从零开始理解 CNN(上):为什么图像任务需要卷积神经网络?

🔥 星恒随风: 个人主页 ❄️ 个人专栏: 《指针合集》 | 《C语言基础》 | 《数据结构》 | 《机器学习导论》 | 《前端基础》 ✨ 数据即知识,压缩即智能
写在前面:
在前面的文章中,我们已经学习了 MLP,也就是多层感知机。MLP 的核心思想是: 把输入数据看成一个向量,然后通过多层线性变换和激活函数完成预测。
但是,当我们把 MLP 直接用于图像任务时,很快就会遇到一个问题: 图像有空间结构
目录
- [从零开始理解 CNN(上):为什么图像任务需要卷积神经网络?](#从零开始理解 CNN(上):为什么图像任务需要卷积神经网络?)
-
- [一、先从一个问题开始:MLP 为什么不太适合直接处理图像?](#一、先从一个问题开始:MLP 为什么不太适合直接处理图像?)
- 二、图片被"压扁"后,空间关系被破坏了
- [三、CNN 的核心想法:不要一口气看全图,而是先看局部](#三、CNN 的核心想法:不要一口气看全图,而是先看局部)
- 四、卷积核可以理解成什么?
- 五、类比:卷积核像侦察兵
- 六、特征图是什么?
- [七、CNN 为什么适合图像?](#七、CNN 为什么适合图像?)
- 八、特点一:局部连接------先看局部,再理解整体
- 九、特点二:参数共享------同一个探测器,全图复用
- 十、特点三:层次化特征提取------从边缘到语义
- [十一、CNN 和 MLP 的本质区别](#十一、CNN 和 MLP 的本质区别)
- [十二、CNN 的历史位置](#十二、CNN 的历史位置)
- 十三、上篇总结
一、先从一个问题开始:MLP 为什么不太适合直接处理图像?
假设有一张 224 × 224 的 RGB 图片。
它的输入维度是:
224 × 224 × 3 = 150528
也就是说,一张图片在计算机眼里,本质上是 150528 个数字。
如果使用 MLP,通常要先把图片拉平成一个长向量:
text
224 × 224 × 3 → 150528这听起来好像可以,但问题很快出现了。
二、图片被"压扁"后,空间关系被破坏了
我们识别图片时,不只是看每个像素的数值,还要看它们之间的空间关系。
例如识别一片水稻叶片时,我们可能会关注:
| 视觉线索 | 对识别有什么帮助 |
|---|---|
| 叶片边缘 | 判断叶片轮廓 |
| 叶脉纹理 | 判断植物结构 |
| 颜色变化 | 判断是否发黄、枯萎 |
| 病斑形状 | 判断病害类型 |
| 病斑分布 | 判断病害严重程度 |
这些信息都不是孤立像素能表达的,而是由局部区域共同构成的。
如果把图片拉平成一维向量,模型当然仍然能训练,但它没有天然利用图像的二维空间结构。
形象理解:
这就像你把一张地图剪成很多小块,然后排成一条直线。地图上的城市、河流、道路都还在,但它们之间的相对位置关系变得很难利用。
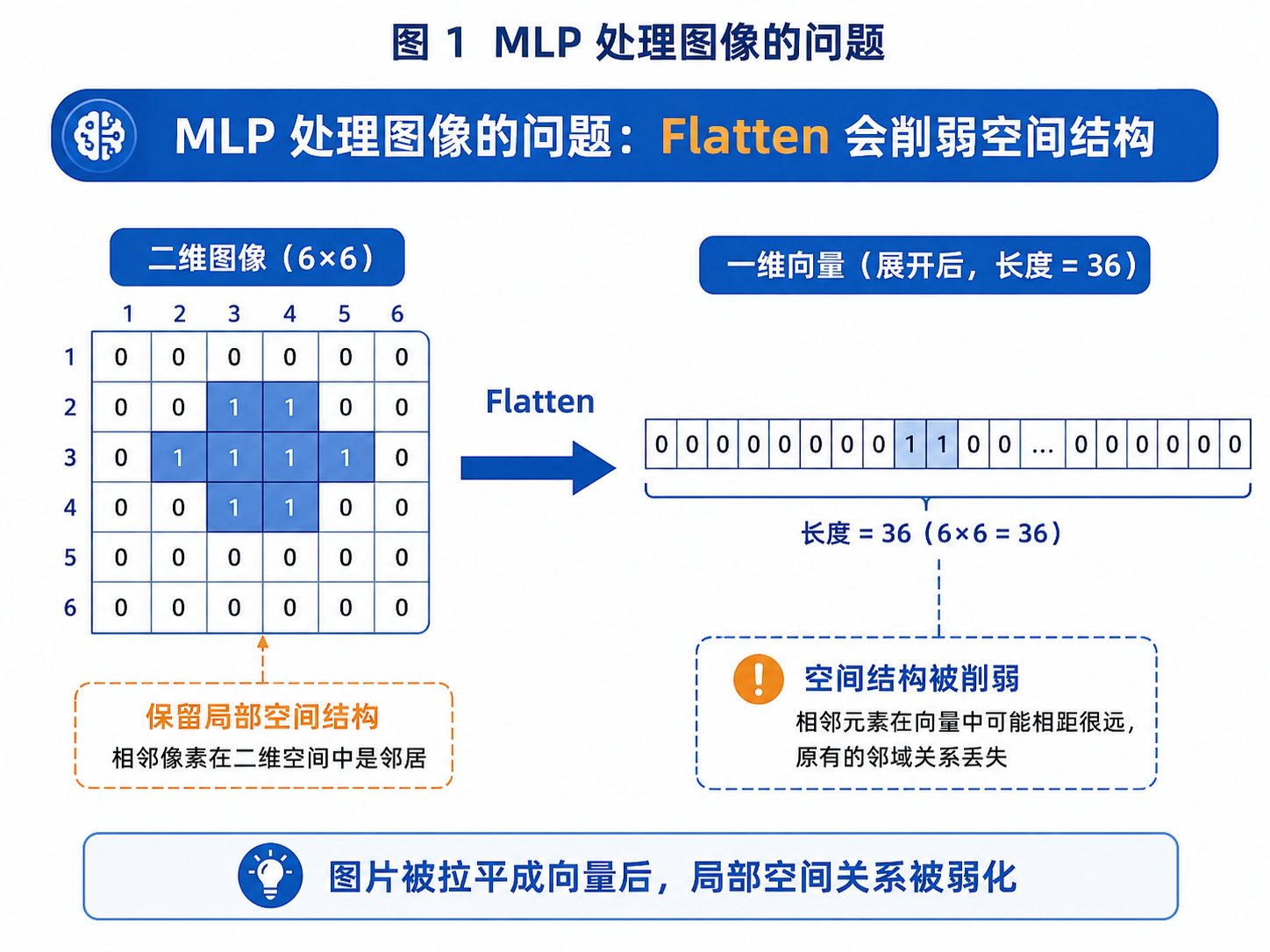
图 1:MLP 将二维图像拉平成一维向量后,局部空间关系会被削弱。
三、CNN 的核心想法:不要一口气看全图,而是先看局部
CNN 的思路非常符合人类看图像的方式。
我们看一张图时,往往不是一眼就理解所有内容,而是先观察局部:
边缘在哪里?
纹理有什么变化?
有没有明显斑点?
有没有局部形状?
局部结构之间如何组合?
CNN 也是这样做的。
它不会让每个神经元一开始就连接整张图片,而是使用一个小窗口在图片上滑动,一块一块地观察局部区域。
这个小窗口就是:
卷积核,也叫 filter 或 kernel
四、卷积核可以理解成什么?
卷积核可以理解成一个:
特征探测器
它在图片上滑动,每到一个位置,就问一个问题:
"这里有没有我想找的特征?"
比如:
有没有竖直边缘?
有没有水平边缘?
有没有颜色突变?
有没有某种纹理?
有没有病斑形状?
如果有,输出值就比较大;如果没有,输出值就比较小。
所以卷积层不是神秘操作,它更像是一组会学习的"图像侦察兵"。
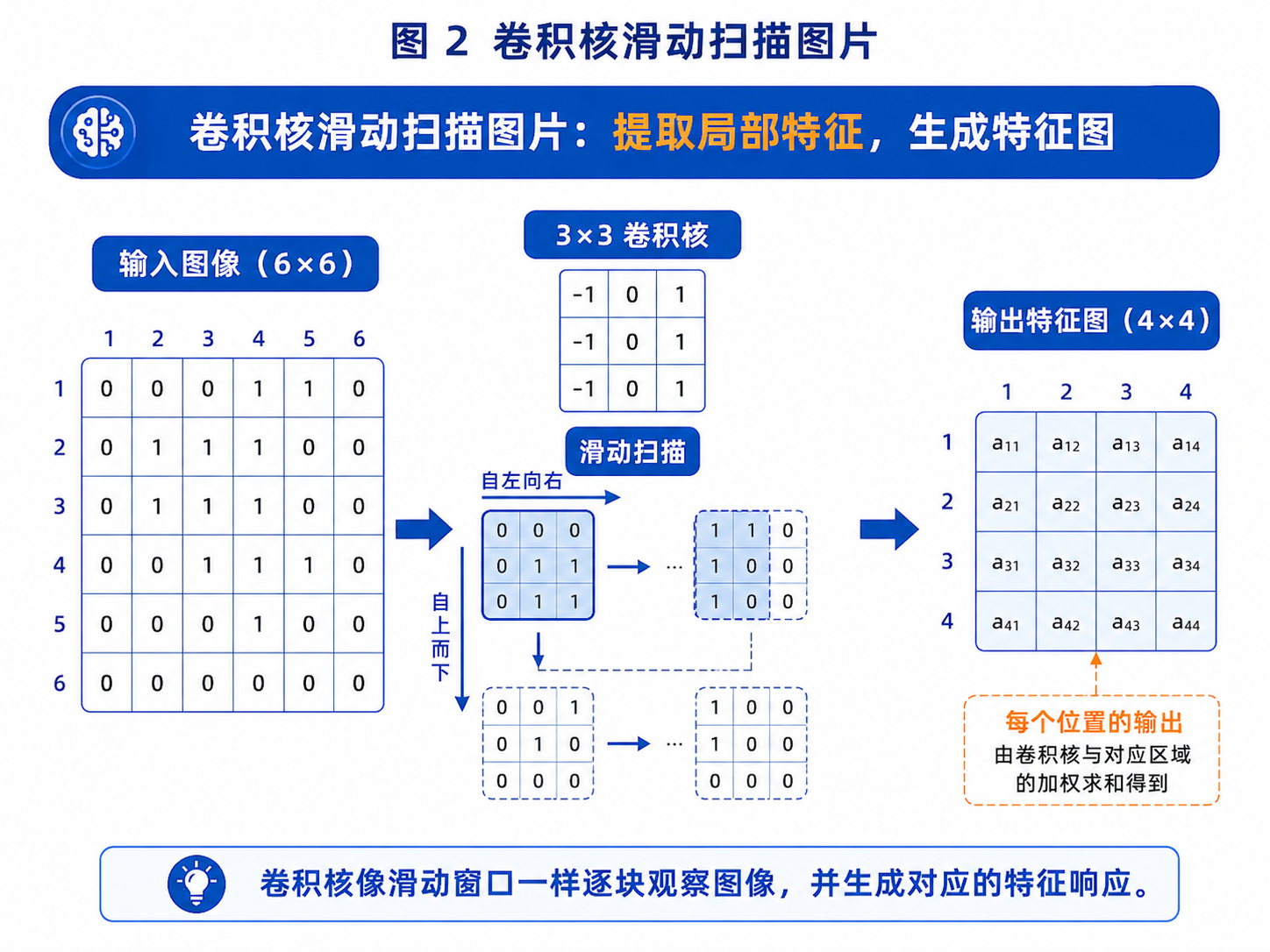
图 2:卷积核在图像上滑动,每次只观察一个局部区域,并生成对应的特征响应。
五、类比:卷积核像侦察兵
你可以把整张图片想象成一片地图。
卷积核就是一个侦察兵。
它不会一次看完整张地图,而是从左到右、从上到下慢慢巡逻。
每走到一个位置,它就检查:
这里有没有边缘?
这里有没有纹理?
这里有没有斑点?
这里有没有某种局部形状?
如果发现目标,它就在输出图上做一个标记。
这张输出图就叫:
特征图,Feature Map
六、特征图是什么?
特征图可以理解为:
模型在整张图片上找到某种特征的位置分布图。
比如:
一个卷积核负责找竖直边缘;
另一个卷积核负责找水平边缘;
另一个卷积核负责找斑点纹理;
另一个卷积核负责找颜色突变。
那么不同卷积核就会输出不同的特征图。
换句话说,卷积层的输出不再是原始像素,而是模型眼中"有用特征"的响应分布。
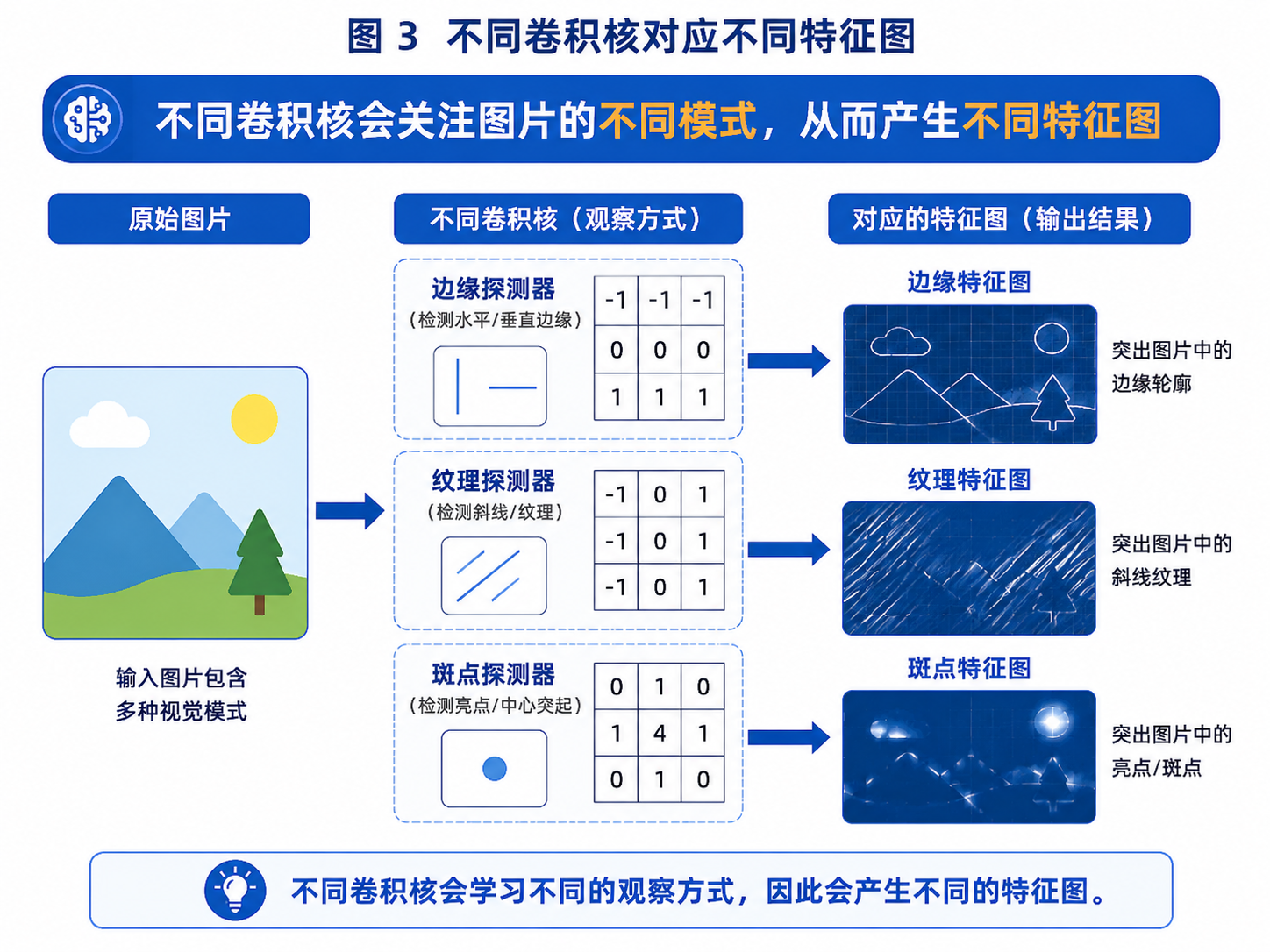
图 3:不同卷积核会学习不同的观察方式,因此会产生不同的特征图。
七、CNN 为什么适合图像?
CNN 之所以适合图像,主要依赖三个核心特点:
| 特点 | 含义 | 为什么重要 |
|---|---|---|
| 局部连接 | 一次只看图像局部区域 | 符合图像的局部结构特点 |
| 参数共享 | 同一个卷积核在整张图上复用 | 大幅减少参数量 |
| 层次化特征提取 | 从简单特征逐层组合成复杂特征 | 符合视觉理解过程 |
八、特点一:局部连接------先看局部,再理解整体
图像中的一个像素,通常和它附近的像素关系更密切。
比如一条边缘,往往来自相邻像素之间的颜色或亮度突变。
一个病斑,也往往表现为某个局部区域内颜色、纹理、形状的共同变化。
因此,CNN 没有必要让每个神经元一开始就看整张图。
它只需要先看局部区域。
例如一个 3×3 卷积核,每次只观察一个 3×3 的小窗口。
这就是局部连接。
九、特点二:参数共享------同一个探测器,全图复用
假设有一个卷积核学会了检测"竖直边缘"。
那么这个卷积核不应该只在图片左上角生效。
因为竖直边缘可能出现在图片任何位置。
所以 CNN 会让同一个卷积核在整张图片上滑动。
这就是参数共享。
参数共享的好处:
减少参数量;提升特征复用能力;同一个特征探测器可以在全图工作;更适合处理目标位置变化的问题。
十、特点三:层次化特征提取------从边缘到语义
CNN 最精彩的地方,是它可以逐层构建特征。
浅层可能学到:
text
边缘;
亮暗变化;
颜色变化;
简单纹理。中间层可能学到:
text
角点;
局部图案;
叶脉纹理;
病斑边缘;
局部形状组合。深层可能学到:
text
叶片整体结构;
病害区域模式;
物体部件;
类别相关语义。这就是层次化特征提取。
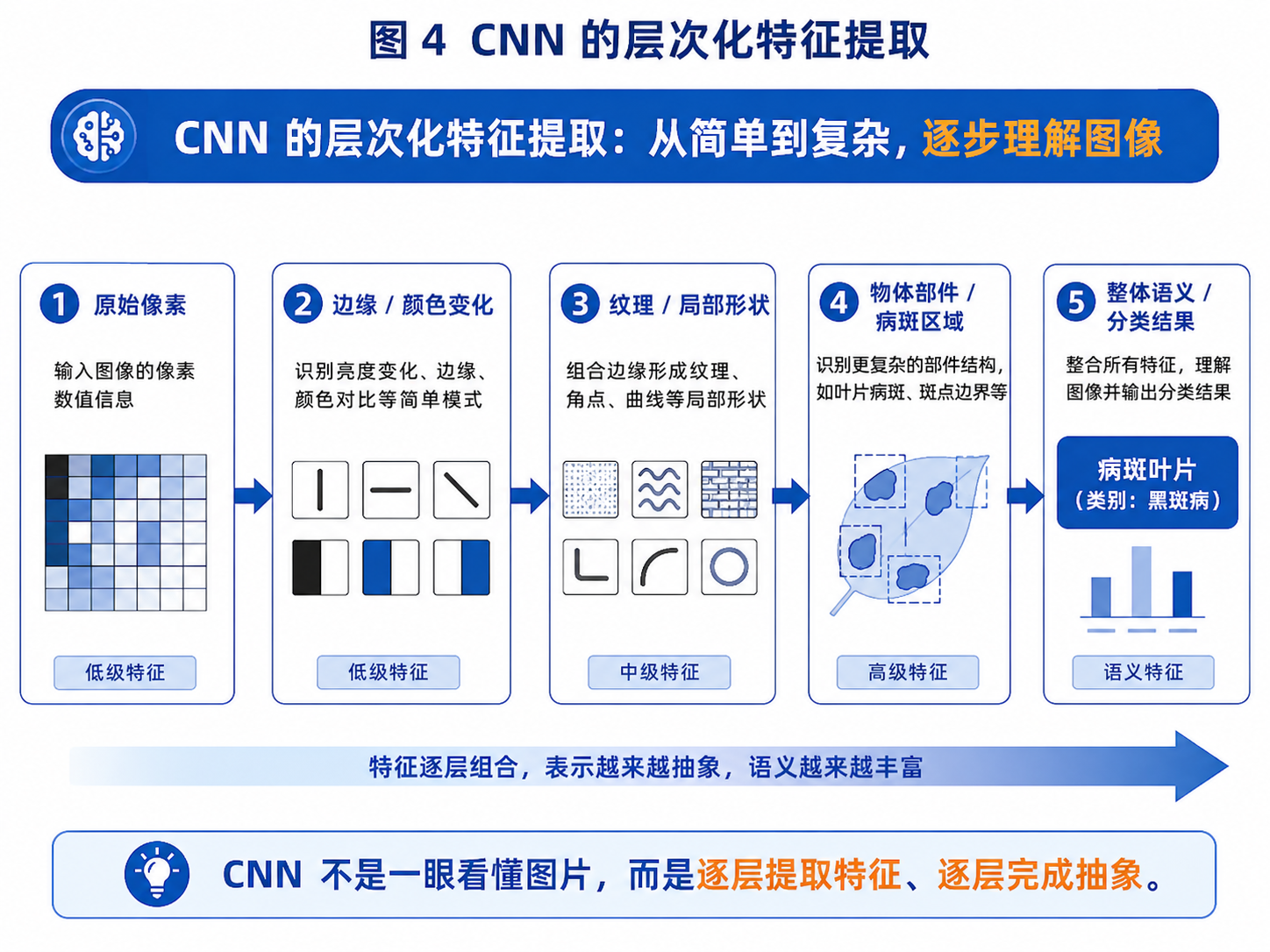
图 4:CNN 通过多层卷积逐步完成从低级视觉特征到高级语义特征的抽象。
十一、CNN 和 MLP 的本质区别
| 对比点 | MLP | CNN |
|---|---|---|
| 输入方式 | 通常先拉平成向量 | 保留图像二维结构 |
| 参数连接 | 全连接 | 局部连接 |
| 参数复用 | 较弱 | 同一卷积核全图共享 |
| 图像结构利用 | 不直接利用空间结构 | 天然利用空间结构 |
| 适合任务 | 表格、简单向量特征 | 图像、视觉任务 |
所以 CNN 不是简单地"比 MLP 更高级"。
更准确地说,CNN 的结构更符合图像数据的特点。
十二、CNN 的历史位置
CNN 并不是突然出现的。
LeNet 是早期非常经典的 CNN 代表,被用于手写字符和文档识别任务。
后来,AlexNet 在 ImageNet 大规模图像分类任务中取得突破,让深度卷积神经网络真正成为计算机视觉领域的重要主线。
CNN 不只是一个"课堂概念",而是推动计算机视觉发展的重要基础结构。后面的 VGG、ResNet、YOLO 等模型,都和 CNN 的思想密切相关。
十三、上篇总结
这一篇我们主要解决了一个问题:
为什么图像任务需要 CNN?
答案可以总结为三句话:
第一, 图像有空间结构,不能简单当成长向量处理。
第二, 卷积核可以像滑动窗口一样扫描局部区域,提取边缘、纹理、斑点等局部特征。
**第三,**CNN 通过局部连接、参数共享和层次化特征提取,更自然地适配图像数据。