一、图的存储和遍历
图的存储有两种:邻接矩阵和邻接表:
- 其中,邻接表的存储方式与树的孩子表示法完全一样。因此,用 vector 数组以及链式前向星就能实现。
- 邻接矩阵就是用一个二维数组,其中
edges[i][j]存储顶点i与顶点j之间边的信息。
图的遍历分两种:DFS 和 BFS
1.邻接矩阵
邻接矩阵,是指用一个矩阵 (即二维数组) 存储图中边的信息 (即各个顶点之间的邻接关系),存储顶点之间邻接关系的矩阵称为邻接矩阵。
对于带权图而言,若顶点 v_i 和 v_j 之间有边相连,则邻接矩阵中对应项存放着该边对应的权值,若顶点 v_i 和 v_j 不相连,则用 无穷 来代表这两个顶点之间不存在边。
对于不带权的图,可以创建一个二维的 bool 类型的数组,来标记顶点 v_i 和 v_j 之间有边相连。
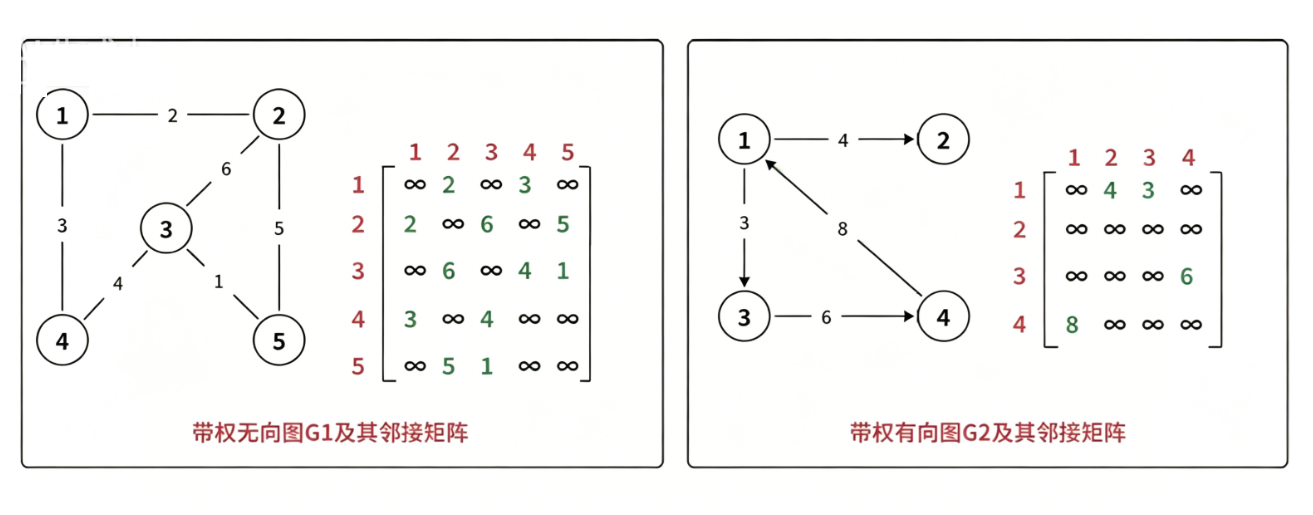
【注意】 矩阵中元素个数为 n * n,即空间复杂度为 O(n^2),n 为顶点个数,和实际边的条数无关,适合存储稠密图。
cpp
#include <iostream>
#include <cstring>
using namespace std;
const int N = 1010;
int n, m;
int edges[N][N];
int main()
{
memset(edges, -1, sizeof edges);
cin >> n >> m; // 读入结点个数以及边的个数
for(int i = 1; i <= m; i++)
{
int a, b, c; cin >> a >> b >> c;
// a - b 有一条边,权值为 c
edges[a][b] = c;
// 如果是无向边,需要反过来再存一下
edges[b][a] = c;
}
return 0;
}2.vector 数组
和树的存储一模一样,只不过如果存在边权的话,我们的 vector 数组里面放一个结构体或者是 pair 即可。
cpp
#include <iostream>
#include <vector>
using namespace std;
typedef pair<int, int> PII;
const int N = 1e5 + 10;
int n, m;
vector<PII> edges[N];
int main()
{
cin >> n >> m; // 读入结点个数以及边的个数
for(int i = 1; i <= m; i++)
{
int a, b, c; cin >> a >> b >> c;
// a 和 b 之间有一条边,权值为 c
edges[a].push_back({b, c});
// 如果是无向边,需要反过来再存一下
edges[b].push_back({a, c});
}
return 0;
}3.用链式前向星的方式存储
cpp
#include <iostream>
#include <queue>
using namespace std;
const int N = 1e5 + 10;
// 链式前向星
int h[N], e[N * 2], ne[N * 2], w[N * 2], id;
int n, m;
// 其实就是把 b 头插到 a 所在的链表后面
void add(int a, int b, int c)
{
id++;
e[id] = b;
w[id] = c; // 多存一个权值信息
ne[id] = h[a];
h[a] = id;
}
bool st[N];
void dfs(int u)
{
cout << u << endl;
st[u] = true;
// 遍历所有的孩子
for(int i = h[u]; i; i = ne[i])
{
// u->v 的一条边
int v = e[i];
if(!st[v])
{
dfs(v);
}
}
}
int main()
{
cin >> n >> m; // 读入结点个数以及边的个数
for(int i = 1; i <= m; i++)
{
int a, b, c; cin >> a >> b >> c;
// a 和 b 之间有一条边,权值为 c
add(a, b, c); add(b, a, c);
}
return 0;
}4.DFS
4.1 用邻接矩阵的方式存储
代码实现:
cpp
#include <iostream>
#include <cstring>
#include <queue>
using namespace std;
const int N = 1010;
int n, m;
int edges[N][N];
bool st[N]; // 标记哪些点已经访问过
void dfs(int u)
{
cout << u << endl;
st[u] = true;
// 遍历所有孩子
for(int v = 1; v <= n; v++)
{
// 如果存在 u->v 的边,并且没有遍历过
if(edges[u][v] != -1 && !st[v])
{
dfs(v);
}
}
}
int main()
{
memset(edges, -1, sizeof edges);
cin >> n >> m; // 读入结点个数以及边的个数
for(int i = 1; i <= m; i++)
{
int a, b, c; cin >> a >> b >> c;
// a - b 有一条边,权值为 c
edges[a][b] = c;
// 如果是无向边,需要反过来再存一下
edges[b][a] = c;
}
return 0;
}4.2 用 vector 数组的方式存储
代码实现:
cpp
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
typedef pair<int, int> PII;
const int N = 1e5 + 10;
int n, m;
vector<PII> edges[N];
bool st[N]; // 标记哪些点已经访问过
void dfs(int u)
{
cout << u << endl;
st[u] = true;
// 遍历所有孩子
for(auto& t : edges[u])
{
// u->v 的一条边,权值为 w
int v = t.first, w = t.second;
if(!st[v])
{
dfs(v);
}
}
}
int main()
{
cin >> n >> m; // 读入结点个数以及边的个数
for(int i = 1; i <= m; i++)
{
int a, b, c; cin >> a >> b >> c;
// a 和 b 之间有一条边,权值为 c
edges[a].push_back({b, c});
// 如果是无向边,需要反过来再存一下
edges[b].push_back({a, c});
}
return 0;
}4.3 用链式前向星的方式存储
代码实现:
cpp
#include <iostream>
#include <queue>
using namespace std;
const int N = 1e5 + 10;
// 链式前向星
int h[N], e[N * 2], ne[N * 2], w[N * 2], id;
int n, m;
// 其实就是把 b 头插到 a 所在的链表后面
void add(int a, int b, int c)
{
id++;
e[id] = b;
w[id] = c; // 多存一个权值信息
ne[id] = h[a];
h[a] = id;
}
bool st[N];
void dfs(int u)
{
cout << u << endl;
st[u] = true;
// 遍历所有的孩子
for(int i = h[u]; i; i = ne[i])
{
// u->v 的一条边
int v = e[i];
if(!st[v])
{
dfs(v);
}
}
}
int main()
{
cin >> n >> m; // 读入结点个数以及边的个数
for(int i = 1; i <= m; i++)
{
int a, b, c; cin >> a >> b >> c;
// a 和 b 之间有一条边,权值为 c
add(a, b, c); add(b, a, c);
}
return 0;
}5.BFS
5.1 用邻接矩阵的方式存储
代码实现:
cpp
#include <iostream>
#include <cstring>
#include <queue>
using namespace std;
const int N = 1010;
int n, m;
int edges[N][N];
bool st[N]; // 标记哪些点已经访问过
void bfs(int u)
{
queue<int> q;
q.push(u);
st[u] = true;
while(q.size())
{
auto a = q.front(); q.pop();
cout << a << endl;
for(int b = 1; b <= n; b++)
{
if(edges[a][b] != -1 && !st[b])
{
q.push(b);
st[b] = true;
}
}
}
}
int main()
{
memset(edges, -1, sizeof edges);
cin >> n >> m; // 读入结点个数以及边的个数
for(int i = 1; i <= m; i++)
{
int a, b, c; cin >> a >> b >> c;
// a - b 有一条边,权值为 c
edges[a][b] = c;
// 如果是无向边,需要反过来再存一下
edges[b][a] = c;
}
return 0;
}5.2 用 vector 数组的方式存储
代码实现:
cpp
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
typedef pair<int, int> PII;
const int N = 1e5 + 10;
int n, m;
vector<PII> edges[N];
bool st[N]; // 标记哪些点已经访问过
void bfs(int u)
{
queue<int> q;
q.push(u);
st[u] = true;
while(q.size())
{
auto a = q.front(); q.pop();
cout << a << endl;
for(auto& t : edges[a])
{
int b = t.first, c = t.second;
if(!st[b])
{
q.push(b);
st[b] = true;
}
}
}
}
int main()
{
cin >> n >> m; // 读入结点个数以及边的个数
for(int i = 1; i <= m; i++)
{
int a, b, c; cin >> a >> b >> c;
// a 和 b 之间有一条边,权值为 c
edges[a].push_back({b, c});
// 如果是无向边,需要反过来再存一下
edges[b].push_back({a, c});
}
return 0;
}5.3 用链式前向星的方式存储
代码实现:
cpp
#include <iostream>
#include <queue>
using namespace std;
const int N = 1e5 + 10;
// 链式前向星
int h[N], e[N * 2], ne[N * 2], w[N * 2], id;
int n, m;
// 其实就是把 b 头插到 a 所在的链表后面
void add(int a, int b, int c)
{
id++;
e[id] = b;
w[id] = c; // 多存一个权值信息
ne[id] = h[a];
h[a] = id;
}
bool st[N];
void bfs(int u)
{
queue<int> q;
q.push(u);
st[u] = true;
while(q.size())
{
auto a = q.front(); q.pop();
cout << a << endl;
for(int i = h[a]; i; i = ne[i])
{
int b = e[i], c = w[i];
if(!st[b])
{
q.push(b);
st[b] = true;
}
}
}
}
int main()
{
cin >> n >> m; // 读入结点个数以及边的个数
for(int i = 1; i <= m; i++)
{
int a, b, c; cin >> a >> b >> c;
// a 和 b 之间有一条边,权值为 c
add(a, b, c); add(b, a, c);
}
return 0;
}二、最小生成树
一个具有 n 个顶点的连通图 ,其生成树为包含 n-1 条边和所有顶点的极小连通子图 。对于生成树来说,若砍去一条边就会使图不连通;若增加一条边就会形成回路。
一个图的生成树可能有多个,将所有生成树中权值之和最小的树称为最小生成树。
构造最小生成树有多种算法,典型的有普利姆(Prim)算法和克鲁斯卡尔(Kruskal)算法两种,它们都是基于贪心的策略。下面讲解算法的具体流程,关于正确性的证明(看《算法导论》)。
模板题
1.Prim 算法
核心:不断加点。
Prim 算法构造最小生成树的基本思想:
- 从任意一个点开始构造最小生成树;
- 将距离该树权值最小且不在树中的顶点,加入到生成树中。然后更新与该点相连的点到生成树的最短距离;
- 重复 2 操作 n 次,直到所有顶点都加入为止。
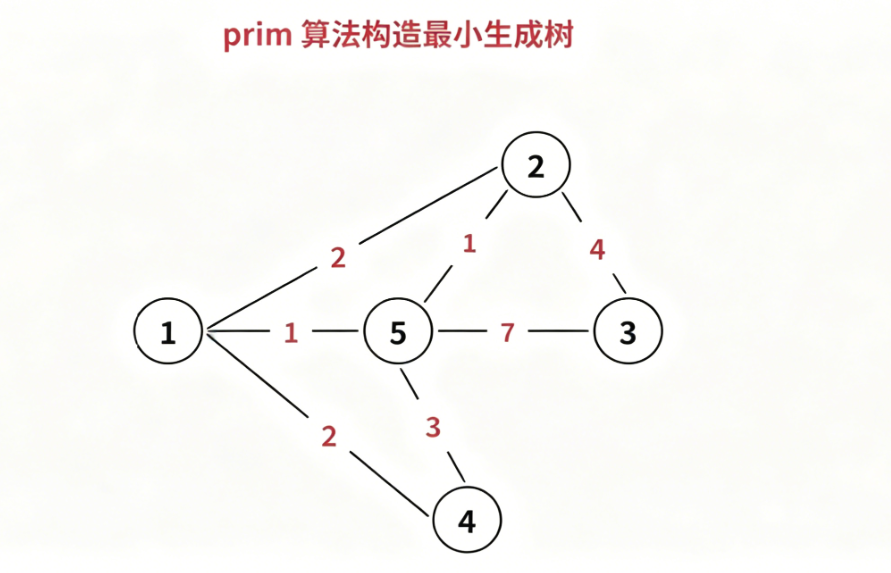
具体流程:
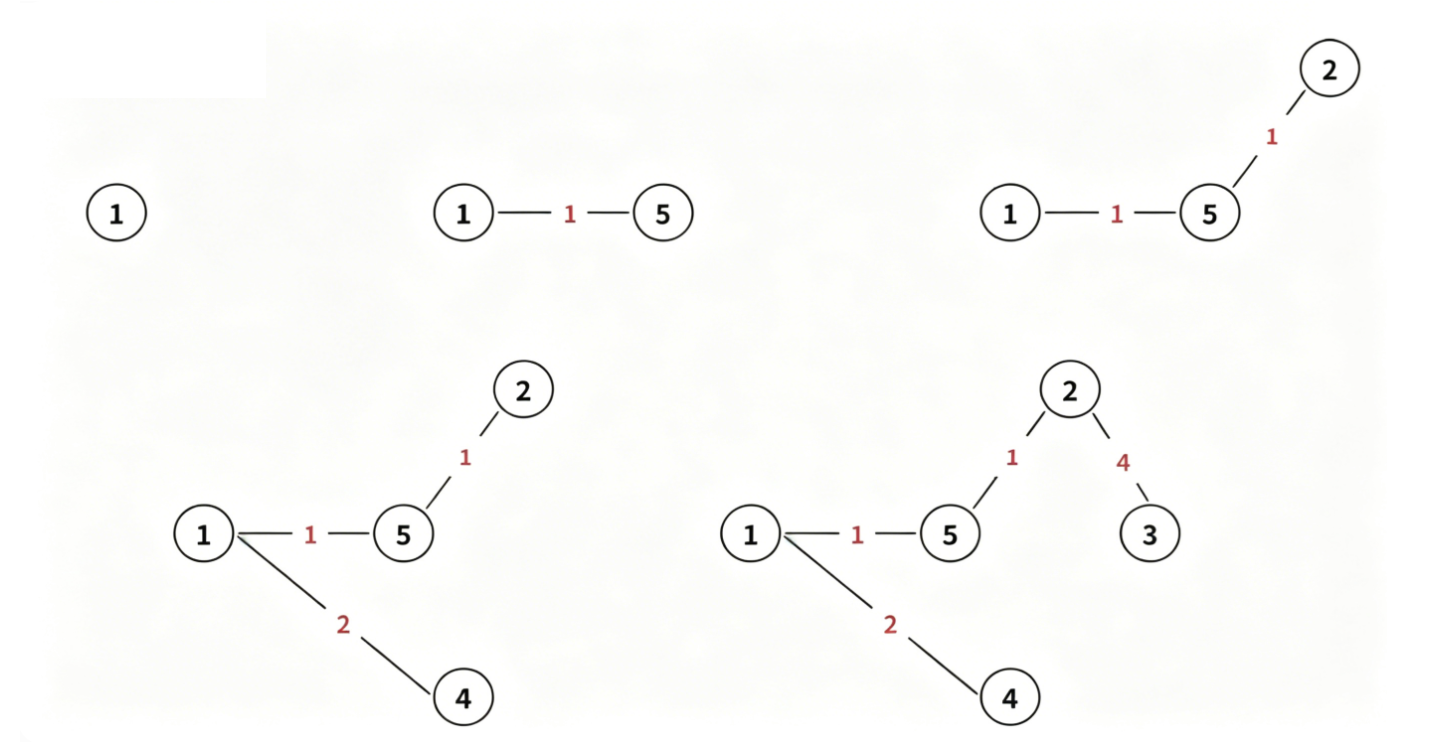
代码实现 - 邻接矩阵:
cpp
#include <iostream>
#include <cstring>
using namespace std;
const int N = 5010, INF = 0x3f3f3f3f;
int n, m;
int edges[N][N]; // 邻接矩阵存储图
int dist[N]; // 某个点距离生成树的最短距离
bool st[N]; // 标记哪些点已经加入到生成树
int prim()
{
// 初始化
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
int ret = 0;
for(int i = 1; i <= n; i++) // 循环加入 n 个点
{
// 1. 找最近点
int t = 0;
for(int j = 1; j <= n; j++)
if(!st[j] && dist[j] < dist[t])
t = j;
// 判断是否联通
if(dist[t] == INF) return INF;
st[t] = true;
ret += dist[t];
// 2. 更新距离
for(int j = 1; j <= n; j++) // 枚举 t 能走到哪
dist[j] = min(dist[j], edges[t][j]);
}
return ret;
}
int main()
{
cin >> n >> m;
// 初始化邻接矩阵
memset(edges, 0x3f, sizeof edges);
for(int i = 1; i <= m; i++)
{
int x, y, z; cin >> x >> y >> z;
// 注意有重边的情况
edges[x][y] = edges[y][x] = min(edges[x][y], z);
}
int ret = prim();
if(ret == INF) cout << "orz" << endl;
else cout << ret << endl;
return 0;
}代码实现 - 邻接表 - vector 数组:
cpp
#include <iostream>
#include <vector>
#include <cstring>
using namespace std;
typedef pair<int, int> PII;
const int N = 5010, INF = 0x3f3f3f3f;
int n, m;
vector<PII> edges[N];
int dist[N];
bool st[N];
int prim()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
int ret = 0;
for(int i = 1; i <= n; i++)
{
// 1. 找最近点
int t = 0;
for(int j = 1; j <= n; j++)
if(!st[j] && dist[j] < dist[t])
t = j;
// 判断是否联通
if(dist[t] == INF) return INF;
st[t] = true;
ret += dist[t];
// 2. 更新距离
for(auto& p : edges[t])
{
int a = p.first, b = p.second;
dist[a] = min(dist[a], b);
}
}
return ret;
}
int main()
{
cin >> n >> m;
for(int i = 1; i <= m; i++)
{
int x, y, z; cin >> x >> y >> z;
// 如果有重边,怎么办?
// 不影响
edges[x].push_back({y, z});
edges[y].push_back({x, z});
}
int ret = prim();
if(ret == INF) cout << "orz" << endl;
else cout << ret << endl;
return 0;
}2.Kruskal 算法
核心:不断加边。
Kruskal 算法构造最小生成树的基本思想:
- 所有边按照权值排序;
- 每次选出权值最小且两端顶点不连通的一条边,直到所有顶点都联通。
代码实现:
cpp
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 5010, M = 2e5 + 10, INF = 0x3f3f3f3f;
int n, m;
struct node
{
int x, y, z;
}a[M];
int fa[N]; // 并查集
bool cmp(node &a, node &b)
{
return a.z < b.z;
}
int find(int x)
{
return x == fa[x] ? fa[x] : fa[x] = find(fa[x]);
}
int kk()
{
sort(a + 1, a + 1 + m, cmp);
int cnt = 0;
int ret = 0;
for(int i = 1; i <= m; i++)
{
int x = a[i].x, y = a[i].y, z = a[i].z;
int fx = find(x), fy = find(y);
if(fx != fy)
{
cnt++;
ret += z;
fa[fx] = fy;
}
}
return cnt == n - 1 ? ret : INF;
}
int main()
{
cin >> n >> m;
for(int i = 1; i <= m; i++) cin >> a[i].x >> a[i].y >> a[i].z;
// 初始化并查集
for(int i = 1; i <= n; i++) fa[i] = i;
int ret = kk();
if(ret == INF) cout << "orz" << endl;
else cout << ret << endl;
return 0;
}