本篇文章更加偏向于理论上的更深层次理解,深度理解虚拟地址空间的作用,并引出结构体vm_area_struct,理解它对于虚拟地址空间构建的作用,以及验证命令行环境变量的地址高度
目录
[1.避免物理内存的 "提前闲置浪费"](#1.避免物理内存的 “提前闲置浪费”)
[2.物理内存的 "动态调度更灵活"](#2.物理内存的 “动态调度更灵活”)
[3.物理内存的 "碎片化问题被弱化"](#3.物理内存的 “碎片化问题被弱化”)
[把虚拟地址空间类比成 "进程专属的内存快递柜":](#把虚拟地址空间类比成 “进程专属的内存快递柜”:)
[1.进程 = 快递柜的使用者](#1.进程 = 快递柜的使用者)
[2.mm_struct = 快递柜的 "总说明书"](#2.mm_struct = 快递柜的 “总说明书”)
[3.vm_area_struct = 每个区域的 "分区标签"](#3.vm_area_struct = 每个区域的 “分区标签”)
[4.物理内存 = 真正的 "仓库"](#4.物理内存 = 真正的 “仓库”)
一、为什么要有虚拟地址空间?
根据前面的讲解,我们所能访问和看见的地址,通通都是虚拟地址,而虚拟地址与真实物理地址是需要通过页表来进行映射的,这样才能通过虚拟地址来间接修改物理地址上的数据内容。
但是我们总会有个疑问,为什么不能直接使用和修改真实物理内存空间,而要弄个虚拟地址空间出来呢?这不是会更麻烦吗?那我们来详细分析虚拟地址空间到底有什么用
1.保护物理内存
虚拟内存通过页表将虚拟地址映射到物理地址。每个进程都有自己独立的虚拟地址空间,与其他进程的虚拟地址空间相互隔离。虚拟地址空间能够防止进程直接访问物理内存出现的非法行为,比如当一个进程试图访问超出其虚拟地址空间范围的地址时,CPU会检测到这种非法访问,并触发一个缺页异常。内核捕获这个异常后,会判定这是一个无效的内存访问,从而阻止进程访问到其他进程或操作系统内核的物理内存,有效保护了物理内存的完整性和安全性。
2.将进程的内存空间分布无序变有序
一个进程占用的物理内存其实是由相当多的内存碎片组成的,比如一个进程100MB但是它在真实物理内存并非是一整块的100MB大小的内存,而是可能由多个10MB、20MB的内存碎片组成的,这样就看起来杂乱无章了,此时虚拟地址空间就起到了一个相当重要的作用
虚拟地址和物理地址是一个简单的映射关系,这就意味着无论你在物理空间的哪个角落,我都可以用虚拟地址映射找到你,那我们将虚拟地址组织有序,是不是就能把抽象的物理地址具象化了?如何将虚拟地址组织有序?于是我们就有了栈空间、堆空间、代码段等等,也就是我们之前看到的那张图
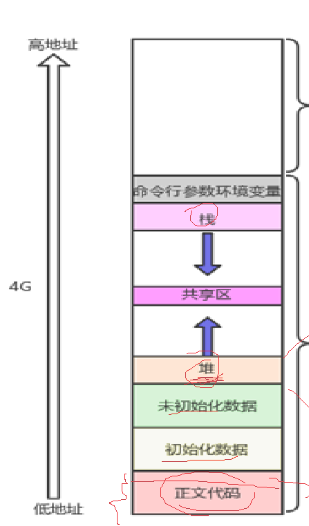
是不是一切都看得有序多了,只要通过这些有序的虚拟地址,不管进程的内存在物理地址中有多么散乱,就能映射出这些无序的物理内存,将它们全部找出来,真正实现了空间分布无序变有序!!!
3.解耦进程管理与内存管理
我们先来区分一下进程管理与内存管理的边界在哪里
当多个进程想要修改数据,就要通过虚拟地址和页表映射来进行一一修改,然后在物理内存划分出新的内存区域,添加修改内容。这句简单的总结包含了进程管理与内存管理,但是我们看到它明明 是一套连续且完整的流程,为什么说虚拟地址空间能够让它们关系解耦呢?
我们之前说过,创建一个新的进程的时候,是先创建它的内部数据结构,而数据和代码并没有马上得到,这是"懒加载"机制的思想,再引用之前"大富翁"的例子,我们知道每一个进程都以为自己独占了一整个物理内存空间,因此开辟一块空间对于进程来讲就是小case,那么当我们在堆上申请了一块空间比如 malloc(1024),它真的在物理内存上面申请的吗???当然不是,它是在虚拟内存空间上的堆区申请的,那么就会有人疑问,那都在虚拟内存空间申请了,根据页表上虚拟地址的映射关系,不正好对应物理空间也给它开辟了这么多空间吗?
虚拟地址空间解耦进程管理和内存管理的核心就在这里,在进程管理中,你申请了一大块的空间,有了一整块的虚拟地址,但是它映射的物理地址还不存在!!!因为此时你这一整块空间还没开始使用,给你对应的物理内存不是浪费了吗?物理内存不是马上全部给你,而是等到你要用的时候,才会给你动态申请相应的物理空间!
这就是解耦的核心所在,你在进程管理时不管申请了多少空间,也都只是虚拟地址空间,给你一批虚拟地址就是给你画的饼,在物理内存管理看来,这跟它没关系,不管你申请了多少,只要你没开始使用这些空间,我在物理空间就不会提前给你开辟放着不动,而是先给其他要用的进程!!!
总结:给地址 ≠ 给物理空间,这就是解耦的核心。
解耦的巨大优势:
1.避免物理内存的 "提前闲置浪费"
如果没有解耦,进程申请内存时内核必须立刻分配物理内存 ------ 哪怕进程申请了 1GB 内存但只用到 100MB,剩下的 900MB 物理内存会被 "占着不用",其他需要内存的进程只能干等。
而解耦后,进程申请的只是 "虚拟地址的饼",物理内存要等进程实际访问时才分配。比如进程malloc(1GB),内核只给它 1GB 虚拟地址,但物理内存还是空的;直到进程往其中写数据,内核才按 "用多少给多少" 的原则分配物理页。这样闲置的物理内存可以优先给其他正在使用的进程,避免了 "占着茅坑不拉屎" 的资源浪费。
2.物理内存的 "动态调度更灵活"
解耦后,进程管理(给虚拟地址)和内存管理(给物理内存)是独立的,进程可以 "大胆申请" 虚拟地址(反正只是逻辑范围),不用考虑物理内存是否足够;内核可以 "按需分配" 物理内存,把有限的物理页优先给当前活跃的进程(比如前台游戏进程优先获得物理内存,后台闲置的进程只保留虚拟地址,物理页被回收给其他进程),这种动态调度让物理内存的 "周转率" 大幅提升 ------ 同样的物理内存,能支撑更多进程同时运行,这对内存资源紧张的设备(如手机、嵌入式设备)尤为关键。
我说白了,目前手机的运行内存普遍也就8G或者16G,一个王者荣耀游戏都要几十个G,所以物理内存也只给核心运行的区域,而没有运行到的地方不给物理内存,这也就是为什么手机能运行大型游戏的原因。
3.物理内存的 "碎片化问题被弱化"
没有解耦时,进程申请连续物理内存会受限于物理碎片化(比如需要 100MB 连续物理内存,但实际只有零散的小页),而解耦后,进程申请的是连续虚拟地址,内核可以把分散的物理小页通过页表 "拼接" 成连续的虚拟地址(前面提到的 "物理无序→虚拟有序")。哪怕物理内存碎片化严重,只要有足够的空闲小页,就能满足进程的连续内存需求 ------ 这让物理内存的利用率更高,不用为了 "凑连续大块" 而浪费空闲小页。
简单说,解耦的本质是让物理内存 "用在刀刃上":不提前分配、不闲置、不被碎片化限制,把有限的物理资源优先分配给真正需要的进程和操作,这就是它提升内存使用高效性的核心逻辑
二、理解vm_area_struct
我们已经知道了mm_struct是虚拟地址空间的结构体,里面含有代码段、数据段、堆区、栈区等等虚拟空间,但是这些区域太过庞大,单独一个mm_struct结构体无法管理到位,于是mm_struct结构体当中又划分了许多空间,每一段空间由结构体vm_area_struct来管理,具体图如下:
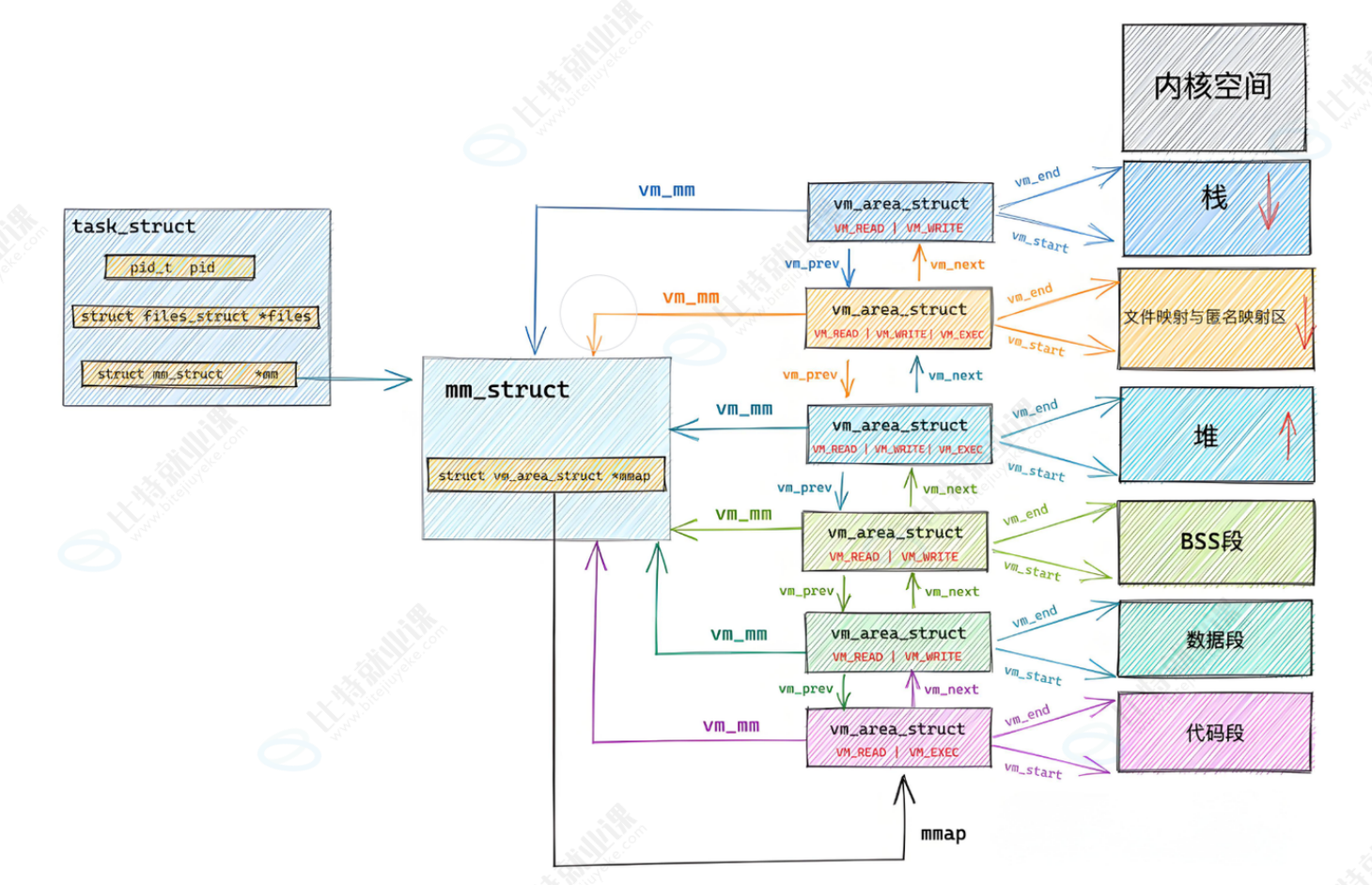
vm_area_struct由双向链表来连接,它们各自管辖着各自的空间,可以这样理解:
把虚拟地址空间类比成 "进程专属的内存快递柜":
1.进程 = 快递柜的使用者
每个进程都有一个专属的快递柜(虚拟地址空间),柜子上有很多格子(虚拟地址),只有这个进程能打开自己的柜子。
2.mm_struct = 快递柜的 "总说明书"
说明书里写着:这个柜子分了几个区域(比如 "放零食的格子"= 堆区,"放衣服的格子"= 栈区,"放书本的格子"= 代码段),每个区域有多大、能放什么东西。
3.vm_area_struct = 每个区域的 "分区标签"
比如堆区的标签写着:"这个区域从第 10 格到第 100 格,只能放零食(对应堆区的虚拟地址范围 + 读写权限)";代码段的标签写着:"这个区域从第 1 格到第 5 格,只能看不能拆(对应代码段的只读 + 执行权限)"。
4.物理内存 = 真正的 "仓库"
快递柜里的格子(虚拟地址)本身是空的,你往格子里放东西(比如malloc申请内存),其实是从仓库(物理内存)调货
你说 "我要在堆区第 10 格放个包裹",仓库不会立刻把包裹搬过来,等你真的要打开第 10 格(访问内存),仓库才把包裹送过来(内核分配物理内存)。
仓库里的包裹可能堆得很乱(物理内存碎片化),但快递柜的格子是按区域排好的(虚拟地址连续),你完全不用管仓库有多乱。
总结:这个图本质是 "快递柜(虚拟地址空间)的说明书 + 分区标签"
三、命令行参数环境变量地址验证展示
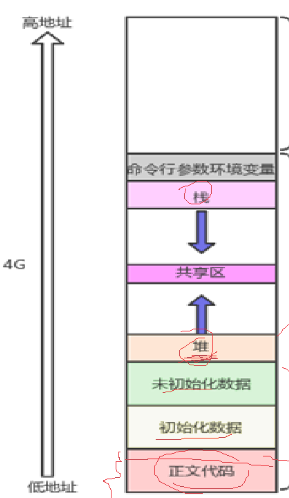
这个图我们是可以知道命令行参数环境变量的地址是比栈区还要高的,我们继续用代码验证一下,依旧使用第一篇虚拟地址空降讲解使用过的代码,我们额外添加打印环境变量地址的代码然后对比即可:
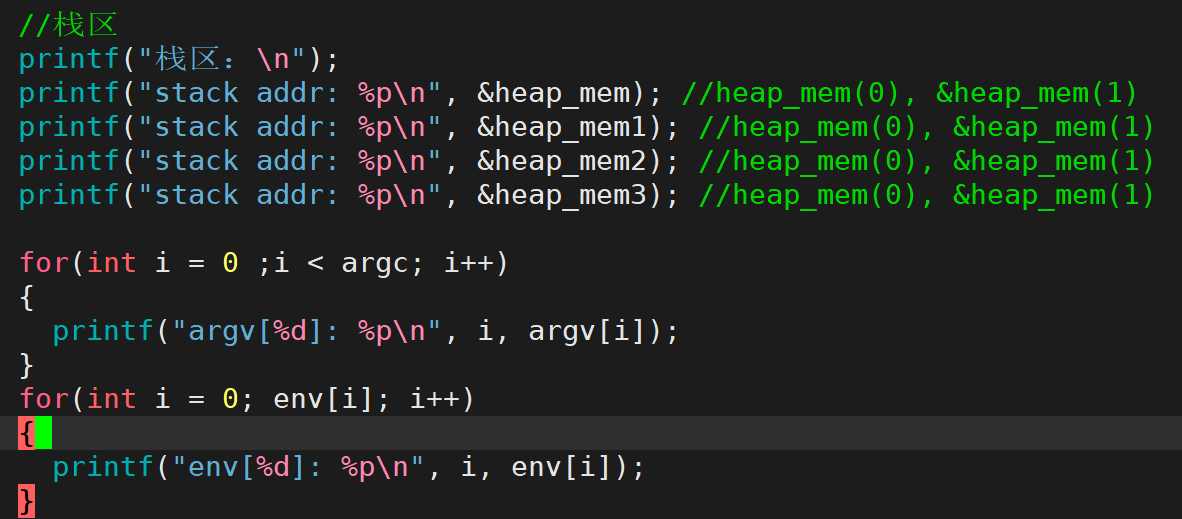
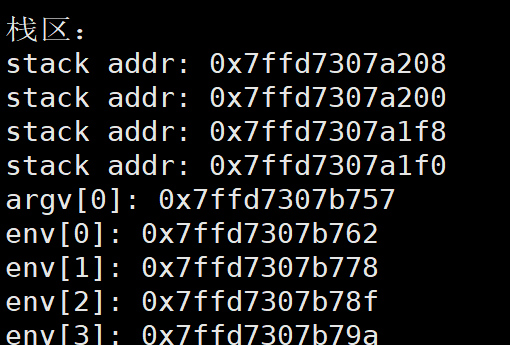
观察地址的后四位,很显然环境变量地址是比栈区的地址要高的,验证结论成立
四、测试代码
我将这三篇文章用到的完整测试代码放在这里给大家直接复制
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_unval;
int g_val = 100;
int main(int argc, char *argv[], char *env[])
{
const char *str = "helloworld";
printf("code addr: %p\n", main); //正文代码
printf("init global addr: %p\n", &g_val); //初始化数据
printf("uninit global addr: %p\n\n", &g_unval); //未初始化数据
static int test = 10;
char *heap_mem = (char*)malloc(10);
char *heap_mem1 = (char*)malloc(10);
char *heap_mem2 = (char*)malloc(10);
char *heap_mem3 = (char*)malloc(10);
//堆区
printf("堆区:\n");
printf("heap addr: %p\n", heap_mem); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem1); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem2); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n\n", heap_mem3); //heap_mem(0), &heap_mem(1)
printf("test static addr: %p\n\n", &test); //heap_mem(0), &heap_mem(1)
//栈区
printf("栈区:\n");
printf("stack addr: %p\n", &heap_mem); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem1); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem2); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n\n", &heap_mem3); //heap_mem(0), &heap_mem(1)
printf("read only string addr: %p\n", str);
for(int i = 0 ;i < argc; i++)
{
printf("argv[%d]: %p\n", i, argv[i]);
}
for(int i = 0; env[i]; i++)
{
printf("env[%d]: %p\n", i, env[i]);
}
return 0;
}至此,虚拟地址空间的大框架已经完全搭建完毕,对于学习后面的内容,理解到这个程度已经完全足够了,更多的虚拟地址空间相关的内容,我们在后面讲解的内容还会一一完善。后续内容也会持续更新,大家敬请期待!