《博主简介》
小伙伴们好,我是阿旭。
专注于计算机视觉领域,包括目标检测、图像分类、图像分割和目标跟踪等项目开发,提供模型对比实验、答疑辅导等。
《------往期经典推荐------》
二、机器学习实战专栏【链接】 ,已更新31期,欢迎关注,持续更新中~~
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
- 引言
- 一、3类目标检测器:闭集、开集、开放词汇
-
- [1. 闭集目标检测器(Closed-set Object Detectors)](#1. 闭集目标检测器(Closed-set Object Detectors))
- [2. 开集目标检测器(Open-set Object Detectors)](#2. 开集目标检测器(Open-set Object Detectors))
- [3. 开放词汇型目标检测器(Open-vocabulary Object Detectors)](#3. 开放词汇型目标检测器(Open-vocabulary Object Detectors))
- [二、Grounding DINO 核心原理拆解](#二、Grounding DINO 核心原理拆解)
-
- [1. 图像特征提取(基于 DINO)](#1. 图像特征提取(基于 DINO))
- [2. 文本特征编码(基于 BERT)](#2. 文本特征编码(基于 BERT))
- [3. 跨注意力融合(Cross Attention)](#3. 跨注意力融合(Cross Attention))
- [4. 目标预测(Language-Guided Query Selection)](#4. 目标预测(Language-Guided Query Selection))
- 三、环境搭建与安装
-
- [1. 前置要求](#1. 前置要求)
- [2. 安装步骤(命令行执行)](#2. 安装步骤(命令行执行))
-
- [(1)克隆 Grounding DINO 仓库](#(1)克隆 Grounding DINO 仓库)
- (2)安装依赖包
- (3)下载预训练模型权重
- [(4)GPU 环境报错解决](#(4)GPU 环境报错解决)
- [四、实战!用文本 Prompt 检测物体](#四、实战!用文本 Prompt 检测物体)
-
- [1. 导入必要库](#1. 导入必要库)
- [2. 检查 GPU 是否可用](#2. 检查 GPU 是否可用)
- [3. 加载预训练模型](#3. 加载预训练模型)
- [4. 用文本 Prompt 检测图片](#4. 用文本 Prompt 检测图片)
- [5. 结果示例](#5. 结果示例)
- 五、总结与展望
- 参考资料
引言
在深度学习目标检测领域,我们早已习惯了这样的流程:搭建 GPU 环境、准备标注数据集、训练 YOLO/Faster R-CNN/DETR 等模型...... 整套流程步骤繁琐,还受数据集质量和算力限制,耗时耗力。
但如果告诉你,有一款工具能跳过所有训练步骤,直接通过文本描述就能检测图片中的任意物体------比如输入"左车道的红色汽车""可爱的婴儿""青苹果",就能精准输出目标的边界框和置信度,你会不会心动?
它就是 Grounding DINO ------一款强大的开放词汇型目标检测器。今天这篇文章,我们就从核心概念、工作原理、环境搭建到实战演示,带你一站式掌握这款工具!

一、3类目标检测器:闭集、开集、开放词汇
在深入 Grounding DINO 之前,我们需要先明确三类目标检测器的区别,这样才能更好地理解它的优势:
1. 闭集目标检测器(Closed-set Object Detectors)
- 最常见的目标检测模型类型,比如 YOLO、SSD、Faster R-CNN、DETR 等
- 只能检测预定义标签(如"汽车""行人""飞机"),标签范围固定
- 优势:数据集质量高时效果稳定;劣势:需手动标注数据集,无法检测未定义类别
2. 开集目标检测器(Open-set Object Detectors)
- 既能检测训练集中的已知类别,也能识别未知类别(标注为"unknown")
- 优势:避免将未知物体误判为已知类别;劣势:模型选择少,实际应用场景有限(代表模型:Proser、OpenDet)
3. 开放词汇型目标检测器(Open-vocabulary Object Detectors)
- 无需预定义标签,支持任意相关文本输入(单词、短语、句子均可)
- 直接通过文本描述匹配图片中的目标,打破类别限制
- 代表模型:Grounding DINO、GLIP、OWL-ViT(本文主角就是 Grounding DINO!)
二、Grounding DINO 核心原理拆解
Grounding DINO 之所以强大,核心在于它将"图像特征提取"与"文本语义理解"深度融合,整个工作流程可分为4步:
1. 图像特征提取(基于 DINO)

- DINO 是一种自监督学习方法,无需人工标注数据,直接从图像中学习特征并生成特征图
- Grounding DINO 采用预训练的 Vision Transformer(ViT-B/ViT-L)作为图像编码器,高效提取图像全局与局部特征

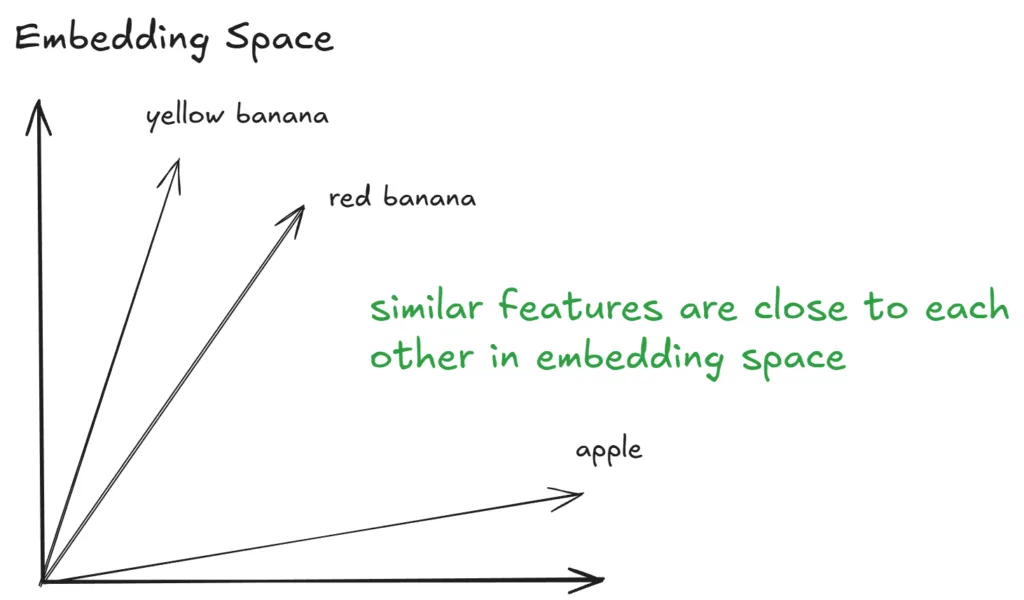
2. 文本特征编码(基于 BERT)
- 通过 BERT 文本编码器,将输入的文本 Prompt(如"黑色的狗""白色的猫")转化为嵌入令牌(embedding tokens)
- 这些令牌在嵌入空间中表征文本语义,语义相似的文本会聚集在同一区域
3. 跨注意力融合(Cross Attention)
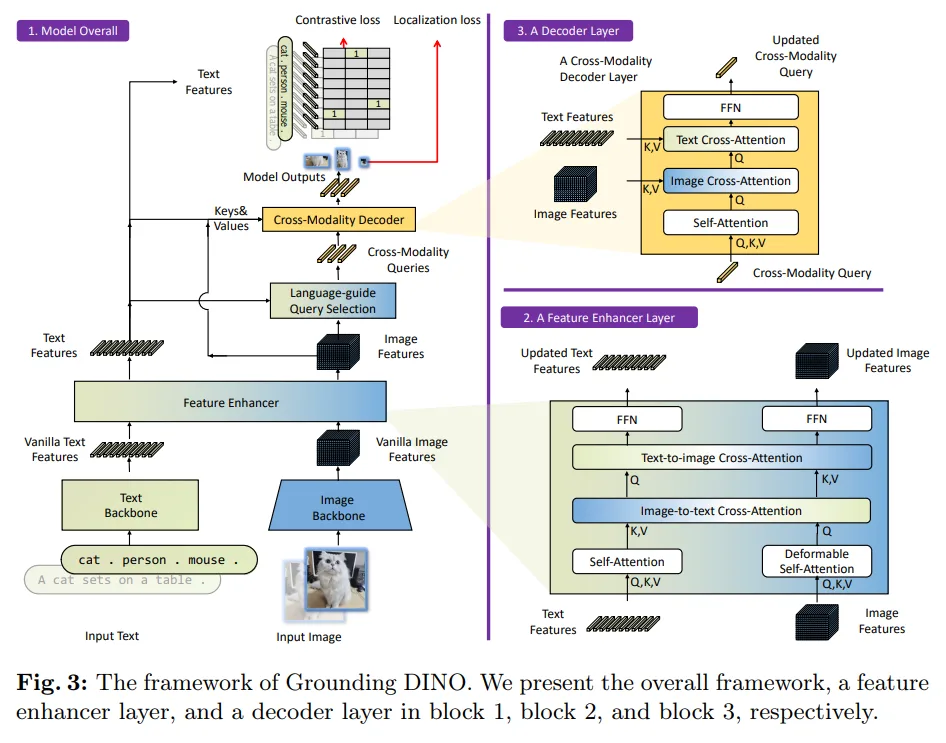
- 核心环节:通过跨注意力机制,建立图像特征与文本嵌入的关联,实现"文本-图像对齐"
- 简单说:让模型知道"文本描述的目标"对应"图像中的哪个区域"
4. 目标预测(Language-Guided Query Selection)
- 通过"语言引导查询选择模块"筛选出最相关的融合特征
- 输入改进后的 DETR 检测头,最终输出目标的边界框(boxes)、置信度(logits)和对应文本短语(phrases)
三、环境搭建与安装
1. 前置要求
- 已安装 Python 3.8+
- GPU 支持(可选但推荐,需安装对应版本的 CUDA)
- PyTorch 1.17+(GPU 版需匹配 CUDA 版本)
2. 安装步骤(命令行执行)
(1)克隆 Grounding DINO 仓库
bash
git clone https://github.com/IDEA-Research/GroundingDINO.git(2)安装依赖包
bash
cd GroundingDINO/
pip install -e .(3)下载预训练模型权重
bash
mkdir weights # 创建权重文件夹
cd weights
# 下载预训练权重文件
wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
cd ..(4)GPU 环境报错解决
若搭建 GPU 环境后出现 NameError: name '_C' is not defined,需先配置 CUDA 环境变量,再重新安装依赖:
bash
# 替换为你的 CUDA 安装路径(如 /usr/local/cuda-12.9)
export CUDA_HOME=/path/to/cuda-12.9
pip install -e . # 重新安装依赖四、实战!用文本 Prompt 检测物体
环境搭建完成后,直接上代码!我们将用 Jupyter Notebook 演示完整流程,新手也能轻松跟上~
1. 导入必要库
python
import cv2
from PIL import Image
import numpy as np
import torch
from torchvision.ops import box_convert
from groundingdino.models import build_model
from groundingdino.util.slconfig import SLConfig
from groundingdino.util.utils import clean_state_dict
from groundingdino.util.inference import annotate, load_image, predict
import groundingdino.datasets.transforms as T
from huggingface_hub import hf_hub_download2. 检查 GPU 是否可用
python
# 输出为 True 说明 GPU 环境配置成功
print(torch.cuda.is_available())3. 加载预训练模型
python
def load_model_hf(repo_id, filename, ckpt_config_filename, device='cpu'):
# 从 Hugging Face 下载配置文件
cache_config_file = hf_hub_download(repo_id=repo_id, filename=ckpt_config_filename)
args = SLConfig.fromfile(cache_config_file)
model = build_model(args)
args.device = device
# 下载并加载模型权重
cache_file = hf_hub_download(repo_id=repo_id, filename=filename)
checkpoint = torch.load(cache_file, map_location='cpu')
log = model.load_state_dict(clean_state_dict(checkpoint['model']), strict=False)
print(f"模型加载成功:{cache_file} \n => {log}")
model.eval() # 切换到推理模式
return model
# 配置模型参数(直接使用 Hugging Face 上的预训练模型)
ckpt_repo_id = "ShilongLiu/GroundingDINO"
ckpt_filename = "groundingdino_swint_ogc.pth"
ckpt_config_filename = "GroundingDINO_SwinT_OGC.cfg.py"
# 加载模型(GPU 可用时替换 device='cuda')
model = load_model_hf(ckpt_repo_id, ckpt_filename, ckpt_config_filename, device='cuda')4. 用文本 Prompt 检测图片
python
# 1. 配置参数
TEXT_PROMPT = 'black dog, white cat' # 多个文本 Prompt 用句号分隔
BOX_TRESHOLD = 0.45 # 边界框置信度阈值(可调整)
TEXT_TRESHOLD = 0.25 # 文本匹配阈值(可调整)
# 2. 加载测试图片(替换为你的图片路径)
local_image_path = "test_image.jpg"
image_source, image = load_image(local_image_path)
# 3. 执行目标检测
boxes, logits, phrases = predict(
model=model,
image=image,
caption=TEXT_PROMPT,
box_threshold=BOX_TRESHOLD,
text_threshold=TEXT_TRESHOLD
)
# 4. 绘制边界框和标签
annotated_frame = annotate(
image_source=image_source,
boxes=boxes,
logits=logits,
phrases=phrases
)
# 转换图像通道(BGR → RGB,适配 PIL 显示)
annotated_frame = annotated_frame[..., ::-1]
# 5. 输出结果
print(f"检测到的目标数量:{len(boxes)}")
print(f"边界框坐标:{boxes}")
print(f"置信度:{logits}")
print(f"匹配的文本短语:{phrases}")
# 显示标注后的图片
Image.fromarray(annotated_frame)
5. 结果示例
运行代码后,你会得到类似这样的输出:
检测到的目标数量:2
边界框坐标:tensor([[0.2412, 0.6010, 0.4580, 0.7889], [0.7945, 0.4216, 0.3380, 0.6429]])
置信度:tensor([0.9110, 0.5470])
匹配的文本短语:['black dog', 'white cat']同时会显示标注了"黑色的狗""白色的猫"边界框和置信度的图片,检测效果一目了然~
五、总结与展望
Grounding DINO 最核心的优势在于打破了传统目标检测的类别限制------无需标注数据集、无需训练,只要输入文本描述,就能检测任意物体,极大降低了目标检测的使用门槛。
无论是快速原型开发、小众场景检测(如"公交车旁的足球运动员""货架上的绿色苹果"),还是科研实验,它都能发挥巨大作用。
参考资料
- Grounding DINO 官方仓库:https://github.com/IDEA-Research/GroundingDINO
好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!