企业级 AI 平台真正的考验,从来不是客户看完演示点头鼓掌,而是技术团队问完一圈之后,自己还有几个问题答不上来。
这周有一场两小时的产品交流,来访方一次性派出了开发、算法、AI 工程师和职能岗。功能演示只占了前 20 分钟,剩下的一个半小时全是技术追问------上下文会不会爆、知识库会不会脏、数据会不会进训练、压缩掉的东西放哪里、文件版本怎么管。
每一个问题都问在了企业级 AI 的真实工程边界上。复盘这场对话,比一周的代码更有信息量。
一、上下文压缩与沙箱缺位
被追问得最深的一个点是------
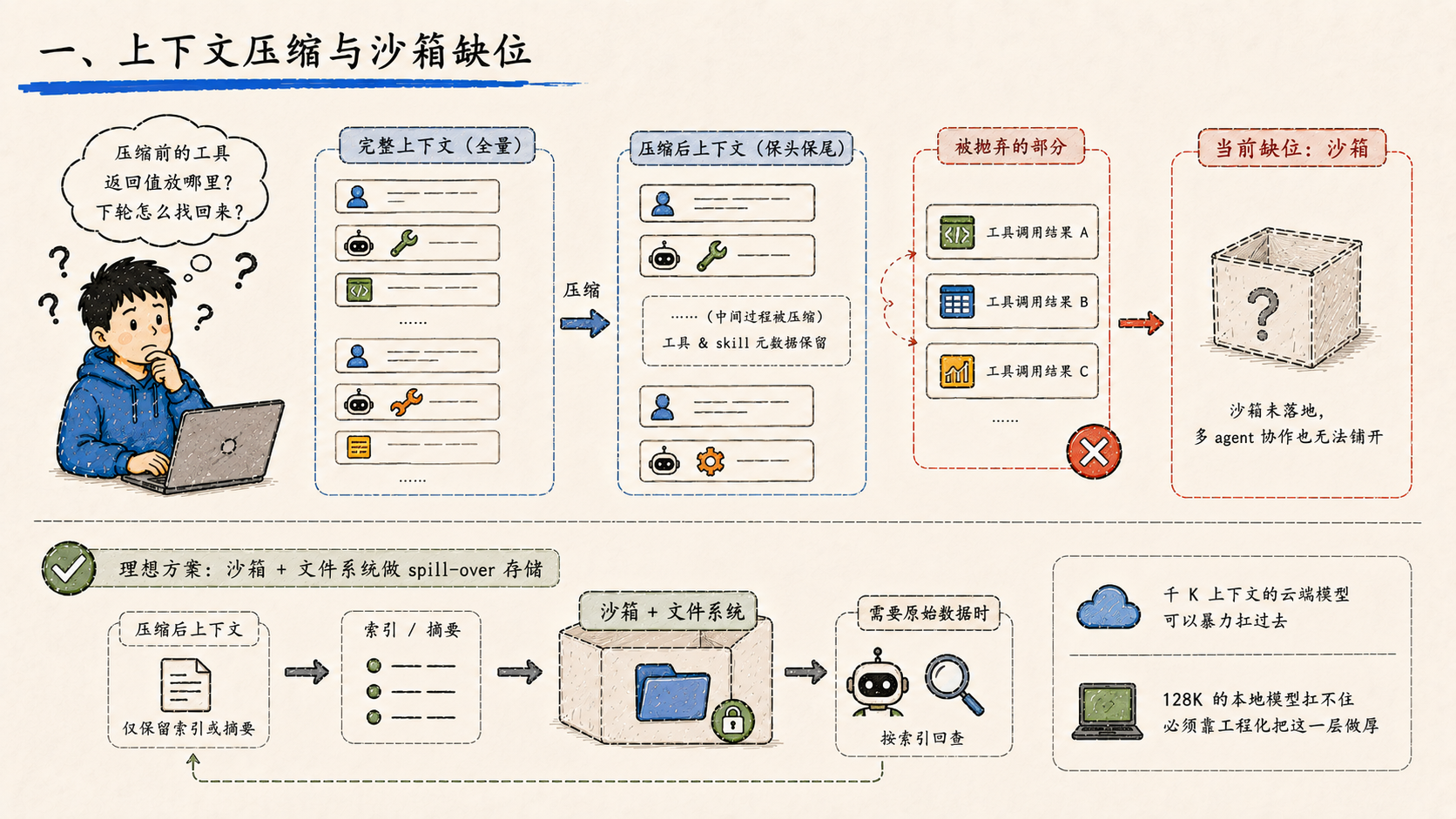
"企业全量接口注册进去之后,上下文窗口必然溢出。压缩之前的那些工具返回值放在哪里?模型下一轮想用的时候,怎么找回来?"
这是真正硬核的提问。
主流压缩策略目前的做法是:保留对话头部和尾部,中间的工具调用过程被压缩,工具和 skill 的元数据保留。听起来合理------但 "压缩之前的那些工具返回值",事实是直接抛弃。
不抛弃的方案行业里早有共识:用一个独立的沙箱 + 文件系统做 spill-over 存储,模型上下文里只保留索引或摘要,需要原始数据时再回查。这套机制没有沙箱就跑不起来。
而沙箱这件事,恰好是当前还没补齐的能力。多 agent 协作也要等沙箱落地之后才能真正铺开。
这件事决定的不是"能不能跑",而是"能不能上本地小模型"。 千 K 上下文窗口的云端模型可以暴力扛过去,128K 的本地模型扛不住,必须靠工程化把这一层做厚。
二、知识库的真实复杂度远超"切片 + 向量"
知识库被追问了三轮,每一个问题都打在真实痛点上:
-
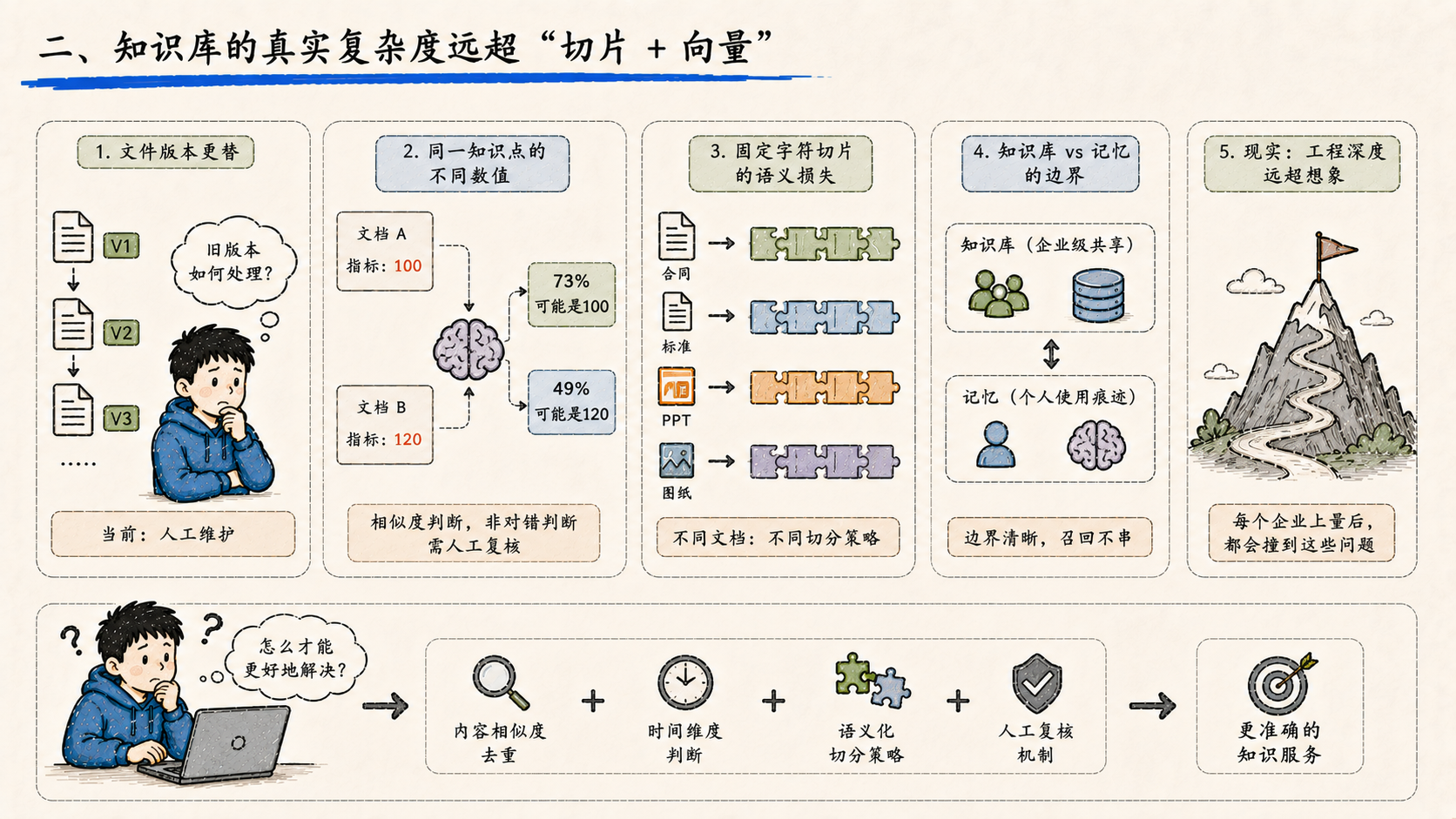
文件版本更替:同一份文档的 V1、V2、V3 都进了库,新版本上传不会自动废弃旧版本。现状是靠人工维护,提醒员工"尽量不要引入相似文件的不同版本"。这是一个尚未解决的工程问题,需要做"内容相似度 + 时间维度"的双因子去重。
-
同一知识点的不同数值:两份文档里同一个指标对不上,知识库会把两个值都召回,用相似度拟合给一个概率(73% 可能是 A,49% 可能是 B)。这不是对错判断,是相似度判断,最终需要人工复核。
-
固定字符切片的语义损失:目前所有文档都按固定字符长度切片 + 重合区域。但是合同、技术标准、PPT、设计图纸,每一种文档的"语义单元"是不一样的------合同按条款切,标准按章节切,PPT 按页切。这件事在主流知识库领域已经有方法论,完整落地仍在路上。
-
知识库 vs 记忆的边界 :会议纪要应该入知识库还是入记忆?结论是------企业级共享走知识库,个人使用痕迹走记忆。 这条边界划清楚,召回路径才能不串。
知识库的工程深度,比"上传文档 + 做向量"要厚得多。 每一个企业上量之后都会撞到这些问题。
三、"上传到平台的数据会不会变成大模型训练语料"
这是企业级 AI 平台被问到最多的问题,没有之一。
回答需要分层讲清楚:
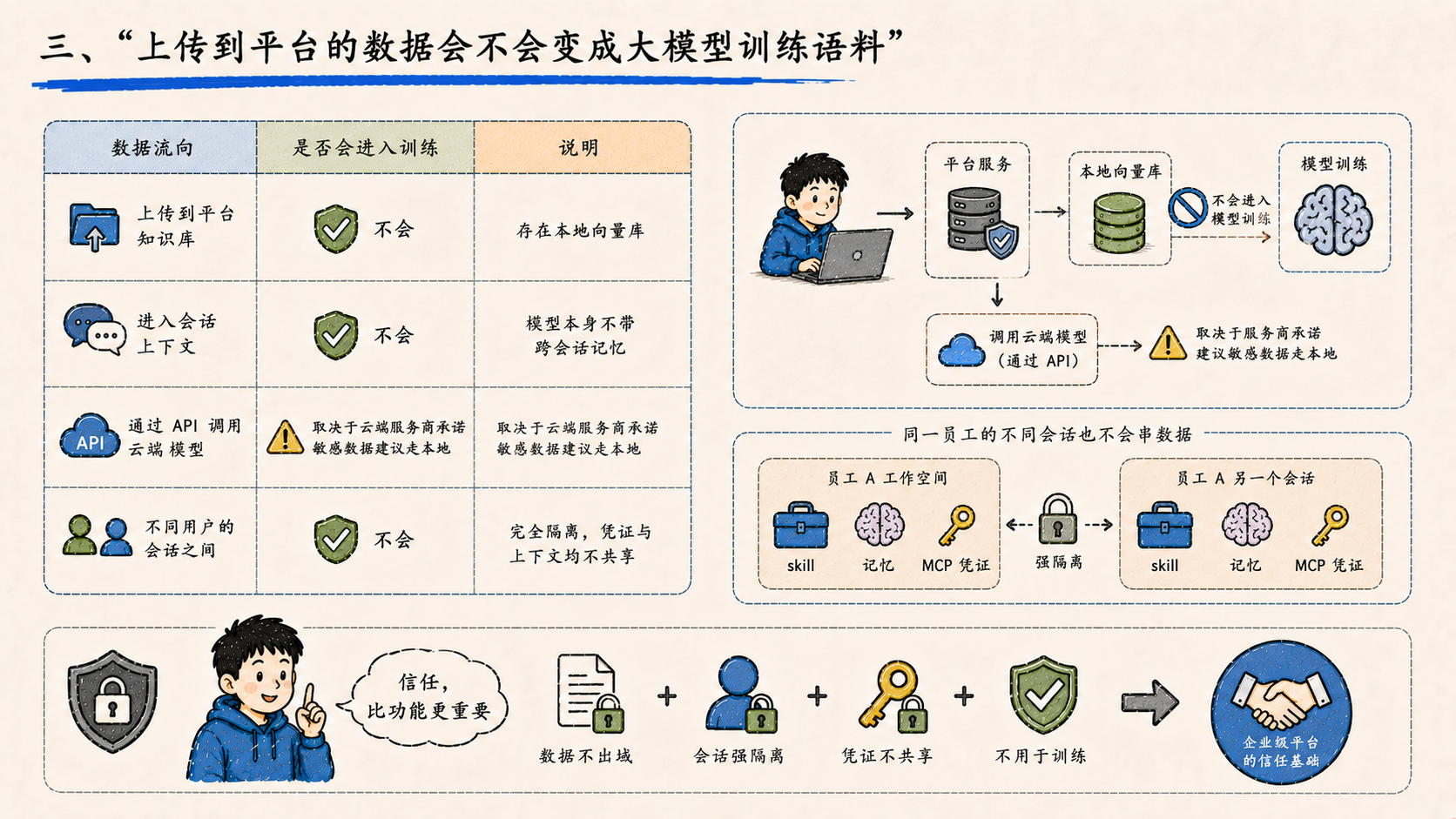
| 数据流向 | 是否会进入训练 |
|---|---|
| 上传到平台知识库 | 不会,存在本地向量库 |
| 进入会话上下文 | 不会,模型本身不带跨会话记忆 |
| 通过 API 调用云端模型 | 取决于云端服务商承诺,敏感数据建议走本地 |
| 不同用户的会话之间 | 完全隔离,凭证与上下文均不共享 |
更隐蔽的一层担忧是------同一个员工的不同会话之间会不会串数据?答案也是不会。每个员工的工作空间存的是自己的 skill、自己的记忆、自己的 MCP 凭证,会话级别强隔离。
把这套权限模型讲清楚,比演示十个功能都管用。企业级 AI 平台卖的是信任,不是聊天框。
四、模型路由:不是为了省钱,是为了合规
被问到"是否支持自动模型路由"的时候,现状是手动切换。
但是路由能力的真正价值,被对方的技术负责人一句话讲明白了:
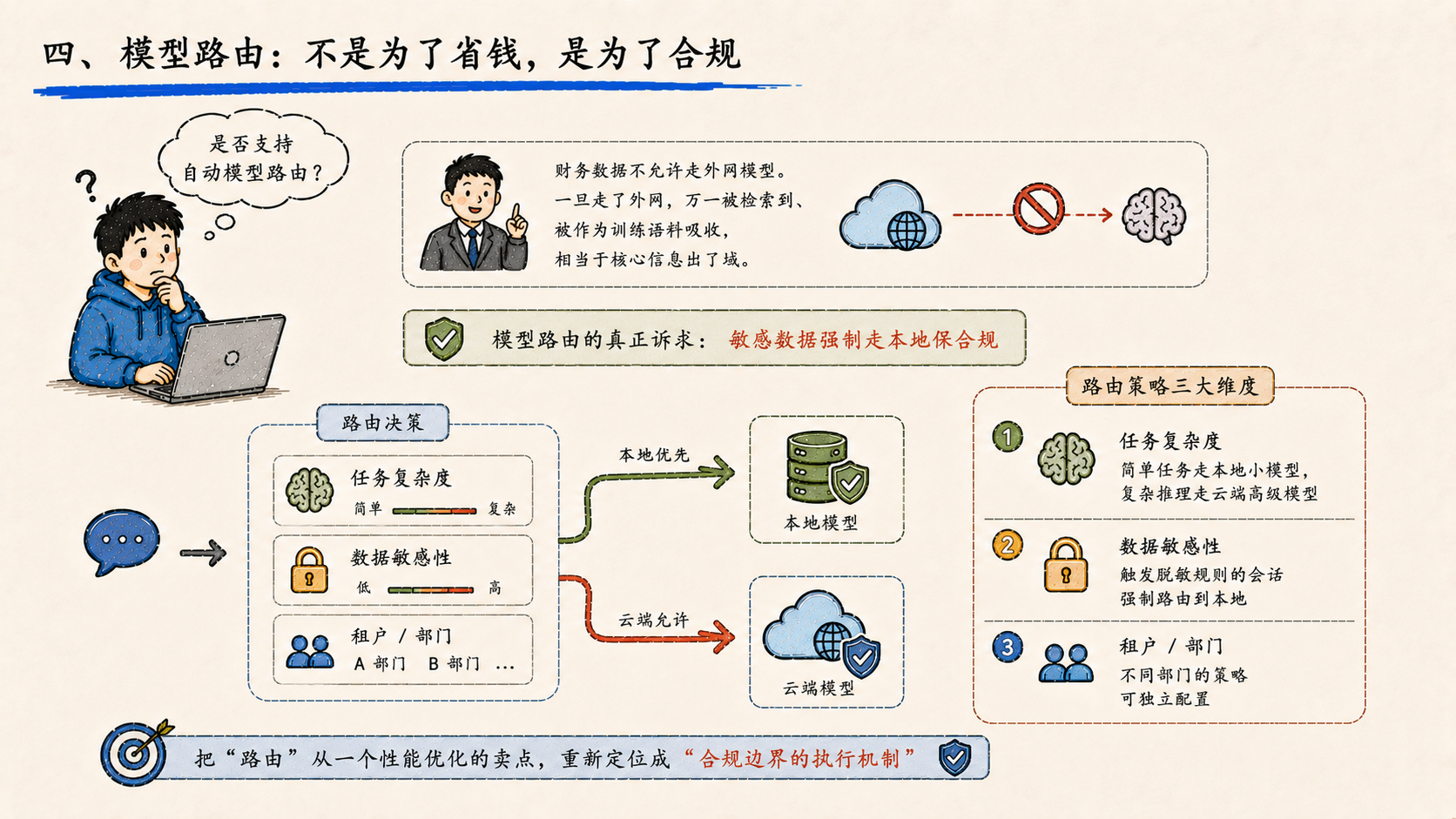
财务的数据可能就不允许走外网模型。一旦走了外网,万一被检索到、被作为训练语料吸收,相当于核心信息出了域。这才是模型路由的真正诉求。
不是"复杂任务走高级模型省成本",而是 "敏感数据强制走本地保合规"。
完整的路由策略至少要支持三个维度:
-
任务复杂度 → 简单任务走本地小模型,复杂推理走云端高级模型
-
数据敏感性 → 触发脱敏规则的会话强制路由到本地
-
租户/部门 → 不同部门的策略可独立配置
把"路由"从一个性能优化的卖点,重新定位成 "合规边界的执行机制",这件事的优先级会立刻变高。
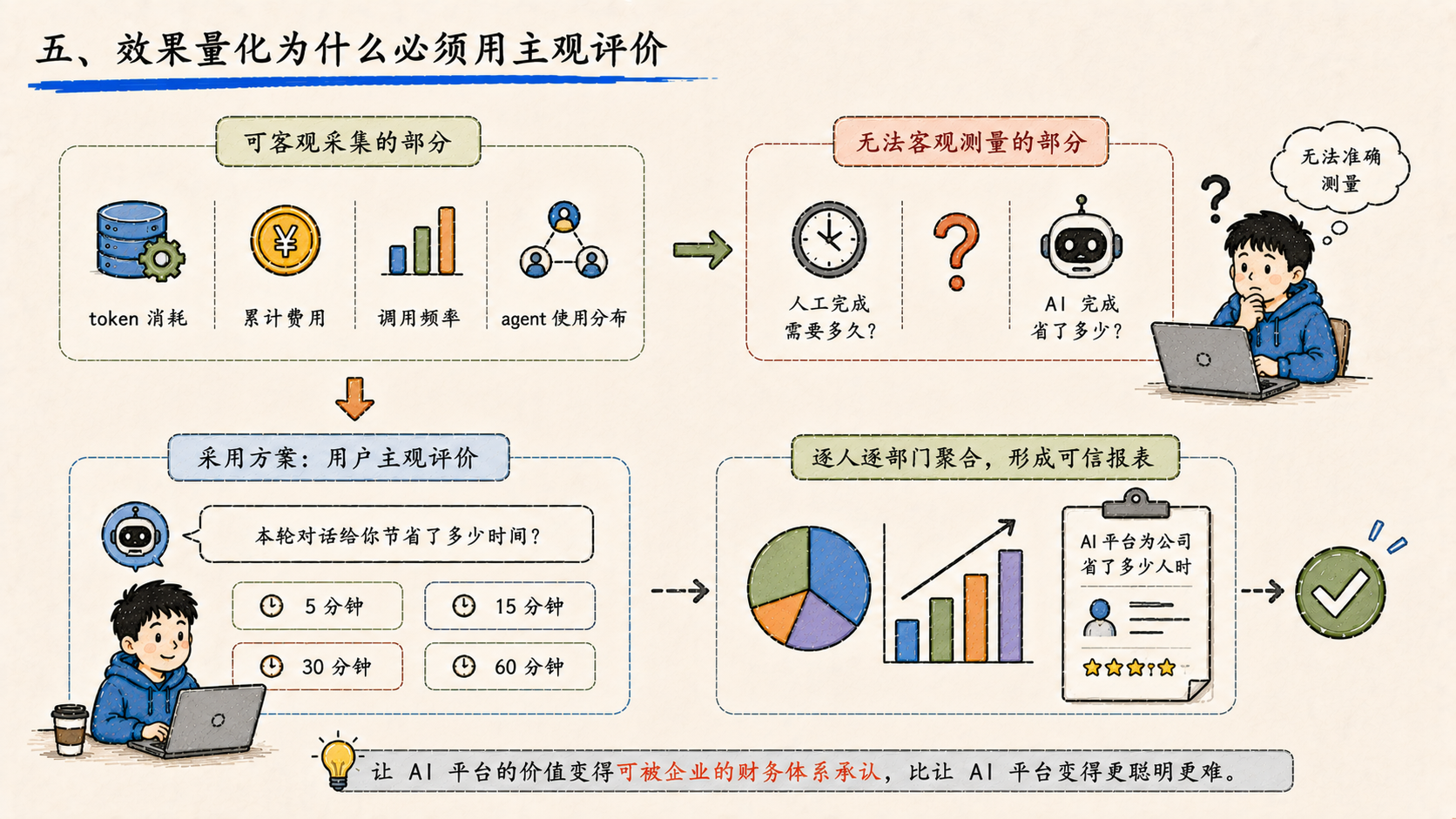
五、效果量化为什么必须用主观评价
最后一个绕不开的问题是------投入产出怎么算?
技术上可以客观采集的部分是确定的:每次调用的 token 消耗、累计费用、调用频率、各 agent 的使用分布。
但 "节省了多少时间"这件事,没有任何客观办法测量。 同一个流程让人做要多久?让 AI 做又省了多少?这两个数字本质上都不可测。
最后采用的方案是用户主观评价:每一轮长任务结束后,会话底部弹一个选项------"本轮对话给你节省了多少时间?5 分钟 / 15 分钟 / 30 分钟 / 60 分钟"。
听起来不严谨,但这是目前能给企业老板看的最现实的数字。主观但可累计,逐人逐部门聚合之后,最终形成一份 "AI 平台为公司省了多少人时"的可信报表。
让 AI 平台的价值变得可被企业的财务体系承认,比让 AI 平台变得更聪明更难。
两个小时的交流,演示只占了 20 分钟。剩下的一个半小时全在回答"系统出了问题怎么办"的边界条件。
这种交流比任何单方面的演示更有价值------技术团队问出来的每一个问题,都是这套系统从"能演示"到"能上线"之间真正的工程缺口。
回去之后要整理的反馈清单,比这一周开发的功能还要重。
这,是第三十五天。
**《从0到1:企业级AI项目迭代日记》**记录一个企业级 AI 项目从创意、架构到落地的真实过程。不讲神话,只记录进化。
如果你也在做企业 AI 落地,欢迎留言来聊。或者,把这篇转发给一个正在踩同样坑的朋友。