上一篇《Harness 到底指什么》把 harness 的边界说清楚了------平台层,负责上下文管理、记忆、subagent 编排、工具调用、hook、运行闭环,业务工程建在它之上,不应去改它。这篇往下走一层:harness 自身怎么扩展?
具体说三件事:skill 该写什么、配置目录放什么、hook 怎么挂。CC 和 Codex 都提供了这三块能力,很多人以为某个能力是某家独有,其实两边都有对应物。真正的差异不在"谁有谁没有",而在面对同一个扩展问题,两家工程上的解法走了不同的路。
一、Skill ------ 该写什么、怎么加载触发

解决什么问题
LLM 的默认行为是通用的。但你在具体项目里工作,积累了大量可复用的工作流:特定领域的代码审查标准、某个框架的最佳实践、固定的提交信息格式、每次都要检查的 checklist。
这些内容有三种常见的处理方式:每次手敲进去(重复劳动)、放进系统 prompt(全局污染,所有对话都带着)、写成 shell 脚本包一层(脱离 agent 上下文)。Skill 是第四种解法:把可复用的工作流、资源、专业知识打包成自包含单元,在合适的时机自动或手动加载,其余时间不干扰对话。
Codex 怎么做
Codex 的 skill 是一个自包含文件夹,提供 specialized workflows、tool integrations、domain expertise 和 bundled resources(来自 codex-rs/skills/src/assets/samples/skill-creator/SKILL.md)。
每个 skill 的入口是 SKILL.md,frontmatter 有三个字段:
yaml
name: my-skill # 必须,也是调用时的标识符
description: | # 必须,内容是"何时该用这个 skill"
This skill should be used when...
metadata:
short-description: 一行摘要 # 可选,用于展示列表description 字段的写法决定了触发质量。它的语义是"在什么情况下调用我",而不是"我能做什么"------前者是触发条件,后者是能力描述,agent 用前者来匹配场景,写错了触发率会很低。
系统内置 skill 用 include_dir! 宏编译进二进制(skills/src/lib.rs:10),启动时安装到 $CODEX_HOME/skills/.system(:24)。为了避免每次启动都重装,用 fingerprint marker 文件做判断------如果嵌入内容的哈希没变,就跳过安装(:32)。这是分发稳定性的保障,让系统 skill 的行为在升级前后保持一致。
用户自定义 skill 放 $CODEX_HOME/skills/,无需额外注册,重启后生效。
CC 怎么做
CC 的 skill 放在 .claude/skills/<name>/SKILL.md,frontmatter 有三个字段:name、description、disallowed-tools。
触发方式有两种:用户显式调用 /skill-name,或 Claude 根据对话上下文自动判断调用。第二种方式完全依赖 description 的描述质量------写得越清楚,自动触发越准确。
除了本地 skill,CC 有 plugin skill 机制:通过 plugin 市场安装,用 /plugin 管理。会话内可以用 /reload-skills 重新扫描(v2.1.152 支持),或在 SessionStart hook 里带 reloadSkills 参数触发重扫。
disallowed-tools 是 CC 这边独有的字段:可以在 skill 级别关掉某些工具。比如一个"代码审查" skill 只需要读文件,不需要写文件,在 disallowed-tools 里把写文件工具关掉,这个 skill 运行期间就不会触发写操作,减少误操作风险。
对比
| 维度 | Codex | CC |
|---|---|---|
| 存放位置 | $CODEX_HOME/skills/ |
.claude/skills/<name>/ |
| frontmatter 字段 | name / description / metadata.short-description | name / description / disallowed-tools |
| 触发方式 | 上下文自动触发 | 显式 /skill-name + 上下文自动触发 |
| 工具级收口 | 无专用字段 | disallowed-tools |
| 内置 skill | 编译进二进制,fingerprint 重装优化 | plugin 市场 |
| 热重载 | 随文件系统更新 | /reload-skills 或 SessionStart hook |
实操建议
写 skill 最容易踩的坑是 description 写成能力介绍,而不是调用条件。举个反例:
能力介绍写法:"This skill provides Python code review capabilities, including style checking and performance analysis."
触发率很低,因为 agent 看到的是"我有这个能力",不知道什么时候该调。
改成条件触发写法:
"This skill should be used when reviewing Python code, checking for style issues, or analyzing performance bottlenecks in Python files."
其余几点:
- CC 的
disallowed-tools要用好:给每个 skill 明确限制工具范围,避免 skill 之间相互干扰 - 系统内置 skill 是维护负担,Codex 把它们编进二进制是为了分发一致性,自己日常用的直接放用户目录即可
- 本地 skill 提交到仓库,团队共享------skill 本身就是可复用的工作流资产,不应该只活在个人机器上
二、配置目录 ------ .codex vs .claude,放什么
解决什么问题
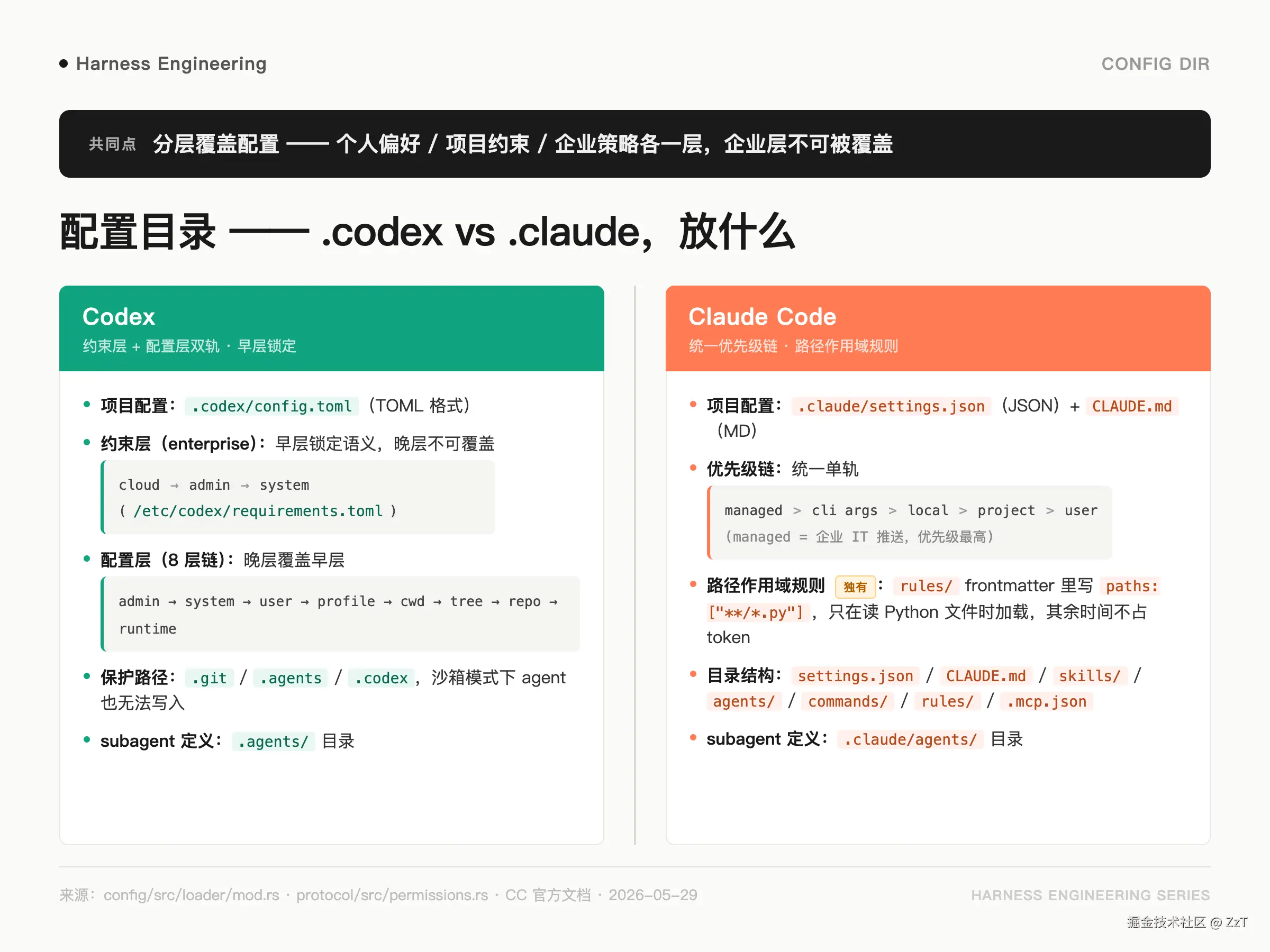
Agent 的行为需要配置:用什么模型、允许哪些工具、项目级的代码规范约束、企业级的安全边界。这里有一个天然的冲突:个人偏好、项目约束、企业策略三者的配置权力不一样,不能全部放在一个文件里用"后者覆盖前者"简单处理------企业的安全边界不应该被项目配置文件覆盖掉。
配置目录的核心设计问题是:谁的配置可以覆盖谁的配置,在哪里锁死。
Codex 怎么做
Codex 的项目级配置是 .codex/config.toml,格式是 TOML。分层加载顺序在 config/src/loader/mod.rs:79-100 有完整注释,分两套逻辑:
约束层(constraint,用于企业/安全策略):
javascript
cloud → admin → system (/etc/codex/requirements.toml)这一层用"早层锁定"语义:a constraint defined in an earlier layer cannot be overridden by a later layer(原文)。系统管理员在 /etc/codex/requirements.toml 写的约束,项目层无法覆盖,用户层也无法覆盖。
配置层(普通配置,晚层覆盖早层):
arduino
admin → system (/etc/codex/config.toml)
→ user ($CODEX_HOME/config.toml)
→ profile ($CODEX_HOME/<name>.config.toml)
→ cwd (./config.toml)
→ tree (./.codex/config.toml,逐级往上找)
→ repo (git root/.codex/config.toml)
→ runtime (--config 参数等)项目根的判断由 project_root_markers 决定,默认是 .git。配置文件越靠近项目根,优先级越高(runtime 最高)。
保护路径是另一个硬约束:PROTECTED_METADATA_PATH_NAMES = [".git", ".agents", ".codex"](protocol/src/permissions.rs:27)。即使在 danger-full-access 沙箱模式下,agent 也无法写入这三个目录。这是系统级保护,不是可选配置。
.agents/ 放 subagent 定义;.codex/hooks.toml 放 hook 配置(下一节展开)。
CC 怎么做
CC 的配置目录是 .claude/,包含:
settings.json:JSON 格式,agent 行为配置CLAUDE.md:Markdown,系统 prompt 和上下文说明skills/:本地 skill 目录agents/:子 agent 定义commands/:自定义斜杠命令rules/:按路径作用域加载的规则文件.mcp.json:MCP 工具配置
优先级从高到低:managed(企业 IT 推送)> 命令行参数 > local > project(.claude/)> user(~/.claude/)。其中 managed settings 是企业层强制策略,优先级最高,项目层无法覆盖。
rules/ 有一个值得单独说的特性:支持 frontmatter 里的 paths: 字段做路径作用域。比如 rules/python-style.md 里写 paths: ["**/*.py"],这条规则只在 Claude 读取 Python 文件时才被加进上下文,其余时间不占 token。在大仓库里,这个特性能明显降低无关规则的 token 消耗。
对比
| 维度 | Codex | CC |
|---|---|---|
| 项目配置文件 | .codex/config.toml(TOML) |
.claude/settings.json(JSON)+ CLAUDE.md(MD) |
| 企业强制策略 | requirements.toml,约束层锁定,晚层不可覆盖 | managed settings,优先级最高 |
| 分层逻辑 | 约束层(锁定)+ 配置层(覆盖)两套独立逻辑 | 统一优先级链,managed 最高 |
| 保护路径 | .git / .agents / .codex,沙箱也不可写 |
无类似机制 |
| 路径作用域规则 | 无 | rules/ frontmatter paths: 字段 |
| subagent 定义 | .agents/ |
.claude/agents/ |
两家在"企业策略不可被覆盖"这件事上的方向一致,但实现不同:Codex 把约束层和配置层的合并逻辑分开写,约束层在代码里有明确的"早层锁定"语义;CC 靠优先级链,managed 最高优先级来保证。
实操建议
分层的核心价值是让配置归属清晰:
- 个人偏好(用哪个模型、什么风格)放用户层(
~/.codex/config.toml或~/.claude/settings.json),不要提交到仓库 - 项目约束(工具权限范围、代码规范说明)放项目层,提交到仓库,让团队成员共享同一套约束
- 企业安全边界(禁止调用某些工具、网络访问限制)用管理层,不要试图用项目层覆盖
- CC 的
rules/路径作用域要充分利用:与其把所有规则堆在一个大 CLAUDE.md 里,不如按语言或目录拆开,每次只加载相关的
三、Hook ------ 事件、类型、信任
解决什么问题
Agent 在执行过程中有很多关键节点:工具调用前后、会话开始结束、用户提交 prompt 时、上下文压缩时、子 agent 启动停止时。在这些节点插入自定义逻辑,能做的事很多:
- 在写文件前做一次确认
- 在工具调用后记录审计日志
- 在会话结束时做完成度检查
- 在权限申请时自动决策
两家都用事件驱动的生命周期模型,但挂载配置、处理器类型、信任机制各有差异。
Codex 怎么做
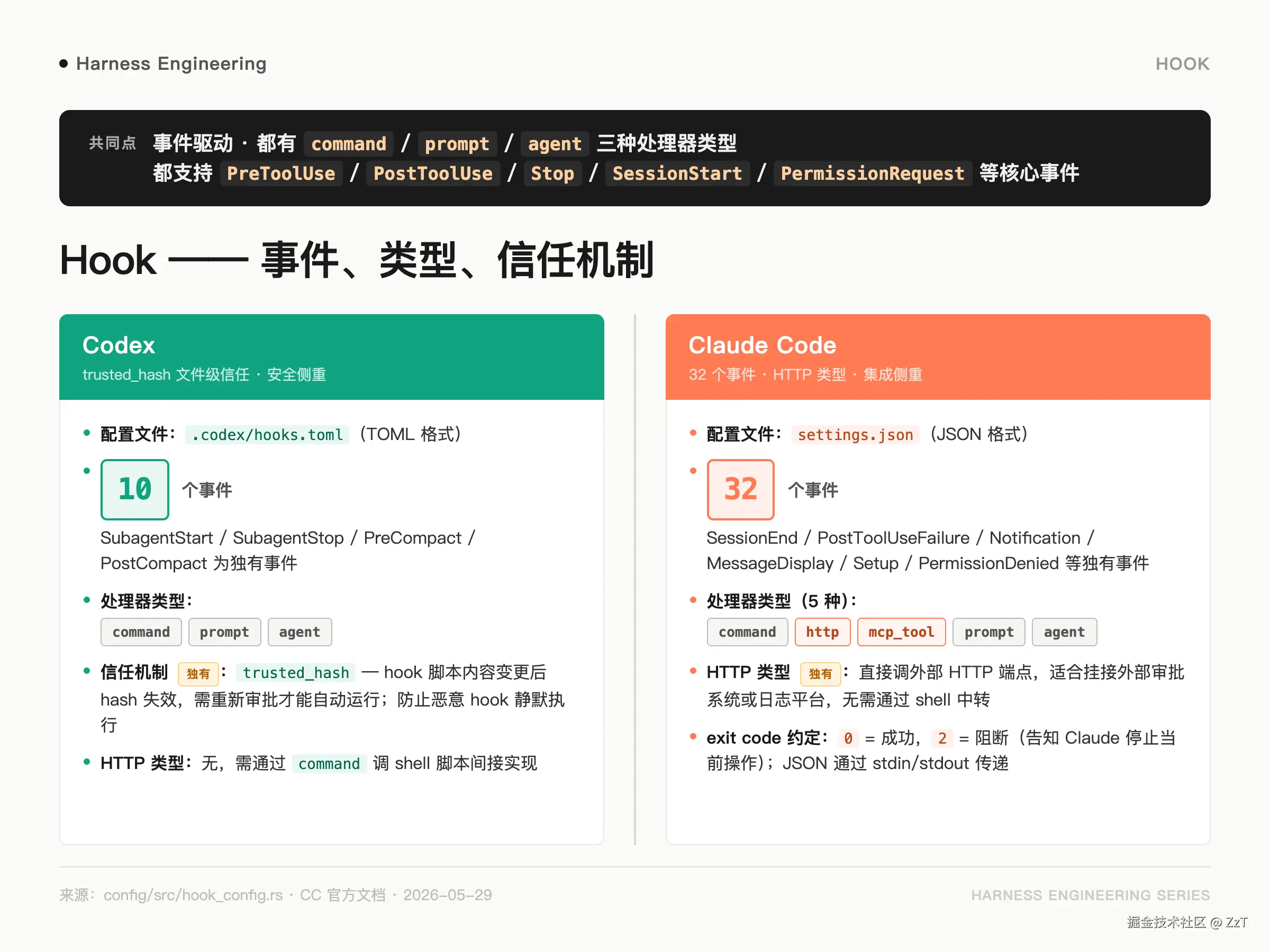
Codex 的 hook 配置在 .codex/hooks.toml(TOML 格式)。
完整事件列表(来自 config/src/hook_config.rs,共 10 个):
vbnet
PreToolUse 工具调用前
PostToolUse 工具调用后
PermissionRequest 权限申请时
PreCompact 上下文压缩前
PostCompact 上下文压缩后
SessionStart 会话启动
UserPromptSubmit 用户提交 prompt
SubagentStart 子 agent 启动
SubagentStop 子 agent 停止
Stop agent 停止处理器类型(HookHandlerConfig enum,hook_config.rs:137-156):
rust
enum HookHandlerConfig {
command { command, commandWindows, timeout, async, statusMessage },
prompt {},
agent {},
}三种类型------command(shell 命令)、prompt(LLM 评估)、agent(子 agent 验证)。
信任机制通过 HookStateToml 里的 trusted_hash: Option<String> 字段实现(hook_config.rs:29)。每个 hook 需要在 state 段里声明 hash,只有 hash 与当前文件内容匹配,hook 才会自动运行;不匹配时需要用户审批。
toml
[state.my-audit-hook]
trusted_hash = "sha256:abc123"
[hooks.PostToolUse]
[[hooks.PostToolUse]]
matcher = "write_file"
[[hooks.PostToolUse.hooks]]
type = "command"
command = "echo 'file written' >> /tmp/audit.log"trusted_hash 的设计动机是防御恶意 hook:在多人共享的仓库里,如果 .codex/hooks.toml 被篡改,hash 失效,hook 就不会静默执行,而是触发审批------把 hook 自身作为一个潜在的攻击面对待。
CC 怎么做
CC 的 hook 配置在 settings.json 里。官方文档列出 32 个事件,包括:SessionStart / SessionEnd / UserPromptSubmit / PreToolUse / PostToolUse / PostToolUseFailure / Stop / PermissionRequest / Notification / MessageDisplay 等。
处理器类型:command(shell)/ http(HTTP 请求)/ mcp_tool(MCP 工具)/ prompt(LLM 评估)/ agent(子 agent 验证)。
几个执行约定值得记:
matcher字段支持正则,匹配工具名或事件内容- exit code 0 = 成功,2 = 阻断(告知 Claude 停止当前操作)
- JSON 通过 stdin/stdout 传递上下文和结果
prompt 类型的实际用法:可以在 Stop hook 里写一个 prompt,让小模型判断"任务是否真正完成",如果没有则返回非 0,让 Claude 继续。这把 hook 的角色从"监听+拦截"扩展到了"监听+判断+回控",相当于在 agent loop 末尾加了一层自动 QA。
http 类型是 CC 独有的:直接调 HTTP 端点,不需要通过 shell 脚本间接实现。适合把 hook 挂到外部审批系统或日志平台。
对比
| 维度 | Codex | CC |
|---|---|---|
| 配置文件 | .codex/hooks.toml(TOML) |
settings.json(JSON) |
| 事件总数 | 10 个 | 32 个 |
| 处理器类型 | command / prompt / agent | command / http / mcp_tool / prompt / agent |
| 独有事件 | SubagentStart / SubagentStop / PreCompact / PostCompact | SessionEnd / PostToolUseFailure / Notification / MessageDisplay / Setup / PermissionDenied 等 |
| 信任机制 | trusted_hash:hash 匹配才自动执行 |
依赖文件系统权限 |
| HTTP 类型 | 无(需通过 command 间接实现) | 有,直接调 HTTP 端点 |
两家都有 prompt 和 agent 类型的 hook,这点和很多人的印象不一样------源码里 HookHandlerConfig enum 明确有这两个 variant。差异主要在:Codex 有 trusted_hash 的文件级信任机制(安全侧重),CC 多了 HTTP 类型和更多事件节点(集成侧重)。
实操建议
从使用频率来说,几个最常用的组合:
PreToolUse+matcher匹配危险工具 +command类型:在rm -rf、git push --force前插一条日志或确认PostToolUse+command:把工具调用记录写到审计文件,供事后复查Stop+prompt类型:让 LLM 判断"本次任务目标是否达成",没达成就返回 exit code 2,触发 Claude 继续- Codex 用户注意
trusted_hash的维护:每次修改 hook 脚本后,hash 会失效,需要重新信任。这是预期行为,不是 bug,但如果频繁改 hook,要把更新 hash 纳入工作流
小结
三块扩展能力,两边的设计方向可以各用一句话概括:
Codex:在构建期锁定(系统 skill 编译进二进制)、在运行期验证(trusted_hash),约束层早层锁定不可被覆盖------安全边界优先,把约束往前移。
CC:以文件系统为中心,路径作用域规则、plugin 市场、HTTP hook 把扩展点做得更灵活------可组合性优先,把灵活度往外延。
两家都没有"哪个能力是我独有的"。真正的分歧是对同一个扩展需求的工程态度:Codex 更倾向相信"约束越早确定越安全",CC 更倾向相信"组合越灵活越有用"。
使用哪套 harness、用哪种扩展方式,最终取决于你的场景------团队规模、安全要求、和外部系统的集成深度。两套哲学没有对错,只有适不适合。
Harness Engineering 系列
这个系列围绕 coding agent 的「平台层(harness)与业务工程」,逐篇拆解:
- Harness 到底指什么 ------ 平台层与业务工程的边界
- 复杂任务的 Spec 怎么写 ------ 多 Agent、编排者入口、rules / docs / skills 组织
- Harness 怎么扩展:skill、配置目录与 hook ------ 本篇
- Harness 怎么管住 agent:权限与 effort ------ 待更
- Harness 怎么扛住长任务:compact、memory、goal ------ 待更
本系列持续更新,欢迎关注我的掘金。