STREAM LOAD 允许您从本地文件系统或流式数据源导入数据。提交导入作业后,系统会同步运行该作业,并在作业完成后返回作业结果。您可以根据作业结果判断作业是否成功。有关 Stream Load 的应用场景、限制和支持的数据文件格式的信息,请参阅通过 Stream Load 从本地文件系统导入数据。
语法
curl --location-trusted -u <username>:<password> -XPUT <url>
(
data_desc
)
[opt_properties]用户名和密码,指定用于连接集群的账户的用户名和密码。这是一个必需参数。如果您使用的账户未设置密码,则只需输入
<username>:XPUT
指定 HTTP 请求方法。这是一个必需参数。Stream Load 仅支持 PUT 方法。
url
http://<fe_host>:<fe_http_port>/api/<database_name>/<table_name>/_stream_load| 参数 | 是否必填 | 描述 |
|---|---|---|
| fe_host | 是 | 集群中 FE 节点的 IP 地址。 注意 如果您将导入作业提交到特定的 BE 或 CN 节点,则必须输入该 BE 或 CN 节点的 IP 地址。 |
| fe_http_port | 是 | 集群中 FE 节点的 HTTP 端口号。默认端口号为 8030。 注意 如果您将导入作业提交到特定的 BE 或 CN 节点,则必须输入该 BE 或 CN 节点的 HTTP 端口号。默认端口号为 8030。 |
| database_name | 是 | 表所属的数据库名称。 |
| table_name | 是 | 表的名称。 |
data_desc(核心)
描述您要导入的数据文件。data_desc 描述符可以包含数据文件的名称、格式、列分隔符、行分隔符、目标分区以及与表的列映射。语法:
-T <file_path>
-H "format: CSV | JSON"
-H "column_separator: <column_separator>"
-H "row_delimiter: <row_delimiter>"
-H "columns: <column1_name>[, <column2_name>, ... ]"
-H "partitions: <partition1_name>[, <partition2_name>, ...]"
-H "temporary_partitions: <temporary_partition1_name>[, <temporary_partition2_name>, ...]"
-H "jsonpaths: [ \"<json_path1>\"[, \"<json_path2>\", ...] ]"
-H "strip_outer_array: true | false"
-H "json_root: <json_path>"
-H "ignore_json_size: true | false"
-H "compression: <compression_algorithm> | Content-Encoding: <compression_algorithm>"opt_properties
指定一些可选参数,这些参数应用于整个导入作业。语法:
-H "label: <label_name>"
-H "where: <condition1>[, <condition2>, ...]"
-H "max_filter_ratio: <num>"
-H "timeout: <num>"
-H "strict_mode: true | false"
-H "timezone: <string>"
-H "load_mem_limit: <num>"
-H "partial_update: true | false"
-H "partial_update_mode: row | column"
-H "merge_condition: <column_name>"实操演练(csv文件)
导入csv文件
准备:在本地创建一个example.csv文件,并写入数据
vim example.csv
# 写入以下数据
1,Lily,23
2,Rose,23
3,Alice,24
4,Julia,25进入StarRocks数据库创建数据库和表table1(测试)
msyql -uroot -P9030 -h127.0.0.1 -p
create database testdb;
use testdb;
CREATE TABLE `table1`
(
`id` int(11) NOT NULL COMMENT "user ID",
`name` varchar(65533) NULL COMMENT "user name",
`score` int(11) NOT NULL COMMENT "user score"
)
ENGINE=OLAP
PRIMARY KEY(`id`)
DISTRIBUTED BY HASH(`id`);包含id name 和score字段,对应example.csv文件的内容
现在设置导入参数
-XPUT
http://198.134.198.12:8030/api/testdb/table1/_stream_load198.134.198.12:8030填写对应的IP和端口,可以进入StarRocks数据库使用show proc frontends\G;查看http_port端口
定义导入标识标签
-H "label:label1"设置超时时间,最长不超过100秒
-H "timeout:100"设置错误容忍度,最大为0.2
-H "max_filter_ratio:0.2"指定用逗号 , 作为 CSV 列分隔符,文件格式一致
-H "column_separator:,"导入文件 -T 文件地址
-T example.csvHTTP 1.1 标准请求头
-H "Expect:100-continue"导入
curl --location-trusted -u root:StarRocks@123 -H "label:label1" \
-H "Expect:100-continue" \
-H "timeout:100" \
-H "column_separator:," \
-H "max_filter_ratio:0.2" \
-T example.csv \
-XPUT http://198.134.198.12:8030/api/testdb/table1/_stream_load导入作业完成后,系统以 JSON 格式返回作业结果:
{
"TxnId": 7399,
"Label": "label1",
"Db": "testdb",
"Table": "table1",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 4,
"NumberLoadedRows": 4,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 42,
"LoadTimeMs": 284,
"BeginTxnTimeMs": 1,
"StreamLoadPlanTimeMs": 3,
"ReadDataTimeMs": 0,
"WriteDataTimeMs": 107,
"CommitAndPublishTimeMs": 171
}| 参数名称 | 说明 |
|---|---|
| TxnId | 导入作业的事务 ID。 |
| Label | 导入作业的标签。 |
| Status | 此次导入的数据的最终状态。 * Success:表示数据导入成功,数据已经可见。 * Publish Timeout:表示导入作业已经成功提交,但是由于某种原因数据并不能立即可见。可以视作已经成功、不必重试导入。 * Label Already Exists:表示该标签已经被其他导入作业占用。数据可能导入成功,也可能是正在导入。 * Fail:表示数据导入失败。您可以指定标签重试该导入作业。 |
| Message | 导入作业的状态详情。如果导入作业失败,这里会返回具体的失败原因。 |
| NumberTotalRows | 读取到的总行数。 |
| NumberLoadedRows | 成功导入的总行数。只有当返回结果中的 Status 为 Success 时有效。 |
| NumberFilteredRows | 导入过程中因数据质量不合格而过滤掉的行数。 |
| NumberUnselectedRows | 导入过程中根据 WHERE 子句指定的条件而过滤掉的行数。 |
| LoadBytes | 此次导入的数据量大小。单位:字节 (Bytes)。 |
| LoadTimeMs | 此次导入所用的时间。单位:毫秒 (ms)。 |
| BeginTxnTimeMs | 导入作业开启事务的时长。 |
| StreamLoadPlanTimeMs | 导入作业生成执行计划的时长。 |
| ReadDataTimeMs | 导入作业读取数据的时长。 |
| WriteDataTimeMs | 导入作业写入数据的时长。 |
| CommitAndPublishTimeMs | 导入作业提交和数据发布的耗时。 |
如果导入作业失败,系统还会返回ErrorURL,例如
{"ErrorURL": "http://172.26.195.68:8045/api/_load_error_log?file=error_log_3a4eb8421f0878a6_9a54df29fd9206be"}可以wget下来查看详情
wget http://172.26.195.68:8045/api/_load_error_log?file=error_log_3a4eb8421f0878a6_9a54df29fd9206be进入StarRocks客户端查看数据是否导入成功
mysql> use testdb;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 4 | Julia | 25 |
| 1 | Lily | 23 |
| 2 | Rose | 23 |
| 3 | Alice | 24 |
+------+-------+-------+
4 rows in set (0.04 sec)导入JSON文件
在您的本地文件系统中,创建一个名为 example.json 的 JSON 文件。该文件由两列组成,依次表示城市 ID 和城市名称。
{"name": "Beijing", "code": 2}创建一个名为 table2 的主键表。该表由两列组成:id 和 city,其中 id 是主键。
CREATE TABLE `table2`
(
`id` int(11) NOT NULL COMMENT "city ID",
`city` varchar(65533) NULL COMMENT "city name"
)
ENGINE=OLAP
PRIMARY KEY(`id`)
DISTRIBUTED BY HASH(`id`);启动 Stream Load
运行以下命令将 example2.json 的数据导入到 table2 中:
curl -v --location-trusted -u root:StarRocks@123 -H "strict_mode: true" \
-H "Expect:100-continue" \
-H "format: json" -H "jsonpaths: [\"$.name\", \"$.code\"]" \
-H "columns: city,tmp_id, id = tmp_id * 100" \
-T example2.json -XPUT \
http://198.134.198.12:8030/api/testdb/table2/_stream_load- 如果您使用的账户未设置密码,则只需输入
<username>:。 - 您可以使用 SHOW FRONTENDS 查看 FE 节点的 IP 地址和 HTTP 端口。
example.json 由两个键 name 和 code 组成,映射到 table2 的 id 和 city 列,如下图所示。
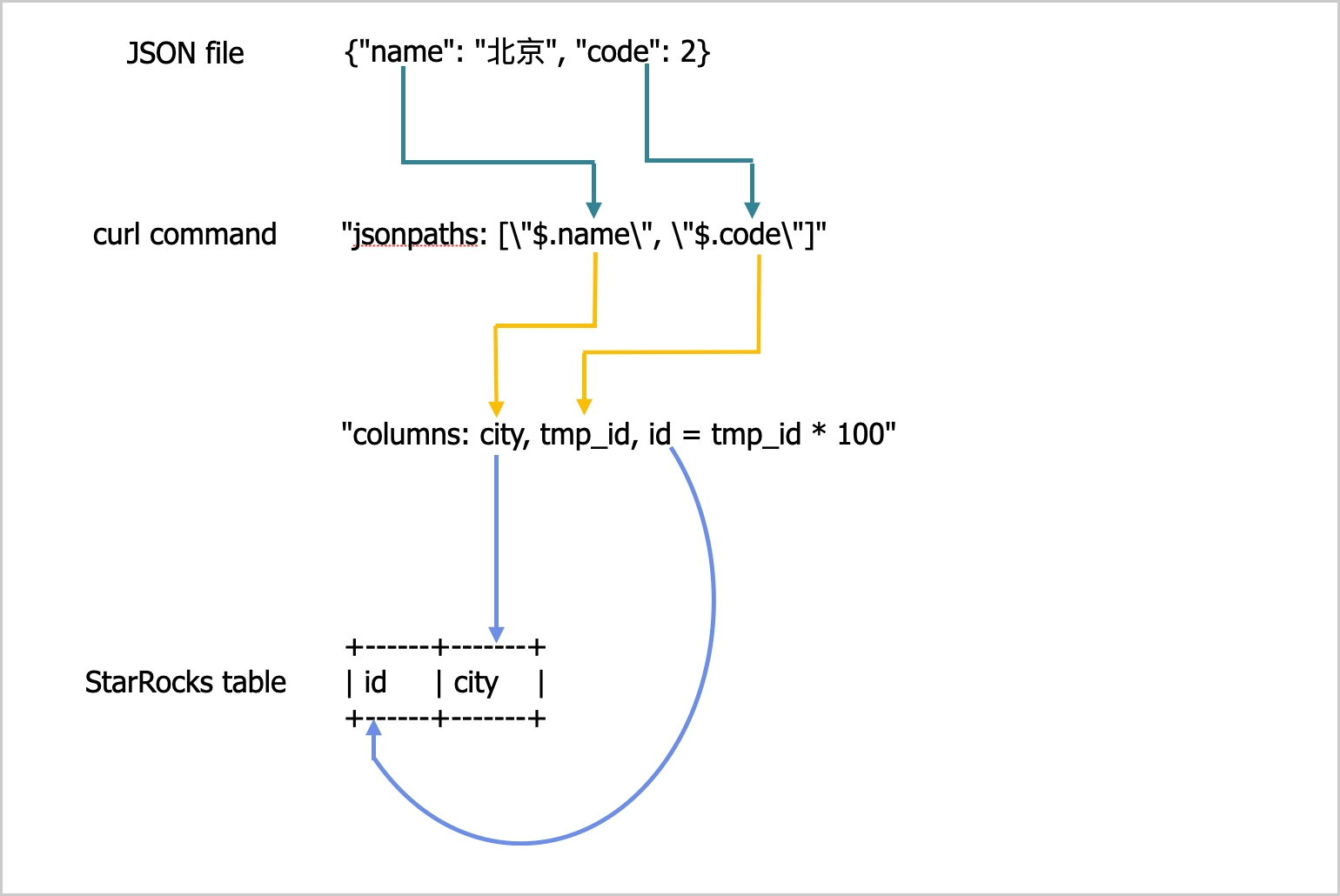
上述图中的映射描述如下:
-
StarRocks 提取
example2.json的name和code键,并将它们映射到jsonpaths参数中声明的name和code字段。 -
StarRocks 提取
jsonpaths参数中声明的name和code字段,并按顺序将它们映射到columns参数中声明的city和tmp_id字段。 -
StarRocks 提取
columns参数中声明的city和tmp_id字段,并按名称将它们映射到table2的city和id列。-H "columns: city,tmp_id, id = tmp_id * 100"
在上述示例中,example.json 中 code 的值在加载到 table2 的 id 列之前乘以 100。
有关 jsonpaths、columns 和 StarRocks 表列之间的详细映射,请参见 STREAM LOAD 中的"列映射"部分。
导入完成后,您可以查询 table2 以验证导入是否成功:
mysql> select * from testdb.table2;
+------+---------+
| id | city |
+------+---------+
| 200 | Beijing |
+------+---------+
1 row in set (0.04 sec)官方文档:https://docs.starrocks.io/zh/docs/loading/StreamLoad/
大家有空可以看看CLup平台:
https://www.csudata.com/clup/manual![]() https://www.csudata.com/clup/manual
https://www.csudata.com/clup/manual