翻译自:https://implicit-layers-tutorial.org/implicit_functions/
不动点的高效微分
不动点求解器
让我们从数值不动点开始,比如那些构成深度平衡模型(DEQ)基础的不动点。我们的主要目标是解释如何高效地对由不动点方程隐式定义的函数进行自动微分。
数学上,对于某个函数 f : R n → R n f : \mathbb R^n \to \mathbb R^n f:Rn→Rn,如果
z = f ( z ) , z = f(z), z=f(z),
则称 z ∈ R n z \in \mathbb R^n z∈Rn 是 f f f 的不动点。
不动点的一种理解方式是,如果我们应用 f f f,我们停留在同一个地方。许多迭代算法,如优化算法,都符合这种模式。因此,我们在这里为不动点开发的高效自动微分方法可以立即应用于优化例程的高效微分,只需选择 f f f 为所讨论优化算法的更新函数即可。
另一种理解不动点方程的方式是将其作为一个(非线性)方程组,就像我们通常将其指定为 g ( z ) = 0 g(z) = 0 g(z)=0 一样,只是这里 z z z 出现在等式两边。实际上,如果我们选择 g ( z ) = f ( z ) − z g(z) = f(z) - z g(z)=f(z)−z,那么就可以化简为通常的非线性方程形式。
更一般地,我们可能有一个参数化 函数 f : R p × R n → R n f : \mathbb R^p \times \mathbb R^n \to \mathbb R^n f:Rp×Rn→Rn,它接受一个参数向量 a ∈ R p a \in \mathbb R^p a∈Rp。那么我们可以将不动点写为
z = f ( a , z ) . z = f(a, z). z=f(a,z).
这对应于一个参数化方程组。一旦涉及参数,我们可能会问诸如此类的问题:当我们改变参数值时,不动点会如何变化?但在深入这类问题之前,让我们先看看如何计算数值不动点。
也许计算数值不动点最简单的方法是朴素的前向迭代 ,我们迭代 z k + 1 = f ( z k ) z_{k+1} = f(z_k) zk+1=f(zk) 直到 z k + 1 z_{k+1} zk+1 与 z k z_k zk 足够接近:
python
import jax.numpy as jnp
def fwd_solver(f, z_init):
z_prev, z = z_init, f(z_init)
while jnp.linalg.norm(z_prev - z) > 1e-5:
z_prev, z = z, f(z)
return z这种方法是否成功取决于我们如何初始化以及 f f f 的性质(至少包括 f f f 是否有不动点!)。即使它确实成功,也可能需要很多步才能收敛。
更复杂的方法是牛顿迭代 ,它利用 f f f 的导数信息来迈出更智能的步长(代价是每一步使用更多计算):
python
import jax
def newton_solver(f, z_init):
f_root = lambda z: f(z) - z
g = lambda z: z - jnp.linalg.solve(jax.jacobian(f_root)(z), f_root(z))
return fwd_solver(g, z_init)第三种方法是 Anderson 加速:
python
def anderson_solver(f, z_init, m=5, lam=1e-4, max_iter=50, tol=1e-5, beta=1.0):
x0 = z_init
x1 = f(x0)
x2 = f(x1)
X = jnp.concatenate([jnp.stack([x0, x1]), jnp.zeros((m - 2, *jnp.shape(x0)))])
F = jnp.concatenate([jnp.stack([x1, x2]), jnp.zeros((m - 2, *jnp.shape(x0)))])
res = []
for k in range(2, max_iter):
n = min(k, m)
G = F[:n] - X[:n]
GTG = jnp.tensordot(G, G, [list(range(1, G.ndim))] * 2)
H = jnp.block([[jnp.zeros((1, 1)), jnp.ones((1, n))],
[ jnp.ones((n, 1)), GTG]]) + lam * jnp.eye(n + 1)
alpha = jnp.linalg.solve(H, jnp.zeros(n+1).at[0].set(1))[1:]
xk = beta * jnp.dot(alpha, F[:n]) + (1-beta) * jnp.dot(alpha, X[:n])
X = X.at[k % m].set(xk)
F = F.at[k % m].set(f(xk))
res = jnp.linalg.norm(F[k % m] - X[k % m]) / (1e-5 + jnp.linalg.norm(F[k % m]))
if res < tol:
break
return xk有了这些求解器,我们就可以计算一些不动点了!我们将研究一个玩具 DEQ 不动点层,它可以使用我们开发的任何求解器:
python
def fixed_point_layer(solver, f, params, x):
z_star = solver(lambda z: f(params, x, z), z_init=jnp.zeros_like(x))
return z_star该层接受以下参数:
- 一个求解器,命名为
solver, - 要寻找不动点的函数
f, - 参数
params, - 输入值
x。
有了这些输入,它计算出的输出就是该函数的不动点。
以下是我们将使用的函数 f,其参数只是一个权重矩阵 W:
python
f = lambda W, x, z: jnp.tanh(jnp.dot(W, z) + x)我们将为参数和输入初始化一些随机值:
python
from jax import random
ndim = 10
W = random.normal(random.PRNGKey(0), (ndim, ndim)) / jnp.sqrt(ndim)
x = random.normal(random.PRNGKey(1), (ndim,))现在我们可以使用求解器来找到不动点:
python
z_star = fixed_point_layer(fwd_solver, f, W, x)
print(z_star)[ 0.00649604 -0.7015958 -0.984715 -0.04196563 -0.615222 -0.4818384
0.5783121 0.9556704 -0.08373158 0.8447803 ]
python
z_star = fixed_point_layer(newton_solver, f, W, x)
print(z_star)[ 0.00649406 -0.701595 -0.98471504 -0.04196503 -0.6152214 -0.48183855
0.5783122 0.9556704 -0.08372932 0.8447797 ]
python
z_star = fixed_point_layer(anderson_solver, f, W, x)
print(z_star)[ 0.00649838 -0.70159334 -0.9847146 -0.04194273 -0.6152194 -0.48183322
0.5783227 0.95566964 -0.08373427 0.84477484]在数值容差范围内,我们可以看到,无论使用哪种求解器,我们都计算出了大致相同的数值不动点。也就是说,我们将要计算的值与计算它的方式解耦了。
通过迭代求解器的朴素自动微分
我们已经可以对 fixed_point_layer 函数进行微分。例如,我们可以使用 jax.grad 来计算输出之和关于参数矩阵的梯度:
python
g = jax.grad(lambda W: fixed_point_layer(fwd_solver, f, W, x).sum())(W)
print(g[0])[ 0.00756657 -0.81259 -1.1404793 -0.04861288 -0.7125525 -0.5580555
0.6697878 1.1068411 -0.0970227 0.97842234]正如我们所料,在数值容差范围内,该梯度值不依赖于计算不动点的方法:
python
g = jax.grad(lambda W: fixed_point_layer(newton_solver, f, W, x).sum())(W)
print(g[0])[ 0.0075213 -0.812574 -1.1404784 -0.04860311 -0.7125377 -0.5580563
0.66979027 1.1068394 -0.09697371 0.97840786]如果我们已经可以通过这些不动点层进行微分,还有什么需要做的呢?
问题在于,以这种方式微分是极其低效的。我们正在微分求解器的所有展开的迭代。对于每一步,我们的自动微分工具都在存储前向传播中的值,以便在反向传播中使用。这意味着使用大量内存!
为了做得更好,我们需要从隐式函数微分的角度来思考。
隐函数定理
首先,让我们回顾一些基础知识并建立我们的微分符号。对于函数 f : R n → R m f : \mathbb R^n \to \mathbb R^m f:Rn→Rm,我们将点 x ∈ R n x \in \mathbb R^n x∈Rn 处的导数记为
∂ f ( x ) : R n → R m . \partial f(x) : \mathbb R^n \to \mathbb R^m. ∂f(x):Rn→Rm.
换言之, ∂ f ( x ) \partial f(x) ∂f(x) 也是一个函数,将输入空间 R n \mathbb R^n Rn 上的扰动映射到输出空间 R m \mathbb R^m Rm 上的扰动。此外, ∂ f ( x ) \partial f(x) ∂f(x) 是线性的。我们可以考虑在 x x x 处写出 f f f 的一阶 Taylor 级数:
f ( x + v ) = f ( x ) + ∂ f ( x ) v + O ( ∥ v ∥ 2 ) , f(x + v) = f(x) + \partial f(x) v + \mathcal O(\|v\|^2), f(x+v)=f(x)+∂f(x)v+O(∥v∥2),
其中 v ∈ R n v \in \mathbb R^n v∈Rn 是一个扰动向量。
注意,因为 ∂ f ( x ) \partial f(x) ∂f(x) 是线性的,我们将它对向量 v v v 的应用记为 ∂ f ( x ) v \partial f(x) v ∂f(x)v,使用并列而不是括号。这很方便,并且强调了我们也可以将 ∂ f ( x ) \partial f(x) ∂f(x) 视为一个矩阵(关于输入和输出空间的标准基):
∂ f ( x ) ∈ R m × n . \partial f(x) \in \mathbb R^{m \times n}. ∂f(x)∈Rm×n.
在本节中,我们主要将 ∂ f ( x ) \partial f(x) ∂f(x) 作为矩阵来处理。
最后一个符号是关于多元函数的。当我们只想对其中一个参数求导时,我们会在 ∂ \partial ∂ 运算符上使用下标:
∂ 0 f ( x , y ) ≜ ∂ g ( x ) where g ( x ) = f ( x , y ) , ∂ 1 f ( x , y ) ≜ ∂ g ( y ) where g ( y ) = f ( x , y ) . \begin{aligned} \partial_0 f(x, y) &\triangleq \partial g(x) \text{ where } g(x) = f(x, y), \\ \partial_1 f(x, y) &\triangleq \partial g(y) \text{ where } g(y) = f(x, y). \end{aligned} ∂0f(x,y)∂1f(x,y)≜∂g(x) where g(x)=f(x,y),≜∂g(y) where g(y)=f(x,y).
这个符号基于 Spivak 的经典著作《Calculus on Manifolds》(1965),也用于 Sussman 和 Wisdom 的《Structure and Interpretation of Classical Mechanics》(2015)和《Functional Differential Geometry》(2013)。后两本书都是开放获取的。具体参见《Functional Differential Geometry》的序言,了解对这种符号的辩护。这种符号的另一个优点是它与 JAX 的自动微分 API 有直接对应关系!
现在我们准备陈述我们将在这些笔记中使用的隐函数定理的版本。
隐函数定理。
设 f : R p × R n → R n f : \mathbb R^p \times \mathbb R^n \to \mathbb R^n f:Rp×Rn→Rn 且 a 0 ∈ R p a_0 \in \mathbb R^p a0∈Rp, z 0 ∈ R n z_0 \in \mathbb R^n z0∈Rn 满足
- f ( a 0 , z 0 ) = 0 f(a_0, z_0) = 0 f(a0,z0)=0,且
- f f f 连续可微且 Jacobian ∂ 1 f ( a 0 , z 0 ) ∈ R n × n \partial_1 f(a_0, z_0) \in \mathbb R^{n \times n} ∂1f(a0,z0)∈Rn×n 非奇异。
那么存在包含 a 0 a_0 a0 和 z 0 z_0 z0 的开集 S a 0 ⊂ R p S_{a_0} \subset \mathbb R^p Sa0⊂Rp 和 S z 0 ⊂ R n S_{z_0} \subset \mathbb R^n Sz0⊂Rn,以及一个唯一的连续函数 z ∗ : S a 0 → S z 0 z^* : S_{a_0} \to S_{z_0} z∗:Sa0→Sz0,使得
- z 0 = z ∗ ( a 0 ) z_0 = z^*(a_0) z0=z∗(a0),
- f ( a , z ∗ ( a ) ) = 0 ∀ a ∈ S a 0 f(a, z^*(a)) = 0 \quad \forall a \in S_{a_0} f(a,z∗(a))=0∀a∈Sa0,且
- z ∗ z^* z∗ 在 S a 0 S_{a_0} Sa0 上可微。
关于详细历史以及关于隐函数定理多种变体,参见 Krantz 和 Parks 的著作《The Implicit Function Theorem: History, Theory, and Applications》(2002)。
我们可以将 f ( a , z ) = 0 f(a, z) = 0 f(a,z)=0 视为在 z z z 上定义了一个由 a a a 参数化的非线性方程组。点 ( a 0 , z 0 ) (a_0, z_0) (a0,z0) 是一个名义解。该定理的强大之处在于,它告诉我们我们可以考虑一个解映射 函数 z ∗ z^* z∗,它满足
f ( a , z ∗ ( a ) ) = 0 ∀ a ∈ S a 0 . f(a, z^*(a)) = 0 \quad \forall a \in S_{a_0}. f(a,z∗(a))=0∀a∈Sa0.
注意两边都是 a a a 的函数,所以我们可以对两边关于 a a a 求导,并在点 ( a 0 , z 0 ) (a_0, z_0) (a0,z0) 处求值,得到
∂ 0 f ( a 0 , z 0 ) + ∂ 1 f ( a 0 , z 0 ) ∂ z ∗ ( a 0 ) = 0. \partial_0 f(a_0, z_0) + \partial_1 f(a_0, z_0) \partial z^*(a_0) = 0. ∂0f(a0,z0)+∂1f(a0,z0)∂z∗(a0)=0.
整理后,我们发现解映射的 Jacobian 必须由下式给出
∂ z ∗ ( a 0 ) = − ∂ 1 f ( a 0 , z 0 ) − 1 ∂ 0 f ( a 0 , z 0 ) . \partial z^*(a_0) = - \\partial_1 f(a_0, z_0)^{-1} \partial_0 f(a_0, z_0). ∂z∗(a0)=−∂1f(a0,z0)−1∂0f(a0,z0).
也就是说,解映射的 Jacobian 可以仅用 f f f 在解点 ( a 0 , z 0 ) (a_0, z_0) (a0,z0) 处的 Jacobian 来表示。换句话说,给定 a 0 a_0 a0,无论我们如何求解方程来计算 z 0 z_0 z0,我们都可以仅使用解点处的导数信息来计算 Jacobian。这可以帮助我们避免微分通过迭代求解器!
我们也可以将其应用于不动点。隐函数定理可以直接应用,因为我们可以将不动点 z = f ( a , z ) z = f(a, z) z=f(a,z) 通过 g ( a , z ) ≜ f ( a , z ) − z g(a, z) \triangleq f(a, z) - z g(a,z)≜f(a,z)−z 转化为非线性系统 g ( a , z ) = 0 g(a, z) = 0 g(a,z)=0,但我们可以重新进行上述导数计算以获得一个简洁的表达式。
为了得到不动点解映射 Jacobian 的简洁表达式,我们从不动点开始
z 0 = f ( a 0 , z 0 ) , z_0 = f(a_0, z_0), z0=f(a0,z0),
然后考虑局部解映射 z ∗ z^* z∗,它作为 a 0 a_0 a0 附近 a a a 的函数满足
z ∗ ( a ) = f ( a , z ∗ ( a ) ) z^*(a) = f(a, z^*(a)) z∗(a)=f(a,z∗(a))
然后对两边求导并在 ( a 0 , z 0 ) (a_0, z_0) (a0,z0) 处求值:
∂ z ∗ ( a 0 ) = ∂ 0 f ( a 0 , z 0 ) + ∂ 1 f ( a 0 , z 0 ) ∂ z ∗ ( a 0 ) , \partial z^*(a_0) = \partial_0 f(a_0, z_0) + \partial_1 f(a_0, z_0) \partial z^*(a_0), ∂z∗(a0)=∂0f(a0,z0)+∂1f(a0,z0)∂z∗(a0),
整理得到
∂ z ∗ ( a 0 ) = I − ∂ 1 f ( a 0 , z 0 ) − 1 ∂ 0 f ( a 0 , z 0 ) . \partial z^*(a_0) = I - \\partial_1 f(a_0, z_0)^{-1} \partial_0 f(a_0, z_0). ∂z∗(a0)=I−∂1f(a0,z0)−1∂0f(a0,z0).
同样,我们得到了不动点解的导数表达式。我们仅使用函数 f f f 在不动点本身的导数信息。我们可以节省内存!
现在我们有了不动点解映射的导数的数学表达式,我们只需要将其连接到我们的自动微分系统。
自动微分的两个变换:JVP 和 VJP
自动微分(autodiff)建立在两个变换之上:Jacobian-向量积(JVP)和向量-Jacobian 积(VJP)。为了增强我们对不动点求解器和其他隐式函数的自动微分能力,我们必须将我们的数学结果连接到 JVP 和 VJP。
在数学上,Jacobian-向量积(JVP) 建模了映射
( x , v ) ↦ ( f ( x ) , ∂ f ( x ) v ) , (x, v) \mapsto (f(x), \, \partial f(x) v), (x,v)↦(f(x),∂f(x)v),
其中 f : R n → R m f : \mathbb R^n \to \mathbb R^m f:Rn→Rm, x ∈ R n x \in \mathbb R^n x∈Rn, v ∈ R n v \in \mathbb R^n v∈Rn。
JVP 回答诸如此类的问题:
- 在给定的输入点 x x x 处,如果我们使用一个向量 v v v扰动输入,输出的变化(一阶近似)是多少?
- Taylor 级数 f ( x + v ) = f ( x ) + ∂ f ( x ) v + O ( ∥ v ∥ 2 ) f(x + v) = f(x) + \partial f(x) v + \mathcal O(\|v\|^2) f(x+v)=f(x)+∂f(x)v+O(∥v∥2) 的前两项是什么?
在程序中,JVP 是前向模式自动微分的基础,也就是说,如果你的自动微分系统声称实现了前向模式,那就意味着它提供了一种计算编程语言中函数的 JVP 的方法。
在 JAX 中,我们可以使用 jax.jvp 来计算 JVP:
python
def f(x):
return jnp.sin(x) * x ** 2
x = 2.
y = f(x)
print(y)3.6371896
python
delta_x = 1.
y, delta_y = jax.jvp(f, (x,), (delta_x,))
print(y)
print(delta_y)3.6371896
1.9726022这里 Δ y \Delta y Δy 表示 Δ y = ∂ f ( x ) Δ x \Delta y = \partial f(x) \Delta x Δy=∂f(x)Δx 的值,在 x = 2 x = 2 x=2 和 Δ x = 1 \Delta x = 1 Δx=1 处求值。我们可以用数值近似来检查结果:
python
eps = 1e-4
delta_y_approx = (f(x + eps * v) - f(x)) / eps
print(delta_y_approx)1.97649如果你的自动微分系统实现了 JVP,那就意味着你可以一次一列 地计算 Jacobian 矩阵。也就是说,要计算完整的矩阵 ∂ f ( x ) \partial f(x) ∂f(x),你可以将 one-hot(标准基)向量作为 v v v 输入到 JVP 计算中,每个这样的输入将揭示 Jacobian 矩阵的一列。每次 JVP 的计算成本与原始函数 f f f 的评估成本相似,对于典型函数,通常只需要 FLOPs 和内存的一个小常数倍数。
相比之下,向量-Jacobian 积(VJP) 让我们一次一行 地计算 Jacobian 矩阵。数学上,VJP 是映射
( x , w ) ↦ ( f ( x ) , w T ∂ f ( x ) ) , (x, w) \mapsto (f(x), \, w^\mathsf{T} \partial f(x)), (x,w)↦(f(x),wT∂f(x)),
其中 w ∈ R m w \in \mathbb R^m w∈Rm 是一个看起来像 f f f 的输出的向量。JVP 操作于扰动,而 VJP 中涉及的向量的解释则稍微微妙一些。VJP 回答诸如此类的问题:
- 在给定的输入点 x ∈ R n x \in \mathbb R^n x∈Rn 处,如果我们有一个向量 w ∈ R m w \in \mathbb R^m w∈Rm,它表示输出扰动 Δ y \Delta y Δy 上的一个标量值线性函数(例如,表示一个标量值损失函数如何随输出的微小变化而变化),那么表示输入扰动 Δ x \Delta x Δx 上的相应线性函数的向量是什么?也就是说,什么 λ ∈ R n \lambda \in \mathbb R^n λ∈Rn 使得如下公式对任意 Δ x \Delta x Δx 成立?(其中我们定义了 Δ y = ∂ f ( x ) Δ x \Delta y = \partial f(x) \, \Delta x Δy=∂f(x)Δx)
⟨ w , Δ y ⟩ = ⟨ w , ∂ f ( x ) Δ x ⟩ = ⟨ λ , Δ x ⟩ , \langle w, \, \Delta y \rangle = \langle w, \, \partial f(x) \, \Delta x \rangle = \langle \lambda, \, \Delta x \rangle, ⟨w,Δy⟩=⟨w,∂f(x)Δx⟩=⟨λ,Δx⟩,
这种精确(尽管抽象)的解释在 ODE 微分等上下文中被证明是有用的,在这些上下文中我们并不总是有矩阵代数表达式可用,而必须处理更抽象的线性映射。
撇开精确的解释不谈,关键思想是 VJP 让我们一次一行地构建 Jacobian 矩阵,其 FLOPs 计算成本仅是对原始函数求值成本的一个小常数倍数。然而,VJP 的内存成本与计算的"深度"概念成比例,使其内存密集得多。
在程序中,VJP 是反向模式 自动微分的基础,也就是说,如果你的自动微分系统声称实现了反向模式,那就意味着它提供了一种计算编程语言中函数的 VJP 的方法。反向模式在机器学习中如此无处不在的原因在于 VJP 与标量值函数的梯度之间的关系,以及基于梯度的标量值损失函数优化的重要性。如果我们有一个定义在神经网络参数上的标量值损失函数 ℓ \ell ℓ,其中
ℓ : R n → R \ell : \mathbb R^n \to \mathbb R ℓ:Rn→R
并且对于某些神经网络我们可能有 n ≈ 10 9 n \approx 10^9 n≈109,我们是更愿意一次一行地计算 ℓ \ell ℓ 的 Jacobian 矩阵,还是一次一列地计算?(注意 ℓ \ell ℓ 的 Jacobian 有一行和十亿列!)
实际上,对于标量值函数 f f f,梯度 ∇ f ( x ) ∈ R n \nabla f(x) \in \mathbb R^n ∇f(x)∈Rn 的一个好的数学定义,是使得如下公式对所有向量 v ∈ R n v \in \mathbb R^n v∈Rn 成立的向量:
⟨ ∇ f ( x ) , v ⟩ = ∂ f ( x ) v \langle \nabla f(x), \, v \rangle = \partial f(x) v ⟨∇f(x),v⟩=∂f(x)v
我们可以通过简单地在 ( x , 1 ) (x, 1) (x,1) 处求值,从 VJP 映射 ( x , w ) ↦ ( f ( x ) , w T ∂ f ( x ) ) (x, w) \mapsto (f(x), \, w^\mathsf{T} \partial f(x)) (x,w)↦(f(x),wT∂f(x)) 计算出 ∇ f ( x ) \nabla f(x) ∇f(x)。实际上,jax.grad 本质上被定义为
python
def grad(f):
def gradfun(x):
_, f_vjp = jax.vjp(f, x)
grad_val, = f_vjp(1.)
return grad_val
return gradfun你可能已经猜到了,jax.vjp 是我们在 JAX 中计算 VJP 的方法:
python
def f(x):
return jnp.sin(x) * x ** 2
x = 2.
y = f(x)
print(y)3.6371896
python
w = 1.
y, f_vjp = jax.vjp(f, x)
lmbda, = f_vjp(w)
print(y)
print(lmbda)3.6371896
1.9726022JVP 和 VJP 之所以是自动微分的基本构建块,与函数组合有关。如果我们有两个函数的组合 f = g ∘ h f = g \circ h f=g∘h,我们可以通过组合 g g g 和 h h h 的 JVP 来写出 f f f 的 JVP:
python
h = jnp.sin
g = lambda x: x ** 3
def f_jvp(x, delta_x):
y, delta_y = jax.jvp(h, (x,), (delta_x,))
z, delta_z = jax.jvp(g, (y,), (delta_y,))
return z, delta_z
z, delta_z = f_jvp(1., 1.)
print(z)
print(delta_z)0.59582317
1.1477209
python
# 检查与应用于 f 的 jax.jvp 是否一致
f = lambda x: g(h(x))
z, delta_z = jax.jvp(f, (1.,), (1.,))
print(z)
print(delta_z)0.59582317
1.1477209类似地,对于相同的组合 f = g ∘ h f = g \circ h f=g∘h,我们可以通过组合 g g g 和 h h h 的 VJP 来写出 f f f 的 VJP:
python
def f_vjp(x, w):
y, h_vjp = jax.vjp(h, x)
z, g_vjp = jax.vjp(g, y)
lmbda_y, = g_vjp(w)
lmbda_x, = h_vjp(lmbda_y)
return z, lmbda_x
python
z, lmbda = f_vjp(1., 1.)
print(z)
print(lmbda)0.59582317
1.1477209
python
# 检查与应用于 f 的 jax.vjp 是否一致
z, f_vjp_ = jax.vjp(f, 1.)
lmbda, = f_vjp_(1.)
print(z)
print(lmbda)0.59582317
1.1477209回到不动点:不动点 JVP 和 VJP
现在我们可以将我们的数学隐式微分表达式连接到 JAX 的自动微分!回顾一下,对于不动点解映射 z ∗ z^* z∗,对于任意参数值 a ∈ R p a \in \mathbb R^p a∈Rp,它给出不动点方程的解
z ∗ ( a ) = f ( a , z ∗ ( a ) ) , z^*(a) = f(a, z^*(a)), z∗(a)=f(a,z∗(a)),
我们推导出在特定点 a 0 a_0 a0(其中 z 0 = z ∗ ( a 0 ) z_0 = z^*(a_0) z0=z∗(a0))处,必有
∂ z ∗ ( a 0 ) = I − ∂ 1 f ( a 0 , z 0 ) − 1 ∂ 0 f ( a 0 , z 0 ) . \partial z^*(a_0) = I - \\partial_1 f(a_0, z_0)^{-1} \partial_0 f(a_0, z_0). ∂z∗(a0)=I−∂1f(a0,z0)−1∂0f(a0,z0).
这个表达式将解映射在某点的 Jacobian 与函数 f f f 在该点的 Jacobian 联系起来。为了将其连接到 JAX,我们只需要推导出相应的 JVP 和 VJP 表达式。
对于 JVP,我们想要计算 ( a 0 , v ) ↦ ( z ∗ ( a 0 ) , ∂ z ∗ ( a 0 ) v ) (a_0, v) \mapsto (z^*(a_0), \, \partial z^*(a_0) v) (a0,v)↦(z∗(a0),∂z∗(a0)v),所以我们有
∂ z ∗ ( a 0 ) v = I − ∂ 1 f ( a 0 , z 0 ) − 1 ∂ 0 f ( a 0 , z 0 ) v . \partial z^*(a_0) v = I - \\partial_1 f(a_0, z_0)^{-1} \partial_0 f(a_0, z_0) v. ∂z∗(a0)v=I−∂1f(a0,z0)−1∂0f(a0,z0)v.
我们可以分两步计算这个表达式:首先,通过应用 f f f 的适当 JVP 计算 u = ∂ 0 f ( a 0 , z 0 ) v u = \partial_0 f(a_0, z_0) v u=∂0f(a0,z0)v。然后,通过整理得到方程
w = u + ∂ 1 f ( a 0 , z 0 ) w , w = u + \partial_1 f(a_0, z_0) w, w=u+∂1f(a0,z0)w,
计算最终值 w = I − ∂ 1 f ( a 0 , z 0 ) − 1 u w = I - \\partial_1 f(a_0, z_0)^{-1} u w=I−∂1f(a0,z0)−1u。注意,这本身将 w w w 表达为一个仿射函数的不动点,即函数 w ↦ u + ∂ 1 f ( a 0 , z 0 ) w w \mapsto u + \partial_1 f(a_0, z_0) w w↦u+∂1f(a0,z0)w,所以我们可以使用不动点求解器来求解这个线性系统。
对于 VJP,我们想要计算 ( a 0 , w ) ↦ ( z ∗ ( a 0 ) , w T ∂ z ∗ ( a 0 ) ) (a_0, w) \mapsto (z^*(a_0), \, w^\mathsf{T} \partial z^*(a_0)) (a0,w)↦(z∗(a0),wT∂z∗(a0)),类似地我们可以写出
w T ∂ z ∗ ( a 0 ) = w T I − ∂ 1 f ( a 0 , z 0 ) − 1 ∂ 0 f ( a 0 , z 0 ) . w^\mathsf{T} \partial z^*(a_0) = w^\mathsf{T} I - \\partial_1 f(a_0, z_0)^{-1} \partial_0 f(a_0, z_0). wT∂z∗(a0)=wTI−∂1f(a0,z0)−1∂0f(a0,z0).
我们可以再次将其分解为两步:首先计算 u T = w T I − ∂ 1 f ( a 0 , z 0 ) − 1 u^\mathsf{T} = w^\mathsf{T} I - \\partial_1 f(a_0, z_0)^{-1} uT=wTI−∂1f(a0,z0)−1,可以重写为方程
u T = w T + u T ∂ 1 f ( a 0 , z 0 ) u^\mathsf{T} = w^\mathsf{T} + u^\mathsf{T} \partial_1 f(a_0, z_0) uT=wT+uT∂1f(a0,z0)
因此我们可以将 u u u 计算为一个仿射不动点。其次,我们需要计算 u T ∂ 0 f ( a 0 , z 0 ) u^\mathsf{T} \partial_0 f(a_0, z_0) uT∂0f(a0,z0),这只是一个 f f f 的 VJP。
我们可以使用 jax.custom_jvp 和 jax.custom_vjp 将这些隐式微分公式连接到 JAX 的自动微分。以下是 VJP 版本:
python
from functools import partial
from jax import custom_vjp
@partial(jax.custom_vjp, nondiff_argnums=(0, 1))
def fixed_point_layer(solver, f, params, x):
z_star = solver(lambda z: f(params, x, z), z_init=jnp.zeros_like(x))
return z_star
def fixed_point_layer_fwd(solver, f, params, x):
z_star = fixed_point_layer(solver, f, params, x)
return z_star, (params, x, z_star)
def fixed_point_layer_bwd(solver, f, res, z_star_bar):
params, x, z_star = res
_, vjp_a = jax.vjp(lambda params, x: f(params, x, z_star), params, x)
_, vjp_z = jax.vjp(lambda z: f(params, x, z), z_star)
return vjp_a(solver(lambda u: vjp_z(u)[0] + z_star_bar,
z_init=jnp.zeros_like(z_star)))
fixed_point_layer.defvjp(fixed_point_layer_fwd, fixed_point_layer_bwd)我们可以检查结果与我们之前计算的梯度相似(之前依赖于微分通过不动点求解器的所有迭代):
python
g = jax.grad(lambda W: fixed_point_layer(fwd_solver, f, W, x).sum())(W)
print(g[0])[ 0.00756657 -0.81259 -1.1404793 -0.04861288 -0.7125525 -0.5580555
0.6697878 1.1068411 -0.0970227 0.97842234]
python
g = jax.grad(lambda W: fixed_point_layer(newton_solver, f, W, x).sum())(W)
print(g[0])[ 0.0075213 -0.812574 -1.1404784 -0.04860311 -0.7125377 -0.5580563
0.66979027 1.1068394 -0.09697371 0.97840786]
python
g = jax.grad(lambda W: fixed_point_layer(anderson_solver, f, W, x).sum())(W)
print(g[0])[ 0.00759155 -0.8125818 -1.140499 -0.04842732 -0.7127035 -0.5580155
0.66974455 1.1068457 -0.09696102 0.97841185]这些与我们之前找到的值一致,但计算效率高得多!
以下是主要要点:
- 通用自动微分可以处理不动点迭代,但微分通过求解器是内存低效的(并且通常是 FLOP 低效和数值不稳定的)。
- 相反,我们可以使用隐式微分,它只需要最终的不动点值(而不是所有迭代值)。
- 隐式微分看起来像是"在不动点处线性化,求解线性系统"。我们可以再次使用不动点迭代来求解线性系统,尽管我们可以自由选择任何求解方式。
改进的求解器实现
本节是 JAX 特有的。
我们已经看到,到目前为止,我们的求解器实现可以使用 JAX 的自动微分进行朴素微分,并且我们可以基于隐式微分为它们定义自定义微分规则。然而,我们可以改进这些实现,使其更高效,并支持更多的 JAX 变换。
我们之前的 fwd_solver 实现是:
python
def fwd_solver(f, z_init):
z_prev, z = z_init, f(z_init)
while jnp.linalg.norm(z_prev - z) > 1e-5:
z_prev, z = z, f(z)
return z如果我们改用 jax.lax.while_loop 结构化控制流原语来实现它,那么我们将获得使用 jax.jit 编译它以及使用 jax.vmap 自动批处理的能力。重写后看起来像:
python
from jax import lax
def fwd_solver(f, z_init):
def cond_fun(carry):
z_prev, z = carry
return jnp.linalg.norm(z_prev - z) > 1e-5
def body_fun(carry):
_, z = carry
return z, f(z)
init_carry = (z_init, f(z_init))
_, z_star = lax.while_loop(cond_fun, body_fun, init_carry)
return z_star幸运的是,newton_solver 完全不需要改变,因为它是基于 fwd_solver 实现的。
我们可以类似地更新 anderson_solver:
python
def anderson_solver(f, z_init, m=5, lam=1e-4, max_iter=50, tol=1e-5, beta=1.0):
x0 = z_init
x1 = f(x0)
x2 = f(x1)
X = jnp.concatenate([jnp.stack([x0, x1]), jnp.zeros((m - 2, *jnp.shape(x0)))])
F = jnp.concatenate([jnp.stack([x1, x2]), jnp.zeros((m - 2, *jnp.shape(x0)))])
def step(n, k, X, F):
G = F[:n] - X[:n]
GTG = jnp.tensordot(G, G, [list(range(1, G.ndim))] * 2)
H = jnp.block([[jnp.zeros((1, 1)), jnp.ones((1, n))],
[ jnp.ones((n, 1)), GTG]]) + lam * jnp.eye(n + 1)
alpha = jnp.linalg.solve(H, jnp.zeros(n+1).at[0].set(1))[1:]
xk = beta * jnp.dot(alpha, F[:n]) + (1-beta) * jnp.dot(alpha, X[:n])
X = X.at[k % m].set(xk)
F = F.at[k % m].set(f(xk))
return X, F
# 展开前 m 步
for k in range(2, m):
X, F = step(k, k, X, F)
res = jnp.linalg.norm(F[k] - X[k]) / (1e-5 + jnp.linalg.norm(F[k]))
if res < tol or k + 1 >= max_iter:
return X[k], k
# 在 lax.while_loop 中运行剩余步骤
def body_fun(carry):
k, X, F = carry
X, F = step(m, k, X, F)
return k + 1, X, F
def cond_fun(carry):
k, X, F = carry
kmod = (k - 1) % m
res = jnp.linalg.norm(F[kmod] - X[kmod]) / (1e-5 + jnp.linalg.norm(F[kmod]))
return (k < max_iter) & (res >= tol)
k, X, F = lax.while_loop(cond_fun, body_fun, (k + 1, X, F))
return X[(k - 1) % m], k我们可以检查这些新的实现是否计算出与之前相同的值,而且它们现在更快了,因为底层循环是经过编译的,适用于我们使用的任何后端(CPU、GPU 或 TPU):
python
z_star = fixed_point_layer(fwd_solver, f, W, x)
print(z_star)[ 0.00649604 -0.7015958 -0.984715 -0.04196563 -0.615222 -0.4818384
0.5783121 0.9556704 -0.08373158 0.8447803 ]
python
z_star = fixed_point_layer(newton_solver, f, W, x)
print(z_star)[ 0.00649406 -0.701595 -0.98471504 -0.04196503 -0.6152214 -0.48183855
0.5783122 0.9556704 -0.08372932 0.8447797 ]
python
z_star = fixed_point_layer(anderson_solver, f, W, x)
print(z_star)[ 0.00649838 -0.70159334 -0.9847146 -0.04194273 -0.6152194 -0.48183322
0.5783227 0.95566964 -0.08373427 0.84477484]我们可以检查我们的隐式微分仍然适用于这些新的求解器:
python
g = jax.grad(lambda W: fixed_point_layer(fwd_solver, f, W, x).sum())(W)
print(g[0])[ 0.00756657 -0.81259 -1.1404793 -0.04861288 -0.7125525 -0.5580555
0.6697878 1.1068411 -0.0970227 0.97842234]
python
g = jax.grad(lambda W: fixed_point_layer(newton_solver, f, W, x).sum())(W)
print(g[0])[ 0.0075213 -0.812574 -1.1404784 -0.04860311 -0.7125377 -0.5580563
0.66979027 1.1068394 -0.09697371 0.97840786]
python
g = jax.grad(lambda W: fixed_point_layer(anderson_solver, f, W, x).sum())(W)
print(g[0])[ 0.00759155 -0.8125818 -1.140499 -0.04842732 -0.7127035 -0.5580155
0.66974455 1.1068457 -0.09696102 0.97841185]由常微分方程(ODE)定义的函数的微分
ODE 和 odeint
我们想要微分通过常微分方程(ODE)求解器,比如 jax.scipy.integrate 的 odeint。数学上,像 odeint 这样的原语求解初值问题(IVP),其形式为
y ˙ ( t ) = f ( t , y ( t ) ) , y ( 0 ) = y 0 , \dot y(t) = f(t, y(t)), \qquad y(0) = y_0, y˙(t)=f(t,y(t)),y(0)=y0,
对于某个动力学函数 f : R × R n → R n f : \mathbb{R} \times \mathbb{R}^n \to \mathbb{R}^n f:R×Rn→Rn 和初值 y 0 ∈ R n y_0 \in \mathbb{R}^n y0∈Rn,其中我们使用传统的简写符号 y ˙ ( t ) ≡ ∂ y ( t ) \dot y(t) \equiv \partial y(t) y˙(t)≡∂y(t),并将 ∂ y ( t ) ∈ R n \partial y(t) \in \mathbb{R}^n ∂y(t)∈Rn 视为 R n × 1 \mathbb{R}^{n \times 1} Rn×1(通过压缩对时间求导引入的单例维度)。换言之,对于任何 t t t 值, y ( t ) ∈ R n y(t) \in \mathbb{R}^n y(t)∈Rn 的值由动力学函数 f f f 和初值 y 0 y_0 y0 通过 ODE 隐式定义。(我们假设函数 y y y 存在且由这些输入数据唯一定义。 f f f 的可微性存在充分条件以保证这一点成立,并且这些条件可以与隐函数定理联系起来!)
在 Python 中,我们向 odeint 输入一个表示 f f f 的 Python 可调用对象、一个表示初值 y 0 y_0 y0 的数组,以及一个时间序列 0 < t 1 < ⋯ < t K 0 < t_1 < \cdots < t_K 0<t1<⋯<tK。然后 odeint 计算并输出 y ( t 1 ) , ... , y ( t K ) y(t_1), \ldots, y(t_K) y(t1),...,y(tK) 的值:
python
from functools import partial
from jax.experimental.ode import odeint
import jax.numpy as jnp
def f(state, t, rho, sigma, beta):
x, y, z = state
return jnp.array([sigma * (y - x), x * (rho - z) - y, x * y - beta * z])
ys = odeint(partial(f, rho=28., sigma=10., beta=8./3),
y0=jnp.array([1., 1., 1.]),
t=jnp.linspace(0, 10., 10000))
python
import matplotlib.pyplot as plt
def plot_3d_path(ax, ys, color):
x0, x1, x2 = ys.T
ax.plot(x0, x1, x2, lw=0.5, color=color)
fig = plt.figure(figsize=(6, 4), dpi=150)
ax = fig.gca(projection='3d')
plot_3d_path(ax, ys, 'b');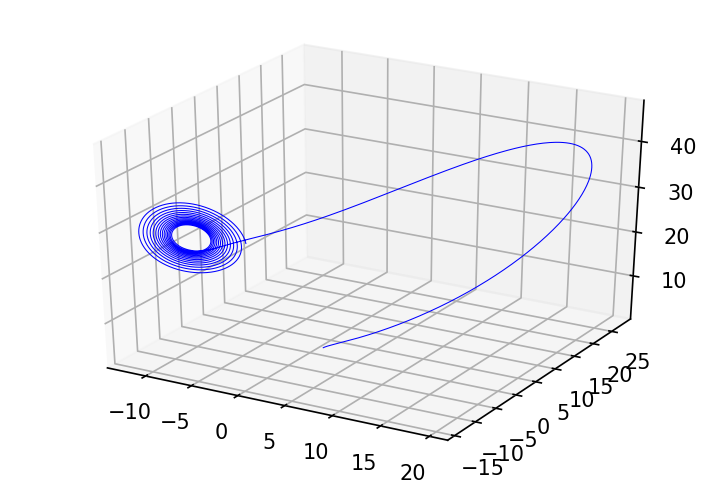
因此,odeint 从其输入数据( f f f 的参数和初值 y 0 y_0 y0)到其输出定义了一个隐函数。它将计算什么值(ODE 初值问题的解)与如何计算解分离开来:有许多替代算法可以求解 ODE 初值问题。下面是我们将使用的两个简单算法。
最直接的积分器是一阶前向 Euler 方法:
python
from jax import lax
def odeint_euler(f, y0, t, *args):
def step(state, t):
y_prev, t_prev = state
dt = t - t_prev
y = y_prev + dt * f(y_prev, t_prev, *args)
return (y, t), y
_, ys = lax.scan(step, (y0, t[0]), t[1:])
return ys
ys = odeint_euler(f, jnp.array([-2., -2., 2.]), jnp.linspace(0, 10., 10000),
28., 10., 8./3)通过使用 lax.scan,我们将积分器循环编译为单个原语执行。
python
fig = plt.figure(figsize=(6, 4), dpi=150)
ax = fig.gca(projection='3d')
plot_3d_path(ax, ys, 'g')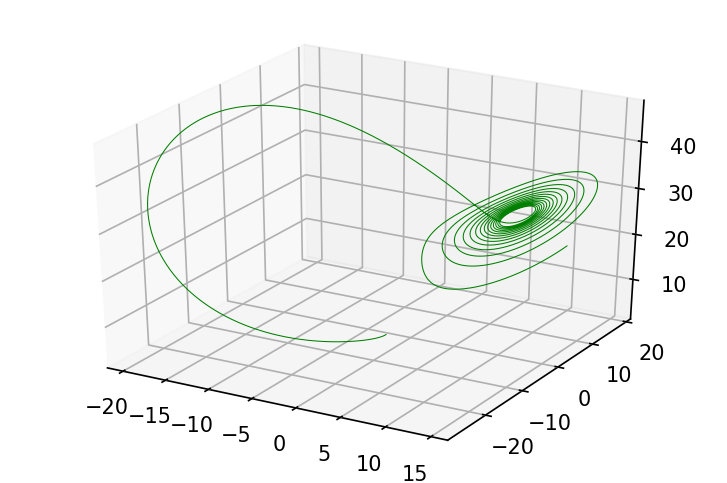
一个稍微复杂一点的积分器是四阶 Runge-Kutta 格式,它使用对动力学函数的多次求值来更好地近似步长上的积分:
python
def odeint_rk4(f, y0, t, *args):
def step(state, t):
y_prev, t_prev = state
h = t - t_prev
k1 = h * f(y_prev, t_prev, *args)
k2 = h * f(y_prev + k1/2., t_prev + h/2., *args)
k3 = h * f(y_prev + k2/2., t_prev + h/2., *args)
k4 = h * f(y_prev + k3, t + h, *args)
y = y_prev + 1./6 * (k1 + 2 * k2 + 2 * k3 + k4)
return (y, t), y
_, ys = lax.scan(step, (y0, t[0]), t[1:])
return ys
python
ys = odeint_rk4(f, jnp.array([5., 5., 5.]), jnp.linspace(0, 10., 10000),
28., 10., 8./3)
python
fig = plt.figure(figsize=(6, 4), dpi=150)
ax = fig.gca(projection='3d')
plot_3d_path(ax, ys, 'violet');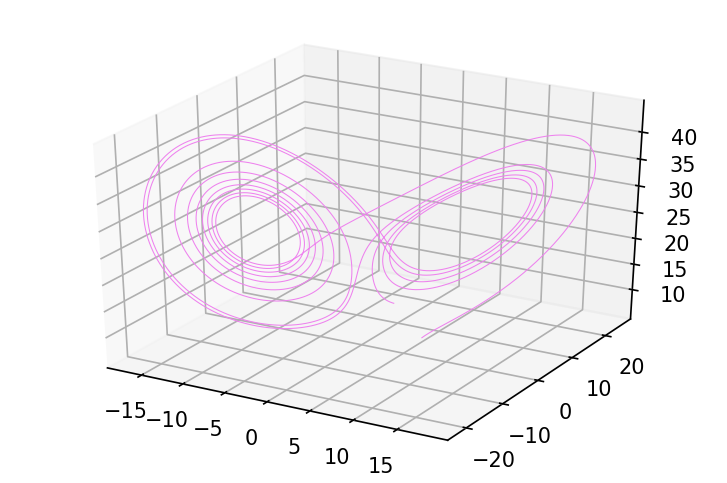
JAX 中的 odeint 实现使用自适应步长方案。
与不动点一样,我们可以直接微分通过数值 ODE 积分算法的操作。但这对于神经常微分方程等应用来说很快就会变得过于内存密集。
要理解如何高效地 自动微分通过 odeint Python 函数,我们首先需要理解如何从数学角度考虑由 ODE 定义的函数的微分。也就是说,我们希望提出关于当 f f f 的参数或初值 y 0 y_0 y0 发生微小变化时,解函数 y y y 的值如何变化的问题。
为了简化数学阐述,在本节的大部分内容中,我们假设我们只想在一个时间索引 T T T 处评估解函数,而不是在一个时间序列 t 1 , ... , t K t_1, \ldots, t_K t1,...,tK 上。也就是说,我们将专门讨论以下形式的 ODE 初值问题
计算 y ( T ) 使得 y ˙ ( t ) = f ( t , y ( t ) ) ∀ t ∈ 0 , T , y ( 0 ) = y 0 , \begin{aligned} \text{计算} \quad y(T)&~ \\ \text{使得} \quad \dot y(t) &= f(t, y(t)) \quad \forall t \in 0, T, \\ \quad y(0) &= y_0, \end{aligned} 计算y(T)使得y˙(t)y(0) =f(t,y(t))∀t∈0,T,=y0,
其中 f f f 和 y 0 y_0 y0 是输入数据。
一旦我们解决了仅使用输出时间 y ( T ) y(T) y(T) 的微分问题,扩展到多个时间索引将是直接的。
ODE 的微分
考虑由 a ∈ R p a \in \mathbb{R}^p a∈Rp 和 b ∈ R n b \in \mathbb{R}^n b∈Rn 参数化的 ODE 初值问题:
∂ 0 y ( t , a , b ) = f ( t , y ( t , a , b ) , a ) , y ( 0 , a , b ) = b . \partial_0 y(t, a, b) = f(t, y(t, a, b), a), \qquad y(0, a, b) = b. ∂0y(t,a,b)=f(t,y(t,a,b),a),y(0,a,b)=b.
注意,因为解 y y y 依赖于 a a a 和 b b b,我们将其写为这些值的函数。
我们想要回答诸如此类的问题:
- 前向模式的 Jacobian-向量积。 如果我们将参数 a a a 和 b b b 扰动为 a + Δ a a + \Delta a a+Δa 和 b + Δ b b + \Delta b b+Δb,那么在时间 T T T 处 y y y 的值如何变化(一阶近似)?即 ∂ 1 y ( T , a , b ) Δ a + ∂ 2 y ( T , a , b ) Δ b \partial_1 y(T, a, b) \, \Delta a + \partial_2 y(T, a, b) \, \Delta b ∂1y(T,a,b)Δa+∂2y(T,a,b)Δb 的值是多少?
- 反向模式的向量-Jacobian 积。 给定一个关于时间 T T T 处 y y y 的最终值扰动的线性函数(可能表示损失函数如何随 y ( T , a , b ) y(T, a, b) y(T,a,b) 的微小扰动而变化),损失函数如何随参数 a a a 和 b b b 的微小扰动而变化的线性近似是什么?即给定一个向量 w ∈ R n w \in \mathbb{R}^n w∈Rn 表示关于 y ( T , a , b ) y(T, a, b) y(T,a,b) 扰动的线性函数, w T ∂ 1 y ( T , a , b ) w^\mathsf{T} \partial_1 y(T, a, b) wT∂1y(T,a,b) 和 w T ∂ 2 y ( T , a , b ) w^\mathsf{T} \partial_2 y(T, a, b) wT∂2y(T,a,b) 是什么?
前向模式的 Jacobian-向量积
为了理解当 a a a 发生微小扰动时解如何变化,我们假设在 a a a 的邻域内 ODE 解存在,并将 ODE 方程的两边作为 a a a 的函数进行微分:
∂ 1 ∂ 0 y ( t , a , b ) = ∂ 1 f ( t , y ( t , a , b ) , a ) ∂ 1 y ( t , a , b ) + ∂ 2 f ( t , y ( t , a , b ) , a ) . (*) \partial_1 \partial_0 y(t, a, b) = \partial_1 f(t, y(t, a, b), a) \partial_1 y(t, a, b) + \partial_2 f(t, y(t, a, b), a). \tag{*} ∂1∂0y(t,a,b)=∂1f(t,y(t,a,b),a)∂1y(t,a,b)+∂2f(t,y(t,a,b),a).(*)
注意,由于偏导数可交换,我们可以通过以下方式重排左边:
∂ 1 ∂ 0 y ( t , a , b ) = ∂ 0 ∂ 1 y ( t , a , b ) . \partial_1 \partial_0 y(t, a, b) = \partial_0 \partial_1 y(t, a, b). ∂1∂0y(t,a,b)=∂0∂1y(t,a,b).
这个方程的两边都是 n × p n \times p n×p 矩阵(压缩对时间求导引入的单例维度)。我们可以将其应用于特定的扰动 Δ a ∈ R p \Delta a \in \mathbb{R}^p Δa∈Rp:
∂ 0 ∂ 1 y ( t , a , b ) Δ a = ∂ 1 f ( t , y ( t , a , b ) , a ) ∂ 1 y ( t , a , b ) Δ a + ∂ 2 f ( t , y ( t , a , b ) , a ) Δ a , \partial_0 \partial_1 y(t, a, b) \, \Delta a = \partial_1 f(t, y(t, a, b), a) \partial_1 y(t, a, b) \, \Delta a + \partial_2 f(t, y(t, a, b), a) \, \Delta a, ∂0∂1y(t,a,b)Δa=∂1f(t,y(t,a,b),a)∂1y(t,a,b)Δa+∂2f(t,y(t,a,b),a)Δa,
现在两边都是 R n \mathbb{R}^n Rn 中的向量。
这个新方程本身看起来像一个 ODE!为了简化符号,我们可以定义一个新函数 z ( t , a , b ) ≜ ∂ 1 y ( t , a , b ) Δ a z(t, a, b) \triangleq \partial_1 y(t, a, b) \, \Delta a z(t,a,b)≜∂1y(t,a,b)Δa,并将其视为一个新的状态向量分量。直观地说, z ( t , a , b ) z(t, a, b) z(t,a,b) 表示给定我们对参数值的扰动时 y ( t , a , b ) y(t, a, b) y(t,a,b) 值的扰动。微分方程 ( ∗ ) (*) (∗) 给出了它的动力学:
∂ 0 y ( t , a , b ) ∂ 0 z ( t , a , b ) \] = \[ f ( t , y ( t , a , b ) , a ) g ( t , y ( t , a , b ) , z ( t , a , b ) , a ) \] \\begin{bmatrix} \\partial_0 y(t, a, b) \\\\ \\partial_0 z(t, a, b) \\end{bmatrix} = \\begin{bmatrix} f(t, y(t, a, b), a) \\\\ g(t, y(t, a, b), z(t, a, b), a) \\end{bmatrix} \[∂0y(t,a,b)∂0z(t,a,b)\]=\[f(t,y(t,a,b),a)g(t,y(t,a,b),z(t,a,b),a)
其中
g ( t , y , z , a ) ≜ ∂ 1 f ( t , y , a ) z + ∂ 2 f ( t , y , a ) Δ a . g(t, y, z, a) \triangleq \partial_1 f(t, y, a) z + \partial_2 f(t, y, a) \, \Delta a . g(t,y,z,a)≜∂1f(t,y,a)z+∂2f(t,y,a)Δa.
初始条件呢?它们也同样整齐地对应: y ( 0 , a , b ) y(0, a, b) y(0,a,b) 值的扰动根据定义为 Δ b \Delta b Δb,所以我们有
y ( 0 , a , b ) z ( 0 , a , b ) = b Δ b . \begin{bmatrix} y(0, a, b) \\ z(0, a, b) \end{bmatrix} = \begin{bmatrix} b \\ \Delta b \end{bmatrix}. y(0,a,b)z(0,a,b)=bΔb.
最终结果是,我们可以将 JVP 表示为一个增广的 ODE 系统,因此在代码中我们可以将 JVP 规则实现为对 odeint 的新调用,使用 JAX 的 custom_jvp 机制:
python
import jax
odeint_rk4 = jax.custom_jvp(odeint_rk4, nondiff_argnums=(0,))
@odeint_rk4.defjvp
def odeint_rk4_jvp(f, primals, tangents):
y0, t, *args = primals
delta_y0, _, *delta_args = tangents
nargs = len(args)
def f_aug(aug_state, t, *args_and_delta_args):
primal_state, tangent_state = aug_state
args, delta_args = args_and_delta_args[:nargs], args_and_delta_args[nargs:]
primal_dot, tangent_dot = jax.jvp(f, (primal_state, t, *args), (tangent_state, 0., *delta_args))
return jnp.stack([primal_dot, tangent_dot])
aug_init_state = jnp.stack([y0, delta_y0])
aug_states = odeint_rk4(f_aug, aug_init_state, t, *args, *delta_args)
ys, ys_dot = aug_states[:, 0, :], aug_states[:, 1, :]
return ys, ys_dot有了这个 odeint JVP 规则,我们现在可以研究诸如:如果我们稍微扰动起点的第三个分量,解路径会如何变化?
python
def evolve(y0):
return odeint_rk4(f, y0, jnp.linspace(0, 1., 1000), 28., 10., 8./3)
y0 = jnp.array([5., 5., 5.])
delta_y0 = jnp.array([0., 0., 1.])
ys, delta_ys = jax.jvp(evolve, (y0,), (delta_y0,))
python
def plot_3d_path_with_delta(ax, ys, delta_ys, color):
x0, x1, x2 = ys.T
dx0, dx1, dx2 = delta_ys.T
skip = 10
ax.plot(x0, x1, x2, lw=0.5, color=color)
ax.quiver(x0[::skip], x1[::skip], x2[::skip], dx0[::skip], dx1[::skip], dx2[::skip])
fig = plt.figure(figsize=(6, 4), dpi=150)
ax = fig.gca(projection='3d')
plot_3d_path_with_delta(ax, ys, delta_ys, 'violet')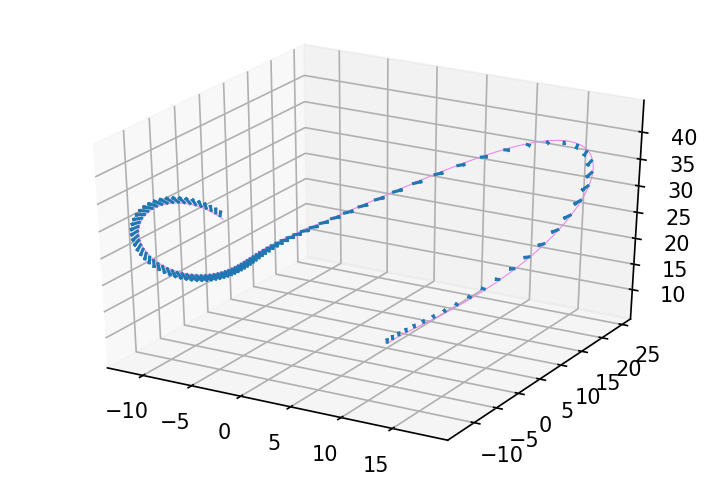
或者,如果我们扰动其中一个动力学参数,轨迹会如何变化?
python
def evolve(y0, rho, sigma, beta):
return odeint_rk4(f, y0, jnp.linspace(0, 1., 1000), rho, sigma, beta)
y0 = jnp.array([5., 5., 5.])
delta_y0 = jnp.array([0., 0., 0.])
rho = 28.
sigma = 10.
beta = 8./3
delta_rho = 0.
delta_sigma = 1.
delta_beta = 0.
ys, delta_ys = jax.jvp(evolve,
(y0, rho, sigma, beta),
(delta_y0, delta_rho, delta_sigma, delta_beta))
python
fig = plt.figure(figsize=(6, 4), dpi=150)
ax = fig.gca(projection='3d')
plot_3d_path_with_delta(ax, ys, delta_ys, 'violet')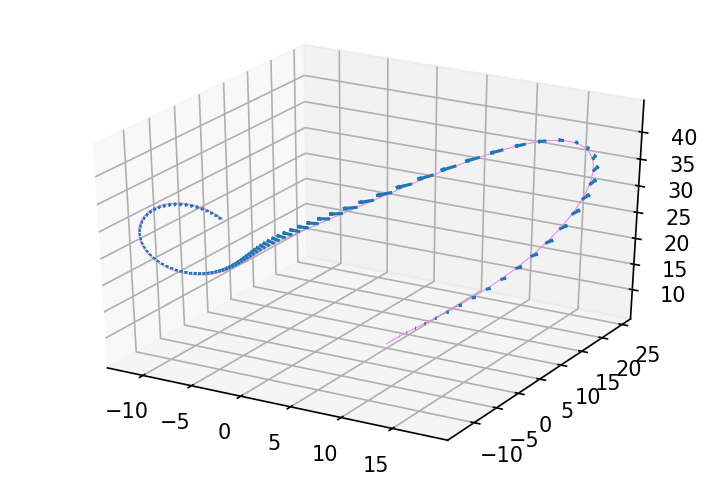
python
delta_rho = 0.
delta_sigma = 0.
delta_beta = 1.
ys, delta_ys = jax.jvp(evolve,
(y0, rho, sigma, beta),
(delta_y0, delta_rho, delta_sigma, delta_beta))
python
fig = plt.figure(figsize=(6, 4), dpi=150)
ax = fig.gca(projection='3d')
plot_3d_path_with_delta(ax, ys, delta_ys, 'violet')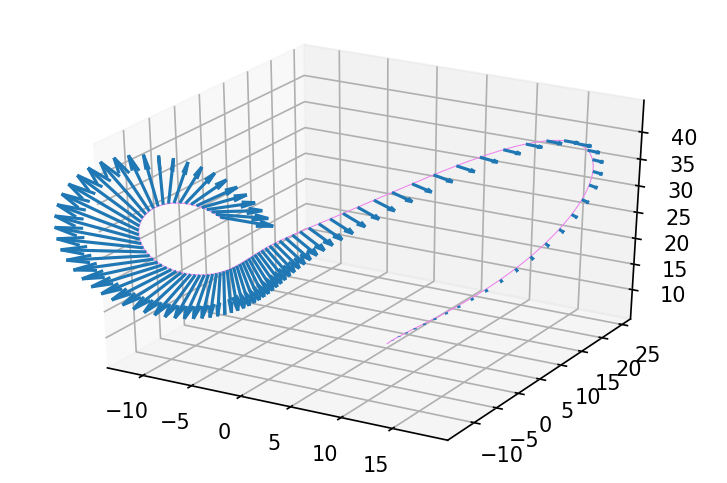
从对比图示中看起来轨迹对 beta 参数的变化非常敏感!
我们可以通过实际扰动参数的值并观察轨迹的变化来验证:
python
perturbed_ys = evolve(y0, rho, sigma, beta + 1.)
fig = plt.figure(figsize=(6, 4), dpi=150)
ax = fig.gca(projection='3d')
plot_3d_path(ax, ys, 'blue')
plot_3d_path(ax, perturbed_ys, 'orange')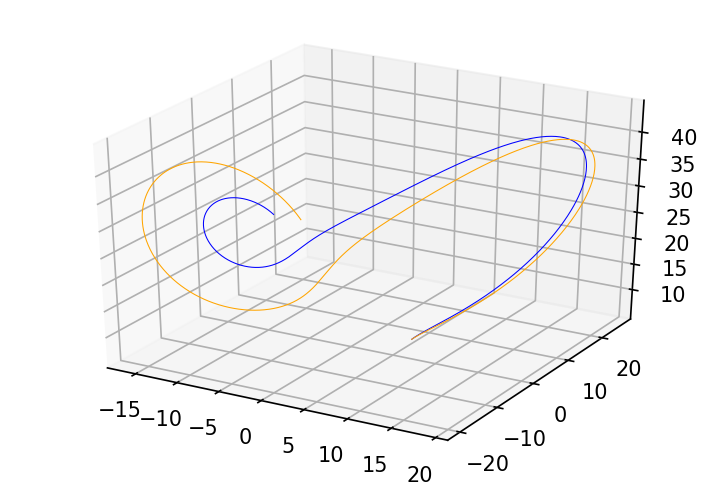
反向模式的向量-Jacobian 积
要推导 VJP,我们只需要考虑转置一个具有特定线性结构的 ODE 初值问题。然后我们可以将转置与 JVP 线性化结果结合起来得到 VJP。
考虑以下形式的 ODE 初值问题
∂ 0 z ( t , u , v ) = A ( t ) z ( t , u , v ) + B ( t ) u , z ( 0 , u , v ) = v , \partial_0 z(t, u, v) = A(t) z(t, u, v) + B(t)u, \qquad z(0, u, v) = v, ∂0z(t,u,v)=A(t)z(t,u,v)+B(t)u,z(0,u,v)=v,
其中向量 u ∈ R p u \in \mathbb{R}^p u∈Rp 和 v ∈ R n v \in \mathbb{R}^n v∈Rn,状态维度为 z ( t , u , v ) ∈ R n z(t, u, v) \in \mathbb{R}^n z(t,u,v)∈Rn。在每个时间 t t t 处, A ( t ) ∈ R n × n A(t) \in \mathbb{R}^{n \times n} A(t)∈Rn×n 和 B ( t ) ∈ R n × p B(t) \in \mathbb{R}^{n \times p} B(t)∈Rn×p 是矩阵。
注意映射 ( u , v ) ↦ z ( T , u , v ) (u, v) \mapsto z(T, u, v) (u,v)↦z(T,u,v) 是线性的。也就是说,如果我们取 ( u , v ) = ( 0 , 0 ) (u, v) = (0, 0) (u,v)=(0,0),那么 z ≡ 0 z \equiv 0 z≡0 是一个解。此外,如果 z 1 z_1 z1 和 z 2 z_2 z2 分别是输入 ( u 1 , v 1 ) (u_1, v_1) (u1,v1) 和 ( u 2 , v 2 ) (u_2, v_2) (u2,v2) 的解,那么对于标量 α , β ∈ R \alpha, \beta \in \mathbb{R} α,β∈R, α z 1 + β z 2 \alpha z_1 + \beta z_2 αz1+βz2 是给定输入 ( α u 1 + β u 2 , α v 1 + β v 2 ) (\alpha u_1 + \beta u_2, \alpha v_1 + \beta v_2) (αu1+βu2,αv1+βv2) 的解,这可以通过形成 z 1 z_1 z1 和 z 2 z_2 z2 的 ODE 方程的相应线性组合来验证。
因为 ( u , v ) ↦ z ( T , u , v ) (u, v) \mapsto z(T, u, v) (u,v)↦z(T,u,v) 是线性的,对于 z ( T , u , v ) z(T, u, v) z(T,u,v) 值上的任意线性函数,我们可以通过组合定义 ( u , v ) (u, v) (u,v) 上的一个线性函数。特别地,对于给定的向量 w ∈ R n w \in \mathbb{R}^n w∈Rn,我们希望找到向量 λ u ∈ R p \lambda_u \in \mathbb{R}^p λu∈Rp 和 λ v ∈ R n \lambda_v \in \mathbb{R}^n λv∈Rn,使得
⟨ w , z ( T , u , v ) ⟩ = ⟨ λ u , u ⟩ + ⟨ λ v , v ⟩ \langle w, \, z(T, u, v) \rangle = \langle \lambda_u, \, u \rangle + \langle \lambda_v, \, v \rangle ⟨w,z(T,u,v)⟩=⟨λu,u⟩+⟨λv,v⟩
对任意向量 u u u 和 v v v 成立。
首先考虑特殊情况 B ( t ) ≡ 0 B(t) \equiv 0 B(t)≡0 ,所以我们有
∂ 0 z ( t , v ) = A ( t ) z ( t , v ) , z ( 0 , v ) = v . (*) \partial_0 z(t, v) = A(t) z(t, v), \qquad z(0, v) = v. \tag{*} ∂0z(t,v)=A(t)z(t,v),z(0,v)=v.(*)
对于给定的 w w w,我们希望找到 λ \lambda λ 使得
⟨ w , z ( T , v ) ⟩ = ⟨ λ , v ⟩ = ⟨ λ , z ( 0 , v ) ⟩ . \langle w, \, z(T, v) \rangle = \langle \lambda, \, v \rangle = \langle \lambda, \, z(0, v) \rangle. ⟨w,z(T,v)⟩=⟨λ,v⟩=⟨λ,z(0,v)⟩.
换句话说,我们知道这个线性映射在时间 t = T t=T t=T 处作用于状态的表示向量,即向量 w w w,我们希望找到该线性映射在时间 t = 0 t=0 t=0 处作用于状态的表示向量,即向量 λ \lambda λ。
由于基本任务是将一个 t t t 值的表示向量转换为另一个 t t t 值的表示向量,我们可以推广这个问题,要求一个函数 t ↦ λ ( t ) t \mapsto \lambda(t) t↦λ(t) 使得
⟨ w , z ( T , v ) ⟩ = ⟨ λ ( t ) , z ( t , v ) ⟩ ∀ t ∈ 0 , T . \langle w, \, z(T, v) \rangle = \langle \lambda(t), \, z(t, v) \rangle \qquad \forall t \in 0, T. ⟨w,z(T,v)⟩=⟨λ(t),z(t,v)⟩∀t∈0,T.
那么特别地,取 t = T t=T t=T 我们得到 λ ( T ) = w \lambda(T) = w λ(T)=w,取 t = 0 t = 0 t=0 我们得到具有以下性质的向量 λ ( 0 ) \lambda(0) λ(0):
⟨ w , z ( T , v ) ⟩ = ⟨ λ ( 0 ) , z ( 0 , v ) ⟩ = ⟨ λ ( 0 ) , v ⟩ . \langle w, \, z(T, v) \rangle = \langle \lambda(0), \, z(0, v) \rangle = \langle \lambda(0), \, v \rangle. ⟨w,z(T,v)⟩=⟨λ(0),z(0,v)⟩=⟨λ(0),v⟩.
我们可以通过固定 λ ( T ) = w \lambda(T) = w λ(T)=w 并确保 ⟨ λ ( t ) , z ( t , v ) ⟩ \langle \lambda(t), \, z(t, v) \rangle ⟨λ(t),z(t,v)⟩ 的值不随时间变化来找到这样的函数 λ \lambda λ:
0 = ∂ ( t ↦ ⟨ λ ( t ) , z ( t , v ) ⟩ ) = ⟨ ∂ λ ( t ) , z ( t , v ) ⟩ + ⟨ λ ( t ) , ∂ 0 z ( t , v ) ⟩ = ⟨ ∂ λ ( t ) , z ( t , v ) ⟩ + ⟨ λ ( t ) , A ( t ) z ( t , v ) ⟩ = ⟨ ∂ λ ( t ) + A ( t ) T λ ( t ) , z ( t , v ) ⟩ , \begin{aligned} 0 &=\partial ( t \mapsto \langle \lambda(t), \, z(t, v) \rangle ) \\ &= \langle \partial \lambda(t), \, z(t, v) \rangle + \langle \lambda(t), \, \partial_0 z(t, v) \rangle \\ &= \langle \partial \lambda(t), \, z(t, v) \rangle + \langle \lambda(t), \, A(t) z(t, v) \rangle \\ &= \langle \partial \lambda(t) + A(t)^\mathsf{T} \lambda(t), \, z(t, v) \rangle, \end{aligned} 0=∂(t↦⟨λ(t),z(t,v)⟩)=⟨∂λ(t),z(t,v)⟩+⟨λ(t),∂0z(t,v)⟩=⟨∂λ(t),z(t,v)⟩+⟨λ(t),A(t)z(t,v)⟩=⟨∂λ(t)+A(t)Tλ(t),z(t,v)⟩,
其中在第三行我们使用了线性 ODE ( ∗ ) (*) (∗)。因此,为了实现 ⟨ λ ( t ) , z ( t , v ) ⟩ \langle \lambda(t), \, z(t, v) \rangle ⟨λ(t),z(t,v)⟩ 的值不随时间变化的目标,并满足 λ ( T ) = w \lambda(T) = w λ(T)=w,选择 λ \lambda λ 来求解 ODE 初值问题
∂ λ ( t ) = − A ( t ) T λ ( t ) , λ ( T ) = w . \partial \lambda(t) = - A(t)^\mathsf{T} \lambda(t), \qquad \lambda(T) = w. ∂λ(t)=−A(t)Tλ(t),λ(T)=w.
这个系统被称为线性 ODE ∂ z ( t ) = A ( t ) z ( t ) \partial z(t) = A(t) z(t) ∂z(t)=A(t)z(t) 的伴随系统。
直观地说,在每个时间 t t t, λ ( t ) \lambda(t) λ(t) 的值表示 ⟨ w , z ( T , v ) ⟩ \langle w, \, z(T, v) \rangle ⟨w,z(T,v)⟩ 的值会如何随 z ( t , v ) z(t, v) z(t,v) 的扰动而变化。通过在所有时间点 t t t 追踪该量,我们可以将已知的 t = T t=T t=T 处的值(即 λ ( T ) = w \lambda(T) = w λ(T)=w)与 t = 0 t=0 t=0 处感兴趣的值联系起来。
对于更一般的情况 B ( t ) ≢ 0 B(t) \not\equiv 0 B(t)≡0 ,再次考虑线性 ODE 初值问题
∂ 0 z ( t , u , v ) = A ( t ) z ( t , u , v ) + B ( t ) u , z ( 0 , u , v ) = v , \partial_0 z(t, u, v) = A(t) z(t, u, v) + B(t)u, \qquad z(0, u, v) = v, ∂0z(t,u,v)=A(t)z(t,u,v)+B(t)u,z(0,u,v)=v,
和任务:给定 w ∈ R n w \in \mathbb{R}^n w∈Rn,需要计算 λ u ∈ R p \lambda_u \in \mathbb{R}^p λu∈Rp 和 λ v ∈ R n \lambda_v \in \mathbb{R}^n λv∈Rn 使得
⟨ w , z ( T , u , v ) ⟩ = ⟨ λ u , u ⟩ + ⟨ λ v , v ⟩ . \langle w, \, z(T, u, v) \rangle = \langle \lambda_u, \, u \rangle + \langle \lambda_v, \, v \rangle. ⟨w,z(T,u,v)⟩=⟨λu,u⟩+⟨λv,v⟩.
如果我们使用与上面相同的函数 λ \lambda λ,它满足 ∂ λ ( t ) = − A ( t ) T λ ( t ) \partial \lambda(t) = -A(t)^\mathsf{T} \lambda(t) ∂λ(t)=−A(t)Tλ(t),由于 ODE 中涉及 B B B 的新项,我们将不再像 B ≡ 0 B \equiv 0 B≡0 时那样在所有时间 t ∈ 0 , T t \in 0, T t∈0,T 上有 ⟨ w , z ( T , u , v ) ⟩ = ⟨ λ ( t ) , z ( t , u , v ) ⟩ \langle w, \, z(T, u, v) \rangle = \langle \lambda(t), \, z(t, u, v)\rangle ⟨w,z(T,u,v)⟩=⟨λ(t),z(t,u,v)⟩。但我们可以将差写为 ∂ 0 z ( t , u , v ) \partial_0 z(t, u, v) ∂0z(t,u,v) 与 A ( t ) z ( t , u , v ) A(t) z(t, u, v) A(t)z(t,u,v) 之差的时间积分:
⟨ w , z ( T , u , v ) ⟩ − ⟨ λ ( t ) , z ( t , u , v ) ⟩ = ∫ t T ⟨ λ ( τ ) , ∂ 0 z ( τ , u , v ) − A ( τ ) z ( τ , u , v ) ⟩ d τ = ∫ t T ⟨ λ ( τ ) , B ( τ ) u ⟩ d τ . \begin{aligned} \langle w, \, z(T, u, v) \rangle - \langle \lambda(t), \, z(t, u, v) \rangle &= \int_t^T \langle \lambda(\tau), \, \partial_0 z(\tau, u, v) - A(\tau) z(\tau, u, v) \rangle \, \mathrm{d}\tau \\ &= \int_t^T \langle \lambda(\tau), \, B(\tau) u \rangle \, \mathrm{d} \tau. \end{aligned} ⟨w,z(T,u,v)⟩−⟨λ(t),z(t,u,v)⟩=∫tT⟨λ(τ),∂0z(τ,u,v)−A(τ)z(τ,u,v)⟩dτ=∫tT⟨λ(τ),B(τ)u⟩dτ.
整理后,我们有
⟨ w , z ( T , u , v ) ⟩ = ⟨ λ ( t ) , z ( t , u , v ) ⟩ + ⟨ ∫ t T B ( τ ) T λ ( τ ) d τ , u ⟩ , \langle w, \, z(T, u, v) \rangle = \langle \lambda(t), \, z(t, u, v) \rangle + \langle \textstyle \int_t^T B(\tau)^\mathsf{T} \lambda(\tau) \, \mathrm{d}\tau, \, u \rangle, ⟨w,z(T,u,v)⟩=⟨λ(t),z(t,u,v)⟩+⟨∫tTB(τ)Tλ(τ)dτ,u⟩,
对所有 t ∈ 0 , T t \in 0, T t∈0,T 成立,特别地在 t = 0 t=0 t=0 处我们有
⟨ w , z ( T , u , v ) ⟩ = ⟨ λ ( 0 ) , z ( 0 , u , v ) ⟩ + ⟨ ∫ 0 T B ( τ ) T λ ( τ ) d τ , u ⟩ . \langle w, \, z(T, u, v) \rangle = \langle \lambda(0), \, z(0, u, v) \rangle + \langle \textstyle \int_0^T B(\tau)^\mathsf{T} \lambda(\tau) \, \mathrm{d}\tau, \, u \rangle. ⟨w,z(T,u,v)⟩=⟨λ(0),z(0,u,v)⟩+⟨∫0TB(τ)Tλ(τ)dτ,u⟩.
也就是说,我们找到了我们需要的向量 λ u \lambda_u λu 和 λ v \lambda_v λv 可以写成
λ u = ∫ 0 T B ( t ) T λ ( t ) d t , λ v = λ ( 0 ) . \begin{aligned} \lambda_u &= \int_0^T B(t)^\mathsf{T} \lambda(t) \, \mathrm{d}t, \\ \lambda_v &= \lambda(0). \end{aligned} λuλv=∫0TB(t)Tλ(t)dt,=λ(0).
为了计算这些量,特别是定义 λ u \lambda_u λu 的积分,我们可以设置一个新的增广 ODE 初值问题:
∂ λ ( t ) ∂ γ ( t ) = − A ( t ) T λ ( t ) B ( t ) T λ ( t ) , λ ( T ) γ ( T ) = w 0 . \begin{bmatrix} \partial \lambda(t) \\ \partial \gamma(t) \end{bmatrix}= \begin{bmatrix} -A(t)^\mathsf{T} \lambda(t) \\ B(t)^\mathsf{T} \lambda(t) \end{bmatrix}, \qquad \begin{bmatrix} \lambda(T) \\ \gamma(T) \end{bmatrix}= \begin{bmatrix} w \\ 0 \end{bmatrix}. ∂λ(t)∂γ(t)=−A(t)Tλ(t)B(t)Tλ(t),λ(T)γ(T)=w0.
通过求解这个增广状态在时间 t = 0 t=0 t=0 处的值(我们可以通过调用 odeint 来实现),我们计算出了 λ u \lambda_u λu 和 λ v \lambda_v λv。
为了构建完整的 VJP,我们可以将这个转置结果与上面推导的 JVP 结果结合起来。即,给定 ODE 系统
∂ 0 y ( t , a , b ) = f ( t , y ( t , a , b ) , a ) , y ( 0 , a , b ) = b . \partial_0 y(t, a, b) = f(t, y(t, a, b), a), \qquad y(0, a, b) = b. ∂0y(t,a,b)=f(t,y(t,a,b),a),y(0,a,b)=b.
再次考虑 JVP ODE
∂ 0 y ( t , a , b ) ∂ 0 z ( t , a , b ) = f ( t , y ( t , a , b ) , a ) ∂ 2 f ( t , y , a ) Δ a + ∂ 1 f ( t , y , a ) z , y ( 0 , a , b ) z ( 0 , a , b ) = b Δ b . \begin{bmatrix} \partial_0 y(t, a, b) \\ \partial_0 z(t, a, b) \end{bmatrix}= \begin{bmatrix} f(t, y(t, a, b), a) \\ \partial_2 f(t, y, a) \, \Delta a + \partial_1 f(t, y, a) z \end{bmatrix}, \qquad \begin{bmatrix} y(0, a, b) \\ z(0, a, b) \end{bmatrix}= \begin{bmatrix} b \\ \Delta b \end{bmatrix}. ∂0y(t,a,b)∂0z(t,a,b)=f(t,y(t,a,b),a)∂2f(t,y,a)Δa+∂1f(t,y,a)z,y(0,a,b)z(0,a,b)=bΔb.
我们可以将转置结果应用于 JVP ODE 的第二个块分量,通过选择
A ( t ) ≜ ∂ 1 f ( t , y , a ) , B ( t ) ≜ ∂ 2 f ( t , y , a ) , \begin{aligned} A(t) &\triangleq \partial_1 f(t, y, a), \\ B(t) &\triangleq \partial_2 f(t, y, a), \end{aligned} A(t)B(t)≜∂1f(t,y,a),≜∂2f(t,y,a),
那么感兴趣的整体系统变为
∂ 0 y ( t , a , b ) ∂ 0 λ ( t ) ∂ 0 γ ( t ) = f ( t , y ( t , a , b ) , a ) − ∂ 1 f ( t , y ( t , a , b ) , a ) T λ ( t ) ∂ 2 f ( t , y ( t , a , b ) , a ) T λ ( t ) , y ( T , a , b ) λ ( T ) γ ( T ) = y T w 0 . \begin{bmatrix} \partial_0 y(t, a, b) \\ \partial_0 \lambda(t) \\ \partial_0 \gamma(t) \end{bmatrix}= \begin{bmatrix} f(t, y(t, a, b), a) \\ -\partial_1 f(t, y(t, a, b), a)^\mathsf{T} \lambda(t) \\ \partial_2 f(t, y(t, a, b), a)^\mathsf{T} \lambda(t) \end{bmatrix}, \qquad \begin{bmatrix} y(T, a, b) \\ \lambda(T) \\ \gamma(T) \end{bmatrix}= \begin{bmatrix} y_T \\ w \\ 0 \end{bmatrix}. ∂0y(t,a,b)∂0λ(t)∂0γ(t) = f(t,y(t,a,b),a)−∂1f(t,y(t,a,b),a)Tλ(t)∂2f(t,y(t,a,b),a)Tλ(t) , y(T,a,b)λ(T)γ(T) = yTw0 .
我们可以通过调用 odeint 来求解这个完整的联合系统。作为替代方案,如果我们在前向传播过程中保存 t ↦ ( t , y ( t , a , b ) ) t \mapsto (t, y(t, a, b)) t↦(t,y(t,a,b)) 的值,然后用它们形成 t ↦ y ( t , a , b ) t \mapsto y(t, a, b) t↦y(t,a,b) 的插值近似,在反向传播中我们可以查询插值,这样我们只需要求解线性化 ODE
∂ 0 λ ( t ) ∂ 0 γ ( t ) = − ∂ 1 f ( t , y ( t , a , b ) , a ) T λ ( t ) ∂ 2 f ( t , y ( t , a , b ) , a ) T λ ( t ) , λ ( T ) γ ( T ) = w 0 . \begin{bmatrix} \partial_0 \lambda(t) \\ \partial_0 \gamma(t) \end{bmatrix}= \begin{bmatrix} -\partial_1 f(t, y(t, a, b), a)^\mathsf{T} \lambda(t) \\ \partial_2 f(t, y(t, a, b), a)^\mathsf{T} \lambda(t) \end{bmatrix}, \qquad \begin{bmatrix} \lambda(T) \\ \gamma(T) \end{bmatrix}= \begin{bmatrix} w \\ 0 \end{bmatrix}. ∂0λ(t)∂0γ(t)=−∂1f(t,y(t,a,b),a)Tλ(t)∂2f(t,y(t,a,b),a)Tλ(t),λ(T)γ(T)=w0.