哈喽,艾瑞巴蒂我是生活爱好者,之前在NAS部署过一个用ai写小说的项目,写了一篇《NAS江湖:重生之靠docker逆袭人生》,突发奇想,能不能在NAS上部署一套AI生成漫画的工作流?搜了很多资料,找到一个对于小白相对友好,也能落地的项目,在NAS上部署Open WebUI。它是一个支持部署在NAS上的私有AI平台,它不仅支持本地的模型,同时支持云端的api模型。
Open WebUI特点
1.、它类似于ChatGPT,可以进行沉浸式对话
- 内置RAG私有知识库
3、.多用户与权限管理
4、支持多厂商的模型统一入口
5、完全离线私有化
本篇教程是自己经过一天的实战检测,在NAS上部署Open WebUI,对接硅基流动的接口,拆解小说为漫画的分镜,以及调用硅基流动的生图。
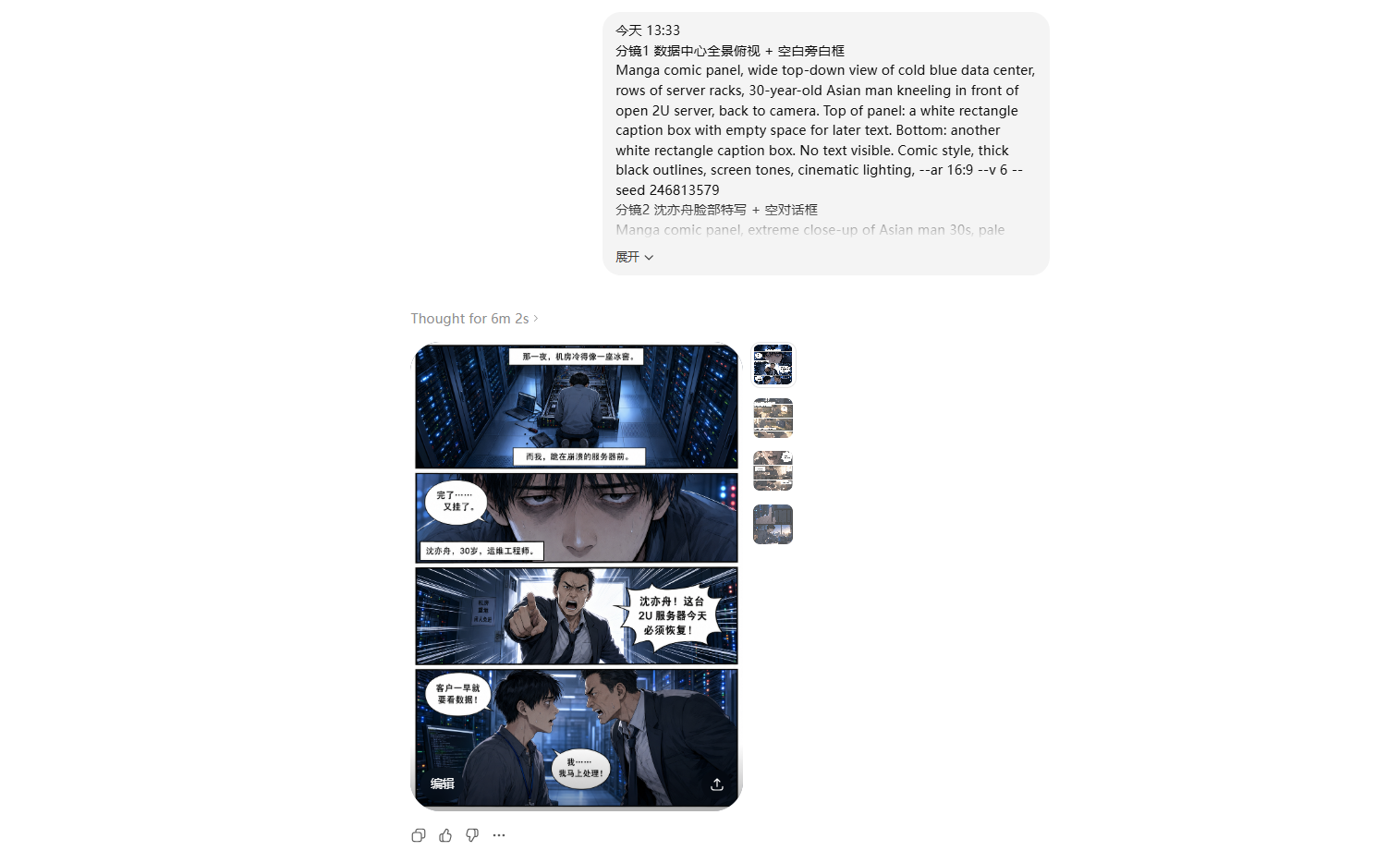
下图是用之前NAS写的一篇《NAS江湖:重生之靠docker逆袭人生》的小说,下面是生成的漫画效果。



漫画中的分镜是借助Open WebUI进行撰写的,图片的生成时借助ChatGPT,因为硅基流动有些优惠券,所以一直使用它来测试,使用硅基流动中的生图的模型,有明显的短版,有些文字没办法直接放到图片上。
比较好的解决方案是借助Open WebUI来写漫画的分镜,搭配优质生图模型出图。
一、NAS部署Open WebUI
进入威联通NAS,打开ContainerStaion,将代码进行复制。
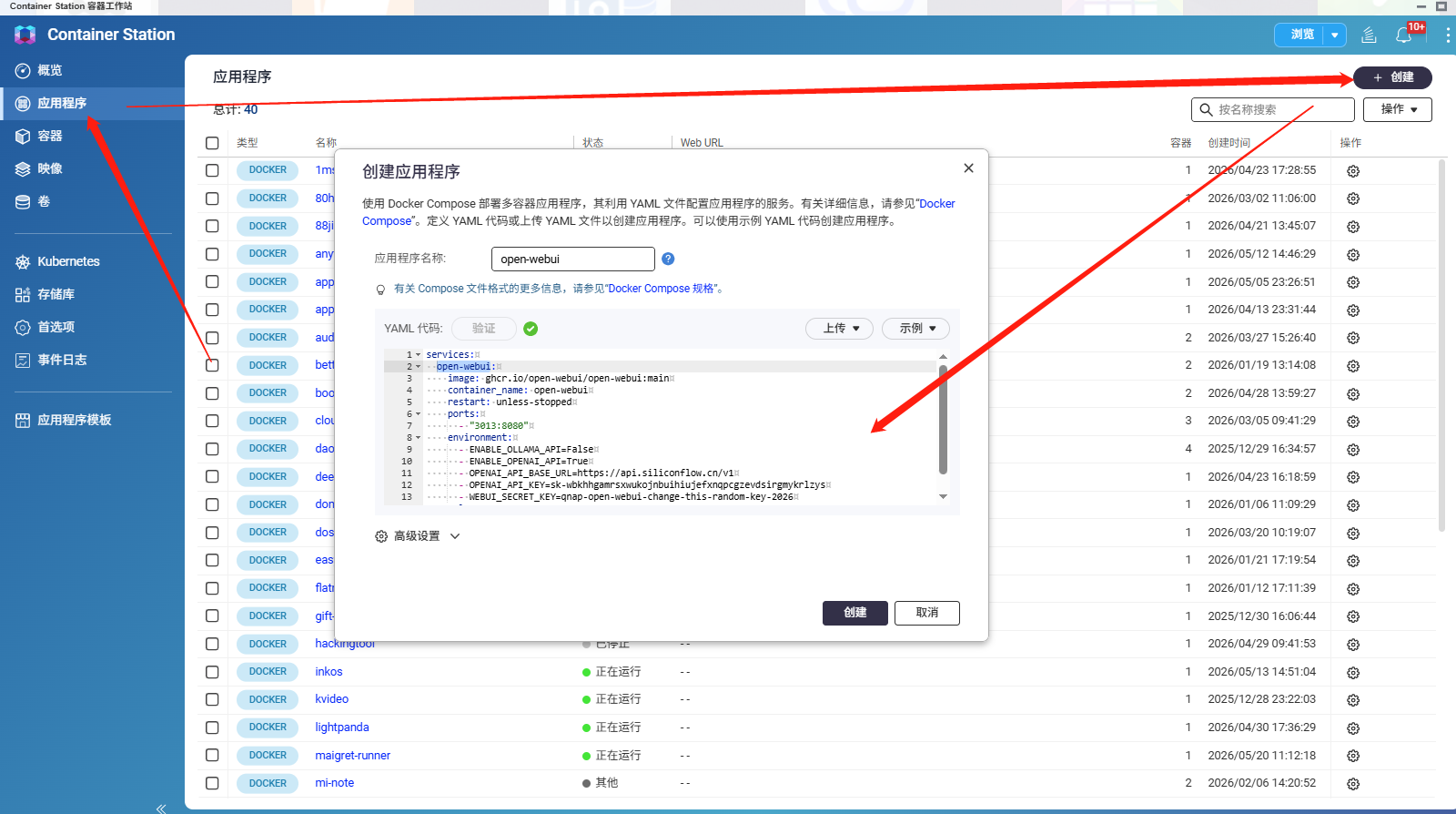
等待的过程有点久。
二、体验Open WebUI
容器部署好,等会在访问,否则会出现拒绝访问。同样还是在浏览器中的输入NAS的ip+端口号可以访问该项目。

第一次登陆首先需要进行注册管理员账号。

登入后的画面。
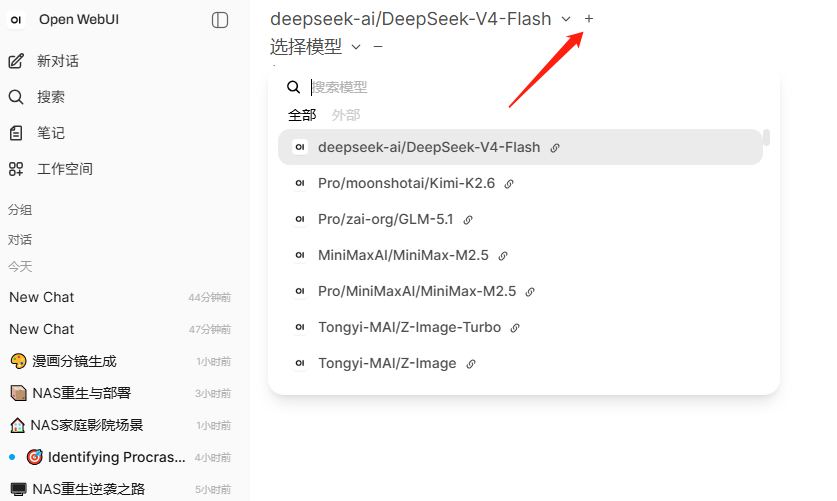
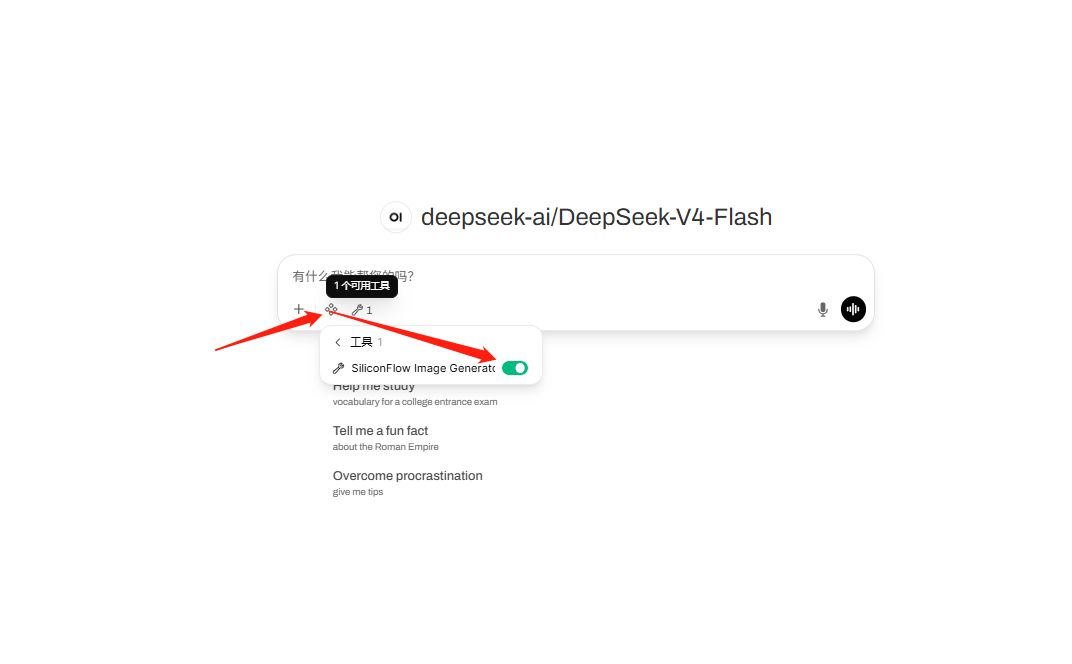
接着需要配置模型,点击上方的"+",选择模型,推荐模型:deepseek-ai/DeepSeek-V4-Flash。
然后新建聊天,将之前撰写的小说,喂给Open WebUI。
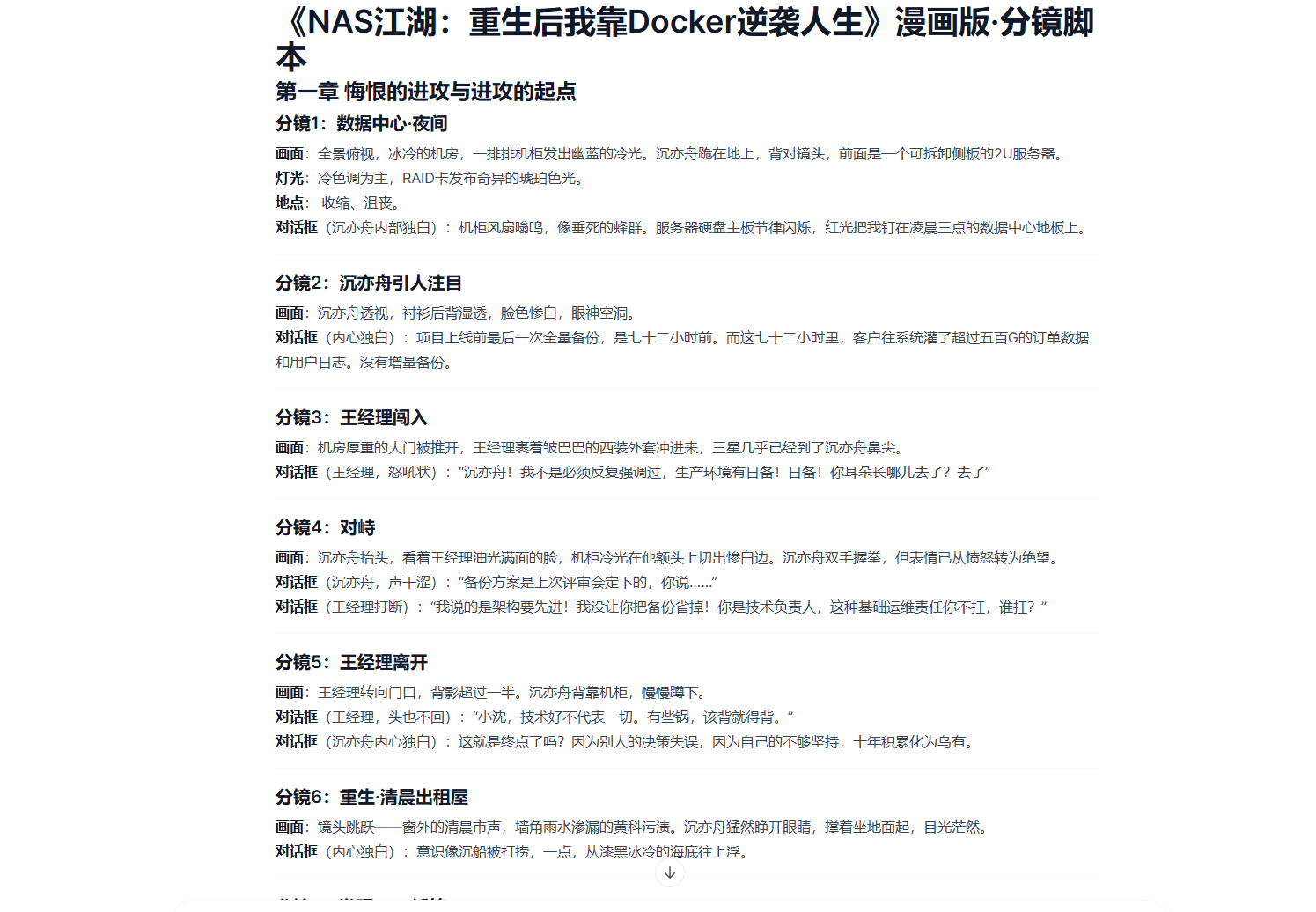
它会帮撰写号分镜。

文案没有修改的话,直接进行下一步,做出可以直接作图的清单。

下面开始需要添加生图的模型。点击左下角→【设置】→【管理员设置】
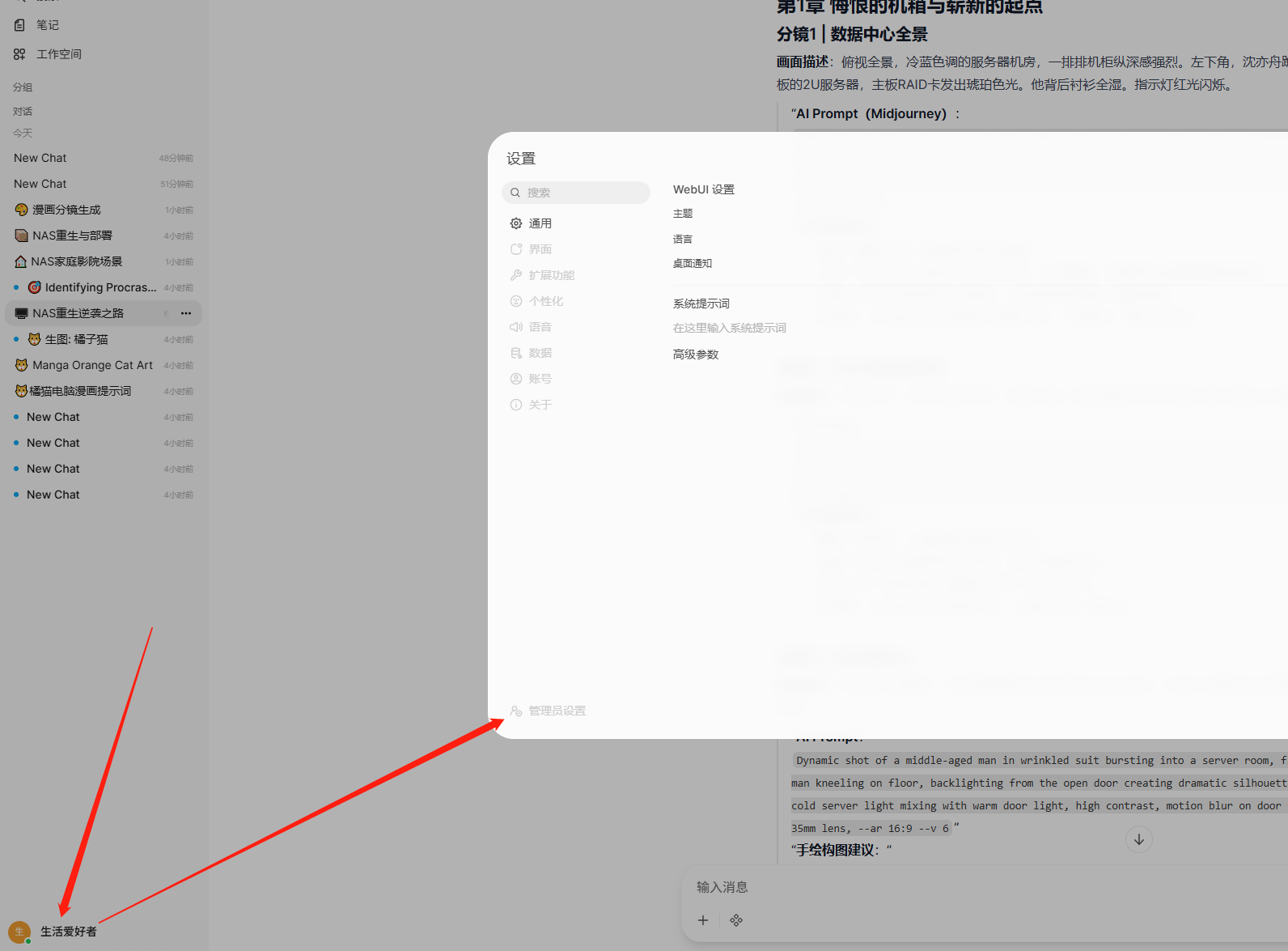
然后点击图像,首先将图片生成的滑块点开。按照要求填模型、图片尺寸、接口地址以及API密钥,最后点击保存。
生成的图片有漫画的味道,但是还不能将文字添加到图片上。有些文字甚至会乱码。



可以复制写好的分镜,直接粘贴到其它平台。
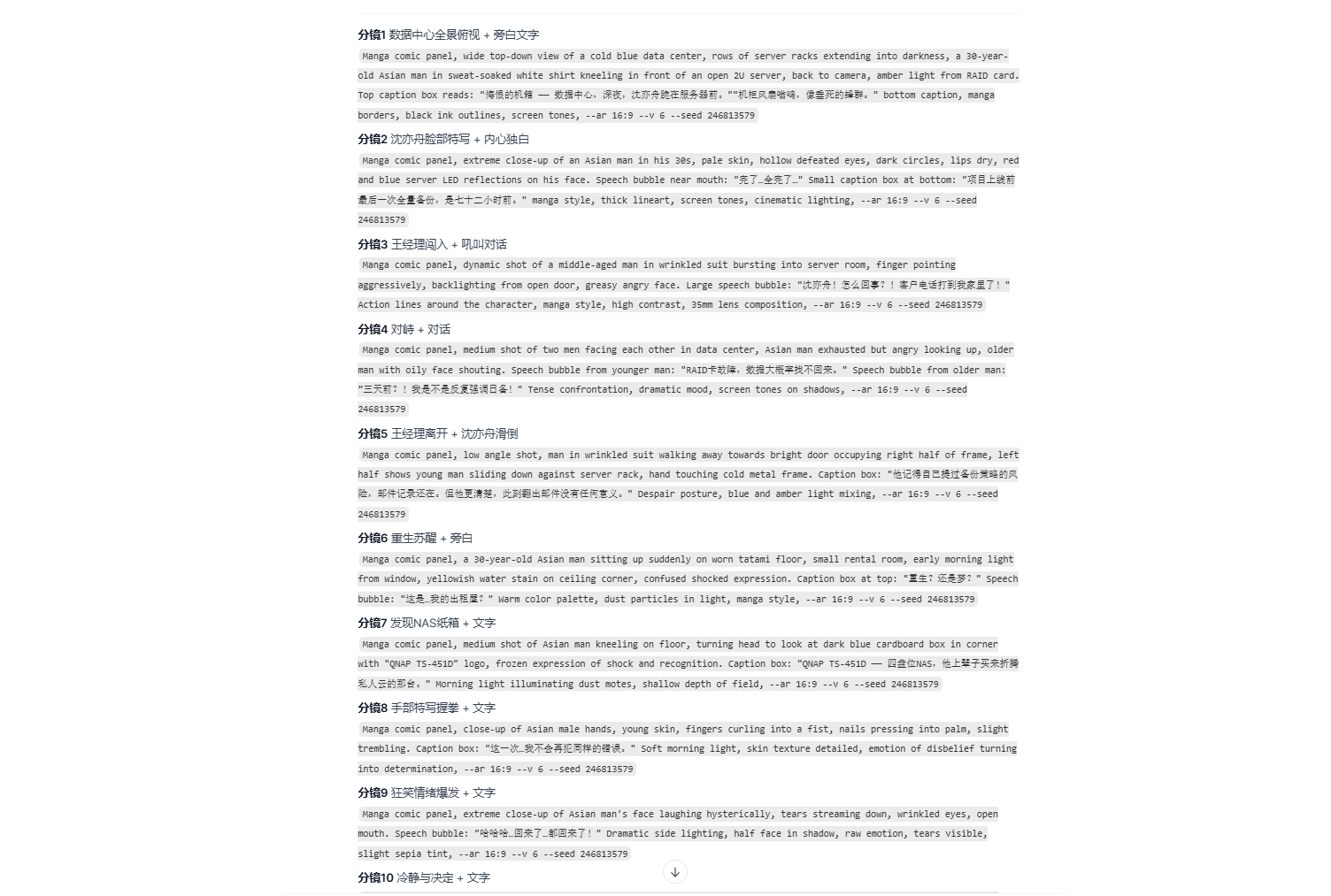
公司有ChatGPT的账号,直接丢进去后,直接帮做好漫画,就是开头为大家展示的图片。
下图是可用的yaml码,注意需要这个地方填入自己的api密钥。
把 sk-这里换成你的硅基流动API密钥 → 改为 sk-xxxxxxxxxxxxxxxxxxxxxxxx
services:
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
restart: unless-stopped
ports:
- "3013:8080"
environment:
-
ENABLE_OLLAMA_API=False
-
ENABLE_OPENAI_API=True
-
OPENAI_API_BASE_URL=https://api.siliconflow.cn/v1
-
OPENAI_API_KEY=sk-这里换成你的硅基流动API密钥
-
WEBUI_SECRET_KEY=qnap-open-webui-change-this-random-key-2026
volumes:
- /share/Container/open-webui/data:/app/backend/data
最后来说下再部署中遇到的问题,部署open-webui很简单,选择一些常用的模型,进行文字类创作没有问题,但是生图遇到不小的阻力。
可能添加完生图模型后,又没办法调用生图的模型,需要自己新建一个"硅基流动生图工具,让open-webui可以调用硅基流动的接口。

然后将下方的代码粘贴进去。
"""
title: SiliconFlow Image Generator
description: Generate images using SiliconFlow image generation API.
author: local
version: 1.0.0
"""
from pydantic import BaseModel, Field
from typing import Optional, Callable, Awaitable
import json
import urllib.request
import urllib.error
class Tools:
class Valves(BaseModel):
SILICONFLOW_API_KEY: str = Field(
default="",
description="SiliconFlow API Key, starts with sk-"
)
MODEL: str = Field(
default="Kwai-Kolors/Kolors",
description="SiliconFlow image model ID"
)
IMAGE_SIZE: str = Field(
default="1024x1024",
description="Image size, for example: 1024x1024"
)
NUM_INFERENCE_STEPS: int = Field(
default=20,
description="Number of inference steps"
)
GUIDANCE_SCALE: float = Field(
default=7.5,
description="Guidance scale"
)
def init(self):
self.valves = self.Valves()
async def generate_image(
self,
prompt: str,
image_size: Optionalstr = None,
event_emitter: OptionalCallable\[\[dict, AwaitableNone]] = None,
) -> str:
"""
Generate an image with SiliconFlow.
:param prompt: Image prompt. English prompts usually work better.
:param image_size: Optional image size, such as 1024x1024, 960x1280, 768x1024.
:return: Markdown image link.
"""
if not self.valves.SILICONFLOW_API_KEY:
return "请先在工具设置里填写 SiliconFlow API Key。"
if event_emitter:
await event_emitter(
{
"type": "status",
"data": {
"description": "正在调用硅基流动生成图片...",
"done": False,
},
}
)
url = "https://api.siliconflow.cn/v1/images/generations"
final_size = image_size or self.valves.IMAGE_SIZE
payload = {
"model": self.valves.MODEL,
"prompt": prompt,
"image_size": final_size,
"batch_size": 1,
"num_inference_steps": self.valves.NUM_INFERENCE_STEPS,
"guidance_scale": self.valves.GUIDANCE_SCALE,
}
request = urllib.request.Request(
url=url,
data=json.dumps(payload).encode("utf-8"),
headers={
"Authorization": f"Bearer {self.valves.SILICONFLOW_API_KEY}",
"Content-Type": "application/json",
},
method="POST",
)
try:
with urllib.request.urlopen(request, timeout=180) as response:
result = json.loads(response.read().decode("utf-8"))
except urllib.error.HTTPError as e:
detail = e.read().decode("utf-8", errors="ignore")
return f"硅基流动生图失败。HTTP {e.code}\n\n{detail}"
except Exception as e:
return f"硅基流动生图失败:{str(e)}"
image_url = None
images = result.get("images")
if isinstance(images, list) and len(images) > 0:
image_url = images0.get("url")
elif isinstance(images, dict):
image_url = images.get("url")
data = result.get("data")
if not image_url and isinstance(data, list) and len(data) > 0:
image_url = data0.get("url")
elif not image_url and isinstance(data, dict):
image_url = data.get("url")
if not image_url:
return "图片已生成,但没有解析到图片 URL。接口返回:\n\n```json\n" + json.dumps(result, ensure_ascii=False, indent=2) + "\n```"
if event_emitter:
await event_emitter(
{
"type": "status",
"data": {
"description": "图片生成完成。",
"done": True,
},
}
)
return f"图片生成完成:\n\n!generated image({image_url})\n\n图片链接是临时链接,请及时保存。"
在进行聊天的时候点击下方的小菱形图标,再将滑块点开,就可以调用生图的模型啦。
总结
Open WebUI 在NAS上部署比较简单,配上模型适合用于给漫画做分镜,笔者调用硅基流动模型生成的漫画图片画面感有漫画的感觉,但是没办法将文字嵌入到图片中。大家有好的方法也欢迎分享。