 @bit::Shadow
@bit::Shadow
✧(≖ ◡ ≖✿
目录
[LBA(Logical Block Addressing)定址法](#LBA(Logical Block Addressing)定址法)
[*文件Access Modify Change](#*文件Access Modify Change)
[Super Block](#Super Block)
[GDT(Group Descriptor Table,块组描述符表)](#GDT(Group Descriptor Table,块组描述符表))
[⚠️ 恢复前最重要的第一原则](#⚠️ 恢复前最重要的第一原则)
[" . "的引用计数为什么是2?](#“ . ”的引用计数为什么是2?)
物理机械磁盘
目标:探寻物理磁盘内数据的组织方式。硬盘读取是如何实现的尽量高效读取?
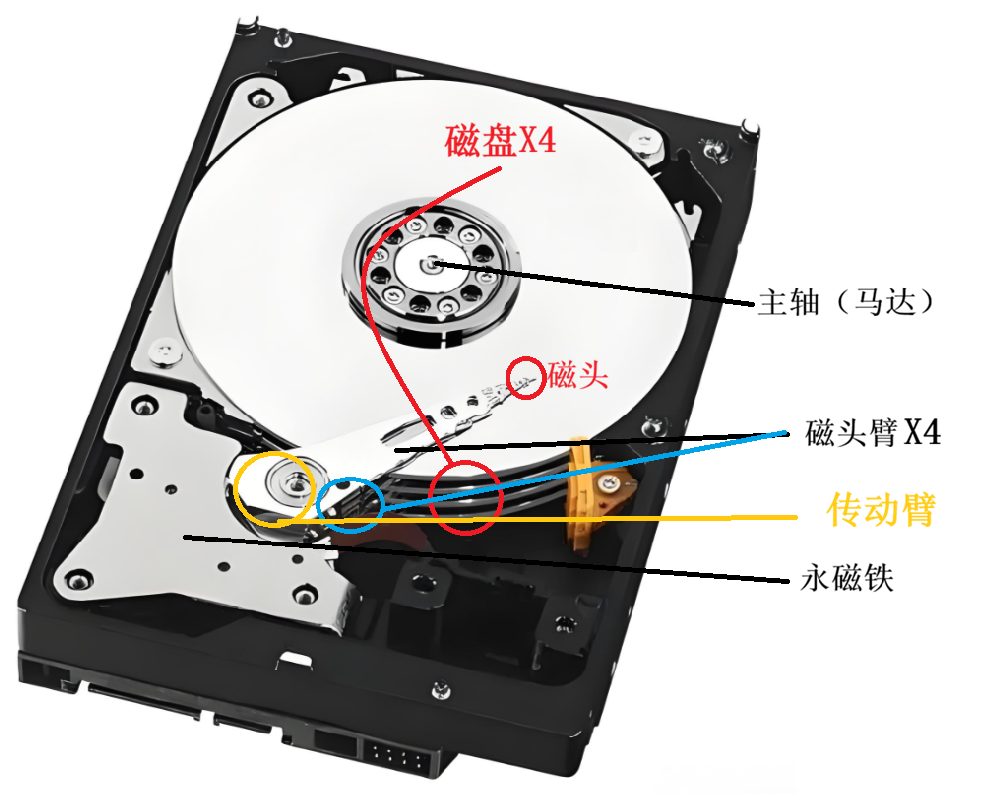
主体部分抽象图示:
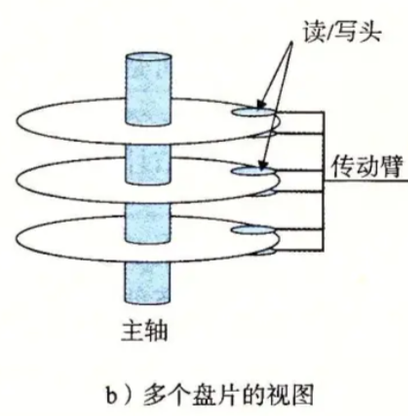
传动臂统一控制多个磁头臂!
磁盘
磁盘上以"同心圆"的形式组织数据:

每个同心圆称为磁道,磁道常被分作8分份,每份称为一个"扇面"。
在读/写磁盘数据时,磁头精准定位于高速旋转的(每秒120转左右)磁盘特定磁道的特定扇面,通过识别扇面上凸起的类型来读写信息。
LBA(Logical Block Addressing)定址法
柱面
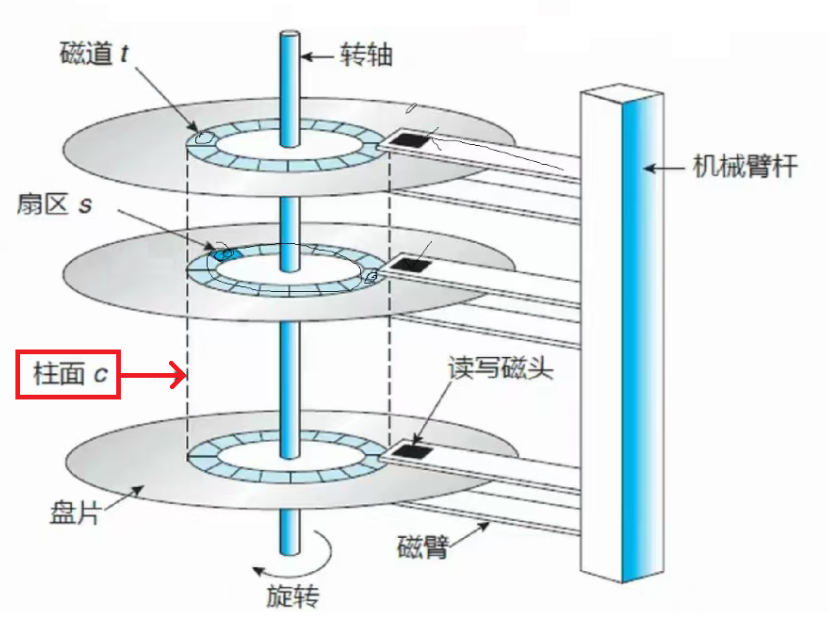
柱面+扇区,组成类似于"数组"的区块结构,从而据此来实现初步定址法"CHS定址法"。
CHS定址法
例:1号柱面(Cylind)、2号磁头(header)及3号扇区(Sector),通过三者编号-构成"CHS定址法"。
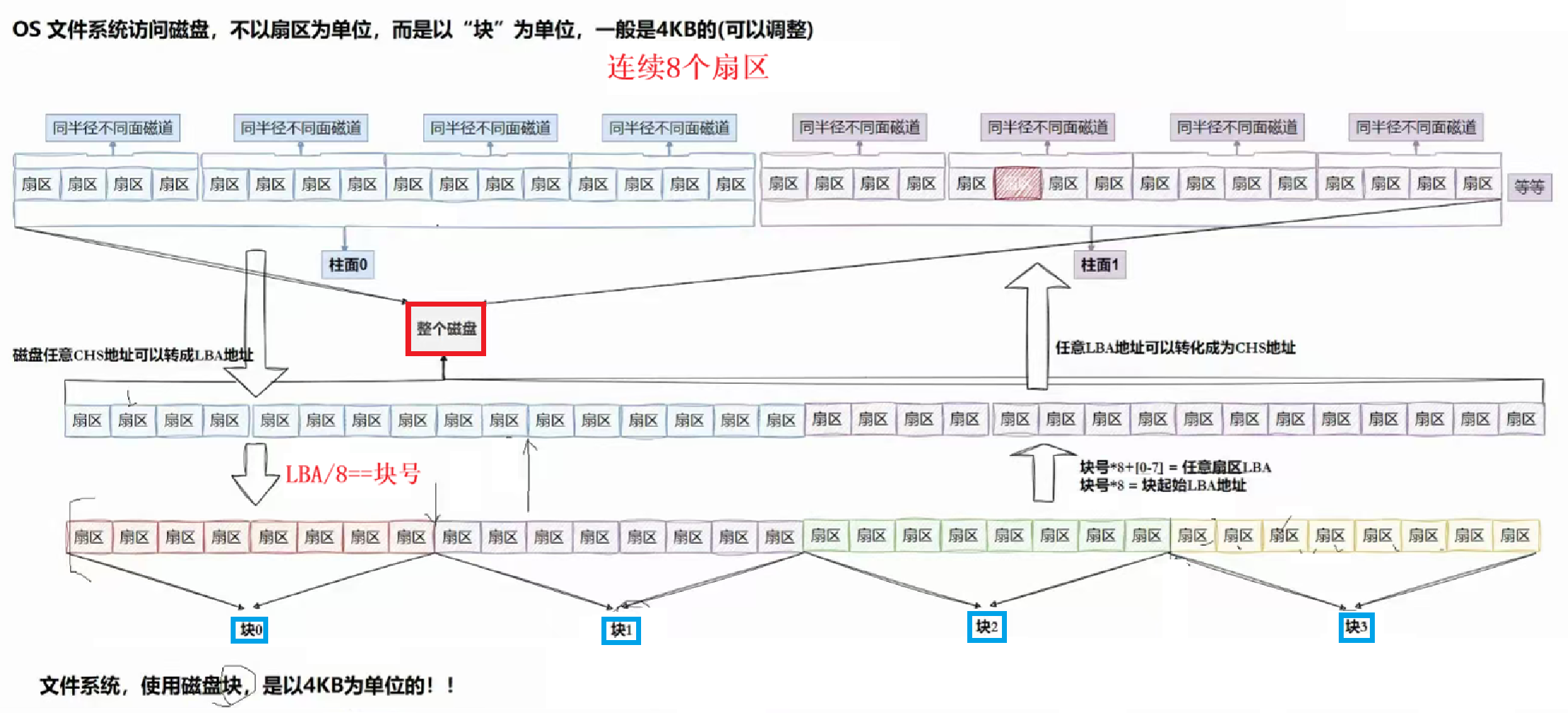
CHS->>LBA:
原理:"分治思想"将大块数据,逐步划分渐渐缩小。
OS操作系统访问磁盘不以扇区为单位,而是以"块"为单位,一般是4KB的。
此"块"是独立于磁盘的扇区等的,是操作系统自定义大小的规划结果。
文件属性查询指令:stat
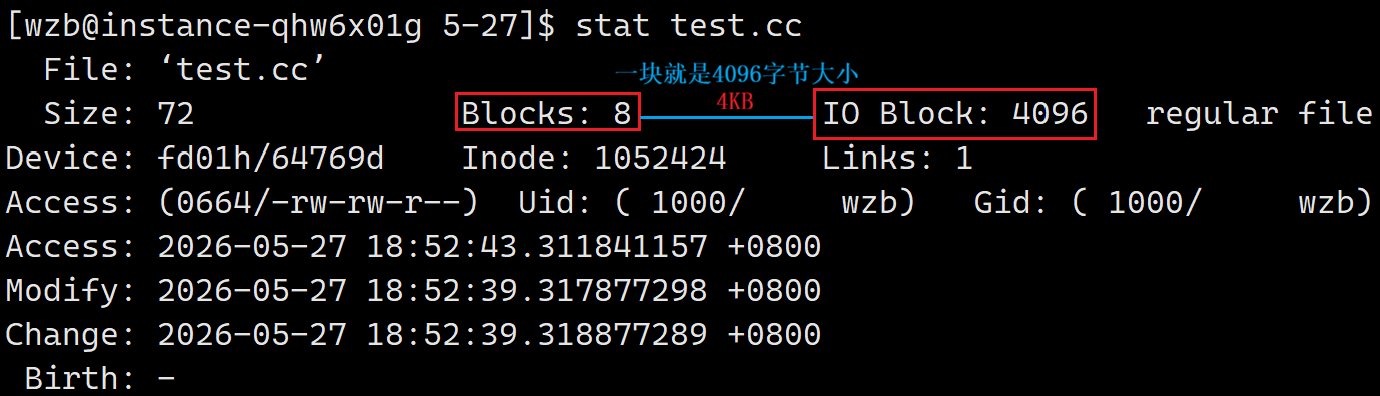
*文件Access Modify Change
|--------|------------|----------------|
| stat 文件名 |||
| Access | 读取文件内容 | less cat head |
| Modify | 修改文件内容 | cat > vim |
| Change | 文件属性改变 | chmod chown mv |
注意:随Modify数据改变,Change对应数据也通常会改变。像文件大小,修改时间等元数据改变。
内核Linux文件属性+内容分析
文件 == 文件内容+文件属性。
属性
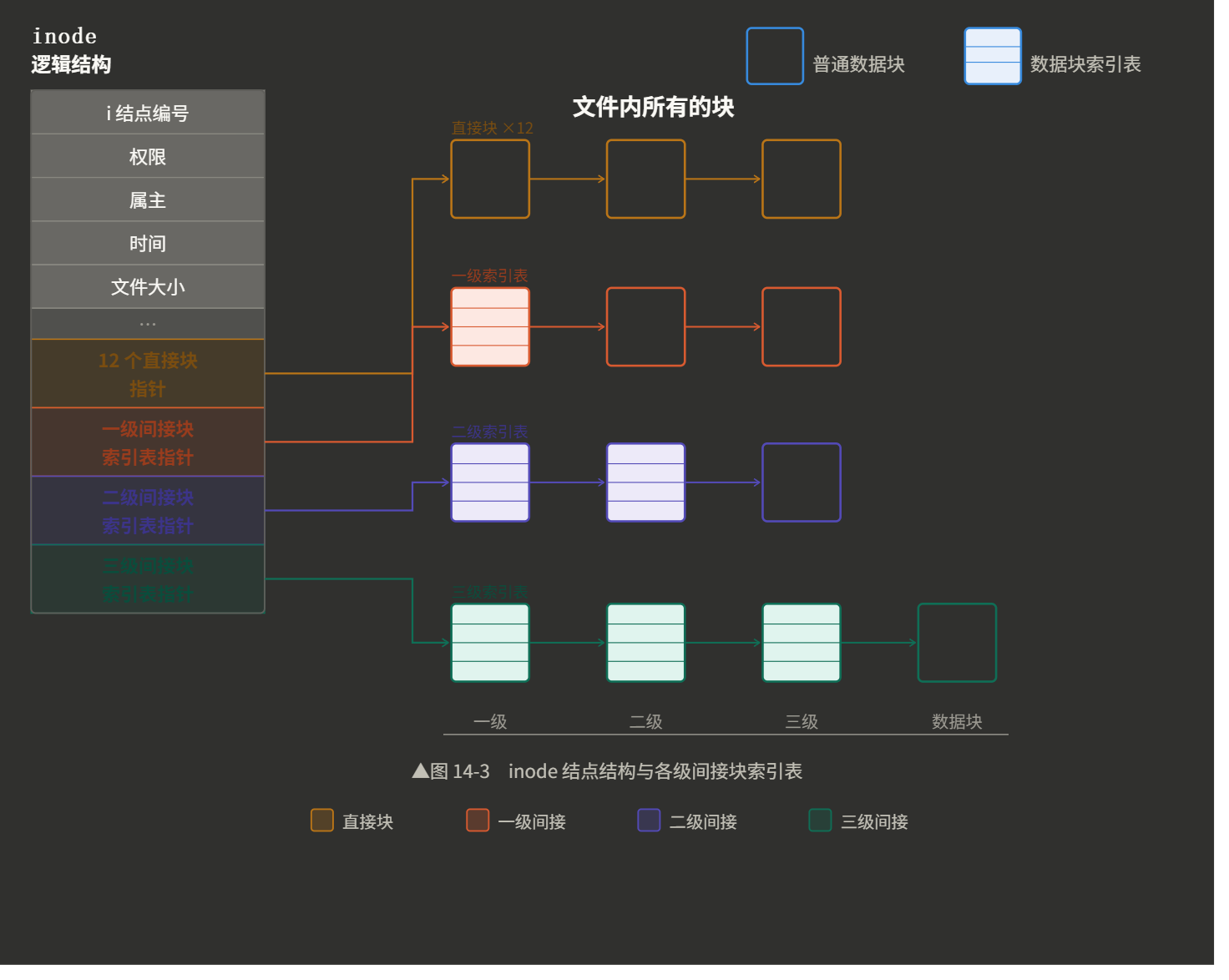
组织形式------struct inode { // ............ }
cpp
struct inode
{
//type
//size
//pri
//............
int inode_number; // inode编号-文件/目录的身份证号
}inode查询方式:ls -i # " i "是Linux下文件/目录的inode查询选项。
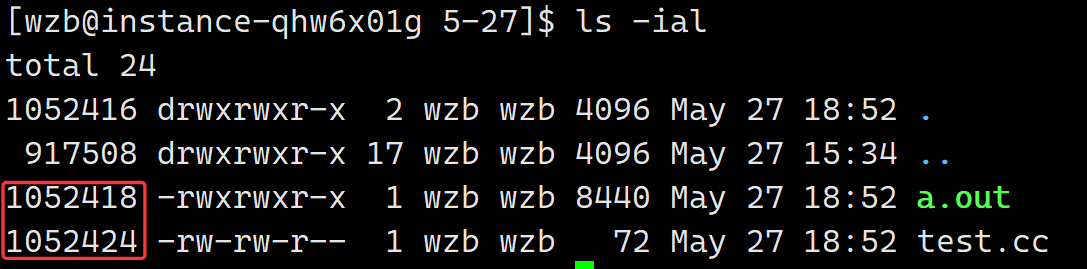
内容
多级指针管理Data Blocks,来扩展内容存储量:
|------|------------|-------------------|
| 指针类型 | 指向内容 | |
| 直接指针 | 数据块 | 12*4KB = 48KB |
| 一级指针 | 指向存有直接指针的块 | 256*4KB = 1MB |
| 二级指针 | 指向存在一级指针的块 | 256*1MB = 256MB |
| 三级指针 | 指向存在二级指针的块 | 256*256MB = 64GB |
☆☆☆内核中文件管理整体的分治管理链路:
分治的目的:将大块数据逐步划分为更小的内存块。
Super Block就是作为"更小的内存块"存在:
核心关系:
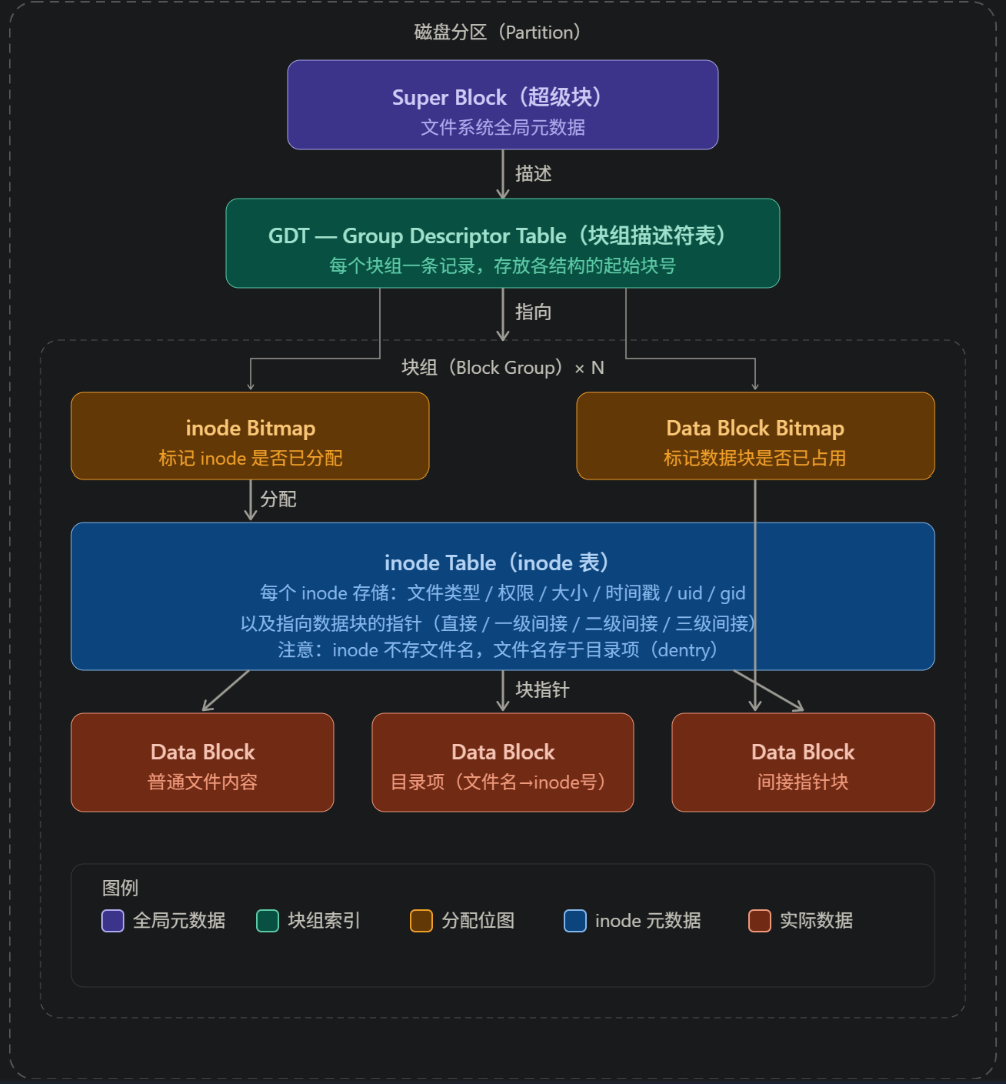
Super Block
功能:作为文件系统的身份证,类似于一本书的总目录/版权页,记录文件系统的全局信息:块大小、总块数、空闲块数、inode总数、空闲inode数、每块组包含的块数等。内核挂载文件系统时首先读取它。
位于Block Group内,但不一定可以存储全部的Block Group的目标特定信息,只有一份。(有备份)
GDT(Group Descriptor Table,块组描述符表)
功能:基于文件系统把磁盘分成若干块组(Block Group),分块信息就存储于GDT中。记录该块组中四个关键结构的起始块号:inode Bitmap、Data Block Bitmap等以及数据块区域的起始位置。
Super Block描述整体有多大,GDT描述"每组东西的分配位置"。
块组内部元素
Ⅰ• inode Bitmap :一个位图每位对应一个inode槽,1 = 已分配,0 = 空闲。创建文件时内核扫描它找一个空位。
Ⅱ• Data Block Bitmap:同理,每位对应一个数据块,管理数据块 的占用状态。
Ⅲ• inode Table:一张固定大小的表,每行是一个inode,存储文件的元数据(权限、大小、时间戳、uid/gid)以及若干块指针(直接指针*12+一/二/三级间接指针)。
Ⅳ• Data Blocks:存放真实内容。对普通文件是字节流;对目录文件是(文件名->inode号)的映射表;对应间接指针是下一级块号的列表。
☆☆☆查找一个文件的完整路径就是:Super Block确认块大小-->GDT找到对应块组的inode Table位置-->读取inode Table位置-->读取inode-->顺着块指针-->读取Data Blocks
*文件名在哪?
在Linux文件系统内,文件名不属于inode,而是存在于"目录"这个特殊文件内。
链接
"链接"是针对于目录、文件单元各自的独立链接。例如通过链接可实现文件路径的快速切换 ,不同目录下可执行文件的直接运行。
链接情况查询方式: ls -i
软链接
链接性质:建立后操作单个对象数据自动同步到另一对象。
创建方式:
ln -s 路径/文件 新对象
删除方式:
unlink 对象名
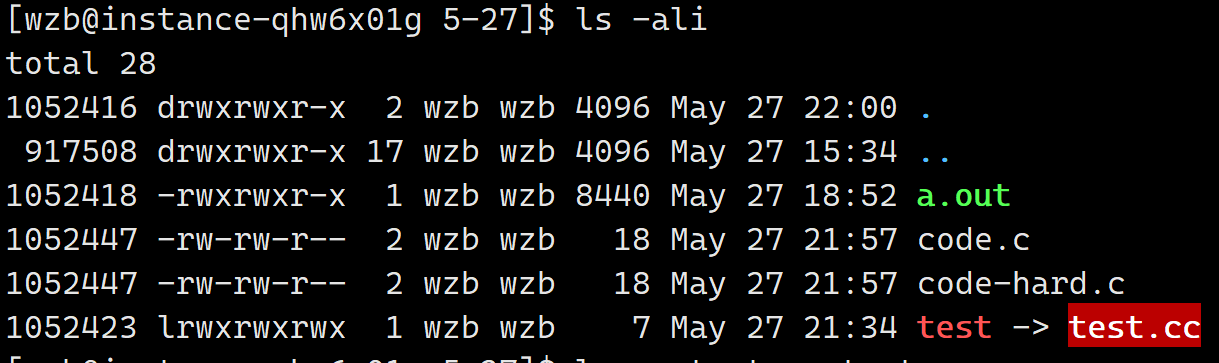
以文件链接为例:
软链接后链接目标加以"->"表示链接对象
ln -s test.cc test
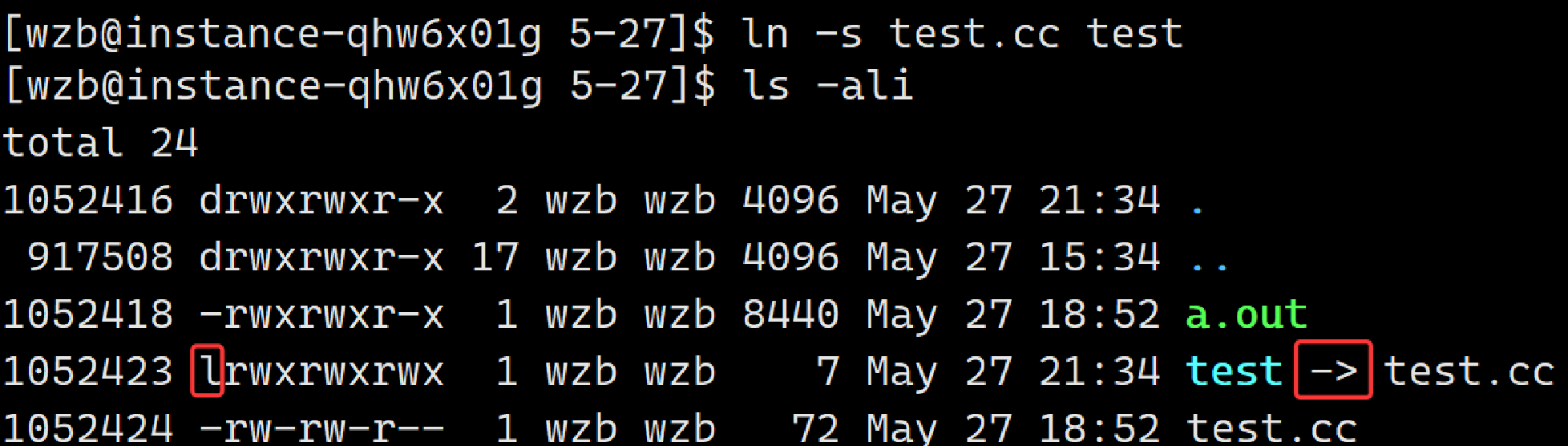
由于文件无后缀所以失去属性,打开文件:
链接后对对象操作相互同步:
在test文件下新增一行,保存退出发现test.cc下已同步。

软链接可以看作为一种"快捷方式",通过访问此快捷方式就可以对原对象操作。作为一个独立的文件(依据:inode不同上图中新链接文件1052423 链接对象:1052424)
同样的对于目录操作也是如此,不同目录下指定进行链接。
悬空链接:
⚠️ 恢复前最重要的第一原则
立刻停止任何写入操作! 包括:不要创建新文件、不要下载东西、不要编辑和保存其他文件、甚至尽量避免在当前目录下执行大型命令。任何写入行为都可能把你想恢复的 test.cc 内容给"覆盖"掉,一旦覆盖,神仙也难救了。
硬链接
创建方式:
ln 文件 目标文件 //软链接去除"-s"的结构
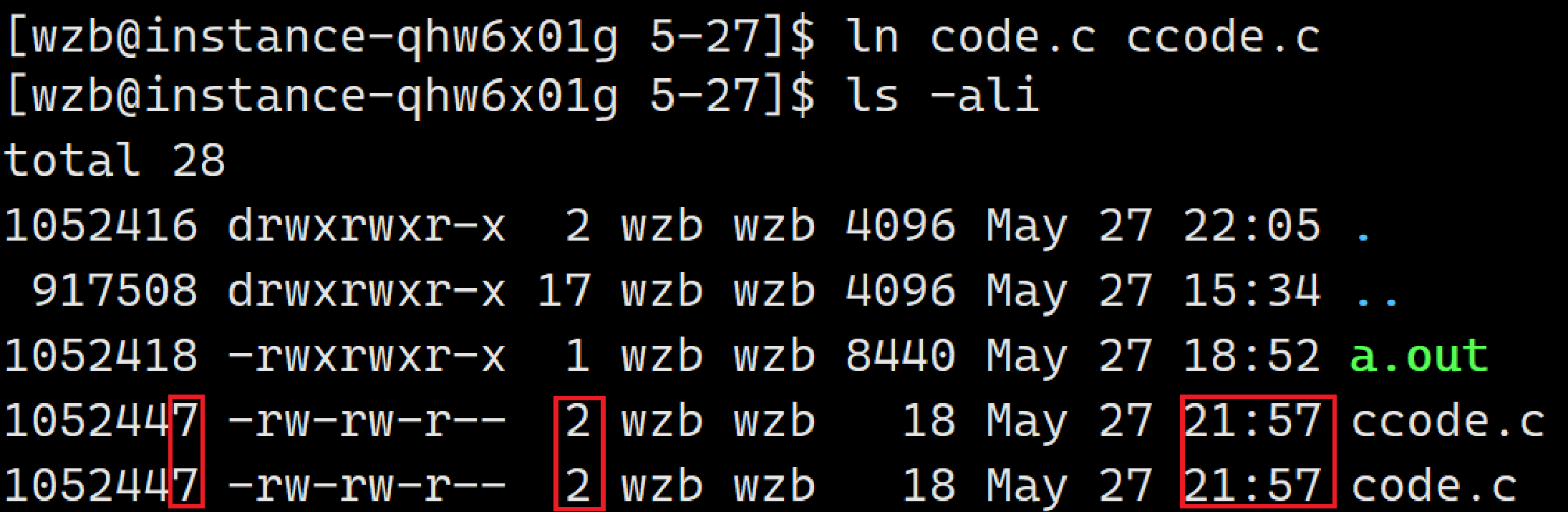
硬链接创建的文件本质上并不是一个独立的文件而是原链接文件的拷贝对象,从"二者inode一致、甚至创建时间都继承自原对象可以看出"。
unlink直接对ccode.c操作:
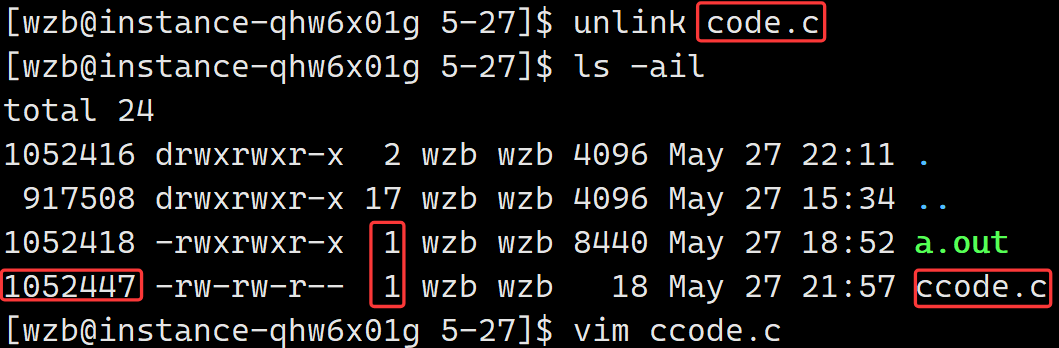
发现inode没有改变,这也符合预期。且"2->1",可以发现若我们再次进行创建链接1--2--3---4渐增,我们有理由推断这其实就是"引用计数"的具体应用。
因此由于硬链接的unlink性质我们常用硬链接作"备份文件"的作用。
为什么不能对目录建立硬链接呢?
易形成"环装链路",当我们再执行文件时由于inode一样。就可能因为查找路径时的多叉树结构而无限循环,因此不允许对目录间建立硬链接。
" . "的引用计数为什么是2?
自己创建时 + " . " == 1 + 1 == 2
感谢观看
求关注
