Windows 下 CUDA / cuDNN / PyTorch GPU 训练环境搭建完整指南:虚拟环境与系统级环境两种方案
面向读者:刚接触深度学习环境配置的新手、正在从云端迁移到本地训练的开发者、需要维护 Windows 训练机的中级开发者。
实践场景:Windows 10/11 + NVIDIA 显卡 + Python + PyTorch / YOLO 系列目标检测训练。
本文示例版本:Python 3.11、PyTorch 2.8.0 + CUDA 12.8 wheel、NVIDIA RTX 50 系显卡。实际项目中请优先参考 PyTorch 和 NVIDIA 官方页面的最新版本。
---
1. 为什么 Windows GPU 环境容易让人困惑
很多同学第一次在 Windows 上配置深度学习 GPU 环境时,最常遇到几个问题:
- 明明装了显卡驱动,
torch.cuda.is_available()却是False nvidia-smi显示 CUDA 13.x,但 PyTorch 安装命令却写 CUDA 12.8- 网上教程要求手动安装 CUDA Toolkit、cuDNN、复制 DLL,但 PyTorch 官网只让执行一条
pip install - 系统里有多个 Python,虚拟环境明明激活了,结果运行的还是另一个 Python
- Windows 下训练启动时报
WinError 2、DataLoader worker、fbgemm.dll等错误
根本原因是:NVIDIA 驱动、CUDA Toolkit、cuDNN、PyTorch wheel、Python 环境是不同层次的东西。它们有关联,但不是同一个东西。
2. 先理解四个核心概念
2.1 NVIDIA Driver:显卡驱动
显卡驱动是 GPU 能被系统和程序调用的基础。没有驱动,后面的 CUDA、PyTorch 都谈不上。
检查命令:
powershell
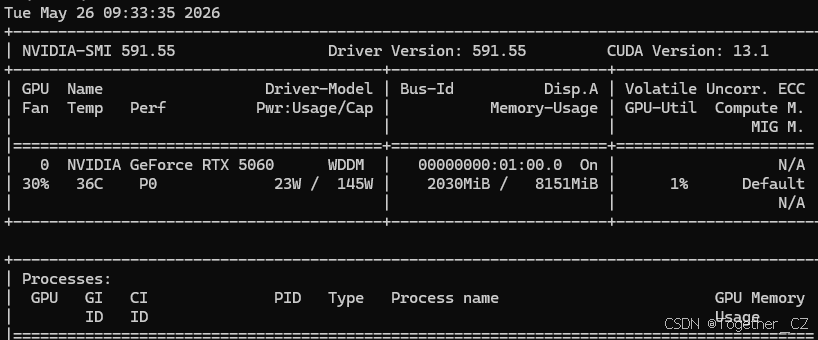
nvidia-smi如果能看到显卡型号、驱动版本、显存占用,说明驱动大体正常。
注意:nvidia-smi 里显示的 CUDA Version 表示当前驱动支持的 CUDA Driver API 上限,不等于你已经安装了对应版本的 CUDA Toolkit。
例如:
text
Driver Version: 591.55
CUDA Version: 13.1这只能说明驱动最高支持 CUDA 13.1 一类的运行能力,不代表你的电脑已经安装了 nvcc,也不代表 PyTorch 必须安装 CUDA 13.1 版本。
2.2 CUDA Toolkit:CUDA 开发工具包
CUDA Toolkit 是 NVIDIA 提供的开发工具包,里面包含:
nvcc编译器- CUDA 头文件
- 静态/动态库
- 示例程序
- Nsight 等开发工具
检查命令:
powershell
nvcc --version如果提示找不到 nvcc,说明没有安装 CUDA Toolkit,或者没有加入 PATH。
对于大多数 PyTorch 训练任务来说,不一定需要系统级 CUDA Toolkit。只有以下场景通常才需要:
- 编译自定义 CUDA/C++ 扩展
- 使用
nvcc - 编译依赖 CUDA Toolkit 的第三方库
- 做 CUDA C/C++ 开发
2.3 cuDNN:深度神经网络加速库
cuDNN 是 NVIDIA 提供的深度学习加速库,常用于卷积、归一化、RNN 等深度学习算子。
过去很多教程会要求手动下载 cuDNN,然后把 DLL 复制到 CUDA Toolkit 目录。但对现代 PyTorch pip wheel 来说,通常不需要手工复制 cuDNN,因为 PyTorch 的 CUDA wheel 会携带匹配的运行时库。
在 PyTorch 中检查:
powershell
python -c "import torch; print(torch.backends.cudnn.version())"如果输出一个数字,例如:
text
91002说明 PyTorch 能访问到 cuDNN。
2.4 PyTorch CUDA wheel:最常用、最省心的训练运行环境
PyTorch 官方提供带 CUDA 运行库的 pip wheel。以 CUDA 12.8 wheel 为例:
powershell
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu128这类 wheel 通常已经包含训练所需的 CUDA Runtime、cuDNN、cuBLAS 等运行库。只要显卡驱动足够新,PyTorch 就可以调用 GPU。
所以很多时候,正确思路不是:
text
先装 CUDA Toolkit -> 再装 cuDNN -> 再装 PyTorch而是:
text
先装 NVIDIA 驱动 -> 再安装匹配的 PyTorch CUDA wheel -> 验证 torch.cuda3. 总体架构图
可选:需要 nvcc 时
开发/编译 CUDA 扩展
Windows 系统
NVIDIA Driver 显卡驱动
nvidia-smi 可识别 GPU
Python 环境
虚拟环境 .venv
系统级 Python
PyTorch CUDA wheel
内置 CUDA Runtime / cuDNN / cuBLAS
torch.cuda.is_available() == True
YOLO / PyTorch GPU 训练
CUDA Toolkit
4. 两种安装方案怎么选
Windows 下建议优先考虑两种方案:
| 方案 | 安装位置 | 适合人群 | 优点 | 风险 |
|---|---|---|---|---|
| 虚拟环境方案 | 项目目录 .venv |
大多数开发者、训练项目、多人协作 | 隔离、安全、容易删除重来 | 每个项目可能要单独建环境 |
| 系统级方案 | 全局 Python 3.11 | 单机固定训练环境、只维护一个项目 | 命令短,任何位置都能调用 | 会污染全局包,回滚麻烦 |
本文建议:
- 新手和项目开发:优先虚拟环境
- 固定训练机、明确知道风险:可以系统级安装
- 需要
nvcc或编译自定义 CUDA 算子:再安装 CUDA Toolkit
5. 方案选择流程图
否
是
否,大多数 PyTorch/YOLO 训练
是
是,推荐
否,只维护一套全局环境
准备在 Windows 上训练深度学习模型
是否已经安装 NVIDIA 驱动?
先安装/更新 NVIDIA Driver
运行 nvidia-smi 验证
是否需要 nvcc / 编译 CUDA 扩展?
是否希望隔离项目依赖?
安装 CUDA Toolkit,可选安装系统级 cuDNN
使用虚拟环境方案
使用系统级 Python 方案
安装 PyTorch cu128 wheel
验证 torch.cuda / cuDNN / YOLO 导入
开始训练
6. 安装前检查清单
6.1 检查 Windows 和显卡
powershell
Get-ComputerInfo | Select-Object WindowsProductName, WindowsVersion, OsBuildNumber, OsArchitecture
Get-CimInstance Win32_VideoController | Select-Object Name, DriverVersion, AdapterRAM
nvidia-smi重点看:
- 是否能看到 NVIDIA 显卡
nvidia-smi是否能正常运行- 显卡驱动是否较新
- 显存大小是否符合训练需求
6.2 检查 Python
建议使用 Python 3.11:
powershell
where python
where python311
python --version
python311 --version如果系统里有 Python 3.8、3.10、3.11 多个版本,一定要确认当前命令到底指向哪个解释器。
6.3 检查是否已经有 CUDA Toolkit
powershell
nvcc --version找不到 nvcc 并不代表不能训练 PyTorch 模型。它只说明系统级 CUDA Toolkit 没有安装或没有加入 PATH。
7. 虚拟环境方案:推荐方式
虚拟环境方案的核心目标是:不动系统 Python,不污染全局环境,所有依赖都装在项目目录里。
7.1 适合场景
- 你有多个项目,依赖版本不同
- 你担心全局 Python 被装乱
- 你希望出问题后能直接删除环境重来
- 你要把项目复制到另一台电脑复现
7.2 流程图
进入项目目录
创建 .venv-yolo26-cu128
升级 pip / setuptools / wheel
安装 torch 2.8.0+cu128 / torchvision 0.23.0+cu128
安装项目依赖 requirements-yolo26-cu128.txt
验证 torch.cuda
验证 cuDNN
验证 YOLO 导入/推理
训练 train.py
7.3 手动安装步骤
这里我们以本地化开发训练YOLOv26目标检测模型为切入点进行环境的构建,进入项目目录:
powershell
cd D:\self\v26创建虚拟环境:
powershell
python311 -m venv .venv-yolo26-cu128激活虚拟环境:
powershell
.\.venv-yolo26-cu128\Scripts\Activate.ps1如果 PowerShell 不允许执行脚本,可以临时使用:
powershell
powershell.exe -ExecutionPolicy Bypass或者不激活,直接使用完整路径:
powershell
.\.venv-yolo26-cu128\Scripts\python.exe --version升级基础工具:
powershell
python -m pip install --upgrade pip setuptools wheel安装 CUDA 版 PyTorch:
powershell
python -m pip install torch==2.8.0 torchvision==0.23.0 --index-url https://download.pytorch.org/whl/cu128安装项目依赖:
powershell
python -m pip install -r requirements-yolo26-cu128.txt -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn如果你使用官方 PyPI:
powershell
python -m pip install -r requirements-yolo26-cu128.txt7.4 一键安装脚本
项目中已经提供虚拟环境一键安装脚本:
powershell
cd D:\self\v26
.\install_yolo26_windows.bat强制重建虚拟环境:
powershell
.\install_yolo26_windows.bat -ForceRecreate指定 Python:
powershell
.\install_yolo26_windows.bat -PythonCommand D:\Python311\python311.exe7.5 验证
powershell
where python
python -c "import sys, torch; print(sys.executable); print(torch.__version__, torch.version.cuda, torch.cuda.is_available(), torch.cuda.get_device_name(0))"
python -c "import torch; print(torch.backends.cudnn.version())"期望看到类似:
text
D:\self\v26\.venv-yolo26-cu128\Scripts\python.exe
2.8.0+cu128 12.8 True NVIDIA GeForce RTX 5060
910027.6 启动训练
powershell
python train.pyWindows 下建议在训练参数中显式指定:
python
workers=0原因是 Windows 的多进程启动机制和 Linux 不一样,PyTorch DataLoader 在多 worker 时可能出现 WinError 2、子进程启动失败等问题。
8. 系统级方案:直接安装到全局 Python
系统级方案的核心目标是:让全局 Python 3.11 直接具备 GPU 训练能力。
8.1 适合场景
- 这台电脑就是固定训练机
- 你希望任何目录都能直接执行
python311 - 你能接受全局包版本被改变
不适合:
- 多项目、多版本依赖
- 想要轻松回滚
- 不确定全局 Python 里已有项目是否依赖旧版本包
8.2 系统级方案流程图
不需要,普通 PyTorch 训练
需要 nvcc/编译扩展
确认 nvidia-smi 正常
确认全局 Python 3.11
备份 pip freeze
是否需要 CUDA Toolkit?
跳过 Toolkit
winget 安装 Nvidia.CUDA
全局安装 PyTorch cu128 wheel
全局安装项目依赖
pip check
验证 torch.cuda / cuDNN
python311 train.py
8.3 手动安装步骤
确认 Python:
powershell
python311 --version
python311 -m pip --version备份当前全局依赖:
powershell
python311 -m pip freeze > global_python311_freeze_before.txt升级基础工具:
powershell
python311 -m pip install --upgrade pip setuptools wheel安装 CUDA 版 PyTorch:
powershell
python311 -m pip install torch==2.8.0 torchvision==0.23.0 --index-url https://download.pytorch.org/whl/cu128安装项目依赖:
powershell
python311 -m pip install -r requirements-yolo26-cu128.txt -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn验证:
powershell
python311 -c "import torch; print(torch.__version__, torch.version.cuda, torch.cuda.is_available(), torch.cuda.get_device_name(0))"
python311 -c "from ultralytics import YOLO; print('ok')"训练:
powershell
python311 train.py8.4 系统级一键脚本
项目中已经提供系统级一键安装脚本:
powershell
cd D:\self\v26
.\install_yolo26_windows_system.bat先演练,不实际安装:
powershell
.\install_yolo26_windows_system.bat -DryRun指定 Python:
powershell
.\install_yolo26_windows_system.bat -PythonCommand D:\Python311\python311.exe同时安装 CUDA Toolkit:
powershell
.\install_yolo26_windows_system.bat -InstallCudaToolkit脚本会保存安装前后的 pip freeze 快照,方便排查。
9. 是否要安装系统级 CUDA Toolkit 和 cuDNN
9.1 普通 PyTorch / YOLO 训练
通常不需要。
推荐组合:
text
NVIDIA Driver + PyTorch CUDA wheel优点:
- 安装简单
- 版本匹配由 PyTorch 官方 wheel 处理
- 不需要手动复制 cuDNN DLL
- 不容易把系统 PATH 搞乱
9.2 需要编译 CUDA 扩展
如果你需要 nvcc,就需要 CUDA Toolkit:
powershell
winget install --id Nvidia.CUDA --exact --source winget --accept-source-agreements --accept-package-agreements安装后重新打开终端,验证:
powershell
nvcc --version9.3 手动安装 cuDNN
如果你不是使用 PyTorch wheel 自带的 cuDNN,而是做 TensorFlow、C++ 推理、CUDA 原生开发等,可能需要单独安装 cuDNN。此时应严格参考 NVIDIA 官方 cuDNN 文档。
常见方式包括:
- zip/tarball 包安装
- wheel 安装
- conda 安装
不建议随意从旧教程下载 DLL 后到处复制。版本不匹配很容易导致运行时 DLL 加载失败。
10. 版本关系:不要被数字吓到
10.1 nvidia-smi 的 CUDA 版本
nvidia-smi 中的 CUDA 版本是驱动支持能力,不是 PyTorch 实际使用的 CUDA Runtime 版本。
10.2 PyTorch 的 CUDA 版本
PyTorch 中查看:
powershell
python -c "import torch; print(torch.version.cuda)"如果输出:
text
12.8表示当前 PyTorch wheel 是基于 CUDA 12.8 构建的。
10.3 CUDA Toolkit 的版本
CUDA Toolkit 中查看:
powershell
nvcc --version这个版本只在你需要编译 CUDA 代码时重要。普通 PyTorch 训练不要求它和 torch.version.cuda 完全一致。
11. 常见错误与排查
11.1 torch.cuda.is_available(): False
可能原因:
- 装的是 CPU 版 PyTorch
- 当前 Python 不是你以为的那个环境
- NVIDIA 驱动未安装或太旧
- 显卡不支持当前 PyTorch wheel
排查:
powershell
where python
python -c "import sys, torch; print(sys.executable); print(torch.__version__, torch.version.cuda, torch.cuda.is_available())"
nvidia-smi如果看到:
text
torch 1.x.x+cpu说明装的是 CPU 版,需要重新安装 CUDA wheel。
11.2 虚拟环境激活后仍然运行全局 Python
检查:
powershell
where python第一条应该是:
text
项目目录\.venv-yolo26-cu128\Scripts\python.exe如果不是,说明虚拟环境没有正确激活,或者虚拟环境里缺少 python.exe 入口。
可以补齐:
powershell
Copy-Item .\.venv-yolo26-cu128\Scripts\python311.exe .\.venv-yolo26-cu128\Scripts\python.exe -Force11.3 fbgemm.dll 或 DLL 加载失败
可能原因:
- PyTorch 安装不完整
- wheel 与 Python 版本不匹配
- 缺少运行库
- 环境中混入了旧版本包
建议:
powershell
python -m pip uninstall torch torchvision torchaudio -y
python -m pip install torch==2.8.0 torchvision==0.23.0 --index-url https://download.pytorch.org/whl/cu128虚拟环境中出问题时,最省事的方式通常是删除 .venv 后重建。
11.4 Windows DataLoader 报 WinError 2
错误类似:
text
FileNotFoundError: [WinError 2] 系统找不到指定的文件通常是 Windows 下 PyTorch DataLoader 多进程 worker 启动失败。
解决:
python
model.train(..., workers=0)训练速度可能略有影响,但稳定性更好。
11.5 CUDA out of memory
显存不足。
解决顺序:
- 减小
batch - 减小
imgsz - 换更小模型,例如从
x/l换到m/s/n - 关闭其他占用显存的程序
示例:
python
model.train(data="self.yaml", batch=4, imgsz=640, device=0, workers=0)11.6 标签类别越界
错误类似:
text
Label class 10 exceeds dataset class count 10含义:数据集中出现了类别编号 10,但配置 nc: 10 只允许 0-9。
解决:
- 如果确实有 11 类,改成
nc: 11,并提供 11 个类别名 - 如果原始标注是
1-10,需要整体平移成0-9 - 不要在没确认类别语义前盲目批量替换
12. 训练脚本建议写法
Windows 下建议把通用训练参数集中起来:
python
from ultralytics import YOLO
if __name__ == "__main__":
save_dir = "runs/detect/"
device = [0]
epochs = 100
train_args = dict(
data="self.yaml",
save_dir=save_dir,
epochs=epochs,
device=device,
workers=0,
)
model = YOLO("weights/yolo26n.pt")
model.train(batch=8, name="yolo26n", **train_args)这样以后切换模型时,不容易漏掉 workers=0、device=[0] 等关键参数。
13. 验证命令合集
13.1 驱动
powershell
nvidia-smi13.2 Python 和 PyTorch
powershell
where python
python -c "import sys; print(sys.executable)"
python -c "import torch; print(torch.__version__, torch.version.cuda, torch.cuda.is_available())"
python -c "import torch; print(torch.cuda.get_device_name(0))"
python -c "import torch; print(torch.backends.cudnn.version())"13.3 实际 GPU 计算
powershell
python -c "import torch; x=torch.randn(2048,2048,device='cuda'); y=x@x; torch.cuda.synchronize(); print(y.shape, y.device)"13.4 YOLO 导入
powershell
python -c "from ultralytics import YOLO; print('ultralytics ok')"13.5 YOLO 推理
powershell
python -c "from ultralytics import YOLO; model=YOLO('weights/yolo26n.pt'); r=model.predict(source='ultralytics/assets/bus.jpg', device=0, imgsz=640, save=False); print(len(r))"14. 回滚方案
14.1 虚拟环境回滚
虚拟环境最简单:
powershell
Remove-Item .\.venv-yolo26-cu128 -Recurse -Force然后重新运行一键脚本即可。
14.2 系统级 Python 回滚
系统级环境没有那么干净。建议安装前保存:
powershell
python311 -m pip freeze > global_python311_freeze_before.txt如果后续要排查,可以对比安装前后依赖差异。
严重混乱时,最彻底的方式是:
- 卸载/重装 Python 3.11
- 或者新建虚拟环境,不再依赖全局 Python
14.3 CUDA Toolkit 回滚
如果通过 winget 安装:
powershell
winget uninstall --id Nvidia.CUDA卸载后重新打开终端,再检查:
powershell
nvcc --version15. 推荐实践总结
对大多数 Windows 深度学习训练项目,推荐路径是:
text
安装 NVIDIA Driver
-> nvidia-smi 验证
-> 创建项目虚拟环境
-> 安装 PyTorch CUDA wheel
-> 安装项目依赖
-> 验证 torch.cuda / cuDNN
-> 训练只有在确实需要 CUDA 编译能力时,才额外安装 CUDA Toolkit。
一句话总结:
PyTorch/YOLO 训练需要的是"能运行 CUDA 的 PyTorch 环境",不一定需要你手工安装系统级 CUDA Toolkit 和 cuDNN。虚拟环境优先,系统级安装谨慎使用。
16. 官方参考资料
- PyTorch 官方安装页面:https://pytorch.org/get-started/locally/
- PyTorch 历史版本安装命令:https://pytorch.org/get-started/previous-versions/
- NVIDIA CUDA Windows 安装指南:https://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows/
- NVIDIA cuDNN 安装指南:https://docs.nvidia.com/deeplearning/cudnn/installation/latest/
- NVIDIA cuDNN Developer 页面:https://developer.nvidia.com/cudnn