PostgreSQL 18 在处理 JSON 数据时,主要提供两种数据类型:json 和 jsonb。
💡 核心建议: 在实际开发中,强烈建议优先使用 jsonb 类型。
因为它以二进制格式存储,不仅支持 GIN 索引以加速查询,还提供了更丰富的函数和操作符,整体性能显著优于存储纯文本的 json 类型。
以下是 PostgreSQL 18 中处理 JSON(以 jsonb 为主)的常用函数与操作符分类详解:
🔍 提取与查询操作符
这些操作符用于从 JSON 文档中提取数据或进行基础判断,json 和 jsonb 均支持:
->:按键 获取元素,返回 JSON 类型 。- 示例:
SELECT '{"name": "张三"}'::jsonb -> 'name';结果为"张三"(字符串带双引号)
- 示例:
->>:按键 获取元素,返回 文本(TEXT)类型 。- 示例:
SELECT '{"name": "张三"}'::jsonb ->> 'name';结果为张三
- 示例:
#>:按路径 获取嵌套元素,返回 JSON 类型 。(字符串带双引号)- 示例:
SELECT '{"a": {"b": 1}}'::jsonb #> '{a,b}';结果为1 示例:SELECT '{"a": {"b": 1},"c": {"b": 2}}'::jsonb #> '{c,b}';结果为 2
- 示例:
#>>:按路径 获取嵌套元素,返回 文本(TEXT)类型。
💡 避坑小贴士:
当提取出纯文本(使用 ->>)后,如果该字段在业务逻辑中是数字或布尔值,PostgreSQL 不会自动帮转换类型。需要手动进行显式转换,例如:
- 转整数 :
(info->>'age')::INT - 转布尔值 :
(settings->>'is_active')::BOOLEAN
🛠️ JSONB 专属的高级操作符
这些操作符仅 jsonb 支持,非常适合用于 WHERE 条件过滤:
@>:判断左侧 JSONB 是否包含右侧的 JSONB(常用于数组或对象包含判断)。<@:判断左侧 JSONB 是否被包含于右侧。?: 判断 JSONB 对象是否包含某个指定的键(或数组是否包含某个字符串元素)。?|:判断 JSONB 是否包含任意一个指定的键(传入数组)。?&:判断 JSONB 是否包含所有指定的键(传入数组)。
⚙️ 修改 JSONB 数据的函数
当需要更新 JSON 文档内部的值时,可以使用以下专属函数:
jsonb_set(target jsonb, path text[], new_value jsonb, [create_if_missing boolean]):更新指定路径的值。- 注意:第三个参数
new_value必须是jsonb类型,如果是字符串需要带上双引号(如'"新值"'),数字或布尔值则直接写。
- 注意:第三个参数
jsonb_insert(target jsonb, path text[], new_value jsonb, [insert_after boolean]):在指定路径插入新值(常用于数组)。jsonb_pretty(jsonb):将 JSONB 数据以带缩进的易读格式返回。
📊 常用处理函数速查
- 数组处理 :
jsonb_array_length(jsonb):获取数组的长度。jsonb_array_elements(jsonb):将 JSON 数组展开为多行(返回 jsonb 格式)。jsonb_array_elements_text(jsonb):将 JSON 数组展开为多行(返回 text 格式,更常用)。
- 对象处理 :
jsonb_object_keys(jsonb):返回最外层 JSON 对象的所有键(Key)。jsonb_each(jsonb):将最外层 JSON 对象展开为键值对的多行。
- 类型与转换 :
jsonb_typeof(jsonb):获取最外层 JSON 值的类型(如 object, array, string, number 等)。to_jsonb(anyelement)/to_json(anyelement):将普通 SQL 类型转换为 JSON。
📦 将查询结果生成为 JSON
如果需要将数据库的查询结果直接打包成 JSON 字符串返回给前端,可以使用以下聚合或构建函数:
json_build_object(key, value, ...):手动指定键值对,构建一个 JSON 对象。jsonb_build_object(key, value, ...):同上,返回jsonb类型。row_to_json(record):将一行记录(Record)直接转换为一个 JSON 对象。json_agg(expression)/jsonb_agg(expression):将多行查询结果聚合为一个 JSON 数组。
📦 将JSONB数据转为特定类型对象
在 PostgreSQL 中,将 JSONB 数据转为特定类型的对象,通常有两种核心场景:一种是直接在 SQL 中将其转为数据库记录(Record) ,另一种是在应用程序(如 Java)中将其映射为实体对象。
以下是具体的实现方案:
1. 在 SQL 中转为数据库记录(Record)
如果想在数据库查询时直接将 JSONB 拆解并映射为带有明确字段和类型的行记录,可以使用 PostgreSQL 内置的 **jsonb_to_record**或 **jsonb_to_recordset**函数。
核心语法:
必须配合 AS 子句来定义返回的字段名和对应的数据类型。
sql
-- 假设有一个包含用户信息的 JSONB 数据
SELECT *
FROM jsonb_to_record(
'{"id": 101, "name": "张三", "age": 28, "is_active": true}'::jsonb
) AS user_record(id INT, name TEXT, age INT, is_active BOOLEAN);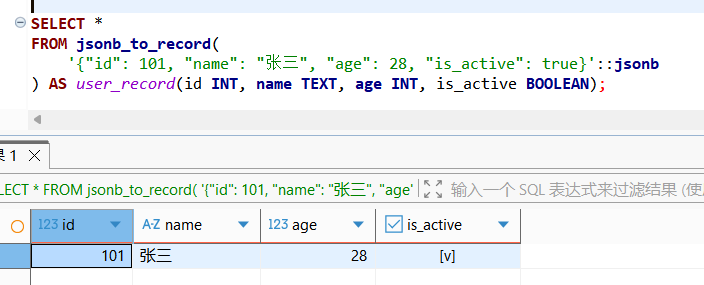
jsonb_to_record:将单个 JSONB 对象转为一行记录。jsonb_to_recordset:如果是一个 JSONB 数组,该函数可以将其转为多行记录。
2. 在 Java 应用程序中映射为对象
在实际的后端开发中,通常需要将数据库的 JSONB 字段直接映射为 Java 对象(如 POJO、Map 或自定义 DTO)。
方案 A:使用 Hibernate 6+ 原生支持(推荐)
如果使用的是 Spring Boot 3.x 或 Hibernate 6+,可以直接使用原生的 @JdbcTypeCode 注解,将 JSONB 字段自动映射为 Java 的 Map 或自定义实体类。
sql
import org.hibernate.annotations.JdbcTypeCode;
import org.hibernate.type.SqlTypes;
@Entity
@Table(name = "products")
public class Product {
@Id
private Long id;
// 自动将数据库的 jsonb 映射为 Java 的 Map 对象
@JdbcTypeCode(SqlTypes.JSON)
@Column(columnDefinition = "jsonb")
private Map<String, Object> attributes;
// 也可以映射为自定义的 Java 实体类
@JdbcTypeCode(SqlTypes.JSON)
private Specification specification;
// getters and setters...
}注意:在保存实体时,建议将 JSON 字段初始化为空对象(如 new HashMap<>()),避免出现 null 值导致的问题。
方案 B:使用 MyBatis-Plus 的 TypeHandler
如果使用的是 MyBatis-Plus,由于 PostgreSQL 的 jsonb 对应 JDBC 的 JdbcType.OTHER,需要自定义一个 TypeHandler 来处理 Java 对象与数据库 JSONB 之间的转换。
可以自定义一个继承自 BaseTypeHandler 或 JacksonTypeHandler 的处理器,在写入数据库时将 Java 对象转为 PGobject,读取时再解析回 Java 对象。
java
@MappedTypes({Object.class})
@MappedJdbcTypes(JdbcType.OTHER) // JSONB 对应 JdbcType.OTHER
public class JsonbTypeHandler extends BaseTypeHandler<Object> {
private static final PGobject jsonObject = new PGobject();
@Override
public void setNonNullParameter(PreparedStatement ps, int i,
Object parameter, JdbcType jdbcType) throws SQLException {
jsonObject.setType("jsonb");
// 使用 fastjson 或 jackson 序列化
jsonObject.setValue(JSON.toJSONString(parameter));
ps.setObject(i, jsonObject);
}
// 省略 getNullableResult 等读取解析方法...
}3. 在 SQL 中转为自定义复合类型(Composite Type)
如果经常在 SQL 中处理某种固定结构的 JSONB,可以提前在数据库中创建一个复合类型(类似于数据库层面的 DTO),然后通过自定义函数或 CAST 来实现转换。
sql
-- 1. 创建自定义复合类型
CREATE TYPE product_info AS (name TEXT, price DEC);
-- 2. 创建一个转换函数(将 JSONB 转为该复合类型)
CREATE FUNCTION jsonb_to_product_info(data JSONB)
RETURNS product_info AS $$
SELECT (data->>'name')::TEXT, (data->>'price')::DEC;
$$ LANGUAGE SQL IMMUTABLE;
-- 3. 创建隐式转换规则
CREATE CAST (JSONB AS product_info)
WITH FUNCTION jsonb_to_product_info(JSONB) AS IMPLICIT;
-- 4. 直接像转换普通类型一样使用
SELECT data::product_info FROM product_prices;建议:
- 如果是临时 SQL 查询 或报表分析,直接用
jsonb_to_record最方便。 - 如果是后端业务开发,优先使用框架(Hibernate/MyBatis)提供的对象映射能力,这样代码最简洁且易于维护。
🚀 推荐用 jsonb_to_record 关联表字段查询?
jsonb_to_record 关联表字段,是处理 JSONB 关联查询时,性能极佳的一种写法。
在 PostgreSQL 中,要将 jsonb_to_record 与表字段关联,核心是搭配 **LATERAL**关键字来使用。 在处理 JSONB 数据时,如果频繁使用 -> 或 ->> 操作符去提取字段,PostgreSQL 可能会触发一种叫 DeTOASTing(解压膨胀) 的机制。简单来说,就是每次提取一个字段,数据库都可能要把整行庞大的 JSONB 数据完整解压一遍,这在数据量大时会造成严重的性能损耗(Read Amplification)。
而使用 jsonb_to_record,数据库只会对 JSONB 文档进行一次解析,然后将其转换为标准的 SQL 列。在后续的关联或条件筛选中,直接读取这些解析好的列,效率极高。
💻 实战 SQL 演示
假设有一张 users 表,其中 data 字段是 JSONB 类型,里面嵌套了用户的基础信息和登录信息。可以这样写关联查询:
sql
SELECT
u.id,
parsed_user.name,
parsed_login.last_login,
parsed_login.login_count
FROM
users u,
-- 第一步:将 JSONB 字段解析为标准的 SQL 列(第一层)
LATERAL jsonb_to_record(u.data)
AS parsed_user(name TEXT, login JSONB),
-- 第二步:如果 JSONB 内部还有嵌套对象,可以继续用 LATERAL 解析(第二层)
LATERAL jsonb_to_record(parsed_user.login)
AS parsed_login(last_login DATE, login_count INT)
-- 可以直接像普通表字段一样进行条件过滤
WHERE
parsed_login.login_count > 10; 代码原理解析:
LATERAL关键字 :它允许右侧的子查询(即jsonb_to_record函数)引用左侧表(users u)中的字段(u.data)。AS parsed_user(...):这里必须定义好要提取的字段名和对应的数据类型(如name TEXT)。- 嵌套解析 :如示例所示,如果 JSONB 结构很复杂,可以把上一步解析出来的 JSONB 列(
parsed_user.login)再次丢给下一个LATERAL jsonb_to_record进行拆解。
⚠️ 注意事项
虽然这种方法在提取大量字段或进行复杂关联时性能极佳,但它也有一个限制:这种解析后的字段无法直接利用 JSONB 的 GIN 索引。
- 如果的查询条件主要依赖 JSONB 内部的某个字段**(比如
WHERE data @> '{"status": "active"}')** ,直接在WHERE子句中使用 JSONB 操作符配合 GIN 索引依然是最快的。 - 如果需要提取多个字段参与
JOIN、复杂的WHERE过滤,或者要避免 DeTOASTing 带来的性能损耗,LATERAL jsonb_to_record绝对是的最佳选择。
🚀 性能优化提示
如果经常对 JSONB 字段进行包含查询(如 @>, ?),强烈建议创建 GIN 索引,可以极大提升查询速度:
sql
-- 对整个 jsonb 字段建立 GIN 索引
CREATE INDEX idx_your_table_data ON your_table USING GIN(your_jsonb_column);GIN 索引的全称是 Generalized Inverted Index(广义倒排索引) 。它是 PostgreSQL 中专门为处理多值数据类型(如数组、JSONB、全文检索的文本)而设计的一种极其强大的索引结构。
结合之前对 JSONB 的关注,理解 GIN 索引对于优化复杂数据的查询性能至关重要。
🧠 GIN 索引的核心原理:倒排映射
为了直观理解,我们可以对比一下普通的 B-tree 索引:
- 传统 B-tree 索引 :建立的是
行 -> 值的映射。一行数据在索引中只会出现一次。 - GIN 倒排索引 :建立的是
值 -> 行的映射。它会把一行数据中的多个元素拆解开,一行数据可以在索引中出现多次。
举个实际的例子:
假设有一张文章表,其中 tags 是一个数组类型的字
| row_id | tags (数组) |
|---|---|
| 1 | {数据库, 索引, GIN} |
| 2 | {数据库, B-tree} |
| 3 | {GIN, 性能优化} |
如果给 tags 字段建立 GIN 索引,PostgreSQL 会在内部维护这样一张映射表:
"B-tree"→ 指向第 2 行"GIN"→ 指向第 1 行、第 3 行"数据库"→ 指向第 1 行、第 2 行"性能优化"→ 指向第 3 行
当执行 SELECT * FROM articles WHERE tags @> ARRAY['GIN']; 时,数据库不需要扫描整张表,而是直接去 GIN 索引里找 "GIN" 这个键,瞬间就能拿到它指向的第 1 行和第 3 行,查询效率极高。
🎯 GIN 索引的核心应用场景
GIN 索引是处理以下三种复杂数据类型的"标配":
-
JSONB 数据查询(最关心的场景)
当的业务大量使用 JSONB 存储半结构化数据,并且经常需要查询 JSON 内部是否包含某个键值对时,GIN 索引是必选项。
-
支持的典型操作符 :
@>(包含)、?(是否存在某个键)、?|(是否包含任意一个键)。 -
实战 SQL :sql
sql-- 1. 创建 GIN 索引 CREATE INDEX idx_users_profile ON users USING GIN(profile_data); -- 2. 极速查询包含特定键值对的用户(例如 skills 包含 "PostgreSQL") SELECT * FROM users WHERE profile_data @> '{"skills": ["PostgreSQL"]}'; -- 3. 极速查询是否存在某个键(例如是否存在 "email") SELECT * FROM users WHERE profile_data ? 'email';
-
-
数组(Array)元素搜索
适用于标签系统、多选属性等场景。
-
支持的典型操作符 :
&&(重叠/有交集)、@>(包含)、<@(被包含)。 -
实战 SQL :
sqlCREATE INDEX idx_products_tags ON products USING GIN(tags); -- 查询同时包含 'electronics' 和 'sale' 标签的商品 SELECT * FROM products WHERE tags @> ARRAY['electronics', 'sale'];
-
-
全文检索(Full Text Search)
PostgreSQL 内置的全文检索功能完全依赖 GIN 索引来加速。它会将文本拆解为词位(tsvector)进行倒排。
-
支持的典型操作符 :
@@(匹配查询)。 -
实战 SQL :
sql-- 对文本内容建立 GIN 索引(通常配合 to_tsvector 函数) CREATE INDEX idx_docs_content ON documents USING GIN(to_tsvector('english', content)); -- 搜索同时包含 'PostgreSQL' 和 'index' 的文档 SELECT * FROM documents WHERE to_tsvector('english', content) @@ to_tsquery('english', 'PostgreSQL & index');
-
⚖️ GIN 索引的性能权衡与调优
GIN 索引虽然查询极快,但在使用时也有需要注意的地方:
- 写入成本较高:由于一行数据可能被拆解成多个索引键,插入和更新数据时,GIN 索引的维护开销比 B-tree 大。
- Fast Update 机制 :为了解决写入慢的问题,PostgreSQL 默认开启了
fastupdate。新插入的数据会先放在一个待处理的列表中,等积累到一定量(默认 4MB)或触发VACUUM时,再一次性合并到主索引中。这加快了写入速度,但如果待处理列表过大,可能会短暂影响查询性能。 - 索引体积:如果 JSONB 或数组中的元素重复度很低(即唯一键非常多),GIN 索引的体积可能会比较大。
总结建议: 如果的表读多写少 ,或者经常需要对 JSONB、数组进行包含性查询(@>, ? 等),强烈建议创建 GIN 索引。它是让 PostgreSQL 在复杂数据类型上跑出 NoSQL 般查询速度的秘密武器。