
✨ 把代码写进星轨,
用逻辑丈量宇宙。
| 导航 | 链接 |
|---|---|
| 个人主页 | 🏠 星轨初途 |
| 基础语言专栏 | 💻 C语言 、 📚 数据结构 |
| C++ 进阶专栏 | 🏆 C++学习(竞赛类) 、 ⚙️ C++专栏(开发类) |
| 刷题实战专栏 | 🚀 算法及编程题分享 |

文章目录
- 前言
- [一、list 是什么?](#一、list 是什么?)
-
-
- [🎯 链表(list)的核心特性与优缺点](#🎯 链表(list)的核心特性与优缺点)
-
- 二、list常见构造方式
- 三、list迭代器的使用
- 四、list容量和元素访问
- 五、list的增删查改
- 六、常见算法操作
- [七、避坑指南:list 迭代器失效深度解析](#七、避坑指南:list 迭代器失效深度解析)
-
-
- [1. 插入操作:永远不会失效](#1. 插入操作:永远不会失效)
- [2. 删除操作:局部失效](#2. 删除操作:局部失效)
- [3. 正确的解决办法](#3. 正确的解决办法)
- [💡 深度对比:vector vs list 迭代器失效](#💡 深度对比:vector vs list 迭代器失效)
-
- 八、对比vector和list
- 结束语
前言
在前几篇文章中,我们深入解析并手撕了 vector 的底层实现,深刻体会到了连续内存带来的极速随机访问体验(时间复杂度 O ( 1 ) O(1) O(1))。但是,vector 也有一个致命的软肋:如果在头部或中间进行插入和删除操作,需要挪动大量数据,效率极低(时间复杂度 O ( N ) O(N) O(N));同时,空间不足时的扩容也会带来较大的性能开销。
为了解决这种"频繁在任意位置增删数据"的痛点,C++ 标准模板库(STL)为我们准备了另一把神兵利器------list(链表)。今天,就让我们一起来揭开它的神秘面纱。
一、list 是什么?
list 的本质是一个带头双向循环链表。
如果你在数据结构阶段学过链表,那你一定知道这是链表结构中最复杂、但也最完美、最实用的一种形态。我们来拆解一下这几个关键词:
- 带头(哨兵位):链表内部维护了一个不存储有效数据的"哨兵位节点(头节点)"。它的存在极大地简化了代码逻辑,让你在进行头插、尾插、头删、尾删时,完全不需要去判断链表是否为空,避免了繁琐的空指针检查。
- 双向 :每个节点除了存储数据外,还包含两个指针:一个指向前一个节点(
prev),一个指向后一个节点(next)。这使得链表不仅能从前往后遍历,还能从后往前遍历。 - 循环 :链表尾节点的
next指向哨兵位节点,而哨兵位节点的prev指向尾节点。它们首尾相连,形成了一个闭环。
底层结构示意图:
text
+---------------------------------------------------------+
| |
v |
+------------+ +------------+ +------------+ |
| | next | | next | | |
| 哨兵位 | -----> | 节点 1 | -----> | 节点 2 | ----+ |
| (不存数据) | <----- | (有效数据) | <----- | (有效数据) | <---+
| | prev | | prev | |
+------------+ +------------+ +------------+ 🎯 链表(list)的核心特性与优缺点
与 vector 相比,list 具有截然不同的特性,它们俩可以说是"相爱相杀"的互补关系:
✨ 优点:
- 极致的插入/删除效率 :只要拿到了目标位置的迭代器,在任意位置进行插入和删除操作的时间复杂度都是真正的 O ( 1 ) O(1) O(1),不需要挪动任何其余元素。
- 按需分配,拒绝浪费 :每次插入一个新元素,就单独向系统申请一块该节点大小的内存;删除元素时立刻释放。不存在
vector那样需要提前预留空间或扩容带来的内存浪费与拷贝开销。 - 迭代器极少失效 :在
list中进行插入操作绝对不会导致原有迭代器失效;进行删除操作时,也只有被删除的那个节点的迭代器会失效,其余节点的迭代器依然坚挺(而vector一旦扩容,所有迭代器全部报废)。
🧨 缺点:
- 不支持随机访问 :这也是它最大的硬伤。由于内存物理空间不连续,
list无法像数组那样使用operator[](即list[i])来直接访问第i个元素。要想找某个元素,只能老老实实从头(或尾)开始遍历,时间复杂度为 O ( N ) O(N) O(N)。 - CPU 高速缓存命中率极低 :由于节点是随用随申请的,它们在内存中就像是漫天散落的星星,物理地址相差甚远,这导致 CPU 缓存预取数据的机制彻底失效,遍历速度在底层硬件级别上远不如
vector。 - 空间开销较大:每个节点除了存放数据,还需要额外存放至少两个指针(在 64 位系统下就是 16 字节的额外开销),存储密度低。
🔗 官方参考文档: cplusplus - list 详解
二、list常见构造方式
| 构造函数 ( (constructor)) | 接口说明 |
|---|---|
| list (size_type n, const value_type& val = value_type()) | 构造的 list 中包含 n 个值为 val 的元素 |
| list() | 构造空的 list |
| list (const list& x) | 拷贝构造函数 |
| list (InputIterator first, InputIterator last) | 用 [first, last) 区间中的元素构造 list |
cpp
#include <iostream>
#include <list>
#include <vector>
using namespace std;
int main() {
// 1. 无参构造:list()
// 结果: 创建一个空的链表
list<int> l1;
// 2. 填充构造:list(size_type n, const value_type& val)
// 结果: l2 包含 5 个值为 10 的元素 {10, 10, 10, 10, 10}
list<int> l2(5, 10);
// 3. 拷贝构造:list(const list& x)
// 结果: l3 深拷贝 l2 的数据,包含 {10, 10, 10, 10, 10}
list<int> l3(l2);
// 4. 迭代器区间构造:list(InputIterator first, InputIterator last)
// 结果: 使用 vector 的迭代器区间初始化,l4 包含 {1, 2, 3}
vector<int> v = {1, 2, 3};
list<int> l4(v.begin(), v.end());
return 0;
}三、list迭代器的使用
由于 list 的底层物理空间不连续,我们不能 使用 [] 来遍历它。迭代器是 list 最核心的遍历方式。
| 函数声明 | 接口说明 |
|---|---|
| begin + end | 返回第一个元素的迭代器 + 返回最后一个元素下一个位置的迭代器 |
| rbegin + rend | 返回第一个元素的 reverse_iterator,即 end 位置;返回最后一个元素下一个位置的 reverse_iterator,即 begin 位置。 |
以下是正向和反向遍历的简洁代码示例:
C++
cpp
#include <iostream>
#include <list>
using namespace std;
int main()
{
list<int> lt = {1, 2, 3, 4, 5};
// ==========================================
// 1. 正向遍历 (begin + end)
// ==========================================
cout << "正向遍历: ";
// begin() 指向 1,end() 指向 5 的下一个位置(越界标志)
list<int>::iterator it = lt.begin();
while (it != lt.end()) {
cout << *it << " ";
++it;
}
cout << endl; // 输出: 1 2 3 4 5
// ==========================================
// 2. 反向遍历 (rbegin + rend)
// ==========================================
cout << "反向遍历: ";
// rbegin() 指向最后一个元素 5,rend() 指向第一个元素 1 的前一个位置
list<int>::reverse_iterator rit = lt.rbegin();
while (rit != lt.rend())
{
cout << *rit << " ";
++rit; // 注意:反向迭代器执行 ++ 操作,实际上是向链表头部移动
}
cout << endl; // 输出: 5 4 3 2 1
return 0;
}补充小贴士: 在现代 C++ 中,如果你只需要顺序读取数据,强烈建议直接使用范围
for循环 (for (auto e : lt)),它的底层其实就是用begin和end迭代器实现的,代码会更加清爽。

四、list容量和元素访问
| 函数声明 | 接口说明 |
|---|---|
| empty | 检测 list 是否为空,是返回 true,否则返回 false |
| size | 返回 list 中有效节点的个数 |
| front | 返回 list 的第一个节点中值的引用 |
| back | 返回 list 的最后一个节点中值的引用 |
- 💡 代码实战演示
cpp
#include <iostream>
#include <list>
using namespace std;
int main()
{
list<int> lt = {10, 20, 30, 40};
// ==========================================
// 1. 容量接口测试 (Capacity)
// ==========================================
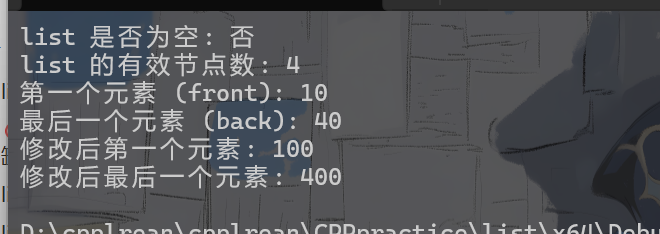
cout << "list 是否为空: " << (lt.empty() ? "是" : "否") << endl; // 输出: 否
cout << "list 的有效节点数: " << lt.size() << endl; // 输出: 4
// ==========================================
// 2. 元素访问接口测试 (Element Access)
// ==========================================
cout << "第一个元素 (front): " << lt.front() << endl; // 输出: 10
cout << "最后一个元素 (back): " << lt.back() << endl; // 输出: 40
// 【重点避坑/进阶】:因为返回的是引用,可以直接修改头尾的值
lt.front() = 100;
lt.back() = 400;
cout << "修改后第一个元素: " << lt.front() << endl; // 输出: 100
cout << "修改后最后一个元素: " << lt.back() << endl; // 输出: 400
return 0;
}
五、list的增删查改
| 函数声明 | 接口说明 |
|---|---|
| push_front | 在 list 首元素前插入值为 val 的元素 |
| pop_front | 删除 list 中第一个元素 |
| push_back | 在 list 尾部插入值为 val 的元素 |
| pop_back | 删除 list 中最后一个元素 |
| insert | 在 list position 位置中插入值为 val 的元素 |
| erase | 删除 list position 位置的元素 |
| swap | 交换两个 list 中的元素 |
| clear | 清空 list 中的有效元素 |
- 💡 代码实战演示
由于 list 是双向链表,它的头插、头删效率和尾插、尾删一样,都是 O ( 1 ) O(1) O(1),这点远胜于 vector。
cpp
#include <iostream>
#include <list>
#include <algorithm> // 为了使用 find
using namespace std;
// 辅助打印函数
void print_list(const list<int>& lt, const string& name)
{
cout << name << ": ";
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
}
int main()
{
list<int> lt;
// ==========================================
// 1. 头尾插入与删除 (push / pop)
// ==========================================
lt.push_back(10); // 尾插 10
lt.push_back(20); // 尾插 20
lt.push_front(5); // 头插 5
lt.push_front(1); // 头插 1
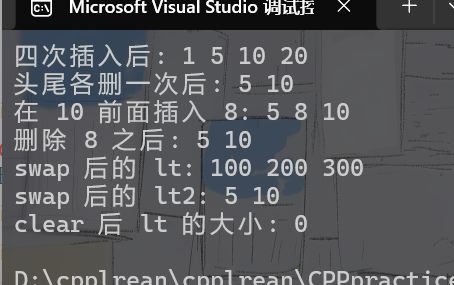
print_list(lt, "四次插入后"); // 输出: 1 5 10 20
lt.pop_front(); // 头删 (删掉 1)
lt.pop_back(); // 尾删 (删掉 20)
print_list(lt, "头尾各删一次后"); // 输出: 5 10
// ==========================================
// 2. 指定位置插入与删除 (insert / erase)
// ==========================================
// 注意:list 没有 find 成员函数,需要使用 <algorithm> 里的全局 find
auto pos = find(lt.begin(), lt.end(), 10);
if (pos != lt.end())
{
// 在 10 的前面插入 8
lt.insert(pos, 8);
}
print_list(lt, "在 10 前面插入 8"); // 输出: 5 8 10
// 再找一次 8,把它删掉
pos = find(lt.begin(), lt.end(), 8);
if (pos != lt.end())
{
lt.erase(pos);
}
print_list(lt, "删除 8 之后"); // 输出: 5 10
// ==========================================
// 3. 交换与清空 (swap / clear)
// ==========================================
list<int> lt2 = {100, 200, 300};
// 交换 lt 和 lt2 的内容 (极速交换,只换指针不拷数据)
lt.swap(lt2);
print_list(lt, "swap 后的 lt"); // 输出: 100 200 300
print_list(lt2, "swap 后的 lt2"); // 输出: 5 10
// 清空 lt (保留哨兵位,只是干掉有效节点)
lt.clear();
cout << "clear 后 lt 的大小: " << lt.size() << endl; // 输出: 0
return 0;
}
六、常见算法操作
在 C++ 中,很多算法都定义在 <algorithm> 头文件中。但是,由于 list 的底层是物理空间不连续的链表,它不支持随机访问迭代器 。因此,对于需要大量跳跃访问的算法(如排序),list 无法使用全局版本的算法,而是在类内部自己实现了这些专用的成员函数。
- list 常见算法接口
| 函数声明 / 算法 | 接口说明 |
|---|---|
std::find (全局) |
查找值为 val 的元素,返回该位置的迭代器。若未找到,返回 end()。 |
reverse (成员) |
将 list 中的元素逆序排列。 |
sort (成员) |
对 list 中的元素进行升序排序。 |
unique (成员) |
去除 list 中连续的 重复元素(通常配合 sort 一起使用)。 |
⚠️ 【重要避坑】:为什么 list 必须用自己的
sort()?
<algorithm>库中的std::sort底层使用的是快速排序等算法,要求容器必须支持随机访问迭代器 (能够直接使用it + n或it - n的操作)。而list的迭代器是双向迭代器 ,不支持加减运算,因此如果强行对list使用std::sort会导致编译报错。所以,list专门提供了属于自己的成员函数lt.sort()(底层基于归并排序实现)。
- 💡 代码实战演示
下面这段代码演示了这四个最常用算法的具体用法。特别要注意 unique() 去重的前提条件:
cpp
#include <iostream>
#include <list>
#include <algorithm> // 为了使用全局的 std::find
using namespace std;
// 辅助打印函数
void print_list(const list<int>& lt, const string& name)
{
cout << name << ": ";
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
}
int main()
{
list<int> lt = {5, 2, 8, 5, 1, 9, 2, 2, 8};
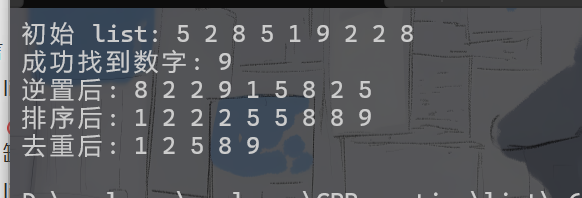
print_list(lt, "初始 list");
// 输出: 5 2 8 5 1 9 2 2 8
// ==========================================
// 1. 查找 (std::find) -> 属于全局算法
// ==========================================
auto pos = find(lt.begin(), lt.end(), 9);
if (pos != lt.end())
{
cout << "成功找到数字: " << *pos << endl;
}
// ==========================================
// 2. 逆置 (reverse) -> 属于成员函数
// ==========================================
lt.reverse();
print_list(lt, "逆置后");
// 输出: 8 2 2 9 1 5 8 2 5
// ==========================================
// 3. 排序 (sort) -> 属于成员函数
// ==========================================
// 注意:绝对不能写成 std::sort(lt.begin(), lt.end()); 会编译报错!
lt.sort();
print_list(lt, "排序后");
// 输出: 1 2 2 2 5 5 8 8 9
// ==========================================
// 4. 去重 (unique) -> 属于成员函数
// ==========================================
// 注意:unique 只能去除【连续的】重复元素。
// 因此,在去重之前,通常必须要先调用 sort() 将相同的元素排列在一起!
lt.unique();
print_list(lt, "去重后");
// 输出: 1 2 5 8 9
return 0;
}
在你的 vector 博客之后补充 list 的迭代器失效,是一个非常专业的举动。因为 vector 和 list 在内存结构上的巨大差异,导致了它们在"迭代器失效"表现上的截然不同。
以下是为你润色和补充的**"七、避坑指南:list 迭代器失效深度解析"**专题内容:
七、避坑指南:list 迭代器失效深度解析
在上一篇 vector 的底层实现中,我们提到了 vector 扩容会导致"全军覆没"(所有迭代器失效)。而 list 由于其非连续存储的特性,在迭代器失效的表现上要"温柔"得多。
1. 插入操作:永远不会失效
在 vector 中,push_back 或 insert 可能会触发扩容导致内存搬迁,从而使所有迭代器失效。
但在 list 中,插入一个新节点只需:
- 申请一个新节点的内存。
- 改变前后节点的
next和prev指针。
结论 :在 list 中进行 insert 或 push 操作,原有的任何迭代器都不会失效。它们依然忠实地指向原来那个节点,因为那个节点的物理地址从始至终都没有改变。
2. 删除操作:局部失效
list 的迭代器失效只发生在一种情况下:执行 erase 或 pop 时。
由于 list 的每个节点是独立申请的,当你删除某个节点时,只有指向当前被删除节点的那个迭代器会失效(因为它指向的内存被释放了),而指向其他节点的迭代器依然是安全有效的。
💣 错误示范:
cpp
auto it = lt.begin();
while (it != lt.end())
{
if (*it % 2 == 0)
{
lt.erase(it); // ❌ 此时 it 已经指向了一块被销毁的内存,变成了野指针
}
++it; // ❌ 对失效的 it 进行自增,程序会崩溃
}3. 正确的解决办法
与 vector 相同,list::erase 会返回被删除节点下一个位置的有效迭代器。我们必须利用这个返回值来更新我们的迭代器。
✅ 正确示范(删除所有偶数):
C++
cpp
auto it = lt.begin();
while (it != lt.end())
{
if (*it % 2 == 0)
{
// erase 返回下一个有效位置,完美衔接
it = lt.erase(it);
}
else
{
// 只有没删除时才手动自增
++it;
}
}💡 深度对比:vector vs list 迭代器失效
| 操作 | vector 迭代器失效情况 | list 迭代器失效情况 |
|---|---|---|
| 插入 (insert/push) | 可能全部失效 (触发扩容时) | 永不失效 |
| 删除 (erase/pop) | 被删位置及之后全部失效 | 仅被删节点失效 |
| 失效根源 | 内存挪动/空间释放 | 仅当前节点空间释放 |
八、对比vector和list
| 特性 | vector | list |
|---|---|---|
| 底层结构 | 动态顺序表,一段连续空间 | 带头结点的双向循环链表 |
| 随机访问 | 支持随机访问,访问某个元素效率O(1) | 不支持随机访问,访问某个元素效率O(N) |
| 插入和删除 | 任意位置插入和删除效率低,需要搬移元素,时间复杂度为O(N),插入时有可能需要增容,增容:开辟新空间,拷贝元素,释放旧空间,导致效率更低 | 任意位置插入和删除效率高,不需要搬移元素,时间复杂度为O(1) |
| 空间利用率 | 底层为连续空间,不容易造成内存碎片,空间利用率高,缓存利用率高 | 底层节点动态开辟,小节点容易造成内存碎片,空间利用率低,缓存利用率低 |
| 迭代器 | 原生态指针 | 对原生态指针(节点指针)进行封装 |
| 迭代器失效 | 在插入元素时,要给所有的迭代器重新赋值,因为插入元素有可能会导致重新扩容,致使原来迭代器失效,删除时,当前迭代器需要重新赋值否则会失效 | 插入元素不会导致迭代器失效,删除元素时,只会导致当前迭代器失效,其他迭代器不受影响 |
| 使用场景 | 需要高效存储,支持随机访问,不关心插入删除效率 | 大量插入和删除操作,不关心随机访问 |
💡 核心建议:日常开发 90% 的场景请无脑选择
vector!现代 CPU 高速缓存(Cache)对连续内存的预取优化,让
vector的遍历和操作速度极快。只有当你确实需要高频在任意位置增删数据,或者单个元素体积巨大拷贝成本过高时,才考虑使用
list。
结束语
本文我们从底层结构出发,全面梳理了 C++ list 的核心机制与实战用法。最后,我们提炼出以下三条核心开发准则:
- 精准定位容器特性 :
list作为带头双向循环链表,其最大的价值在于 O ( 1 ) O(1) O(1) 的任意位置极速增删 ,完美弥补了vector在数据搬移和扩容时的性能短板。 - 警惕专属算法与迭代器陷阱 :由于物理空间不连续,
list无法使用std::sort等需要随机访问的全局算法,必须依赖类内专属成员函数;此外,在执行erase删除操作时,务必利用其返回值来安全更新迭代器,避免坠入野指针陷阱。 - 业务导向的工程选型 :由于 CPU 缓存等硬件特性的限制,在绝大多数常规场景中,
vector依然是首选;只有当业务明确面临海量、高频的中间位置增删时 ,才应祭出list这把利器。
理解并掌握 list 与 vector 的物理结构差异与互补关系,能够帮助我们在面对复杂的业务数据流时,做出最合理的底层选型。下一篇我们将讲解list的底层实现,让我们更加了解它吧!