刚刚,Claude 官方发布了自己的最新模型,Opus 4.8。距离上一代 4.7 只隔了 41 天,是它历代小版本里最快的一次。
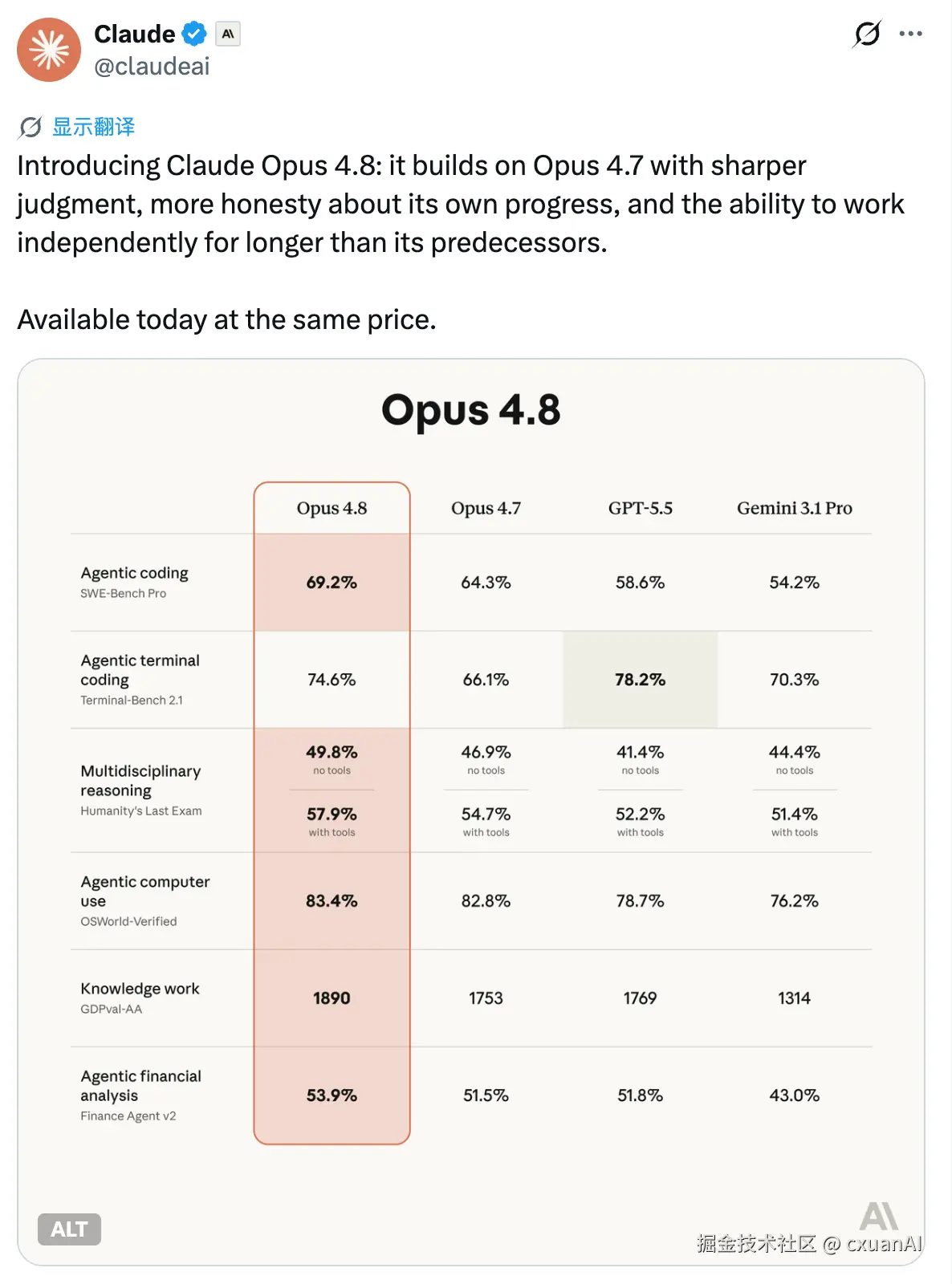
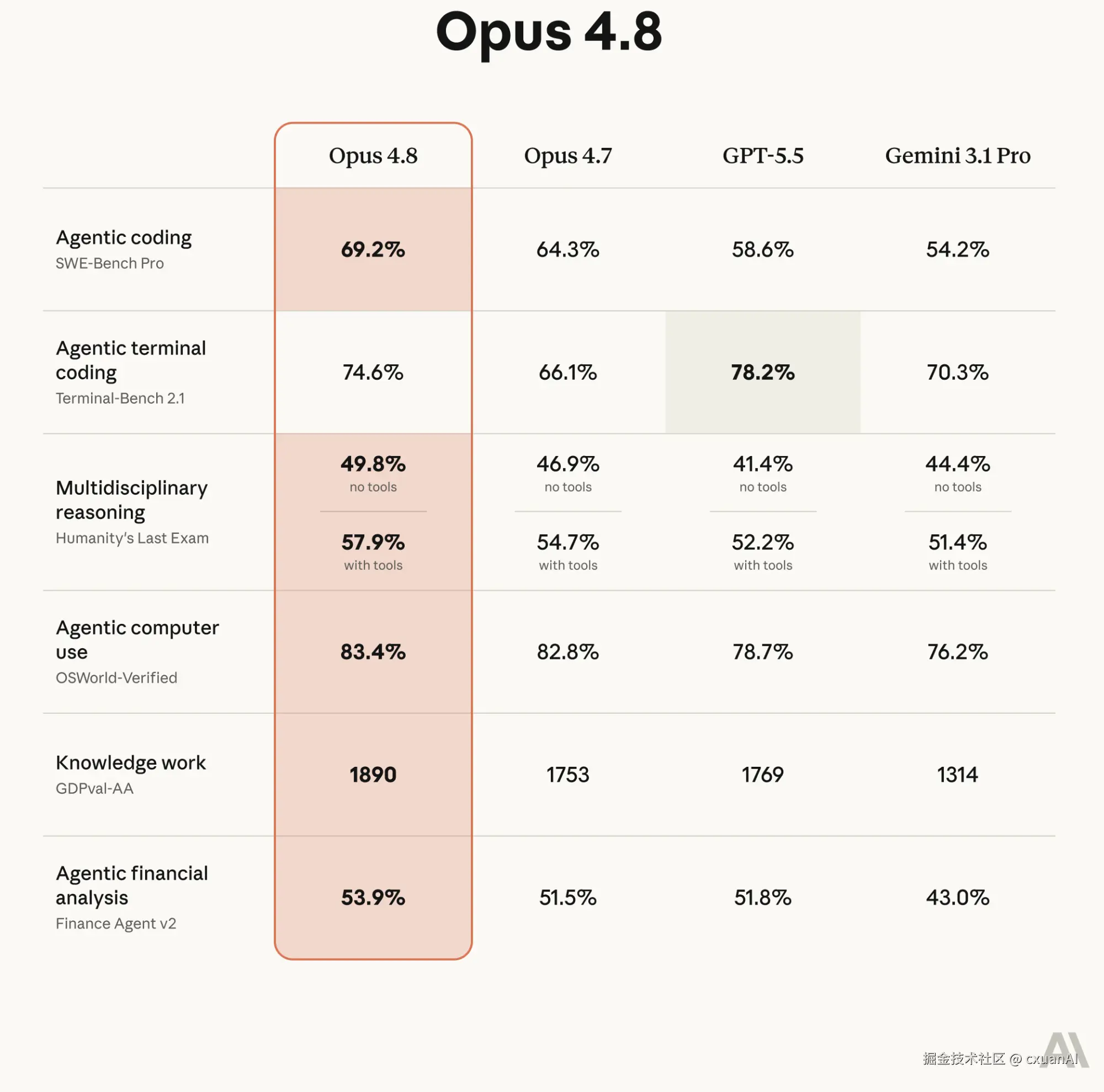
从 4.8 和 4.7 的对比上来看,没有太多明显的突出的优势。甚至有一项数字 Terminal coding ,不如 GPT 5.5 。这个说的是考虑命令行里的复杂编排。
讽刺的是,4.8 在这个榜上从 66.1% 干到 74.6%,+8.5 个点,是它所有项目里单项涨幅最大的一个。结果还是输了,GPT-5.5 在这里 78.2%,还是压着它。
而官方的声明则表是,Opus 4.8 要具备更敏锐的判断力,对自身进展的诚实度更高,而且能够比之前的模型更长时间的独立工作。
token 标准价格没动,还是 5/25 每百万 token。
变的是 fast mode。Opus 4.8 的是 10/50,速度 2.5 倍;而 4.7 的要 30/150。同样的高速档,便宜了 3 倍。
官方还说,Opus 4.8 可以像经验丰富的工程师一样进行调用,而无需持续检查。
它在长时间运行的会话中保持专注,并在你的代码库中跟踪工作进展,因此你可以将一项功能或 bug 排查任务交给它,同时专注于下一步。(我想大家对 Opus 的期待不仅只是一项功能或者改一个 bug 吧)
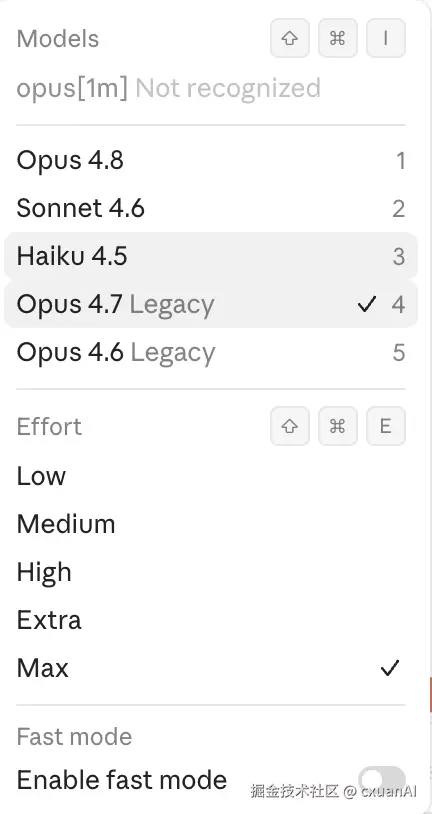
而且 4.8 来了,就要把 4.6 和 4.7 下了,4.7 下了我能理解,但是 4.6 是为何?
到具体的选择上来说,做 agentic coding(让 agent 自己读代码、改、跑测试)的,你可以用上 4.8;如果活儿是 terminal 重度(一大堆命令行编排)的,GPT-5.5 还更稳。
这次还增加了一个新的功能,dynamic workflows(研究预览版)。
这玩意说的是,对于最棘手的研究类型等任务,Claude 会制定计划,运行数百个并行子代理,并在报告结果前验证其工作。
数百个子代理。。。活能干的好不好不说,token 反正是秒没。
我去官网看了一下这个 dynamic workflows 的介绍,它全文是这么说的:
它能够帮助 Claude 端到端地处理最具挑战性的任务。你通常需要数个季度才能完成的工作,现在只需几天即可完成。Claude 会动态编写编排脚本,在单个会话中运行数十到数百个并行 subagent ,并在您收到任何结果之前检查其工作。
因为有些问题比较复杂,单个 agent 无法一次性解决,尤其是在复杂的旧代码库中:比如在整个服务中搜寻错误,涉及数百个文件的迁移,或者在提交之前需要从各个角度进行严格测试的计划。动态工作流可以端到端地处理所有这些问题。
然后放了一张图
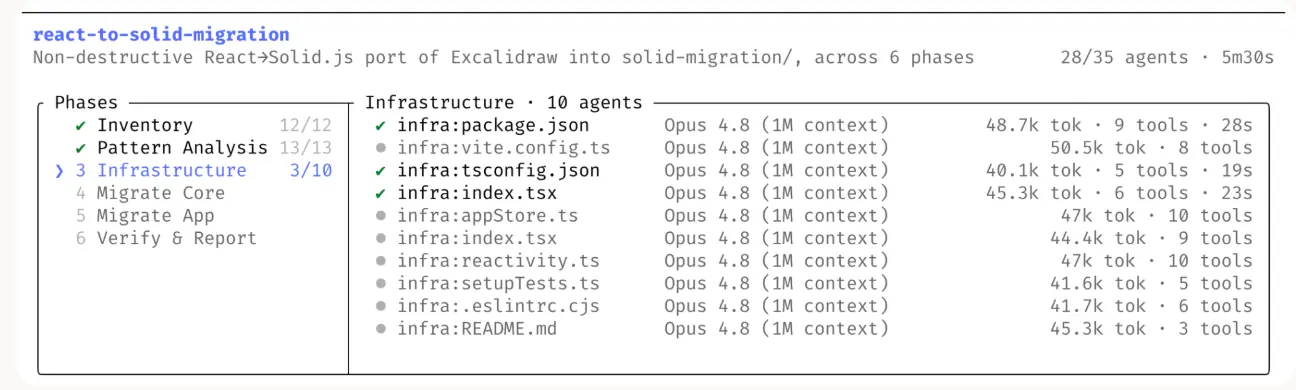
官方也发了⚠️声明:dynamic workflows 消耗的令牌数量可能比典型的 Claude Code 会话多得多,因此我们建议从范围较窄的任务开始,以便了解其在工作中的使用情况。
注意这一句多得多,我觉得至少是 2x 的消耗。
如果要用这项功能,官方建议你开 auto 模式,启动后,你有两种方式启动 dynamic workflows :
- 直接请 Claude 直接创建一个动态工作流程(例如,"创建工作流程")
- 启动 Claude Code 特有的设置
ultracode,可以通过 effort 设置为 xhigh 拉满启动。
(目前在 Enterprise / Team / Max 上。),像我 Pro 的是没权限看的 :)
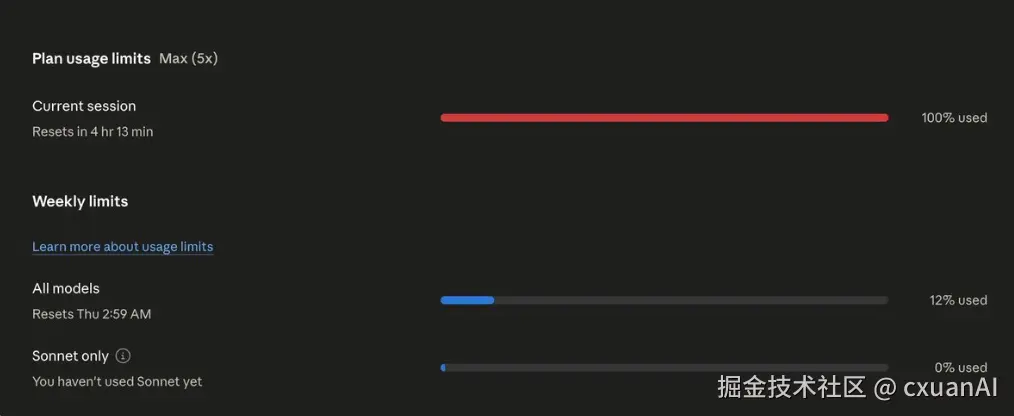
我看到 Theo 老哥用 100 美元的档位实测了一次,他说 ultracode 他用一个简单的 prompt 就达到 5h 限额了。
官方还放了一张容易被划过去的图:Misaligned behavior(失准行为)评分,越低越好。
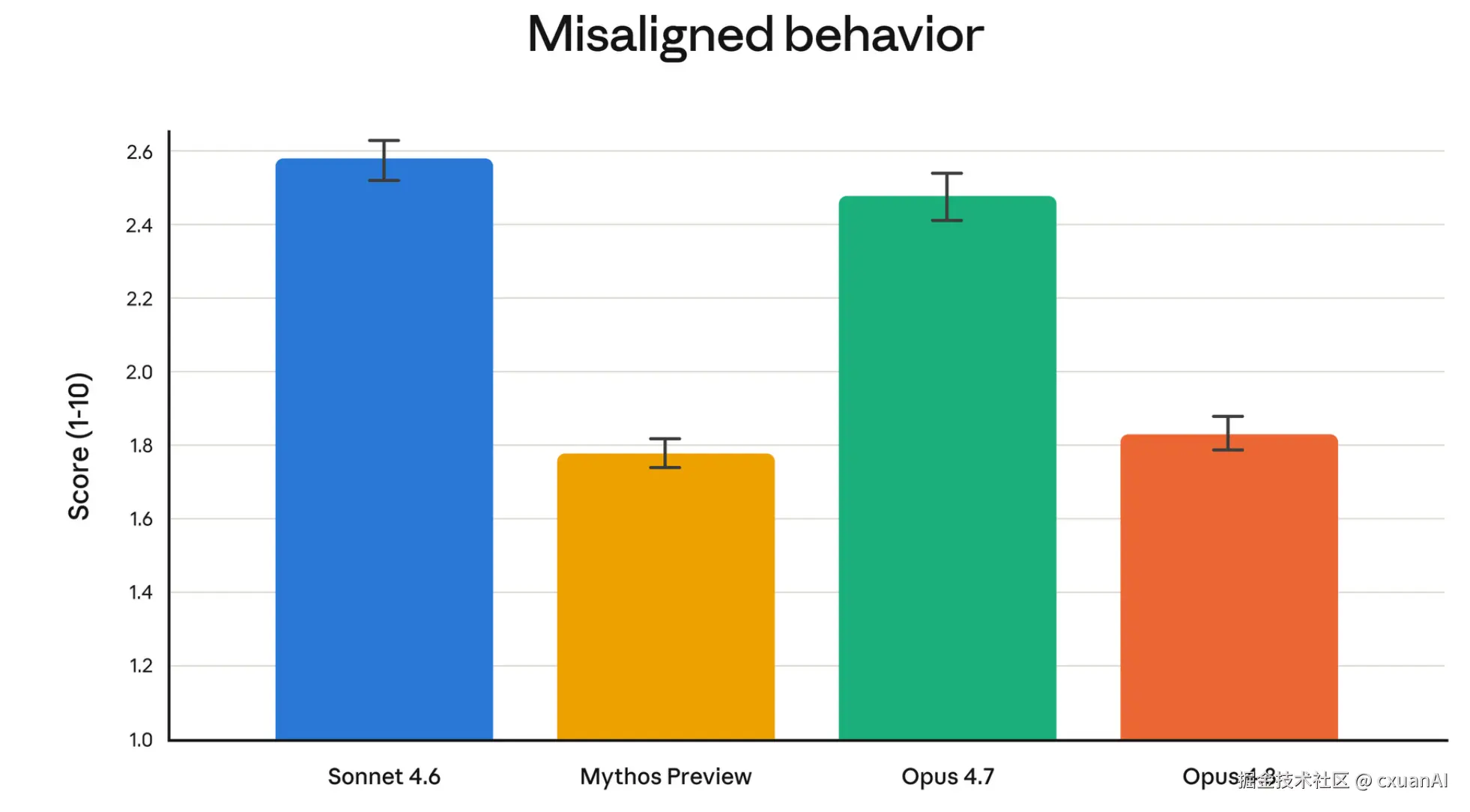
评分越低,说明模型会比较诚实,代表着失准行为的下降。
这么一看,Opus 4.7 真是一坨了,活干的不好,还欺上瞒下,又臭又长。
这次模型发布的最后,Claude 介绍了自己未来要发布 mythos 的计划。
目前只有少数组织目前正在使用 Claude Mythos Preview 进行网络安全工作。这种能力水平的模型在普遍发布之前需要更强的网络安全保护措施。我们正在开发这些保护措施并取得迅速进展,预计在未来几周内将 Mythos 级模型提供给所有客户。
这也就是说 mythos 马上就要发布了。
而且 Claude 还介绍了自己未来要发布一些经济实惠并且能力相当的好模型。