一.深度学习概述
1.深度学习简介
机器学习在处理图像和文本方面能力较弱
深度学习是基于人工智能网络,深度是指网络中使用多层,每层都通过非线性变换处理数据,并逐渐提取出更复杂,更抽象的特征
传统机器学习算法依赖人工设计特征,并进行特征提取;而深度学习方法不需要人工,而是依赖算法自动提取特征
深度学习通过模仿人脑的神经网络来处理和分析复杂的数据,从大量数据中自动提取复杂特征,这也是深度学习被看作黑盒子,可解释性差的原因
深度学习尤其擅长高维数据,如图像语音和文本
2.深度学习特点
1.多层非线性变化:深度学习模型由多个层次组成,每一层都应用非线性激活函数对输入数据进行变换。较低的层级通常捕捉到简单的特征(如边缘、颜色等),而更高的层级则可以识别更复杂的模式(如物体或面部识别)。
2.自动特征提取:与传统机器学习算法不同,深度学习能够自动从原始数据中学习到有用的特征,而不需要人工特征工程。这使得深度学习在许多领域中表现出色。
3.大数据和计算能力:深度学习模型通常需要大量的标注数据和强大的计算资源(如GPU)来进行训练。大数据和高性能计算使得深度学习在图像识别、自然语言处理等领域取得了显著突破。
4.可解释性差:深度学习模型内部的运作机制相对不透明,被称为"黑箱",这意味着理解模型为什么做出特定决策可能会比较困难。这对某些应用场景来说是一个挑战。
提升可解释性可以让前面卷积层的神经元尽可能多,后面的神经元尽可能少
3.常用的深度学习模型
卷积神经网络CNN:输入层,隐藏层(卷积层,池化层,全连接层),输出层
主要用于图像处理,使用卷积层来自动提取图像中的局部特征,并通过池化层减少参数数量,提高计算效率
循环神经网络RNN
适用于处理序列数据,自然语言处理,语音识别
RNN具有记忆功能,可以处理输入数据的时间依赖性,但标准RNN难以捕捉长期依赖关系
自编码器:
一种无监督学习模型,通常用于降维,特征学习或者异常检测
自编码器由编码器和解码器组成,编码器将输入压缩降维,解码器将低维表示重建原始输入
生成对抗网络GAN:
广泛用于图像生成,视频合成等领域
包含两个子网络,生成器和判别器,生成器负责创建看起来真实的假样本,而且判别器则试图区分真假样本
Transformer:
主要用于自然语言处理任务,尤其是机器翻译,文本生成等
采用自注意力机制,使它能够并行处理整个句子的信息,在机器翻译,文本摘要等任务中表现出色
序列数据是指后面的数据对前面有依赖,比如长文本
深度强化学习:
图神经网络:
4.应用场景
计算机视觉:图像分类,目标检测,面部识别,图像生成
自然语言处理:机器翻译,情感分析,文本生成,语音识别,聊天机器人
推荐系统:电影、音乐推荐,电商推荐,社交媒体推荐
多模态大模型:一个大模型能处理所有类型任务
5.PyTorch框架
是一个基于Python语言的深度学习框架,将数据封装成张量进行处理
提供了灵活且高效的工具,用于构建、训练和部署机器学习和深度学习模型
广泛应用于学术研究和工业界
pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple安装
PyTorch特点
类似NumPy的张量计算
自动微分系统
深度学习库
动态计算图
GPU加速(CUDA支持)
支持多种应用场景
跨平台支持
二.张量(Tensor)
PyTorch中张量就是元素为同一种数据类型的多维矩阵,在PyTorch中,张量以"类"的形式封装起来,对张量的一些运算、处理的方法被封装在类中
PyTorch张量与NumPy数组类似,但PyTorch的张量具有GPU加速的能力(通过CUDA),这使得深度学习模型能够高效地在GPU上运行
PyTorch提供了对张量的强大支持,可以进行高效的数值计算、矩阵操作、自动求导等
张量是PyTorch中的核心数据抽象,PyTorch支持各种张量子类型,一维张量称为向量
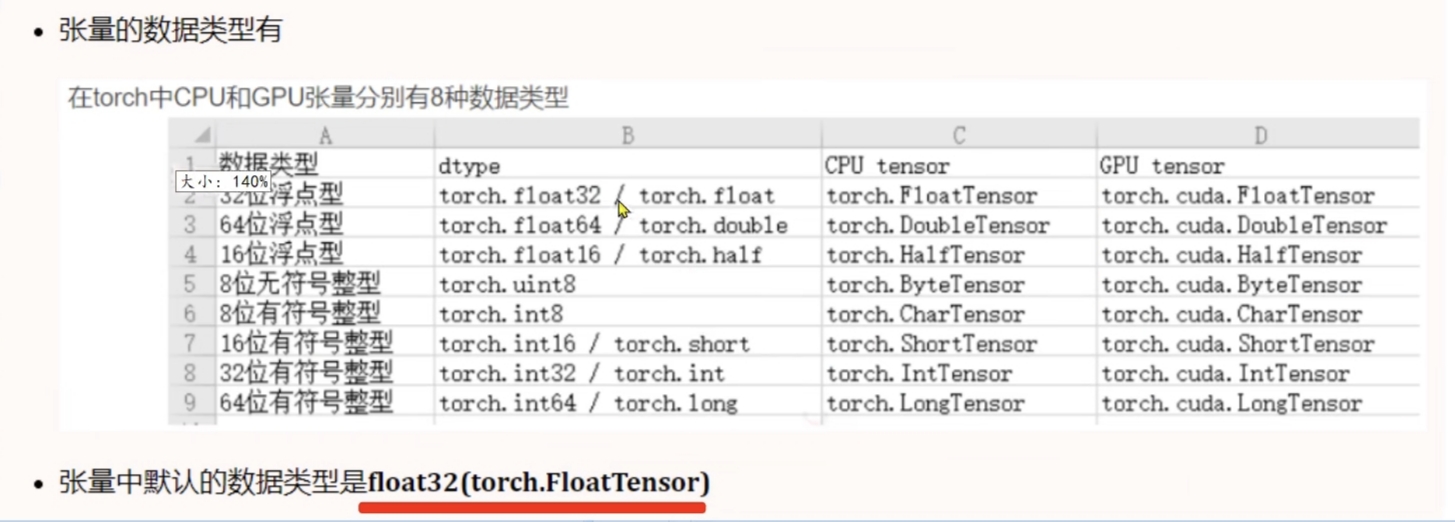
1.张量的基本创建方式
torch.tensor基于指定数据创建张量
torch.Tensor基于指定性状创建张量,小写能做的大写都能做,还能直接创建指定维度的张量,生成随机数
torch.IntTensor如果类型不匹配,会尝试自动转换类型
torch.ones(a,b)和torch.ones_like(data)创建全1张量
torch.zeros(a,b)和torch.zeros_like(data)创建全0张量
torch.full(size(a,b),fill_value=指定值)和torch.full_like(data,fill_value=指定值)创建全为指定值张量
前面的调用生成a行b列的张量,后面的调用生成和tensor类型的张量data维度一致的张量
torch.arange(a,b,c)和torch.linspace(a,b,c)创建线性张量
torch.arange(a,b,c)从a到b,逐个+c,包含a但不包含b
torch.linspace(a,b,c)从a到b,一共c个,包含a和b
torch.random.initial_seed()和torch.random.manual_seed()随机种子设置
torch.random.initial_seed()采用当前系统时间戳创建随机种子
torch.random.manual_seed(a)设置随机种子后每次生成结果都一样
torch.rand(size(a,b))/randn(size(a,b))创建随机浮点类型张量,a行b列
torch.rand(size(a,b))均匀分布
randn(size(a,b))正态分布
torch.randint(low,high,size(a,b))创建随机整数类型张量,a行b列
2.张量元素类型转换
data.type(torch.DounleTensor)
data.type(torch.int16)转为int类型张量
data.half()/double()/float()/short()/int()/long()
half()是float16类型

t1.dtype是指t1中元素数据类型,type(t1)是指张量类型
Tensor.numpy函数可以将张量转换为ndarry数组,但是共享内存,通过.copy()函数避免共享
from_numpy函数可以将ndarry数组转换为Tensor张量,但是共享内存,通过.copy() 函数避免共享
torch.tensor可以将ndarry数组转换为Tensor,默认不共享内存
对于只有一个元素的张量,使用item将值从张量中提取出来
3.张量运算
add()加,张量加一个值则该数值和张量中每个值运算,不会修改原来的数据,要修改数据使用add_()可以用+符号代替
sub()减
mul()乘,张量相乘使用点乘,要求两个张量维度一致,对应元素直接相乘
matmul()矩阵相乘,使用转置相乘,a的列数=b的行数,结果是a行b列,符号是@
div()除,除法会有小数形式
neg()取反
dot()只对一维张量有效
4.张量运算函数
data.sum(dim=0),dim=0按列求和,dim=1按行求和,不写则全求和
data.max()
data.min()
data.mean()
上面四个有dim参数,下面的没有
data.pow(a),每个数开a次方,符号是**,等同于data ** a
data.sqrt(),平方根
data.exp(),e的每个元素次幂
data.log()
data.log2()
data.log10()
5.张量索引操作
简单行列索引
获取第二行的数据data行,列,data1,:或者data1
列表索引
返回(0,1)和(1,2)两个位置的元素,dataa,b,c,d,返回的是第a+1行,第c+1列的数据,第一个数组是行索引集合,第二个数组书列索引集合
返回第0,1行的1,2列共四个元素,data \[ \[0,1 ],1,2 ]
范围索引
返回前三行的前两列,data:3,:2
第二行到最后一行,前两列的数据,data1:,:2
所有奇数行,偶数列,data1::2,::2
布尔索引
datatorch.tensor(True,True,False),:
第三列,大于五的行数据datadata\[:,2>5]
第二行,大于五的列数据data:,data\[1>5]
多维索引
获取0轴上的第一个数据data0,:,:
获取1轴上的第一个数据data:,0,:
获取2轴上的第一个数据data:,:,0
6.张量形状操作
data.shape,输出torch.Size(a,b)表示a行b列
data.shape0输出行数
data.shape1输出列数
data.shape-1输出最后一维的大小
data.reshape(a,b)转换成a行b列的张量
保证张量数据不变的前提下改变数据的维度,将其转换成指定的形状
squeze()
删除形状为1的维度(降维)
unsqueeze(a)
在a轴上增加一个1维度
teamspose(a,b)
一次交换两个维度,不会改变原数据
permute(2,0,1)
一次交换多个维度,将012维度改变顺序为2,0,1维度顺序
view(a,b)
只能修改连续的张量,存储数据和逻辑顺序一致,修改后仍然连续
如果张量使用transpose或者permute修改后则不能用view
contigous()
把不连续的张量变为连续的张量,修改内存存储顺序
is_contigous()
判断张量是否连续
7.张量拼接操作
torch.cat(data1,data2,dim=0)函数可以将多个张量根据指定的维度拼接起来,不改变维度数,除了拼接的维度外,其他维度数必须保持一致
上述表示 在0维度上拼接两个张量
torch.stack(data1,data2,dim=0)函数在一个新的维度上连接一系列张量,会增加新维度,并且所有输入张量的形状必须完全相同,生成的是(2,原数据维度)维张量
8.自动微分模块
参数会根据损失函数关于对应参数的梯度进行调整,为了计算这些梯度,PyTorch内置了torch.autograd的微分模块,支持任意计算图的自动梯度计算
对损失函数求导,结合反向传播,更新权重参数w,b
多元线性公式y=wx+b
权重更新公式w新= w旧 - 学习率*梯度
偏置更新公式b新=b旧 - 学习率*梯度
实际开发中不考虑偏置
梯度基本计算:PyTorch不支持向量张量对向量张量的求导,只支持标量张量对向量张量的求导
如果x是张量,y必须是标量才可以求导
计算梯度:y.backward
获取x点的梯度值:x.grad
1.创建标量:
w = torch.tensor(10, requires_grad=True, dtype=torch.float),创建一个标量10,允许自动微分,浮点数类型
2.损失函数:
loss = 2 * w ** 2
3.计算梯度:
loss.sum().backward(),保证loss是一个标量
4.更新权重:
w.data = w.data - 0.01* w.grad
9.自动微分小技巧
一个张量一旦设置了自动微分,就不能直接转成numpy的ndarray对象了,需要通过detach()函数解决
t1如果设置了 requires_grad=True,则t1.numpy()报错
可以通过t2= t1.detach().numpy()拷贝另一份数据转换
三.线性回归
1.准备数据集

生成的值是numpy对象,需要转成张量形式,coef为权重w
首先创建数据集对象,把tensor转换成数据集对象
dataset = TensorDataset(x,y)
然后创建数据加载器对象
daraloader = DataLoader(daraset,batch_size = 16, shuffle = True),参数分别表示数据集对象, 批次大小,是否打乱数据(训练集打乱,测试集不打乱)
2.构建模型
下一步创建初始的线性回归模型
model= nn.Linear(1,1),参数表示输入的特征维度和输出特征维度
3.设置损失函数和优化器
创建损失对象
criterion = nn.MSELoss()
创建优化器对象
optimizer = optim.SGD(model.parameters(),lr = 0.01),参数分别表示模型参数和学习率
4.训练模型
epochs为训练轮数
epoch_loss为每轮的损失
total_loss总损失
train_sample为训练样本
按照训练轮数循环
for epoch in range(epochs)
从数据加载器中逐个批次获取数据
for train_x, train_y in dataloader
模型预测
y_pred = model(train_x)
计算损失
loss = criterion(y_pred, train_y.reshape(-1,1))
计算总损失
total_loss += loss.item()
total_sample += 1
梯度清零,反向传播,梯度更新
optimizer.zero_grad()
loss.backwart()
optimizer.step()
把本轮平均损失添加到列表中
loss_list.append(total_loss/total_sample)
绘制损失曲线
plt.plot(range(epochs),loss_list)
plt.title("损失值曲线变化图")
plt.grid()
绘制样本点分布情况
plt.scatter(x,y)
绘制训练模型的预测值
y_pred = torch.tensor(data = v \* model.weight + model.bias for v in x)
计算真实值
y_true = torch.tensor(data = v \* coeft + 14.5 for v in x)
绘制预测值和真实值的折线图
plt.plot(x,y_pred, color = 'red' , label = '预测值')
plt.plot(x, y_true , color = 'green', label = '真实值')
plt.legend()
plt.grid()
plt.show()
四.神经网络
1.神经网络概述
人工神经网络ANN也称神经网络,是一种模仿生物神经网络结构和功能的计算模型,人脑可以看作是一个生物神经网络,由众多的神经元连接而成,各个神经元传递复杂的电信号,树突接收到姝蕊你好,对信号处理,通过轴突输出信号,当电信号通过树突进入到细胞核时,会逐渐聚集电荷,达到一定的点位后,细胞会被激活,通过轴突发出电信号
神经网络由多个神经元组成,构建神经网络就是在构建神经元,来源不同树突的信息,进行加权计算,输入到细胞核中求和,再通过激活函数输出细胞值
神经网络优点:精度高,性能优于其他的机器学习方法,甚至在某些领域超过了人类
可以近似任意的非线性函数
近年来在学界和业界收到了热捧,有大量的框架和库可供调用
缺点:黑线,很难解释模型工作原理
训练时间长,需要大量算力
网络结构复杂,需要调整超参数
小数据集上表现不佳,容易发生过拟合
2.神经网络构建
有几个特征输入层就有几个神经元,相邻层神经元相互连接,同层神经元相互隔离
前层输出就是后层输入
全神经网络连接就是全连接,接收的样本数据是二维的
每个连接都有权重值
首先对特征加权求和,再传给激活函数处理
1.输入层:即输入x的那一层,每个输入特征对应一个神经元,输入层将数据传递给下一层的神经元
2.输出层:即输出y的那一层,输出层的神经元根据网络的任务(回归,分类等)生成最终的预测结果
3.隐藏层:输入层和输出层之间都是隐藏层,神经网络(),隐藏层的神经元通过加权和激活函数处理输入,并将结果传递到下一层。
每个神经元有内部状态值,激活值,内部状态值梯度和激活值梯度
每个神经元工作时,前向传播会产生两个值,内部状态值和激活值,反向传播时会产生激活值梯度和内部状态值梯度
内部状态值:神经元或隐藏单元的内部存储值,它反映了当前神经元接收到的输入、历史信息以及网络内部的权重计算结果
激活值:
四.激活函数
激活函数用于对每层的输出数据进行变换,进而为整个网络注入了非线性因素,此时,神经网络就可以拟合各种曲线
1.没有引入非线性因素的网络等价于使用一个线性模型来拟合
2.通过给网络输出增加激活函数,实现引入非线性因素,是的网络模型可以逼近任意函数,提升网络对复杂问题的拟合能力
1.sigmoid激活函数
激活函数公式:
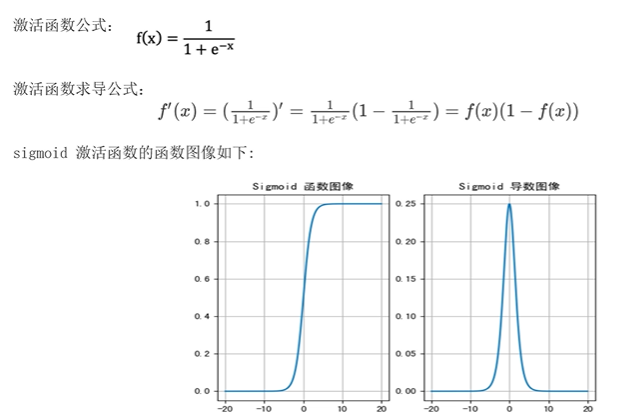
x越大,整体越大,x为加权求和结果
sigmoid函数可以将任意的输入映射到(0,1)之间,当输入的值大致在小于-6或者大于6时,意味着输入任何值得到的激活值都是差不多的,这样会丢失部分的信息,比如输入100和输入10000经过sigmoid的激活值几乎都是等于1的,但是输入的数据之间相差100倍的信息就丢失了
对于sigmoid来说,输入值在-6,6之间,输出值才会有明显差异,输入值在-3,3之间才会有比较好的效果
通过上述导数图像,我们发现导数值范围时(0,0.25),当输入小于-6或者大于6时,sigmoid激活函数图像的导数接近为0,此时网络参数将更新极其缓慢,或者无法更新
一般来说,sigmoid网络在五层以内就会产生梯度消失现象,而且,该激活函数并不是以0为中心的,所以在实践中这种激活函数使用的很少,一般只用于二分类的输出层
2.tanh激活函数
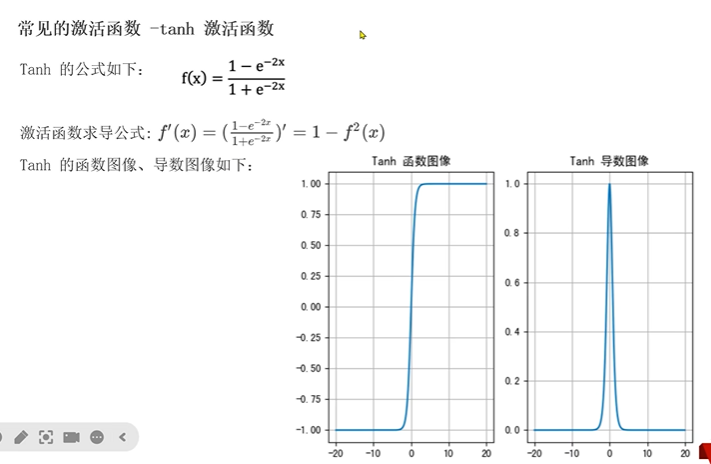
x越大,整体越接近1,x越小,整体越接近-1
tanh在-3,3有效果,在-1,1效果明显,将值映射到-1,1,导数值范围在0,1
Tanh 函数将输入映射到 (−1,1)之间,图像以 0 为中心,在 0 点对称,当输入大概 <−3 或者 >3 时将被映射为 −1 或者 1。其导数值范围 (0,1),当输入的值大概 <−3 或者 >3 时,其导数近似 0。
与Sigmoid相比,它是以0为中心的,且梯度相对于sigmoid大,使得其收敛速度要比Sigmoid快,减少迭代次数,然而,从图中可以看出Tanh两侧的导数也为0,同样会造成梯度消失
若使用时可在隐藏层使用tanh函数,在输出层sigmoid函数
3.ReLU激活函数
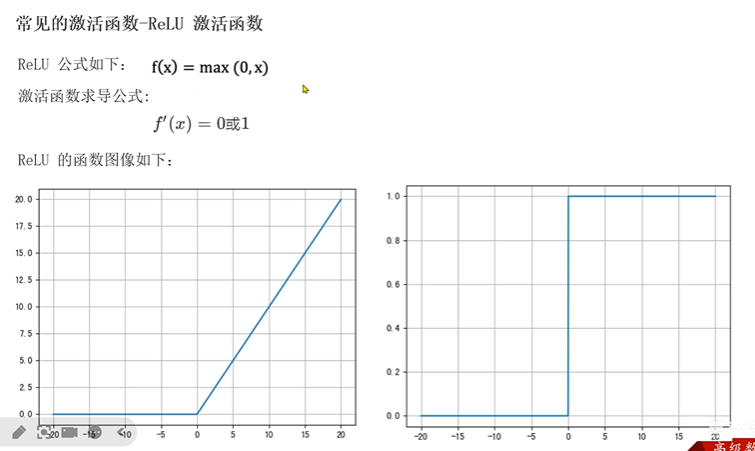
默认情况下,ReLU只考虑正样本
ReLU激活函数将小于0的值映射为0,而大于0的值保持不变,它更重视正信号,而忽略负信号,这种激活函数运算更为简单,能够提高模型的训练效率
当x<0时,ReLU导数为0,当x>0时,则不存在饱和问题。所以ReLU能够在x>0时能保持梯度不衰减,从而缓解梯度消失问题,然而随着训练的推进,部分输入会落于小于0区域,导致对应权重无法更新。这种现象被称为"神经元死亡"
ReLU是目前最常用的激活函数,与sigmoid相比,ReLU的优势是:采用sigmoid函数,计算量大,反向传播求误差梯度时,计算量相对大,而采用ReLU激活函数,整个过程的计算量节省很多。sigmoid函数反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网格的训练。ReLU会使一部分神经元输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生
4.softmax激活函数
softmax用于多分类过程中,它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。计算方法如下:
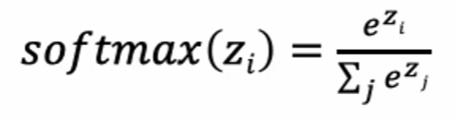
softmax就是将网络输出的logits通过softmax函数,就映射成为(0,1)的值,而这些值的累和为1(满足概率的性质),那么我们将它理解成概率,选取概率最大(也就是值对应最大的)节点,作为我们的预测目标类别。
5.激活函数的选择方法
对于隐藏层:
1.优先选择ReLU激活函数
2.如果ReLU效果不好,那么尝试其他函数,如Leaky ReLU等
3.如果你使用了ReLU,需要注意一下Dead ReLU问题,避免出现0梯度从而导致过多的神经元死亡
4.少使用sigmoid激活函数,可以尝试使用tanh激活函数
对于输出层:
1.二分类问题选择sigmoid激活函数
2.多分类问题选择softmax激活函数
3.回归问题选择identity激活函数
五.参数初始化
在构建网络后,网络中的参数是需要初始化的,我们需要初始化的参数主要有权重和偏置,偏置一般初始化为0即可,而对权重的初始化则会更加重要
参数初始化的作用:1.防止梯度消失或爆炸:初始权重值过大或过小会导致梯度在反向传播中指数级增大或缩小
2.提高收敛速度:合理的初始化是的网络的激活值分布适中,有助于梯度高效更新
3.保持对称性破除:权重的初始化需要打破对称性,否则网络的学习能力会受到限制
1.常用的参数初始化方法
随机初始化
均匀分布初始化
权重参数初始化从区间均匀随机取值,默认区间为(0,1).可以设置为在均匀分布中生成当前神经元的权重,其中d为神经元的输入数量
正态分布初始化
随机初始化从均值为0,标准差是1的高斯分布中取样,使用一些很小的值对参数w进行初始化
优点:能有效打破对称性
缺点:随机选择范围不当可能导致梯度问题
使用场景:浅层网络或低复杂度模型。隐藏层1-3层,总层数不超过5层
全0初始化
所有权重初始化为0
优点:实现简单
缺点:无法打破对称性,所有神经元更新方向相同,无法有效训练
使用场景:几乎不使用,仅用于偏置项的初始化
全1初始化
所有权重初始化为1
优点:实现简单
缺点:无法打破对称性,所有神经元更新方向相同,无法有效训练
会导致激活值在网络中呈指数级增长,容易出现梯度爆炸
使用场景:测试或调试:比如验证神经网络是否能正常前向传播和反向传播
特殊模型结构:某些稀疏网络或特定的自定义网络中可能需要手动设置部分参数为1
偏置初始化:偶尔可以将偏置初始化为小的正值(0.1),但很少用1作为偏置的初始值
固定值初始化
所有权重初始化为固定值
优点:实现简单
缺点:无法打破对称性,所有神经元更新方向相同,无法有效训练
初始权重过大或过小可能导致梯度爆炸或梯度消失
使用场景:测试或调试
kaiming初始化
也叫HE初始化:HE初始化分为正态分布的HE初始化、均匀分布的HE初始化
正态分布的HE初始化:从0,std中抽取样本,std = sqrt(2/fan_in)
均匀分布的HE初始化:从-limit,limit中的均匀分布中抽取样本,limit是sqrt(6/fan_in)
fan_in为输入层神经元的个数,当前层接受的上一层的神经元的数量。简单来说,就是当前层接收多少个输入
一般使用ReLU激活函数
优点:适合ReLU,能保持梯度稳定
缺点:对非ReLU激活函数效果一般
使用场景:深度网络(10层及以上),使用ReLU,Leaky ReLU激活函数
xavier初始化
也叫Glorot初始化:分为正态分布的xavier初始化和均匀分布的xavier初始化
正态分布的xavier初始化:从0,std中抽取样本,std = sqrt(2/(fan_in+fan_out))
均匀分布的HE初始化:从-limit,limit中的均匀分布中抽取样本,limit是sqrt(6/(fan_in+fan_out))
fan_in为输入层神经元的个数,当前层接受的上一层的神经元的数量,fan_out为输出层神经元个数,当前层会传递给下一层的神经元的数量
优点:适用于Sigmoid,Tanh等激活函数,解决梯度消失问题
缺点:对ReLU等激活函数表现欠佳
使用场景:深度网络(10层及以上),使用Sigmoid或Tanh激活函数
六.神经网络搭建
在pytorch中定义深度神经网络其实就是层堆叠的过程,继承自nn.Module,实现两个方法:
_init_方法中定义网络中的层结构,主要是全连接层,并进行初始化
forward方法,在实例化模型的时候,底层会自动调用该函数。该函数中为初始化定义的layer传入数据,进行前向传播等。