一、引言
在 Flink 生产环境中,我们基本上都会遇到以下内存问题:
| 问题现象 | 根因方向 |
|---|---|
| java.lang.OutOfMemoryError: Java heap space | Task Heap 不足 |
| java.lang.OutOfMemoryError: Direct buffer memory | Network/Framework Off-Heap 不足 |
| java.lang.OutOfMemoryError: Metaspace | JVM Metaspace 不足 |
| Container 被 YARN/K8s Kill(exit code 137) | 总进程内存超出容器限制 |
| RocksDB 性能下降或 OOM | Managed Memory 配置不当 |
| GC 频繁导致 Checkpoint 超时 | 堆内存比例失调 |
只有深入理解Flink内存模型,才能做到精准配置、高效调优、从容排障。
二、TaskManager 内存模型
TaskManager 内存模型架构图如下:
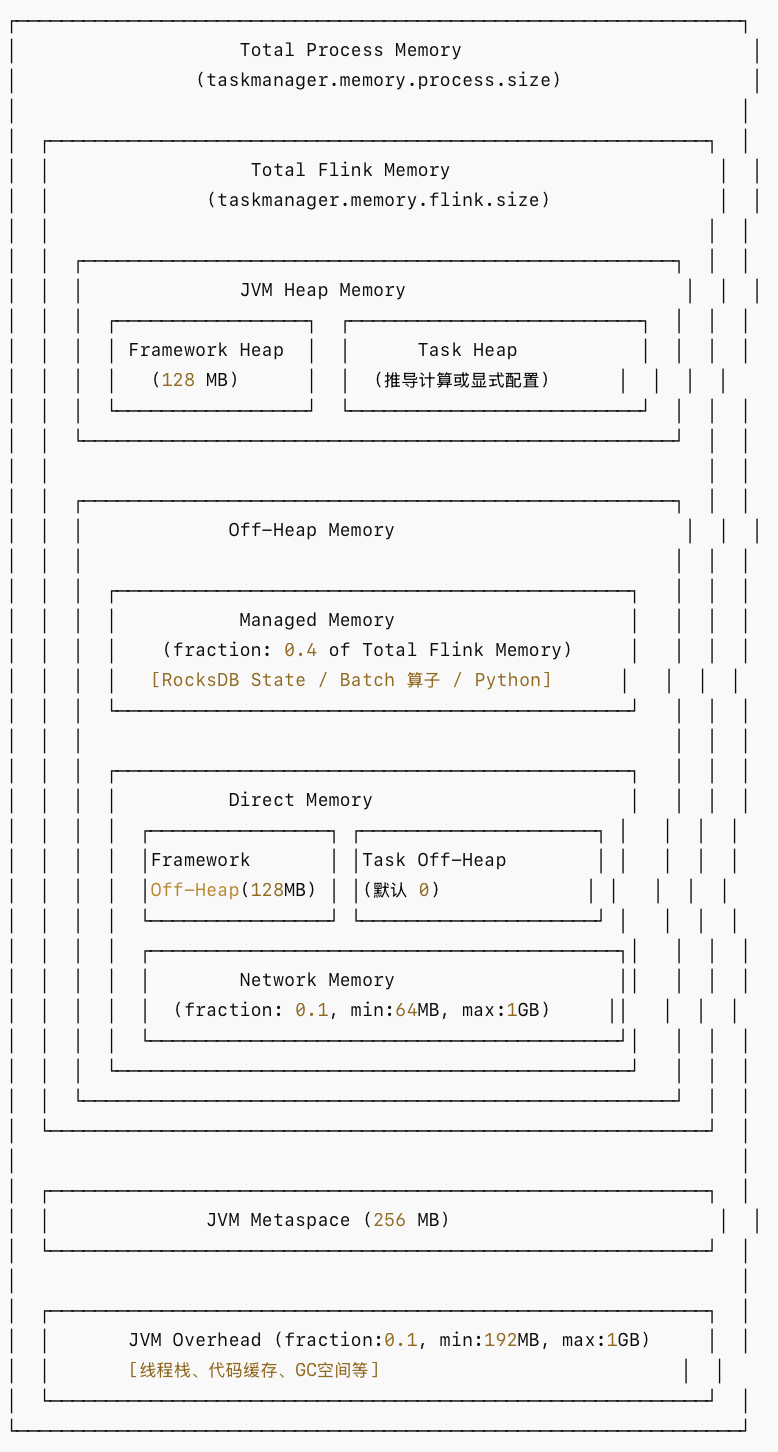
内存区域层级关系公式如下:
Total Process Memory = Total Flink Memory + JVM Metaspace + JVM Overhead
Total Flink Memory = Heap Memory + Off-Heap Memory
= (Framework Heap + Task Heap)
+ (Managed Memory + Framework Off-Heap + Task Off-Heap + Network Memory)各内存区域用途与参数说明如下:
| 内存区域 | 用途 | 默认值 | 配置参数 |
|---|---|---|---|
| Framework Heap | Flink 框架本身使用的堆内存(如 Akka、内部数据结构) | 128 MB | taskmanager.memory.framework.heap.size |
| Task Heap | 用户代码执行使用的堆内存(算子逻辑、用户对象) | 推导计算 | taskmanager.memory.task.heap.size |
| Framework Off-Heap | 框架使用的堆外直接内存 | 128 MB | taskmanager.memory.framework.off-heap.size |
| Task Off-Heap | 用户代码使用的堆外直接内存 | 0 | taskmanager.memory.task.off-heap.size |
| Network Memory | 网络数据交换的 Network Buffers | fraction 0.1 | taskmanager.memory.network.{fraction/min/max} |
| Managed Memory | Flink 管理的堆外内存(RocksDB/批处理排序/Python) | fraction 0.4 | taskmanager.memory.managed.{size/fraction} |
| JVM Metaspace | 类元数据存储 | 256 MB | taskmanager.memory.jvm-metaspace.size |
| JVM Overhead | 线程栈、代码缓存、GC 空间等 JVM 开销 | fraction 0.1 | taskmanager.memory.jvm-overhead.{fraction/min/max} |
-
Managed Memory
- 如果使用EmbeddedRocksDBStateBackend,Managed Memory 直接影响 RocksDB 的 Block Cache 和 Write Buffer 大小
- 如果使用HashMapStateBackend,流处理模式下 Managed Memory 几乎不使用,可适当调小
-
Network Memory
//用于 Task 之间数据交换的 Network Buffer Pool
Buffer 数量 = Network Memory / taskmanager.memory.segment-size (默认 32KB)
//并行度越高、shuffle 越多,需要的 Network Buffer 越多
-
Task Heap Memory
- 如果不显式配置
taskmanager.memory.task.heap.size,Flink 会根据 Total Flink Memory 减去其他所有组件来推导 - 使用 HashMapStateBackend(原 FsStateBackend)时,所有 State 数据都存储在 Task Heap 中
- 如果不显式配置
三、JobManager 内存模型
JobManager 内存模型架构图如下:
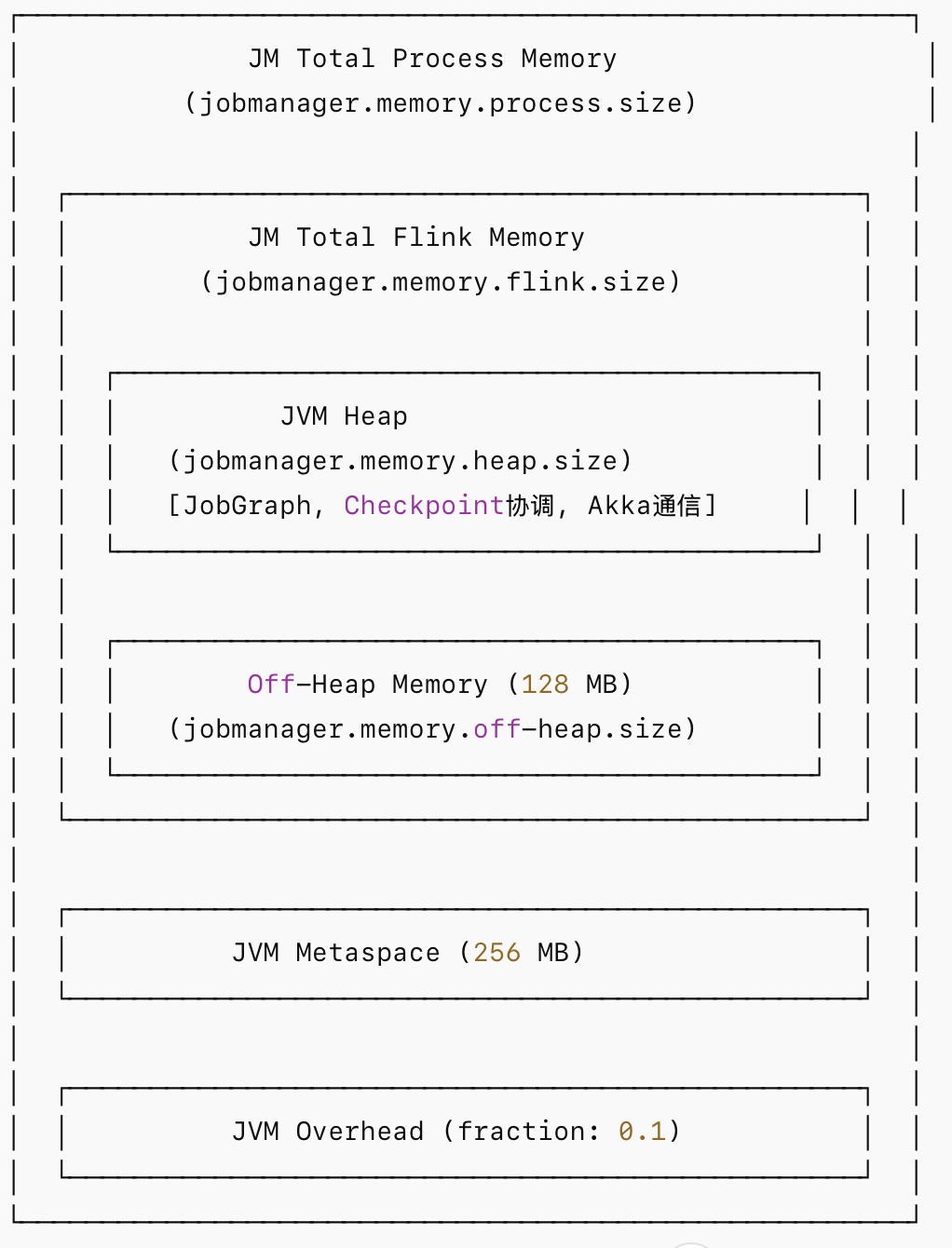
内存区域层级关系公式如下:
Total Process Memory = Total Flink Memory + JVM Metaspace + JVM Overhead
Total Flink Memory = Heap Memory + Off-Heap Memory大多数Flink流式作业JM Heap 2-4 GB 通常足够,若存在作业拓扑复杂(大量算子/并行度)、大量 Checkpoint 元数据等场景,适当增大 JM Heap。
四、核心参数配置策略与推演
在实际配置中,我们通常不建议手动配置每一个细分区域,而是采用"顶层决定底层"的策略,以下二选一确定总基座:
taskmanager.memory.process.size:进程总内存。推荐在容器化环境(YARN/K8s)中使用,因为这代表了 Pod/Container 的硬性资源限制(Resource Limit)。taskmanager.memory.flink.size:Flink 总内存。如果是 Standalone 物理机部署,推荐用这个。
Flink内存模型各区域核心比例参数按需调整:
- 网络内存:
taskmanager.memory.network.fraction(默认 0.1)。如果你的作业并行度极高,或者属于严重依赖 Shuffle 的复杂拓扑,可能需要调大此比例,避免Insufficient number of network buffers报错。 - 托管内存:
taskmanager.memory.managed.fraction(默认 0.4)。- 推演: 如果你使用
HashMapStateBackend且是流处理,这部分内存完全被浪费了,建议将其设为0.0或极小值,从而把宝贵的空间让给 Task Heap! - 推演: 如果你使用
RocksDBStateBackend,这 40% 的堆外内存是 RocksDB MemTable 和 BlockCache 的命脉,大状态作业下甚至需要调至 0.5-0.6。
- 推演: 如果你使用
- JVM 开销:
taskmanager.memory.jvm-overhead.fraction(默认 0.1)。下限为 192MB,上限为 1GB。
以配置taskmanager.memory.process.size = 4096m为例,内存分配推演如下:
Step 1: 计算 JVM Overhead
JVM Overhead = 4096 × 0.1 = 409.6 MB
约束检查: max(192MB, min(409.6MB, 1024MB)) = 409.6 MB ✓
Step 2: 计算 JVM Metaspace = 256 MB (默认值)
Step 3: 计算 Total Flink Memory
Total Flink Memory = 4096 - 409.6 - 256 = 3430.4 MB
Step 4: 计算 Managed Memory
Managed Memory = 3430.4 × 0.4 = 1372.16 MB
Step 5: 计算 Network Memory
Network Memory = 3430.4 × 0.1 = 343.04 MB
约束检查: max(64MB, min(343.04MB, 1024MB)) = 343.04 MB ✓
Step 6: 计算 Task Heap (推导)
Task Heap = Total Flink Memory - Framework Heap - Framework Off-Heap
- Task Off-Heap - Network - Managed
= 3430.4 - 128 - 128 - 0 - 343.04 - 1372.16
= 1459.2 MB五、常见问题诊断与调优实践
1.问题诊断决策树
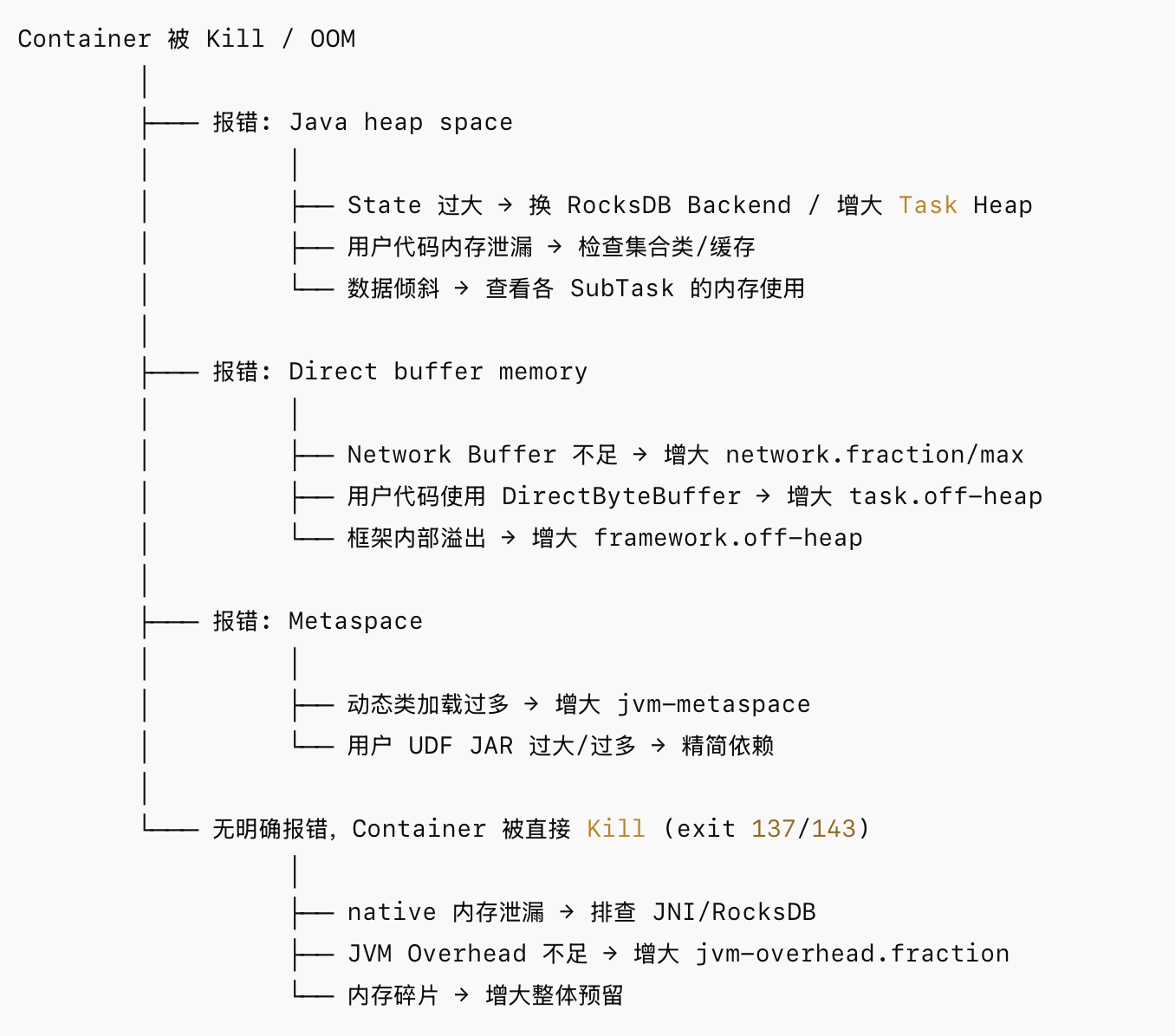
2.基于 State Backend 的调优策略

3.Network Memory 调优策略
| 场景 | Network 需求 | 建议 fraction |
|---|---|---|
| 纯 forward / rebalance 少 | 低 | 0.05~0.08 |
| 大量 keyBy / shuffle | 中等 | 0.1~0.15 |
| 高并行度 + 多 shuffle 阶段 | 高 | 0.15~0.2 |
4.最佳实践总结
- 明确状态后端类型:配置内存前,先问自己用的是 Heap 还是 RocksDB。Heap 贪图
Task Heap,RocksDB 贪图Managed Memory,两者此消彼长。 - 警惕容器化 OOM-Killer:在 K8s 环境下,永远为 JVM Overhead 和 Native Memory 留出安全边际,不要把内存用得太满。
- 监控先行:调优不是盲人摸象。务必接入 Flink Metrics(如
Status.JVM.Memory.Heap.Used、Status.Flink.Memory.Managed.Used),通过 Grafana 观察内存曲线再做决策。
Flink 的内存模型设计虽然复杂,但其背后的逻辑非常严密:将不可控的 OOM 转化为可控的框架内内存管理。通过理解 JVM 堆、托管内存、网络内存的三角关系,我们能够针对不同的业务场景(大状态、高并发、复杂计算)做出最合理的资源配置。