记忆预取机制详解
源码地址: https://github.com/NousResearch/hermes-agent.git
注意: 本文档基于特定版本的源码撰写,在线代码持续更新中,部分代码片段可能与最新代码有所偏差,仅供参考。
一、概述
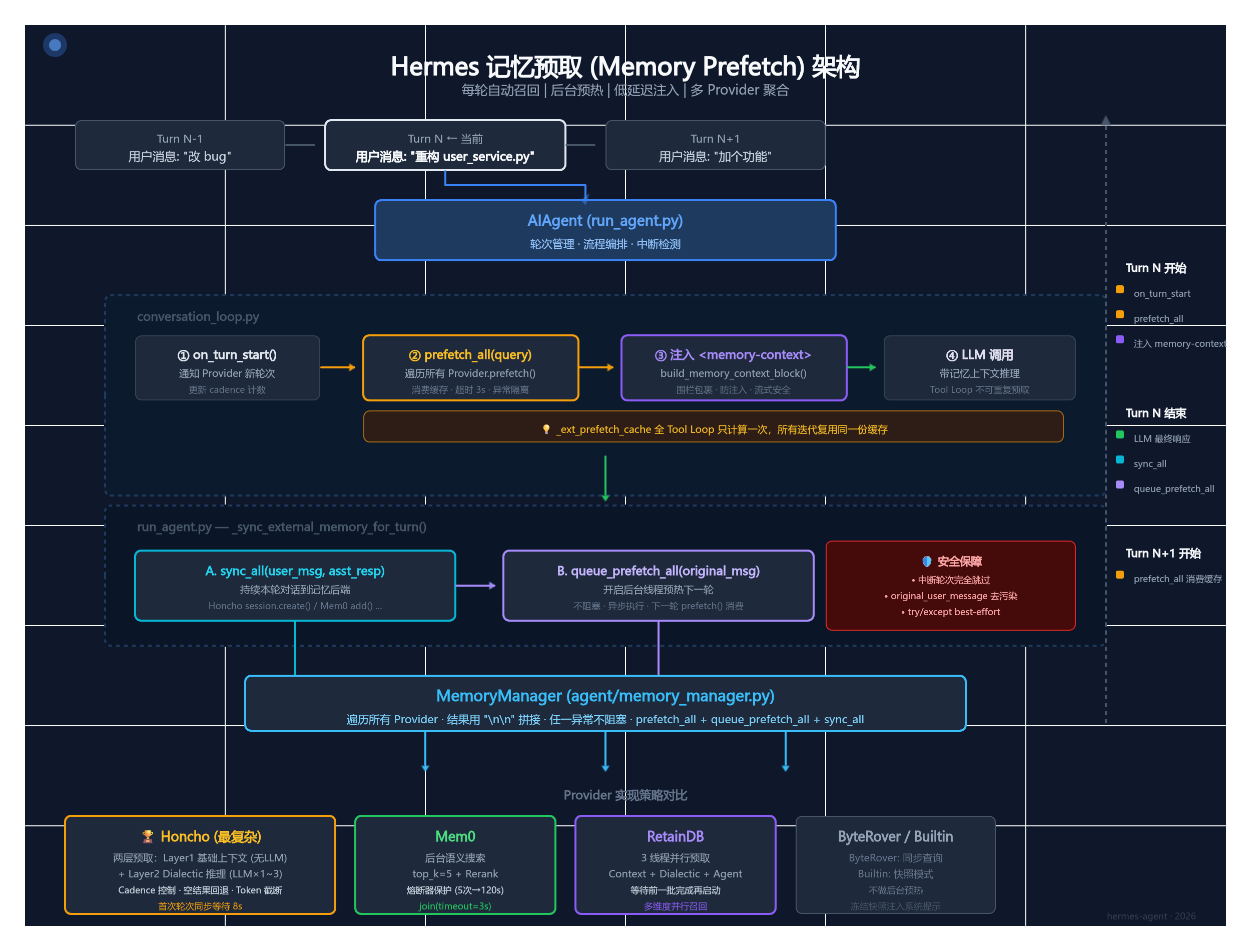
记忆预取(Memory Prefetch)是 Hermes 记忆系统中每轮对话前自动执行的上下文召回机制。其核心思想是:在 LLM 发起 API 调用之前,主动从记忆后端检索与当前用户消息相关的历史记忆,注入到当前轮次的上下文中,让模型无需显式调用工具即可"感知"到持久记忆。
预取与工具调用式检索的区别:
| 维度 | 预取(Prefetch) | 工具调用检索(Tool Call) |
|---|---|---|
| 触发方式 | 每轮自动,对模型透明 | 模型显式调用 *_search 等工具 |
| 时机 | 用户消息到达后、LLM 调用前 | LLM 决策后、工具循环中 |
| 注入方式 | <memory-context> 围栏块 |
作为 tool result 返回 |
| 用途 | 被动上下文补充 | 主动深度查询 |
二、架构概览
┌──────────────┐
│ AIAgent │
│ run_agent.py │
└──────┬───────┘
│
┌─────────────┼─────────────┐
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ Prefetch │ │ Sync │ │ Queue │
│ (读) │ │ (写) │ │ Prefetch │
└────┬─────┘ └────┬─────┘ └────┬─────┘
│ │ │
▼ ▼ ▼
┌────────────────────────────────────┐
│ MemoryManager │
│ agent/memory_manager.py │
│ │
│ prefetch_all() ← 每轮开始前 │
│ queue_prefetch_all() ← 每轮结束后 │
│ sync_all() ← 每轮结束后 │
└────────────────┬───────────────────┘
│
┌─────────┼─────────┐
▼ ▼ ▼
┌──────────┐ ┌──────┐ ┌──────┐
│ builtin │ │Honcho│ │Mem0 │ ...
│Provider │ │ │ │ │
└──────────┘ └──────┘ └──────┘MemoryManager 作为中枢协调器,遍历所有注册的 Provider,调用其 prefetch() / queue_prefetch() 方法。单个 Provider 的失败不会阻塞其他 Provider。
三、核心接口:prefetch() 与 queue_prefetch()
这两个方法定义在 MemoryProvider 抽象基类中(agent/memory_provider.py):
3.1 prefetch(query) -> str --- 同步读取
# agent/memory_provider.py:92-101
def prefetch(self, query: str, *, session_id: str = "") -> str:
"""Recall relevant context for the upcoming turn.
Called before each API call. Return formatted text to inject as
context, or empty string if nothing relevant. Implementations
should be fast --- use background threads for the actual recall
and return cached results here.
"""
return ""- 调用时机 :每轮 LLM 调用前,在
conversation_loop.py中执行 - 返回值:格式化的记忆文本,将被注入到当前轮次的 user message 之前
- 性能要求:应快速返回------重量级检索应在后台线程中完成,此处只消费缓存结果
- 默认行为:返回空字符串(无预取)
3.2 queue_prefetch(query) --- 后台预热
# agent/memory_provider.py:106-113
def queue_prefetch(self, query: str, *, session_id: str = "") -> None:
"""Queue a background recall for the NEXT turn.
Called after each turn completes. The result will be consumed
by prefetch() on the next turn. Default is no-op --- providers
that do background prefetching should override this.
"""- 调用时机 :每轮对话结束后,在
run_agent.py的_sync_external_memory_for_turn()中执行 - 设计目的 :提前启动耗时的后台检索(如 LLM 推理、语义搜索),结果缓存起来供下一轮 的
prefetch()消费 - 默认行为:空操作
3.3 二者的配合模式
轮次 N 结束:
├── sync_all(user_msg, asst_resp) ← 持久化本轮对话
└── queue_prefetch_all(user_msg) ← 开启后台线程,预热下一轮
... 用户输入下一轮消息 ...
轮次 N+1 开始:
├── on_turn_start(N+1, msg) ← 通知 Provider 轮次开始
└── prefetch_all(msg) ← 消费后台线程缓存的结果
└── 注入 <memory-context> 到本轮系统提示关键设计理念:
queue_prefetch跑在后台线程中,不阻塞用户看到回复prefetch只读取缓存,几乎零延迟- 如果
queue_prefetch还没跑完,prefetch会join(timeout=3.0)等待,超时则本轮无预取结果
四、MemoryManager 的实现细节
4.1 prefetch_all() --- 聚合所有 Provider 的预取结果
# agent/memory_manager.py, lines 339-356
def prefetch_all(self, query: str, *, session_id: str = "") -> str:
parts = []
for provider in self._providers:
try:
result = provider.prefetch(query, session_id=session_id)
if result and result.strip():
parts.append(result)
except Exception as e:
logger.debug(
"Memory provider '%s' prefetch failed (non-fatal): %s",
provider.name, e,
)
return "\n\n".join(parts)- 遍历所有已注册 Provider
- 用
"\n\n"拼接各 Provider 的非空结果 - 任一 Provider 异常不影响其他
4.2 queue_prefetch_all() --- 触发所有 Provider 的后台预热
# agent/memory_manager.py, lines 358-367
def queue_prefetch_all(self, query: str, *, session_id: str = "") -> None:
for provider in self._providers:
try:
provider.queue_prefetch(query, session_id=session_id)
except Exception as e:
logger.debug(
"Memory provider '%s' queue_prefetch failed (non-fatal): %s",
provider.name, e,
)- 与
prefetch_all()对称,但无返回值 - 每个 Provider 在自己的后台线程中执行检索
五、完整轮次生命周期
5.1 轮次开始时(conversation_loop.py)
# agent/conversation_loop.py:567
# 步骤 1:通知 Provider 新轮次开始(用于 cadence 追踪)
agent._memory_manager.on_turn_start(agent._user_turn_count, _turn_msg)
# agent/conversation_loop.py:580
# 步骤 2:执行预取
_ext_prefetch_cache = agent._memory_manager.prefetch_all(_query) or ""
# agent/conversation_loop.py:751-757(简化)
# 步骤 3:在工具循环中,将预取结果注入到当前轮次的 user message 前
# 使用 build_memory_context_block() 包裹,且只在第一个 API 调用时注入
if _ext_prefetch_cache:
_fenced = build_memory_context_block(_ext_prefetch_cache)重要优化 :预取结果 _ext_prefetch_cache 只计算一次 ,在整个工具循环(可能 10+ 次 API 调用)中复用同一份缓存,避免每次 tool call 都触发 prefetch_all() 带来的延迟和成本。
5.2 轮次结束时(run_agent.py)
# run_agent.py:1973-1987(简化)
# _sync_external_memory_for_turn()
def _sync_external_memory_for_turn(self, *, original_user_message, final_response, interrupted):
if interrupted:
return # 中断的轮次不同步,防止污染记忆
if not (self._memory_manager and final_response and original_user_message):
return
try:
self._memory_manager.sync_all(original_user_message, final_response, ...)
self._memory_manager.queue_prefetch_all(original_user_message, ...)
except Exception:
pass关键保护:
- 中断的轮次被完全跳过:部分助手输出、中止的工具链不是"持久对话事实",同步到外部记忆会污染未来的召回
- 使用
original_user_message而非user_message:后者可能携带注入的 skill 内容,会膨胀 Provider 查询 - 整体被
try/except包裹:外部记忆是 strictly best-effort,配置错误的后端绝不能阻塞用户看到回复
六、预取结果注入机制
6.1 <memory-context> 围栏
预取结果通过 build_memory_context_block() 包裹为受保护的上下文块:
# agent/memory_manager.py:227-241
def build_memory_context_block(raw_context: str) -> str:
clean = sanitize_context(raw_context)
return (
"<memory-context>\n"
"[System note: The following is recalled memory context, "
"NOT new user input. Treat as authoritative reference data --- "
"this is the agent's persistent memory and should inform all responses.]\n\n"
f"{clean}\n"
"</memory-context>"
)围栏的三重作用:
- 语义隔离:通过 System note 明确告知 LLM 这是记忆数据而非用户新输入
- 安全防注入 :如果记忆后端返回的内容中嵌入了
<memory-context>标签,sanitize_context()会将其剥离 - 流式安全 :
StreamingContextScrubber状态机处理跨 chunk 边界的标签,防止流式输出中泄漏
6.2 注入位置
预取结果被注入到当前轮次 user message 之前(作为同一轮次消息体的一部分),而非系统提示中:
# agent/conversation_loop.py:751-762(简化)
if idx == current_turn_user_idx and msg.get("role") == "user":
_injections = []
if _ext_prefetch_cache:
_fenced = build_memory_context_block(_ext_prefetch_cache)
if _fenced:
_injections.append(_fenced)
# ... 合并注入内容到 user message 前这种设计保证:
- 预取内容与当前轮次语义绑定,过期自动丢弃
- 不影响系统提示的稳定性(系统提示在会话中冻结,由 MemoryTool 的快照机制保证)
七、Provider 级实现对比
各外部 Provider 对 prefetch() / queue_prefetch() 的实现策略各不相同:
7.1 Honcho
queue_prefetch() prefetch()
───────────────── ────────────
开启后台线程: 消费缓存:
├── 基础上下文刷新 (context_cadence) ├── Layer 1: 基础上下文 (表示 + Peer Card)
│ peer.context() │ 首次同步获取,后续从缓存读取
│ ├── Layer 2: Dialectic 推理补充
└── Dialectic 推理 (dialectic_cadence) │ 从 _prefetch_result 读取
Pass 0 → Pass 1 → Pass 2 │ 首次轮次同步等待 (timeout=8s)
LLM 多轮推理 │ 后续轮次 join(timeout=3s)
└── Token 预算截断Cadence 控制
Honcho 将预取内容分为两层,每层有独立的刷新间隔控制:
| 参数 | 默认值 | 控制对象 | API 调用 | 开销 |
|---|---|---|---|---|
context_cadence |
1 | 基础上下文(表示 + Peer Card) | peer.context() |
低(无 LLM) |
dialectic_cadence |
1 | LLM 多轮推理补充 | .chat() × 1~3 次 |
高(LLM 推理) |
context_cadence --- 基础上下文层
控制基础上下文(用户表示 + Peer Card)的刷新频率。这是一个轻量级 API 调用,不涉及 LLM 推理,开销很低。
# plugins/memory/honcho/__init__.py:723-728
# queue_prefetch() 中的逻辑
if self._context_cadence <= 1 or \
(self._turn_count - self._last_context_turn) >= self._context_cadence:
self._last_context_turn = self._turn_count
self._manager.prefetch_context(self._session_key, query) # 后台异步- 当
context_cadence = 1时每轮都刷新(默认行为) - 增大该值可降低 API 调用频率,适合基础信息变化缓慢的场景
- 基础上下文的首次获取在
prefetch()中同步执行,保证第一轮不空
dialectic_cadence --- LLM 推理补充层
控制 Dialectic 多轮 LLM 推理的执行频率。这是预取中最昂贵的部分:每次调用通过 Honcho 后端执行 1~3 次 .chat() LLM 调用(由 dialectic_depth 参数决定)。
# plugins/memory/honcho/__init__.py:741-744
# queue_prefetch() 中的逻辑
effective = self._effective_cadence()
if (self._turn_count - self._last_dialectic_turn) < effective:
return # 跳过,距离上次成功不到 effective 轮
# 后台线程执行多轮 LLM 推理
self._prefetch_thread = Thread(target=_run_dialectic_depth, ...)
self._prefetch_thread.start()_effective_cadence() 空结果回退机制 :当 Dialectic 连续返回空结果时,_effective_cadence() 会动态增大间隔,避免对"沉默"后端无限重试:
# plugins/memory/honcho/__init__.py:825-830
def _effective_cadence(self) -> int:
if self._dialectic_empty_streak <= 0:
return self._dialectic_cadence
widened = self._dialectic_cadence + self._dialectic_empty_streak
ceiling = self._dialectic_cadence * _BACKOFF_MAX # _BACKOFF_MAX = 8
return min(widened, ceiling)| 连续空结果次数 | dialectic_cadence=1 时有效间隔 |
dialectic_cadence=2 时有效间隔 |
|---|---|---|
| 0 | 1 轮 | 2 轮 |
| 3 | 4 轮 | 5 轮 |
| 5 | 6 轮 | 7 轮 |
| ≥8 | 8 轮(封顶) | 16 轮(封顶) |
- 一旦某次返回非空结果,
dialectic_empty_streak立即重置为 0,间隔回到基准值 - Cadence 只在获得非空结果时才推进
_last_dialectic_turn:空返回的轮次不计入,下轮立即重试
两层独立调度 :两者使用各自的 _last_context_turn / _last_dialectic_turn 独立追踪,互不干扰。例如 context_cadence=3, dialectic_cadence=1 意味着基础上下文每 3 轮刷新一次,但 Dialectic 推理每轮都执行。
Cadence 实例:一段聊天中发生了什么
假设配置 context_cadence=1, dialectic_cadence=2,用户 Jack 和助手 Alice 的对话如下:
距离计算 :
距上次 = 当前轮次 - 上次刷新轮次,当距上次 ≥ cadence时触发刷新。Turn 1 为首轮,context 和 dialectic 均强制刷新。
Turn 1 ─────────────────────────────────────────────────────
Jack: 帮我写一个 Python 脚本,读取 CSV 并输出统计摘要。
Alice: [生成脚本] ...done. 还需要什么调整吗?
🔄 context: ✅ 同步刷新(首轮),_last_context_turn = 1
🔄 dialectic: ⏳ 同步等待 8s → 拿到结果:「Jack 偏好 Python」「正在做数据处理」
_last_dialectic_turn = 1
Turn 2 ─────────────────────────────────────────────────────
Jack: 加个功能:按列分组后再统计。
Alice: [修改脚本] 添加了 groupby + describe。还有其他需求吗?
🔄 context: ✅ 后台刷新(距上次 2-1=1 ≥ 1),_last_context_turn = 2
🔄 dialectic: 跳过(距上次 2-1=1 < 2)
→ context 每轮都刷(开销低);dialectic 本轮不执行(昂贵的 LLM 推理隔轮调用)
Turn 3 ─────────────────────────────────────────────────────
Jack: 顺便把结果输出为 Markdown 表格。
Alice: [追加 Markdown 导出] 完成了。需要我解释代码吗?
🔄 context: ✅ 后台刷新(距上次 3-2=1 ≥ 1),_last_context_turn = 3
🔄 dialectic: ✅ 后台执行(距上次 3-1=2 ≥ 2),_last_dialectic_turn = 3
→ Dialectic 推理出「Jack 的脚本在迭代增强」
→ 本轮消费上一轮缓存,本轮产出下轮消费
Turn 4 ─────────────────────────────────────────────────────
Jack: 解释一下 groupby 那部分的逻辑。
Alice: [解释] groupby 按指定列分组,然后对各组调用 describe()...
🔄 context: ✅ 后台刷新(距上次 4-3=1 ≥ 1),_last_context_turn = 4
🔄 dialectic: 跳过(距上次 4-3=1 < 2)
→ 注入 Turn 3 产出的记忆(含「迭代增强」的推理结论)
Turn 5 ─────────────────────────────────────────────────────
Jack: 谢谢,脚本没问题了。现在帮我看一下这个 SQL 查询...
Alice: 好的,请贴查询。
🔄 context: ✅ 后台刷新(距上次 5-4=1 ≥ 1),_last_context_turn = 5
→ 话题从 Python 切换到 SQL,Peer Card 随每轮刷新自动更新
🔄 dialectic: ✅ 后台执行(距上次 5-3=2 ≥ 2),_last_dialectic_turn = 5
→ 但后端返回空结果 → dialectic_empty_streak = 1
→ _effective_cadence() = 2 + 1 = 3,下次要等 3 轮才重试
Turn 6 ─────────────────────────────────────────────────────
Jack: SELECT * FROM orders WHERE ...
Alice: [分析 SQL] 这个查询会全表扫描,建议加索引...
🔄 context: ✅ 后台刷新(距上次 6-5=1 ≥ 1),_last_context_turn = 6
🔄 dialectic: 跳过(距上次 6-5=1 < 3,空结果回退生效中)
Turn 7 ─────────────────────────────────────────────────────
Jack: 那加个 WHERE 条件会有帮助吗?
Alice: 加上索引后,WHERE 过滤可以利用索引加速...
🔄 context: ✅ 后台刷新(7-6=1 ≥ 1)
🔄 dialectic: 跳过(距上次 7-5=2 < 3,回退中)
Turn 8 ─────────────────────────────────────────────────────
Jack: 索引应该建在哪些列上?
Alice: 主要看 WHERE / JOIN / ORDER BY 中出现的列...
🔄 context: ✅ 后台刷新(8-7=1 ≥ 1)
🔄 dialectic: ✅ 后台执行(距上次 8-5=3 ≥ 3),_last_dialectic_turn = 8
→ 拿到非空结果「Jack 在排查慢查询」
→ dialectic_empty_streak 重置为 0,_effective_cadence() 回到 2关键观察:
| 维度 | 行为 |
|---|---|
| 基础上下文 | cadence=1 意味着每轮都刷新------context 只是轻量 API 调用(无 LLM),可以放心每轮更新 Peer Card |
| Dialectic | 奇数轮执行、偶数轮跳过------昂贵的 LLM 推理隔轮调用,空结果时自动退避到 3 轮间隔 |
| 回退恢复 | Turn 5 空结果 → 间隔扩到 3 → Turn 8 恢复拿到结果 → 立即归零,回到每 2 轮执行 |
| 缓存滑动窗口 | 每轮注入的都是上一轮刷新周期的产物,模型始终感知"几轮前的我" |
两层输出的实际内容
以上面 Turn 5(话题切换到 SQL)为例,经过多次 Python 对话后,context 和 dialectic 分别产出了什么:
Layer 1:基础上下文 (来自 peer.context(),无 LLM)
## Session Summary
User is working on data processing scripts. The assistant has helped write
a Python CSV reader with pandas, added groupby + describe aggregation, and
formatted output as Markdown tables.
## User Representation
Jack is a developer who works primarily in Python for data analysis.
Prefers concise, functional code with clear comments. Values efficiency
and asks for explanations when encountering unfamiliar syntax.
## User Peer Card
- Language: zh-CN, but comfortable with English technical terms
- OS: macOS, prefers CLI tools
- Frequently works with: pandas, CSV files, Markdown export
- Communication style: direct, asks follow-up questions
- Current session started: 2026-05-28 14:30
## AI Self-Representation
The AI assistant (Alice) has been helping with Python data processing
tasks --- generating scripts, adding features iteratively, and providing
explanations. Maintains a helpful and patient tone.
## AI Identity Card
- Role: coding assistant
- Strengths: Python, data analysis, SQL optimizationLayer 2:Dialectic 推理补充 (来自 Honcho .chat(),有 LLM 推理)
Jack is iteratively enhancing a data processing script --- starting from
basic CSV reading, moving through groupby aggregation, and now shifting
to Markdown output formatting. He appears to be building a reporting
pipeline. His questions are focused and incremental, suggesting comfort
with the tech stack but a need for guided implementation. The conversation
pattern indicates he values understanding over copy-paste solutions.最终注入到模型的内容 (两层拼接后由 build_memory_context_block 包裹):
<memory-context>
[System note: The following is recalled memory context, NOT new user input.
Treat as authoritative reference data --- this is the agent's persistent memory
and should inform all responses.]
## Session Summary
User is working on data processing scripts...
## User Representation
Jack is a developer who works primarily in Python...
## User Peer Card
- Language: zh-CN, but comfortable with English technical terms
...
## AI Self-Representation
The AI assistant (Alice) has been helping...
## AI Identity Card
- Role: coding assistant
...
## Memory Supplement
Jack is iteratively enhancing a data processing script --- starting from
basic CSV reading, moving through groupby aggregation, and now shifting
to Markdown output formatting...
</memory-context>两者对比:
| 维度 | 基础上下文 (context) | Dialectic 补充 |
|---|---|---|
| 数据来源 | peer.context() API |
.chat() LLM 推理 |
| 开销 | 低(纯 API 调用) | 高(1~3 次 LLM 调用) |
| 内容类型 | 结构化:表示、卡片、摘要 | 自然语言:推理结论 |
| 更新频率 | 受 context_cadence 控制 |
受 dialectic_cadence 控制 |
| 典型产物 | "Jack uses Python, prefers CLI" | "Jack is building a reporting pipeline iteratively" |
| 缺失时的表现 | 静默降级,无上下文注入 | 静默降级,仅基础上下文生效 |
说明 :
peer.context()是 Honcho SDK(honcho-ai包)中Peer类的方法,非 Hermes 内部实现。Hermes 通过self.honcho.peer(peer_id)获取 peer 实例后调用其context()方法。源码见 Honcho GitHub。
代码片段:
① _format_first_turn_context() --- 将 peer.context() 返回的 dict 格式化为 Markdown 段落:
# plugins/memory/honcho/__init__.py:468-495
def _format_first_turn_context(self, ctx: dict) -> str:
"""Format the prefetch context dict into a readable system prompt block."""
parts = []
summary = ctx.get("summary", "")
if summary:
parts.append(f"## Session Summary\n{summary}")
rep = ctx.get("representation", "")
if rep:
parts.append(f"## User Representation\n{rep}")
card = ctx.get("card", "")
if card:
parts.append(f"## User Peer Card\n{card}")
ai_rep = ctx.get("ai_representation", "")
if ai_rep:
parts.append(f"## AI Self-Representation\n{ai_rep}")
ai_card = ctx.get("ai_card", "")
if ai_card:
parts.append(f"## AI Identity Card\n{ai_card}")
if not parts:
return ""
return "\n\n".join(parts)这 5 个字段正好对应了上面示例输出的 5 个 ## 段落。
② prefetch() --- 两层组装逻辑,分别消费 context 缓存和 dialectic 缓存:
# plugins/memory/honcho/__init__.py:574-681 (关键片段)
parts = []
# ----- Layer 1: Base context (representation + card) -----
with self._base_context_lock:
if self._base_context_cache is None:
ctx = self._manager.get_prefetch_context(self._session_key)
self._base_context_cache = self._format_first_turn_context(ctx) if ctx else ""
base_context = self._base_context_cache
# Check if background context prefetch has a fresher result
if self._manager:
fresh_ctx = self._manager.pop_context_result(self._session_key)
if fresh_ctx:
formatted = self._format_first_turn_context(fresh_ctx)
if formatted:
self._base_context_cache = formatted
base_context = formatted
if base_context:
parts.append(base_context)
# ----- Layer 2: Dialectic supplement -----
# ... first-turn synchronous wait logic (8s timeout) ...
with self._prefetch_lock:
dialectic_result = self._prefetch_result # 消费后台线程产物
self._prefetch_result = ""
if dialectic_result and dialectic_result.strip():
parts.append(dialectic_result) # 直接追加自然语言结论
if not parts:
return ""
result = "\n\n".join(parts) # 两层用空行拼接关键点:Layer 1 走 _format_first_turn_context() 结构化包装,Layer 2 是裸字符串直接追加------因为 dialectic 本身就是 LLM 生成的自然语言结论,无需再包装。
③ build_memory_context_block() --- 将拼接后的字符串包裹进围栏,注入到用户消息末尾:
# agent/memory_manager.py:227-241
def build_memory_context_block(raw_context: str) -> str:
"""Wrap prefetched memory in a fenced block with system note."""
if not raw_context or not raw_context.strip():
return ""
clean = sanitize_context(raw_context)
return (
"<memory-context>\n"
"[System note: The following is recalled memory context, "
"NOT new user input. Treat as authoritative reference data --- "
"this is the agent's persistent memory and should inform all responses.]\n\n"
f"{clean}\n"
"</memory-context>"
)④ _build_dialectic_prompt() --- 驱动 dialectic 输出的实际 prompt,决定推理结论的语义方向:
# plugins/memory/honcho/__init__.py:897-908
# Pass 0 --- 首轮:探索用户画像
return (
"Who is this person? What are their preferences, goals, "
"and working style? Focus on facts that would help an AI "
"assistant be immediately useful."
)
# Pass 0 --- 后续轮次:聚焦会话上下文
return (
"Given what's been discussed in this session so far, what "
"context about this user is most relevant to the current "
"conversation? Prioritize active context over biographical facts."
)这就是为什么 dialectic 输出是 "Jack is iteratively enhancing a data processing script..." 这样面向当前会话的推理结论,而非静态的用户档案。
⑤ _run_dialectic_depth() --- 多轮迭代,每轮在上轮基础上深化,信号足够时提前终止:
# plugins/memory/honcho/__init__.py:949-989
def _run_dialectic_depth(self, query: str) -> str:
is_cold = not self._base_context_cache
results: list[str] = []
for i in range(self._dialectic_depth): # depth 默认 3
if i == 0:
prompt = self._build_dialectic_prompt(0, results, is_cold)
else:
if results and self._signal_sufficient(results[-1]):
break # 质量够了,提前退出
prompt = self._build_dialectic_prompt(i, results, is_cold)
result = self._manager.dialectic_query(
self._session_key, prompt,
reasoning_level=level,
peer="user",
)
results.append(result or "")
for r in reversed(results): # 取最深一层的非空结果
if r and r.strip():
return r
return ""Dialectic 的实际开销 = 1~dialectic_depth 次 .chat() 调用。所以 dialectic_cadence 才是控制成本的真正杠杆。
首次轮次特殊处理:
prefetch()在首次轮次会同步等待 dialectic 结果(超时 8s)- 超时后线程继续运行,结果会在下一轮被消费
- session 初始化时的 prewarm 也会提前启动 dialectic
7.2 Mem0
queue_prefetch() prefetch()
───────────────── ────────────
后台线程: 消费缓存:
├── 熔断器检查 ├── join 后台线程 (timeout=3s)
├── client.search(query, top_k=5) ├── 读取 _prefetch_result
├── rerank 重排序 └── 格式化为 "## Mem0 Memory\n- fact1\n- fact2"
└── 写入 _prefetch_result熔断器保护:
- 连续 5 次失败后熔断器打开
- 冷却期 120 秒后尝试恢复
- 防止 API 雪崩
7.3 RetainDB
queue_prefetch()
─────────────────
并行启动 3 个后台线程:
├── _prefetch_context(query) ← 上下文检索
├── _prefetch_dialectic(query) ← Dialectic 推理
└── _prefetch_agent_model() ← Agent 模型更新等待上一批线程完成后再启动新一批,防止线程堆积。
7.4 ByteRover
queue_prefetch() prefetch()
───────────────── ────────────
无操作 (no-op) 同步执行 brv query
阻塞等待直到查询完成 (timeout)ByteRover 选择了最简方案:不做后台预热,直接在 prefetch() 中同步查询。适用于低延迟本地后端。
7.5 内置 Provider(builtin)
内置 MemoryTool 不实现 prefetch() / queue_prefetch(),因为 MEMORY.md / USER.md 内容已在会话开始时通过冻结快照注入系统提示,无需每轮动态预取。
八、关键设计决策
| 决策 | 原因 |
|---|---|
| Prefetch 缓存复用 | 一轮对话中可能有 10+ 次 tool call,每次都调用 prefetch_all() 会带来 10x 延迟和成本;缓存一次、全程复用 |
| Queue → Consume 分离 | 后台线程做重活,prefetch() 只读缓存,保证 LLM 调用不被记忆检索阻塞 |
使用 original_user_message |
user_message 可能包含 skill 注入内容,会膨胀/破坏 Provider 查询 |
| 中断轮次跳过同步 | 部分输出不是"事实",同步到记忆会污染未来召回 |
| best-effort 容错 | 所有记忆操作被 try/except 包裹,记忆后端故障不影响对话 |
| Cadence 间隔控制 | Honcho/RetainDB 的 LLM 推理昂贵,通过 cadence 参数控制调用频率 |
| 熔断器 | Mem0 等外部 API 可能不稳定,熔断器防止连续失败雪崩 |
| Token 预算截断 | 预取内容过大时会挤占上下文窗口,Honcho 通过 context_tokens 参数限制 |
| 首次轮次特殊处理 | 第一轮没有 queue_prefetch 预热结果,需要同步等待或快速返回 |
九、时序图
用户发送消息 "帮我重构 user_service.py"
│
▼
┌─ conversation_loop.py ────────────────────────────────────────┐
│ │
│ 1. on_turn_start(turn=3, "帮我重构 user_service.py") │
│ └─ Provider 更新 cadence 计数,判断是否需要刷新 │
│ │
│ 2. _ext_prefetch_cache = prefetch_all("帮我重构...") │
│ └─ builtin: "" (快照模式,不参与预取) │
│ └─ Honcho: "## Peer Context\n- user prefers OOP\n- │
│ 常用 Python patterns: repository, factory" │
│ │
│ 3. build_memory_context_block(_ext_prefetch_cache) │
│ └─ "<memory-context>\n[System note: ...]\n\n │
│ ## Peer Context\n- user prefers OOP\n..." │
│ │
│ 4. 注入到 user message 前 → 发送给 LLM │
│ │
│ ┌─ Tool Loop (可能多次) ─────────────────────────────────┐ │
│ │ 每次迭代复用同一份 _ext_prefetch_cache │ │
│ └────────────────────────────────────────────────────────┘ │
│ │
│ 5. LLM 最终回复 │
│ │
└───────────────────────────────────────────────────────────────┘
│
▼
┌─ run_agent.py : _sync_external_memory_for_turn() ─────────────┐
│ │
│ sync_all("帮我重构...", "好的,我来重构...") │
│ └─ Honcho: 后台线程 → 持久化本轮对话 │
│ │
│ queue_prefetch_all("帮我重构...") │
│ └─ Honcho: 后台线程 → dialectic_query("帮我重构...") │
│ └─ Pass 0: "重构偏好" │
│ └─ Pass 1: "测试习惯" │
│ └─ 结果写入 _prefetch_result (下一轮消费) │
│ │
└───────────────────────────────────────────────────────────────┘十、配置影响
预取行为受以下配置影响(cli-config.yaml):
memory:
memory_enabled: true # 是否启用记忆
provider: honcho # 记忆后端选择Provider 级配置(以 Honcho 为例):
| 参数 | 默认值 | 说明 |
|---|---|---|
recall_mode |
hybrid |
context(仅注入) / tools(仅工具) / hybrid(两者) |
context_cadence |
1 | 基础上下文刷新间隔(轮次) |
dialectic_cadence |
1 | Dialectic 调用间隔(轮次) |
context_tokens |
--- | 预取文本的 token 预算上限 |
injection_frequency |
every-turn |
every-turn / first-turn |
当 recall_mode = "tools" 时,prefetch() 和 queue_prefetch() 都直接返回/跳过,记忆只通过工具调用提供。