目录
[1、标准 Skill 不是一段超长提示词](#1、标准 Skill 不是一段超长提示词)
[3、一个嵌入式代码审查 Skill 应该怎么写](#3、一个嵌入式代码审查 Skill 应该怎么写)
[6、详细规则不要全塞进 SKILL.md](#6、详细规则不要全塞进 SKILL.md)
[7、脚本是 Skill 里很容易被忽略的部分](#7、脚本是 Skill 里很容易被忽略的部分)
[8、嵌入式行业写 Skill 要特别注意什么](#8、嵌入式行业写 Skill 要特别注意什么)
上一篇文章聊过一次 Skill(Skill是什么,嵌入式开发也该开始准备了),当时更多是讲它为什么重要。
这篇我想往下走一步:如果真的要在嵌入式开发里创建一个标准 Skill,应该怎么做?
我现在越来越觉得,Skill 不是一个概念问题,而是一个工程习惯问题。
以前我们和 AI 协作,大多是临时对话。
写一个驱动,就告诉它不要动态内存、要有超时、错误码要统一。
查一个 RTOS 问题,就告诉它先整理现象、再列可能方向、不要直接下结论。
做一次代码 review,就提醒它重点看指针、数组、中断、并发、实时性,不要只说命名和注释。
这些话说一次没问题,说三次就有点浪费。
如果同一套规则反复出现,它就不应该继续停留在聊天记录里,而应该沉淀成 Skill。
Skill 的本质,就是把老工程师反复提醒的话,变成 AI 默认遵守的工作规则。
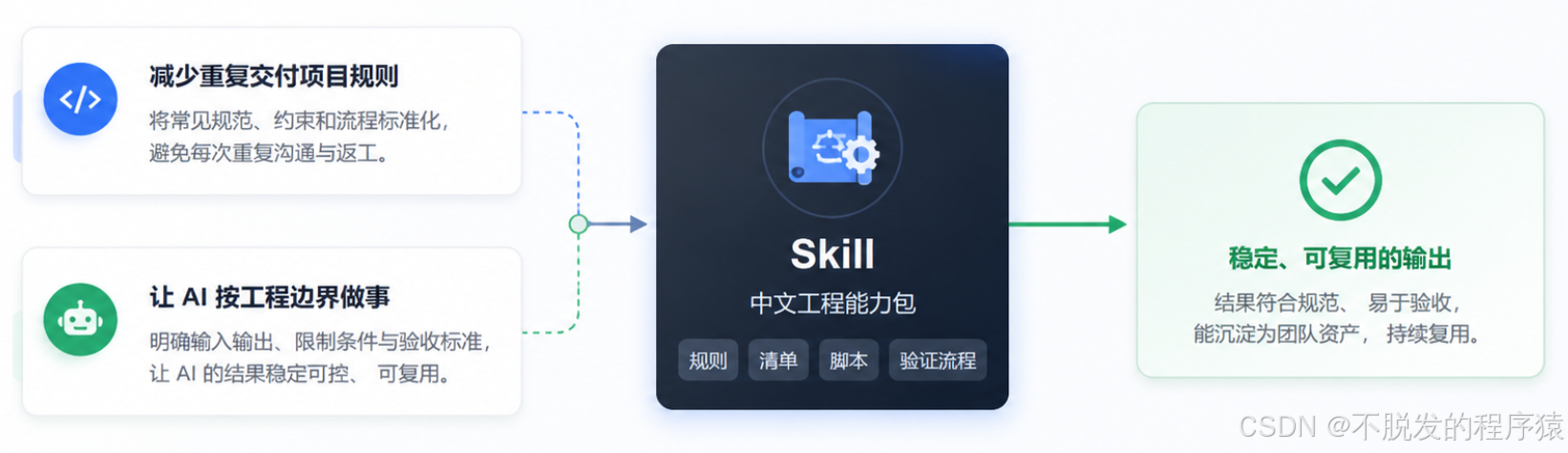
1、标准 Skill 不是一段超长提示词
很多人第一次做 Skill,容易把它写成一篇很长的提示词。
把所有经验、所有规则、所有例子都塞进一个文件里。看起来很完整,但实际用起来不一定好。
因为 AI 每次工作时,最怕上下文太乱。
一个好的 Skill,应该像一个小型工程包。
入口文件只放最关键的触发条件和工作流程。
详细检查项放到参考文件里。
能脚本化的部分放到脚本里。
需要复用的模板放到 assets 或 templates 里。
这样做的好处是,AI 先看到核心规则,真正需要时再加载详细资料,而不是一上来就被几千行内容淹没。
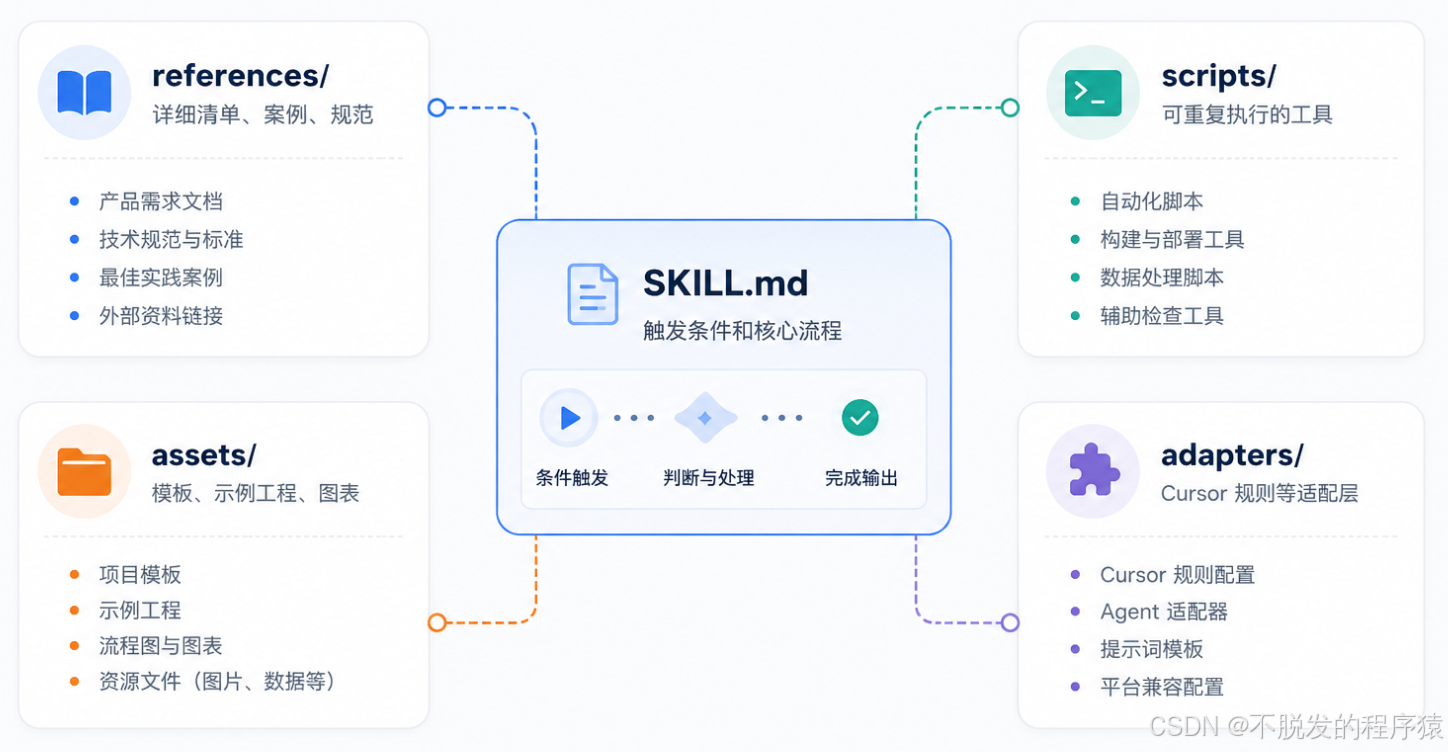
一个比较标准的目录可以这样设计:
embedded-code-review/
├─ SKILL.md
├─ references/
│ └─ review-checklist.md
├─ scripts/
│ └─ check_embedded_c_smells.py
└─ adapters/
└─ cursor-embedded-code-review.mdc其中 SKILL.md 是核心入口。
references/ 放详细规则,比如嵌入式代码审查清单。
scripts/ 放可以重复执行的小工具,比如扫描高风险函数、动态内存、忙等。
adapters/ 放不同工具的适配层,比如 Cursor 的 .mdc 规则文件。
这个结构不复杂,但已经足够应付大多数团队的第一版 Skill。
2、先选一个真实场景,不要一上来做大而全
如果你问我嵌入式行业最适合先做哪个 Skill,我会选代码审查。
原因很简单。
它高频、风险低、价值明显。
嵌入式 C/C++ 代码里,很多问题不是语法错,而是工程风险。
比如数组越界、长度字段没有校验、中断里调用阻塞接口、volatile 用错、任务之间共享变量没有保护、DMA buffer 没处理 cache、等待硬件状态没有超时。
这些问题靠 AI 临时 review 也能发现一部分,但如果没有规则,它经常会把重点放偏。
它可能会说变量名可以更清楚,注释可以更完整,函数可以拆分。
这些建议不是完全没用,但不是嵌入式 review 的第一优先级。
所以代码审查 Skill 的第一件事,就是告诉 AI:
先看会不会死机、丢数据、破坏硬件状态、影响实时性。
风格建议往后放。
这就是工程边界。
3、一个嵌入式代码审查 Skill 应该怎么写
下面是我会放进 SKILL.md 的核心内容。
注意,Skill 里面可以是中文,而且我建议嵌入式团队内部使用时就写中文。
因为很多工程规则本来就是团队内部口径,中文更容易写清楚,也更容易让新人理解。
---
name: embedded-code-review
description: 嵌入式 C/C++ 代码审查 Skill。用于审查 MCU、RTOS、驱动、BSP、通信协议、低功耗、异常处理相关代码,重点发现指针越界、并发竞态、中断上下文误用、实时性风险、内存/栈风险、错误处理不完整、硬件寄存器和时序需要人工确认的问题。
---
# 嵌入式 C/C++ 代码审查
## 工作原则
- 先判断代码场景:裸机主循环、RTOS 任务、中断服务函数、驱动层、协议解析、启动/低功耗、测试脚本。
- 优先审查会导致死机、数据损坏、实时性失效、硬件误操作、量产风险的问题。
- 不把风格建议放在前面,除非风格问题会引入实际风险。
- 涉及寄存器位、芯片时序、电气限制、DMA/cache、编译器特性时,标注"需要人工确认"。
- 如果代码上下文不足,先列缺失信息,再基于现有证据给出条件化判断。这段里最重要的是 description。
很多工具触发 Skill 时,主要先看名字和描述。描述写得太虚,AI 就不知道什么时候该用。比如只写"用于代码审查",范围太大。最好把触发场景写具体:MCU、RTOS、驱动、BSP、通信协议、低功耗、异常处理。
后面的工作原则则是为了防止 AI 跑偏。
嵌入式代码 review 和普通业务代码 review 不一样。普通代码可能更关注可读性、抽象、复用、测试覆盖。嵌入式当然也关心这些,但第一优先级通常是稳定性、实时性、资源和硬件边界。
4、审查顺序要写清楚
Skill 里一定要有顺序。
因为没有顺序,AI 会按它自己的习惯来。它可能先看命名,再看函数长度,最后才提一句"注意数组越界"。
我会把审查顺序写成这样:
## 审查顺序
1. 内存安全:空指针、数组越界、长度字段可信度、结构体对齐、生命周期、栈上大对象。
2. 并发与中断:volatile、原子性、临界区、锁顺序、ISR 中阻塞、ISR 中调用不可重入接口。
3. 实时性:忙等、无超时等待、长临界区、日志打印、动态内存、不可控循环。
4. 硬件交互:寄存器读改写、清标志顺序、外设状态机、DMA buffer、cache 一致性、上电/复位时序。
5. 错误处理:返回值丢失、错误码不统一、失败后资源状态不一致、重试策略缺失。
6. 可维护性:接口边界、模块职责、命名、注释,只在影响理解或维护风险时提出。这个顺序背后其实是嵌入式工程师的判断。
先看会不会出事故,再看好不好维护。
这不是说代码风格不重要,而是面向工程风险时,优先级不能错。
5、输出格式也要固定
如果不固定输出格式,AI 很容易写成一段散文。
看起来很顺,但不好落地。
我更喜欢让它按问题卡片输出:
## 总体判断
- 风险等级:高 / 中 / 低
- 主要风险:一句话概括
- 需要补充的上下文:如果没有则写"无"
## 具体问题
### [P1] 问题标题
- 位置:文件名/函数名/关键代码片段
- 触发条件:什么情况下发生
- 可能后果:死机、丢数据、实时性下降、硬件误操作等
- 修改建议:给出可执行建议
- 是否需要人工确认:是/否,原因这套格式有几个好处。
第一,面向修改,不只是面向评论。
第二,方便你放到 code review 里。
第三,能强制 AI 说明触发条件。很多风险不是一句"这里可能有问题"就结束了,必须说明什么情况下会触发。
第四,能把"需要人工确认"单独拎出来。
这对嵌入式非常重要。
AI 可以提醒你 DMA 可能有 cache 一致性问题,但具体芯片、具体 cache 策略、具体 MPU 配置,必须回到工程里确认。
6、详细规则不要全塞进 SKILL.md
SKILL.md 不适合放太长。
详细检查项可以放到 references/review-checklist.md。
比如:
# 嵌入式代码审查详细清单
## 内存与边界
- 指针参数是否检查为空。
- 长度字段是否先验证再使用。
- payload_len、frame_len、offset 是否可能溢出。
- 数组下标是否由外部输入直接决定。
- 栈上是否创建大数组或大结构体。
## 中断与并发
- ISR 中是否调用可能阻塞、加锁、打印、分配内存的函数。
- 中断和任务共享变量是否只用 volatile,但缺少原子性或临界区。
- 多任务共享资源是否有一致的加锁顺序。这样做的好处是,入口保持清爽,细节又不会丢。
以后你发现团队又踩了新坑,比如某个芯片 DMA buffer 必须 32 字节对齐,就可以补到 checklist 里。
Skill 会随着项目经验慢慢长出来。
7、脚本是 Skill 里很容易被忽略的部分
很多人做 Skill 只写文档,不放脚本。
我觉得这有点可惜。
有些事情让 AI 每次分析,不如直接脚本扫描。
比如嵌入式 C 里可以先粗略扫这些高风险模式:
strcpy、sprintf这类无边界函数;malloc/free/new/delete动态内存;while(flag);裸忙等;- ISR 函数;
- 临界区和关闭中断;
- 可能没有超时的硬件等待。
它不负责最终判断,只负责给 AI 和工程师提供第一轮线索。
这类脚本很适合随着项目迭代。
比如你们项目里禁止使用某些 API,就加进去。
比如要求驱动层不能调用日志接口,也可以扫。
比如发布前要检查某些 debug 宏是否关闭,也可以扫。
当 Skill 里有脚本,AI 就不只是"会说",而是能配合工具做一些确定性的工作。
8、嵌入式行业写 Skill 要特别注意什么
我觉得有几条很重要。
第一,中文没问题,而且很多时候更适合。
团队规则、调试习惯、历史问题,用中文写得更自然。name 建议用英文短横线,因为工具识别和目录兼容更稳;但正文、清单、输出要求完全可以用中文。
第二,硬件事实必须留人工确认口。
寄存器、时序、电气特性、errata、DMA/cache,这些不能让 AI 装懂。Skill 里必须反复强调,不确定就标注"需要人工确认"。
第三,不要把 Skill 写成知识百科。
Skill 不是教材,不需要解释什么是指针、什么是 RTOS。AI 本身知道很多通用知识。你要写的是你们项目里更在意什么、按什么顺序做、哪些地方不能踩。
第四,脚本越确定,越应该沉淀。
比如扫描危险 API、统计栈使用、解析 map 文件、检查发布宏、生成测试表,这些都很适合放进 Skill。
第五,输出格式要面向工程流转。
不要让 AI 输出一大段作文。要让它输出能放进 review、bug 单、测试报告里的结构化内容。
AI 发展到现在,已经不是只会帮我们补一个函数了。
它能看工程,能改工程,能生成工程,也能参与重构。
能力变强以后,最重要的问题反而不是"AI 会不会",而是"它会不会按我们的工程规则做"。
嵌入式开发尤其需要这个边界。
因为我们面对的不是纯粹的软件逻辑,还有硬件、实时性、资源限制、量产风险和现场问题。
所以标准 Skill 的价值,不是让 AI 看起来更聪明。
而是让 AI 更守规矩。
它知道先看指针和边界,而不是先夸命名。
它知道 ISR 里不能随便阻塞。
它知道硬件手册没确认的地方要标出来。
它知道输出的问题要能被工程师直接拿去修改、验证和复盘。
对嵌入式工程师来说,未来很重要的一项能力,可能就是把自己的经验整理成 Skill。
你踩过的坑,你反复提醒新人的规则,你每次 review 都会看的点,你每次调试都会走的路径,都值得沉淀下来。
工具会变,模型会变,Cursor、Codex、Claude Code 的入口也可能继续变。
但有一件事不会变:
真正能长期复用的,不是某一次对话里的答案。
而是你沉淀下来的工程方法。