目录
[补充:errno,perror,strerror 三者有啥区别](#补充:errno,perror,strerror 三者有啥区别)
注:本文章内容均来自本人的学习笔记为个人学习总结,禁止转载。
参考自B站课程:韦东山《嵌入式linux应用开发》。由于当时方便记笔记,笔记中少部分图片(仅涉及部分代码以及相关运行结果展示,不涉及重要笔记、资料等)来源于原课程视频截图,版权归原作者"韦东山"及相关权利人所有。本笔记无任何商业用途(除开csdn官方操作),仅供个人学习交流。感谢原up主的课程分享!
一、文件io
文件io很重要,在linux中一切皆文件。
在 Linux 上操作文件时,有两套函数:标准 IO、系统调用 IO。标准 IO 的相关函数是:fopen/fread/fwrite/fseek/fflush/fclose 等。系统调用 IO 的相关函数是:open/read/write/lseek/fsync/close。
基本划分:
|----------------------|----------------------------------------|-----------------|
| 层次 | 函数举例 | 所属 |
| 标准 IO(C 库函数) | fopen、fread、fwrite、fseek、fflush、fclose | C 标准库(libc) |
| 系统调用 IO | open、read、write、lseek、fsync、close | Linux 内核提供的原始接口 |
调用链条举例:
fread → 调用 → read → 触发 svc/syscall 异常 → 进入内核 → sys_read → VFS → 驱动/文件系统
标准 IO 函数内部最终会调用系统调用 IO 函数,并不是直接和内核打交道。
系统调用 IO 函数通过 svc(ARM)或 syscall(x86)指令触发异常,陷入内核。
核心区别:用户空间 buffer
"用户空间分配的 buffer",这是两套函数最本质的差别。
fread 和 read 背后发生了什么:
标准 IO(fread):
应用 buffer ←?← C 库内部缓冲区 ←←← 内核
系统调用 IO(read):
应用 buffer ←←←←←←←←←←←←←←←← 内核
标准 IO 多了一层 C 库的缓冲区:
读文件时:fread 哪怕你只读 10 字节,C 库可能用 read 一次从内核读 4096 字节(一页),暂存在内部 buffer,后续小数据读取直接从这里拿,减少系统调用次数。
写文件时:fwrite 先把数据放进 C 库的内部 buffer,等 buffer 满了或调用 fflush / 关闭文件时,才调用 write 一次性发给内核,批量处理,提高效率。
系统调用 IO(read/write)没有这层缓冲:
每次调用都直接陷入内核,每次都有上下文切换开销。
适合需要立即写入、实时性高的场景,或者自己已经做了缓冲管理。
总结对比:
|----------------|-------------------------|-----------------------|
| 对比维度 | 标准 IO(fopen/fread...) | 系统调用 IO(open/read...) |
| 层次 | C 库函数 | 内核提供的原始接口 |
| 缓冲区 | 有 C 库内部 buffer | 没有,直接和内核交互 |
| 性能 | 大量小数据读写时更快(减少系统调用) | 大数据块读写时更直接 |
| 可移植性 | 跨平台,所有支持 C 标准的系统都有 | Linux/Unix 专有 |
| 适用场景 | 普通文件读写、日志、配置文件 | 驱动开发、网络编程、需要精确控制 |
| 额外功能 | 格式化输入输出(fprintf/fscanf) | 只有纯字节流读写 |
| 打开文件类型 | 只能打开普通文件 | 可以打开设备文件、管道、socket 等 |
补充------Posix
POSIX(Portable Operating System Interface,可移植操作系统接口)是由 IEEE 制定的一系列操作系统接口标准(IEEE 1003 / ISO/IEC 9945),旨在统一 UNIX 及类 UNIX 系统的 API,使应用程序能够在不同平台上无缝移植。它涵盖 进程管理、文件系统、线程与同步、信号处理、时间管理、网络通信 等多个领域。
说白了,POSIX 定义了一套"操作系统必须提供的 API 和命令",只要操作系统和程序都遵守这套标准,程序就能在不同系统上编译运行。
操作系统就是墙上的"插座"。有美标、欧标、国标,各不相同。
程序就是你的"电器插头"。如果每个电器都要为不同的插座定制插头,世界就乱套了。
POSIX 就是那个"国际标准插座接口协议":它规定了------不管你是哪国的插座,只要提供这种标准孔距和电压,所有符合标准的插头都能插进去用。
Linux 实现了一套 POSIX 接口 → 符合 POSIX 标准的程序可以在 Linux 上跑
macOS 也实现了一套 POSIX 接口 → 同一个程序换个编译器就能在 macOS 上跑
QNX(嵌入式实时系统)也实现了 → 程序也能移植过去
不用 POSIX 的典型反面教材:Windows。Windows 有自己的一套 Win32 API(CreateFile、ReadFile、WriteFile),和 POSIX 不兼容,所以 Linux 程序不能直接在 Windows 上编译运行(依赖 WSL 或 Cygwin 这类兼容层才行)。
核心组成 POSIX 标准主要分为四大部分:
Base Definitions:基本数据类型、常量、错误码等定义
System Interfaces:系统调用与库函数(如 open、read、pthread_create)
Shell and Utilities:命令行工具及脚本行为规范
Rationale:设计原理与兼容性说明
二、open函数
1.open函数打开文件
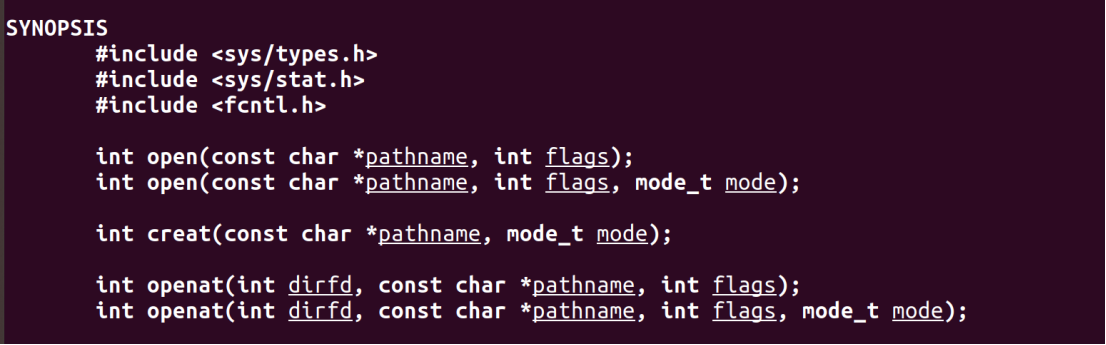
1.函数原型
打开文件,获取操作 "凭证"
2.核心作用
打开指定文件 / 设备文件,返回一个文件描述符(fd,非负整数) ------
后续读写操作都靠这个 fd 来指定 "操作哪个文件",失败返回-1。
3.基本用法
int open(const char *pathname, int flags);
参数 1(pathname):文件路径,比如/sys/class/gpio/export;
参数 2(flags):打开模式,核心是O_RDONLY(只读)、O_WRONLY(只写)、O_RDWR(读写);
返回值:成功 = 文件描述符(如 1、2、3),失败 =-1。
- flags 参数(文件打开方式)
我把常用的选项分成"基本操作"和"特殊行为"两类。
|--------------------------|------------|----------------------------------------------------------------------------------|
| 类别 | 标志宏 | 我的理解/一句话作用 |
| 基本访问模式 (必选其一) | O_RDONLY | 只读 打开。 |
| | O_WRONLY | 只写 打开。 |
| | O_RDWR | 可读可写 打开。 |
| 特殊行为开关 (可选,组合使用) | O_APPEND | 每次写都像排队 。不管文件指针在哪,写之前自动跳到末尾,保证内容都是最新的,不会被覆盖。 |
| | O_CREAT | 文件不在就创建一个 。如果文件已存在,则啥也不干,直接打开。 |
| | O_EXCL | 必须和 O_CREAT一起用 。作用是检查文件是否已存在:如果存在,就直接报错返回,不能打开。常用来确保我们创建的一定是新文件。 |
| | O_TRUNC | 清空后再用 。如果文件存在且有内容,打开的一瞬间就把它清空成长度为0的空文件。必须有写权限。 |
| | O_NONBLOCK | 读写不等待 。以非阻塞方式操作文件(比如设备文件、管道),数据没就绪也不卡住,而是立刻返回一个错误,让程序能继续做别的事。 |
- mode 参数(权限,仅创建文件时用)
这个参数只在用了 O_CREAT 标志创建新文件时才有效,用来给新文件设定访问权限。用的是 Linux 标准的八进制权限数字,比如 0644。
|---------|----------------------------------------------------------|
| mode 示例 | 含义(我的理解) |
| 0600 | 只有我自己 能读、能写,别人完全不搭理。 |
| 0644 | 我自己 能读能写,同组和其他人 只能读。这通常是普通文件最常用的配置。 |
| 0755 | 我自己 能读、能写、能执行,同组和其他人 只能读和执行。常用于可执行程序或脚本。 |
先看一段简单的代码,展示open函数的基本用法:
cpp
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
#include <errno.h>
#include <stdio.h>
#include <unistd.h>//需注意close头文件是这个!
/*
kaizy
open a file: ./open 1.txt
argv[0]:./open
argv[1]:1.txt
argc:2
*/
int main(int argc, char** argv)
{
int fd;
if (argc != 2)
{
printf("Usage:%s <file>\n", argv[0]);
return -1;
}
fd = open(argv[1], O_RDWR);
if (fd < 0)
{
printf("can not open %s\n", argv[1]);
printf("errno=%d\n", errno);
char* msg = strerror(errno);
printf("erro reason:%s\n", msg);
perror("file");
return -1;//出错必须返回
}
printf("open success, fd = %d\n", fd);
close(fd);//文件打开成功后,程序结束前要关闭,否则文件描述符泄漏。虽进程退出时系统会回收,但养成习惯非常重要,以后写长时间运行的程序这是致命 bug。
return 0;
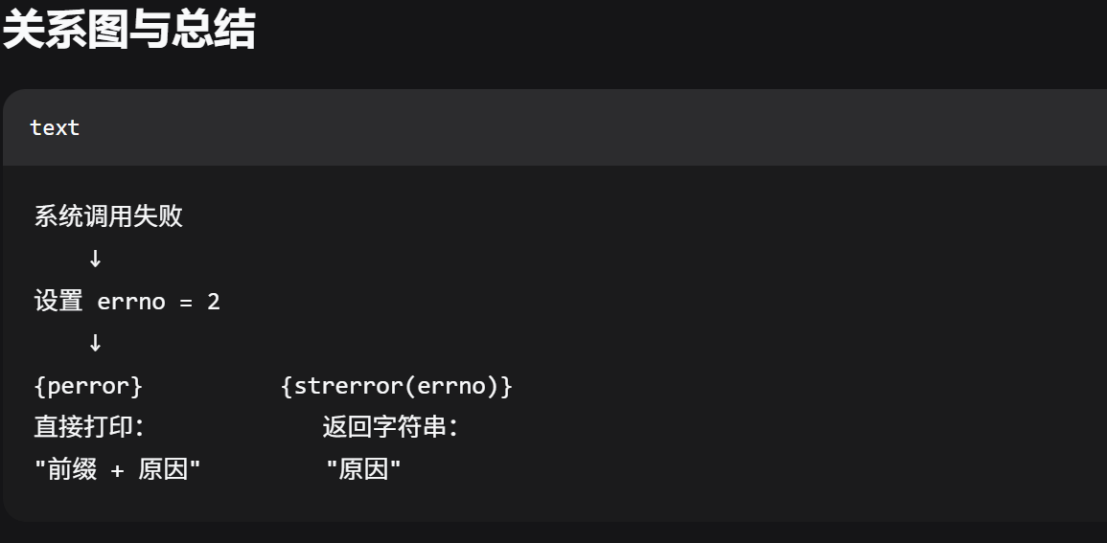
}补充:errno,perror,strerror 三者有啥区别
- errno(错误编号)
它是什么:一个全局变量(实际是宏,但在线程中是线程局部存储),定义在 <errno.h> 里。
它存什么:上次系统调用或某些库函数失败时,记录的错误编号(整数)。
关键规则:
只有函数返回错误时,errno 才有效。调用成功的函数不会清除它,可能保留着上一次失败的值。
每次出错都会被覆盖,所以应该在函数报错后立刻检查它。
cpp
#include <errno.h>
int fd = open("/tmp/no_exist.txt", O_RDONLY);
if (fd == -1) {
printf("errno 的值是:%d\n", errno); // 输出:2
}常见错误码:EACCES (13) 无权限,ENOENT (2) 文件不存在。
- strerror(翻译成可读字符串)
它是什么:一个 C 库函数,包含在 <string.h> 里。
它干什么:传入 errno,返回一个指向静态字符串的指针,告诉你这个错误是什么意思。
特点:只负责翻译,不负责打印。
cpp
#include <string.h>
#include <errno.h>
int fd = open("/tmp/no_exist.txt", O_RDONLY);
if (fd == -1) {
// 把 errno 翻译成字符串,存到 msg 里
char *msg = strerror(errno);
printf("错误原因:%s\n", msg); // 输出:No such file or directory
}不用这个msg直接打印也行。
- perror(自动打印错误信息)
它是什么:一个 C 库函数,包含在 <stdio.h> 里。
它干什么:
打印你给它的字符串(通常是出错函数的名称)。
紧接着打印 errno 对应的错误原因(和 strerror 一样)。
不需要你手动传 errno,它自己会读取全局的 errno。
所有信息直接输出到标准错误。
cpp
#include <stdio.h>
int fd = open("/tmp/no_exist.txt", O_RDONLY);
if (fd == -1) {
// 自动打印你给的字符串,再跟上当前 errno 的原因
perror("打开文件失败");
// 输出:打开文件失败: No such file or directory
}

言归正传、接下来编译运行:
两种编译方式(arm,pc):

后台运行,查看文件描述符(图片来自韦东山课程):
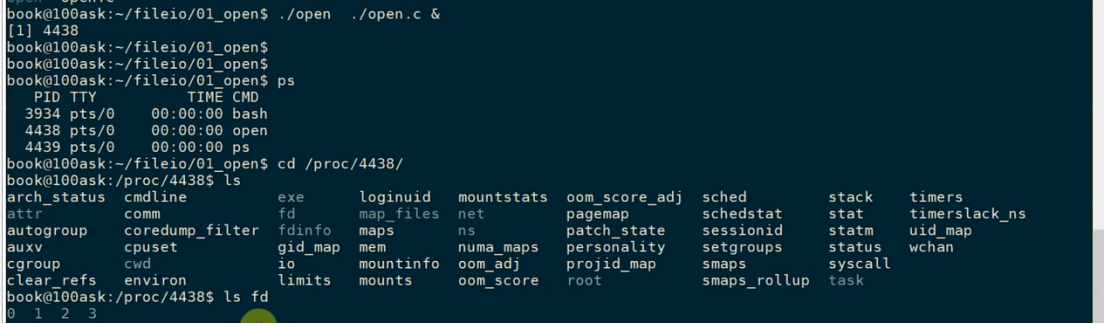
3 就是新打开的文件。0,1,2就是标准输入、输出、错误。
杀死之前的进程:
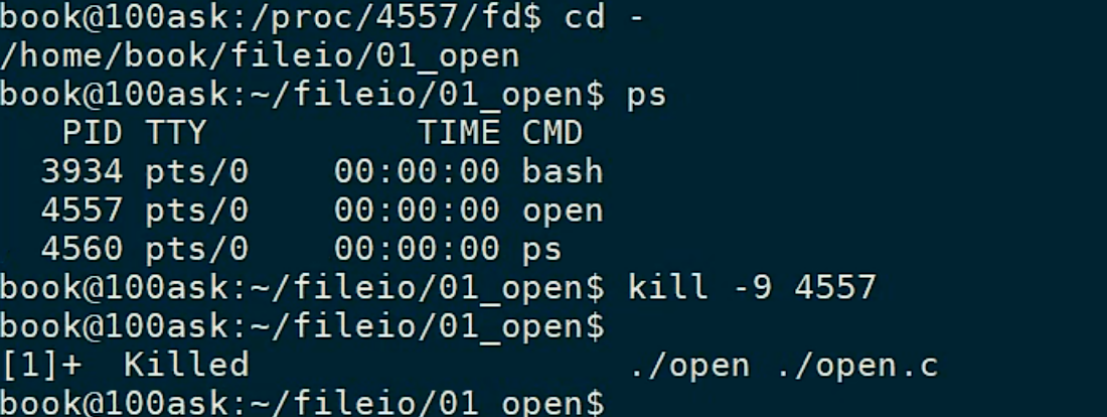
重新创建一个新文件,写入数据,并修改权限,查看能否成功打开这个新文件:
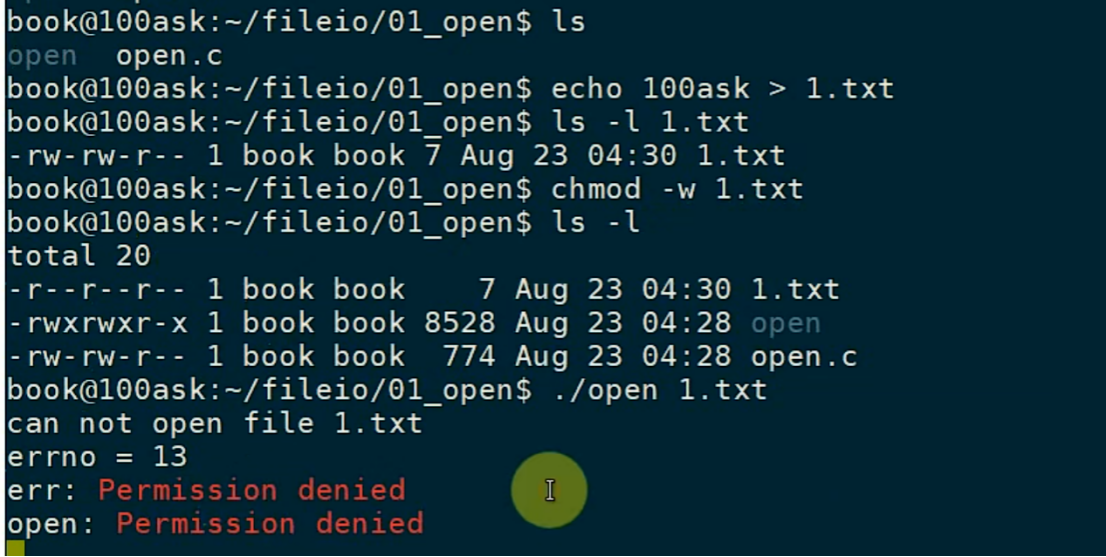
权限改为了只读模式,用读写模式打开,权限不够!
2.使用open函数创建文件
修改之前的代码,新增两个参数:
cpp
int main(int argc, char** argv)
{
int fd;
if (argc != 2)
{
printf("Usage:%s <file>\n", argv[0]);
return -1;
}
fd = open(argv[1], O_RDWR|O_CREAT|O_TRUNC);
if (fd < 0)
{
printf("can not open %s\n", argv[1]);
printf("errno=%d\n", errno);
char* msg = strerror(errno);
printf("erro reason:%s\n", msg);
perror("file");
return -1;//出错必须返回
}
printf("open success, fd = %d\n", fd);
close(fd);//文件打开成功后,程序结束前要关闭,否则文件描述符泄漏。虽进程退出时系统会回收,但养成习惯非常重要,以后写长时间运行的程序这是致命 bug。
return 0;
}一开始并没有1.txt文件
编译运行:
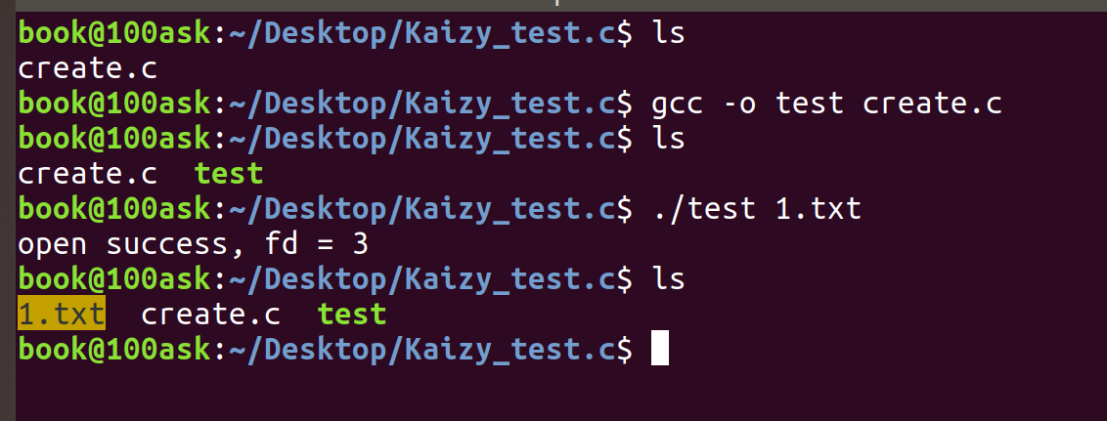

权限很奇怪。
注意观察,我创建了1.txt文件之后再运行,内容会变没,但是权限变为默认的了:
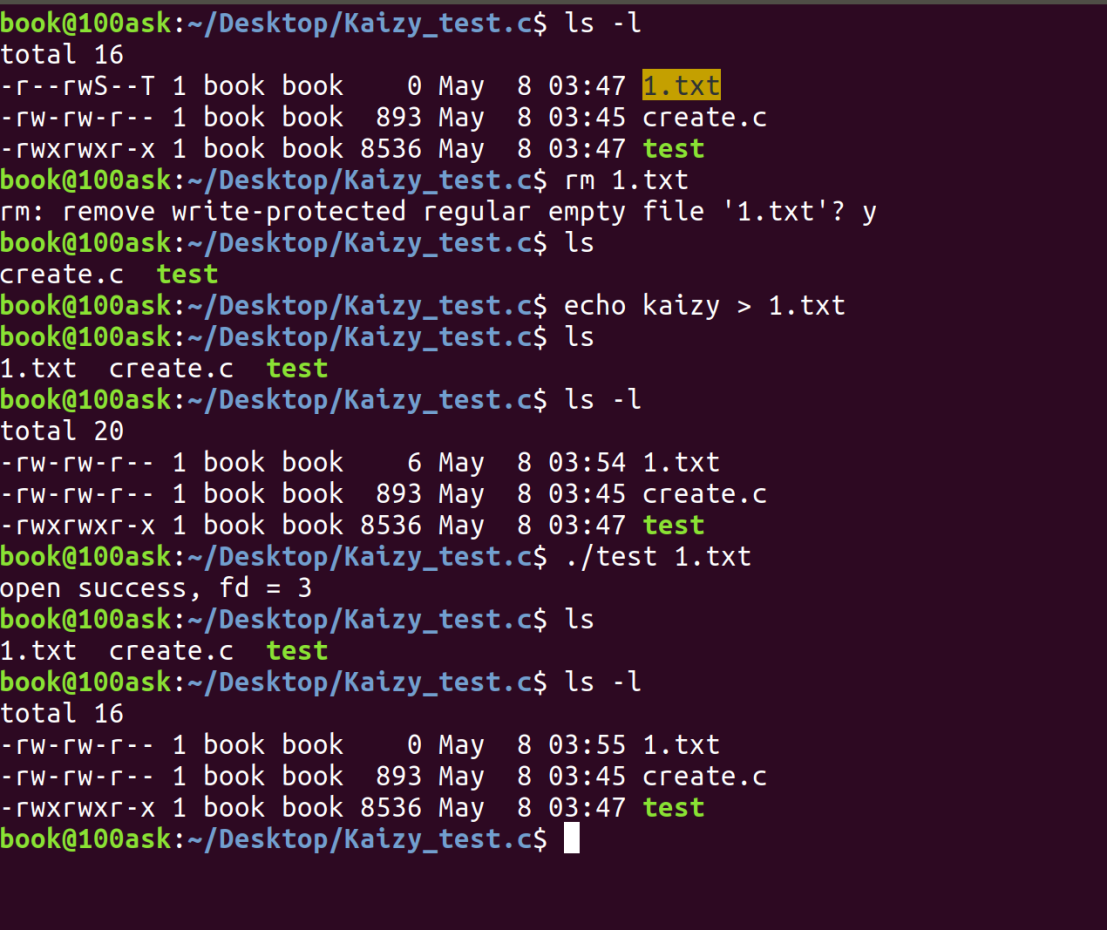
就是 O_TRUNC 标志在默默工作。你用 echo 创建并写入内容,然后你的程序用 O_TRUNC 打开它,瞬间把长度清为 0,但保留了 echo 创建时赋予的权限。
可以在代码里改变它的权限,就用到了mode(图片来自韦东山):
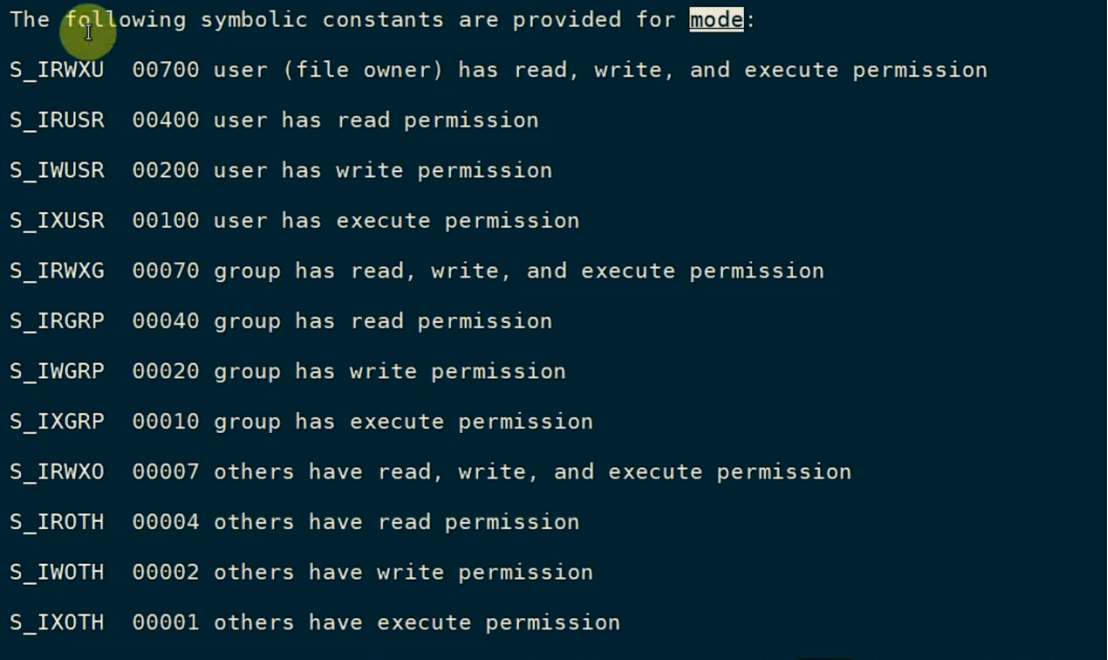
在linux中,权限的分布如下:
Owner Group Other
rwx rwx rwx
010 110 001
Owner(文件所有者):rwx → 二进制 010 → 十进制 2(但这里标的是二进制位)
Group(所属组):rwx → 二进制 110 → 十进制 6
Other(其他人):rwx → 二进制 001 → 十进制 1
假设有一个权限是0561
这四个数字组成 0561,其中:
数字 对应位置 二进制 权限
0 特殊权限(setuid/setgid/sticky) 000 无特殊权限
5 Owner 101 r-x(读+执行)
6 Group 110 rw-(读+写)
1 Other 001 --x(仅执行)
所以 0561 的含义是:
特殊权限:无
Owner:读 + 执行(但不能写)
Group:读 + 写(但不能执行)
Other:只能执行(不能读也不能写)
现在尝试创建一个0666的文件:

编译运行:
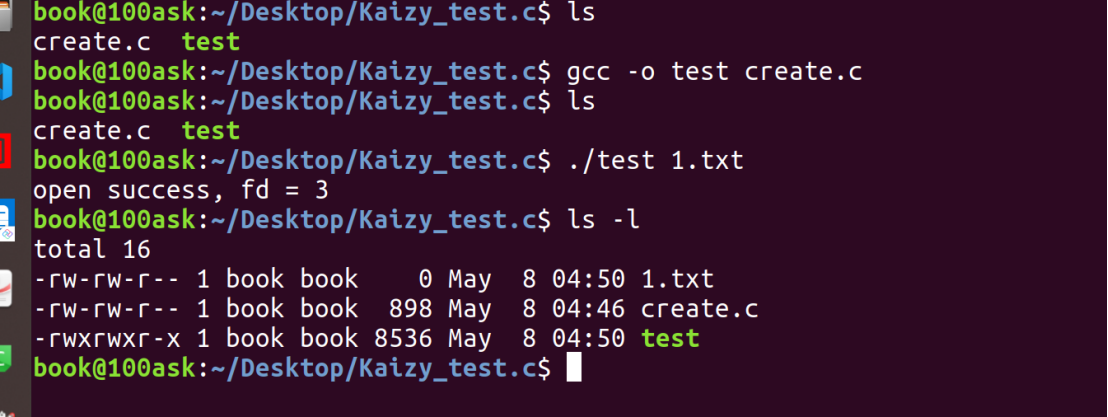
发现其他用户的权限是r而不是rw似乎改不了。
手动加载也不行:
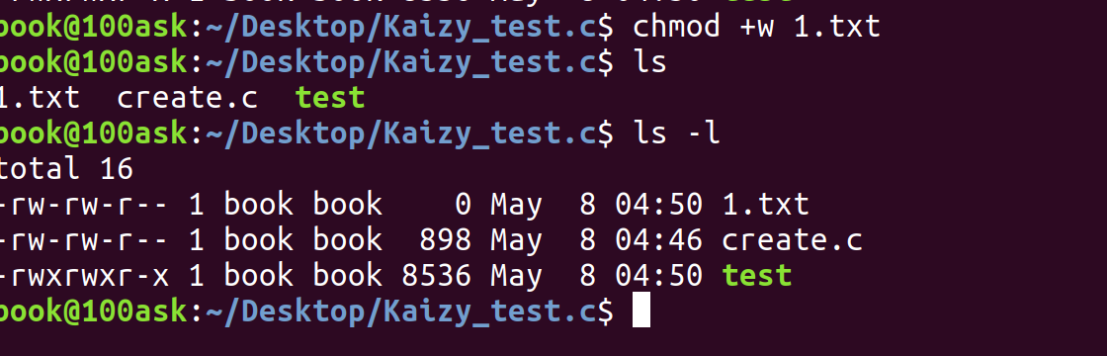
chmod +w 默认给所有三个组(Owner、Group、Other)都加写权限。
这是系统的保护机制在起作用。
再次修改一下,只要文件的拥有者owner有写权限,其他的都只有读权限:
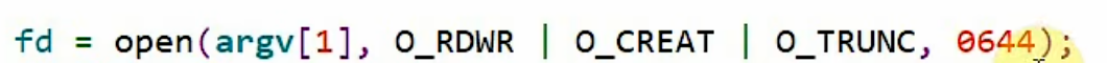
编译运行(图片来自韦东山课程):
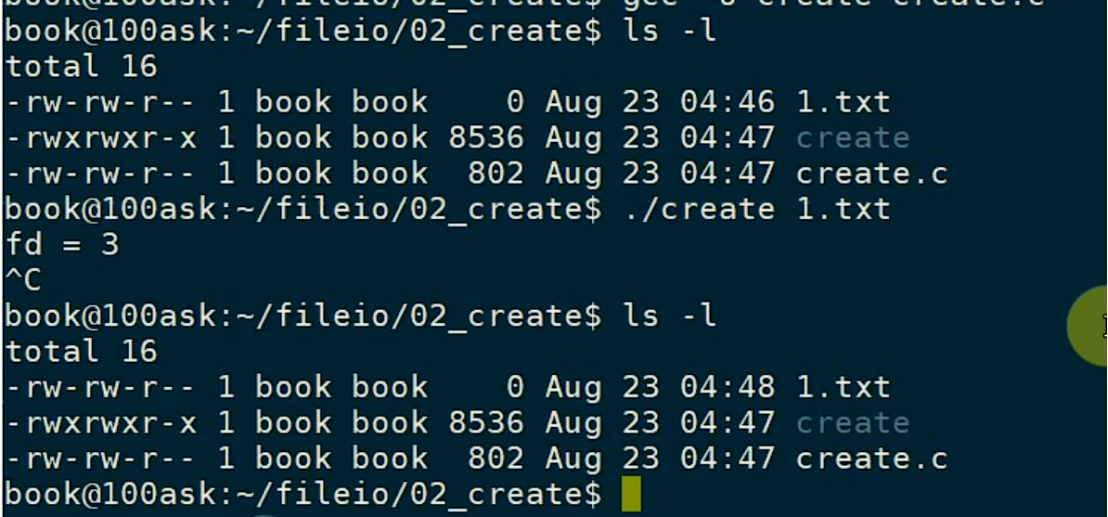
如图,若1.txt本来就存在,则修改不了group的写权限。
删除1.txt,再重新运行生成一个新的txt,就可以看到权限发生变化了:
说明我们只能在创建文件时候是可以指定权限的,但是仍然有一些权限是无法指定的,尝试都设置为777,看看:
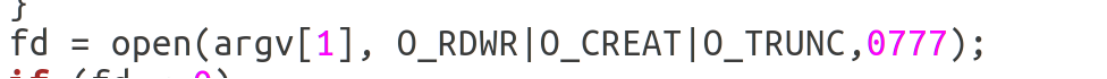
删除之前的txt文件,重新编译运行:
下面来解释原因,为什么other的写权限总是改不了:
这和umask有关:
Man 2 open:搜索umask:

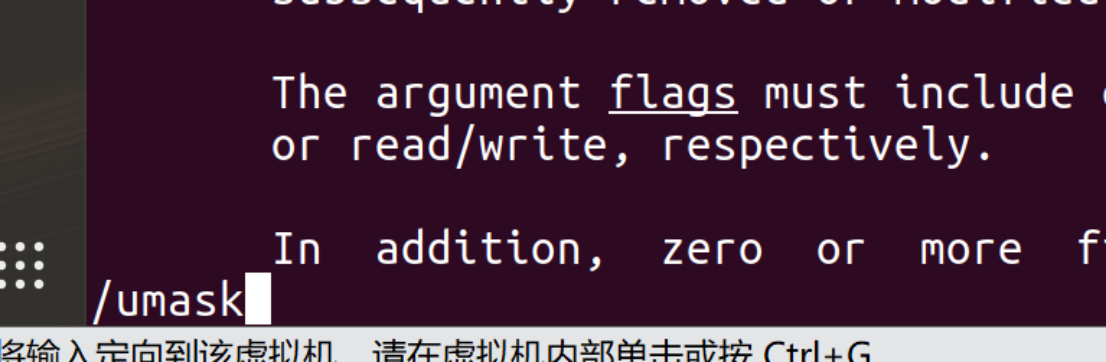
这一句很重要,直接阐明了最终mode的形式:

Umask:0020(8)-->000 000 010(2)
~umask:111 111 101
Mode:777-->111 111 111
Mode & ~umask: 111 111 101-->775-->rwx rwx r_x-->最终的mode!!!
现在是book用户,现在我切换为root:
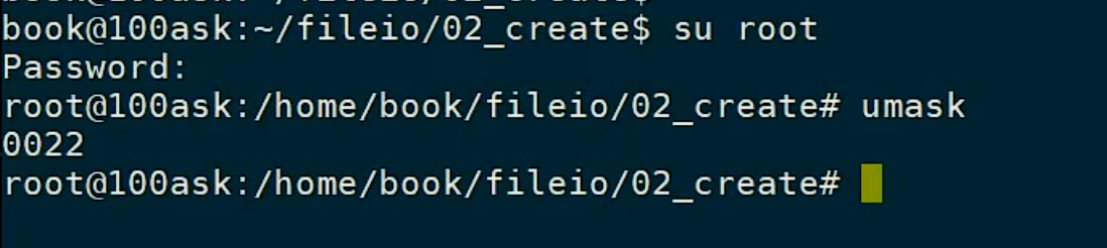
Umask就变为了0022
即000 010 010
----->表示对于同一组用户、其他用户不能有写权限。
同样,用root用户创建一个0777的文件,看看会发生啥:
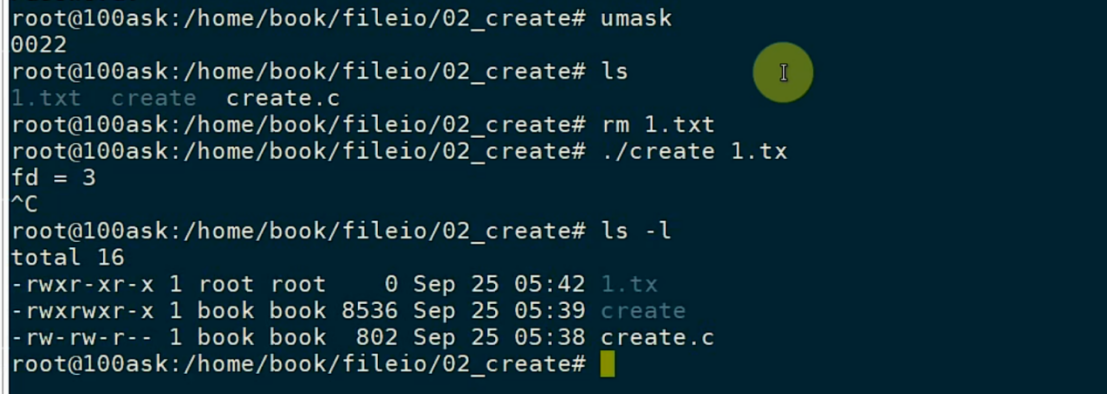
可见除了自己以外都没有写的权限。
为什么要有这样的umask设定?
安全,防止无意中创建权限过大的文件。
假设没有 umask:
你写了个程序,调用 open("config.txt", O_CREAT, 0666)。
结果文件权限是 -rw-rw-rw-,所有人(包括其他用户)都能改写你的配置文件。
如果有人把恶意配置写进去,你的程序就被人拿捏了。
有了 umask(通常默认是 0002 或 0022):
系统自动扣掉 Other 的写权限。
最终权限是 -rw-rw-r--,其他用户只能读不能改。
安全了。
umask 就是一个"默认的安全底线",防止程序或用户不小心创建出权限过大的文件。即使你忘了考虑安全性,系统也会帮你兜住底限。
在代码里怎么无视 umask?
有时候你确实需要精确控制权限(比如创建锁文件),不想被 umask 干涉。用 fchmod 在创建文件后再手动改一遍就行:
fd = open("file.txt", O_CREAT | O_RDWR, 0666);
fchmod(fd, 0666); // 强制设为 0666,无视 umask
三、write函数
在Linux系统中,write函数是一个基本的系统调用,用于将数据写入到已打开的文件中。这个函数的声明可以在unistd.h头文件中找到,其原型如下:
1.函数原型
ssize_t write(int fd, const void *buf, size_t count);
这里,write函数接受三个参数:
int fd:文件描述符,是通过open函数打开文件时返回的一个整数值,用于标识和访问文件。
const void *buf:指向数据的指针,这个数据将被写入文件。buf通常作为缓冲区,用于存储要写入或读取的数据。
size_t count:要写入的字节数。
函数的返回值是实际写入的字节数。如果写入成功,返回值是一个非负数,表示写入的字节数;如果写入失败,返回值为-1,并且errno变量会被设置为相应的错误代码。
2.文件偏移量(POS)的自动更新:
写入前
当前文件偏移量 POS = N。
执行 write(cfd, buf, M),从文件位置 N 开始写入 M 个字节。
写入后
写入完成,内核自动将 POS 向前移动 M 个字节。
新的偏移量 POS = N + M。
后续写入
如果再次调用 write(cfd, buf, M),会从新的位置 (N + M) 继续写入。
写完后,POS 再次增加 M。
注意,write写入的是文件fd,而不是buf,buf只是个存放字符串的缓冲区!
3.一个很简单的示例代码:
cpp
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main()
{
int fd;
char *buf = "hello kaizy!";
fd = open("./file1", O_CREAT|O_RDWR, 0600);
if (fd > 0)
{
printf("open file1 success\nfd=%d\n", fd);
}
write(fd, buf, strlen(buf));
close(fd);
return 0;
}示例代码2:
cpp
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
#include <errno.h>
#include <stdio.h>
#include <unistd.h>//需注意close头文件是这个!
/* kaizy
* ./write 1.txt str1 str2
* argc = 2
* argv[0] = "./open"
* argv[1] = "1.txt"
*/
int main(int argc, char** argv)
{
int fd;
int i;
int len;
if (argc < 3)
{
printf("Usage: %s <file> <string1> <string2> ...\n", argv[0]);
return -1;
}
fd = open(argv[1], O_RDWR|O_CREAT|O_TRUNC,0644);
if (fd < 0)
{
printf("can not open %s\n", argv[1]);
printf("errno=%d\n", errno);
char* msg = strerror(errno);
printf("erro reason:%s\n", msg);
perror("file");
return -1;//出错必须返回
}
printf("open success, fd = %d\n", fd);
//依次向文件写入字符串
for (i = 2; i < argc; i++)
{
len = write(fd, argv[i], strlen(argv[i]));
if (len != strlen(argv[i]))
{
perror("write");
break;
}
write(fd, "\r\n", 2);//每次写入字符串之后,就换行
/*"\r\n":回车 + 换行,两个字符。
2:写入 2 个字节,就是 \r 和 \n。*/
}
close(fd);//文件打开成功后,程序结束前要关闭,否则文件描述符泄漏。虽进程退出时系统会回收,但养成习惯非常重要,以后写长时间运行的程序这是致命 bug。
return 0;
}测试:
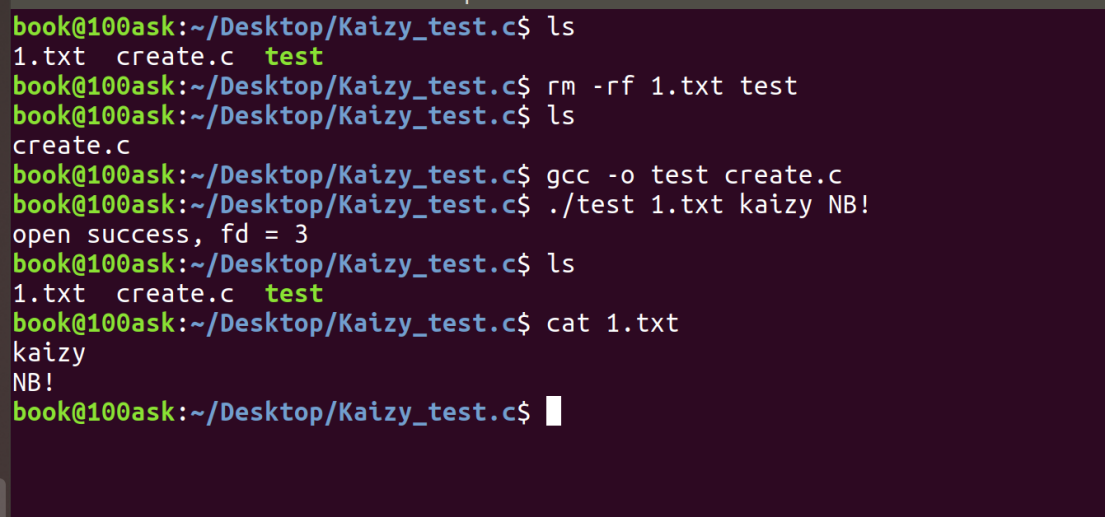
若我想从文件中间某一个位置来写入数据,也是可以的:
这就需要用到lseek函数了:
4.补充:lseek函数
lseek 是 Linux/Unix 系统调用,用于移动文件读写位置指针,实现随机访问文件内容,而无需实际读写数据。它常用于文件定位、获取文件大小、扩展文件等场景。
函数原型
cpp
#include <sys/types.h>
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence);off_t 是一个数据类型 ,专门用来表示文件偏移量(文件大小或位置) 。它定义在 <sys/types.h> 里,本质上是一个整数类型,通常是 long 或 long long。
fd:文件描述符
offset:偏移量(字节,可正可负)
whence:偏移参考位置 SEEK_SET:从文件开头偏移 SEEK_CUR:从当前位置偏移 SEEK_END:从文件末尾偏移
返回值:成功返回新的文件偏移量,失败返回 -1 并设置 errno。
常见用法示例:
重置文件指针到开头
lseek(fd, 0, SEEK_SET);
获取文件大小
int size = lseek(fd, 0, SEEK_END);
printf("file size = %d\n", size);
扩展文件大小
lseek(fd, 100, SEEK_END); // 指针移到文件尾后100字节
write(fd, "\0", 1); // 必须写入才能真正扩展
读取文件并回到开头
write(fd, "hello", 5);
lseek(fd, 0, SEEK_SET); // 回到文件头
read(fd, buf, sizeof(buf));
注意事项
lseek 不会改变文件内容,仅改变文件描述符的内部偏移量。
对管道、套接字、字符设备等不支持随机访问的文件类型,lseek 会失败。
若偏移超出文件末尾且执行写操作,文件会被扩展,中间填充 \0。
获取文件大小时,lseek(fd, 0, SEEK_END) 是高效方法,但需注意恢复原偏移位置。
代码:
cpp
/*write_in_pos:*/
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
#include <errno.h>
#include <stdio.h>
#include <unistd.h>//需注意close头文件是这个!
/* kaizy
* ./write 1.txt str1 str2
* argc = 2
* argv[0] = "./open"
* argv[1] = "1.txt"
*/
int main(int argc, char** argv)
{
int fd;
int i;
int len;
if (argc !=2)
{
printf("Usage: %s <file>\n", argv[0]);
return -1;
}
fd = open(argv[1], O_RDWR|O_CREAT,0644);
if (fd < 0)
{
printf("can not open %s\n", argv[1]);
printf("errno=%d\n", errno);
char* msg = strerror(errno);
printf("erro reason:%s\n", msg);
perror("file");
return -1;//出错必须返回
}
printf("open success, fd = %d\n", fd);
printf("lseek to offset 3 from file head\n");
lseek(fd, 3, SEEK_SET);//在文件开头偏移3字节位置写入数据
write(fd, "123", 3);
close(fd);//文件打开成功后,程序结束前要关闭,否则文件描述符泄漏。虽进程退出时系统会回收,但养成习惯非常重要,以后写长时间运行的程序这是致命 bug。
return 0;
}编译运行:
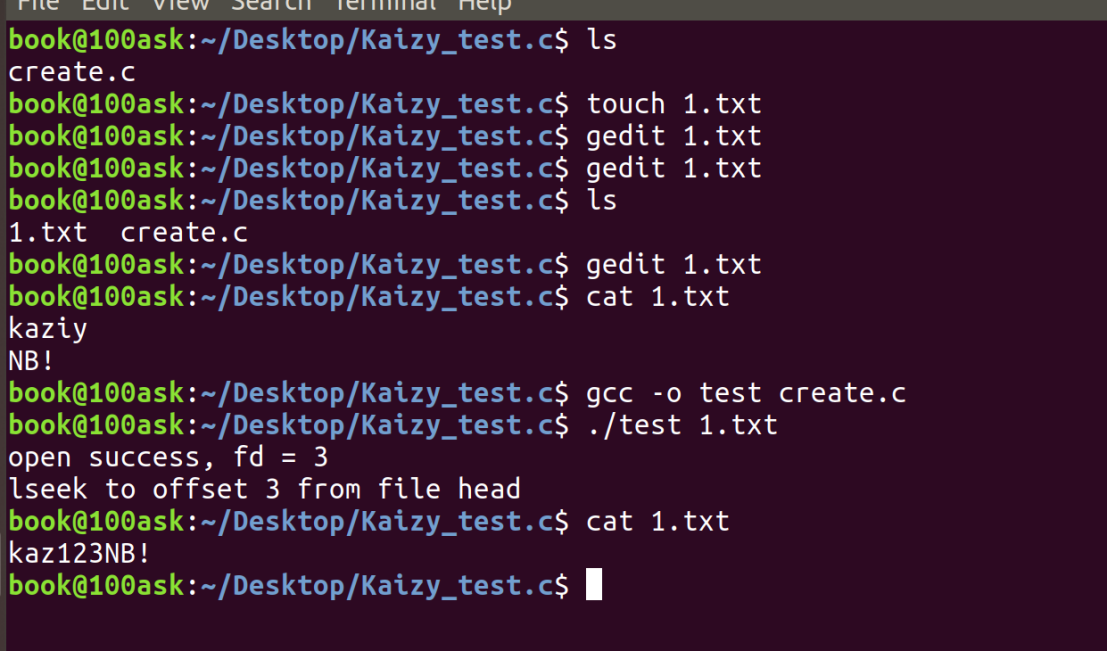
实际上是被覆盖了。
四、read函数
在Linux系统中,read函数是一个常用的系统调用,用于从文件或设备中读取数据。它是低级别I/O操作的核心,直接与操作系统内核交互,提供高效的数据读取方式。
函数定义与参数说明
1.read函数的声明如下:
cpp
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);fd:文件描述符,表示需要读取的文件或设备。通过open等函数获取。
buf:指向用户分配的缓冲区的指针,读取到的数据会存储在该缓冲区中。
count:需要读取的字节数,表示最多读取count字节。
2.返回值:
成功时返回实际读取的字节数。
返回0表示已到达文件末尾。
失败时返回-1,并设置errno指示具体错误。
3.工作原理
read是一个阻塞调用。当请求的数据未准备好时,调用进程会挂起,直到有数据可读或发生错误。其基本流程包括:
检查文件描述符的有效性及权限。
从文件或设备中读取数据到用户提供的缓冲区。
返回实际读取的字节数。
当到达文件末尾时,read返回0,表示没有更多数据可读。
4.使用示例
以下是一个从文件中读取数据的简单示例:
cpp
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
int fd;
ssize_t bytesRead;
char buffer[1024];
// 打开文件
fd = open("example.txt", O_RDONLY);
if (fd == -1)
{
perror("Failed to open file");
return 1;
}
// 读取数据
bytesRead = read(fd, buffer, sizeof(buffer) - 1);
if (bytesRead == -1)
{
perror("Failed to read file");
close(fd);
return 1;
}
// 确保字符串以'\0'结束
buffer[bytesRead] = '\0';
printf("Read %zd bytes: %s\n", bytesRead, buffer);
// 关闭文件
close(fd);
return 0;
}5.注意这个代码细节:
// 确保字符串以'\0'结束
bufferbytesRead = '\0';
Read函数读取的数据会存放在这个缓冲区buffer,但是:
read 的职责:它眼里只有二进制数据,对文件内容无任何假设。读多少字节,就填多少字节进 buffer,绝不会在你数据后面偷偷加个 \0。
printf("%s") 的依赖:%s 打印字符串,全凭那个 \0 才知道在哪停下来。如果 buffer 里没有 \0,printf 会从起始位置一直往下读,直到在内存里撞上某个随机存在的 \0 才停,这就是臭名昭著的缓冲区溢出,结果就是打印出一堆乱码,甚至程序崩溃。
所以,你必须手动加这个 \0,为 printf 或其他字符串处理函数提供一个明确的终止符。
bytesRead = read(fd, buffer, sizeof(buffer) - 1);为什么是sizeof(buffer)-1???
这是为了预留一个字节。
首先看缓冲区数组buffer的定义:
char buffer1024;
Buffer分配了1024字节,下标是0~1023
如果 read 刚好读满 1024 字节,bytesRead 就是 1024。
接下来 buffer1024 = '\0' 写的是不属于 buffer 的内存区域。
这会导致未定义行为,轻则破坏其他变量,重则程序崩溃。
若预留了一个字节:
BytesRead就是1023, buffer1023 = '\0' 写的刚好落在 buffer 的内存区域,
最多读 1023 字节,给 \0 留出第 1024 个位置(下标 1023)。
无论 read 读多少,\0 永远写在合法范围内。
6.错误处理:
read可能因以下原因失败:
EINTR:调用被信号中断。
EIO:I/O错误(如硬件故障)。
EINVAL:参数非法,例如文件描述符无效。
EBADF:文件描述符无效或权限不足。
EFAULT:缓冲区地址不合法。
在每次调用read后,应检查返回值是否为-1,并根据errno进行处理。
7.非阻塞读取:
默认情况下,read是阻塞的。可以通过O_NONBLOCK标志将文件或设备设置为非阻塞模式。当数据不可用时,read会立即返回-1,并设置errno为EAGAIN或EWOULDBLOCK。
示例:
cpp
int fd = open("example.txt", O_RDONLY | O_NONBLOCK);
if (fd == -1)
{
perror("Failed to open file in non-blocking mode");
return 1;
}
ssize_t bytesRead = read(fd, buffer, sizeof(buffer));
if (bytesRead == -1 && errno == EAGAIN)
{
printf("No data available yet, try again later.\n");
}8.应用场景
read不仅适用于文件操作,还可用于读取设备、管道和网络套接字。例如:
从标准输入读取:read(0, buffer, sizeof(buffer));
从管道读取:read(pipefd0, buffer, sizeof(buffer));
从套接字读取:read(sockfd, buffer, sizeof(buffer));
9.另一个示例代码
cpp
/*read:*/
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
#include <errno.h>
#include <stdio.h>
#include <unistd.h>//需注意close头文件是这个!
/* kaizy
* ./read 1.txt
*/
int main(int argc, char** argv)
{
int fd;
int i;
int len;
unsigned char buf[100];
if (argc !=2)
{
printf("Usage: %s <file>\n", argv[0]);
return -1;
}
fd = open(argv[1], O_RDONLY);
if (fd < 0)
{
printf("can not open %s\n", argv[1]);
printf("errno=%d\n", errno);
char* msg = strerror(errno);
printf("erro reason:%s\n", msg);
perror("file");
return -1;//出错必须返回
}
printf("open success, fd = %d\n", fd);
//读取,打印数据
while (1)
{
len = read(fd, buf, sizeof(buf) - 1);
if (len < 0)
{
perror("read");
close(fd);//不要忘了关闭文件。
return -1;
}
else if (len == 0)//表示已经读到文件末尾
{
break;
}
else
{
//读取成功,设置结束符,打印数据
buf[len] = '\0';
printf("buf: %s\n", buf);
}
}
close(fd);//文件打开成功后,程序结束前要关闭,否则文件描述符泄漏。虽进程退出时系统会回收,但养成习惯非常重要,以后写长时间运行的程序这是致命 bug。
return 0;
}编译运行:
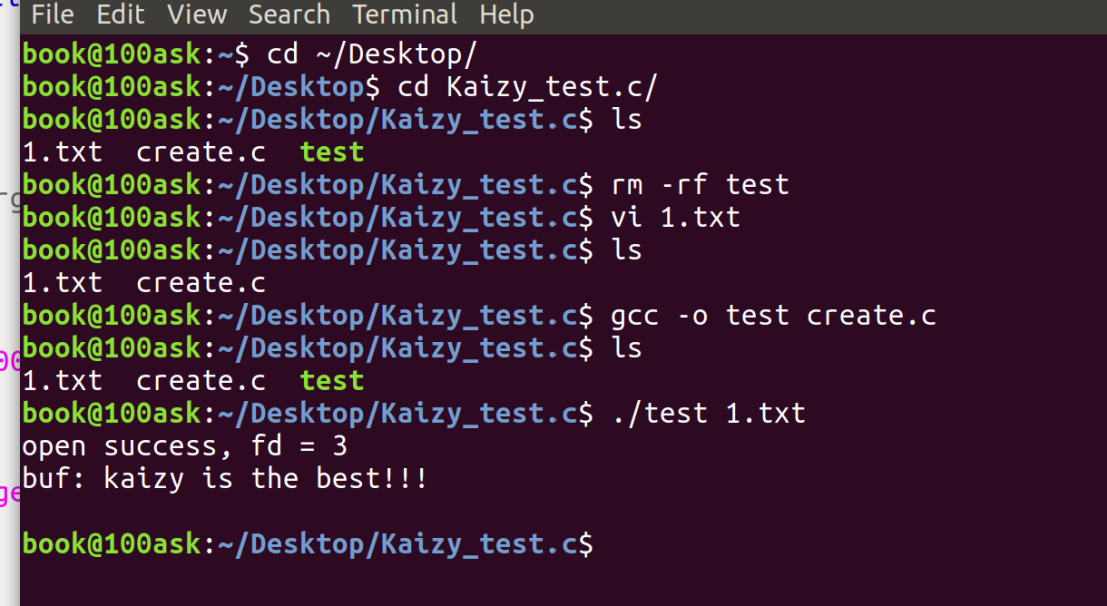
完美!
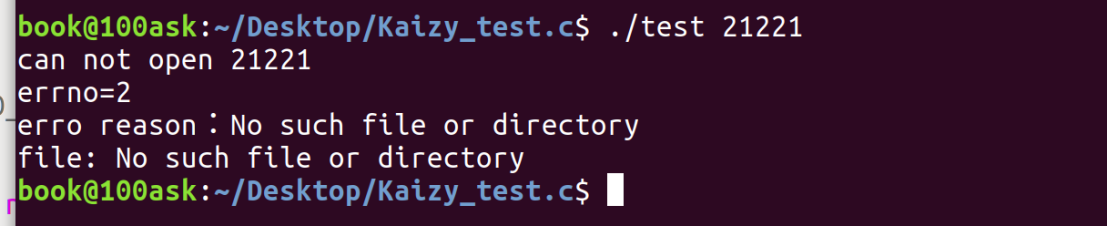
若我读一个不存在的文件:
假设我创建了一个文件,但是该我除去了该文件的读权限(图片来自韦东山课程):
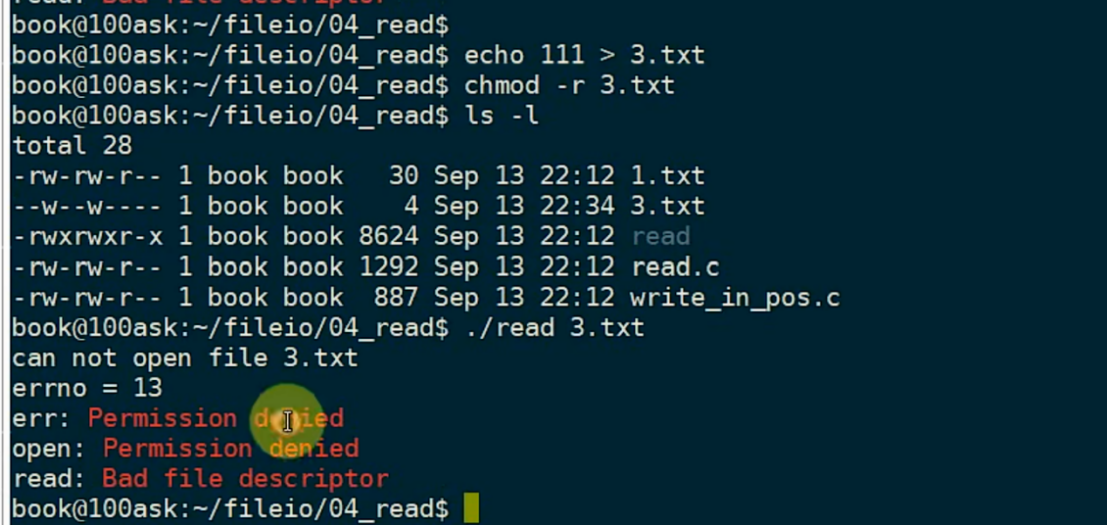
文件不可读,就会报错!