一、题目背景
LeetCode 79「单词搜索」是一道经典的二维网格搜索问题。
题目给定一个 m x n 的字符网格 board,以及一个字符串 word,要求判断 word 是否能够在网格中被搜索出来。
搜索规则如下:
-
单词必须按照字符顺序依次匹配;
-
每一步只能向上下左右四个方向移动;
-
同一个单元格不能在一次搜索路径中被重复使用;
-
如果存在一条合法路径可以构成
word,返回true,否则返回false。
例如:
board = [
['A','B','C','E'],
['S','F','C','S'],
['A','D','E','E']
]
word = "ABCCED"可以从左上角的 A 出发:
A -> B -> C -> C -> E -> D因此返回 true。
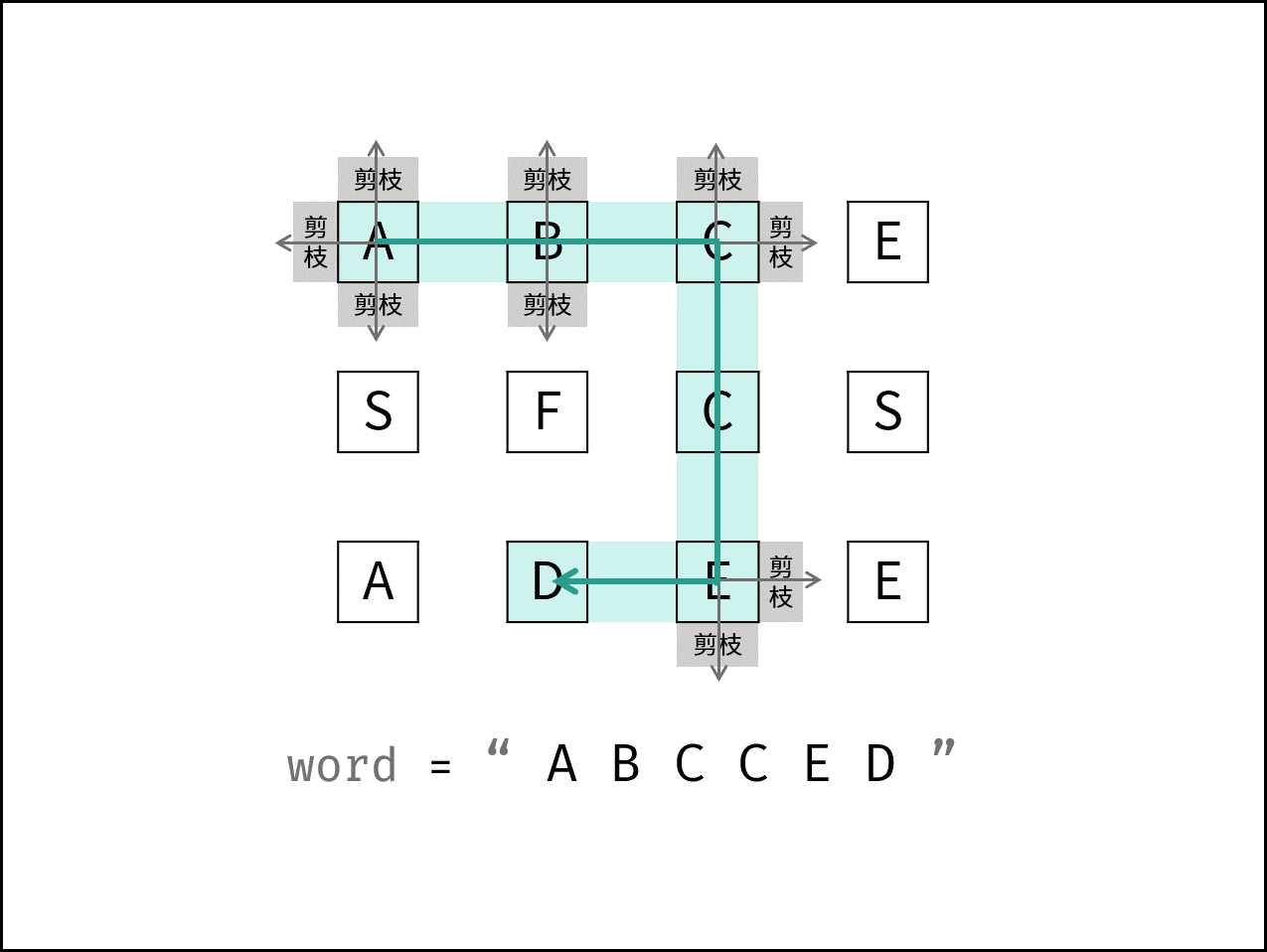
二、问题本质:在二维网格中寻找一条合法路径
这道题的本质不是简单的字符串匹配,而是:
在二维网格中寻找一条长度为
word.length()的路径,使路径上的字符依次等于word中的字符。
由于路径每一步有最多 4 个方向可以选择,所以天然适合使用 深度优先搜索 DFS。
同时,由于每个格子在一条路径中不能重复使用,所以搜索过程中还需要维护访问状态,并在搜索失败时撤销选择。
这正是典型的 回溯算法。
三、为什么使用 DFS + 回溯?
假设我们当前要匹配 word[index],并且当前位置是 (row, col)。
如果:
board[row][col] == word[index]说明当前位置字符匹配成功。
接下来我们需要继续匹配:
word[index + 1]这个字符只能从当前位置的上下左右四个相邻格子中寻找。
因此搜索逻辑可以抽象为:
当前位置匹配成功
标记当前位置已经使用
向上下左右继续搜索下一个字符
如果某个方向成功,返回 true
如果四个方向都失败,撤销当前位置标记
返回 false这就是 DFS + 回溯的核心框架。
四、回溯过程分析
以 word = "ABCCED" 为例。
从 (0, 0) 的 A 开始:
A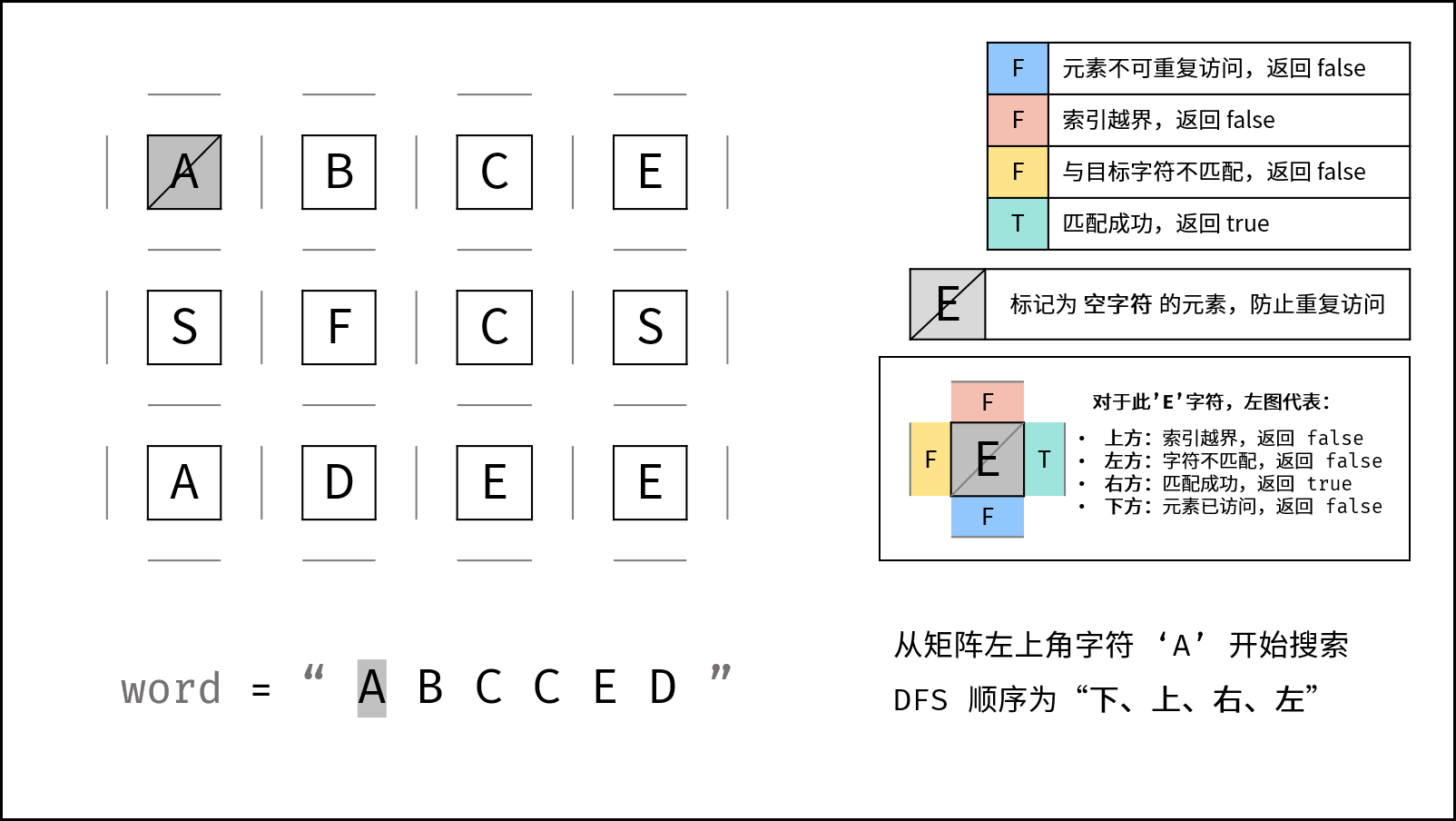
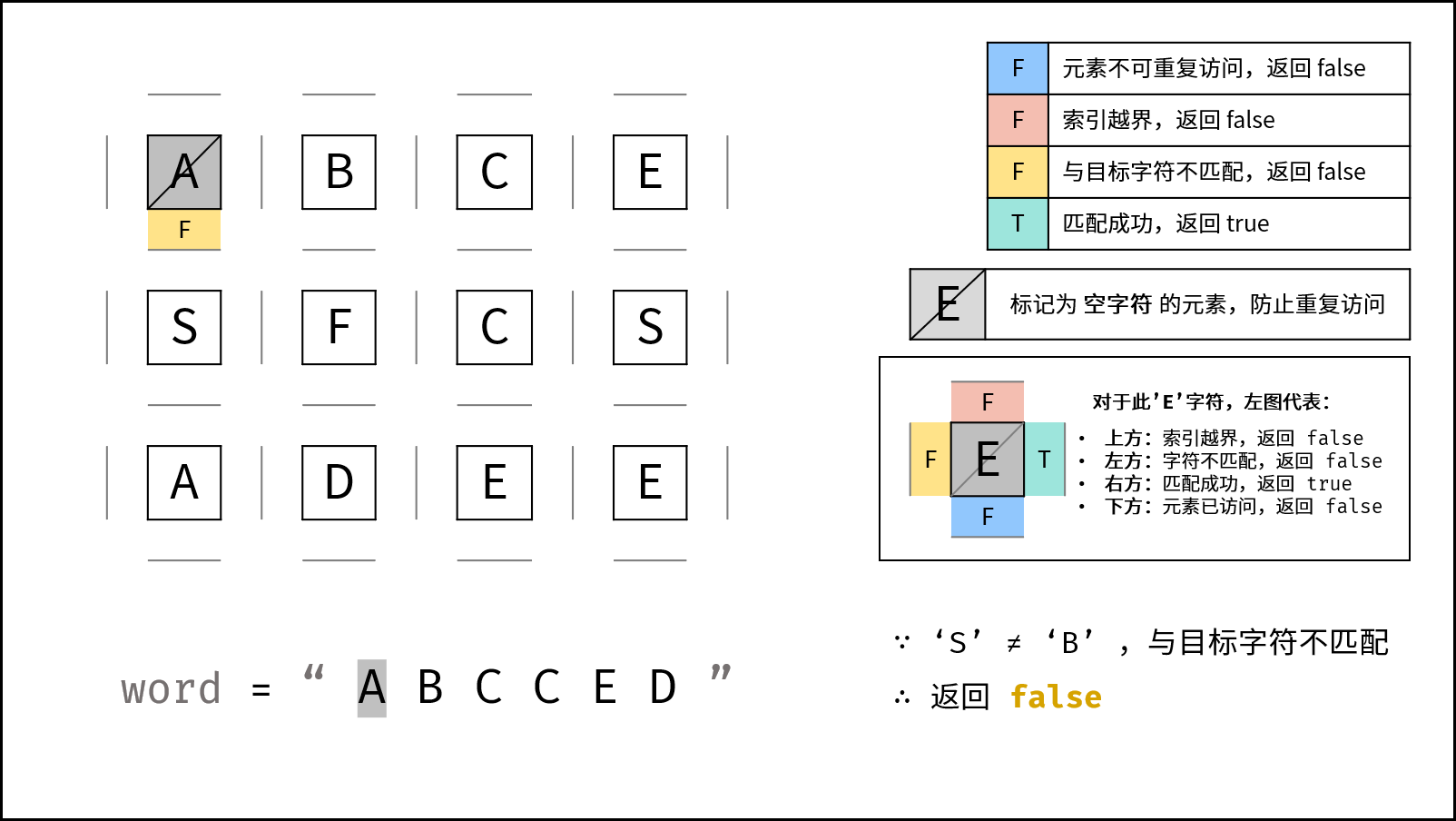
匹配成功,继续找 B。
向右到 (0, 1):
A -> B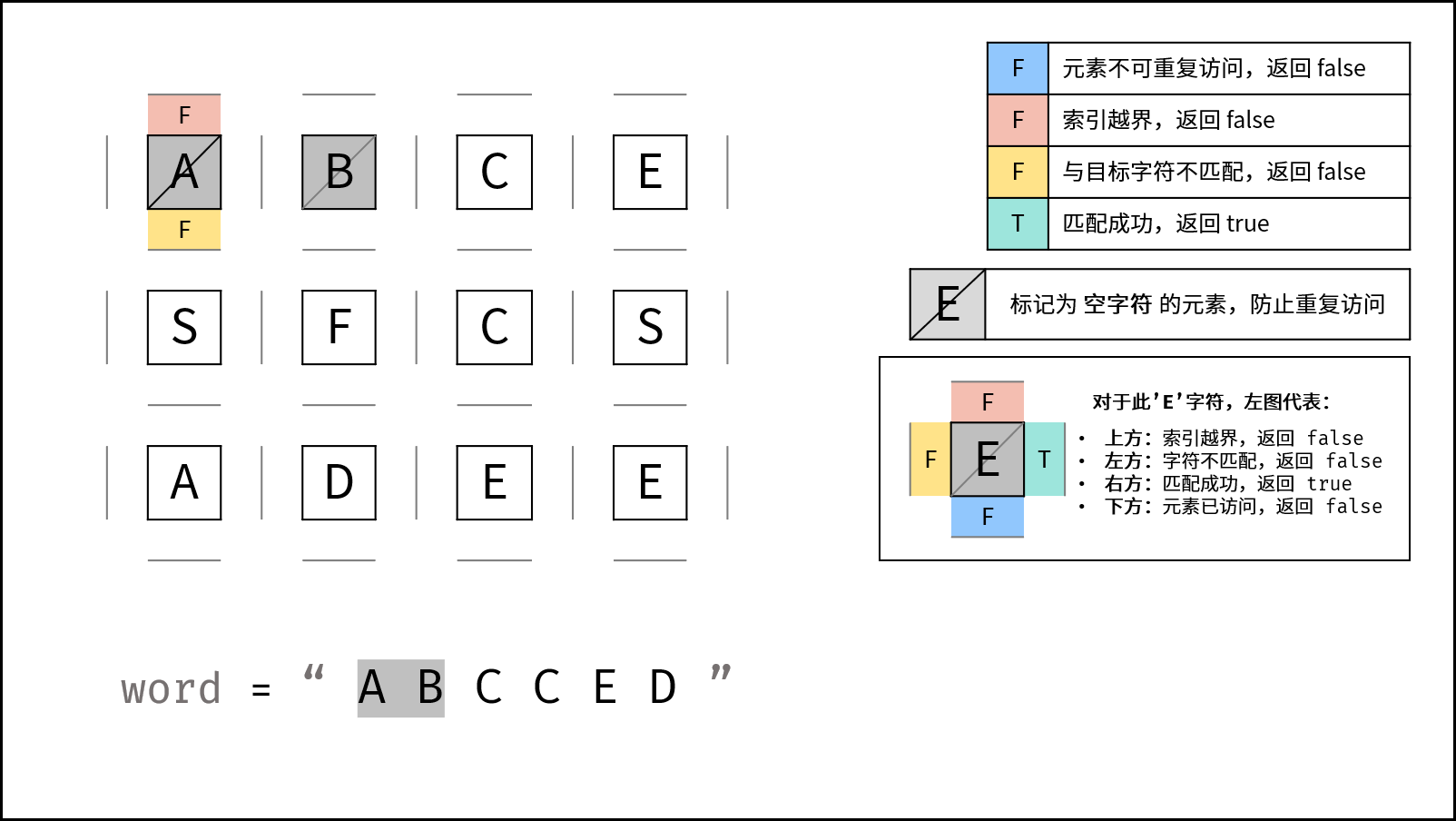
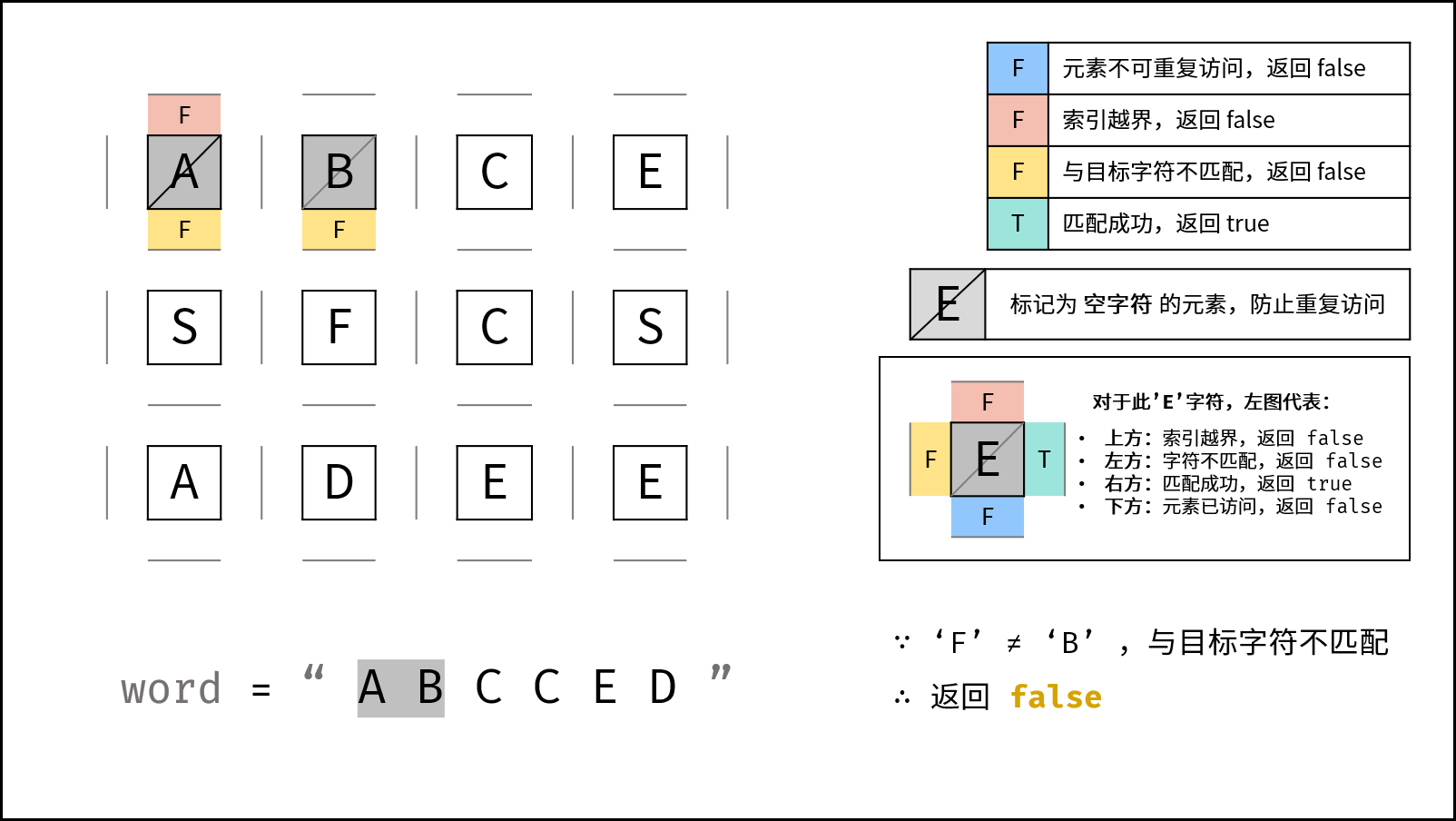
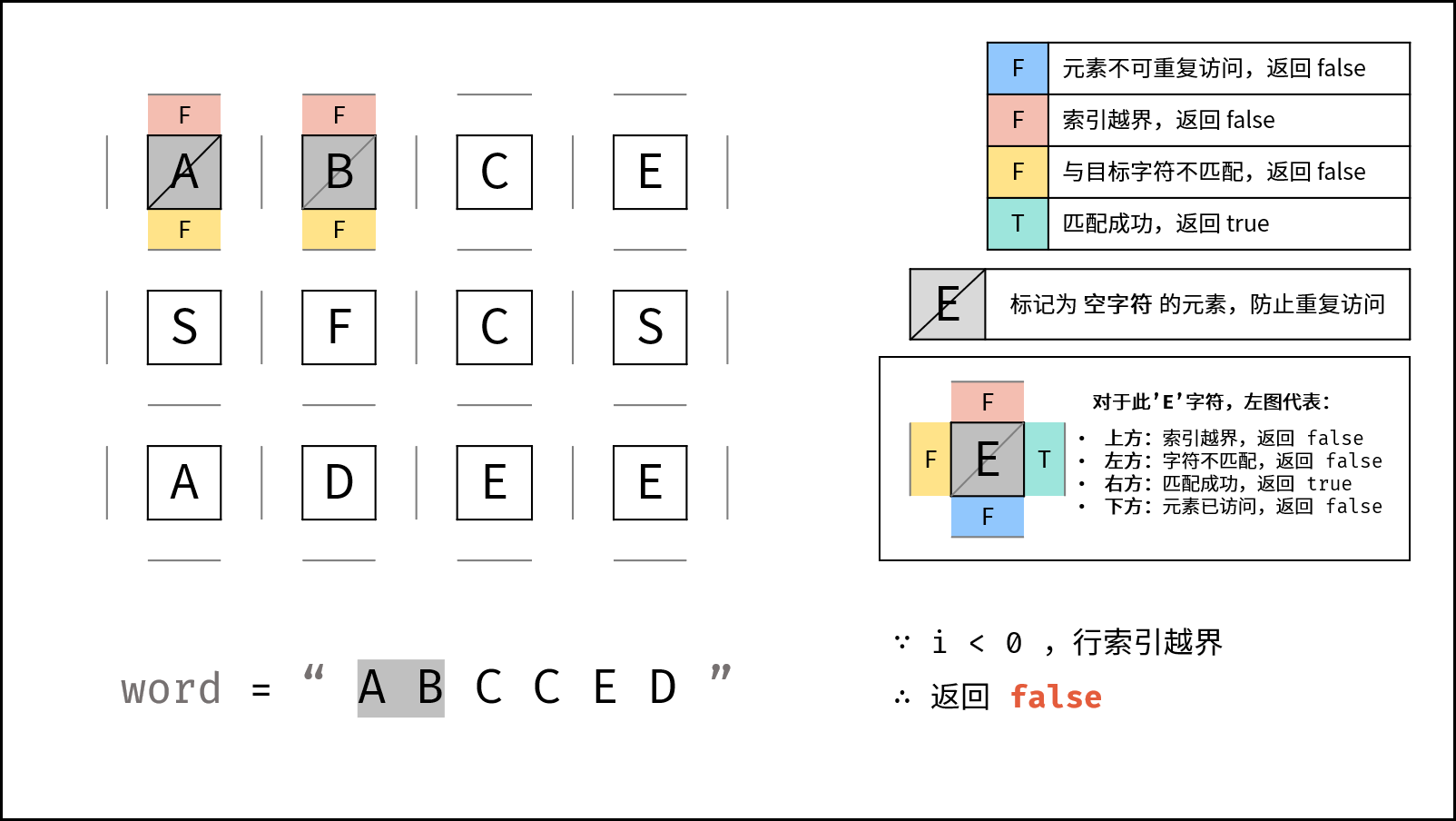
匹配成功,继续找 C。
向右到 (0, 2):
A -> B -> C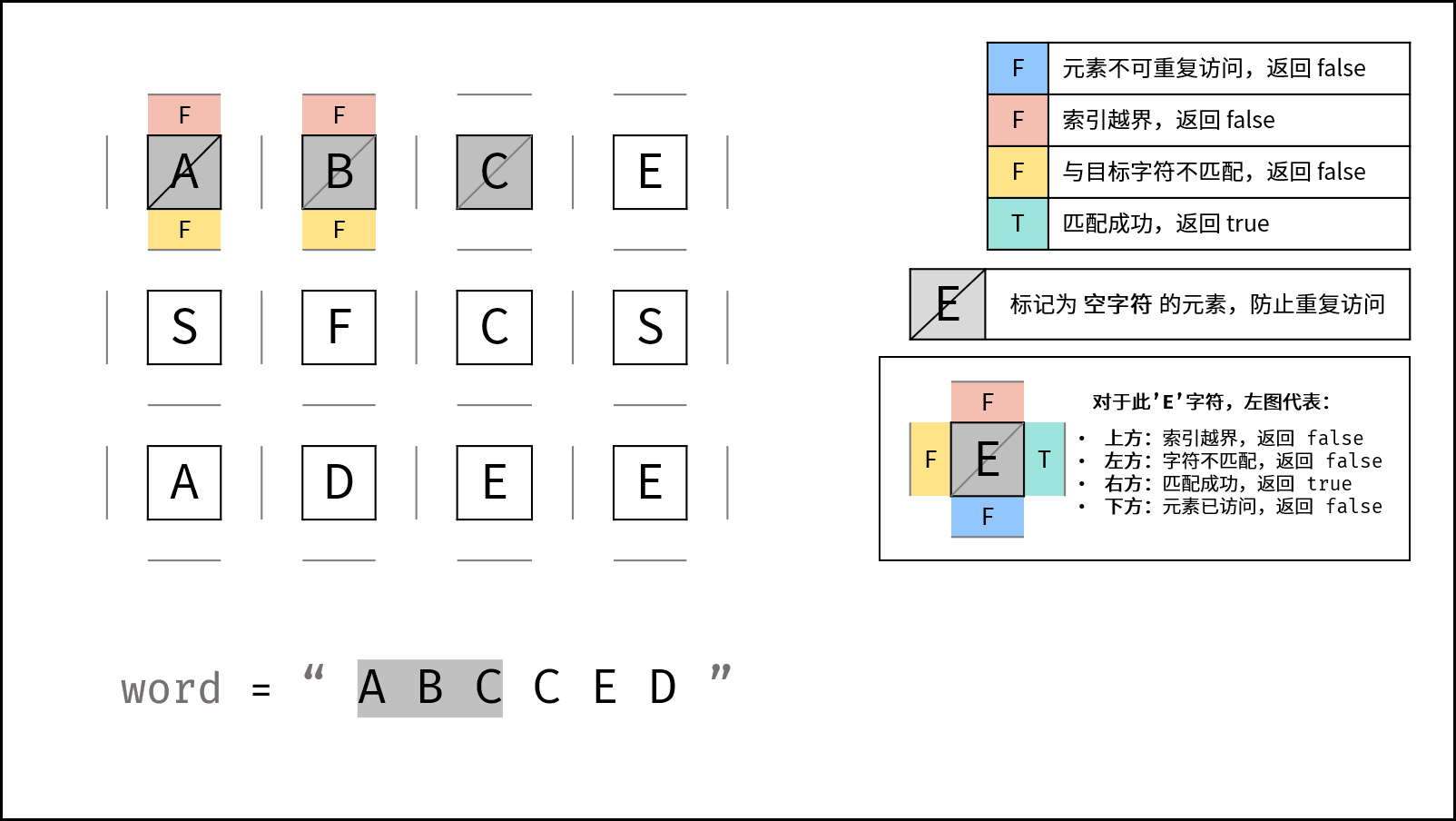
继续找下一个 C。
向下到 (1, 2):
A -> B -> C -> C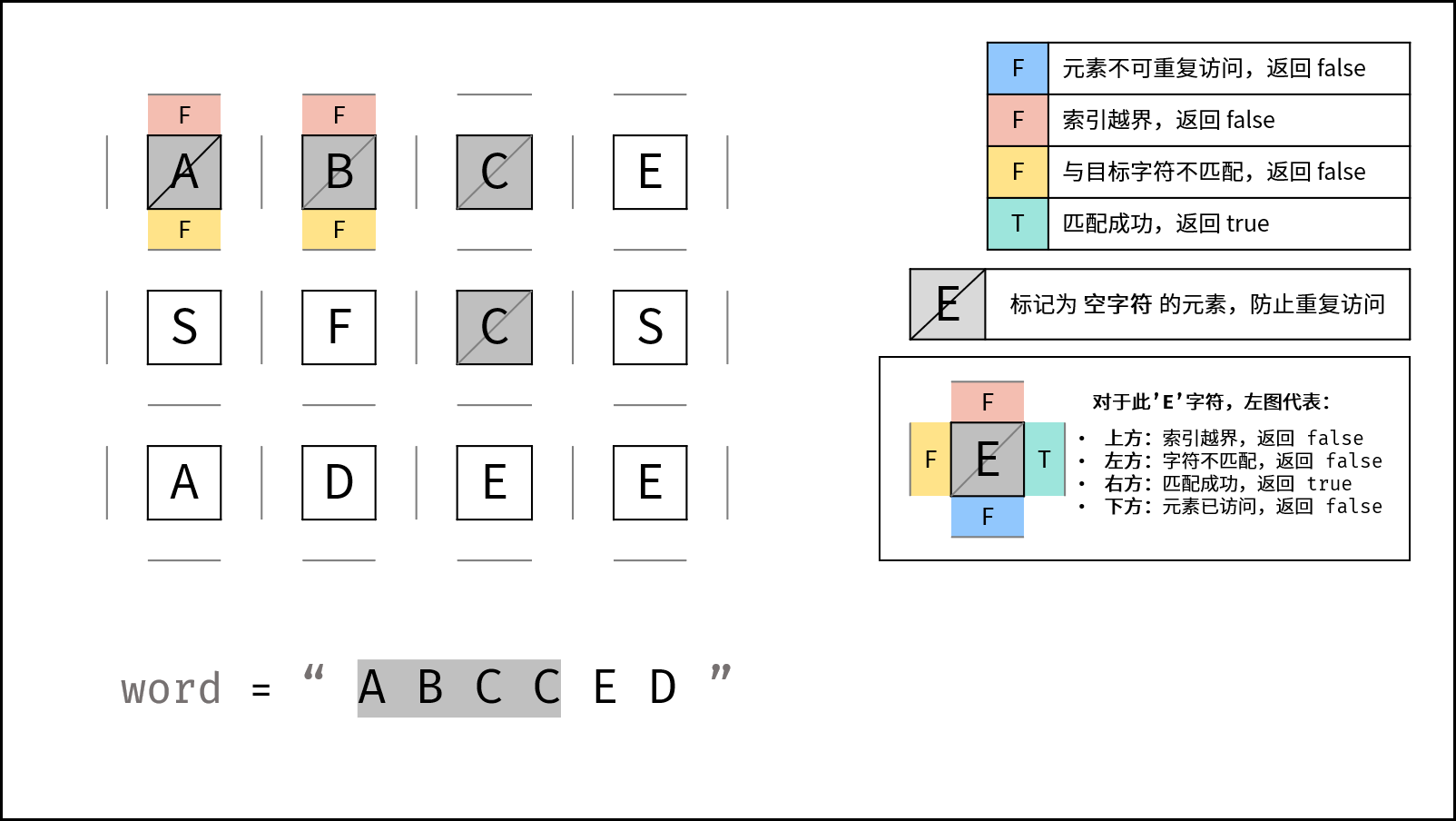
继续找 E。
向下到 (2, 2):
A -> B -> C -> C -> E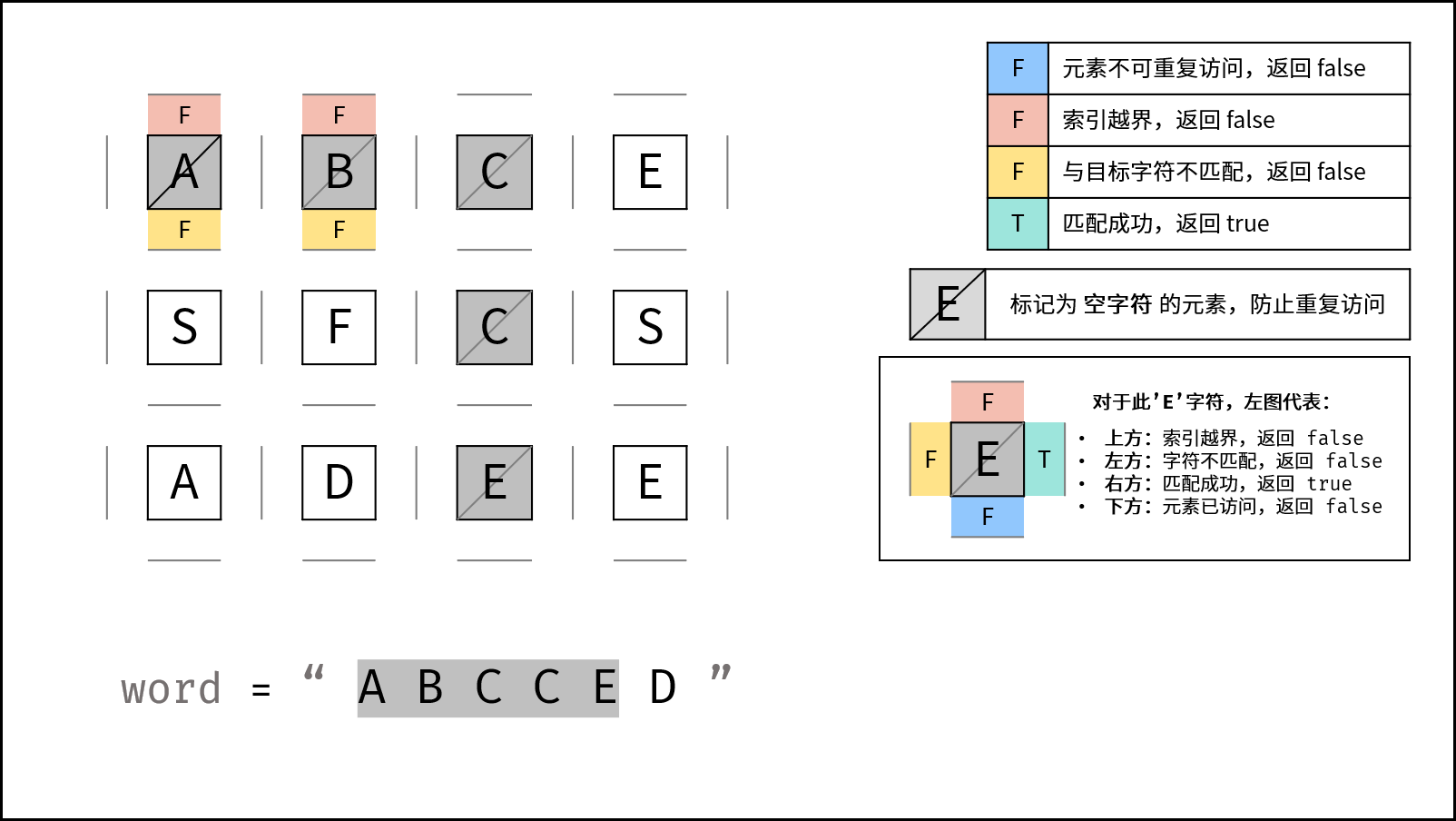
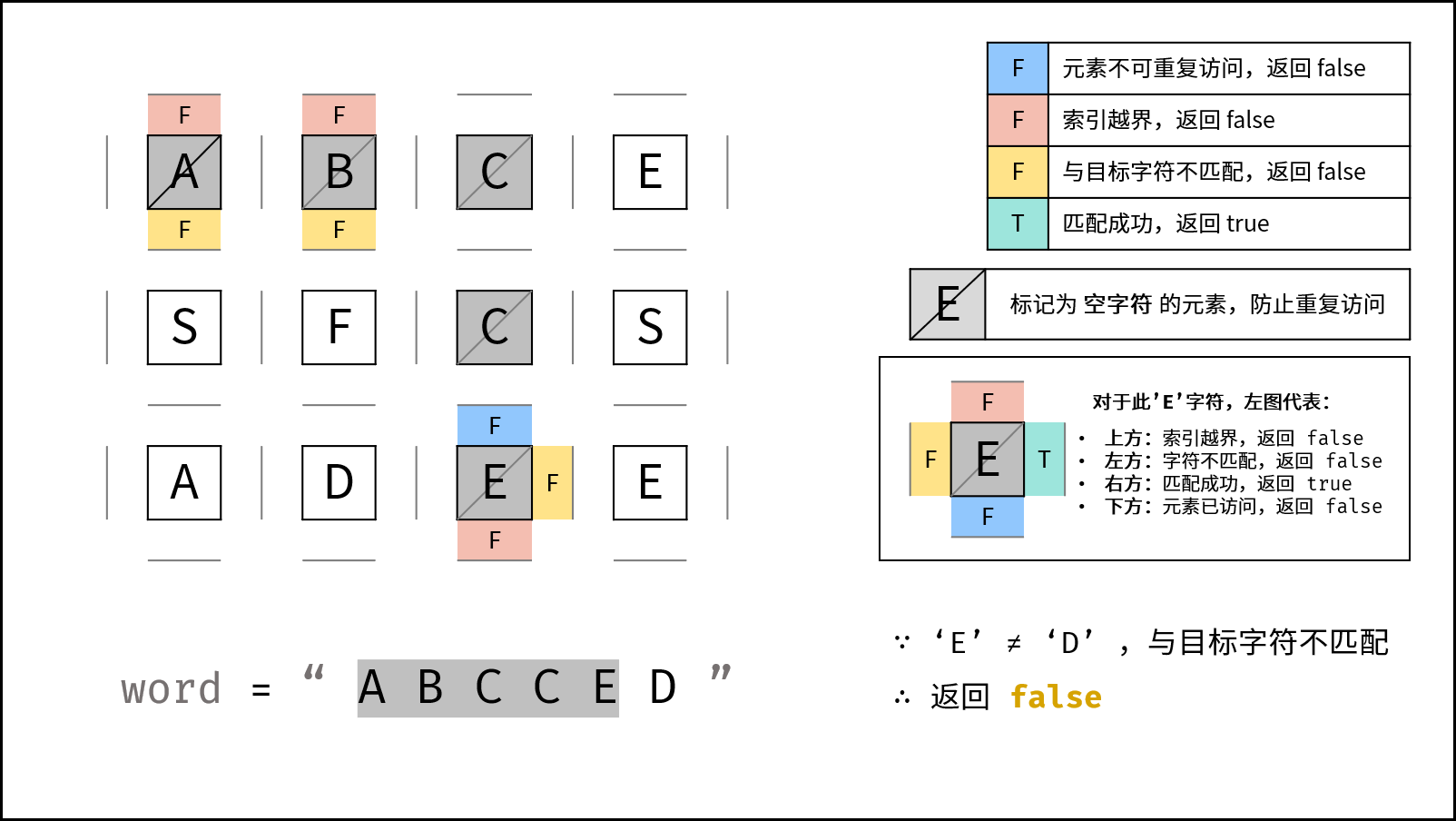
继续找 D。
向左到 (2, 1):
A -> B -> C -> C -> E -> D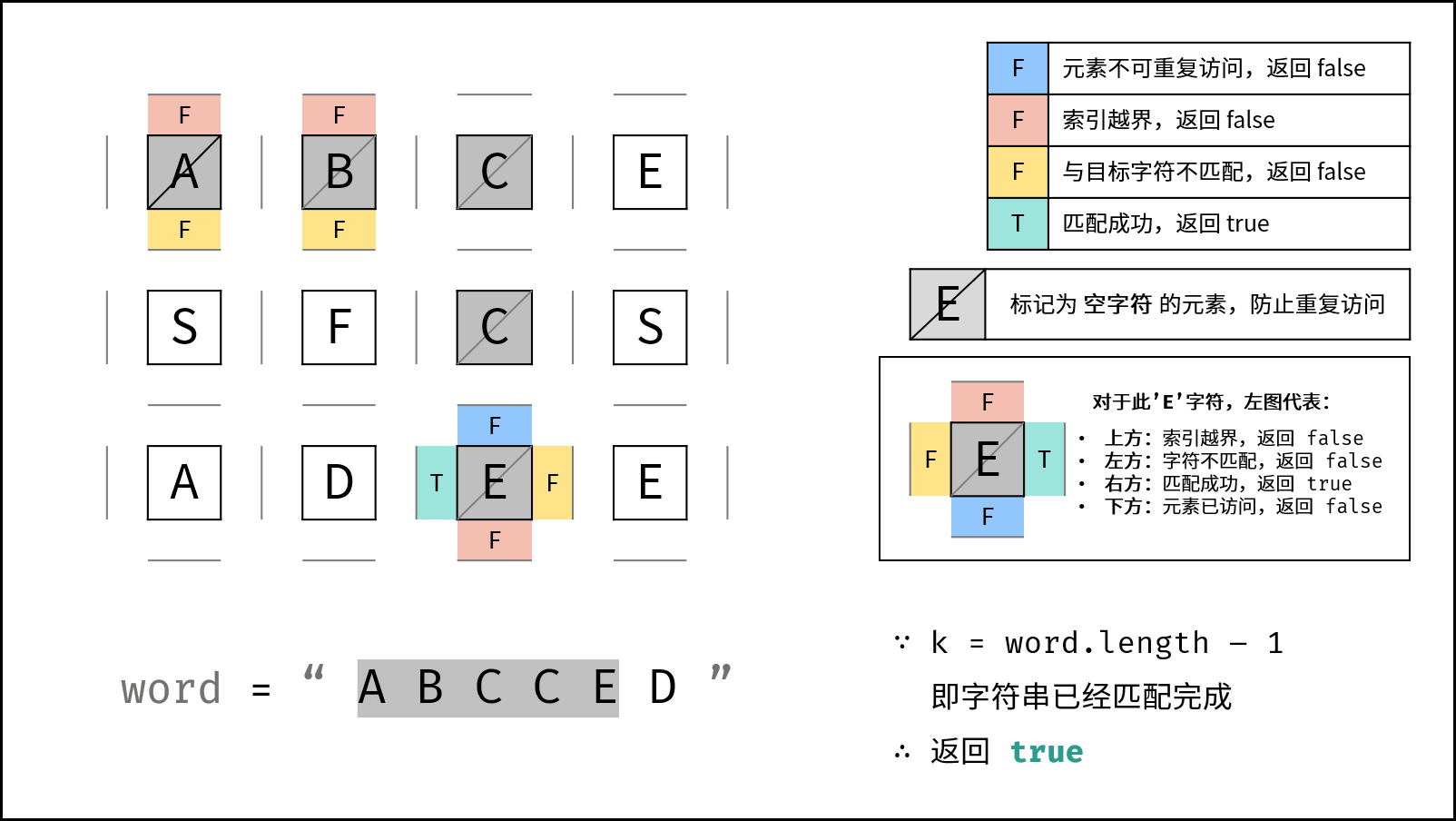
全部匹配成功,返回 true。
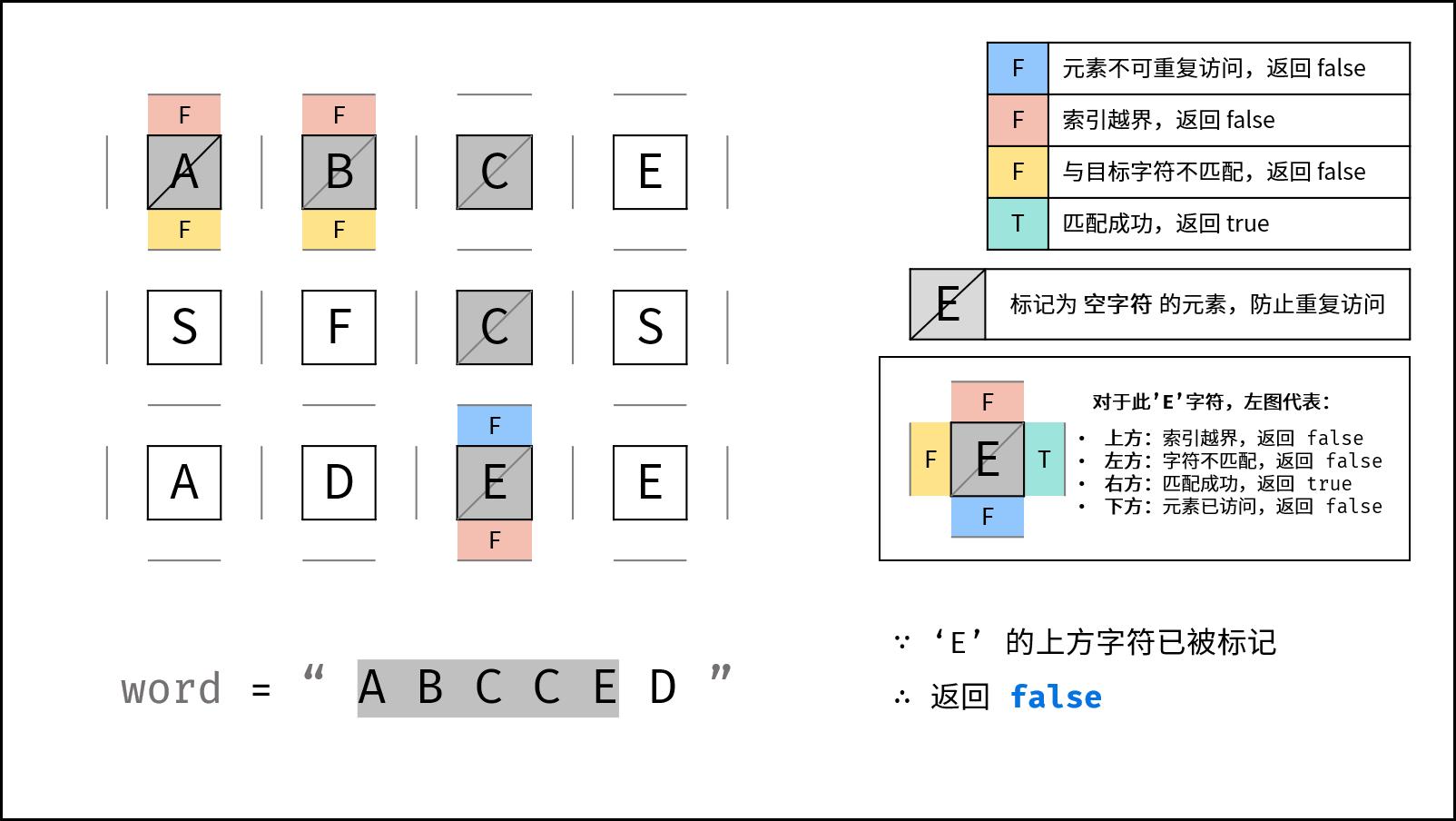
如果某一步发现四个方向都走不通,就需要回退到上一个位置,尝试其他方向。这就是"回溯"的含义。
五、关键问题:如何避免重复使用同一个格子?
题目要求:
同一个单元格内的字母不允许被重复使用。
常见做法有两种:
方法一:使用 visited 数组
定义:
vector<vector<bool>> visited;当某个位置被访问时,将其标记为 true。
搜索结束后,再恢复为 false。
方法二:原地修改 board
由于 board 中只包含大小写英文字母,所以可以临时把访问过的位置改成特殊字符,例如 '#'。
搜索结束后再恢复原字符。
例如:
char temp = board[row][col];
board[row][col] = '#';
// 搜索四个方向
board[row][col] = temp;这种方式可以避免额外的 visited 数组,空间更优。
六、基础版代码实现
#include <vector>
#include <string>
using namespace std;
class Solution {
public:
bool exist(vector<vector<char>>& board, string word) {
int m = board.size();
int n = board[0].size();
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (dfs(board, word, i, j, 0)) {
return true;
}
}
}
return false;
}
private:
bool dfs(vector<vector<char>>& board, string& word, int row, int col, int index) {
int m = board.size();
int n = board[0].size();
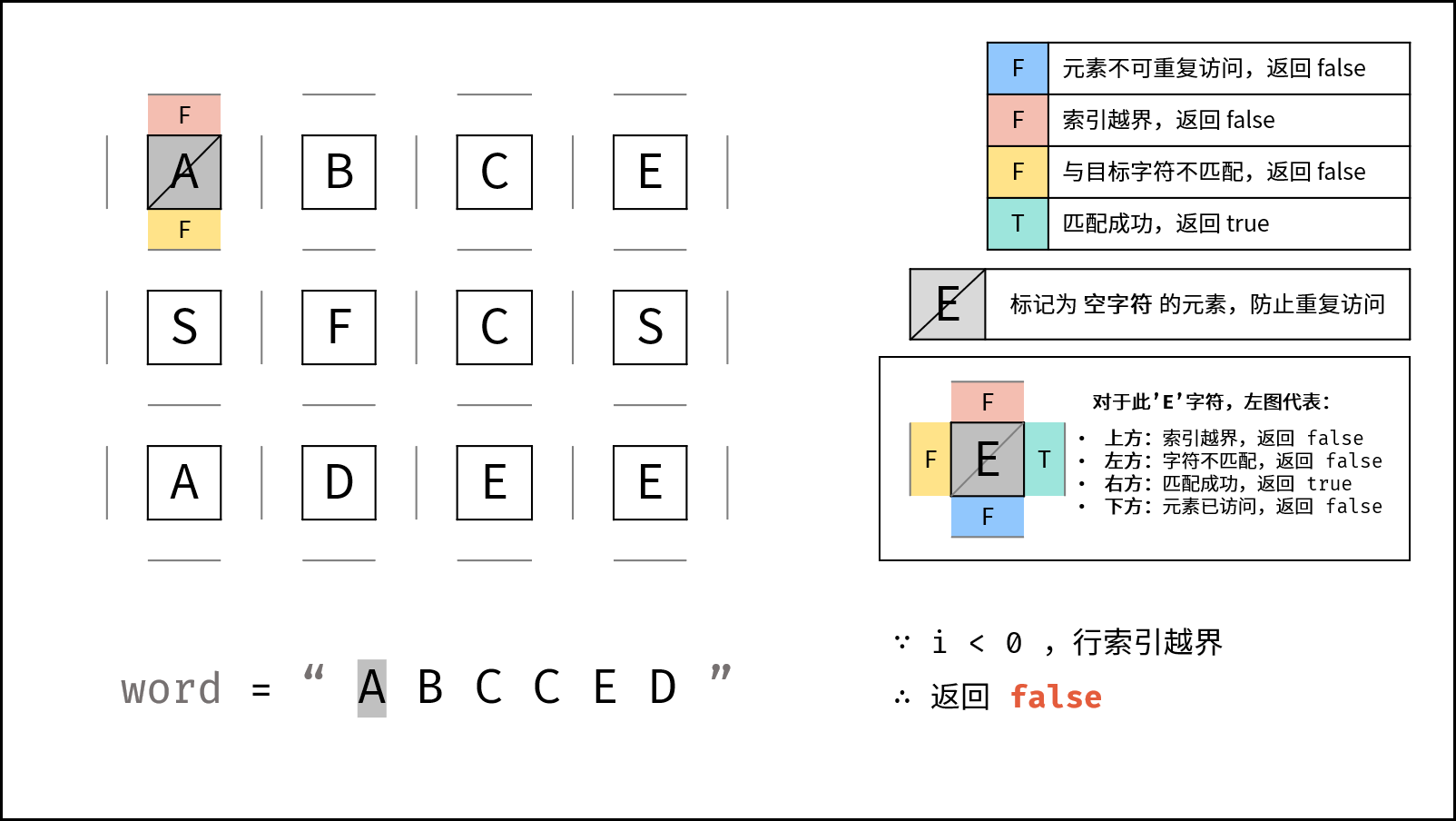
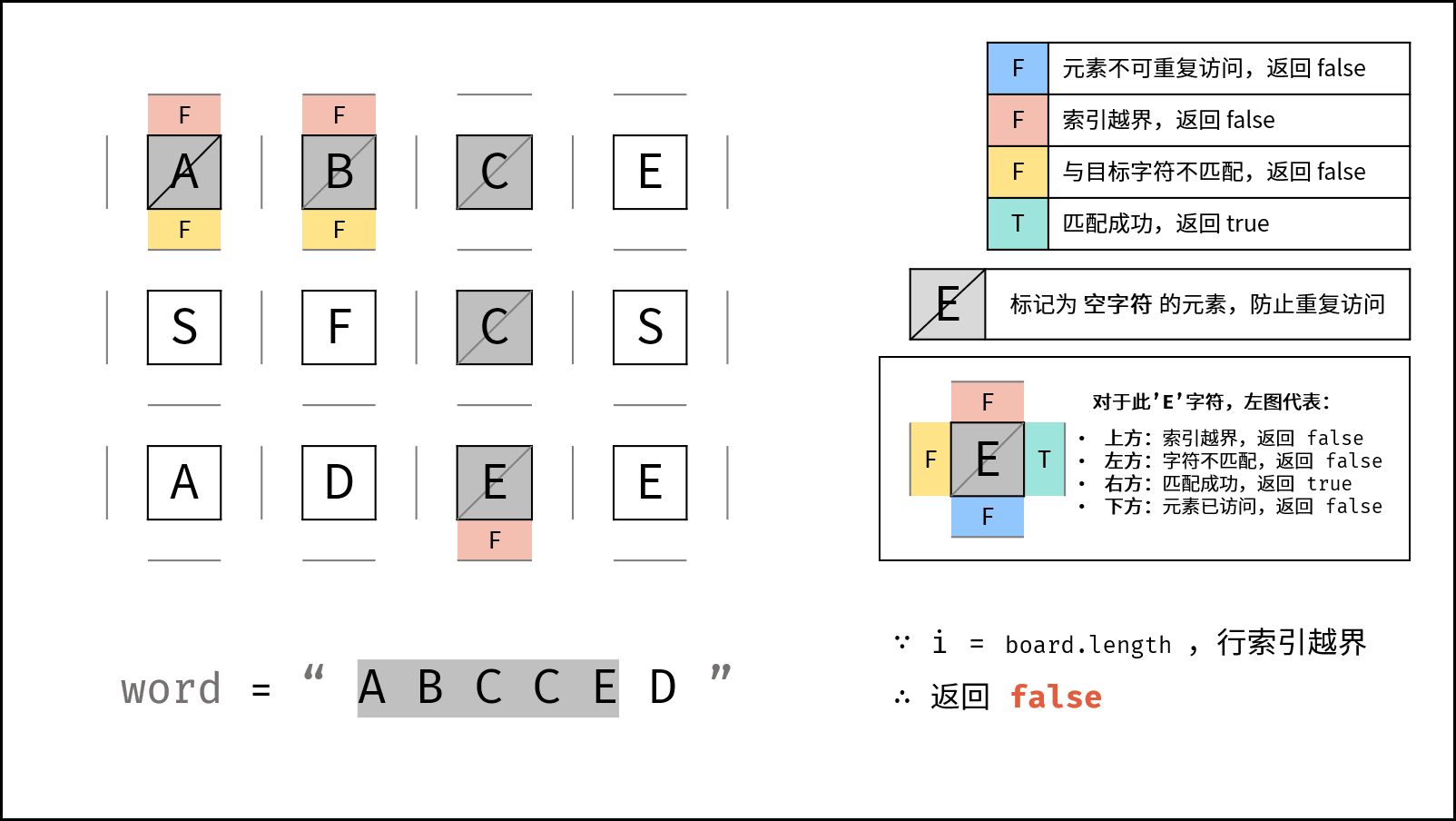
if (row < 0 || row >= m || col < 0 || col >= n) {
return false;
}
if (board[row][col] != word[index]) {
return false;
}
if (index == word.size() - 1) {
return true;
}
char temp = board[row][col];
board[row][col] = '#';
bool found =
dfs(board, word, row + 1, col, index + 1) ||
dfs(board, word, row - 1, col, index + 1) ||
dfs(board, word, row, col + 1, index + 1) ||
dfs(board, word, row, col - 1, index + 1);
board[row][col] = temp;
return found;
}
};七、代码逻辑拆解
1. 枚举起点
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (dfs(board, word, i, j, 0)) {
return true;
}
}
}因为单词可能从任意位置开始,所以需要遍历整个网格,把每一个格子都作为起点尝试搜索。
2. 越界判断
if (row < 0 || row >= m || col < 0 || col >= n) {
return false;
}如果当前位置超出网格范围,说明路径不合法。
3. 字符匹配判断
if (board[row][col] != word[index]) {
return false;
}如果当前位置字符与当前需要匹配的字符不同,直接剪枝。
4. 递归终止条件
if (index == word.size() - 1) {
return true;
}如果已经匹配到单词最后一个字符,并且当前字符也匹配成功,说明整个单词已经找到。
5. 标记当前位置
char temp = board[row][col];
board[row][col] = '#';将当前位置临时标记为 '#',防止后续搜索又走回这个格子。
6. 搜索四个方向
bool found =
dfs(board, word, row + 1, col, index + 1) ||
dfs(board, word, row - 1, col, index + 1) ||
dfs(board, word, row, col + 1, index + 1) ||
dfs(board, word, row, col - 1, index + 1);只要上下左右任意一个方向可以成功匹配剩余字符,就说明当前路径有效。
7. 恢复现场
board[row][col] = temp;这是回溯算法中非常关键的一步。
因为当前路径搜索结束后,其他路径仍然可能需要使用这个格子,所以必须恢复原字符。
如果不恢复,后续搜索结果会被污染。
八、进阶优化:搜索剪枝
题目进阶要求我们使用剪枝优化搜索效率。
虽然本题数据范围较小:
m, n <= 6
word.length <= 15但是从算法设计角度来看,剪枝非常重要。
剪枝一:如果 word 长度大于网格格子数,直接返回 false
如果单词长度超过网格总格子数,一定无法构造成功。
if (word.size() > m * n) {
return false;
}剪枝二:统计字符频率
如果 word 中某个字符出现次数,比 board 中该字符出现次数还多,那么一定无法匹配。
例如:
board 中只有 1 个 A
word 中需要 3 个 A这种情况不需要 DFS,直接返回 false。
剪枝三:从更稀有的字符开始搜索
如果 word 的首字符在网格中出现很多次,而尾字符出现很少次,那么从首字符开始会产生很多无效分支。
例如:
word = "AAAAAZ"如果 A 很多,Z 很少,那么从 A 开始会尝试大量路径。
由于单词路径可以反向搜索,所以可以将 word 反转,从更稀有的一端开始匹配。
if (count[word[0]] > count[word[word.size() - 1]]) {
reverse(word.begin(), word.end());
}这个优化在大网格中非常有效。
九、优化版代码实现
#include <vector>
#include <string>
#include <algorithm>
using namespace std;
class Solution {
public:
bool exist(vector<vector<char>>& board, string word) {
int m = board.size();
int n = board[0].size();
if (word.size() > m * n) {
return false;
}
vector<int> count(128, 0);
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
count[board[i][j]]++;
}
}
for (char c : word) {
count[c]--;
if (count[c] < 0) {
return false;
}
}
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
count[board[i][j]]++;
}
}
if (count[word[0]] > count[word[word.size() - 1]]) {
reverse(word.begin(), word.end());
}
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (board[i][j] == word[0]) {
if (dfs(board, word, i, j, 0)) {
return true;
}
}
}
}
return false;
}
private:
int dirs[4][2] = {
{1, 0},
{-1, 0},
{0, 1},
{0, -1}
};
bool dfs(vector<vector<char>>& board, string& word, int row, int col, int index) {
if (board[row][col] != word[index]) {
return false;
}
if (index == word.size() - 1) {
return true;
}
int m = board.size();
int n = board[0].size();
char temp = board[row][col];
board[row][col] = '#';
for (int i = 0; i < 4; i++) {
int nextRow = row + dirs[i][0];
int nextCol = col + dirs[i][1];
if (nextRow < 0 || nextRow >= m || nextCol < 0 || nextCol >= n) {
continue;
}
if (board[nextRow][nextCol] == '#') {
continue;
}
if (dfs(board, word, nextRow, nextCol, index + 1)) {
board[row][col] = temp;
return true;
}
}
board[row][col] = temp;
return false;
}
};十、优化版代码说明
优化版代码主要做了三件事。
1. 长度剪枝
if (word.size() > m * n) {
return false;
}如果单词长度超过格子总数,必然无法搜索成功。
2. 频率剪枝
for (char c : word) {
count[c]--;
if (count[c] < 0) {
return false;
}
}如果 word 中需要的某个字符数量超过网格中该字符数量,直接返回 false。
这类剪枝属于搜索前预处理,可以大幅减少无意义 DFS。
3. 起点方向优化
if (count[word[0]] > count[word[word.size() - 1]]) {
reverse(word.begin(), word.end());
}如果单词首字符出现次数比尾字符多,那么从尾字符开始搜索分支更少。
例如:
word = "AAAAAB"假如 A 有很多,B 很少,那么反转成:
"BAAAAA"从 B 开始搜索可以显著降低起点数量。
十一、复杂度分析
设:
m = board 的行数
n = board 的列数
L = word 的长度时间复杂度
最坏情况下,每个格子都可能作为起点。
第一个字符之后,每一步最多向 3 个方向扩展,因为不能立刻回到上一个格子。
所以时间复杂度可以近似表示为:
O(m * n * 3^L)严格来说,第一步最多有 4 个方向,后续由于访问限制,分支数会下降。
空间复杂度
如果使用原地修改 board,不额外使用 visited 数组。
递归深度最多为 L,因此空间复杂度为:
O(L)这部分空间来自递归调用栈。
十二、为什么不是 BFS?
这道题也可以从搜索角度理解为路径查找问题,但并不适合 BFS。
原因是:
-
每一条路径都有独立的访问状态;
-
同一个格子不能在同一路径中重复使用;
-
BFS 需要存储大量路径状态,空间开销较大;
-
DFS 天然适合"走一条路径,不行再回退"的搜索模型。
因此,本题最自然的解法是:
DFS + 回溯而不是 BFS。
十三、常见错误总结
错误一:忘记恢复现场
错误写法:
board[row][col] = '#';
// 搜索结束后没有恢复这样会导致其他搜索路径无法正常使用该格子。
正确写法:
char temp = board[row][col];
board[row][col] = '#';
// DFS
board[row][col] = temp;错误二:没有处理越界
搜索上下左右时必须判断边界,否则会访问非法数组下标。
错误三:重复使用同一个格子
如果不做访问标记,可能出现如下非法路径:
A -> B -> A其中同一个 A 被使用了多次。
错误四:递归终止条件写错
很多人会把终止条件写成:
if (index == word.size()) return true;这种写法也可以,但需要配合不同的递归设计。
在本文代码中,当前层负责匹配 word[index],所以终止条件是:
if (index == word.size() - 1) {
return true;
}含义是:当前字符已经是最后一个字符,并且已经匹配成功。
十四、总结
LeetCode 79「单词搜索」是一道典型的二维网格 DFS 回溯题。
它的核心思想可以概括为:
枚举每一个起点
从起点开始 DFS
每次匹配当前字符
向上下左右搜索下一个字符
使用标记防止重复访问
搜索失败后恢复现场这道题考查的不只是 DFS,更重要的是对"状态"的理解。
在回溯算法中,每一步选择都会改变当前路径状态;当这条路径失败时,必须撤销选择,让其他路径继续搜索。
因此,本题的关键不是简单地"递归四个方向",而是:
在搜索过程中正确维护路径状态,并在回溯时恢复现场。
最终推荐解法是:
DFS + 回溯 + 原地标记 + 字符频率剪枝 + 起点方向优化这套写法既清晰,也具备较好的性能表现。