1.作者介绍
李思蓉,女,西安工程大学电子信息学院,2025级研究生
研究方向:玻璃纤维低介电布表面缺陷视觉检测及分类算法研究
电子邮件:++++1332457612@qq.com++++
董柯帆,男,西安工程大学电子信息学院,2025级研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:867068473@qq.com
2 算法介绍
2.1 随机森林算法介绍
随机森林是一种集成学习(Ensemble Learning)算法,它通过构建多棵决策树(Decision Trees)并将它们的预测结果结合起来,从而获得更准确、更稳定的分类结果。它的原理类似于"三个臭皮匠,顶个诸葛亮"。由于单棵决策树容易过拟合,因此随机森林通过引入随机数据和特征让森林中的每棵树都有所不同,最后通过少数服从多数的投票制决定最终分类。核心机制主要有三个:第一,自助采样法,从原始数据中有放回地抽取样本,为每棵树创建一个独立的子训练集;第二,特征随机性,在分裂节点时,不是从所有特征中选最优,而是随机选取一部分特征进行评估;第三,众数投票,预测时,所有树各自给出结果,森林选择出现次数最多的类别。
随机森林算法用于红酒品质分类的完整过程,如图1所示,首先输入红酒理化指标数据,模型通过多棵基于不同样本与特征训练的独立决策树并行预测,各树输出独立分类结果后,采用投票汇总的方式,按少数服从多数规则得到最终预测,本实验中判定该红酒为优质酒(类别2)。
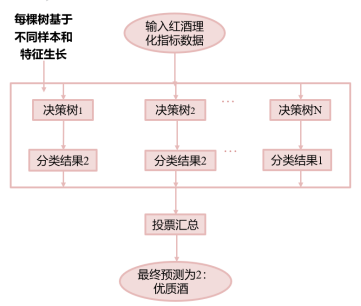
图1 随机森林算法流程示意图

图2 随机森林算法伪代码
该伪代码描述了一种基于随机森林的红酒品质三分类算法流程,如图2所示,首先对含理化特征与品质评分的红酒数据集进行预处理,将品质评分映射为一般、良好、优质三类标签,并按8:2划分为训练集与测试集;随后在训练阶段通过Bootstrap有放回抽样和随机特征子集选择,并行构建100棵独立决策树组成随机森林;最后在预测阶段对测试集样本采用多数投票规则输出分类结果,并计算准确率、混淆矩阵等评估指标,最终返回训练完成的模型与评估结果。
2.2 决策树算法介绍
由于随机森林是由多个决策树集成的,因此决策树的算法至关重要。图3展示了基于基尼指数的CART分类决策树构建流程,算法从输入当前节点数据集与可用特征集开始,首先计算节点基尼不纯度并检查停止分裂条件,若满足条件则生成叶子节点并标记类别;若不满足,则初始化最优分裂参数,遍历所有特征与切分点,对每个划分方案计算加权基尼指数,筛选出基尼指数最小的最优特征与切分点,随后依据最优方案将节点分裂为左右子节点,并对子节点递归执行上述流程,直至所有节点均满足停止分裂条件,完成整棵决策树的构建。
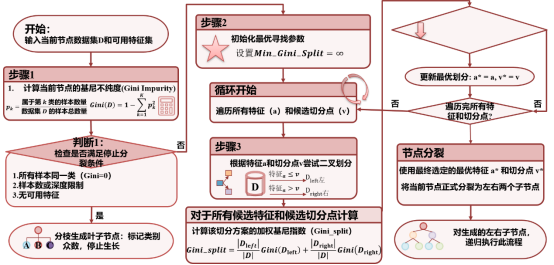
图3 基于基尼指数的CART分类决策树计算步骤
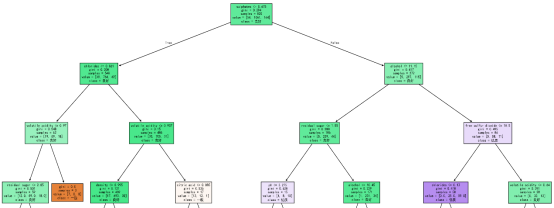
图4 程序里随机森林中的第一个决策树(前三层)可视化图
图4为红酒品质分类任务中一棵CART决策树的可视化结果,整棵树共包含820个训练样本,构建以基尼指数为分裂依据,以硫酸盐(sulphates≤0.675)作为根节点特征(基尼系数为0.294,节点内一般,良好,优质样本分布为54,1061,164,预测类别为"良好"),后续通过氯化物(chlorides≤0.061)、酒精度(alcohol≤11.15)、挥发性酸度(volatile acidity≤0.97)、游离二氧化硫(free sulfur dioxide≤18.5)等理化指标的阈值条件递归分裂,最终将样本划分为一般、良好、优质三类;节点内的基尼系数、样本数、类别分布与预测标签直观呈现了各分裂节点的数据纯度与分类逻辑,其中左下角的橙色节点基尼不纯度为0,代表该节点内的3个样本全部为"一般"品质,数据完全纯净,无需进一步分裂即可直接输出分类结果;整体来看,硫酸盐、酒精度、游离二氧化硫等指标是区分红酒品质的关键特征,同时也反映出训练集中"良好"品质样本占比最高、优质红酒需多指标协同达标等数据分布特点,为红酒品质分类提供了可解释的决策依据。
3. 实验过程
3.1 数据集介绍
本研究使用来源于UCI机器学习存储库的Wine Quality Data Set(红葡萄酒质量数据集),发布于2009年。该数据集的样本数量为1599个样本,主要为11个理化特征(如表1所示)和1个质量分(3-8分的标签),在本次研究中将该数据集分为三类,分别为3-4分(一般)、4-5分(良好)、7-8分(优质酒)。
表1 数据集中11个理化特征
|----------------------|--------|
| fixed acidity | 固定酸度 |
| volatile acidity | 挥发性酸度 |
| citric acid | 柠檬酸 |
| residual sugar | 残留糖分 |
| chlorides | 氯化物 |
| free sulfur dioxide | 游离二氧化硫 |
| total sulfur dioxide | 总二氧化硫 |
| density | 密度 |
| pH | 酸碱度 |
| sulphates | 硫酸盐 |
| alcohol | 酒精含量 |
3.2 代码实现
本次实验系统选用Windows11 64位;软件环境的核心语言为Python3.9.23,使用VS Code作为开发IDE,借助Anaconda3管理环境,同时配置numpy、pandas、scikitlearn、matplotlib、seaborn、imbalancedlearn、joblib等指定版本及以上的第三方库开展实验,具体实验硬件条件和环境配置如表2、3所示。
表2 实验硬件条件
|--------------|-----------------------------------------|
| 硬件组件 | 配置详情 |
| 处理器(CPU) | 英特尔酷睿 i5/i7或AMD锐龙 5/7 |
| 内存 (RAM) | 16GB/32GB DDR4 |
| 硬盘(存储) | 512GB/1TB SSD(SSD硬盘) |
| 显卡(GPU) | NVIDIA GeForce GTX/RTX 系列 |
| 操作系统 | Windows 10/11 64位或Ubuntu 20.04+ (Linux) |
表3 实验环境配置
|--------------------------|-----------------------------------|
| 软件/环境组件 | 版本/类型详情 |
| 核心程序语言 | Python 3.9.x / 3.10.x / 3.11.x 系列 |
| 开发环境(IDE) | VS Code 或 PyCharm |
| 环境与包管理器 | Anaconda / Miniconda 4.x+ (任选) |
| 核心计算库(numpy) | 1.21.0及以上版本 |
| 数据处理库(pandas) | 1.3.0及以上版本 |
| 机器学习库 (scikit-learn) | 1.0.0及以上版本 |
| 数据可视化库(matplotlib) | 3.4.0及以上版本 |
| 统计可视化库(seaborn) | 0.11.0及以上版本 |
| 不平衡学习库(imbalanced-learn) | 0.8.0及以上版本 |
| 模型序列化库(joblib) | 1.1.0及以上版本 |
训练代码的关键部分与注释如下:
python
质量等级分类映射
def categorize_quality(quality):
"""将质量评分转换为三分类"""
if quality in [3, 4]:
return 0 # 一般
elif quality in [5, 6]:
return 1 # 良好
else: # 7, 8
return 2 # 优质
数据集划分
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print(f"\n数据划分:")
print(f" 训练集: {X_train.shape[0]} 样本")
print(f" 测试集: {X_test.shape[0]} 样本")
随机森林模型训练与保存
def train_random_forest(X_train, y_train, n_estimators=100, random_state=42):
"""训练随机森林模型"""
print("\n" + "=" * 60)
print("训练随机森林模型")
print("=" * 60)
rf = RandomForestClassifier(
n_estimators=n_estimators,
random_state=random_state,
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
n_jobs=-1
)
rf.fit(X_train, y_train)
print(f"随机森林训练完成")
print(f" 树的数量: {n_estimators}")
print(f" 特征数量: {X_train.shape[1]}")
return rf
模型预测与评估
def evaluate_model(rf, X_test, y_test, feature_names):
"""评估模型性能"""
print("\n" + "=" * 60)
print("模型评估指标")
print("=" * 60)
# 预测
y_pred = rf.predict(X_test)
# 准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"\n整体准确率: {accuracy:.4f} ({accuracy*100:.2f}%)")
# 详细分类指标
print("\n分类详细指标:")
print("-" * 60)
report = classification_report(
y_test, y_pred,
target_names=['一般(3-4)', '良好(5-6)', '优质(7-8)'],
digits=4
)
print(report)
# 计算每类的精确率、召回率、F1分数
precision, recall, f1, support = precision_recall_fscore_support(
y_test, y_pred, average=None
)
print("\n各类别指标汇总:")
print("-" * 60)
for i, category in enumerate(['一般(3-4)', '良好(5-6)', '优质(7-8)']):
print(f"{category}:")
print(f" 精确率 (Precision): {precision[i]:.4f}")
print(f" 召回率 (Recall): {recall[i]:.4f}")
print(f" F1分数 (F1-Score): {f1[i]:.4f}")
print(f" 样本数 (Support): {support[i]}")
print()
return y_pred, accuracy
预测分类代码的关键部分与注释如下:
模型加载
# 加载训练好的模型
model_path = r'D:\AI\Random Forest\random_forest_model_smote.pkl'
with open(model_path, 'rb') as f:
rf = pickle.load(f)
新数据读取与预处理
# 读取新数据(不包含quality列)
new_data_path = r'D:\AI\Random Forest\new_wine_samples.csv'
df_new = pd.read_csv(new_data_path, sep=';')
print(f"\n新数据形状: {df_new.shape}")
print(f"特征列: {list(df_new.columns)}")
print("\n注意:新数据不包含'quality'列(这正是我们需要预测的)")
# 准备特征(全部列都是特征)
X_new = df_new.values
预测执行与结果打印
# 进行预测
y_pred = rf.predict(X_new)
y_pred_proba = rf.predict_proba(X_new)
# 类别名称
category_names = {0: '一般(3-4)', 1: '良好(5-6)', 2: '优质(7-8)'}
# 输出预测结果
print("\n" + "=" * 60)
print("预测结果")
print("=" * 60)
for i in range(len(y_pred)):
pred_class = y_pred[i]
prob = y_pred_proba[i]
confidence = np.max(prob)
print(f"\n样本 {i+1}:")
print(f" 预测质量等级: {category_names[pred_class]}")
print(f" 置信度: {confidence:.4f} ({confidence*100:.2f}%)")
print(f" 各类别概率:")
for j, cat in enumerate(['一般', '良好', '优质']):
print(f" {cat}: {prob[j]:.4f} ({prob[j]*100:.2f}%)")
# 统计预测结果
print("\n" + "=" * 60)
print("预测结果统计")
print("=" * 60)
unique, counts = np.unique(y_pred, return_counts=True)
for idx, count in zip(unique, counts):
print(f" {category_names[idx]}: {count} 样本 ({count/len(y_pred)*100:.1f}%)")
结果保存
# 保存预测结果
results = pd.DataFrame({
'sample_id': range(1, len(y_pred) + 1),
'predicted_class': [category_names[p] for p in y_pred],
'confidence': np.max(y_pred_proba, axis=1)
})
# 添加各类别概率
for i, cat in enumerate(['prob_一般', 'prob_良好', 'prob_优质']):
results[cat] = y_pred_proba[:, i]
output_path = r'D:\AI\Random Forest\new_samples_prediction_results.csv'
results.to_csv(output_path, index=False, encoding='utf-8-sig')
print(f"\n预测结果已保存到: {output_path}")3.3 结果分析
该实验基于包含1599条样本、11个理化特征的红酒数据集开展,如图5所示,将原始品质评分合并为"一般""良好""优质"三类,按8:2划分为1279条训练集与320条测试集,构建含100棵决策树的随机森林模型;模型整体准确率达88.75%,但受类别分布不均衡影响,各类别表现差异显著。占比82.5%的"良好"类样本识别效果优异,精确率90.14%、召回率96.97%、F1分数93.43%;占比13.6%的"优质"类样本表现中等,F1分数为70.89%;而仅占3.9%的"一般"类样本则因训练样本不足,精确率、召回率与F1分数均为0,模型完全无法识别,宏平均F1分数仅54.77%,反映出模型对少数类的识别能力存在明显短板,整体性能受多数类主导,后续可通过采样或类别权重调整优化模型的均衡识别能力。
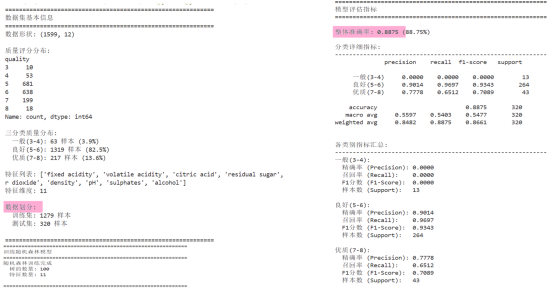
图5 训练打印结果
混淆矩阵热力图直观呈现了随机森林模型的分类表现,如图6所示,模型对测试集中占比最高的"良好"品质样本识别效果优异,264个样本中256个被正确预测,仅8个误判为"优质";但受类别不平衡影响,模型对少数类识别能力不足,13个"一般"品质样本全部被误判为"良好",43个"优质"品质样本中有15个被误判为"良好",存在明显偏向多数类的偏差;右侧特征重要性排序则显示,酒精度是影响红酒品质分类的最关键特征,其次为挥发性酸度和硫酸盐,pH值、游离二氧化硫等特征贡献度相对较低,为后续模型优化与红酒品质分析提供了明确的特征优先级参考。
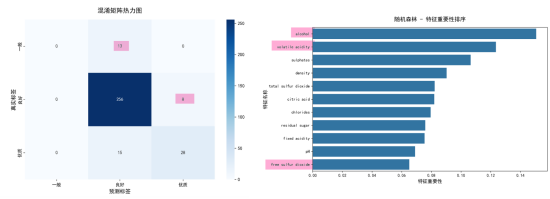
图6 训练模型的混淆矩阵和特征重要性排序
在进行基于随机森林的红酒质量等级预测分类时,新构建的数据集总共6个,每个数据集只有11个理化特征,如图7所示。
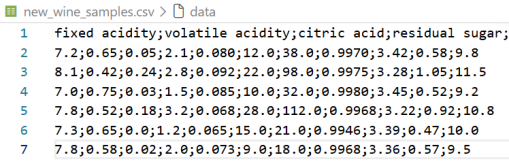
图7 新构建的数据集
最终预测结展示了随机森林模型对6个红酒样本的分类表现,如图8所示,其中4个样本被预测为"良好"品质、2个被预测为"优质"品质,无样本被预测为"一般"品质,与训练集的类别分布高度一致;样本1、5、6的预测置信度较,类别概率分布差异显著,模型判断清晰;而样本2、3、4的置信度仅为50%-55%,类别概率分布接近,模型对这类边界样本的判断存在明显犹豫,易出现混淆;整体来看,模型对区分度较高的样本识别效果稳定,但受类别不平衡影响,无法识别"一般"类样本,且对边界样本的置信度不足,实际应用中需对低置信度结果进行复核,并优化少数类样本的识别能力。

图8 预测结果
3.4 问题与分析
问题:由于"一般(3-4)"类别仅占总样本的3.9%,大多数类与少数类样本比高达20:9:1。随机森林的分割标准倾向于优化整体准确率而忽略少数类实验模式,导致难以学习有效的决策边界。尽管模型验证,整体准确率达到88.75%,但对"一般"类别的识别完全失效,类别指标最高0,如表4所示,因此本研究采用SMOTE处理类别不平衡数据的问题。
表4 类别不平衡导致的结果
|---------|----------------|----------------|----------------|-----|
| 类别 | 精确率 | 召回率 | F1 分数 | 样本数 |
| 一般 (34) | 0.0000 | 0.0000 | 0.0000 | 13 |
| 良好 (56) | 0.9014 | 0.9697 | 0.9343 | 264 |
| 优质 (78) | 0.7778 | 0.6512 | 0.7089 | 43 |
解决方法:利用SMOTE在特征空间中,对极少数样本进行采样k个最近邻样本进行线性插值,从而生成全新的非重复合成样本以改善类别分配。如图9所示,该伪代码描述了多分类SMOTE算法的完整流程,旨在通过过采样解决多分类任务中的类别不平衡问题:算法以原始特征矩阵X、目标标签向量y及近邻数k(默认值为5)为输入,首先统计各类别样本数量,将样本数最多的多数类规模maj_N设为少数类的补齐目标,并初始化合成样本存储空间;随后遍历每个少数类标签,提取该类所有原始样本并计算需合成的样本数量,通过循环生成新样本:先从当前少数类中随机选取根样本x,再从其k个同类近邻中随机选取一个近邻样本x_neigh,生成0到1之间的随机插值因子λ,通过核心公式x_new=x+λ×(x_neigh-x)线性插值生成新的特征向量,将新样本特征与对应标签存入合成样本列表,直至少数类样本数与多数类持平;最后将原始数据与所有合成样本合并,输出类别平衡后的数据集(X_bal,y_bal),为后续模型训练提供均衡的数据基础。

图9 SMOTE算法伪代码
本研究采用SMOTE过采样算法对不平衡红酒品质数据集进行处理,如图10所示,过采样前,训练集中"一般""良好""优质"三类样本数分别为50、1055、174,类别分布严重失衡,模型对"一般"类样本的精确率与召回率均为0.00%,完全无法识别少数类;经SMOTE过采样后,三类样本数均被平衡至1055个,训练集规模由1279条扩展至3165条,新增合成样本1886条,有效消除了类别不平衡问题;对比实验结果表明,过采样后模型对"一般"类样本的精确率提升至33.33%、召回率提升至38.46%,实现了对少数类样本的有效识别,证明SMOTE算法能够显著改善模型在不平衡数据上的偏置问题,提升多分类任务中少数类样本的识别性能。
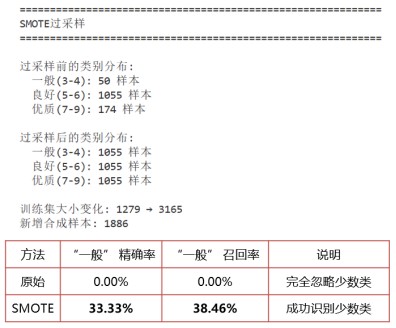
图10 在训练模型中加入SMOTE后的结果
4. 代码附录
wine_quality_rf_train .py
python
"""
基于随机森林的红酒质量等级预测 - 训练代码
将quality分为三类:3-4一般,5-6良好,7-8优质
"""
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import (accuracy_score, classification_report,
confusion_matrix, precision_recall_fscore_support)
from sklearn.tree import plot_tree
import warnings
warnings.filterwarnings('ignore')
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
def categorize_quality(quality):
"""将质量评分转换为三分类"""
if quality in [3, 4]:
return 0 # 一般
elif quality in [5, 6]:
return 1 # 良好
else: # 7, 8
return 2 # 优质
def load_and_preprocess_data(filepath):
"""加载和预处理数据"""
# 读取分号分隔的CSV文件
df = pd.read_csv(filepath, sep=';')
print("=" * 60)
print("数据集基本信息")
print("=" * 60)
print(f"数据形状: {df.shape}")
print(f"\n质量评分分布:")
print(df['quality'].value_counts().sort_index())
# 转换质量等级
df['quality_category'] = df['quality'].apply(categorize_quality)
# 统计三分类分布
category_names = ['一般(3-4)', '良好(5-6)', '优质(7-8)']
print(f"\n三分类质量分布:")
for i, name in enumerate(category_names):
count = (df['quality_category'] == i).sum()
print(f" {name}: {count} 样本 ({count/len(df)*100:.1f}%)")
# 准备特征和目标
X = df.drop(['quality', 'quality_category'], axis=1)
y = df['quality_category']
print(f"\n特征列表: {list(X.columns)}")
print(f"特征维度: {X.shape[1]}")
return X, y, df
def train_random_forest(X_train, y_train, n_estimators=100, random_state=42):
"""训练随机森林模型"""
print("\n" + "=" * 60)
print("训练随机森林模型")
print("=" * 60)
rf = RandomForestClassifier(
n_estimators=n_estimators,
random_state=random_state,
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
n_jobs=-1
)
rf.fit(X_train, y_train)
print(f"随机森林训练完成")
print(f" 树的数量: {n_estimators}")
print(f" 特征数量: {X_train.shape[1]}")
return rf
def visualize_decision_tree(rf, feature_names, tree_index=0):
"""可视化其中一棵决策树"""
print("\n" + "=" * 60)
print(f"决策树可视化 (第{tree_index+1}棵树)")
print("=" * 60)
# 获取指定索引的决策树
tree = rf.estimators_[tree_index]
# 创建图形
fig, ax = plt.subplots(figsize=(20, 10))
plot_tree(tree,
feature_names=feature_names,
class_names=['一般', '良好', '优质'],
filled=True,
fontsize=8,
max_depth=3, # 限制深度以便查看
ax=ax)
plt.title(f'随机森林中的决策树 #{tree_index+1} (显示前3层)', fontsize=14, pad=20)
plt.tight_layout()
# 保存图片
output_path = r'D:\AI\Random Forest\decision_tree_visualization.png'
plt.savefig(output_path, dpi=300, bbox_inches='tight')
print(f"决策树可视化已保存到: {output_path}")
plt.close()
def evaluate_model(rf, X_test, y_test, feature_names):
"""评估模型性能"""
print("\n" + "=" * 60)
print("模型评估指标")
print("=" * 60)
# 预测
y_pred = rf.predict(X_test)
# 准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"\n整体准确率: {accuracy:.4f} ({accuracy*100:.2f}%)")
# 详细分类指标
print("\n分类详细指标:")
print("-" * 60)
report = classification_report(
y_test, y_pred,
target_names=['一般(3-4)', '良好(5-6)', '优质(7-8)'],
digits=4
)
print(report)
# 计算每类的精确率、召回率、F1分数
precision, recall, f1, support = precision_recall_fscore_support(
y_test, y_pred, average=None
)
print("\n各类别指标汇总:")
print("-" * 60)
for i, category in enumerate(['一般(3-4)', '良好(5-6)', '优质(7-8)']):
print(f"{category}:")
print(f" 精确率 (Precision): {precision[i]:.4f}")
print(f" 召回率 (Recall): {recall[i]:.4f}")
print(f" F1分数 (F1-Score): {f1[i]:.4f}")
print(f" 样本数 (Support): {support[i]}")
print()
return y_pred, accuracy
def analyze_feature_importance(rf, feature_names):
"""分析特征重要性"""
print("\n" + "=" * 60)
print("特征重要性分析")
print("=" * 60)
# 获取特征重要性
importances = rf.feature_importances_
indices = np.argsort(importances)[::-1]
# 创建特征重要性表格
print("\n特征重要性排序 (降序):")
print("-" * 60)
importance_list = []
for i, idx in enumerate(indices):
importance = importances[idx]
print(f"{i+1}. {feature_names[idx]:<25} {importance:.4f} ({importance*100:.2f}%)")
importance_list.append((feature_names[idx], importance))
# 可视化特征重要性
fig, ax = plt.subplots(figsize=(10, 6))
sns.barplot(x=importances[indices], y=np.array(feature_names)[indices], ax=ax)
ax.set_xlabel('特征重要性', fontsize=12)
ax.set_ylabel('特征名称', fontsize=12)
ax.set_title('随机森林 - 特征重要性排序', fontsize=14, pad=15)
plt.tight_layout()
# 保存图片
output_path = r'D:\AI\Random Forest\feature_importance.png'
plt.savefig(output_path, dpi=300, bbox_inches='tight')
print(f"\n特征重要性图已保存到: {output_path}")
plt.close()
return importance_list
def plot_confusion_matrix(y_test, y_pred):
"""绘制混淆矩阵热力图"""
print("\n" + "=" * 60)
print("混淆矩阵热力图")
print("=" * 60)
# 计算混淆矩阵
cm = confusion_matrix(y_test, y_pred)
print("\n混淆矩阵:")
print(cm)
# 可视化混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=['一般', '良好', '优质'],
yticklabels=['一般', '良好', '优质'])
plt.title('混淆矩阵热力图', fontsize=14, pad=15)
plt.xlabel('预测标签', fontsize=12)
plt.ylabel('真实标签', fontsize=12)
plt.tight_layout()
# 保存图片
output_path = r'D:\AI\Random Forest\confusion_matrix.png'
plt.savefig(output_path, dpi=300, bbox_inches='tight')
print(f"混淆矩阵热力图已保存到: {output_path}")
plt.close()
def main():
"""主函数"""
# 1. 加载和预处理数据
filepath = r'D:\AI\Random Forest\winequality-red.csv'
X, y, df = load_and_preprocess_data(filepath)
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print(f"\n数据划分:")
print(f" 训练集: {X_train.shape[0]} 样本")
print(f" 测试集: {X_test.shape[0]} 样本")
# 3. 训练随机森林模型
rf = train_random_forest(X_train, y_train, n_estimators=100)
# 4. 可视化其中一棵决策树
visualize_decision_tree(rf, X.columns.tolist(), tree_index=0)
# 5. 评估模型
y_pred, accuracy = evaluate_model(rf, X_test, y_test, X.columns.tolist())
# 6. 特征重要性分析
importance_list = analyze_feature_importance(rf, X.columns.tolist())
# 7. 混淆矩阵热力图
plot_confusion_matrix(y_test, y_pred)
# 8. 保存模型
import pickle
model_path = r'D:\AI\Random Forest\random_forest_model.pkl'
with open(model_path, 'wb') as f:
pickle.dump(rf, f)
print(f"\n模型已保存到: {model_path}")
print("\n" + "=" * 60)
print("训练完成!")
print("=" * 60)
if __name__ == '__main__':
main()
wine_quality_rf_predict.py
"""
基于随机森林的红酒质量等级预测 - 预测代码
加载训练好的模型对新数据进行预测
"""
import pandas as pd
import numpy as np
import pickle
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score, classification_report
import warnings
warnings.filterwarnings('ignore')
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
def load_model(model_path):
"""加载训练好的模型"""
print("=" * 60)
print("加载训练好的模型")
print("=" * 60)
with open(model_path, 'rb') as f:
rf = pickle.load(f)
print(f"模型加载成功: {model_path}")
return rf
def predict_new_data(rf, data_path):
"""对新数据进行预测"""
print("\n" + "=" * 60)
print("对新数据进行预测")
print("=" * 60)
# 读取新数据
df = pd.read_csv(data_path, sep=';')
# 准备特征(去除quality和转换后的类别)
if 'quality' in df.columns:
X = df.drop(['quality'], axis=1)
y_true = df['quality'].values
else:
X = df
y_true = None
# 进行预测
y_pred = rf.predict(X)
y_pred_proba = rf.predict_proba(X)
# 转换预测结果为类别名称
category_names = {0: '一般(3-4)', 1: '良好(5-6)', 2: '优质(7-8)'}
y_pred_labels = [category_names[pred] for pred in y_pred]
# 输出预测结果
print(f"\n预测结果 (前10个样本):")
print("-" * 60)
for i in range(min(10, len(y_pred))):
prob = y_pred_proba[i]
confidence = np.max(prob)
print(f"样本 {i+1}: 预测={y_pred_labels[i]}, 置信度={confidence:.4f}")
# 统计预测结果分布
print(f"\n预测结果分布:")
unique, counts = np.unique(y_pred, return_counts=True)
for idx, count in zip(unique, counts):
print(f" {category_names[idx]}: {count} 样本 ({count/len(y_pred)*100:.1f}%)")
# 如果有真实标签,计算准确率
if y_true is not None:
# 转换真实标签为三分类
def categorize_quality(quality):
if quality in [3, 4]:
return 0
elif quality in [5, 6]:
return 1
else:
return 2
y_true_cat = np.array([categorize_quality(q) for q in y_true])
accuracy = accuracy_score(y_true_cat, y_pred)
print(f"\n预测准确率: {accuracy:.4f} ({accuracy*100:.2f}%)")
print(f"\n详细分类报告:")
print("-" * 60)
print(classification_report(
y_true_cat, y_pred,
target_names=['一般(3-4)', '良好(5-6)', '优质(7-8)'],
digits=4
))
return y_pred, y_pred_proba
def predict_single_sample(rf, feature_values):
"""对单个样本进行预测"""
print("\n" + "=" * 60)
print("单样本预测")
print("=" * 60)
# 特征名称
feature_names = ['fixed acidity', 'volatile acidity', 'citric acid',
'residual sugar', 'chlorides', 'free sulfur dioxide',
'total sulfur dioxide', 'density', 'pH', 'sulphates', 'alcohol']
# 转换为numpy数组
X = np.array(feature_values).reshape(1, -1)
# 预测
y_pred = rf.predict(X)[0]
y_pred_proba = rf.predict_proba(X)[0]
category_names = {0: '一般(3-4)', 1: '良好(5-6)', 2: '优质(7-9)'}
print(f"\n输入特征:")
for name, value in zip(feature_names, feature_values):
print(f" {name}: {value}")
print(f"\n预测结果: {category_names[y_pred]}")
print(f"\n各类别概率:")
for i, (cat, prob) in enumerate(zip(['一般', '良好', '优质'], y_pred_proba)):
print(f" {cat}: {prob:.4f} ({prob*100:.2f}%)")
return y_pred, y_pred_proba
def main():
"""主函数"""
# 1. 加载模型
model_path = r'D:\AI\Random Forest\random_forest_model.pkl'
rf = load_model(model_path)
# 2. 对测试数据进行预测
test_data_path = r'D:\AI\Random Forest\winequality-red.csv'
y_pred, y_pred_proba = predict_new_data(rf, test_data_path)
# 3. 示例:对单个样本进行预测
# 使用一个中等质量的红酒样本
sample_features = [
7.4, # fixed acidity
0.7, # volatile acidity
0.0, # citric acid
1.9, # residual sugar
0.076, # chlorides
11.0, # free sulfur dioxide
34.0, # total sulfur dioxide
0.9978,# density
3.51, # pH
0.56, # sulphates
9.4 # alcohol
]
predict_single_sample(rf, sample_features)
print("\n" + "=" * 60)
print("预测完成!")
print("=" * 60)
if __name__ == '__main__':
main()