目录
[1. 协议是什么](#1. 协议是什么)
[2. 什么是应用层协议](#2. 什么是应用层协议)
[1. 什么是序列化](#1. 什么是序列化)
[2. 什么是反序列化](#2. 什么是反序列化)
[3. 为什么需要序列化](#3. 为什么需要序列化)
[1. 为什么 socket 支持全双工](#1. 为什么 socket 支持全双工)
[2. 应用层视角](#2. 应用层视角)
[1. 为什么使用 JSON](#1. 为什么使用 JSON)
[2. JsonCpp 介绍](#2. JsonCpp 介绍)
[3. JsonCpp 安装](#3. JsonCpp 安装)
[1. 动态构造](#1. 动态构造)
[2. 对象与数组操作](#2. 对象与数组操作)
[3. 类型检查](#3. 类型检查)
[4. 类型转换](#4. 类型转换)
[1. toStyledString / FastWriter](#1. toStyledString / FastWriter)
[2. StreamWriter](#2. StreamWriter)
[3. Reader / CharReader](#3. Reader / CharReader)
[4. 完整流程](#4. 完整流程)
一、再谈协议
在实际互联网开发中,单纯实现 EchoServer 这样的基础功能远远不够。无论是开发网络计算器 、在线商城 还是社交平台 ,都需要传输包含业务逻辑的复杂数据。这就要求我们在传输层之上,必须构建完善的应用层协议和序列化机制,为数据解析建立可靠的防护体系
1. 协议是什么
在日常生活中,协议通常表现为一份合同或一份契约(比如租房协议、保密协议)。它的核心目的是:让不同的独立个体,在一套统一的、没有歧义的标准下协同工作
在计算机网络的世界里,协议(Protocol)的本质也是一种约定
计算机是极其古板的,它只认识 0 和 1。如果两台跨越互联网的机器想要准确无误地交流,它们就必须在发送数据前达成共识:
-
发送的这 4 个字节,究竟代表一个整数,还是代表一个浮点数?
-
数据的开头几个字节,是代表这条消息的长度,还是代表用户的身份 ID?
若缺乏这种跨平台的硬性规范,面对相同的二进制数据流,五花八门的操作系统和硬件架构(如大端/小端机器)就会各行其是,最终解析出截然不同的结果
2. 什么是应用层协议
要说清什么是应用层协议,我们先建立一个核心观念:下层传输层(TCP/IP)只负责数据的安全传输,并不涉及上层应用的具体业务逻辑实现
我们来理解一个「跨国寄件模型」:
快递公司(TCP/IP 协议栈)与制鞋工厂(应用层)
假设你是一家鞋厂的厂长。现在有一家外网客户向你订购了一双高跟鞋。由于这双鞋极其昂贵,在寄送时,你把鞋子拆分成了:左鞋跟、右鞋跟、鞋面皮革、防伪证书,分别装在不同的精美小格子里,塞进了一个大木箱
你找到了顺丰/联邦快递(TCP 协议)。快递公司承诺:只要你把箱子交给我,我一定保证它在路上不丢包、不损坏、并且按照你发货的先后顺序,安全送达客户手中
当我们站在快递员(操作系统内核)的角度想一想:
快递员知道这个木箱里装的是一双鞋,还是一台破损的收音机吗?不知道
快递员会帮你把左鞋跟和鞋面皮革组装成一双可以穿的鞋子吗?绝对不会
回到网络编程中: 当你在客户端调用 send(sockfd, "1+1", 3, 0) 时,TCP 协议栈在底层确保 0x31 0x2b 0x31 这三个字可靠的发送到了服务端的内核接收缓冲区里
但是,TCP 根本不知道 1+1 是个数学加法题! 它甚至不知道 + 是个运算符。在内核看来,这不过是 3 个字节。如果服务端的业务层不去主动解读它,这 3 个字节就只是毫无意义的数据
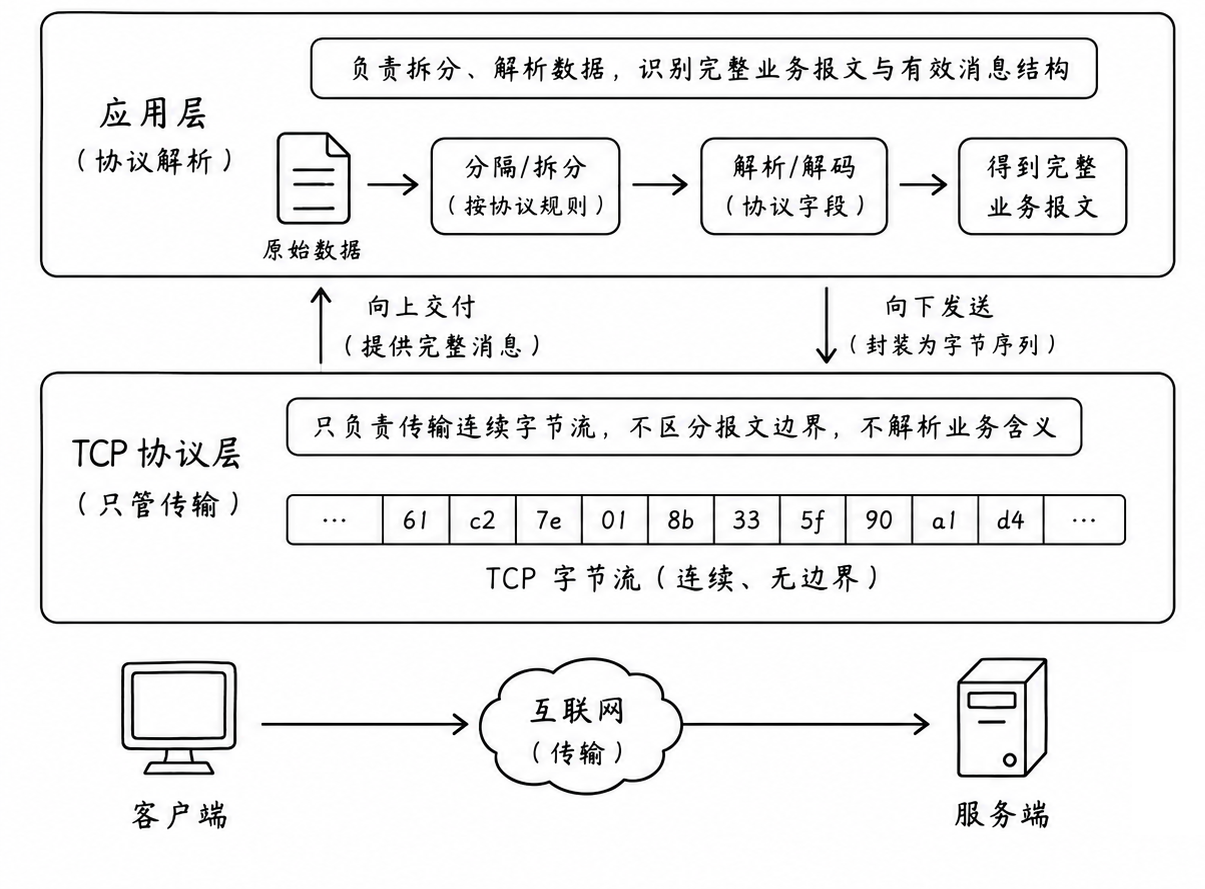
因此,如何解读这 3 个字节,并算出结果,是两端应用层程序之间达成的契约 。这种专门用来服务上层具体业务、如何解析字节流的结构化约定,就叫做 应用层协议
例如,对于一个网络计算器业务,两端的程序员会制定这样一套应用层协议:
-
请求协议规范:前 4 个字节固定放入左操作数,紧接着的 1 个字节放入运算符,最后 4 个字节放入右操作数
-
响应协议规范:前 4 个字节固定放入计算状态码(0 代表成功,1 代表除 0 错误),后 4 个字节固定放入计算结果
这套规范在双端代码中落地后,原本无意义的 TCP 字节流才能够被解读。但要将应用层形态各异的结构化对象(比如 C++ 的 struct)转换为TCP可传输的裸字节流,还需要经过序列化和反序列化这两道关键工序
二、序列化与反序列化
理解了应用层协议的概念后,我们面临一个关键问题:代码中定义的是结构化对象(如类或结构体),而网络传输只能处理字节流。如何在这两种数据形态间进行转换?这正是序列化与反序列化要解决的问题
1. 什么是序列化
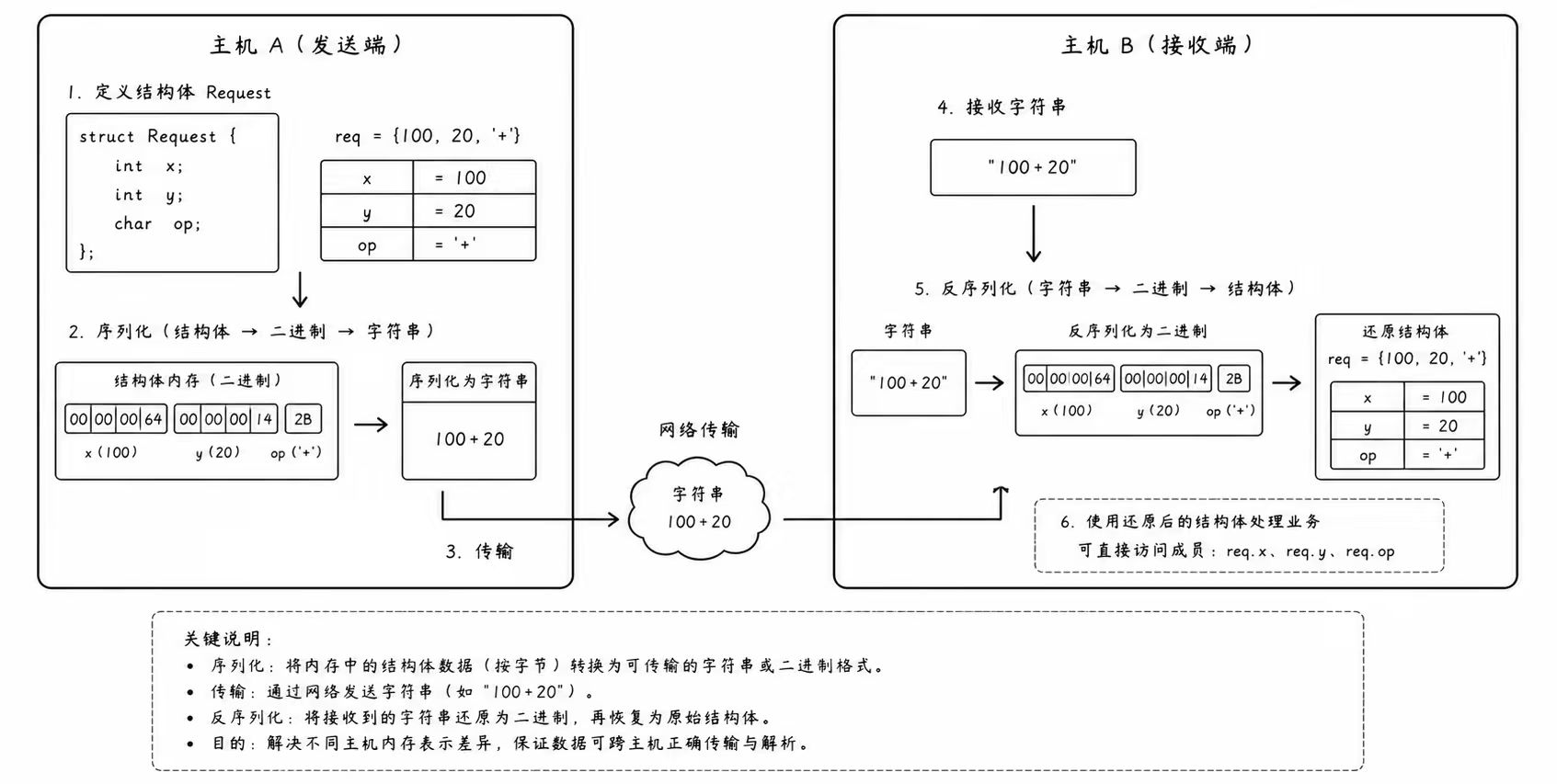
序列化就是将内存中结构化的对象、变量或数据结构, 打包成一串物理上连续的、可存储或可传输的字节流的过程
你可以把它想象成把一件结构复杂的红木家具拆卸成一块块扁平的板材、螺丝,并打包塞进扁平的纸箱里。只有变成这种没有立体空间的扁平形态,火车、货车(网络栈)才能高效地装载它
-
C++ 中的对象形态:
cppstruct Request { int x; int y; char op; }; Request req{100, 20, '+'}; // 具有内存对齐、立体结构的结构体对象 -
序列化后的数据形态:
cpp"100+20" (或者是某种紧凑的二进制编码:0x00000064 0x2B 0x00000014)
2. 什么是反序列化
反序列化 则是序列化的逆向工程:将从网络上接收到的、扁平的字节流数据, 重新组装、还原成内存中具有特定结构的应用层对象
这就好比客户收到了快递寄来的扁平纸箱,他根据随箱附带的组装说明书(应用层协议规范),把板材和螺丝严丝合缝地重新拼装成一把完好如初的红木椅子,让业务层可以直接使用
在代码层面,就是把网络收到的 "100+20" 重新填入到一个新建的 struct Request 变量的各成员槽位中,让后厨的计算函数能够直接读取 req.x 和 req.y
3. 为什么需要序列化
很多时候我们会疑问:既然结构体在内存里本来就是一串连续的本地字节,那我为什么要费尽心思搞什么序列化?直接把结构体的指针丢给 send 函数,强行把这块内存刷给对方不就行了吗?
就像这样:
cpp
// 极其危险且不专业
Request req{100, 20, '+'};
send(sockfd, &req, sizeof(req), 0);这种做法在两台一模一样的机器之间做实验也许能通,但在真正的互联网环境下,它是一颗随时会引爆的定时炸弹。我们之所以必须引入规范的序列化机制,主要是因为直接传输内存块会遭遇以下三大底层壁垒:
① 内存对齐与编译器
不同的操作系统、不同的编译器、甚至相同的编译器在不同的优化级别下,对同一个结构体的内存对齐策略 都可能完全不同。 编译器为了提高 CPU 读取内存的效率,会在结构体成员之间插入一些填充字节。如果发送方和接收方的内存对齐步长不一致,接收方直接强转内存就会发生字段错位,数据瞬间失去意义
② 跨语言
现代互联网架构往往是多语言混编的。你的高并发底层网关可能是用 C++ 写的,但上层的微服务可能是 Java、Go 或者 Python 写的。 如果你直接把 C++ 的内存块 send 过去,Java 根本没有 struct 的概念,Python 的对象存储更是天差地别,它们面对 C++ 的原生内存块根本无法解析
③ 深拷贝指针
如果你的结构体或类中包含指针(例如标准库中的 string 或 vector),直接发送这个结构体会导致严重问题。 因为 string 内部其实只存了一个指向堆区字符串的本地指针(内存地址)。你把这个指针(比如 0x7fffffffe4a0)通过网卡发给另一台机器,另一台机器的内存里这个地址可能什么都没有,或者装着完全无关的数据。一读取,直接触发非法内存访问而崩溃
核心工程共识:
序列化 的本质,就是抹去一切特定硬件、特定语言、特定编译器的痕迹,将数据提炼为通用的、纯粹的逻辑文本或二进制流,以此实现跨平台、跨语言的无缝数据交换
三、全双工
在探讨具体的序列化工具之前,我们有必要先厘清一个贯穿网络编程的关键概念------全双工
在编写 TCP 代码时,当看到同一个 sockfd 既能用于 recv 又能用于 send 时,难免会产生疑问:数据在网络中双向传输时,难道不会发生冲突吗?为什么单个文件描述符能同时支持读写操作?
要理解这个问题,我们需要将视线切入到操作系统的内核之中
1. 为什么 socket 支持全双工
首先必须明确:一个 TCP 套接字在内核中,绝不仅仅对应一个编号,它在底层由两个完全独立、互不干扰的内核缓冲区共同支撑
当你调用 socket 成功创建一个流式套接字时,操作系统会在内核里为你划拨两块独立的内存:发送缓冲区与接收缓冲区
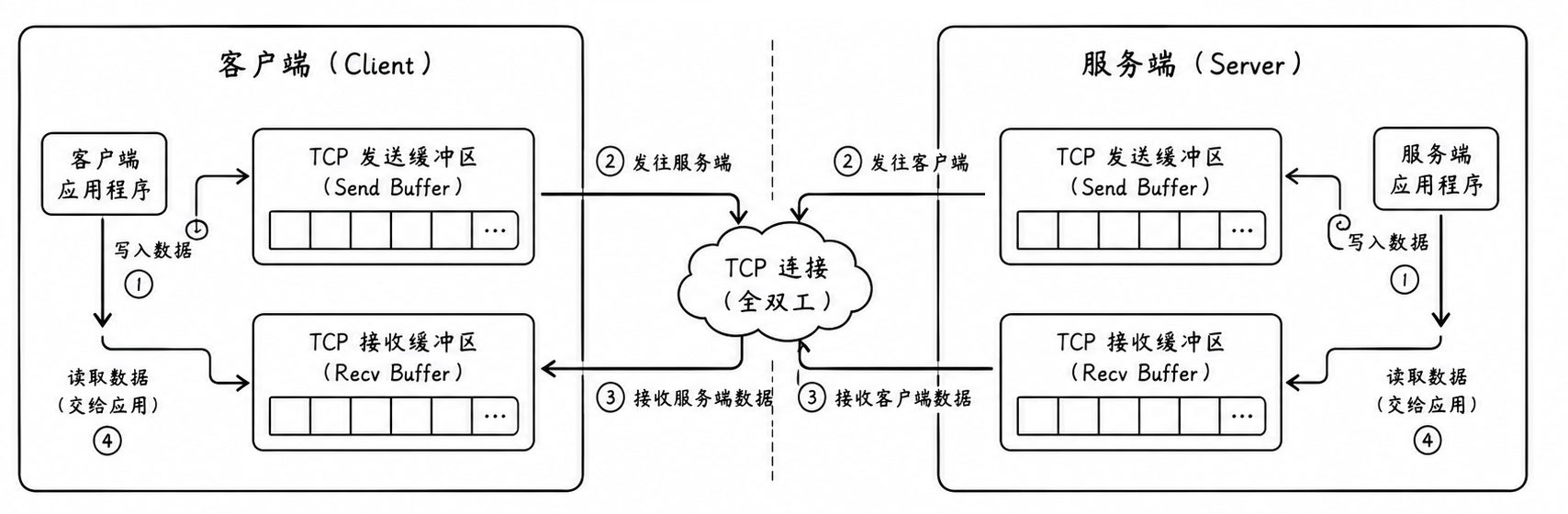
这就从物理上彻底隔绝了读和写的冲突:
-
send / write 的本质 :它并不是把数据直接发送到网络上,而是进行内存拷贝**------** 把应用层用户态缓冲区 里的数据,拷贝到内核的发送缓冲区中。拷贝完成后,系统调用立即成功返回。至于什么时候发、发多少、全由内核中 TCP 自主决定
-
recv / read 的本质 :它的真实动作同样是内存拷贝**------** 当远程主机的网卡把数据发过来时,内核的网络驱动程序会通过中断处理, 将数据塞入本地的接收缓冲区。而 recv 只是负责把内核接收缓冲区里的字节,拷贝到应用层内存中
底层结论:
因为发送缓冲区和接收缓冲区是两块完全不同的内存,所以网卡在驱动层面上,可以一边向外发送数据,一边接收外来数据。两路信号在网卡芯片和双向线缆中完全,这就是全双工的物理基础
2. 应用层视角
得益于内核的双缓冲区设计,应用层程序员在设计架构时,获得了极大的自由度
在单双工(或半双工)的模型下,服务端必须先等 recv 阻塞结束,才能往下调用 send
而在 全双工 的加持下,应用层展现出独特的架构优势:
-
线程读写分离 : 在同一个 TCP 连接上,你可以拉起两个完全独立的线程。线程 A 死循环 recv 并解析对方发来的指令;而 线程 B 则可以在完全不受干扰的情况下调用 send 向对方推送数据。两条执行流操作同一个 sockfd,在底层由于锁的隔离和双缓冲区的独立性,不需要进行任何应用层的同步互斥
-
吞吐量翻倍: 客户端不需要等上一条请求的响应返回,就可以连续调用 send 发送请求。这些请求会堆积在服务端的内核接收缓冲区里等待处理。这种异步并发管道最大程度利用了网卡的物理带宽,能够实现惊人吞吐量
全双工和面向字节流的特性也给上层的协议设计带来了巨大的挑战: 既然客户端可以连续 send,且读写完全异步,那么服务端的接收缓冲区里,可能会堆积着好几条 "半消息" 或者是 "多条消息粘在一起"(俗称粘包与半包问题)
我们在写业务时,就必须引入像 JSON、Protobuf 这样的结构化数据工具,来为字节流划定边界
四、JsonCpp
在全双工的字节流通道中,我们需要一种结构清晰、跨语言支持、且人类可读的数据交换格式来扮演应用层协议的载体。JSON 正是事实上的通用标准,JsonCpp 则是 C++ 中操作 JSON 的核心
1. 为什么使用 JSON
在选择序列化方案时,开发者通常会在二进制流与明文文本之间选择。JSON 之所以能成为互联网大厂、RESTful API、以及多数网络微服务的首选,核心原因在于:
-
可读性与可调试性 : 当网络服务器发生业务报错时,你抓取到了网络报文。如果是二进制流,你看到的将是一堆 0xEF 0xBB 0xBF 这种字符,不借助特殊的解码工具根本无法理解;而 JSON 是纯文本字符串,抓包看到的就是 {"x":100, "y":20, "op":"+"}。一眼就能看清前端发来的数据对不对,排查效率极高
-
跨语言: 几乎所有主流编程语言都原生或者通过第三方库支持 JSON。这使得 C++ 编写的高性能后端,能够与前端网页、手机 App 甚至是 Python AI 微服务进行流畅的跨平台数据对话
2. JsonCpp 介绍
JsonCpp 是一个优秀的 C++ 开源库,专门用于对 JSON 文本进行序列化与反序列化
掌握 JsonCpp 的关键在于理解其三大核心类,其架构层次分明,结构清晰:
| 核心类名 | 核心职责 |
|---|---|
| Json::Value | 核心对象模型。能够转化为任何 JSON 类型(整数、字符串、对象、数组),并以树状结构在内存中存储数据 |
| Json::StreamWriter | 写出器(Writer)。负责将 Json::Value 中的结构化数据转换为一维的 std::string 字节流,为后续的 send 操作做好准备 |
| Json::CharReader | 读取器(Reader)。负责将从网卡接收到的原始 std::string 文本进行解析,将其还原为内存中的 Json::Value 对象 |
在实际工业开发中,JsonCpp 还具备便利的特性:
-
弱类型动态映射: C++ 作为强类型语言,变量类型严格固定(如 int 类型不可变)。而 JSON 则采用弱类型机制。通过重载 operator\[\] 运算符,使 Json::Value 具备动态容器特性。开发者可以像使用 JavaScript 或 Python 那样进行链式键值赋值,底层会自动处理类型转换
-
DOM 解析树: JsonCpp 在反序列化 JSON 字符串时,会在堆内存中构建完整的文档树结构。通过类似 root"user""friends"0"name" 的链式访问语法,开发者可以流畅地定位并提取任意深度的嵌套字段
3. JsonCpp 安装
在 Linux 环境下,我们可以直接利用系统的包管理器一键部署
① Ubuntu / Debian 体系安装:
bash
sudo apt-get update
sudo apt-get install libjsoncpp-dev② CentOS / RHEL / Fedora 体系安装:
bash
sudo yum install jsoncpp-develJsonCpp 属于第三方动态链接库。在完成代码编写后,如果直接编译r,编译器会抛出
undefined reference to 'Json::Value::Value()' 类似的未定义引用错误
正确做法:在编译命令的末尾,显式指定 -ljsoncpp 编译指引标签即可
bash
g++ -std=c++11 main.cc -o server -ljsoncpp五、Json::Value
JsonCpp 作为强类型语言的库,却实现了类似 JavaScript 这种弱类型语言的灵活编码体验。其核心奥秘就在于 Json::Value 这个功能强大的万能容器类
1. 动态构造
Json::Value 本质上是一个突破强类型限制的动态通用容器。它通过重载大量构造函数和赋值运算符,能够无缝兼容 C++ 的各种原生基本数据类型
cpp
#include <jsoncpp/json/json.h>
#include <iostream>
#include <string>
void ConstructDemo() {
Json::Value val_int = 100; // JSON 整数
Json::Value val_string = "hello world"; // JSON 字符串
Json::Value val_bool = true; // JSON 布尔值
Json::Value val_null; // 默认构造,JSON Null
// 打印当前的原生类型
std::cout << "val_int type: " << val_int.type() << std::endl; // 打印类型枚举值
}Json::Value 在内部实现上采用了高效的 union 结构配合类型标签(Type Tag)来实现动态类型切换。单个 Json::Value 对象能够在生命周期内灵活转换数据类型。比如前一刻存储的是整数值,当被赋值为字符串时,它会自动释放原有内存并重新分配存储空间
2. 对象与数组操作
在实际业务场景中,我们经常需要构建复杂的层级嵌套结构化消息。Json::Value 通过重载 operator\[\] 并提供 append 接口,为我们提供了极高的消息组装灵活性
① 组装键值对(JSON Object)
将 Json::Value 视为映射表,可以像使用 std::map 那样直接通过字符串键进行操作。当指定的键不存在时,系统会自动在底层创建对应的键值槽位
cpp
Json::Value root;
root["user_id"] = 10012;
root["nickname"] = "Alice";
root["is_online"] = true;② 组装动态数组(JSON Array)
若需表示一组元素(如在线好友列表),仅需使用 append 方法,Json::Value 便会自动扩展为线性表结构:
cpp
Json::Value phone_list;
phone_list.append("138xxxx8888");
phone_list.append("189xxxx9999");
// 将整个数组作为一个字段,插入 root 对象中
root["phones"] = phone_list;③ 多重嵌套
借助 operator\[\] 返回的 Json::Value 引用特性,我们可以轻松实现链式嵌套调用,仅用一行代码就能构建出复杂的树状数据结构:
cpp
// 一条语句构建:root -> "config" -> "network" -> "timeout" = 5000
root["config"]["network"]["timeout"] = 5000;3. 类型检查
客户端可能由于版本未对齐、或者遭遇了恶意攻击,发来了一些格式错乱的 JSON。 比如,业务层认为 root"user_id" 一定是个数字,于是在代码里直接调用了强转转换方法。如果此时对方发来的是一个字符串 {"user_id": "unknown"},直接强转就会引发无法预知的系统崩溃
因此,在提取具体数据前,必须引入类型校验机制:
cpp
void SafeExtract(const Json::Value& root) {
// 1. 先检查 Key 是否存在
if (root.isMember("user_id")) {
// 2. 校验该字段当前的真实数据类型
if (root["user_id"].isInt()) {
// 3. 强转本地 C++ 类型
int uid = root["user_id"].asInt();
std::cout << "安全读取到用户 ID: " << uid << std::endl;
}
else if (root["user_id"].isString()) {
std::string uid_str = root["user_id"].asString();
std::cout << "读取到字符串型用户 ID: " << uid_str << std::endl;
}
}
}4. 类型转换
| 数据类型 | 类型检查函数 | 类型转换函数 | 返回值 C++ 具体类型 |
|---|---|---|---|
| 字符串 | val.isString() | val.asString() | std::string |
| C 风格字符串 | val.isString() | val.asCString() | const char* |
| 标准有符号整型 | val.isInt() | val.asInt() | int |
| 标准无符号整型 | val.isUInt() | val.asUInt() | unsigned int |
| 64 位有符号长整型 | val.isInt64() | val.asInt64() | Json::Int64 (即 long long) |
| 64 位无符号长整型 | val.isUInt64() | val.asUInt64() | Json::UInt64 (即 unsigned long long) |
| 浮点型 (双精度) | val.isDouble () 或 val.isNumeric () | val.asDouble() | double |
| 浮点型 (单精度) | val.isDouble() | val.asFloat() | float |
| 布尔型 | val.isBool() | val.asBool() | bool |
| 空值 | val.isNull() | 无需转换 | void / 映射为 Json::nullValue |
对于 JSON 的数组和对象,不需要像基本类型那样调用 asInt 转换,因为它们本身就是容器。我们只需要通过以下函数检查它们的容器属性,然后用 operator\[\] 或迭代器去遍历:
-
val.isArray():校验当前节点是否是一个 JSON 数组(如 1, 2, 3)
-
val.isObject():校验当前节点是否是一个 JSON 对象(如 {"x": 1, "y": 2})
-
val.isNumeric():只要当前节点是任意一种数字(int, uint, int64, double 等),均返回 true
六、序列化与反序列化接口
在完成 Json::Value 内存树的构建后,我们需要将其序列化为 string。值得注意的是,JsonCpp 在此过程中经历了重要的 API 迭代,开发者需要充分了解这些版本变更的演进关系
1. toStyledString / FastWriter
在很多老旧的代码库或者网上的速成教程中,你经常会看到这两种写法:
cpp
// 已经过时的序列化方案
Json::Value root;
root["op"] = "+";
root["x"] = 10;
// 写法A:生成带有缩进、换行的格式化文本(适合调试控制台打印)
std::string styled_str = root.toStyledString();
// 写法B:生成没有任何空格、紧凑、适合网络传输的紧凑文本(老版本方案)
Json::FastWriter writer;
std::string fast_str = writer.write(root);为什么现代工业开发要全面禁止它们?
打开最新的 json/json.h 头文件,你会看到 FastWriter 类的头顶上写着 DEPRECATED(已弃用)的编译器警告标签。老一代接口采用直接实例化的方式,其内部策略(如如何处理内存对齐、如何格式化浮点数的精度等)被硬编码在了底层类里,无法做任何差异化定制。更关键的是,它们是非线程安全的,无法适应现代多线程并发引擎的灵活调度
2. StreamWriter
新版 JsonCpp 引入了经典的建造者设计模式(Builder Pattern)。它将 "配置参数" 与 "真正的序列化动作" 进行了隔离:
cpp
#include <sstream>
std::string SerializeNewStyle(const Json::Value& root, bool is_compact = true) {
// 1. 实例化一个专门负责配置参数的工厂
Json::StreamWriterBuilder builder;
if (is_compact) {
// 定制网络级高紧凑流:擦除多余的换行与空格(压榨带宽)
builder["commentStyle"] = "None";
builder["indentation"] = ""; // 将缩进设置为空,即为紧凑模式
} else {
// 定制漂亮的本地调试打印流
builder["indentation"] = " ";
}
// 2. 通过工厂指针产出一个线程安全的写入器(StreamWriter)
std::unique_ptr<Json::StreamWriter> writer(builder.newStreamWriter());
// 3. 借助标准库的 std::ostringstream 进行高效内存级泵出
std::ostringstream os;
writer->write(root, &os); // 将内存树输出进 os 流中
return os.str(); // 最终导出字节流
}3. Reader / CharReader
同样,在将网络接收到的原始 std::string 数据重构为结构化的 Json::Value 树时,我们也需要完成从旧思维到新思维的转变
① 已被彻底淘汰的接口
cpp
// 已经被抛弃的过时反序列化写法
std::string json_data = "{\"x\":10,\"y\":20}";
Json::Value root;
Json::Reader reader;
if (reader.parse(json_data, root)) {
// 解析成功...
}Json::Reader 同样伴随着严重的资源无法精细化定制、解析超大字符串时局部高负载、以及错误定位信息模糊等致命缺陷,目前也已被标记为 DEPRECATED
② 现代工业级范式
现代高并发框架要求:在解析失败时,不仅要安全退出,还要能够精准地给出 "第几行第几个字符解析出错" 的诊断日志。新版 API 为此提供了无与伦比的安全防护
cpp
bool DeserializeNewStyle(const std::string& raw_json, Json::Value& root_out) {
// 1. 实例化反序列化配置建造者
Json::CharReaderBuilder builder;
// 2. 生产出专属的 CharReader 实体(线程安全)
std::unique_ptr<Json::CharReader> reader(builder.newCharReader());
// 3. 准备接收解析失败时的字符串
std::string errs;
// 4. 高效反序列化动作
// 参数说明:(字符串起始指针, 字符串尾部指针, 导出树的地址, 接收错误信息的字符串指针)
bool success = reader->parse(raw_json.c_str(),
raw_json.c_str() + raw_json.size(),
&root_out,
&errs);
if (!success) {
// 日志打印
std::cerr << "应用层解包失败: " << errs << std::endl;
return false;
}
return true;
}4. 完整流程
为了将上述知识融会贯通,我们编写一段完整代码,展示如何将一个结构化的网络加法请求对象进行序列化,模拟网络全双工传输,最终在服务端反序列化的全过程。这正是我们下一篇博客要实现的网络版计算器的核心基础
cpp
#include <iostream>
#include <string>
#include <jsoncpp/json/json.h>
#include <memory>
#include <sstream>
int main() {
std::cout << "========= 【 客户端发送端:序列化封装 】 =========" << std::endl;
// 假设这是我们应用层的结构化业务对象
int left_num = 500;
int right_num = 35;
char operation = '+';
// 1. 业务对象向 Json::Value 转化
Json::Value client_root;
client_root["x"] = left_num;
client_root["y"] = right_num;
client_root["op"] = std::string(1, operation); // char 转单字符 string
// 2. 利用 StreamWriterBuilder 序列化为网络紧凑流
Json::StreamWriterBuilder w_builder;
w_builder["indentation"] = ""; // 紧凑无空格
std::unique_ptr<Json::StreamWriter> writer(w_builder.newStreamWriter());
std::ostringstream os;
writer->write(client_root, &os);
std::string wire_package = os.str(); // 这就是即将给 send 函数的网络包裹
std::cout << "即将通过 TCP 发送字节流: " << wire_package << std::endl;
std::cout << "\n========= 【 服务端接收端:反序列化解包 】 =========" << std::endl;
// 此时,服务端的另一个线程通过 recv 获取到了 wire_package 字符串
Json::Value server_root;
Json::CharReaderBuilder r_builder;
std::unique_ptr<Json::CharReader> reader(r_builder.newCharReader());
std::string parse_errors;
// 执行解包
bool is_ok = reader->parse(wire_package.c_str(),
wire_package.c_str() + wire_package.size(),
&server_root,
&parse_errors);
if (is_ok) {
// 防御性检查
if (server_root["x"].isInt() && server_root["y"].isInt()
&& server_root["op"].isString())
{
int x = server_root["x"].asInt();
int y = server_root["y"].asInt();
std::string op = server_root["op"].asString();
std::cout << "解析成功: " << std::endl;
std::cout << "x: " << x << ", y: " << y << ", 运算符: " << op << std::endl;
std::cout << "计算回显结果: " << (x + y) << std::endl;
}
} else {
std::cerr << "解包错误: " << parse_errors << std::endl;
}
return 0;
}总结
综上所述,从应用层协议、序列化与反序列化,到 JsonCpp 的使用,我们已经开始真正进入现代网络程序业务通信的核心阶段
其中,TCP/IP 协议栈只负责把字节流可靠地发送到对端。但至于这些字节流:
- 如何组织
- 如何解析
- 如何区分业务字段
- 如何恢复成结构化数据
则完全属于应用层协议所需要解决的问题。与此同时,通过 JsonCpp,我们也进一步理解了序列化本质上就是:
结构化数据 → 字节流
而反序列化则是:
字节流 → 结构化数据
而进一步思考会发现,目前我们虽然已经能够:
- 组织 JSON 数据
- 进行序列化
- 通过网络发送
- 再反序列化恢复对象
但这些流程还停留在理论阶段
如何真正基于自定义协议,实现一个完整的网络业务系统,正是下一阶段要解决的问题
在下一篇中,我们将基于 TCP、自定义协议与 JsonCpp,实现一个真正具备 "请求---响应" 模型的网络计算器,进一步理解应用层协议在真实网络程序中的工作方式
