一、简介
1. HDP
HDP = Host Data Path ,是 AMD GPU 内部的一个硬件单元,而不是夹在 HCA/CPU 和 GPU 中间的独立桥。它的职责是处理"host 或 PCIe peer 访问 GPU 显存(HBM)"这条路径。
HDP 就在 GPU 芯片内部、PCIe 接口和显存之间,是 HCA/CPU 直访显存的专用 "门 / 桥"。 提供 HCA/CPU<-> GPU 显存的直接访问通路,让 HCA/CPU 能通过PCI BAR地址空间,直接读 / 写 GPU 的 VRAM,不用走复杂 DMA 或驱动拷贝。
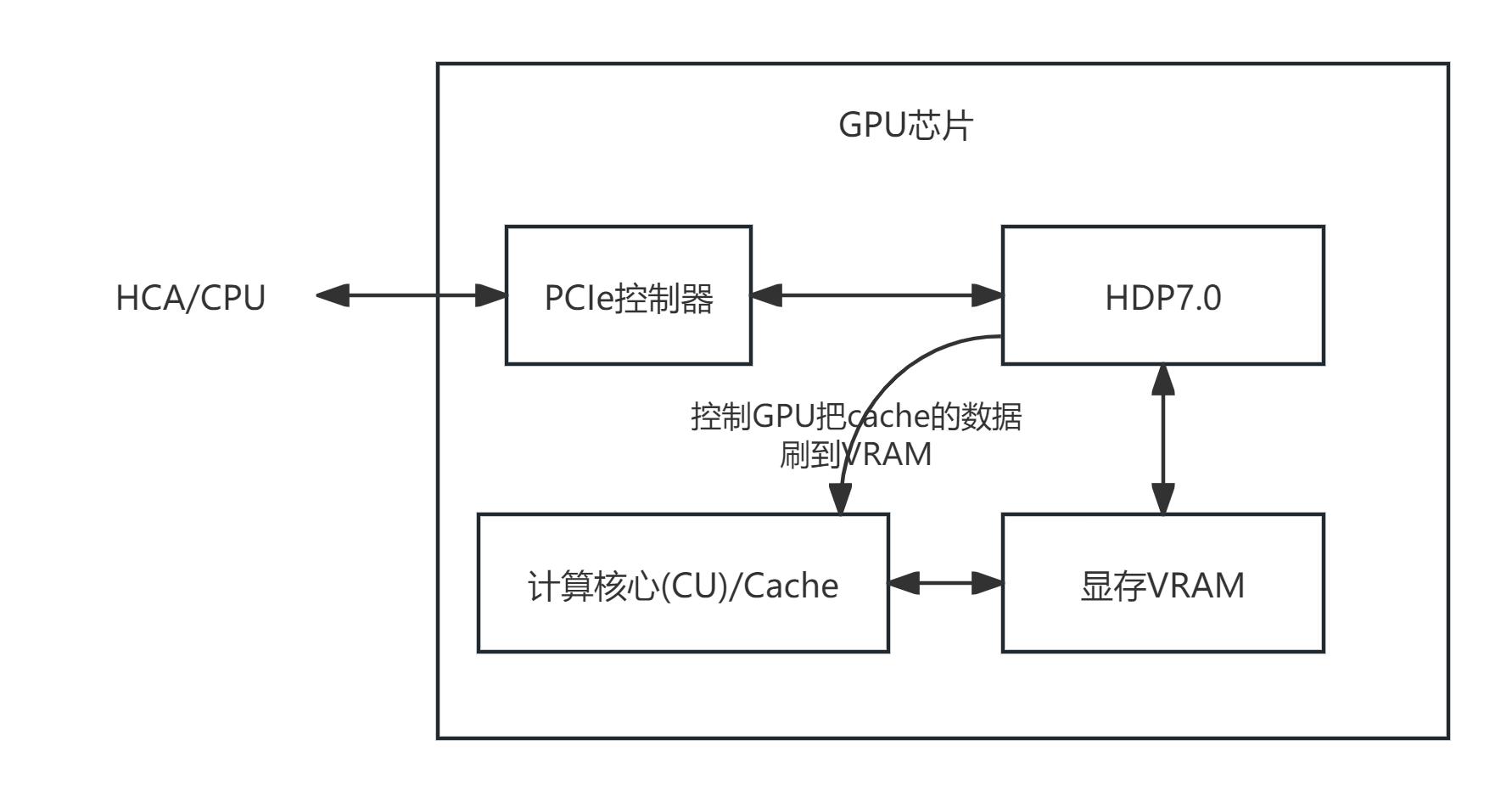
2. HDP 的位置
HDP 在 GPU 内部,不在系统内存这条路径上:

- CPU 访问显存,必须走 HDP(数据通路)
- GPU 访问显存不经过 HDP,而是经过 L1、L2, 但一致受 HDP 控制, 如GPU 核心写 VRAM 时, 驱动里的
amdgpu_hdp_flush()就是用来强制 GPU 把 L2 Cache 里的脏数据刷到 VRAM,让外部设备 HCA/CPU 能读到一致的结果。
3. 数据流向取决于目标 buffer 在哪
- 目标 buffer 在系统内存: HCA RDMA write → 系统内存(根本不过 HDP);GPU 通过 PCIe 反向读,是另一条慢路径。
- 目标 buffer 在 GPU HBM : HCA RDMA write → PCIe → HDP → HBM;GPU 自己读 HBM 走 L2,不过 HDP。
"数据写入系统内存"和"GPU L2 缓存"同时出现,但它们对应的不是同一个 buffer。
二、 HDP 会引发问题的地方
(一) 说明
HDP 有一个 read cache,这才是 IBRC visibility 类问题的关键:
正向(GPU 写 → HCA 读)的可见性问题主要是 HDP 的 cache
- GPU 往 HBM 里写了新值 → CPU/HCA 经过 HDP 读 → 可能命中 HDP read cache 拿到旧值
- 解决: 写
HDP_MEM_FLUSH_CNTL/HDP_REG_FLUSH_CNTL让 HDP 失效自己的 cache,CPU/HCA 就放弃 HDP 的 cache 继续走下去读 VRAM 上的值(GPU 写的)。
反向(HCA 写 → GPU 读)的可见性问题主要是 GPU L2 / CU cache 这边的事,需要 __threadfence_system 之类,跟你 memory 里记的 project_dtk26_gfx938_l2wb_missing.md 对应的就是这条路径上 gfx938 缺 L2 writeback 的坑。
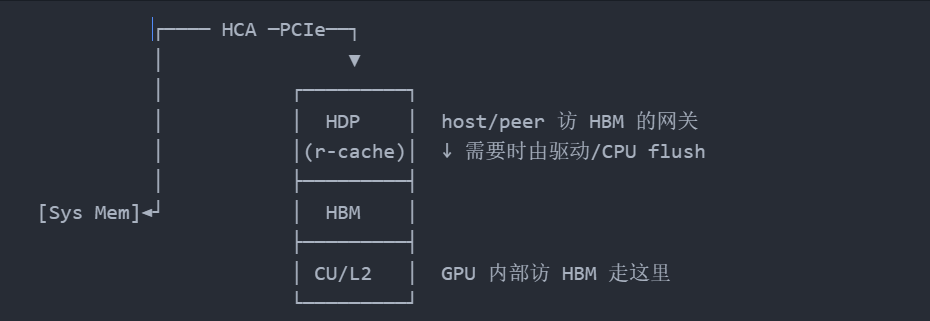
什么时候需要刷 HDP:
1)外部 Read(GPU → 外界,EGRESS)
路径:CU/Core → L2 → VRAM → PCIe → Host/HCA
- 这是GPU 主动写出去。
hipStreamSynchronize/hipDeviceSynchronize会自动确保 L2→VRAM 写回(flush egress)。- 你不用手动碰 HDP,同步后再 RDMA read 是安全的。
2)外部 Write(外界 → GPU,INGRESS)
路径:Host/HCA → PCIe → HDP → VRAM → L2 → CU/Core
- 这是HCA/Host 直接通过 PCIe BAR 写 VRAM(RDMA write 属于这类)。
- 完全不经过 HIP runtime 命令流 ,runtime 不知情、不会主动刷 HDP。
- 必须手动写 HDP_MMIO_FLUSH_CNTL ,把 PCIe 进来的数据提交到 VRAM,并invalidate L2 旧行,否则 GPU 读不到新数据。
3)一句话总览
- EGRESS(GPU→外):sync 管 L2→VRAM,不用 HDP。
- INGRESS(外→GPU):RDMA 写走 HDP,runtime 看不见,必须手动 flush HDP。
(二) 相关案例
1. AMD 上 dushmem PE0 remote write 到 PE1 的 flag,PE1 的 GPU 看不到
AMD GPU 上 PCIe 外部 master(HCA)通过 BAR 写到 GPU memory 时,写会先停在 HDP(Host Data Path)write FIFO 里,本地 GPU CU 不会自动看到,直到刷 HDP:
• 在 AMD ROCm + 高性能网络栈里,HDP flush 是必须的;
这就是你在 dushmem 代码里看到的:
dushmem_types.h 里的 curr_hdp_reg 字段,uint32_t* curr_hdp_reg,注释 // Current GPU's HDP register
这指针指向 HDP flush MMIO 寄存器,写它会把 HDP write FIFO 排空到 GPU memory。
• NVIDIA 上没这玩意儿(用 GDRDMA / GPUDirect 内部一致性),所以 NVSHMEM 原版 code base 里没有;这是 ROCm port 必须额外做的事。
这正好解释你的现象
• PE0 RDMA_WRITE → HCA 把 8B 写到 PCIe → 数据停在 PE1 GPU 的 HDP write FIFO
• PE1 host 端做 loopback RDMA_READ → HCA 通过 PCIe 读 → HDP 是写路径,读不会触发 flush,所以读到的还是 0
• PE1 GPU spin → CU 不会看到 HDP FIFO 里的字节,看到 0
• PE0 send CQE 早就成功了,因为 RC ack 只表示对端 HCA 收到,不表示落 GPU memory
这跟你 phase A 和 phase B 都 observed=0x0 完美匹配。
if (t->current_hdp_reg != NULL) {
*(t->current_hdp_reg) = 0x1; // flush HDP write FIFO
}每条 RDMA 路径(rma / amo / cst)发起前都先刷 HDP。地址通过 HSA 接口拿:
ibrc.cpp:1961:
c->get_info(agent, 0xA00E /* HSA_AMD_AGENT_INFO_HDP_FLUSH */, &hdp);HDP flush 寄存器是个 MMIO,写任意值(dushmem 写 0x1**)就触发**。它把 HDP write FIFO 推到 GPU memory。
注意方向 :HDP flush 是 PE 接收端 要做的,不是发送端 PE0。但 dushmem 的做法是 发送端在 post WR 之前刷自己的 HDP------这其实是为了"刷掉 GPU 之前对自己 RDMA payload buffer 的写",让 HCA 读到最新数据。
接收端可见性需要的"刷"是 PE1 在 spin 时,让 HCA 写回的字节从 HDP write FIFO 出来到 GPU memory ------这个 HCA 写 PCIe 后无法主动触发,必须 PE1 自己(host or kernel)写一下 HDP flush MMIO。
dushmem 在接收端的对应路径是 dushmemi_transfer_enforce_consistency_at_target(false)------它发的就是 loopback RDMA_READ ,目的是把 PCIe write 路径上的"飞行中"字节强制完成。但这个 read 是从 PE1 GPU memory 读、写到 host scratch,它读 GPU memory 之前没人刷 HDP------所以读不到那个 HCA 刚写进 FIFO 的字节。
2. 裸金属 GPU 编程中的可见性陷阱
https://zhuanlan.zhihu.com/p/2029115858438354698
仔细观察出问题的场景:
Round 1: alloc(A) → write(data_1) → dispatch → read(result) → recycle(A)
Round 2: alloc(A) → write(data_2) → dispatch → GPU reads ??? from A
关键在 write(data_2) 这一步。我们的 GpuBuffer.write() 已经使用了 write_volatile+ SeqCst fence,看起来什么都做对了。
但 Round 2 的 GPU 偶尔读到的不是 data_2------它读到了某种混合了 data_1 残留和 data_2 的数据。问题出在 CPU 的 Write-Combine (WC) store buffer 没有完全 drain 到 PCIe 设备。
这里需要理解 x86 WC 内存模型的一个关键细节:
SFENCE/MFENCE 保证的是 CPU 可见性,不是 PCIe 设备可见性。
一次 WC 写入要经过五个阶段才能到达 GPU:

MFENCE 指令把数据从 ② 推到 ③------CPU 的 WC 缓冲区被清空,数据到达 Root Complex(PCIe 控制器)。CPU 认为写入已经"globally visible"。
但 ③→④→⑤ 这段路是 PCIe posted write

------Root Complex 把数据放上 PCIe 总线后就认为完成了,不等 GPU 确认接收。数据可能还在 PCIe fabric 中传输,或者在 GPU 的 HDP (Host Data Path) 缓冲区中排队。
在大多数情况下,③→⑤ 几乎是瞬时完成的(纳秒级),所以问题极少暴露。但在我们的高频 alloc/write/dispatch/recycle 循环中------每轮不到 1ms------时序窗口足以让 GPU 在数据到达 ⑤ 之前就开始读取。
......
为什么正常用 HIP/CUDA 不会遇到这个问题
因为运行时帮你做了。
hipMemcpy / cudaMemcpy 内部会:
-
调用 HDP Flush(AMD 专用的硬件级写入屏障)
-
通过 MMIO 写 HDP flush
寄存器(non-posted write,自带 readback 语义)
- 在 kernel dispatch 前插入 barrier packet
AMD GPU 硬件甚至有一个专用的 HDP (Host Data Path) 缓存块来缓冲 CPU→VRAM 的写入。内核驱动在 command buffer 提交时会自动插入 HDP_MEM_FLUSH PM4 命令。
当你用 KFD 裸金属路径------直接 mmap VRAM、手动写 AQL packet、doorbell 直接触发 dispatch------你绕过了所有这些自动保护。WC 可见性变成你自己的责任。