今天分享一个运营小红书的扣子工作流,1分钟提取500+小红书笔记评论,同时自动同步到飞书。
为什么要提取热门笔记下的评论呢?
简单点说,评论区有时会藏着一些高价值内容,如痛点、真实需求、产品问题等,而提取评论,也更方便我们去做深度分析。
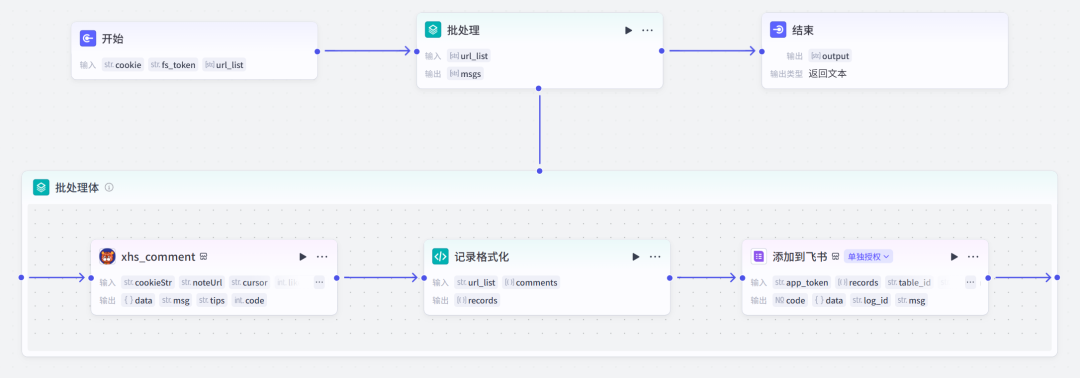
工作流完整截图:
效果展示:
01 搭建工作流
(1)登录扣子,创建一个工作流;
(2)设置开始节点;
提示💡:测试该工作流时会详细介绍各个参数。
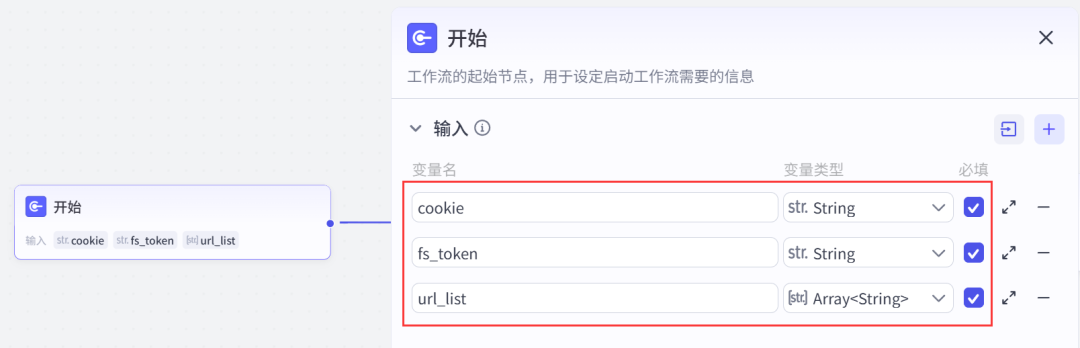
(3)添加一个批处理节点->设置参数;
提示💡:参数务必按照截图给出的来,如果输出选不到,往后做,回过头就可以选了。
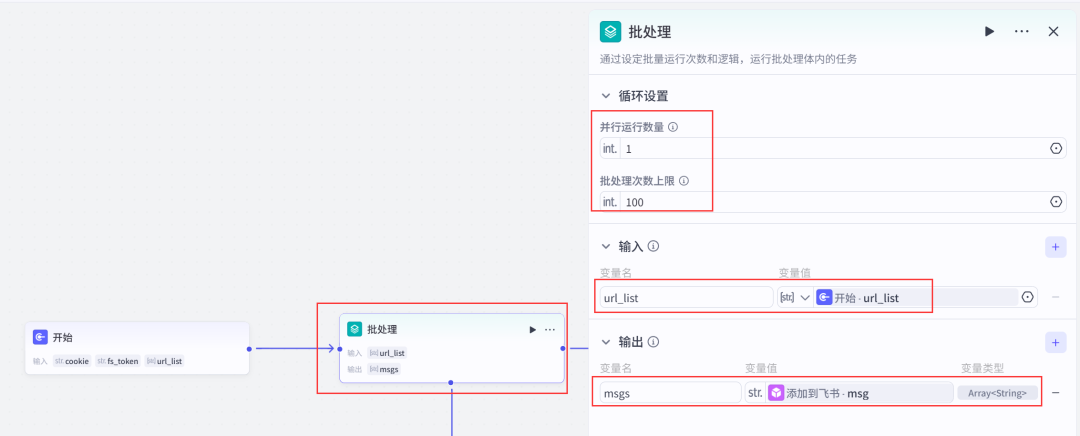
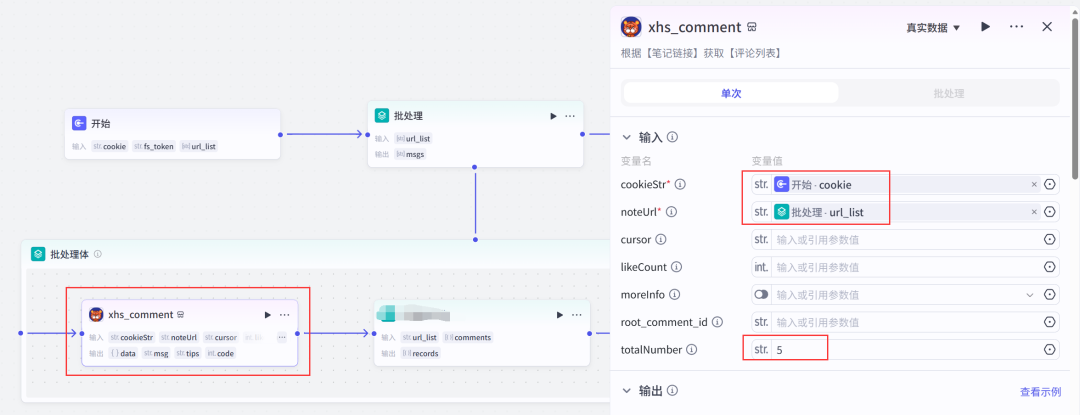
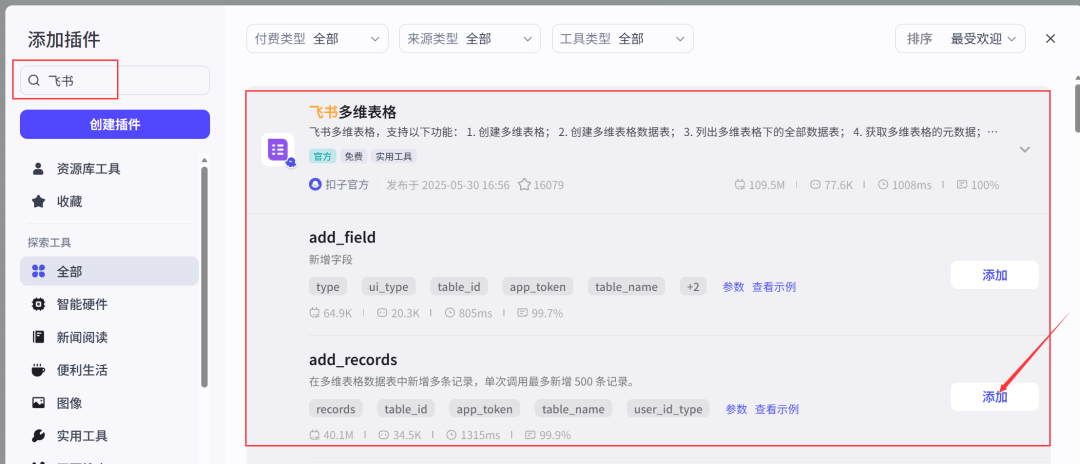
(4)在批处理体中添加一个xhs_comment节点->设置参数;
从添加插件中搜索找到对应图标的插件,展开选择xhs_comment.


设置xhs_comment节点参数。
提示💡:这里的totalNumber可以控制提取的评论条数,但不能超过500条。
(5)添加一个代码节点->重命名为记录格式化->设置参数;
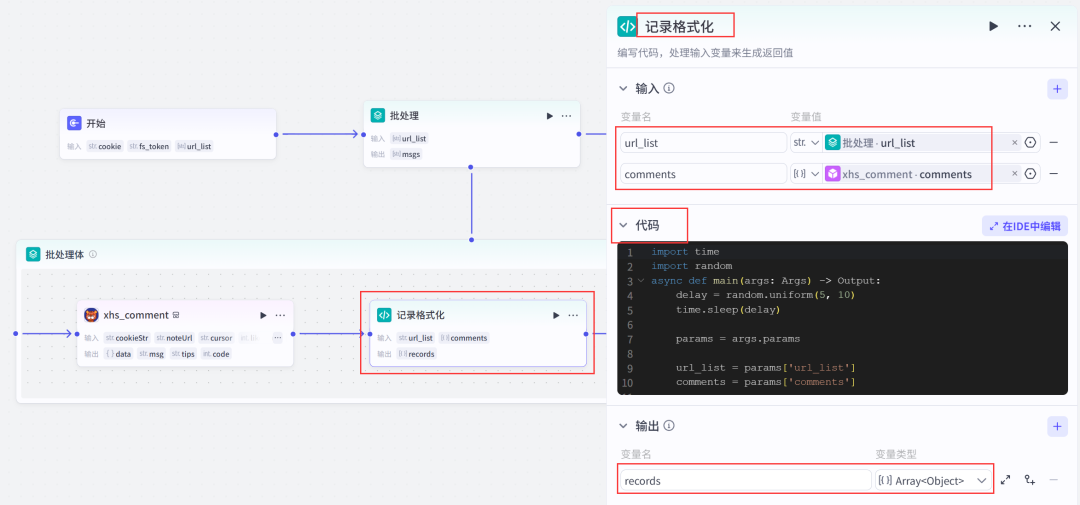
Python代码:
python
import time
import random
async def main(args: Args) -> Output:
delay = random.uniform(5, 10)
time.sleep(delay)
params = args.params
url_list = params['url_list']
comments = params['comments']
records = []
for ele in comments:
comment_content = ele.get('comment_content', '')
comment_like_count = ele.get('comment_like_count', '0')
comment_create_time = ele.get('comment_create_time', '')[:-3]
node_id = ele.get("note_id", '')
likedCount = 0
if '万' in comment_like_count:
num_part = comment_like_count.replace('万', '')
likedCount = float(num_part) * 10000
record = {
"fields": {
"笔记ID":node_id,
"链接":url_list,
"评论": comment_content,
"点赞": int(likedCount),
"评论日期": comment_create_time
}
}
records.append(record)
ret: Output = {
"records": records
}
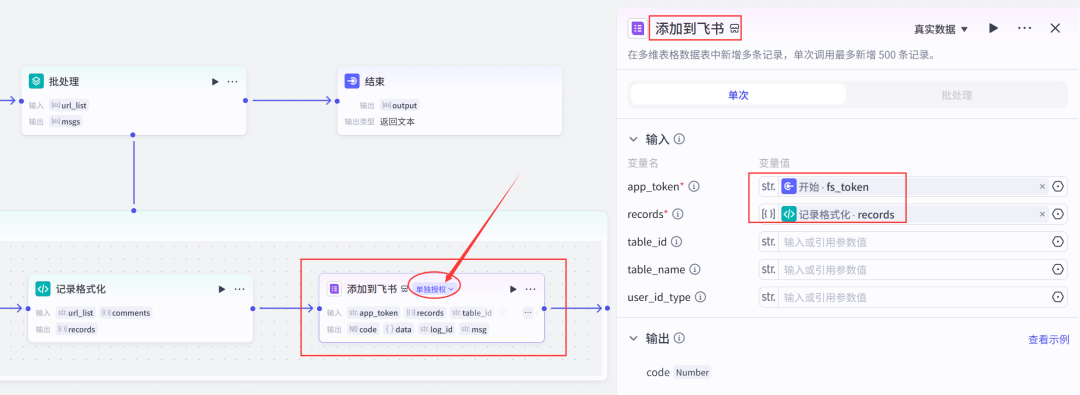
return ret(6)添加一个add_records节点->重命名为添加到飞书->设置参数;
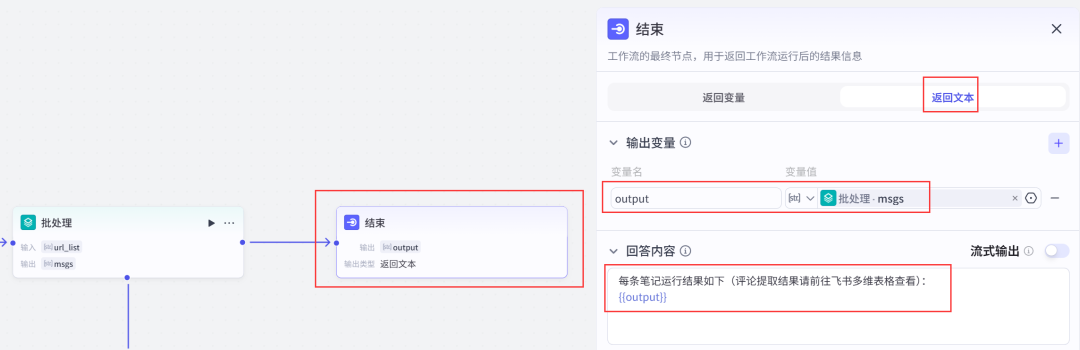
(7)设置结束节点;
02 测试工作流
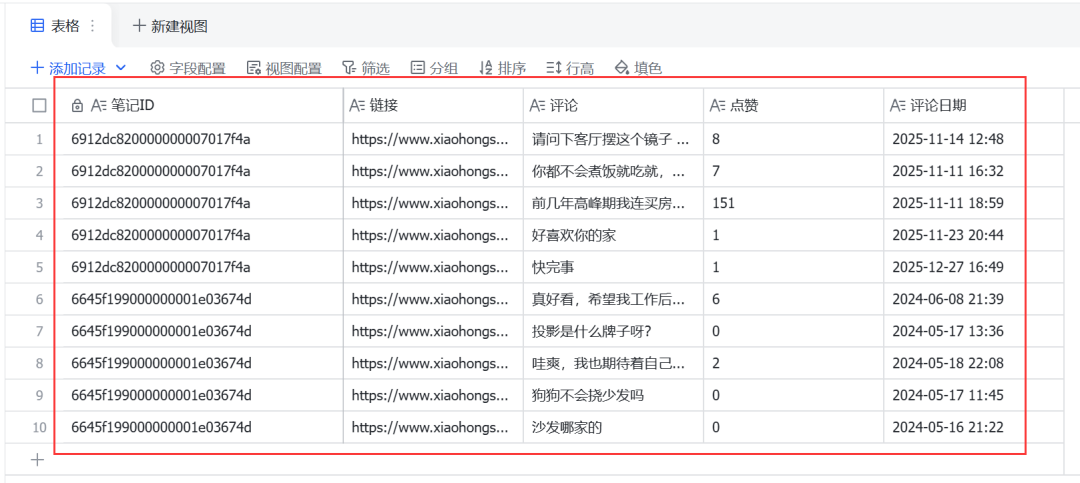
(1)在飞书创建一个多维表格,添加5个字段,按照下图给出的填写;

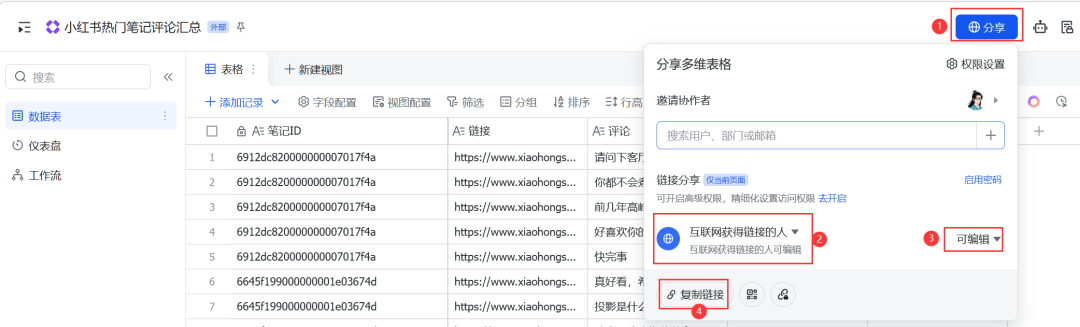
(2)设置下表格权限,复制表格链接;
(3)登录下网页版小红书,刷新下,找到cookie并复制;
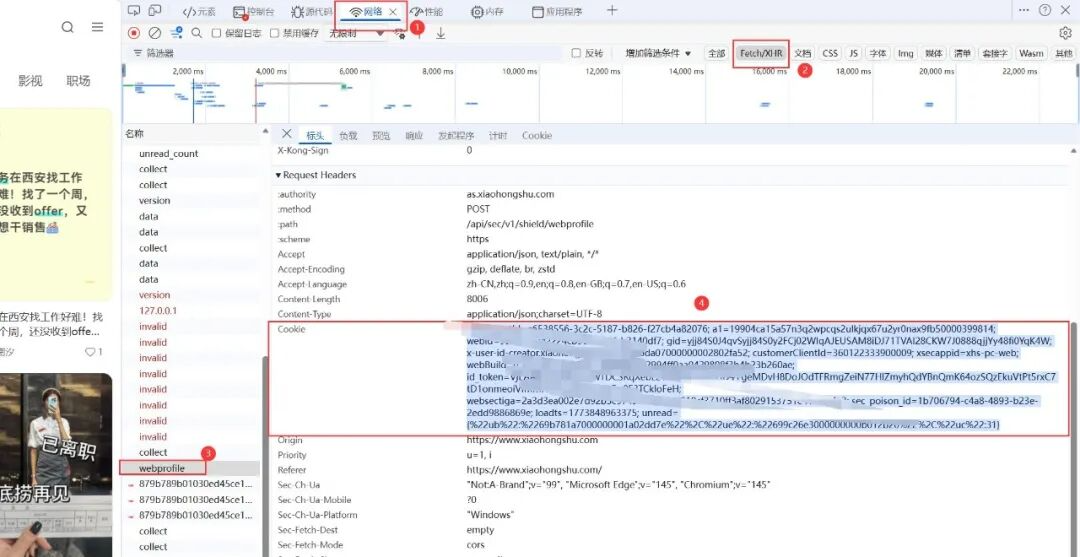
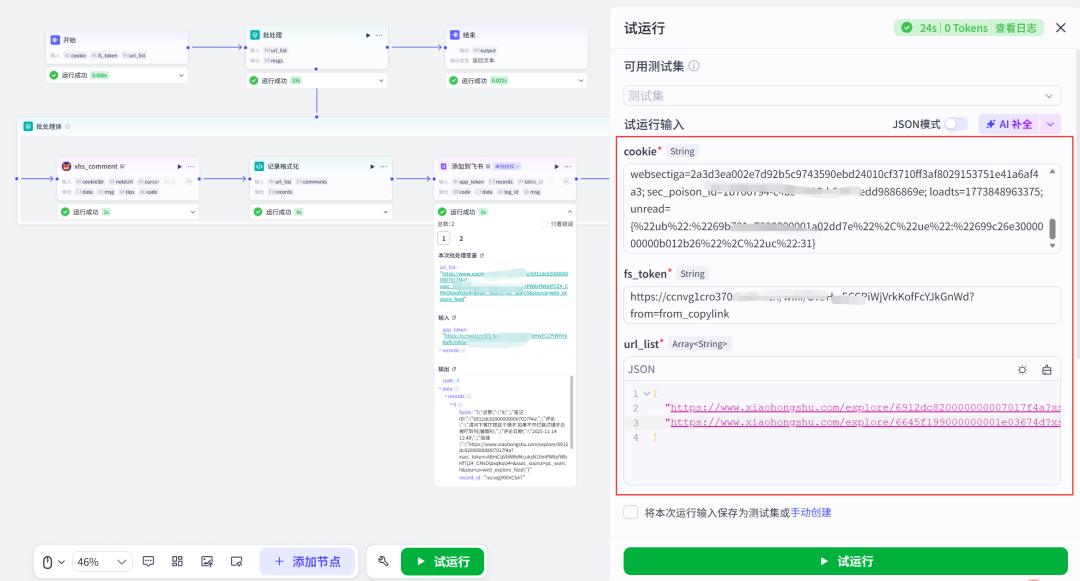
(4)切换到扣子工作流页面,输入参数,点击试运行;
cookie:从第(3)步获取;
fs_token:从第(2)步获取;
url_list:可以输入多条笔记链接,用逗号分隔开;
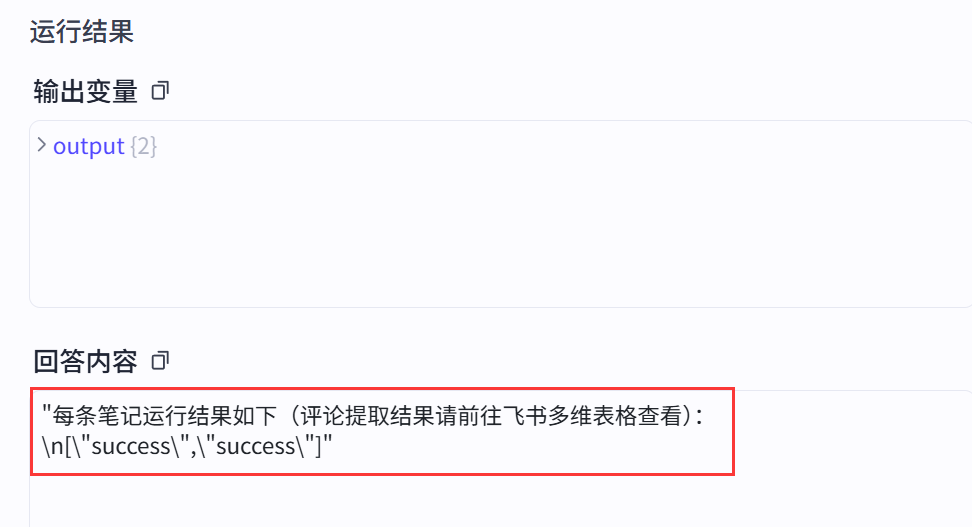
(5)运行成功后,看下输出结果都是success,那么去飞书多维表格就可以看到提取到的评论了;