具身智能、机器人、智能驾驶研发主线:世界模型与VLA技术深度调研
执行摘要
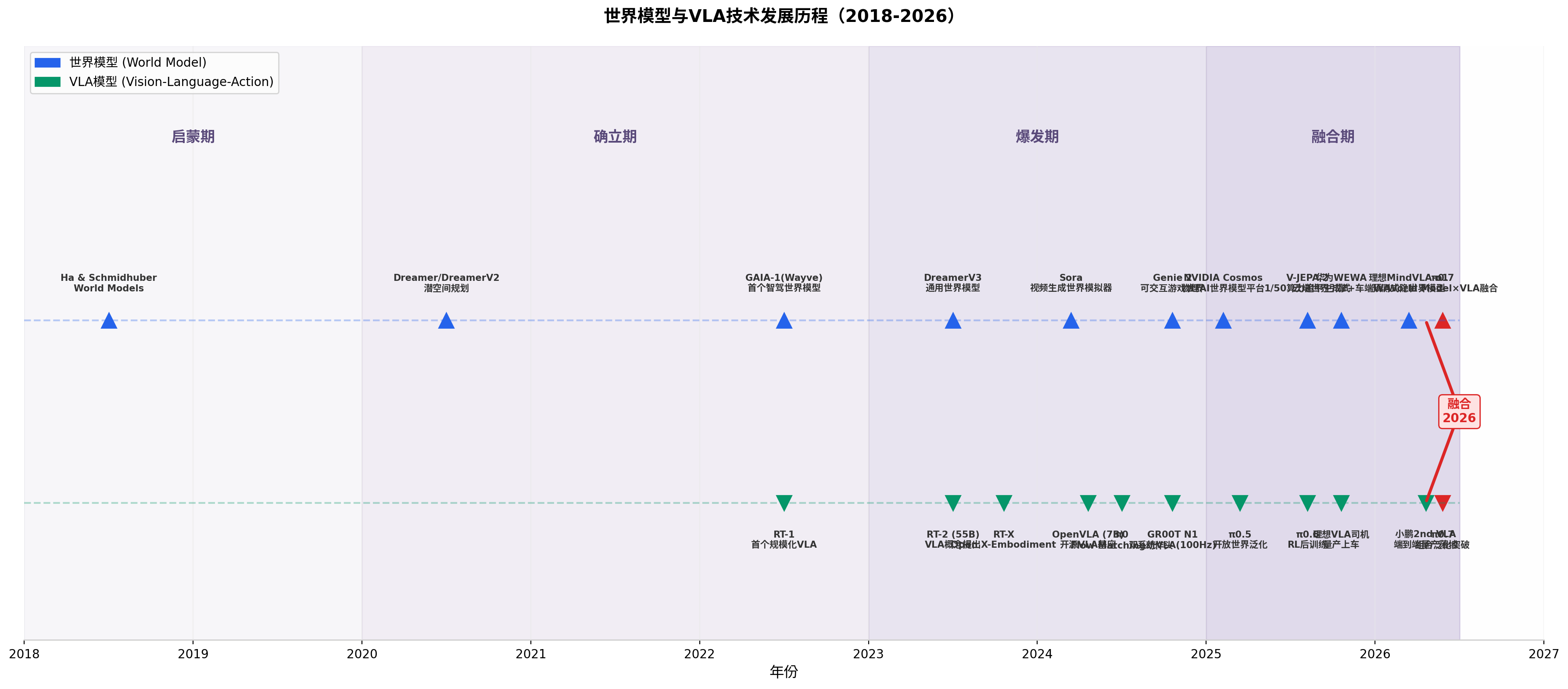
世界模型(World Model)与视觉-语言-动作模型(Vision-Language-Action, VLA)是当前具身智能和智能驾驶两大核心研发主线的技术底座。自2018年Ha与Schmidhuber提出World Models以来,这两条技术路线经历了近八年的独立演进,在2026年迎来历史性融合节点 。Physical Intelligence发布的π0.7 首次在机器人领域实证了"组合泛化"(Compositional Generalization),将世界模型作为Subgoal Image Provider深度集成到VLA架构中,被称为机器人领域的"GPT-3时刻"。在智能驾驶领域,小鹏第二代VLA (2026年3月量产落地)、理想MindVLA-o1 (2026年3月发布)、华为ADS 4.0 WEWA架构等方案同步推进VLA+世界模型的融合落地。
核心技术判断 :未来1-2年,行业将经历"VLA规模化量产 → 世界模型融合 → L3/L4场景落地"的三阶段演进。一段式端到端+VLA+世界模型+强化学习的融合架构已成为头部玩家的共识路线。技术团队应重点关注:(1) 端到端VLA的端侧部署优化 ;(2) 世界模型与VLA的轻量化融合方案 ;(3) 数据闭环与强化学习基础设施。
1. 世界模型(World Model):从"视频预测"到"物理推理"
1.1 发展历程:八年四阶段演进
世界模型的概念最早可追溯至控制论和认知科学中的"心智模型"(Mental Model),指智能体对外部环境及其演化规律的内部表征。在深度学习领域,2018年Ha与Schmidhuber发表的《World Models》标志着这一概念首次被系统性地引入神经网络架构 。该论文构建了一个三部分架构:VAE负责将视觉输入压缩为潜在空间表示,RNN学习潜在状态的时间演化规律,Controller基于潜在表示进行行动决策。这一架构的核心洞察是------AI可以在"梦境"中模拟并优化策略,使训练效率提升数十倍 ,奠定了世界模型"预测未来以指导当下行动"的基本范式。 (腾讯云)
DeepMind随后推出的Dreamer系列(2020-2023)将这一思路推向新的高度。DreamerV2在100个Atari游戏上表现接近真实强化学习模型,但交互样本量仅为原来的1/10,其核心创新在于在潜在空间中进行"想象训练"(imagination-based learning),通过可微分动态模型反向传播策略梯度。DreamerV3(2023)进一步完善了泛化与稳定性,被业界誉为"当前最强的世界模型架构"之一 。 (腾讯云) 与此同时,Wayve在2023年推出了GAIA-1------首个面向自动驾驶的生成式世界模型 ,标志着世界模型从游戏环境走向真实世界应用。 (算力自由)
2024-2025年是世界模型的"爆发期"。OpenAI的Sora(2024年2月)首次展示了长视频生成的震撼效果,OpenAI明确将其定位为"世界模拟器",尽管缺乏交互性和动作条件化。 (算力自由) Google DeepMind的Genie 2(2024年12月)实现了从单张图片生成可交互的2D游戏环境,支持键盘/鼠标输入作为动作条件,标志着世界模型从"被动观看"转向"主动交互"。NVIDIA在2025年1月发布的Cosmos 则是首个专为物理AI设计的世界模型平台,整合了扩散模型和自回归模型两种架构。 (算力自由) 2025年6月,Meta发布的V-JEPA 2 以1/50的算力 追平了生成式世界模型的性能,展示了JEPA(Joint Embedding Predictive Architecture)路线的惊人效率。 (算力自由)
2026年进入"融合期",世界模型与具身智能、智能驾驶进入深度整合阶段。标志性事件包括:π0.7 (2026年4月)首次将世界模型作为Subgoal Image Provider集成到VLA中;DeepMind Gemini Robotics ER 1.6 引入推理优先的世界模型增强空间理解;3个月内发表了21篇 WM-VLA融合论文(WoVR、VLAW、Chain of World、LaST-VLA等)。 (算力自由)
1.2 核心技术架构:两大流派的深层对决
当前世界模型的技术路线可分为生成式 与**预测式(JEPA)**两大流派,二者在目标空间、计算效率和物理理解深度上存在本质差异。 (arXiv.org)
生成式世界模型 以像素空间为预测目标,核心思路是"生成未来以理解世界"。代表模型包括Sora、NVIDIA Cosmos、Genie系列等。这类模型基于Transformer或扩散模型架构,通过海量视频数据训练学习物理世界的视觉规律。生成式模型的优势在于输出直观可解释 ------生成的未来画面可以直接被人眼验证,但其计算开销巨大,因为需要在高维像素空间(百万维)中精确建模每个细节,大量计算浪费在纹理、光照等与决策无关的信息上。 (算力自由)
预测式世界模型(JEPA路线)由Yann LeCun力推,核心理念是"不要重建像素,预测抽象表征" 。V-JEPA 2(Meta, 2025.06)是这一路线的代表:Vision Encoder将视频帧编码为潜在表征,Context Encoder编码上下文窗口,JEPA Predictor在潜在空间预测被mask的未来块。由于目标空间仅为数百维的潜在向量,JEPA以1/50的算力 追平了生成式方法在动作识别、因果推理、长时规划任务上的性能,后训练仅需少于62小时 的机器人交互数据。 (算力自由)
| 维度 | 生成式世界模型 | 预测式世界模型(JEPA) |
|---|---|---|
| 目标空间 | 像素空间(百万维) | 潜在空间(数百维) |
| 代表模型 | Sora, Cosmos, Genie | V-JEPA 2, Causal-JEPA |
| 计算效率 | 低(大量浪费在纹理/光照) | 高(集中在因果相关特征) |
| 可解释性 | 高(生成画面可直接验证) | 低(潜在表征难以直观理解) |
| 物理理解 | 通过像素重建隐式学习 | 通过表征预测显式编码动力学 |
| 训练数据需求 | 海量视频数据 | 较少数据(+自监督预训练) |
| 交互性 | 较弱(单向生成) | 强(支持动作条件预测) |
2026年初Meta发布的Causal-JEPA 尝试弥合两大流派的分歧,在对象级别而非像素级别操作,支持潜在干预(回答反事实问题)和因果图学习,被业界认为"最接近LeCun真正世界模型设想的方案"。 (算力自由)
1.3 世界模型在智能驾驶中的应用形态
在智能驾驶领域,世界模型的应用形态经历了从"仿真数据生成"到"车端实时推理"的演进。华为乾崑ADS 4.0的WEWA架构 (World Engine & World Behavior Architecture)是这一演进的典型代表:**云端世界引擎(WE)**利用扩散生成模型生成密度是真实世界1000倍的高密度难例场景,**车端世界行为模型(WA)**通过全模态感知实现实时推理与拟人化决策。 (21经济网) 这一架构实现了"从人教AI到AI教AI"的范式转变,端到端时延降低50%,通行效率提升20%,重刹率降低30%。 (小牛行研)
商汤绝影的**"开悟"世界模型则专注于可控场景生成,能够理解真实世界中的"物理法则"和"交通规则",实现元素级别的场景编辑和重构,感知结果接近真实精标数据98%。 (亿欧) 理想汽车的MindVLA-o1引入了 预测式隐世界模型**,在Latent Space中完成未来状态推演,训练分为三阶段:海量视频预训练Latent World Token、MindVLA-o1框架内持续世界模型推演、世界模型与驾驶行为联合对齐。 (维科号)
2. VLA模型:具身智能的"端到端"革命
2.1 概念提出与三代架构演进
Vision-Language-Action(VLA)模型的核心思想是将预训练的视觉-语言模型(VLM)的能力迁移到机器人控制领域,实现"看-懂-做"的端到端闭环。Google DeepMind于2023年提出的RT-2是VLA概念的奠基之作 ------基于PaLI-X(55B参数)视觉语言模型,将机器人动作离散化为256-bin的token,与视觉和语言token在同一自回归框架下联合训练。 (Silicon Valley Robotics Center) RT-2展示了涌现能力(Emergent Capabilities):能够遵循涉及训练时未见过的概念指令(如"把物体移到Taylor Swift专辑旁边"),在新语义概念上的成功率达到62% ,远超RT-1的32%。 (Silicon Valley Robotics Center)
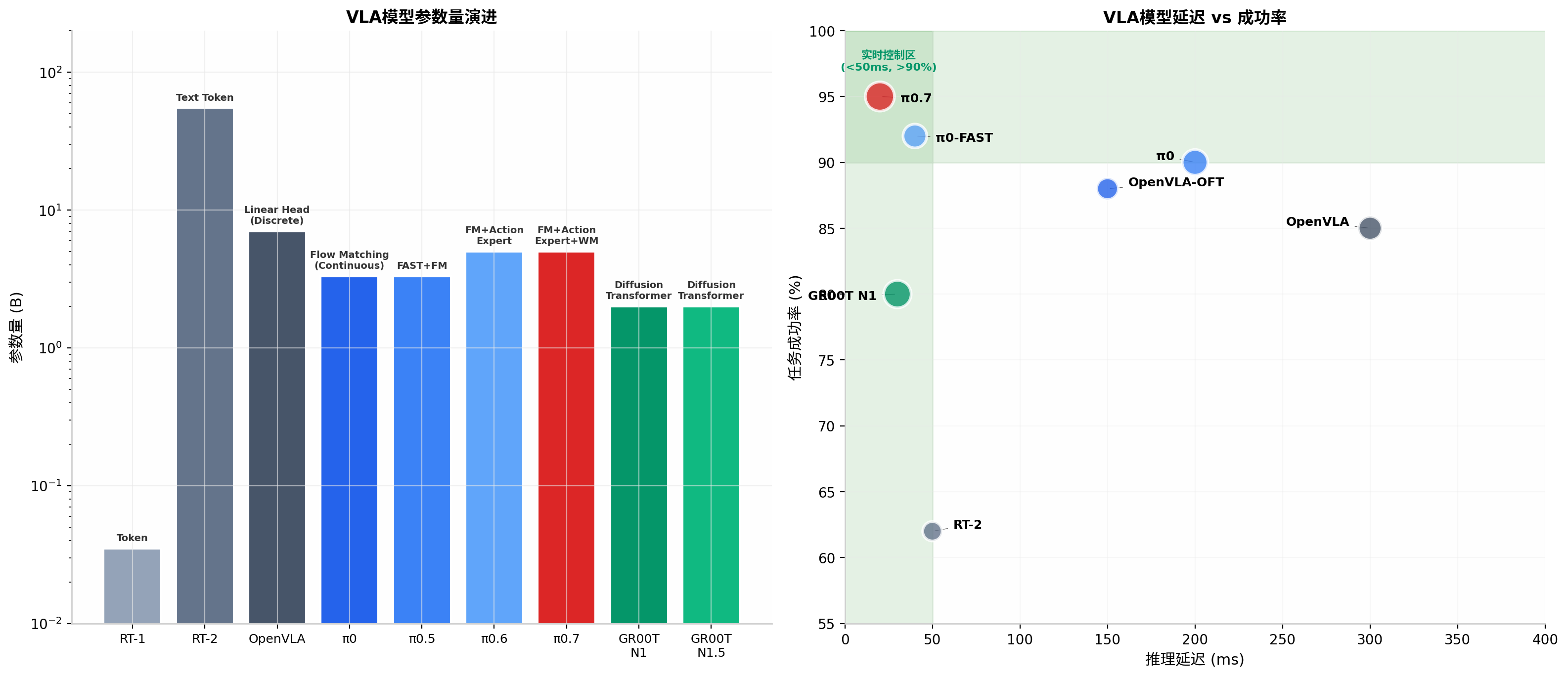
RT-2之后,VLA架构经历了三代关键演进 。 (Github) **第一代(2022-2023)**以RT-1/RT-2为代表,采用离散动作token的自回归生成方式,核心贡献是验证了"VLM可以直接控制机器人"的可行性,但存在控制精度不高、生成速度慢(1-3Hz)的局限。**第二代(2024-2025)**以OpenVLA、π0为代表,引入连续动作表示------OpenVLA采用线性头输出离散动作,π0则开创性地使用Flow Matching生成连续动作chunk,将推理速度提升至50Hz。**第三代(2025-2026)**进入基础模型竞赛阶段,关键特征包括双系统架构(快慢分离)、跨形态泛化(一个模型控制多种机器人)、强化学习后训练(超越模仿学习的天花板)。 (Github)
| 代际 | 时间 | 代表模型 | Action Head | 核心突破 | 推理速度 |
|---|---|---|---|---|---|
| 第一代 | 2022-2023 | RT-1, RT-2 | 离散Token (256-bin) | VLA概念提出,涌现语义能力 | 1-3 Hz |
| 第二代 | 2024-2025 | OpenVLA, π0, Octo | 连续表示(Flow Matching/Diffusion) | 连续动作生成,多机器人支持 | 25-50 Hz |
| 第三代 | 2025-2026 | π0.6, π0.7, GR00T N1.5 | FM+Action Expert (+World Model) | RL后训练,组合泛化,跨本体 | 50-100 Hz |
2.2 关键模型技术架构深度解析
**OpenVLA(Stanford/Berkeley, 2024)**是首个完全开源的7B参数VLA基础模型,基于Prismatic VLM骨干(Llama-2 7B + SigLIP + DinoV2视觉编码器),在Open X-Embodiment数据集(约970K条轨迹)上训练。 (Silicon Valley Robotics Center) 其双视觉编码器设计(SigLIP用于语义特征、DinoV2用于空间特征)为模型提供了比单编码器更强的视觉grounding能力。OpenVLA在LIBERO基准上fine-tuned后达到85-95%成功率,且仅需100-200条演示即可fine-tune新任务。 (Silicon Valley Robotics Center) OpenVLA的开源生态使其成为学术界和工业界最广泛使用的VLA基线,但7.5B参数导致推理延迟约300ms(consumer GPU),离散token的方式也产生动作不平滑的缺点。
**π0系列(Physical Intelligence, 2024-2026)**代表了VLA架构的最前沿演进。π0采用Flow Matching动作头,通过迭代去噪将噪声样本转换为有效动作轨迹,产生最平滑的连续轨迹且支持多模态动作分布(同一任务有多种可行解)。π0.5引入FAST(Frequency-space Action Tokenization)预训练+Flow Matching推理的混合方案,统一了语义规划和电机控制。π0.6将参数扩展至5B(VLM 4.4B + Action Expert 860M),引入专门的Action Expert模块解决大模型"手笨"问题,并首次加入RL后训练(Recap RL)。 (Github)
2026年4月发布的π0.7是VLA领域的里程碑突破 ------首次在机器人领域实证了"组合泛化"(Compositional Generalization)。 (智源社区) π0.7的架构分为三块:4B参数的Gemma3 VLM骨干 负责理解视觉和语言;860M参数的Action Expert 使用Flow Matching生成连续动作chunk,支持50Hz高频控制;从14B BAGEL图像生成模型初始化的World Model 负责将任务指令翻译成成功帧的次目标图像。 (智源社区) 在推理中,模型输入包括4路摄像头、6帧历史画面、关节状态、任务指令和world model实时生成的次目标图像,输出50步的action chunk。π0.7能够在从未训练过的任务中(如用空气炸锅烤红薯)组合已掌握的原子技能完成新任务,展示了**"从动作模仿到条件化行为生成"的范式转变**。 (firecat-web.com)
GR00T N1/N1.5(NVIDIA, 2025)是首款开源、可定制的人形机器人基础模型,采用独特的双系统架构 :System 1(快速反应)使用Diffusion Transformer生成高频动作,System 2(慢速推理)使用VLM进行高层规划。 (zhichai.net) N1.5在架构上进行了关键优化:彻底冻结VLM以保留预训练知识、简化视觉编码器到语言模型的Adapter、引入FLARE训练目标、结合DreamGen合成轨迹生成。 (yanghong.dev) GR00T N1支持100Hz动作生成,在HumanoidBench上展示了 competitive performance,其开源属性(Apache 2.0许可)使其成为人形机器人研发的重要基座。
| 模型 | 机构 | 参数 | 骨干网络 | Action Head | 开源 | 核心特色 |
|---|---|---|---|---|---|---|
| RT-2 | Google DeepMind | 55B | PaLI-X | 离散Token | 否 | VLA概念奠基,涌现语义能力 |
| OpenVLA | Stanford/Berkeley | 7B | Prismatic VLM (Llama2+SigLIP+DinoV2) | 线性头(离散) | 是 | 首个开源VLA,最强开源基线 |
| π0 | Physical Intelligence | 3.3B | PaliGemma | Flow Matching | 部分 | 首个FM VLA,最平滑动作 |
| π0.7 | Physical Intelligence | 5B | Gemma3 + BAGEL-WM | FM + Action Expert + WM | 否 | 组合泛化,世界模型融合 |
| GR00T N1.5 | NVIDIA | ~2B | 自定义VLM | Diffusion Transformer | 是 | 双系统100Hz,人形专用 |
| RDT-1B | 清华/港大 | 1B | Diffusion Transformer | Diffusion Transformer | 是 | 首个1B扩散策略,双臂操作 |
2.3 Action Head:决定VLA性能的关键分野
Action Head是VLA模型中将视觉-语言表征转换为机器人动作的核心模块,其设计选择直接决定了模型的控制精度、推理速度和泛化能力。当前主流技术路线包括四种: (Silicon Valley Robotics Center)
**离散Token(RT-2/OpenVLA早期)**将连续动作空间量化为256个bin,作为语言模型的token自回归生成。优点是实现简单,可直接利用VLM的next-token prediction能力;缺点是量化误差大,动作不平滑,推理速度受限(1-3Hz)。
**Flow Matching(π0系列)**通过迭代去噪生成连续动作轨迹,将随机噪声样本沿学习到的速度场转化为有效动作。优点是生成最平滑的连续轨迹,天然支持多模态动作分布(同一任务多个可行解);缺点是需要10-20步去噪迭代,增加了推理延迟。 (Silicon Valley Robotics Center)
**Diffusion(Octo/GR00T)**使用DDPM风格的扩散过程生成动作,与Flow Matching类似但使用不同的数学框架。优点是动作多样性好,抗干扰能力强;缺点是推理速度较慢,需要多步采样。 (arXiv.org)
**Chunked Prediction(ACT/SmolVLA)**一次预测10-50步的未来动作序列。优点是轨迹平滑、推理高效(一次生成多步);缺点是开放性差,对复杂任务的长程规划能力有限。 (Silicon Valley Robotics Center)
从工程实践看,Flow Matching正在成为VLA动作生成的首选范式 。π0.7通过RTC(Real-time action chunking)技术将Flow Matching与动作分块结合,实现了50Hz的高频控制。NVIDIA的Cosmos Policy和银河通用的LDA-1B也采用了Flow Matching范式。 (成都理工大学)
3. 智能驾驶:端到端VLA路线的量产竞赛
3.1 特斯拉:端到端范式的开创与演进
特斯拉的FSD演进路线为全球智驾行业提供了最重要的技术参照。FSD V12(2023年11月)是端到端自动驾驶的里程碑 ------将城市街道驾驶挑战升级为单个端到端神经网络,经过数百万个视频clip训练,取代了30多万行明确的C++代码。 (dfcfw.com) V12的核心创新在于证明了"纯视觉+端到端"路线的可行性,行驶逻辑更加拟人化。V13(2024年11月)实现了端到端升级,包括36Hz全分辨率AI视频输入、原生AI输入和神经网络架构优化。V14(2025年10月)则通过千亿参数模型统一了Robotaxi与量产车架构 ,C++代码精简至2000多行,拥有"修复95%犹豫变道和刹车问题"的成熟表现。 (dfcfw.com)
特斯拉的技术路线对中国的智驾发展产生了深远影响。何小鹏在体验了特斯拉FSD V14后表示,"已从特斯拉FSD V14和第二代VLA上感受到从L2到L4的明确路径"。 (什么值得买) 特斯拉的端到端方案证明了一套技术架构可以同时支撑L2辅助驾驶和L4自动驾驶,这直接启发了小鹏、理想等企业的技术路线选择。
3.2 国内主机厂:三条VLA量产路径
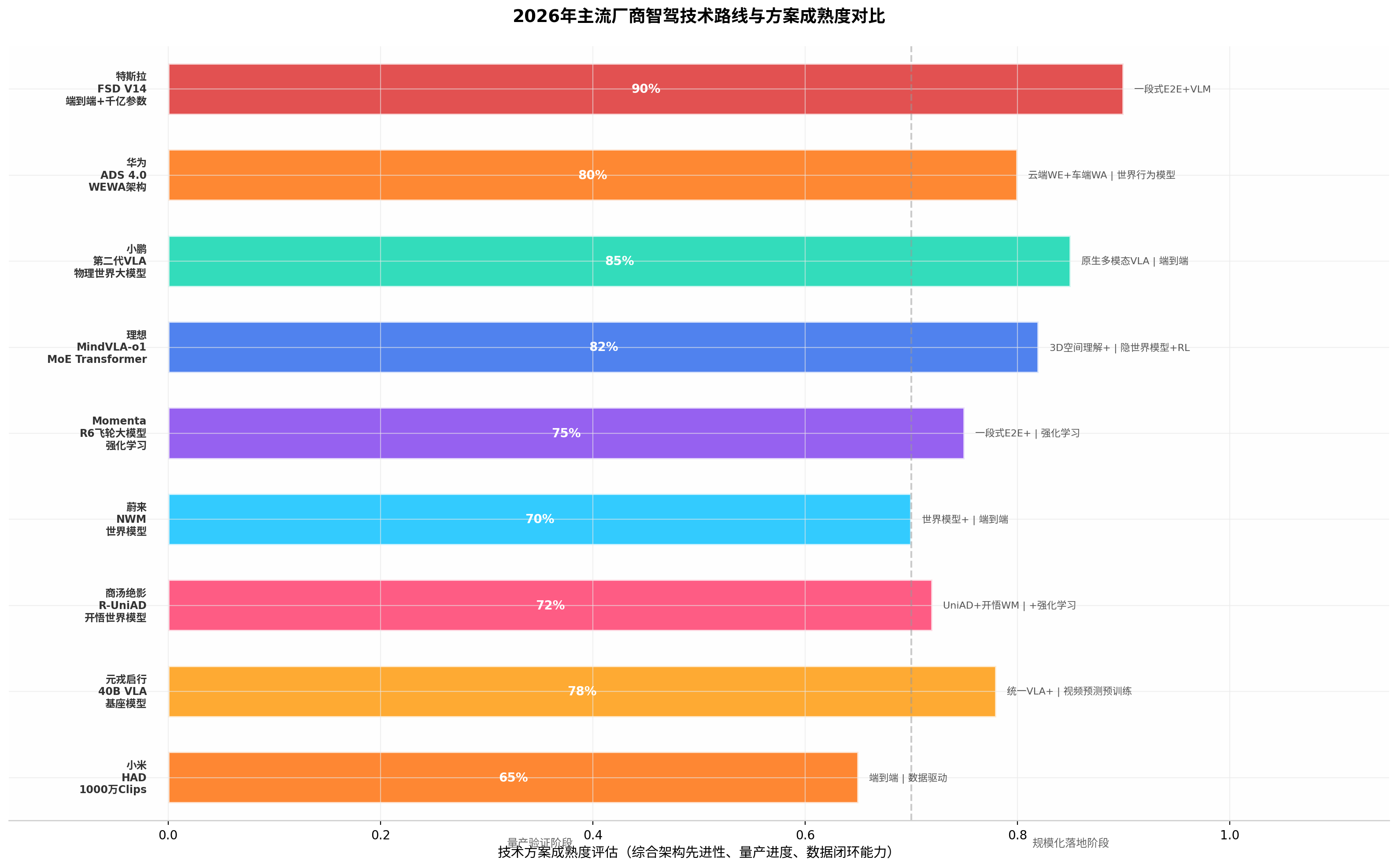
小鹏汽车 的第二代VLA于2026年3月19日正式量产推送 ,成为行业首个量产落地的端到端物理世界大模型。 (什么值得买) 其核心突破在于取消了传统智驾架构中的"语言转译"环节,实现视觉信号到动作指令的直接生成,决策延迟压缩至80毫秒以内 。首批搭载车型包括P7 Ultra、G7 Ultra和X9 Ultra,在北京晚高峰复杂路况下实测1小时39分钟仅介入2次,显著优于特斯拉FSD的10次介入。 (什么值得买) 第二代VLA定位为"面向L4的第一个版本",支持识别交警手势、自动配合查酒驾、无保护左转等L4级初阶能力,GX车型以3000 TOPS算力 预埋L4硬件冗余。 (什么值得买)
理想汽车 的智驾技术演进路线清晰程度在行业内数一数二。2024年实现端到端+VLM双系统量产交付 ;2025年推出VLA司机大模型,将空间理解、语言理解与行动决策统一到同一框架,月使用率达到80% ,VLA指令累计使用超过1200万次。 (魔珐星云具身智能数字人开发者社区) 2026年3月发布的MindVLA-o1 代表了下一代统一架构,以原生多模态MoE Transformer为核心,通过五大技术创新构建面向物理世界的通用智能体:3D空间理解(视觉核心3D ViT编码器+激光雷达点云几何提示)、多模态思考(预测式隐世界模型三阶段训练)、统一行为生成(Action Expert+Parallel Decoding+Discrete Diffusion Refinement)、闭环强化学习和软硬件协同设计。 (维科号) MindVLA-o1的核心理念是"自动驾驶只是物理AI的起点"------同一套VLA模型可以控制车辆,也能够扩展到机器人。 (盖世汽车社区)
华为乾崑ADS 4.0 采用WEWA架构 (World Engine & World Behavior Architecture),由云端世界引擎(WE)和车端世界行为模型(WA)构成。 (21经济网) 云端WE利用扩散生成模型生成密度是真实世界1000倍的高密度难例场景,专注Corner Case(突然横穿的行人、暴雨中的滚动障碍物),通过严格算法校验确保合成场景符合真实世界物理规律。车端WA融合视觉、听觉、触觉等多模态感知信号,实现端到端时延降低50%。 (21经济网) 华为还设计了一套云端Reward奖惩函数,训练模型的安全、合规、可靠且符合人类价值观的决策能力。
3.3 第三方供应商:差异化竞争格局
Momenta 以约61%的份额 位居城市NOA第三方供应商首位。 (IT之家) 其R6飞轮大模型是国内首个在一段式端到端基础上实现真正量产落地的强化学习大模型 ,采用"无图端到端"方案,不依赖高精地图即可在全球城市道路、高速公路、泊车等场景快速部署。 (cnautonews.com) Momenta已通过大规模部署提炼7000万黄金数据 ,包含大量复杂长尾场景。其"一个飞轮两条腿"战略(智能辅助驾驶+自动驾驶Robotaxi协同进化)形成了独特的数据飞轮优势。Momenta与Uber计划于2026年在慕尼黑启动L4级Robotaxi商业化运营 。 (evchanye.com)
商汤绝影 的技术演进路径是"一段式端到端→生成式世界模型→多阶段强化学习"三步走。 (与非网) 2022年推出感知决策一体化的UniAD(CVPR 2023最佳论文),2024年发布"开悟"智能驾驶世界模型,2025年推出R-UniAD ------首个与世界模型协同交互的端到端技术路线,通过"冷启动→虚拟强化→真实微调→模型蒸馏→车端部署"五步法让模型在虚拟场景中自主探索安全边界。 (与非网) 商汤绝影依托20 EFLOPS算力 和超5.4万块GPU,1个GPU产生的仿真数据相当于500台量产车的数据采集效果。 (雪球)
元戎启行 在2026年北京车展推出了40B参数的原生VLA基座大模型 ,核心创新在于"三位一体"模型角色设计------同一个模型同时扮演驾驶员、分析师和评论员/裁判。 (水清木华研究中心) 在预训练阶段摒弃传统轨迹监督(数据利用率仅0.001%),转而采用视频预测任务,将数据利用率提升至接近100%。 (水清木华研究中心)
| 厂商 | 代表方案 | 技术路线 | 量产状态 | 核心差异化能力 |
|---|---|---|---|---|
| 特斯拉 | FSD V14 | 一段式E2E+千亿参数 | 已推送 | 纯视觉,Robotaxi/量产车同源 |
| 华为 | ADS 4.0 WEWA | 云端WE+车端WA | 已上车 | 1000倍难例场景密度生成 |
| 小鹏 | 第二代VLA | 原生多模态VLA | 2026.03量产 | 80ms延迟,全场景覆盖 |
| 理想 | MindVLA-o1 | MoE+隐世界模型+RL | 2026年量产准备 | 物理世界通用智能体 |
| Momenta | R6飞轮 | 一段式E2E+强化学习 | 已量产 | 7000万黄金数据,全球部署 |
| 商汤绝影 | R-UniAD | UniAD+开悟WM+RL | 2025年底量产 | 20 EFLOPS算力,虚拟强化 |
| 元戎启行 | 40B VLA | 视频预测预训练 | 2026年发布 | 三位一体模型,数据利用率100% |
4. 世界模型与VLA的融合:2026年的技术分水岭
4.1 π0.7:VLA+World Model的范式突破
2026年4月Physical Intelligence发布的π0.7,被业界广泛认为是机器人领域的"GPT-3时刻" 。 (智源社区) 其核心突破不在于参数规模的增长,而在于首次实证了"组合泛化"------机器人能够将已学的原子技能自主组合,去完成从未见过的新任务。这一突破的实现关键在于世界模型的引入,但π0.7使用世界模型的方式与传统世界模型派截然不同。
传统世界模型的核心是让模型学会"模拟物理演化"------给一个动作,预测世界会变成什么样,policy基于这个预测做决策。而π0.7中的世界模型不干这事,它只负责一件事:把任务指令翻译成成功那一帧应该长什么样 。 (智源社区) 它不预测动作后果,不模拟物理,不参与决策链路------它是一个"消歧器"(Disambiguator),而不是一个"规划器"(Planner)。这种设计精妙之处在于:用世界模型的武器,干了一件不是世界模型派想象的事 。 (智源社区)
π0.7的世界模型从14B的BAGEL图像生成模型初始化,在推理时实时画出次目标图像(subgoal image),作为VLA的visual prompt输入。这种架构解耦了对未来的想象(显式化为像素图像)和对动作好坏的反思(显式化为文本标签),使主VLA模型无需自己"顿悟"物理世界。 (致力打造和AI共生,与产业共舞的Agent生态平台) 训练上采用Knowledge Insulation 技术,确保Action Expert的连续流匹配梯度不干扰VLM稳定的语义学习,同时继承了MEM(Multi-scale Embodied Memory)多尺度记忆编码器(短期视频memory+长期语义memory)。 (智源社区)
Physical Intelligence联合创始人Sergey Levine的判断是:"一旦跨过组合泛化这个门槛,能力的增长是超线性的。" (Github) π0.7的发布使行业风向发生变化------VLA路线回来了,而且是以一种与世界模型融合的新形态。
4.2 理想MindVLA-o1:智驾领域的融合实践
理想汽车的MindVLA-o1是智能驾驶领域世界模型与VLA融合的另一重要实践。其预测式隐世界模型的设计哲学与π0.7有所不同:不在像素空间生成未来画面,而是在Latent Space中完成未来状态推演 。 (维科号)
MindVLA-o1的世界模型训练分为三阶段:第一阶段 用海量视频数据预训练Latent World Token,让模型学会在隐空间里表征未来;第二阶段 在MindVLA-o1框架内持续进行世界模型推演;第三阶段 将世界模型、多模态推理及驾驶行为三者拉到同一目标下联合优化。 (维科号) 这种设计使模型能够在隐空间中"想象"未来几秒的场景演化,而不只是基于当前帧做出反应。
MindVLA-o1的行为生成层采用三层递进设计:Action Expert 从3D场景特征、导航目标、驾驶指令中提取关键信息生成初始轨迹;Parallel Decoding 让所有轨迹点同时输出而非逐点生成;Discrete Diffusion Refinement 负责精修质量。 (维科号) 快慢思考机制也被整合进同一模型:简单场景直接输出Action Token,复杂场景先经过CoT思维链再输出动作。
4.3 融合路线的三种技术模式
基于对头部玩家技术方案的分析,当前世界模型与VLA的融合呈现三种模式: (水清木华研究中心)
融合模式一:一段式端到端+世界模型+强化学习 。以Momenta、Bosch、文远行为代表。一段式端到端作为智驾核心神经网络,直连传感输入与驾驶输出;世界模型负责路况未来推演,低成本生成海量长尾场景用于仿真训练;强化学习在推演空间中迭代优化输出最优策略。三者形成"数据生成→策略训练→决策执行"的闭环。 (水清木华研究中心)
融合模式二:E2E+基础模型(VLM/VLA)+强化学习+世界模型 。以地平线、千里科技为代表。VLM/VLA做"大脑"负责认知推理,端到端小模型做"小脑"负责快速执行;世界模型和VLA共用同一backbone,将视觉生成和推理统一在同一结构中;强化学习阶段使用GRPO优化模型,奖励"想象的未来"与"真实安全决策"一致的结果。 (水清木华研究中心)
融合模式三:VLA+隐式世界模型(JEPA路线) 。以理想MindVLA-o1、Meta V-JEPA 2为代表。不生成像素级未来画面,在潜在空间预测未来表征;Action Head基于潜在空间预测进行决策;通过自监督预训练+少量交互数据后训练实现高效学习。 (算力自由)
| 融合模式 | 代表厂商 | 世界模型角色 | VLA角色 | 强化学习 | 优势 | 挑战 |
|---|---|---|---|---|---|---|
| E2E+WM+RL | Momenta, Bosch | 场景生成与推演 | 端到端决策 | PPO/GRPO | 闭环完整,数据自循环 | 训练稳定性 |
| VLA+WM统一 backbone | 地平线, 千里科技 | 视觉生成+推理统一 | 认知+决策一体化 | GRPO | 架构简洁,信息无损 | 模型容量需求大 |
| VLA+隐式WM | 理想, Meta | 潜在空间预测 | 基于隐空间决策 | 闭环RL | 计算高效,数据需求少 | 表征可解释性差 |
5. 1-2年工程落地节奏与挑战分析
5.1 落地节奏:四阶段演进
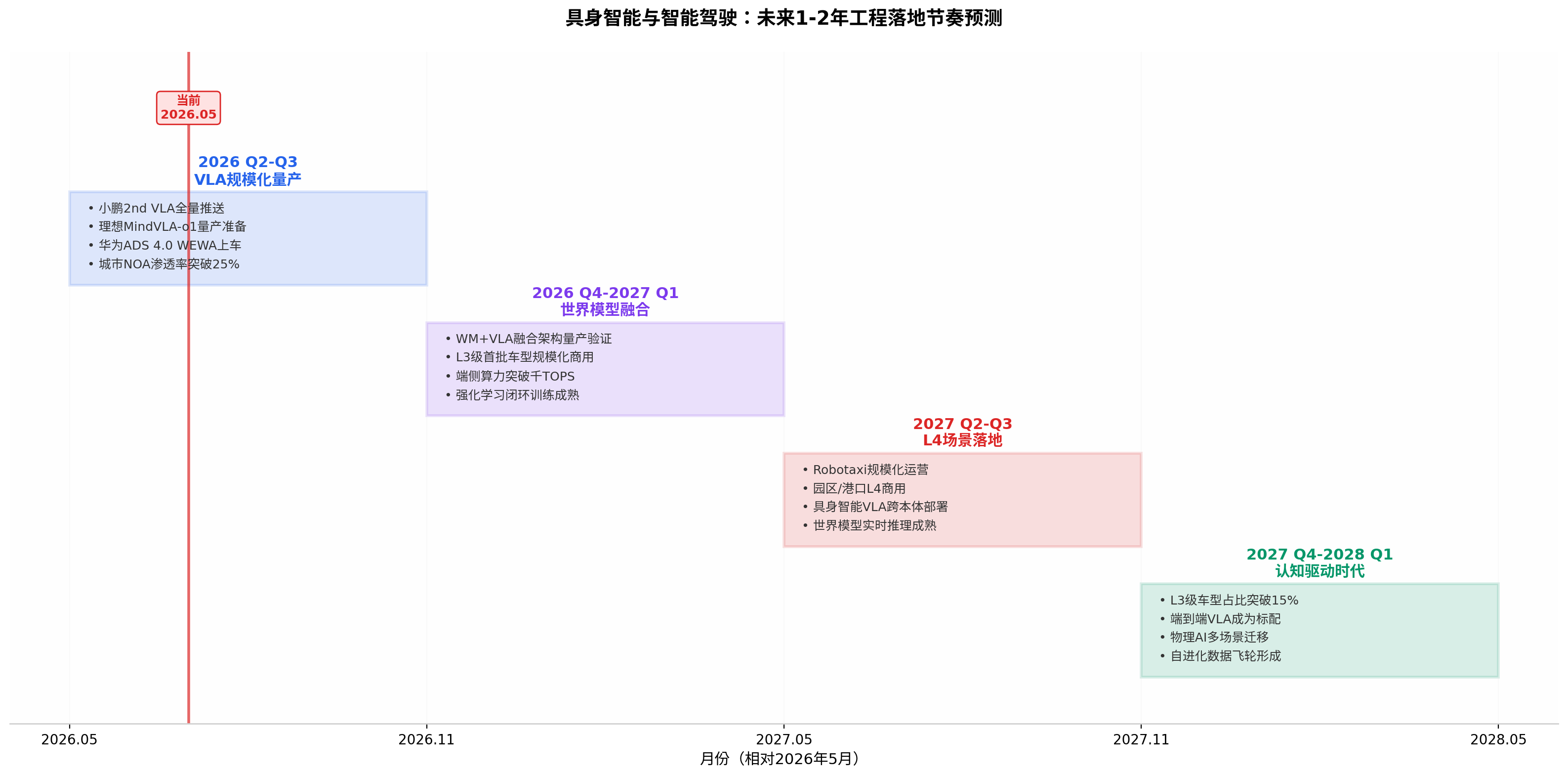
第一阶段(2026 Q2-Q3):VLA规模化量产 。小鹏第二代VLA已率先实现量产推送,理想MindVLA-o1进入量产准备阶段,华为ADS 4.0 WEWA架构持续上车。城市NOA渗透率预计从15%提升至25%。 (IT之家) 这一阶段的核心特征是VLA模型从"能用"走向"好用"------端到端延迟降至100ms以内,全场景覆盖(高速+城区+乡村+泊车),用户体验从"辅助"升级为"拟人"。
第二阶段(2026 Q4-2027 Q1):世界模型融合验证 。WM+VLA融合架构进入量产验证期,L3级首批车型(北汽极狐、长安深蓝已获准入许可)实现规模化商用。 (新浪) 端侧算力突破千TOPS(英伟达Thor-U 700TOPS已上车,理想自研马赫100单颗1280TOPS预计2026年量产)。 (36氪) 强化学习闭环训练基础设施成熟,模型迭代周期从"周级"缩短至"天级"。 (DoNews)
第三阶段(2027 Q2-Q3):L4场景落地 。Robotaxi进入规模化运营(Momenta与Uber计划2026年在慕尼黑启动L4商业化运营),园区/港口/矿区等封闭场景L4商用全面铺开。 (evchanye.com) 具身智能VLA实现跨本体部署(同一模型控制不同形态的机器人),世界模型实时推理在端侧成熟。
第四阶段(2027 Q4-2028 Q1):认知驱动时代 。L3级车型占比预计突破15%,端到端VLA成为20万元以上车型标配。 (盖世汽车社区) 物理AI实现多场景迁移(从车到机器人到无人机),自进化数据飞轮形成------系统从真实环境反馈中持续自我改进,人工标注需求大幅降低。
5.2 四大核心工程挑战
挑战一:端侧算力与模型规模的矛盾 。VLA模型的参数规模已从早期的35M(RT-1)增长到5B(π0.7),而车端算力虽然从254 TOPS(Orin-X)提升到700 TOPS(Thor-U)乃至1280 TOPS(理想马赫100),但模型规模增长速度快于算力提升速度。 (微信公众号(水滴汽车)) 理想汽车表示其双Orin-X芯片运行端到端+VLM已算力吃紧,而VLA的模型结构更复杂、参数进一步扩大,对端侧部署提出严峻挑战。 (微信公众号(水滴汽车)) 解决方案方向包括:模型蒸馏与量化(INT4/INT8)、MoE架构的稀疏激活、端云协同推理(简单场景端侧处理,复杂场景云端支持)。
挑战二:数据闭环的效率瓶颈 。端到端系统的数据闭环面临独特挑战------当系统大幅降低接管率后,依赖测试车的传统闭环方式变得更加困难。 (电子工程专辑 EE Times China) 特斯拉通过数十万辆车队的影子模式实现闭环测试,但这需要巨大的量产规模支撑。对于多数厂商而言,合成数据是解决端到端数据短缺的最有效方法 。 (cyber-car.cn) 华为WEWA的云端世界引擎生成1000倍密度的难例场景、商汤绝影1 GPU=500台量产车的数据采集效果、元戎启行视频预测预训练将数据利用率从0.001%提升至接近100%------这些都是突破数据瓶颈的创新路径。
挑战三:强化学习的训练稳定性 。RL与VLA的深度整合是当前研究热点,但训练稳定性仍是核心难题。RLinf-VLA框架首次实现流匹配VLA模型的在线强化学习微调,在LIBERO平台达到98.3%成功率。 (成都理工大学) 但RL的奖励函数设计、探索-利用平衡、样本效率等问题在具身智能场景中更加复杂。"预训练VLA+RL后训练"正成为行业主要研究方向,但如何在真实机器人上实现稳定、安全的在线学习仍是开放问题。 (成都理工大学)
挑战四:安全验证与法规适配 。L3级自动驾驶的责任划分已明确------系统激活期间发生事故,车企承担主要责任。 (新浪) 这要求智驾系统必须通过严格的安全验证,包括覆盖全生命周期的安全档案、不低于500万元的自动驾驶专项责任险、至少两种有效指标持续监测驾驶员状态。 (盖世汽车社区) 世界模型和VLA的"黑箱"特性与法规要求的可解释性、可验证性之间存在张力。公安部拟于2027年7月实施的《智能网联汽车自动驾驶系统安全要求》将对L3/L4系统提出统一技术规范。 (firecat-web.com)
5.3 对技术团队的建议
基于以上分析,对技术团队的核心建议如下:
短期(6个月内):聚焦VLA端侧部署优化。选择已开源的VLA基座(OpenVLA或GR00T N1.5)进行fine-tuning验证,探索模型量化(INT4 QLoRA可将OpenVLA显存需求降至40GB)和推理加速(TensorRT/ONNX Runtime)方案。同时建立数据闭环基础设施,包括影子模式数据采集、自动标注pipeline和仿真测试环境。
中期(6-18个月):推进世界模型与VLA的融合。可参考π0.7的架构设计------不追求完整的物理仿真,而是将世界模型作为"次目标图像生成器"集成到VLA中。在智能驾驶场景,优先落地预测式隐世界模型(类似MindVLA-o1的Latent Space预测),降低计算开销的同时获得未来推演能力。
长期(18-24个月):构建强化学习闭环训练能力。建立仿真-真实联动的RL训练基础设施,包括高保真世界模型仿真器、奖励函数设计框架和安全约束机制。关注"预训练VLA+RL后训练"范式,使系统能够从真实环境反馈中持续自我改进。
6. 结论与展望
世界模型与VLA的融合正在重新定义具身智能和智能驾驶的技术范式。从2018年两条独立演进的路线,到2026年π0.7和MindVLA-o1引领的深度融合,行业已进入"认知驱动"的新阶段。VLA提供了"看-懂-做"的端到端能力,世界模型赋予了"预判未来"的深度推理能力,强化学习则实现了"从模仿到自主"的进化闭环------三者结合构成了物理AI的完整技术底座。
未来1-2年的关键趋势包括:(1) VLA将从7B参数级向40B+参数级跃迁(元戎启行已发布40B VLA基座),基础模型能力成为核心竞争力;(2) 世界模型将从云端训练走向车端实时推理,端侧算力突破千TOPS是关键使能;(3) L3级自动驾驶将在2026-2027年实现规模化商用,L4级在封闭/半封闭场景率先盈利;(4) 具身智能VLA将实现跨本体泛化,从实验室走向工厂、家庭等真实场景。
对于技术团队而言,当前最核心的战略抉择是技术路线的选择:纯VLA路线(π0.7风格,快速落地)还是VLA+显式世界模型路线(Cosmos Policy风格,长期上限更高)还是VLA+隐式世界模型路线(MindVLA-o1风格,计算效率最优)?考虑到1-2年的工程落地时间窗口,建议采取**"VLA优先、世界模型渐进融合"**的策略------先建立端到端VLA的基础能力,再逐步引入世界模型增强推理深度,最后通过强化学习实现自我进化。