1. τ定律概述
1.1. 韬定律(τ 定律)介绍
2026年5月25日,华为在上海ISCAS 2026由何庭波正式发布,核心是:用"时间缩微"替代"几何缩微",从"拼尺寸"转向"拼速度"。

"韬(τ)定律"被视为对摩尔定律的补充或替代,旨在通过系统性时间优化,推动半导体产业在性能、能效和集成度方面的持续演进。
1.2. 韬定律(τ 定律)发现趋势
- 已落地阶段(2020-2026):
- 基础验证期:过去6年累计量产381款芯片,覆盖通信、汽车、工业等多场景,完成全栈技术验证。
- 商用突破期(2026):麒麟2026手机SoC率先采用双层逻辑折叠技术,基于成熟制程实现性能与能效跃升。
- 中期演进(2027-2030)
- 堆叠层数扩展:从2层逻辑折叠向3-4层推进,进一步缩短信号路径、提升密度。
- 异构封装深化:在AI/服务器芯片中大规模应用2.5D/3D Chiplet架构,搭配灵衢总线实现系统级性能扩展。
- 长期目标(2031+)
- 高端芯片晶体管密度达到等效1.4nm制程水平,实现成熟制程向先进制程性能的等效跃迁。
- 构建覆盖从器件到系统的完整"时间缩微"技术生态,支撑下一代通用计算与AI算力需求。
2. 韬定律(τ 定律)核心架构
韬定律的核心逻辑:是以 "时间缩微(Time Scaling)" 替代传统 "几何缩微(Moore Scaling)";
-
时间常数 τ=R(寄生电阻)X C(寄生电容),实现性能、密度与能效的持续提升;
-
信号传输延迟≈τ;τ 越小,信号越快、带宽越高、能耗越低;
韬定律技术路径:通过逻辑折叠、3D堆叠、软硬协同等全栈技术优化;
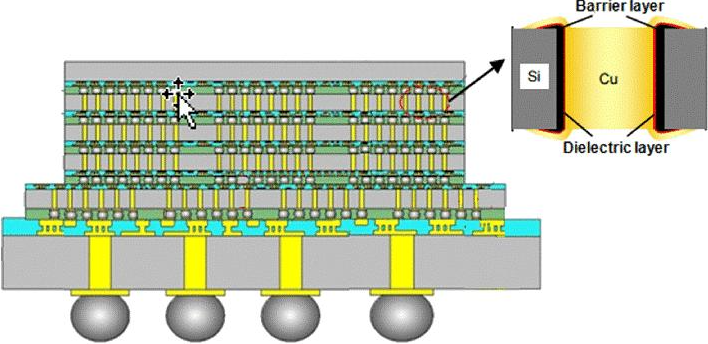
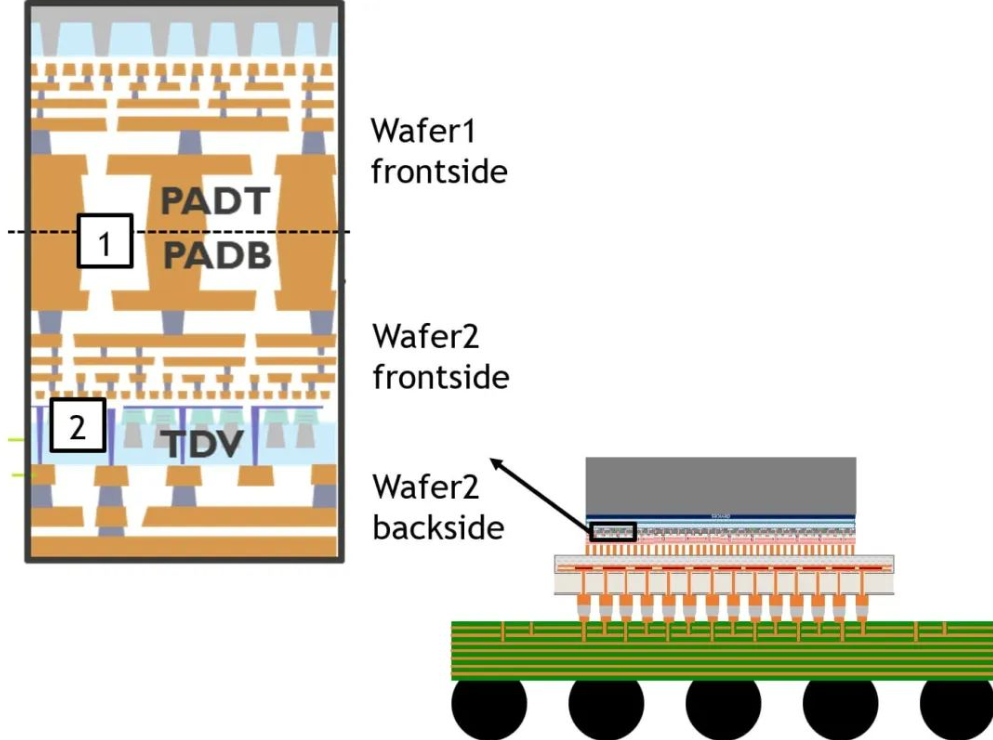
韬定律核心优势:降低对EUV的依赖,盘活成熟制程资源,实现芯片性能与能效的双重跃升;
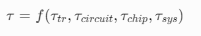
-
τ:系统总延迟(时间常数),是韬定律的核心优化目标。
-
它由四个层级的延迟共同决定:器件级(τ_tr)、电路级(τ_circuit)、芯片级(τ_chip)、系统级(τ_sys)。韬定律的本质,就是通过全栈协同,系统性降低这四个层级的延迟,从而实现性能提升。
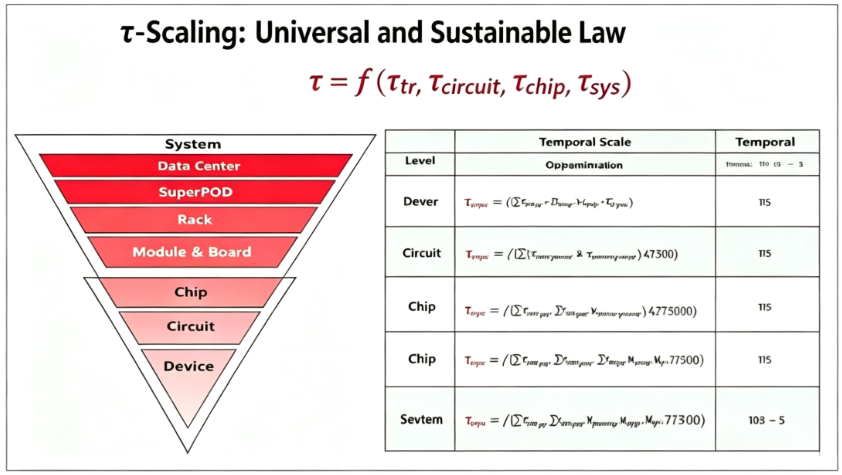
金字塔直观展示了从微观到宏观的延迟来源层级:
-
Device(器件层):晶体管与互连线的基础 RC 延迟
-
Circuit(电路层):逻辑门与布线的路径延迟
-
Chip(芯片层):片内计算、存储与 I/O 协同的延迟
-
Module & Board(模块 / 板级):板上芯片间通信延迟
-
Rack(机柜):机柜内模块间通信延迟
-
SuperPOD(超级集群):多机柜集群间通信延迟
-
Data Center(数据中心):整个数据中心的系统级延迟
每个层级的延迟模型与时间量级:
| 层级 | 目标函数 | 时间尺度 | 核心解读 |
|---|---|---|---|
| Device | 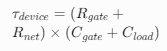 |
ps(皮秒) | 最基础的 RC 延迟,由晶体管栅极、互连线的电阻与电容决定。韬定律通过优化器件材料与结构,直接降低此基础值。 |
| Circuit | 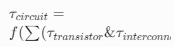 |
ns(纳秒) | 电路延迟由晶体管开关、互连布线延迟,以及动态时序优化(DTCO)共同决定。逻辑折叠技术正是为了大幅缩短互连线延迟。 |
| Chip | 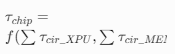 |
μs(微秒) | 芯片级延迟由计算单元、存储单元、I/O 的电路延迟,以及并行度、效率等架构因素决定。软硬协同优化旨在减少无效等待,降低整体延迟。 |
| System | 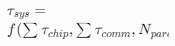 |
ms ~ s(毫秒~秒) | 系统级延迟由各芯片延迟、芯片间通信延迟,以及系统级的并行度、可靠性、软件优化等决定。灵衢总线的目标就是将跨芯片通信延迟从微秒级降至百纳秒级。 |
韬定律的核心不是单一技术,而是一套全栈方法论:从最底层的 RC 延迟,到电路、芯片,再到整个数据中心,系统性地降低时间常数 τ。
3. 摩尔定律(平面芯片)与韬定律(逻辑折叠 + 3D 堆叠)技术对比表
-
韬定律的核心不是单一技术,而是一套全栈方法论:从最底层的 RC 延迟,到电路、芯片,再到整个数据中心,系统性地降低时间常数 ;
-
与传统摩尔定律依赖 "缩小尺寸" 不同,韬定律通过时间缩微,在成熟制程上实现了性能与能效的跃升,为后摩尔时代提供了可持续的技术路径;
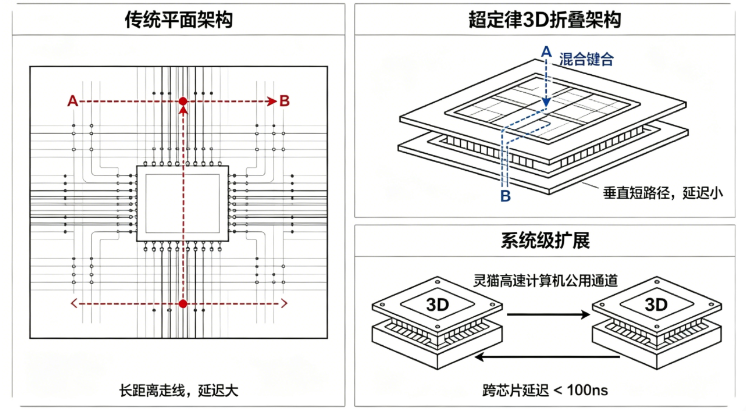
3.1. 整体架构和信号路径对比
| 对比维度 | 传统平面芯片(摩尔路线) | 华为韬定律(逻辑折叠 + 3D 堆叠) |
|---|---|---|
| 整体架构 | 逻辑单元平铺于XY 平面(单层结构) | 基于Z 轴堆叠(2~4 层立体结构),采用逻辑折叠技术 |
| 核心信号路径 | 单元 A → 长距离水平金属走线 → 单元 B | 层 1(主逻辑 / 计算层)→ 混合键合垂直通道 → 层 2(互连 / 存储层) |
| 走线形式 | 全程水平长走线 | 以垂直短走线为主,水平走线大幅缩减 |
| 走线长度 | 走线距离长 | 相比平面方案缩短50% 以上 |
3.2. 硬件工艺与电气特性
| 对比维度 | 传统平面芯片(摩尔路线) | 华为韬定律(逻辑折叠 + 3D 堆叠) |
|---|---|---|
| 互连工艺 | 常规金属布线 | 混合键合 (Hybrid Bonding),无焊料,引脚间距<1μm,支持万级 I/O |
| RC 参数 | 走线长,电阻 R、电容 C 数值大 | 走线极短,R、C 显著降低 |
| 信号延迟 | 微秒 (μs) 级 | 纳秒 (ns) 级,延迟大幅下降 |
| 功耗表现 | 走线损耗大,整体功耗偏高 | 路径损耗小,功耗明显优化 |
| 芯片限速逻辑 | 由最长关键路径决定整颗芯片运行速度 | 路径统一缩短,不再受长走线制约 |
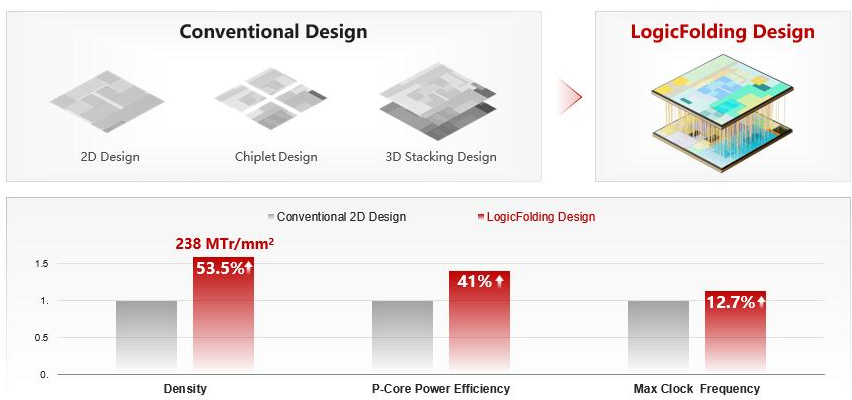
3.2. 关键性能对比
| 对比指标 | 传统平面 / 堆叠方案 | LogicFolding 设计 | 提升幅度 | 关键说明 |
|---|---|---|---|---|
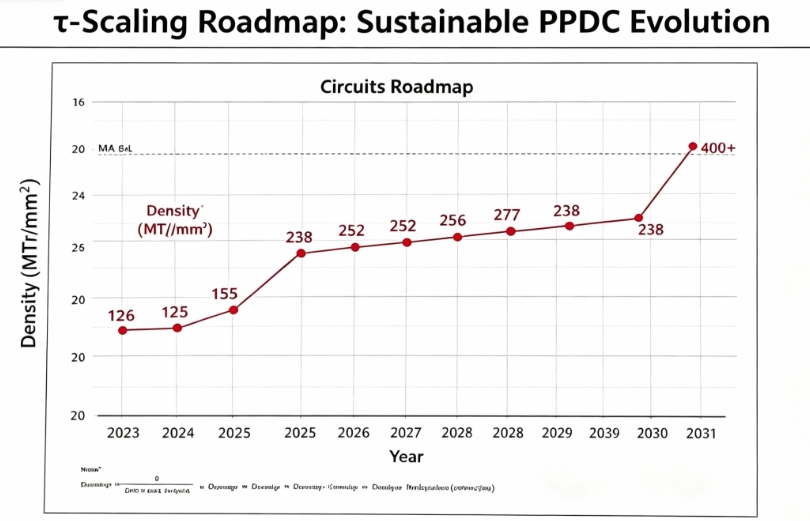
| 晶体管密度 | 基准(约 155 MTr/mm²) | 238 MTr/mm² | +53.5% | 首次实现单层平面到双层有源架构的密度跃升,等效制程节点大幅推进 |
| P 核功耗效率 | 基准 | 提升 41% | +41% | 关键路径缩短、RC 延迟降低带来的能效比显著优化 |
| 最高主频 | 基准(约 2.75GHz) | 提升至约 3.1GHz | +12.7% | 延迟降低使核心频率突破传统工艺瓶颈 |
4. 韬定律(τ 定律)意义
-
中国首次在全球半导体领域提出系统性产业演进原则;
-
为后摩尔时代提供不依赖 EUV 的可行路线,对冲先进制程封锁;
-
让成熟制程(28/14nm)重定义为 "高性能制程",盘活国内晶圆厂投资;