1. 线性模型:机器学习的"万能打底衫"
如果说机器学习是一座大厦,那线性模型就是最底层的地基。它看起来简单到"小学生都能懂"------不就是一条直线嘛?但实际上,从房价预测到疾病诊断,从推荐系统到自然语言处理,几乎所有复杂模型的背后都能看到线性模型的影子。
举个最接地气的例子:你去水果摊挑西瓜,老板告诉你"这个瓜甜",你心里其实已经在做线性计算了:甜度 = 0.7×色泽 + 0.5×根蒂 + 0.3×敲声 + 基础分 。这里的0.7、0.5、0.3就是每个特征的"重要性权重",基础分就是所有特征都为0时的默认甜度。这就是线性模型最朴素的思想:用特征的线性组合来预测结果。
2. 线性模型的基本形式
线性模型的数学表达式非常简洁:
f(x)=w1x1+w2x2+⋯+wdxd+bf(x) = w_1x_1 + w_2x_2 + \dots + w_dx_d + bf(x)=w1x1+w2x2+⋯+wdxd+b
公式符号全解析
- f(x)f(x)f(x):模型的预测值(比如西瓜的甜度、房价)
- xix_ixi:第iii个特征(比如西瓜的色泽、根蒂、敲声)
- wiw_iwi:第iii个特征的权重(表示这个特征对预测结果的影响程度,权重越大越重要)
- bbb:偏置项(也叫截距,相当于所有特征都为0时的基础预测值)
- ddd:特征的个数
为了计算方便,我们通常把它写成向量形式:
f(x)=wTx+bf(x) = w^Tx + bf(x)=wTx+b
其中w=(w1;w2;... ;wd)w = (w_1; w_2; \dots; w_d)w=(w1;w2;...;wd)是列向量,x=(x1;x2;... ;xd)x = (x_1; x_2; \dots; x_d)x=(x1;x2;...;xd)是特征向量,wTw^TwT是www的转置。
通俗解释:向量形式就像把所有特征和权重打包成两个数组,然后做"对应相乘再相加"的操作,计算机处理起来特别快。
3. 线性回归:找一条最"合身"的直线
线性回归是线性模型中最基础也最常用的一种,它的目标是:找到一条直线,使得所有样本点到这条直线的垂直距离之和最小。
3.1 单变量线性回归:一个特征的预测
先从最简单的单变量情况入手,比如我们想用西瓜的"密度"来预测"含糖率"。这时候模型就变成了:
f(x)=wx+bf(x) = wx + bf(x)=wx+b
我们的目标是找到最优的www和bbb,使得预测值f(xi)f(x_i)f(xi)和真实值yiy_iyi的误差最小。这里用均方误差 来衡量误差:
E(w,b)=∑i=1m(yi−f(xi))2=∑i=1m(yi−wxi−b)2E_{(w,b)} = \sum_{i=1}^m (y_i - f(x_i))^2 = \sum_{i=1}^m (y_i - wx_i - b)^2E(w,b)=i=1∑m(yi−f(xi))2=i=1∑m(yi−wxi−b)2
公式符号全解析
- mmm:训练样本的总数
- yiy_iyi:第iii个样本的真实值(比如第iii个西瓜的真实含糖率)
- f(xi)f(x_i)f(xi):第iii个样本的预测值
- E(w,b)E_{(w,b)}E(w,b):所有样本的总误差
通俗解释:均方误差就是每个点的预测误差的平方和。为什么用平方?一是为了让正负误差不抵消(比如预测高了0.2和低了0.2都是误差),二是放大大误差的影响,让模型更关注那些预测错得离谱的点。
3.2 最小二乘法:误差最小化的数学魔法
要最小化均方误差,我们可以用最小二乘法 ,也就是对www和bbb分别求偏导,然后令偏导数为0,解出闭式解:
w=∑i=1m(xi−xˉ)(yi−yˉ)∑i=1m(xi−xˉ)2w = \frac{\sum_{i=1}^m (x_i - \bar{x})(y_i - \bar{y})}{\sum_{i=1}^m (x_i - \bar{x})^2}w=∑i=1m(xi−xˉ)2∑i=1m(xi−xˉ)(yi−yˉ)
b=yˉ−wxˉb = \bar{y} - w\bar{x}b=yˉ−wxˉ
其中xˉ=1m∑i=1mxi\bar{x} = \frac{1}{m}\sum_{i=1}^m x_ixˉ=m1∑i=1mxi是特征的均值,yˉ=1m∑i=1myi\bar{y} = \frac{1}{m}\sum_{i=1}^m y_iyˉ=m1∑i=1myi是标签的均值。
"对数线性回归"(log-linear regression)实际上是在试图让ewTx+be^{w^Tx+b}ewTx+b逼近yyy,但实质上已是在求取输入空间到输出空间的非线性函数映射,如图1所示:
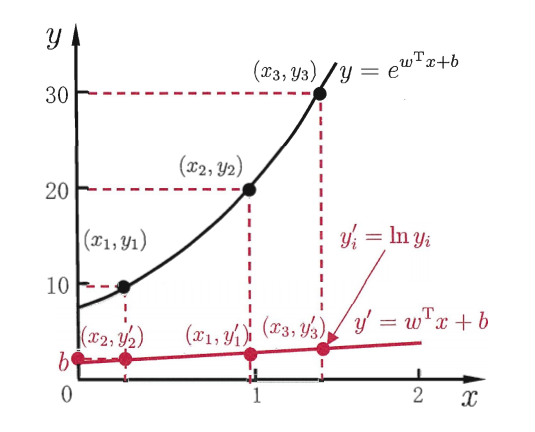
图1:对数线性回归示意图(出处:周志华《机器学习》第三章图3.1) 从图中可以看到,这里的对数函数起到了将线性回归模型的预测值与真实标记联系起来的作用。
3.3 多元线性回归:多个特征的预测
当我们有多个特征时(比如同时用密度和含糖率预测西瓜的好坏评分),就需要用到多元线性回归。这时候模型的向量形式是:
f(xi)=wTxi+bf(x_i) = w^Tx_i + bf(xi)=wTxi+b
为了方便计算,我们把偏置项bbb也放进权重向量里,令x^i=(xi;1)\hat{x}_i = (x_i; 1)x^i=(xi;1)(也就是在特征向量最后加一个1),w^=(w;b)\hat{w} = (w; b)w^=(w;b),这样模型就变成了:
f(xi)=w^Tx^if(x_i) = \hat{w}^T\hat{x}_if(xi)=w^Tx^i
均方误差的矩阵形式为:
Ew^=(y−Xw^)T(y−Xw^)E_{\hat{w}} = (y - X\hat{w})^T(y - X\hat{w})Ew^=(y−Xw^)T(y−Xw^)
其中XXX是m×(d+1)m \times (d+1)m×(d+1)的样本矩阵,每一行是一个样本的x^i\hat{x}_ix^i,yyy是mmm维的标签向量。
对w^\hat{w}w^求偏导并令其为0,得到闭式解:
w^∗=(XTX)−1XTy\hat{w}^* = (X^TX)^{-1}X^Tyw^∗=(XTX)−1XTy
注意:这里要求XTXX^TXXTX是满秩矩阵(这组向量各自独立,没有谁能被其他向量线性表示,相当于 "人人立场不同、互不依附"),否则会有多个解。如果不满秩,我们需要加入正则化项来约束解的范围。
3.4 核心代码实现
下面用Python实现单变量和多元线性回归,基于西瓜数据集3.0:
python
import numpy as np
import matplotlib.pyplot as plt
# 西瓜数据集3.0(密度,含糖率)
data = np.array([
[0.697, 0.460], [0.774, 0.376], [0.634, 0.264], [0.608, 0.318],
[0.556, 0.215], [0.403, 0.237], [0.481, 0.149], [0.437, 0.211],
[0.666, 0.091], [0.243, 0.267], [0.245, 0.057], [0.343, 0.099],
[0.639, 0.161], [0.657, 0.198], [0.360, 0.370], [0.593, 0.042],
[0.719, 0.103]
])
X = data[:, 0:1] # 密度作为特征
y = data[:, 1] # 含糖率作为标签
# 单变量线性回归
def linear_regression_single(X, y):
m = len(X)
x_mean = np.mean(X)
y_mean = np.mean(y)
# 计算w
numerator = np.sum((X - x_mean) * (y - y_mean))
denominator = np.sum((X - x_mean) ** 2)
w = numerator / denominator
# 计算b
b = y_mean - w * x_mean
return w, b
w, b = linear_regression_single(X, y)
print(f"单变量线性回归结果:w={w:.4f}, b={b:.4f}")
# 绘制拟合直线
plt.scatter(X, y, c='red', marker='o', label='样本点')
x_line = np.linspace(0.2, 0.8, 100)
y_line = w * x_line + b
plt.plot(x_line, y_line, c='blue', label='拟合直线')
plt.xlabel('密度')
plt.ylabel('含糖率')
plt.legend()
plt.show()
# 多元线性回归(加入一个虚拟特征演示)
X_multi = np.hstack((X, np.random.randn(len(X), 1))) # 加入一个随机特征
def linear_regression_multi(X, y):
m = len(X)
# 加入偏置项
X_b = np.hstack((X, np.ones((m, 1))))
# 计算闭式解
w_hat = np.linalg.inv(X_b.T @ X_b) @ X_b.T @ y
return w_hat
w_hat = linear_regression_multi(X_multi, y)
print(f"多元线性回归结果:w={w_hat[:-1]}, b={w_hat[-1]:.4f}")4. 对数几率回归:从回归到分类
线性回归预测的是连续值,但现实中很多问题是分类问题(比如判断西瓜是不是好瓜、邮件是不是垃圾邮件)。这时候我们需要把线性回归的输出映射到0到1之间,变成概率,这就是对数几率回归(也叫逻辑回归)。
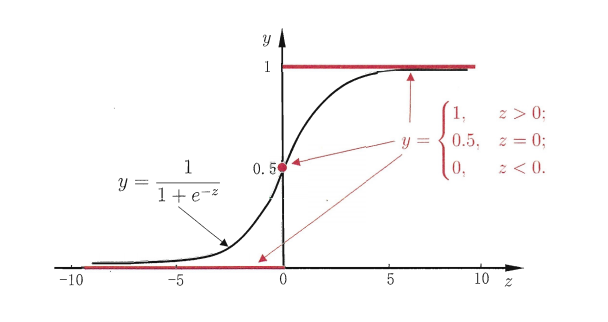
图2:单位阶跃函数与对数几率函数
4.1 Sigmoid函数:概率转换器
我们引入Sigmoid函数 来做映射:
y=11+e−zy = \frac{1}{1 + e^{-z}}y=1+e−z1
其中z=wTx+bz = w^Tx + bz=wTx+b是线性回归的输出。
Sigmoid函数有两个非常好的性质:
- 把任意实数映射到(0,1)(0,1)(0,1)区间,正好符合概率的取值范围
- 单调递增,导数好求:y′=y(1−y)y' = y(1-y)y′=y(1−y)
通俗解释:Sigmoid函数就像一个"概率转换器",把线性回归输出的任意大或小的数,都变成0到1之间的概率值。比如输出0.8表示有80%的概率是正例(好瓜),输出0.2表示有20%的概率是正例。
4.2 对数几率的含义
把Sigmoid函数变形一下,我们得到:
lny1−y=wTx+bln\frac{y}{1-y} = w^Tx + bln1−yy=wTx+b
这里的y1−y\frac{y}{1-y}1−yy叫做几率 ,表示正例发生的概率与负例发生的概率的比值。对几率取对数就是对数几率 (logit)。所以对数几率回归的本质是:用特征的线性组合去拟合对数几率。
通俗解释:对数几率(Logit)的核心作用,就是把一个 0-1 之间的概率问题,转换成了一个可以用线性回归处理的、值域为全体实数的回归问题,让逻辑回归从一个 "玄学的分类模型",变成了可训练、可解释、可优化的经典算法。
4.3 损失函数:交叉熵
对数几率回归用极大似然估计 来求解参数。假设每个样本的标签yiy_iyi服从伯努利分布(伯努利分布是最简单的离散概率分布,只描述只有两种结果的随机试验,也叫0-1 分布),那么似然函数是:
L(w,b)=∏i=1mp(yi∣xi;w,b)L(w,b) = \prod_{i=1}^m p(y_i | x_i; w,b)L(w,b)=i=1∏mp(yi∣xi;w,b)
取对数得到对数似然:
l(w,b)=∑i=1mlnp(yi∣xi;w,b)l(w,b) = \sum_{i=1}^m ln p(y_i | x_i; w,b)l(w,b)=i=1∑mlnp(yi∣xi;w,b)
我们的目标是最大化对数似然,等价于最小化负对数似然,也就是交叉熵损失函数 :
J(w,b)=−1m∑i=1myilny\^i+(1−yi)ln(1−y\^i)J(w,b) = -\frac{1}{m}\sum_{i=1}^m \left y_i ln \\hat{y}_i + (1-y_i) ln (1-\\hat{y}_i) \\rightJ(w,b)=−m1i=1∑myilny\^i+(1−yi)ln(1−y\^i)
其中y^i=11+e−(wTxi+b)\hat{y}_i = \frac{1}{1 + e^{-(w^Tx_i + b)}}y^i=1+e−(wTxi+b)1是模型预测的正例概率。
为什么不用最小二乘法(均方误差)?因为Sigmoid函数在两端的梯度非常小(接近0),如果用均方误差,会导致梯度消失,模型学不到东西。而交叉熵的梯度是y^i−yi\hat{y}_i - y_iy^i−yi,不会出现梯度消失的问题。
5. 线性判别分析(LDA):找一条最好的"分界线"
线性判别分析(Linear Discriminant Analysis,简称LDA)是另一种经典的线性分类方法,它的思想非常直观:把样本投影到一条直线上,使得同类样本尽可能靠近,异类样本尽可能远离。
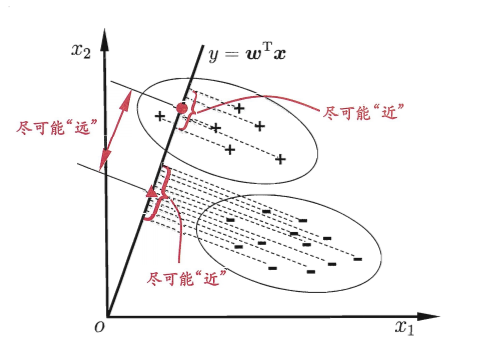
图3:LDA的二维示意图."+""-"分别代表正例和反例,椭圆表示数据簇的外轮廓,虚线表示投影,红色实心圆和实心三角形分别表示两类样本投影后的中心点
5.1 LDA的数学原理
假设我们有两类样本,分别是X0X_0X0(坏瓜)和X1X_1X1(好瓜),它们的均值向量分别是μ0\mu_0μ0和μ1\mu_1μ1。我们要找一个投影方向www,使得:
- 两类样本的投影中心尽可能远:∣∣wTμ0−wTμ1∣∣2||w^T\mu_0 - w^T\mu_1||^2∣∣wTμ0−wTμ1∣∣2尽可能大
- 同类样本的投影尽可能集中:wTS0w+wTS1ww^TS_0w + w^TS_1wwTS0w+wTS1w尽可能小,其中S0S_0S0和S1S_1S1是两类的类内散度矩阵
我们定义类间散度矩阵 Sb=(μ0−μ1)(μ0−μ1)TS_b = (\mu_0 - \mu_1)(\mu_0 - \mu_1)^TSb=(μ0−μ1)(μ0−μ1)T,类内散度矩阵 Sw=S0+S1S_w = S_0 + S_1Sw=S0+S1,那么LDA的目标函数就是:
J=wTSbwwTSwwJ = \frac{w^T S_b w}{w^T S_w w}J=wTSwwwTSbw
最大化这个目标函数,得到最优投影方向:
w=Sw−1(μ0−μ1)w = S_w^{-1}(\mu_0 - \mu_1)w=Sw−1(μ0−μ1)
5.2 LDA vs PCA:有监督 vs 无监督
很多人会把LDA和PCA搞混,它们的核心区别在于:
- LDA是有监督的:利用标签信息,找的是最有利于分类的投影方向
- PCA是无监督的:不利用标签信息,找的是方差最大的投影方向
通俗解释:LDA是"找不同",专门找能把两类分开的方向;PCA是"找共性",找能保留最多信息的方向。
6. 多分类学习:把复杂问题拆成简单问题
前面讲的都是二分类问题,但现实中很多问题是多分类的(比如鸢尾花分为3类、手写数字分为10类)。多分类学习的基本思路是:拆解法,把多分类任务拆成多个二分类任务,然后训练多个二分类器,最后集成它们的结果。
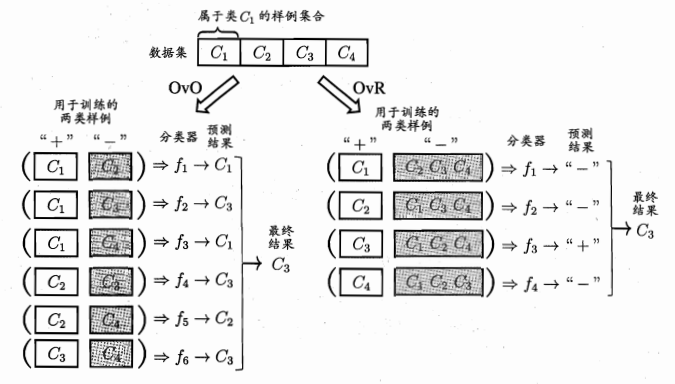
图4:OvO与OvR示意图
6.1 三种拆解方式
常见的拆解方式有三种:OvO、OvR和MvM,它们的对比如表1所示:
表1:多分类拆解方式对比
| 方法 | 全称 | 分类器数量 | 训练速度 | 预测速度 | 优点 | 缺点 |
|---|---|---|---|---|---|---|
| OvO | 一对一(One vs One) | N(N−1)/2N(N-1)/2N(N−1)/2 | 快(每个分类器只训练两个类) | 慢(需要投票) | 训练快,适合类别多的情况 | 分类器数量多,存储开销大 |
| OvR | 一对多(One vs Rest) | NNN | 慢(每个分类器训练所有样本) | 快(取置信度最高的) | 分类器数量少,预测快 | 正负样本不平衡,训练慢 |
| MvM | 多对多(Many vs Many) | kkk(编码长度) | 中等 | 中等 | 有纠错能力,鲁棒性好 | 编码设计复杂 |
6.2 纠错输出码(ECOC)
MvM最常用的实现是纠错输出码(Error Correcting Output Codes,简称ECOC)。它的思想是:给每个类别分配一个唯一的二进制编码,然后每个编码位训练一个二分类器。预测时,把所有分类器的输出组成一个二进制串,和每个类别的编码比较,汉明距离最小的就是预测类别。
ECOC的优点是有纠错能力:如果某个二分类器预测错了,只要错误的位数不超过编码的纠错能力,最终结果还是对的。
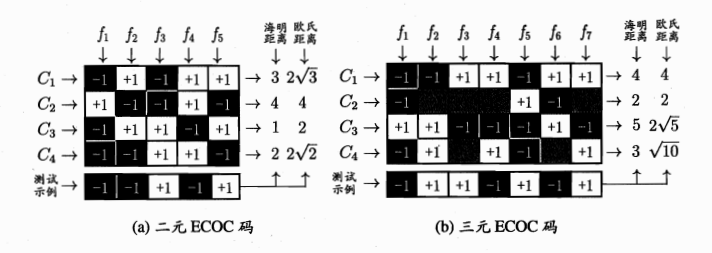
图5:ECOC编码示意图."+1"、"-1"分别表示学习器fi将该类样本作为正、反例;三元码中"0"表示fi不使用该类样本
7. 类别不平衡问题:当"少数派"很重要
在现实任务中,我们经常会遇到类别不平衡的问题:训练集中不同类别的样本数量相差很大。比如:
- 信用卡欺诈检测:99.9%的交易是正常的,只有0.1%是欺诈
- 疾病诊断:99%的人是健康的,只有1%的人患病
这时候如果用准确率作为性能度量,会出现"准确率陷阱":比如一个分类器把所有样本都预测为正常,准确率也有99%,但这显然是一个没用的分类器。
7.1 三种解决方法
- 欠采样:删除多数类的样本,使得正负样本数量接近。比如从990个正常交易中删除980个,剩下10个正常和10个欺诈。优点是训练快,缺点是会丢失多数类的信息。
- 过采样:增加少数类的样本,比如复制少数类样本,或者用SMOTE算法生成新的少数类样本。优点是不丢失信息,缺点是容易过拟合。
- 阈值移动 :不改变样本数量,而是调整预测的阈值。原来的阈值是0.5,现在改成m−m++m−\frac{m^-}{m^+ + m^-}m++m−m−,其中m+m^+m+是正例数,m−m^-m−是负例数。这样可以让更多的样本被预测为正例,提高查全率。
通俗解释:阈值移动就像把"及格线"从60分降到30分,这样更多的少数类样本能被"捞上来",减少漏检。
8. 总结:线性模型的"平凡与伟大"
线性模型看起来简单,但它是机器学习中最基础、最重要的模型之一:
- 可解释性强:每个特征的权重直接反映了它对结果的影响程度,这在医疗、金融等需要解释性的领域至关重要
- 计算效率高:训练和预测都非常快,适合处理大规模数据
- 扩展性好:很多复杂模型都是线性模型的扩展,比如神经网络的每一层都是线性变换加激活函数,支持向量机是线性模型在核空间的扩展
当然,线性模型也有局限性:它只能处理线性关系,对于非线性数据效果不好。但这并不影响它的地位------就像数学中的加减乘除,虽然简单,但却是所有复杂运算的基础。