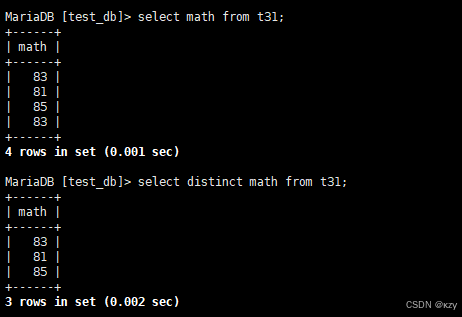
select distinct math from t31;select distinct math from t31,查询math字段去重后的结果,如下所示:
5、where
where用于限定查询条件
常见查询条件如下:


sql
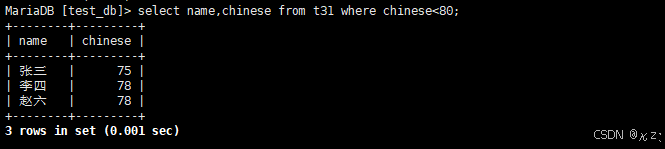
select name,chinese from t31 where chinese<80;select name,chinese from t31 where chinese<80,用于查询语文成绩小于80的同学及语文成绩,结果如下所示:
sql
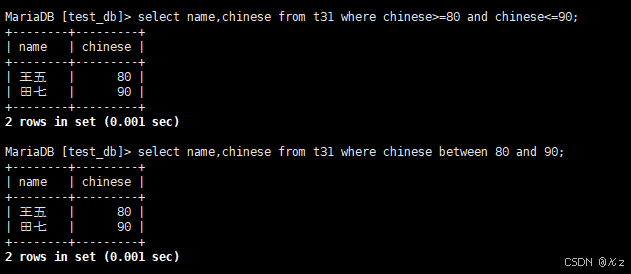
select name,chinese from t31 where chinese>=80 and chinese<=90;select name,chinese from t31 where chinese>=80 and chinese<=90,使用and进行条件连接,用于查询语文成绩在80,90的同学及语文成绩,还可使用between、and进行连接:
sql
select name,chinese from t31 where chinese between 80 and 90;结果如下所示:
sql
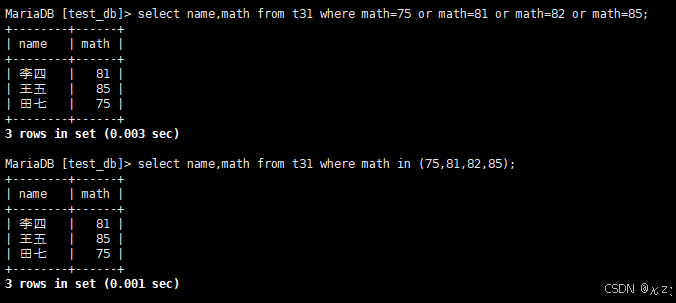
select name,math from t31 where math=75 or math=81 or math=82 or math=85;select name,math from t31 where math=75 or math=81 or math=82 or math=85,使用or进行条件连接,用于查询数学成绩为75、81、82、85的同学及数学成绩,也可使用in进行查询:
sql
select name,math from t31 where math in (75,81,82,85);结果如下所示:
sql
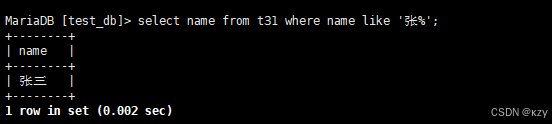
select name from t31 where name like '张%';select name from t31 where name like '张%',%用于匹配任意多个(包括0个)任意字符,用于查询姓张的同学及张某同学,结果如下所示:
sql
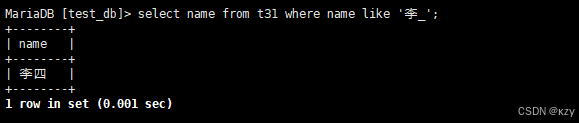
select name from t31 where name like '李_';select name from t31 where name like '李_',_匹配严格的一个任意字符,结果如下所示:
sql
select name,chinese,math from t31 where chinese>math;select name,chinese,math from t31 where chinese>math,where条件中比较运算符两侧都是字段,用于查询语文成绩好于数学成绩的同学,结果如下所示:

sql
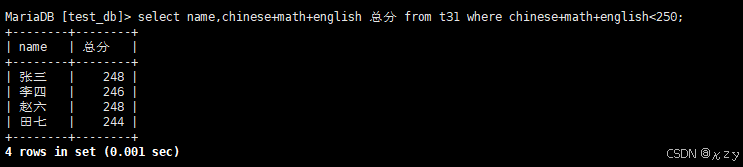
select name,chinese+math+english 总分 from t31 where chinese+math+english<250;select name,chinese+math+english 总分 from t31 where chinese+math+english<250,where条件中使用表达式,但别名不能用在where条件中,用于查询总分小于250分的同学,结果如下所示:
sql
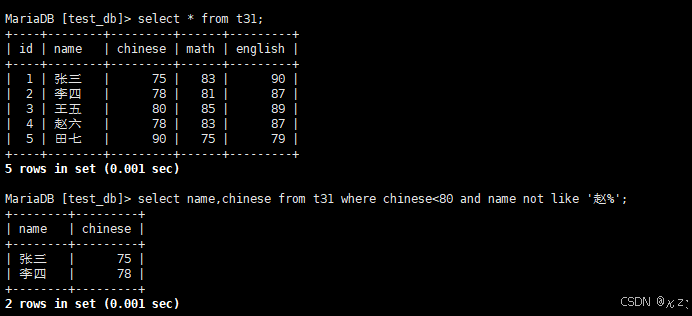
select name,chinese from t31 where chinese<80 and name not like '赵%';select name,chinese from t31 where chinese<80 and name not like '赵%',and与not搭配使用,用于查询语文成绩小于80且不姓赵的同学,结果如下所示:
sql
select name,chinese,math,english,chinese+math+english 总分 from t31 where name like '王%' or (chinese+math+english>245 and english<90);select name,chinese,math,english,chinese+math+english 总分 from t31 where name like '王%' or (chinese+math+english>245 and english<90),为综合性查询,用于查询王某同学,或者总分大于245且英语成绩小于90的同学,结果如下所示:

6、NULL查询
查询t30表:
sql
select * from t30;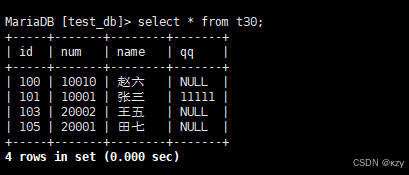
查询qq号已知的同学姓名:
sql
select * from t30 where qq is not null;
NULL和NULL的比较,=和<=>的区别:
sql
select NULL=NULL,NULL=0,NULL=1;
sql
select NULL<=>NULL,NULL<=>0,NULL<=>1;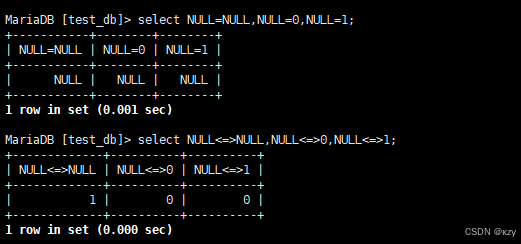
7、结果排序
模板:

没有order by子句的查询,返回的顺序是未定义的。
sql
select name,math from t31 order by math;select name,math from t31 order by math,使用order by用于查询同学及数学成绩,结果按数学成绩升序显示,如下所示:
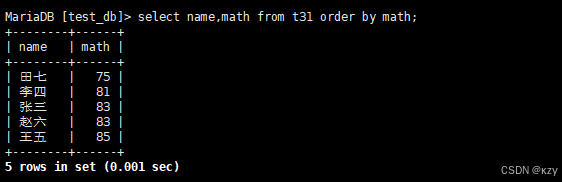
sql
select name,qq from t30 order by qq;select name,qq from t30 order by qq,用于查询同学及qq号,按qq号升序显示,结果如下所示:
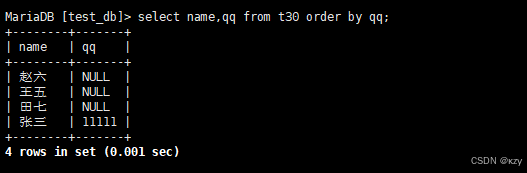
NULL视为比任何值都小,故升序出现在最上面。
sql
select name,qq from t30 order by qq desc;select name,qq from t30 order by qq desc,按qq号降序排序,结果如下所示:
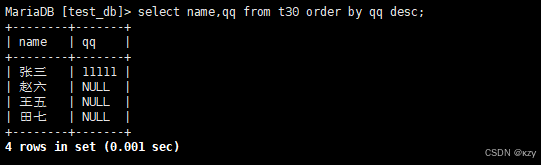
NULL视为比任何值都小,故降序出现在最下面。
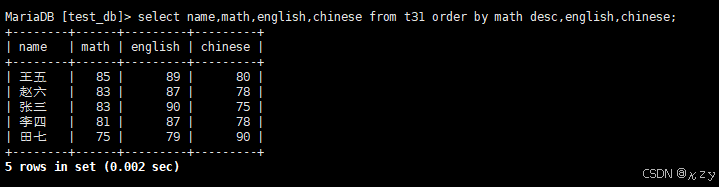
sql
select name,math,english,chinese from t31 order by math desc,english,chinese;select name,math,english,chinese from t31 order by math desc,english,chinese,查询同学各门成绩,order by math desc,english,chinese,依次按数学降序、英语升序、语文升序的方式显示,为多字段排序,排序优先级随书写顺序,结果如下所示:
sql
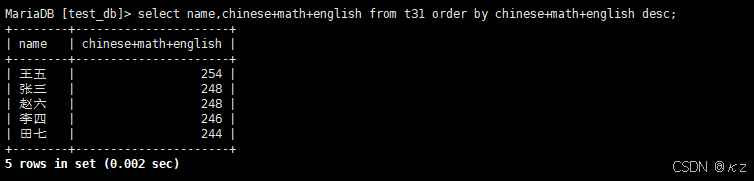
select name,chinese+math+english from t31 order by chinese+math+english desc;select name,chinese+math+english from t31 order by chinese+math+english desc,order by子句中可以使用表达式,查询同学及总分,按总分由高到低排序,结果如下所示:
sql
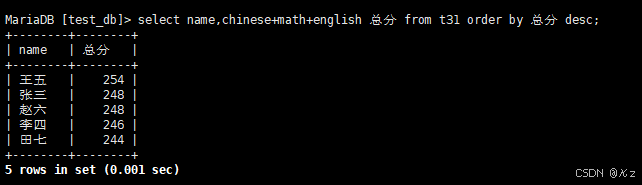
select name,chinese+math+english 总分 from t31 order by 总分 desc;select name,chinese+math+english 总分 from t31 order by 总分 desc,order by子句中也可以使用列别名,查询同学及总分,按总分降序进行排序,结果如下所示:
sql
select name,math from t31 where name like '张%' or name like '王%' order by math desc;select name,math from t31 where name like '张%' or name like '王%' order by math desc,结合where子句和order by子句,用姓于查询张的同学或姓王的同学数学成绩,结果按数学成绩由高到低显示,如下所示:

8、筛选分页
limit、offset用于筛选分页
模板:

sql
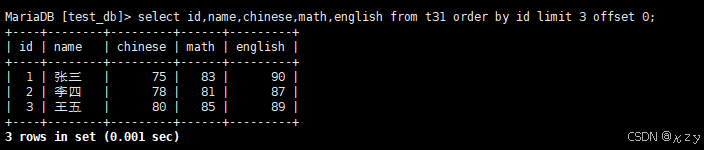
select id,name,chinese,math,english from t31 order by id limit 3 offset 0;select id,name,chinese,math,english from t31 order by id limit 3 offset 0,按id进行分页,每页3条记录,结果如下所示:
sql
select id,name,chinese,math,english from t31 order by id limit 3 offset 3;select id,name,chinese,math,english from t31 order by id limit 3 offset 3,对第2页进行查询,如果结果不足3个,不会有影响,结果如下所示:

9、update
update用于对查询到的结果进行列值更新
模板:

sql
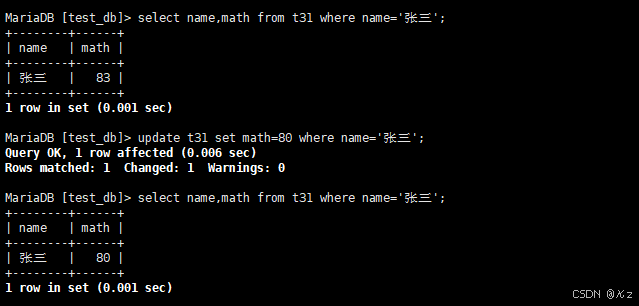
update t31 set math=80 where name='张三';update t31 set math=80 where name='张三',将张三同学的数学成绩变更为80分,结果如下所示:
sql
update t31 set chinese=70,math=80 where name='李四';update t31 set chinese=70,math=80 where name='李四',将李四同学的语文成绩变更为70分,数学成绩变更为80分,结果如下所示:
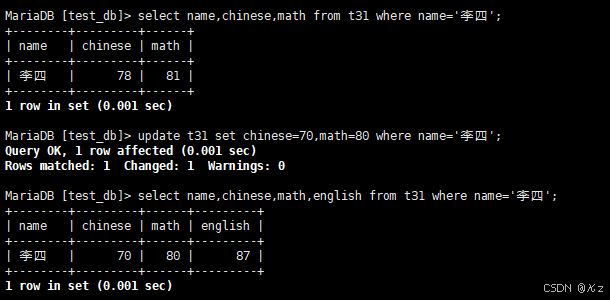
sql
update t31 set math=math+30 order by chinese+math+english limit 3;update t31 set math=math+30 order by chinese+math+english limit 3,将总成绩倒数前三的3位同学的数学成绩加上30分,结果如下所示:
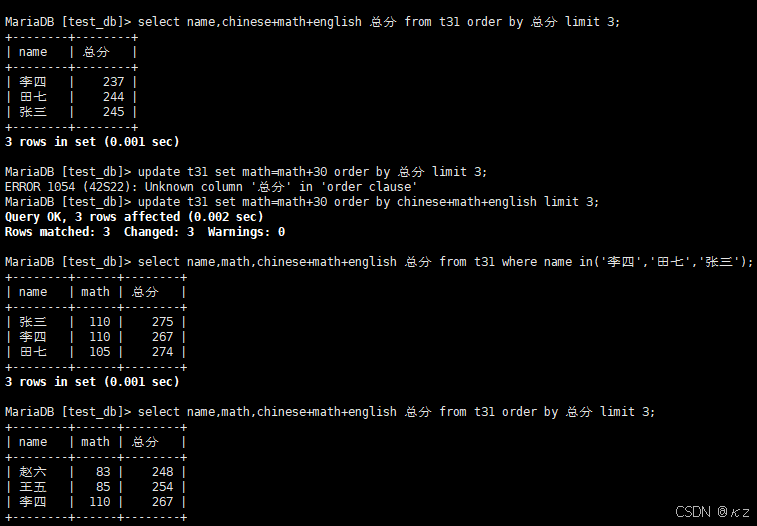
sql
update t31 set chinese=chinese*2;update t31 set chinese=chinese*2,将所有同学的语文成绩更新为原来的2倍,结果如下所示:
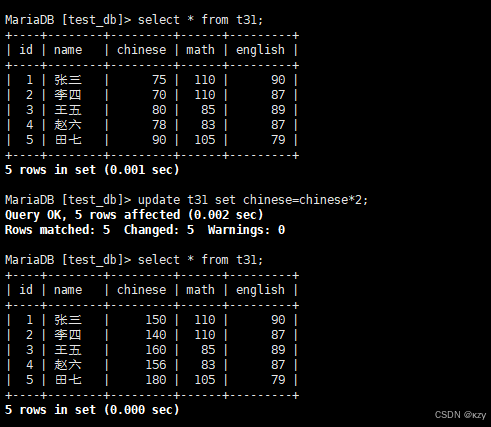
10、delete
delete用于表数据的删除
模板:

sql
delete from t31 where name='张三';delete from t31 where name='张三',用于删除张三同学的考试成绩,结果如下所示:
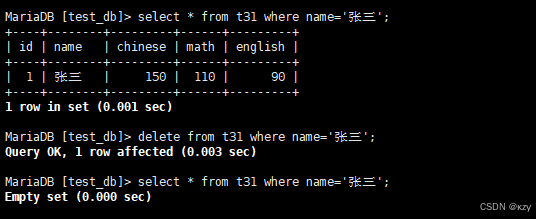
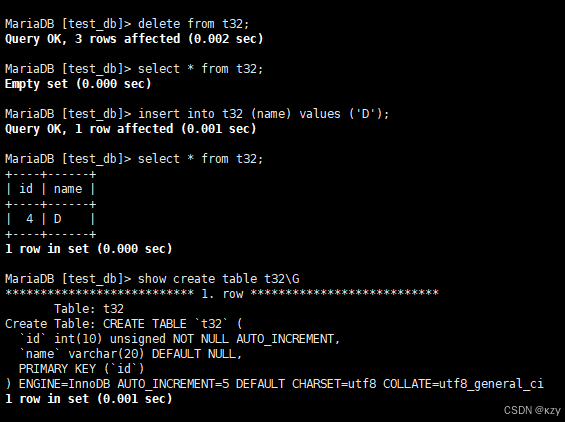
sql
delete from t32;delete from t32,用于删除t32整张表的数据,结果如下所示:
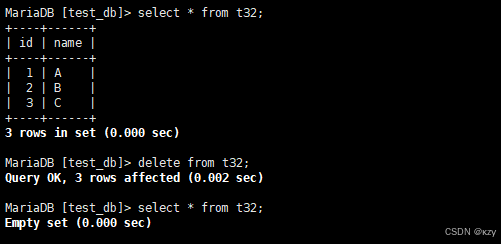
sql
insert into t32 (name) values ('D');insert into t32 (name) values ('D'),此时再插入一条数据,自增id将在原值上增长,如下所示:
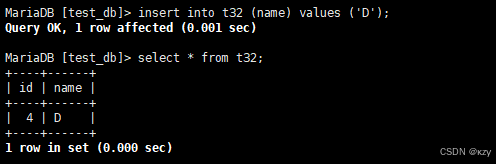
sql
show create table t32\Gshow create table t32\G,查看表结构,会有AUTO_INCREMENT=5该项,如下所示:
11、truncate
模板:

truncate用于截断表,只能对整表进行操作,不能像delete一样针对部分数据操作,实际上truncate不对数据进行操作,所以比delete更快,truncate在删除数据时,并不经过真正的事务,无法回滚,truncate会重置AUTO_INCREMENT项。
sql
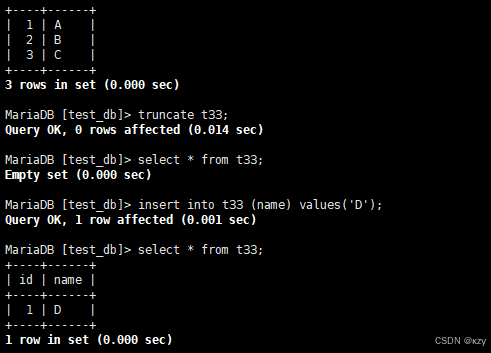
truncate t33;truncate t33,用于截断t33表,结果如下所示:
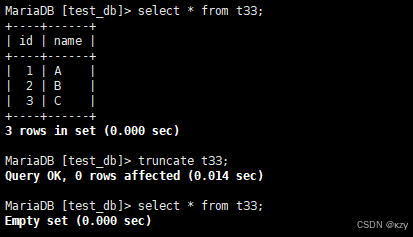
0 rows affected,截断整表数据,故影响行数是0,所以实际上并没有对数据真正操作。
sql
insert into t33 (name) values('D');insert into t33 (name) values('D'),此时再插入一条数据,自增id将重新增长,如下所示:
sql
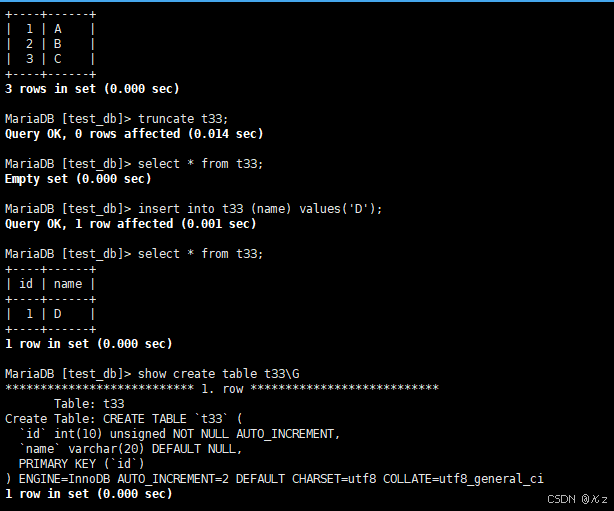
show create table t33\Gshow create table t33\G,查看表结构,会有AUTO_INCREMENT=2一项,如下所示:
12、插入查询结果
模板:

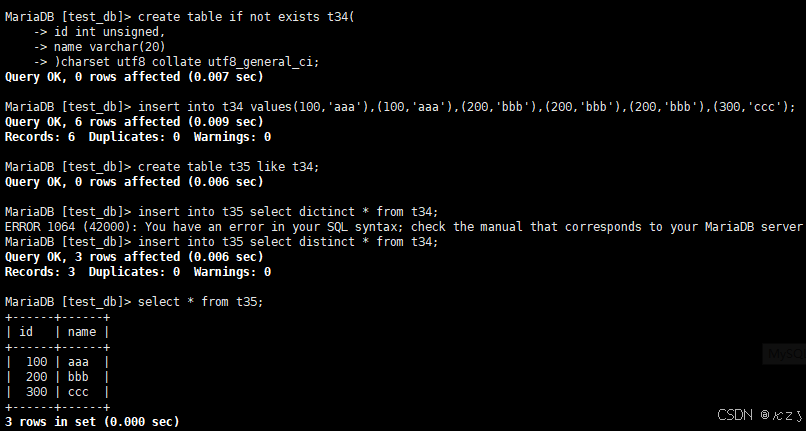
sql
insert into t35 select distinct * from t34;insert into t35 select distinct * from t34,用于将t34的去重数据插入到t35中,结果如下所示:
13、聚合查询
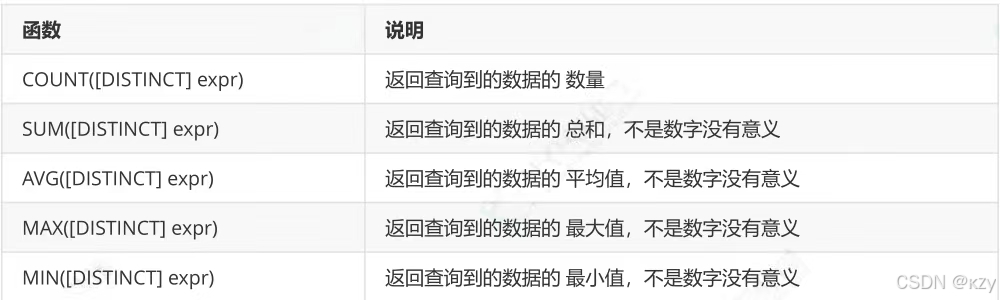
常见查询的聚合函数如下:
sql
select count(*) from t31;select count(*) from t31,使用count(*)统计班级共有多少位同学,使用*做统计,不受NULL影响,结果如下所示:
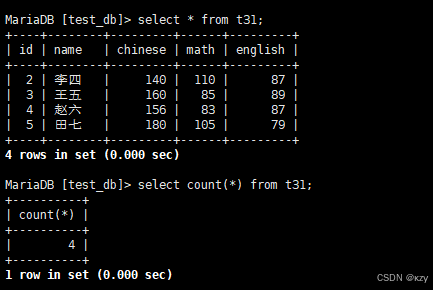
sql
select count(1) from t31;select count(1) from t31,count(1)与count(*)作用一致,都返回班级同学的数量,结果如下所示:
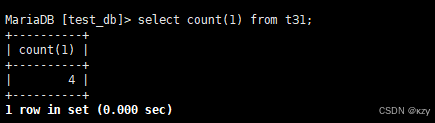
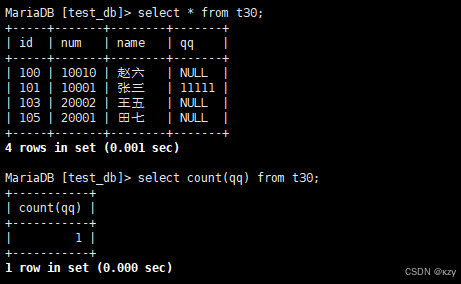
sql
select count(qq) from t30;select count(qq) from t30,用于统计班级的qq号有多少,NULL不计入结果,结果如下所示:
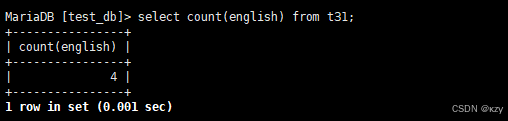
sql
select count(english) from t31;select count(english) from t31,用于统计本次考试的英语成绩分数个数,count(english)统计的是全部英语成绩,结果如下所示:
sql
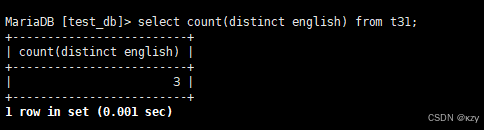
select count(distinct english) from t31;select count(distinct english) from t31,count(distinct english)用于统计的是去重英语成绩的数量,结果如下所示:
sql
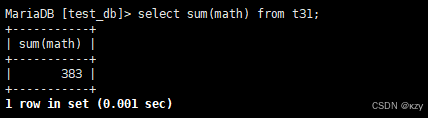
select sum(math) from t31;select sum(math) from t31,sum(math)用于统计数学成绩的总分,结果如下所示:
sql
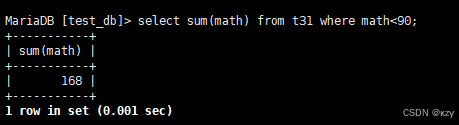
select sum(math) from t31 where math<90;select sum(math) from t31 where math<90,用于统计数学成绩小于90的数学总分,若没有,则返回NULL,结果如下所示:
sql
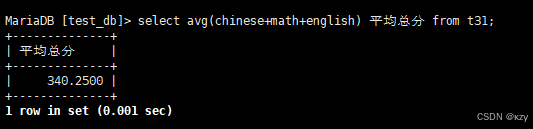
select avg(chinese+math+english) 平均总分 from t31;select avg(chinese+math+english) 平均总分 from t31,avg(chinese+math+english)用于统计平均总分,结果如下所示:
sql
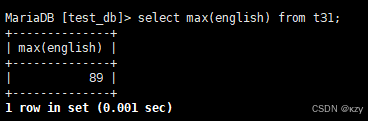
select max(english) from t31;select max(english) from t31,用于查询英语最高分,结果如下所示:
sql
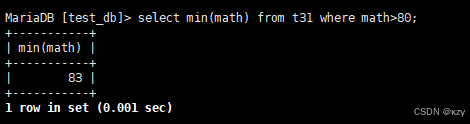
select min(math) from t31 where math>80;select min(math) from t31 where math>80,用于查询80分以上的数学最低分,结果如下所示:
14、group by
在select中使用group by子句可以对指定列进行分组查询
模板:

假设这里有3张表,分别为:t1员工表、t2部门表、t3工资等级表
sql
select deptno,avg(sal),max(sal) from t1 group by depno;select deptno,avg(sal),max(sal) from t1 group by depno,group by depno,按部门号相同进行分组,用于查询每个部门的平均工资和最高工资。
sql
select avg(sal),max(sal),job,depno from t1 group by depno,job;select avg(sal),max(sal),job,depno from t1 group by depno,job,group by depno,job按每个部门的每种岗位进行分组,用于查询每个部门的每种岗位的平均工资和最高工资。
sql
select avg(sal) mysal from t1 group by depno having mysal<2000;select avg(sal) mysal from t1 group by depno having mysal<2000,group by depno having mysal<2000,having和group by配合使用,having将对group by的分组结果进行过滤,用于查询平均工资低于2000的部门和它的平均工资。
二、函数
1、日期函数
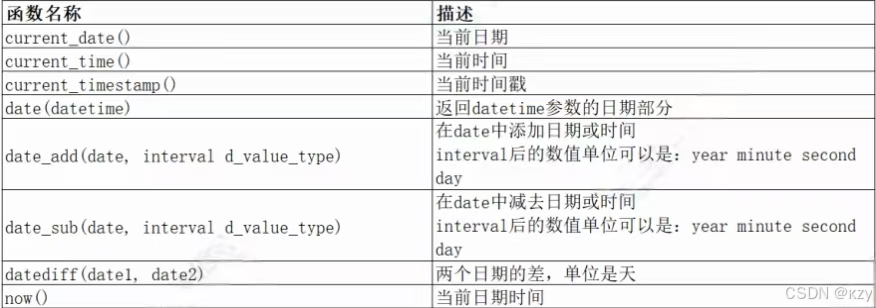
MySQL中常见的日期函数如下:
sql
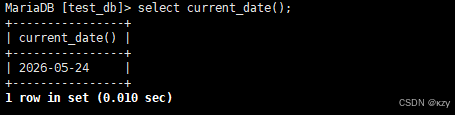
select current_date();select current_date(),用于获取当前日期的年-月-日,结果如下所示:
sql
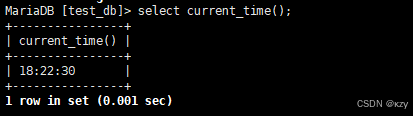
select current_time();select current_time(),用于获取时:分:秒,结果如下所示:
sql
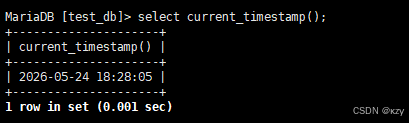
select current_timestamp();select current_timestamp(),用于获取当前时间戳,结果如下所示:
sql
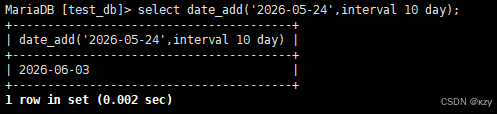
select date_add('2026-05-24',interval 10 day);select date_add('2026-05-24',interval 10 day),date_add用于日期的加法,结果如下所示:
sql
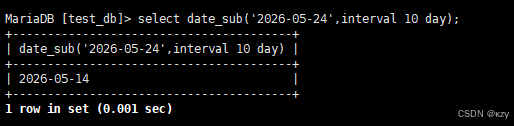
select date_sub('2026-05-24',interval 10 day);select date_sub('2026-05-24',interval 10 day),date_sub用于日期的减法,结果如下所示:
sql
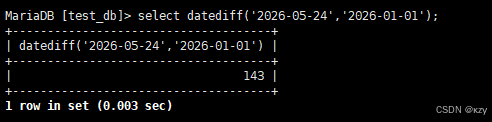
select datediff('2026-05-24','2026-01-01');select datediff('2026-05-24','2026-01-01'),datediff用于计算两个日期相差的天数,结果如下所示:
sql
create table if not exists t36(
id int primary key auto_increment,
content varchar(30) not null,
sendtime datetime
);
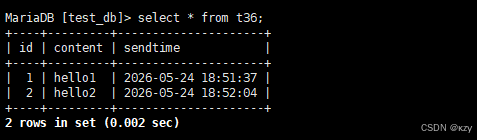
insert into t36(content,sendtime) values('hello1',now());
insert into t36(content,sendtime) values('hello2',now());insert into t36(content,sendtime) values('hello1',now()),insert into t36(content,sendtime) values('hello2',now()),向t36表中插入两条记录,结果如下所示:
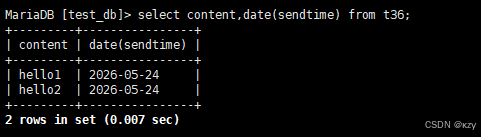
sql
select content,date(sendtime) from t36;select content,date(sendtime) from t36,显示所有留言信息,发布日期只显示日期,不显示具体时间,结果如下所示:
sql
select * from t36 where date_add(sendtime,interval 2 minute)>now();select * from t36 where date_add(sendtime,interval 2 minute)>now(),即查询在2分钟内发布的帖子,结果如下所示:


2、字符串函数
MySQL中常见的字符串函数如下:
sql
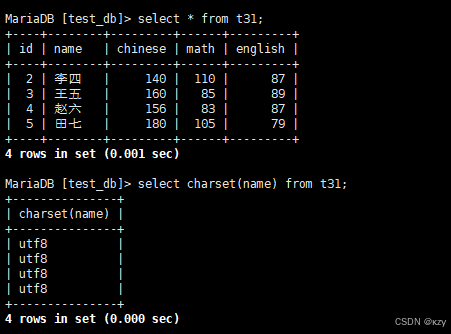
select charset(name) from t31;select charset(name) from t31,用于获取t31表的name列的字符集,结果如下所示:
sql
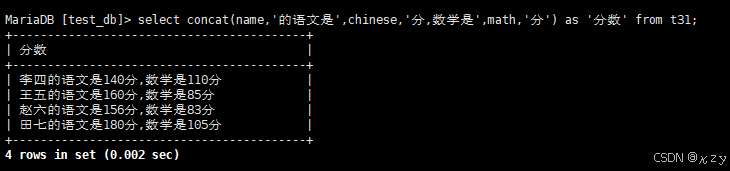
select concat(name,'的语文是',chinese,'分,数学是',math,'分') as '分数' from t31;select concat(name,'的语文是',chinese,'分,数学是',math,'分') as '分数' from t31,使用concat显示t31表的信息,显示格式为:"XXX的语文是XXX分,数学是XXX分,英语XXX分",结果如下所示:
sql
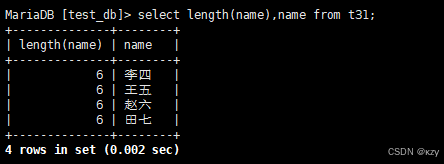
select length(name),name from t31;select length(name),name from t31,用于求t31表中姓名占用的字节数,结果如下所示:
sql
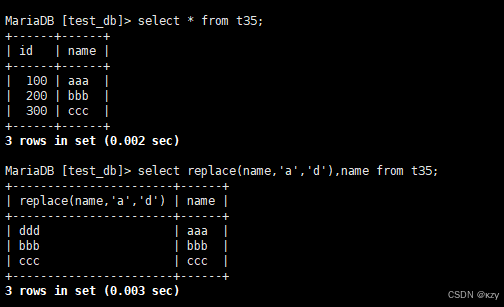
select replace(name,'a','d'),name from t35;select replace(name,'a','d'),name from t35,将t35表中所有名字中有a的替换成d,结果如下所示:
sql
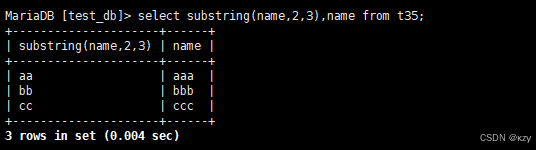
select substring(name,2,3),name from t35;select substring(name,2,3),name from t35,substring(name,2,3)用于截取t35表中name字段的第二个到第三个字符,结果如下所示:
sql
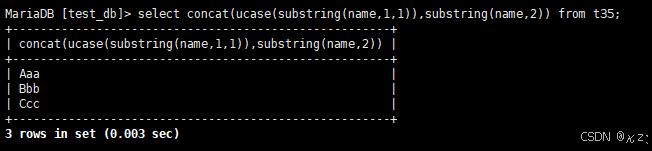
select concat(ucase(substring(name,1,1)),substring(name,2)) from t35;select concat(ucase(substring(name,1,1)),substring(name,2)) from t35,以首字母大写的方式显示name,结果如下所示:
3、数学函数
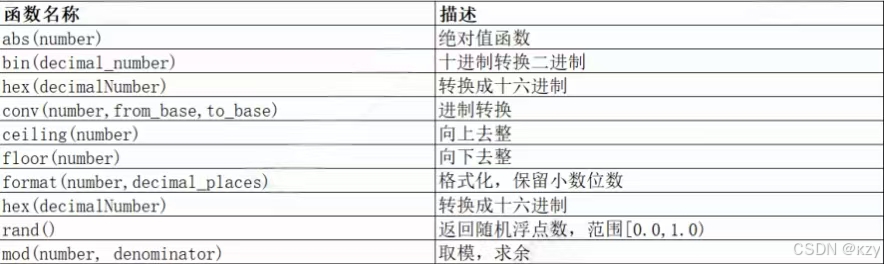
MySQL常见的数学函数如下:
sql
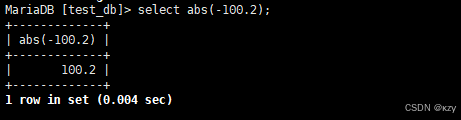
select abs(-100.2);select abs(-100.2),abs用于取绝对值,结果如下所示:
sql
select ceiling(23.04);select ceiling(23.04),ceiling用于向上取整,结果如下所示:
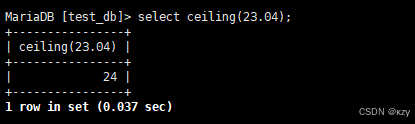
sql
select floor(23.7);select floor(23.7),用于向下取整,结果如下所示:
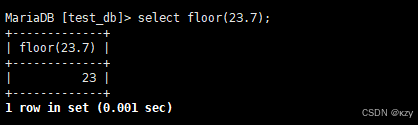
sql
select format(1234.56,2);select format(12.3456,2),format(12.3456,2)用于保留2位小数,结果如下所示:
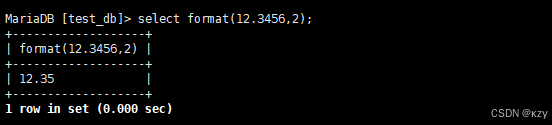
sql
select rand();select rand(),用于产生随机数,结果如下所示:
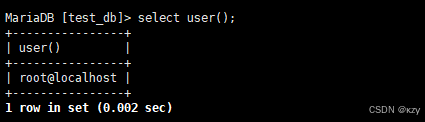
sql
select user();select user(),用于查询当前用户,结果如下所示:
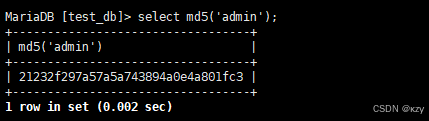
sql
select md5('admin');select md5('admin'),md5('admin')对admin进行md5摘要,摘要后得到一个32位字符串,结果如下所示:
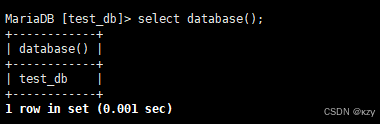
sql
select database();select database(),database()用于显示正在使用的数据库,结果如下所示:
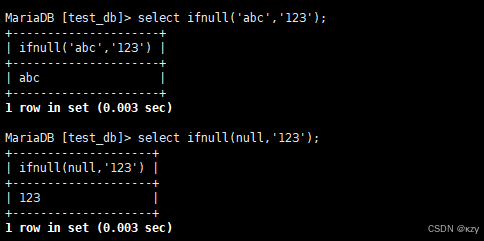
sql
select ifnull('abc','123');
select ifnull(null,'123');select ifnull('abc','123'),select ifnull(null,'123'),ifnull(val1,val2)类似于三目操作符,如果val1为null,则返回val2,否则返回val1,结果如下所示:
三、复合查询
1、单表复合查询
假设这里有3张表,分别为t1员工表,t2部门表、t3工资等级表
sql
select name,job from t1 where sal=(select max(sal) from t1);select name,job from t1 where sal=(select max(sal) from t1),where sal=(select max(sal) from t1),为单表的复合查询,用于查询工资最高的员工名字和工作岗位。
sql
select name,sal from t1 where sal>(select avg(sal) from t1);select name,sal from t1 where sal>(select avg(sal) from t1),where sal>(select avg(sal) from t1),为单表的复合查询,用于查询工资高于平均工资的员工信息。
2、多表查询
实际开发中往往数据来自不同的表,因此需要多表查询。下面通过三张表EMP、DEPT、SALGRADE来演示如何进行多表查询。
sql
select * from EMP,DEPT;select * from EMP,DEPT,会执行笛卡尔积,将EMP表中的每一行和DEPT表中的每一行都组合在一起,如下所示:

sql
select EMP.ename,EMP.sal,DEPT.dname from EMP,DEPT where EMP.depno=DEPT.depno;select EMP.ename,EMP.sal,DEPT.dname from EMP,DEPT where EMP.depno=DEPT.depno,用于查询雇员名、雇员工资以及所在部门的名字,where EMP.depno=DEPT.depno,只要emp表中的deptno=dept表中的deptno字段的记录。
sql
select ename,sal,dname from EMP,DEPT where EMP.depno=DEPT.depno and DEPT.depno=10;select ename,sal,dname from EMP,DEPT where EMP.depno=DEPT.depno and DEPT.depno=10,where EMP.depno=DEPT.depno and DEPT.depno=10,用于查询部门号为10的部门名,员工名和工资。
sql
select ename,sal,grade from EMP,SALGRADE where EMP.sal between losal and hisal;select ename,sal,grade from EMP,SALGRADE where EMP.sal between losal and hisal,用于查询各个员工的姓名、工资、及工资级别。
3、自连接
自连接是指在同一张表连接查询
sql
select empno,ename from emp where emp.empno=(select mgr from emp where ename='FORD');select empno,ename from emp where emp.empno=(select mgr from emp where ename='FORD'),使用子查询显示员工FORD的上级领导的编号和姓名,mgr为员工领导的编号。
sql
select leader.empno,leader.ename from emp leader,emp worker where leader.empno = worker.mgr and worker.ename='FORD';select leader.empno,leader.ename from emp leader,emp worker where leader.empno=worker.mgr and worker.ename='FORD',使用多表查询,使用到表的别名leader、worker。
4、子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询。
(1)单行子查询
单行子查询为返回一行记录的子查询。
sql
select * from EMP where depno=(select depno from EMP where ename='smith');select * from EMP where depno=(select depno from EMP where ename='smith'),where depno=(select depno from EMP where ename='smith',用于查询与smith同一部门的员工。
(2)多行子查询
多行子查询为返回多行记录的子查询。
sql
select ename,job,sal,deptno from emp where job in (select distinct job from emp where deptno=10) and deptno<>10;select ename,job,sal,deptno from emp where job in (select distinct job from emp where deptno=10) and deptno<>10,where job in (select distinct job from emp where deptno=10) and deptno<>10,in关键字用于查询和10号部门的工作岗位相同的雇员的名字、岗位、工资、部门号,但不包含10号自身。
sql
select ename,sal,deptno from EMP where sal>all(select sal from EMP where deptno=30);select ename,sal,deptno from EMP where sal>all(select sal from EMP where deptno=30),where sal>all(select sal from EMP where deptno=30),all关键字用于查询工资比部门30的所有员工的工资高的员工的姓名,工资和部门号。
sql
select ename,sal,deptno from EMP where sal>any(select sal from EMP where deptno=30);select ename,sal,deptno from EMP where sal>any(select sal from EMP where deptno=30),where sal>any(select sal from EMP where deptno=30),any关键字用于查询工资比部门30的任意员工的工资高的员工的姓名、工资和部门号,包含自己部门的员工。
(3)多列子查询
单行子查询是指子查询只返回单列,单行数据;多行子查询是指返回单列多行数据,都是针对单列而言的,而多列子查询则是指查询返回多个列数据的子查询语句。
sql
select ename from EMP where (deptno,job)=(select deptno,job from EMP where ename='SMITH') and ename<>'SMITH';select ename from EMP where (deptno,job)=(select deptno,job from EMP where ename='SMITH') and ename<>'SMITH',where (deptno,job)=(select deptno,job from EMP where ename='SMITH') and ename<>'SMITH',通过where查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人。
(4)from中使用子查询
子查询语句出现在from子句中,这里就要用到一个技巧,把一个子查询当做一个临时表使用。
sql
select ename,deptno,sal,format(asal,2) from EMP,(select avg(sal) asal,deptno dt from EMP group by deptno) tmp where EMP.sal>tmp.asal and EMP.deptno=tmp.dt;select ename,deptno,sal,format(asal,2) from EMP,(select avg(sal) asal,deptno dt from EMP group by deptno) tmp where EMP.sal>tmp.asal and EMP.deptno=tmp.dt,(select avg(sal) asal,deptno dt from EMP group by deptno) tmp,这时select的子查询结果作为一个临时表tmp,用于查询每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资。
sql
select EMP.ename,EMP.sal,EMP.deptno,ms from EMP,(select max(sal) ms,deptno from EMP group by deptno) tmp where EMP.deptno=tmp.deptno and EMP.sal=tmp.ms;select EMP.ename,EMP.sal,EMP.deptno,ms from EMP,(select max(sal) ms,deptno from EMP group by deptno) tmp where EMP.deptno=tmp.deptno and EMP.sal=tmp.ms,(select max(sal) ms,deptno from EMP group by deptno) tmp,将select查询结果作为一个临时表tmp,用于查询每个部门工资最高的人的姓名、工资、部门、最高工资。
sql
select DEPT.dname,DEPT.deptno,DEPT.loc,count(*) '部门人数' from EMP,DEPT where EMP.deptno=DEPT.deptno group by DEPT.deptno,DEPT.dname,DEPT.loc;select DEPT.dname,DEPT.deptno,DEPT.loc,count(*) '部门人数' from EMP,DEPT where EMP.deptno=DEPT.deptno group by DEPT.deptno,DEPT.dname,DEPT.loc,使用多表查询每个部门的信息(部门名、编号、地址)和人员数量,也可使用子查询:
sql
select DEPT.deptno,dname,mycnt,loc from DEPT,(select count(*) mycnt,deptno from EMP group by deptno) tmp where DEPT.deptno=tmp.deptno;select DEPT.deptno,dname,mycnt,loc from DEPT, (select count(*) mycnt,deptno from EMP group by deptno) tmp where DEPT.deptno=tmp.deptno,(select count(*) mycnt,deptno from EMP group by deptno) tmp where DEPT.deptno=tmp.deptno,将select子查询的结果作为一个临时表tmp。
(5)合并查询
为了合并多个select的执行结果,可以使用集合操作符union,union all。
<1> union
该操作符用于取得两个结果集的并集,当使用该操作符时,会自动去掉结果集中的重复行。
sql
select ename,sal,job from EMP where sal>2500 union select ename,sal,job from EMP where job='MANAGER';select ename,sal,job from EMP where sal>2500 union select ename,sal,job from EMP where job='MANAGER',用于查询工资大于2500或职位是MANGGER,union将自动去掉两条select查询结果的重复记录。
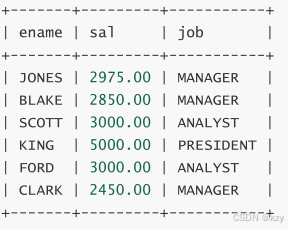
<2> union all
union all用于取得两个结果集的并集,union all不会去掉结果集中的重复行。
sql
select ename,sal,job from EMP where sal>2500 union all select ename,sal,job from EMP where job='MANAGER';select ename,sal,job from EMP where sal>2500 union all select ename,sal,job from EMP where job='MANAGER',用于查询工资大于2500或职位是MANAGER,union all不会去掉结果集的重复记录。
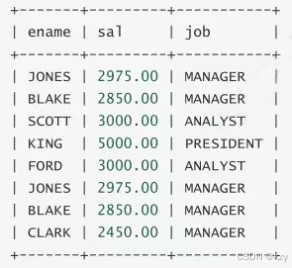
四、内外连接
表的连接分为内连接和外连接两种。
1、内连接
内连接通过where子句对两种表形成的笛卡尔积进行筛选。
模板:

sql
select ename,dname from EMP,DEPT where EMP.deptno=DEPT.deptno and ename='SMITH';select ename,dname from EMP,DEPT where EMP.deptno=DEPT.deptno and ename='SMITH',用于查询SMITH的名字和部门名称,也可使用内连接写法:
sql
select ename,dname from EMP inner join DEPT on EMP.deptno=DEPT.deptno and ename='SMITH';select ename,dname from EMP inner join DEPT on EMP.deptno=DEPT.deptno and ename='SMITH',EMP inner join DEPT,返回EMP、DEPT中匹配的行,EMP.deptno=DEPT.deptno,通过部门编号关联EMP、DEPT表。
2、外连接
外连接分为左外连接和右外连接两种
(1)左外连接
使用联合查询,左侧的表完全显示就是左外连接。
模板:

sql
create table if not exists t37( --学生表
id int,
name varchar(30)
);
insert into t37 values(1,'jack'),(2,'tom'),(3,'jane'),(4,'maria');
sql
create table if not exists t38( --成绩表
id int,
grade int
);
insert into t38 values(1,56),(2,76),(11,8);使用create创建t37学生表,t38成绩表,insert分别向表中插入数据。
若要查询所有学生的成绩,即使这个学生没有成绩,也要将学生的个人信息显示出来,此时就需要将t37学生表与t38成绩表进行左外连接:
sql
select * from t37 left join t38 on t37.id=t38.id;select * from t37 left join t38 on t37.id=t38.id,t37 left join t38 on t37.id=t38.id,将t37学生表与t38成绩表进行左外连接,当t37学生表和右边t38成绩表没有匹配时,也会显示t37学生表的数据,结果如下所示:
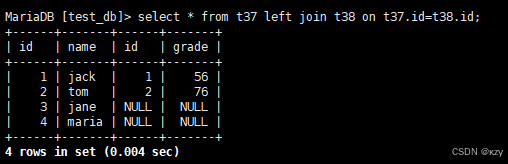
(2)右外连接
与左外连接类似,使用联合查询,右侧的表完全显示就是右外连接。
模板:

sql
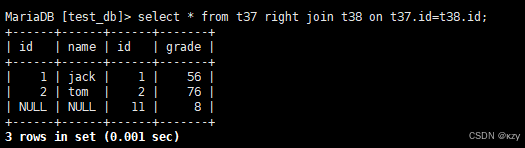
select * from t37 right join t38 on t37.id=t38.id;select * from t37 right join t38 on t37.id=t38.id,对t37学生表和t38成绩表进行右外连接,将所有的成绩都显示出来,即使这个成绩没有学生与它对应,也要显示出来,结果如下所示:
五、索引
1、作用
索引用于提高数据库的性能,只要执行create index,查询速度就可以提高成百上千倍,但查询速度的提高是以插入、更新、删除的速度为代价的,这些写操作,增加了大量的IO,所以索引的价值,在于提高一个海量数据的检索速度。
常见索引分为:
主键索引(primary key)
唯一索引(unique)
普通索引(index)
全文索引(fulltext)-解决中子文索引问题
2、磁盘
MySQL给用户提供存储服务,而存储的都是数据,数据在磁盘这个外设当中。磁盘是计算机中的一个机械设备,相比于计算机其他电子元件,磁盘效率是比较低的,再加上IO本身的特征,如何提高效率,是MySQL的一个重要话题。
磁盘结构如下所示:

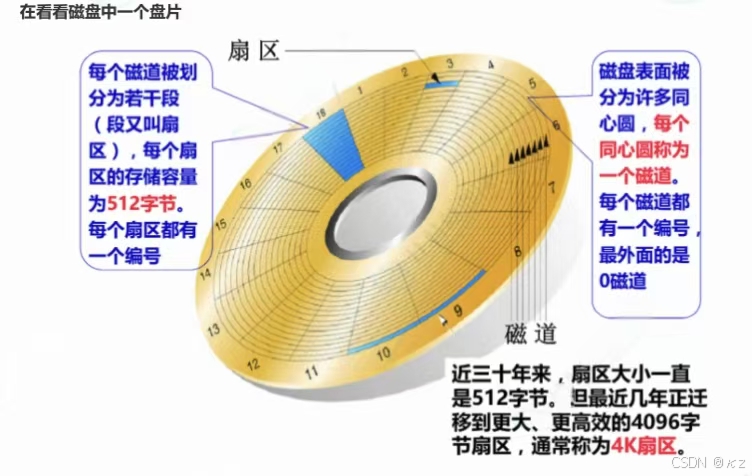
扇区:
MySQL文件,本质其实就是保存在磁盘的盘片当中,也就是扇区。一般来说,MySQL文件很大,也很多,往往需要占据多个扇区。从上图可以看出,在半径方向上,距离圆心越近,扇区越小,距离圆心越远,扇区越大。扇区大小默认为512字节。Linux的大部分目录或者文件,大部分就是保存在磁盘中的。
bash
ls /var/lib/mysql -l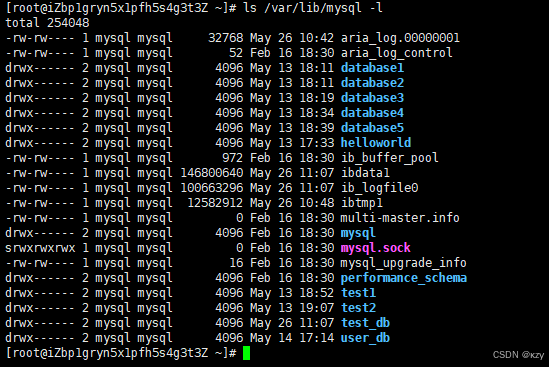
ls /var/lib/mysql -l,可以用来查看MySQL的文件,数据库文件,本质其实就是保存在磁盘的扇区当中,就是一个一个的文件。
找到一个文件的全部,本质就是在磁盘找到所有保存文件的扇区。如果能定位任何一个扇区,那么便能找到所有扇区,因为查找方式是一样的。
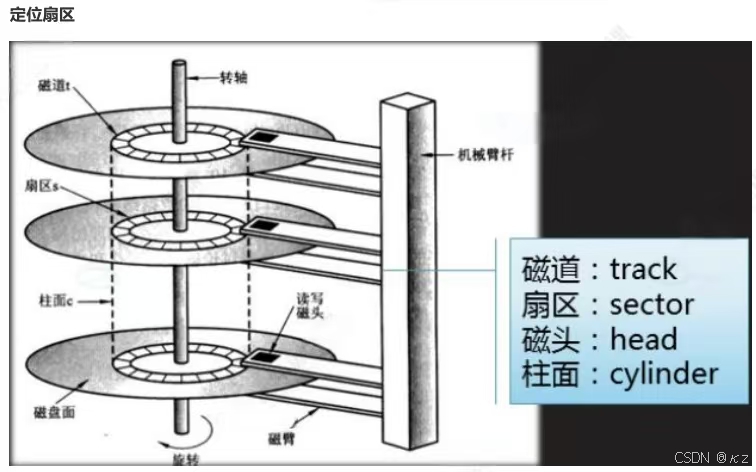
柱面(磁道):多盘磁盘,每盘都是双面,大小完全相等,那么同半径的磁道,整体上便构成了一个柱面。
每个盘面都有一个磁头,磁头和盘面的对应关系是1对1的。
因此只需要磁头、柱面、扇区对应的编号,即可在磁盘上定位所要访问的扇区。这种磁盘数据定位方式称为CHS,系统读取磁盘,是以块为单位的,基本单位是4KB。
3、page
MySQL作为一款应用软件,可以想象成一种特殊的文件系统,有着更高的IO场景。所以,为了提高基本的IO效率,MySQL进行IO的基本单位是16KB。
sql
show global status like 'innodb_page_size';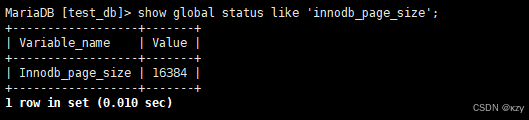
16KB=16*1024=16384,也就是说,磁盘这个硬件设备的基本单位是512字节,而MySQL InnoDB引擎使用16KB进行IO交互,即MySQL和磁盘进行数据交互的基本单位是16KB。这个基本数据单元,在MySQL这里称为page。
MySQL中的数据文件,是以page为单位保存在磁盘当中的。
MySQL的CURD操作,都需要通过计算,找到对应的插入位置,或者找到对应要修改或者查询的数据。而只要涉及计算,就需要CPU参与,而为了便于CPU参与,一定要能够先将数据移动到内存当中。
所以在特定时间内,数据一定是磁盘中有,内存中也有。后续操作完内存数据之后,以特定的刷新策略,刷新到磁盘。而这时,就涉及到磁盘和内存的数据交互,也就是IO了。而此时IO的基本单位就是page。
MySQL服务器在内存中运行时,在服务器内部,就申请了Buffer Pool的大内存空间,来进行各种缓存,其实就是很大的内存空间,来和磁盘数据进行IO交互。
为了提高效率,就一定要尽可能减少系统和磁盘IO的次数。
MySQL中要管理很多数据表文件,而要管理好这些文件,就需要先描述,再组织,可以简单理解为一个个独立文件是由一个或者多个Page构成的。
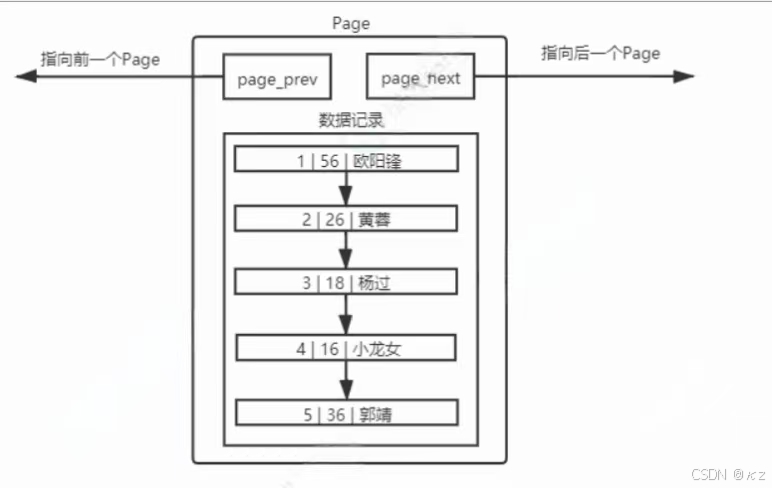
不同的page,在MySQL中,都是16KB,使用prev、next构成双向链表。因为有主键的问题,MySQL会默认按照主键给数据进行排序,从上图的page数据记录可以看出,数据是有序且彼此关联的。
上面页模式中,只有一个功能,就是在查询某条数据的时候直接将一整页的数据加载到内存中,以减少硬盘IO次数,从而提高性能。但是,同时也注意到,页模式内部,采用了链表的结构,前一条数据指向后一条数据,本质上还是通过数据的逐条比较来取出特定的数据。
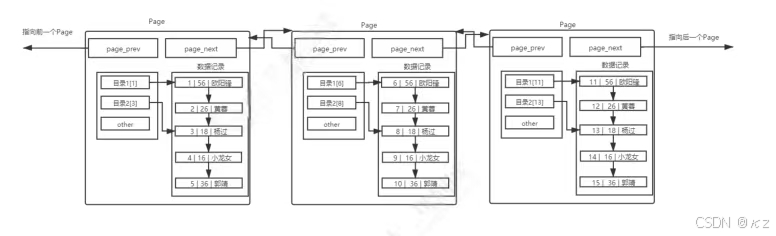
如果有1千万条数据,就需要多个page来保存1千万条数据,多个page彼此通过双链表连接起来,而且每个page内部的数据也都是基于链表的,那么,查找特定一条记录,为线性查找,效率太低。
4、页目录
为了提高查询效率,在page中引入了页目录:
单页page:
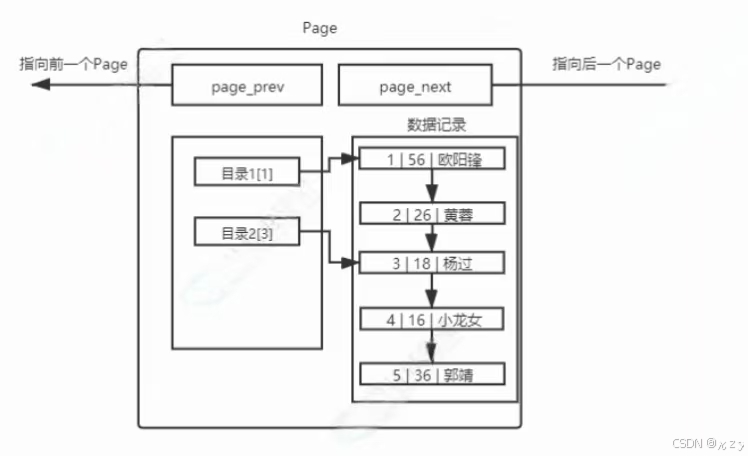
那么现在,比如要查找id=4的记录,之前必须线性遍历4次,才能拿到结果。现在直接通过目录23,直接进行定位新的起始位置,提高了效率,这也就是MySQL为何会通过键值自动排序,可以更方便地引入目录。
多页page:
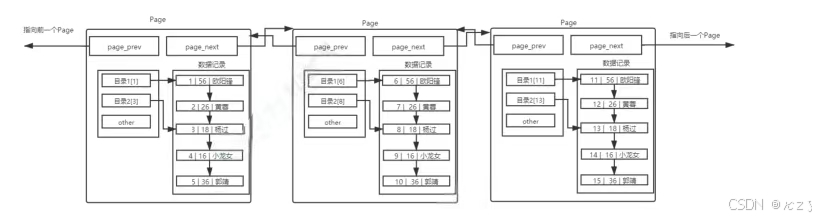
在单表数据不断被插入的情况下,MySQL会在容量不足的时候,自动开辟新的page来保存新的数据,然后通过指针的方式,将所有的page组织起来。
这样,就可以通过多个page遍历,page内部通过目录来快速定位数据。然而,在page之间,也是需要MySQL遍历的,遍历意味着依旧需要进行大量的IO,将下一个page加载到内存,进行线性检测,效率依旧不高。
这时可以考虑给page也带上目录:
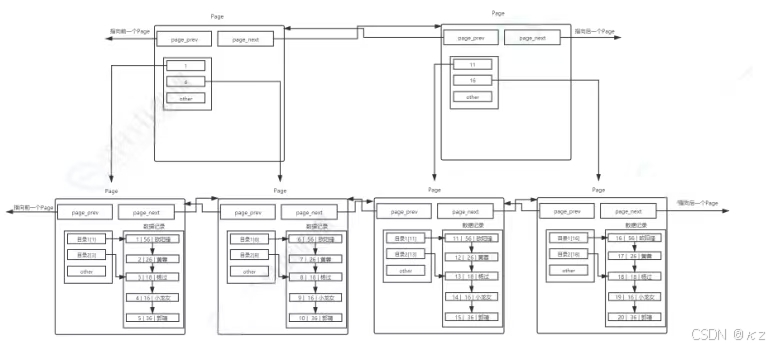
如上图所示,使用一个目录项来指向某一页,而这个目录项存放的就是将要指向的页中存放的最小数据的键值。和页内目录不同的地方在于,这种目录管理的级别是页,而页内目录管理的级别是行。其中,每个目录项的构成是:键值+指针。
存在一个目录页来管理页目录,目录页中的数据存放的就是指向的那一页中最小的数据。有数据,就可以通过比较,找到该访问那个page,进而通过指针,找到下一个page。
目录页的本质也是页,普通页中存的数据是用户数据,而目录页中存的数据是普通页的地址。
主键索引结构如下图:
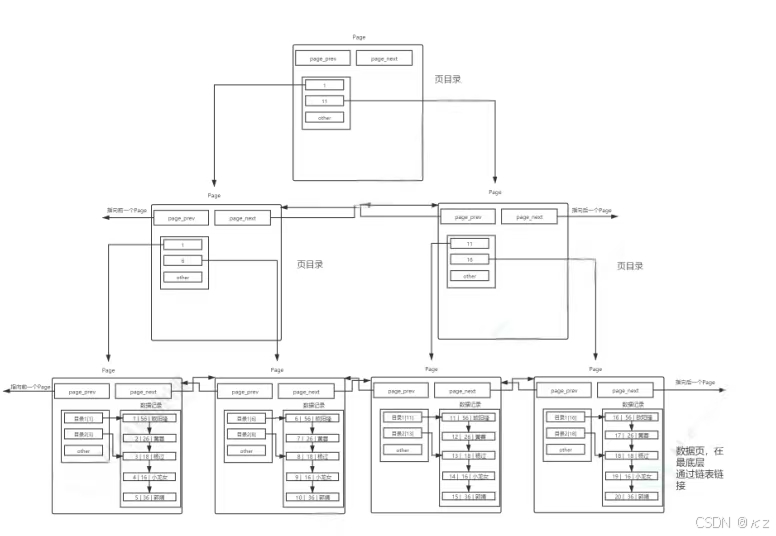
这就是索引的B+树结构,有了这个结构之后,现在查找的page数、IO次数都会相应减少,效率也就提高了。page分为目录页和数据页,目录页只放各个下级page的最小键值。查找的时候,自顶向下找,只需要加载部分目录页到内存,即可完成算法的整个查找过程,大大减少了IO次数。
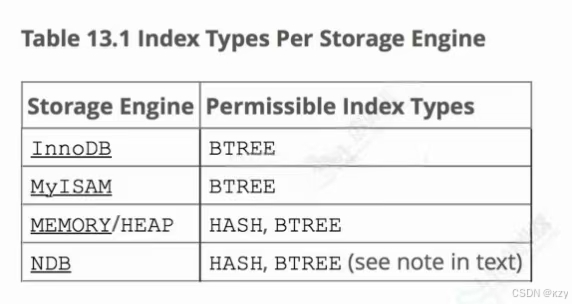
MySQL不同存储引擎支持的索引类型:
5、非聚簇索引
MyISAM存储引擎-主键索引
MyISAM引擎同样使用B+树作为索引结果,叶节点的data域存放的是数据记录的地址。
下图为MyISAM表的主索引,Col1为主键。
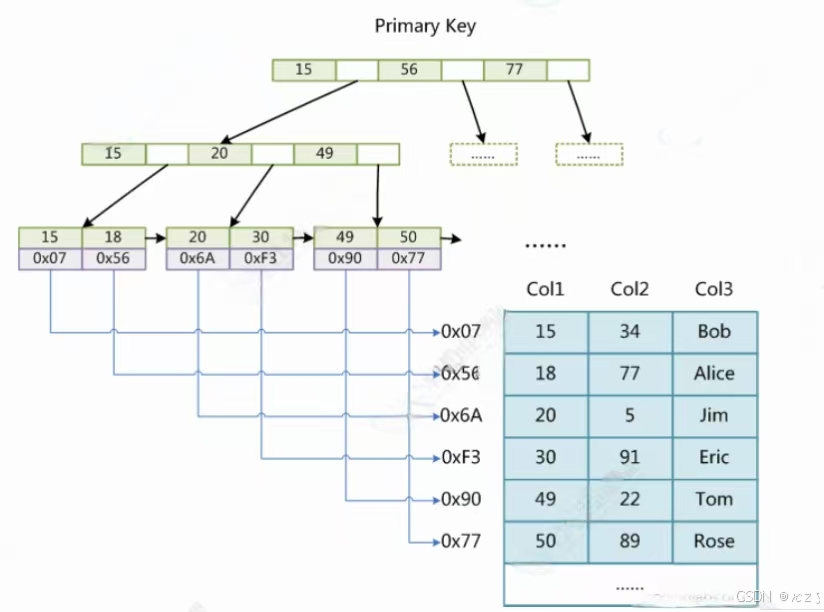
MyISAM最大的特点是,将索引page和数据page分离,也就是叶子结点没有数据,只有对应数据的地址。相比于InnoDB,InnoDB是将索引和数据放在一起。MyISAM这种将用户数据与索引数据分离的索引,称为非聚簇索引。
6、聚簇索引
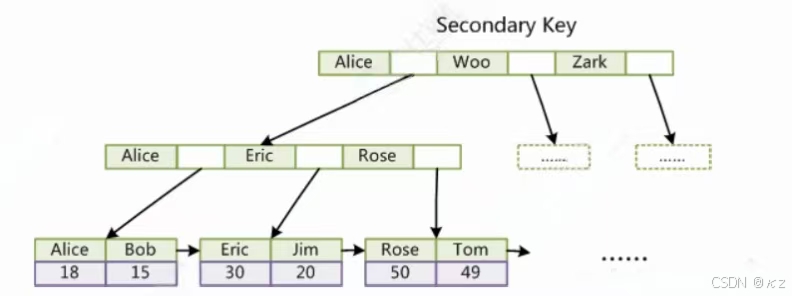
Innode这种将用户数据与索引数据在一起的索引,称为聚簇索引。MySQL除了默认会建立主键索引外,用户也可建立其他列信息的索引,这种索引称为辅助(普通)索引。MyISAM建立辅助索引和主键索引没什么区别,主键不能重复,非主键可重复。
下图是基于MyISAM的col2建立的索引,和主键索引没什么区别:
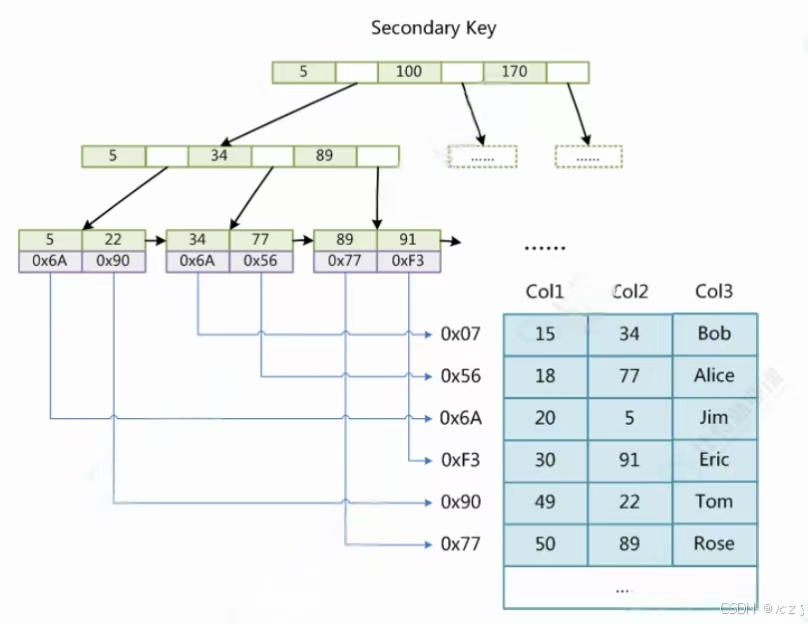
InnoDB除了主键索引,用户也可建立辅助索引。以上表的Col3建立对应的辅助索引如下图:
可以看到,InnoDB的非主键索引中叶子节点并没有数据,而只有对应记录的Key值。
所以通过辅助索引,找到目标记录,需要两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录,称为回表查询。InnoDB针对这种辅助索引的场景,之所以不给叶子节点也附上数据,是为了节省空间。
7、索引操作
(1)主键索引
创建主键索引:
第一种方式:
sql
create table if not exists t39(
id int primary key,
age int not null,
name varchar(16) not null
);create table if not exists t39(id int primary key, age int not null, name varchar(16) not null),id int primary key,在创建表时,直接在id字段名后指定 primary key。
第二种方式:
sql
create table if not exists t40(
id int,
name varchar(30),
primary key(id)
);create table if not exists t40( id int, name varchar(30), primary key(id)),primary key(id),在创建表的最后,指定id列为主键索引。
第三种方式:
sql
create table if not exists t41(
id int,
name varchar(30)
);
alter table t41 add primary key(id);create table if not exists t41( id int, name varchar(30)),alter table t41 add primary key(id),add primary key(id),创建表之后再添加主键id。
主键索引的特点:
一个表中,最多只能有一个主键索引
主键索引的效率高,主键不可重复
创建主键索引的列,它的值不能为null,且不能重复
主键索引的列基本上是int
(2)唯一索引
唯一索引的创建:
第一种方式:
sql
create table if not exists t42(
id int primary key,
name varchar(30) unique
);create table if not exists t42( id int primary key,name varchar(30) unique),name varchar(30) unique,在表定义时,在name列后直接指定unique唯一属性。
第二种方式:
sql
create table if not exists t43(
id int primary key,
name varchar(30),
unique(name)
);create table if not exists t43( id int primary key,name varchar(30),unique(name)),unique(name),创建表时,在表的后面指定name列为unique。
第三种方式:
sql
create table if not exists t44(
id int primary key,
name varchar(30)
);
alter table t44 add unique(name);create table if not exists t44( id int primary key,name varchar(30)),alter table t44 add unique(name),创建表之后,再添加主键name。
唯一索引的特点:
一个表中,可以有多个唯一索引
查询效率高
如果在某一列建立唯一索引,必须保证这列不能有重复数据
如果一个唯一索引上指定not null,等价于主键索引
(3)普通索引
普通索引的创建:
第一种方式:
sql
create table if not exists t45(
id int primary key,
name varchar(20),
index(name)
);create table if not exists t45( id int primary key, name varchar(20), index(name)),index(name)在表定义的最后,指定name列为索引。
第二种方式:
sql
create table if not exists t46(
id int primary key,
name varchar(20)
);
alter table t46 add index(name);create table if not exists t46( id int primary key,name varchar(20)),alter table t46 add index(name),创建完表之后指定name列为普通索引。
第三种方式:
sql
create table if not exists t47(
id int primary key,
name varchar(20)
);
create index idx on t47(name);create table if not exists t47( id int primary key,name varchar(20)),create index idx on t47(name),创建一个索引名为idx的索引。
普通索引的特点:
一个表中可以有多个普通索引
如果某列需要创建索引,但是该列有重复值,则使用普通索引
(4)全文索引
当对文章字段或有大量文字的字段进行检索时,会使用到全文索引。MySQL提供全文索引机制,但要求表的存储引擎必须为MyISAM,且默认的全文索引支持英文,不支持中文。如果要对中文进行全文检索,可以使用sphinx的中文版(coreseek)。
创建全文索引:
sql
create table if not exists t48(
id int unsigned auto_increment not null primary key,
title varchar(200),
body text,
fulltext(title,body)
)engine=MyISAM;create table if not exists t48( id int unsigned auto_increment not null primary key,title varchar(200),body text,fulltext(title,body))engine=MyISAM,fulltext(title,body)为全文索引,对title和body两个字段建立联合全文索引。
查询有没有database数据:
sql
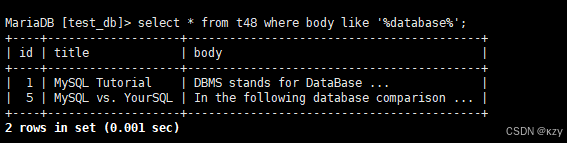
select * from t48 where body like '%database%';select * from t48 where body like '%database%',可以查询到数据,但没有用到全文索引,结果如下所示:
sql
explain select * from t48 where body like '%database%'\G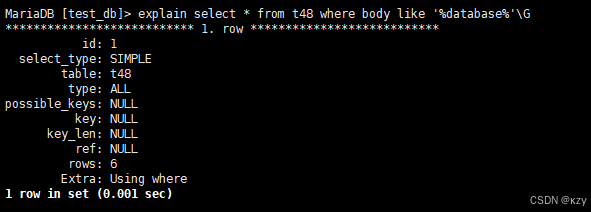
explain select * from t48 where body like '%database%'\G,通过explain来查看是否使用到索引,由上图可以看出,key为null,表示没有用到全文索引。
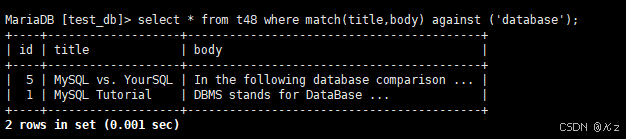
sql
select * from t48 where match(title,body) against ('database');select * from t48 where match(title,body) against ('database'),match(title,body) against ('database'),使用了全文索引,结果如下所示:
sql
explain select * from t48 where match(title,body) against ('database')\G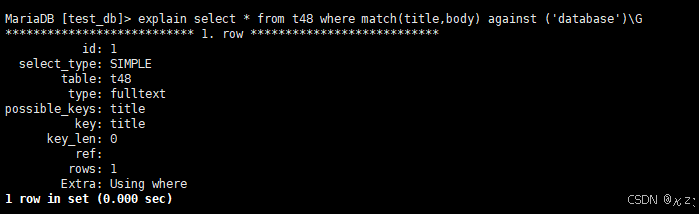
explain select * from t48 where match(title,body) against ('database')\G,通过explain来分析该语句,从上图可以看出,key:title,用到了全文索引。
(5)查询索引
第一种方法:
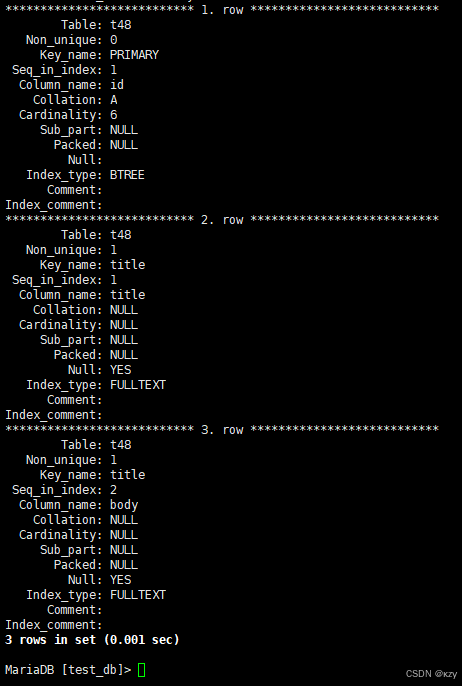
sql
show keys from t48\G结果如下所示:
第二种方法:
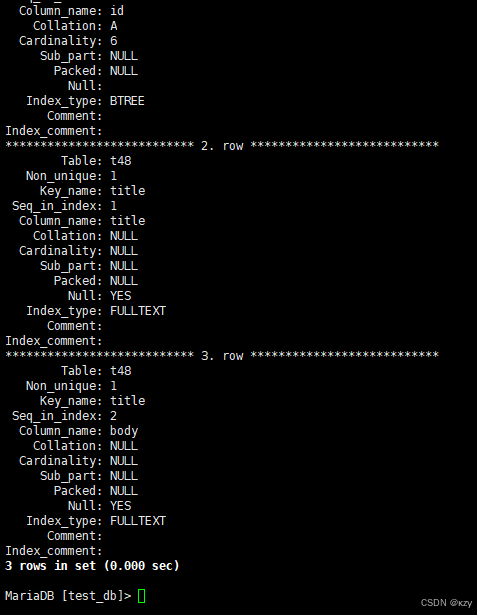
sql
show index from t48\G结果如下所示:
第三种方法:
sql
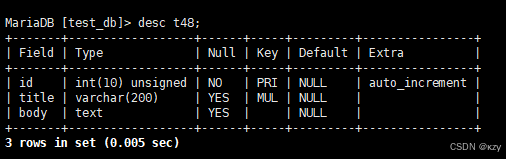
desc t48;结果如下所示:
(6)删除索引
删除主键索引:

sql
alter table t47 drop primary key;alter table t47 drop primary key,删除t47表的主键索引。
删除其他索引:

sql
alter table t46 drop index name;alter table t46 drop index name,删除t46表的索引名为name的索引,索引名就是show keys from t46中的key_name字段。

sql
drop index idx on t47;drop index idx on t47,删除t47表中索引名为idx的索引。
8、应用
索引使用场景:
比较频繁作为查询条件的字段应该创建索引
唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
更新非常频繁的字段不适合创建索引
不会出现在where子句的字段不该创建索引
结语
本文主要围绕MySQL表的CURD操作、索引展开介绍,从最基础的增删查改操作出发,逐步深入到性能优化的核心---索引。整体而言,表是数据的载体,而索引则是提升数据检索效率的关键,二者相辅相成。合理的索引设计能大大提高数据库的查询效率,但过度或不当的索引则会拖慢查询速度并占用额外空间。MySQL表的增删查改与索引优化,核心在于平衡功能与效率。增删改是数据流动的基础,熟练掌握INSERT、UPDATE、DELETE的基本用法,结合索引优化,与业务查询模式精确匹配,并在读写性能之间做出取舍。在实际开发中,结合具体的数据量、读写比例和查询模式,不断调优,才能让MySQL在性能与资源之间达到最佳平衡。