一、参数初始化的意义
在深度学习训练体系中,参数初始化(Weight Initialization) 是极易被忽视、却决定模型能否收敛、收敛速度、精度上限、梯度稳定性 的底层核心。相比于学习率、优化器、正则化等调优手段,初始化是模型训练的起点约束,起点出错,后续所有迭代优化全部无效。
深度神经网络的梯度传播具有累积连乘特性,不当的初始化会直接导致:前向传播激活值饱和、反向传播梯度爆炸/消失、深层网络特征坍塌、模型完全无法收敛。
所有参数初始化算法的迭代演进,本质只围绕一个核心目标:保证深层堆叠网络中,前向传播激活值方差恒定、反向传播梯度方差恒定,全程规避梯度饱和、爆炸、消失问题。
二、理想的初始化策略
目前学术界公认的最优初始化策略,必须同时满足三大守恒约束:
-
前向方差守恒:每层输入、输出特征方差保持一致,避免深层激活值持续放大/缩小,杜绝激活饱和、特征湮灭;
-
反向方差守恒:梯度反向传播时,每层梯度方差稳定,无指数级衰减/放大,彻底解决梯度消失与梯度爆炸;
-
零均值分布:参数分布中心化,规避层间特征偏移,加速模型收敛,减少梯度更新震荡。
补充基础公式:单层神经网络线性变换
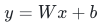
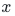 为上一层输出,
为上一层输出,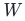 为权重矩阵,
为权重矩阵,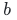 为偏置,
为偏置,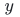 为本层预激活值。所有方差推导均基于该基础模型。
为本层预激活值。所有方差推导均基于该基础模型。
三、错误初始化方式介绍
先拆解三类经典错误初始化,从数学层面解释为什么不能用,根治训练底层问题。
3.1 全零/全常数初始化(生产完全不可用)
3.1.1 现象
所有权重初始化为0或固定常数,训练后所有神经元输出完全一致,梯度完全一致,参数永远同质化更新。
3.1.2 数学根源:对称失效
神经网络核心是神经元差异化特征提取 。若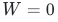 ,则所有神经元预激活值相同,反向传播梯度完全一致,所有参数同步更新,永远无法学习差异化特征,网络等价于单神经元,表征能力彻底坍塌。
,则所有神经元预激活值相同,反向传播梯度完全一致,所有参数同步更新,永远无法学习差异化特征,网络等价于单神经元,表征能力彻底坍塌。
特例 :偏置 可以初始化为0,仅权重禁止全零初始化。
可以初始化为0,仅权重禁止全零初始化。
3.2 超大随机初始化
1权重取值过大,前向传播时预激活值极度离散,经过Sigmoid/Tanh直接落入梯度饱和区,梯度趋近于0,参数停止更新;同时深层叠加会导致激活值指数爆炸,数值溢出。
3.3 极小随机初始化
权重取值过小,多层叠加后激活值无限趋近于0,有效特征被湮灭,反向传播梯度无限衰减,深层参数完全无法更新,出现严重梯度消失。
四、经典初始化算法推导
4.1 朴素随机初始化(Random Normal/Uniform)
4.1.1 原理
从固定方差的均匀分布/正态分布中随机采样权重,是最原始的初始化方式:
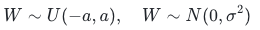
4.1.2 缺陷
无自适应方差约束,无法适配不同网络层数、不同激活函数,深层网络必然出现方差漂移,仅适用于浅层网络,深度模型彻底弃用。
4.2 Xavier/Glorot初始化---对称激活适用
定位 :专为Sigmoid、Tanh等中心对称饱和激活函数设计,首个实现前向/反向方差双守恒的初始化算法。
4.2.1 核心推导逻辑
设输入维度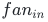 (输入神经元数),输出维度
(输入神经元数),输出维度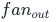 (输出神经元数)。
(输出神经元数)。
1)前向传播守恒要求: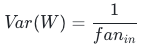
2)反向传播守恒要求: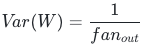
二者无法同时严格满足,Xavier采用调和平均折中,保证双向方差近似守恒:
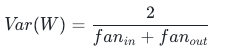
4.2.2 两种实现形式
正态分布 Xavier:
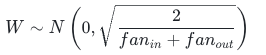
均匀分布 Xavier:
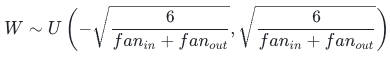
4.2.3 缺陷
无法适配ReLU系列激活函数。ReLU会截断负区间特征,导致输出方差直接减半,Xavier的方差守恒约束被打破,深层网络依然会出现梯度消失。
4.3 He/Kaiming初始化---ReLU最优解
定位 :何恺明团队提出,专门解决Xavier对ReLU系列激活失效的问题,是ReLU/LeakyReLU/PReLU网络的1标准初始化。
4.3.1 缺陷溯源
ReLU激活后输出方差仅为输入的1/2,Xavier无该补偿机制,导致逐层方差衰减,深层特征消失。He初始化引入ReLU方差补偿系数2,重新实现方差守恒。
4.3.2 数学公式
基于输入维度的标准版(前向稳定):
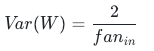
正态分布 He:
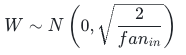
均匀分布 He:
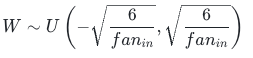
4.3.3 优势
完美补偿ReLU负区间截断带来的方差损失,深层网络前向、反向梯度全程稳定,无方差漂移,是现代CNN、残差网络的默认初始化方案。
4.4 正交初始化(Orthogonal Initialization)
定位 :专为深层循环网络、Transformer、超深残差网络设计,解决多层叠加后的梯度相关性衰减问题。
4.4.1 原理
将权重矩阵初始化为正交矩阵 ,满足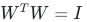 。正交矩阵可保证线性变换过程中向量模长不变,彻底杜绝多层叠加后的梯度衰减与爆炸,完美保留特征信息。
。正交矩阵可保证线性变换过程中向量模长不变,彻底杜绝多层叠加后的梯度衰减与爆炸,完美保留特征信息。
4.4.2 适用场景
RNN、LSTM、GRU、Transformer注意力权重、超深残差网络,是时序模型与大模型底层权重的常用初始化方案。
4.5 截断正态初始化(Truncated Normal)
基于正态分布采样,截断超出±2σ的极端值,避免权重极值导致的激活饱和与梯度异常,广泛用于ResNet、MobileNet等轻量化CV模型,兼顾随机性与稳定性。
五、大模型时代专属初始化(GPT/LLaMA/Transformer核心)
传统Xavier/He初始化无法适配超大深度、超大参数量、归一化前置的大模型架构,因此衍生出专属初始化策略,是大模型训练收敛的核心关键。
5.1 LLaMA 缩放初始化(Layer-wise Scaling)
核心痛点:大模型层数过深,即使单层方差守恒,多层微小误差累积也会导致特征方差漂移。
解决方案:对每一层权重额外增加层数缩放系数:
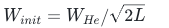
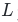 为网络总层数,通过逐层缩放抵消深层累积方差误差,是LLaMA系列模型收敛的核心优化。
为网络总层数,通过逐层缩放抵消深层累积方差误差,是LLaMA系列模型收敛的核心优化。
5.2 GPT 初始化策略
GPT系列采用改良正交初始化+残差缩放:对残差分支权重做0.1倍缩放,避免残差叠加后激活值爆炸,适配Transformer残差架构特性。
5.3 RMS归一化适配初始化
针对大模型常用的RMSNorm(无均值归一化),初始化权重采用零均值、小方差分布,规避均值偏移问题,适配前置归一化架构。
六、特殊网络层初始化
通用权重初始化不能直接套用在特殊层,错误初始化会直接导致模型不收敛。
6.1 偏置Bias初始化
-
全连接层、卷积层:固定初始化为0,无任何负面影响,不破坏方差守恒;
-
Sigmoid二分类输出层:可初始化为小正值,避免初始输出概率过低;
-
ReLU网络Bias严禁大值初始化,极易引发神经元死亡。
6.2 Embedding词嵌入层
采用**正态分布初始化N(0,0.01)**或Xavier初始化,权重幅值不宜过大,保证初始词向量分布均匀,不破坏语义空间分布。
6.3 BN层初始化
-
缩放系数
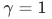 ;
; -
偏移系数
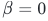 ;
; -
保证初始状态下归一化不破坏原始特征分布。
6.4 Transformer专属初始化
-
QKV投影层:He/GELU适配初始化;
-
位置编码:小方差随机初始化或固定正弦编码;
-
FeedForward层:大模型缩放初始化。
七、PyTorch 初始化代码演示
python
import torch
import torch.nn as nn
import math
def init_weights_standard(model: nn.Module, layer_num: int = 1):
"""
深度学习通用权重初始化工具
:param model: 网络模型
:param layer_num: 网络总层数(大模型缩放用)
"""
for name, m in model.named_modules():
# 卷积层、全连接层初始化
if isinstance(m, (nn.Conv2d, nn.Linear)):
# 默认He初始化(适配ReLU系列)
nn.init.kaiming_normal_(m.weight, mode='fan_in', nonlinearity='relu')
# 大模型逐层缩放适配
if layer_num > 10:
m.weight.data /= math.sqrt(2 * layer_num)
# 偏置初始化为0
if m.bias is not None:
nn.init.constant_(m.bias, 0)
# Embedding层初始化
elif isinstance(m, nn.Embedding):
nn.init.normal_(m.weight, mean=0.0, std=0.01)
# BN层初始化
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1.0)
nn.init.constant_(m.bias, 0.0)
# 正交初始化(时序/Transformer层)
elif isinstance(m, nn.LSTM) or isinstance(m, nn.GRU):
for param in m.parameters():
if len(param.shape) >= 2:
nn.init.orthogonal_(param)
# 单独调用各类初始化方式
if __name__ == "__main__":
# 模拟单层全连接层
linear = nn.Linear(512, 256)
# 1. Xavier初始化(Sigmoid/Tanh专用)
nn.init.xavier_normal_(linear.weight)
# 2. He初始化(ReLU专用)
nn.init.kaiming_normal_(linear.weight, mode='fan_in', nonlinearity='relu')
# 3. 正交初始化
nn.init.orthogonal_(linear.weight)
# 4. 零偏置初始化
nn.init.constant_(linear.bias, 0)
print("权重均值:", linear.weight.mean().item())
print("权重方差:", linear.weight.var().item())八、全系初始化方法横向硬核对比表
| 初始化方式 | 核心原理 | 适配激活函数 | 适配网络 | 核心优缺点 |
|---|---|---|---|---|
| 全零初始化 | 参数统一置0 | 全部不适配 | 无 | 神经元对称坍塌,彻底不可用 |
| 朴素随机初始化 | 固定方差随机采样 | 浅层网络通用 | 浅层网络 | 无方差守恒,深层必然梯度异常 |
| Xavier初始化 | 双向方差折中守恒 | Sigmoid/Tanh | 传统浅层CNN、RNN | 对称激活最优,ReLU完全失效 |
| He初始化 | ReLU方差补偿守恒 | ReLU/LeakyReLU/PReLU | 现代CNN、残差网络 | 深度网络最优,精度与稳定性兼顾 |
| 正交初始化 | 正交矩阵保模长 | 通用 | Transformer、时序网络 | 梯度无衰减,适配超深网络 |
| 大模型缩放初始化 | 逐层抵消累积误差 | GELU/Swish | LLaMA/GPT/Transformer | 解决深层累积漂移,大模型专属 |
九、生产选型指南
9.1 计算机视觉CV任务
-
传统CNN、ResNet、分类检测模型(ReLU):He初始化
-
老式浅层网络(Tanh/Sigmoid):Xavier初始化
-
视觉Transformer(ViT/Swin):正交初始化+缩放修正
-
轻量化移动端模型:截断正态初始化
9.2 NLP与大模型任务
-
常规文本模型:Xavier/正交初始化
-
GPT/LLaMA大模型:逐层缩放初始化
-
Embedding层:小方差正态初始化
-
时序RNN系列:正交初始化
9.3 通用规则
-
只要激活函数是ReLU系列,优先He初始化,绝对不使用Xavier;
-
只要是Sigmoid/Tanh对称激活,优先Xavier;
-
超深网络、大模型必须叠加逐层缩放修正;
-
所有层偏置默认0初始化,BN层固定1、0初始化。
十、初始化导致的问题介绍
-
模型完全不收敛、loss恒定:大概率初始化方差过大,激活饱和梯度为0;
-
深层网络梯度消失:ReLU网络误用Xavier初始化,方差逐层衰减;
-
训练震荡剧烈、不收敛:权重幅值过大,梯度更新爆炸;
-
所有神经元输出一致:存在全零初始化或对称权重未打破;
-
大模型预训练崩溃:未做逐层缩放,深层方差累积漂移。
1. 为什么ReLU网络不能用Xavier初始化?
Xavier基于对称激活函数零均值特性推导,ReLU会截断负区间,输出方差直接减半,打破方差守恒约束,多层叠加后特征方差持续衰减,最终导致深层梯度消失。He初始化额外引入2倍补偿系数,完美适配ReLU特性。
2. 正交初始化的核心优势是什么?
正交矩阵线性变换不改变向量模长,多层叠加后不会出现梯度衰减或爆炸,完美解决超深网络、时序网络的梯度累积问题,是Transformer与RNN的最优初始化方案。
3. 大模型为什么需要逐层缩放初始化?
传统初始化仅保证单层方差守恒,大模型层数极深,微小的单层方差误差会逐层累积,最终导致激活值漂移、训练崩溃。逐层缩放可抵消累积误差,保证全程梯度稳定。
参数初始化的迭代史,本质是方差守恒约束的精准适配史。从最初的随机初始化、全零初始化的野蛮生长,到Xavier解决对称激活方差问题,He初始化适配ReLU非线性截断特性,正交初始化解决深层梯度累积问题,最终迭代出大模型专属的逐层缩放初始化。