一个人能走多远不在于他在顺境时能走得多快,而在于他在逆境时多久能找到曾经的自己。
------ KMP
字符串匹配作为计算机领域最核心的基础算法之一,广泛应用于文本检索、编译器词法分析、网络数据解析、病毒特征匹配等各类实际开发场景中。高效的字符串匹配算法能够大幅提升程序运行效率,降低时间损耗,而 KMP 算法正是解决字符串匹配问题的经典高效算法,它彻底解决了暴力匹配算法的效率缺陷。
一、字符串匹配问题
在程序开发中,字符串匹配是最常见的需求之一:给定一个主串 (目标字符串)和一个子串 (模式字符串),我们需要完成的核心任务是,判断子串是否作为一个连续片段存在于主串当中。 如果存在,返回子串在主串中第一次出现的起始下标;如果不存在,则返回 - 1 作为匹配失败的标识。 这个问题看似简单,却是整个字符串处理领域的基础,而解决这个问题的算法,从最朴素的暴力枚举,到高效的 KMP 算法,体现了算法优化的核心思想。
二、BF 算法(暴力枚举法)
2.1 BF 算法描述
BF 算法全称 Brute Force,即暴力匹配算法,是字符串匹配问题中最直观、最容易理解的解法,它不依赖任何复杂的预处理逻辑,完全依靠逐字符比对完成匹配。 算法执行流程: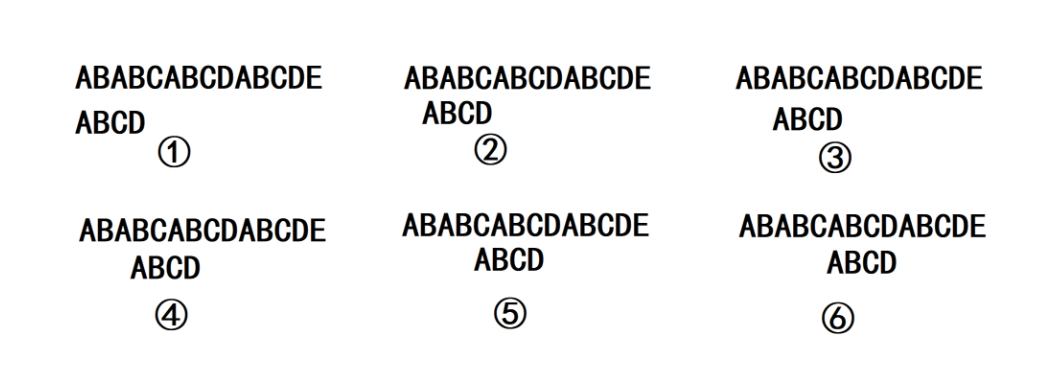
- 定义两个下标变量
i和j,i用于遍历主串,初始指向主串起始位置,j用于遍历子串,初始指向子串起始位置 - 进入循环匹配,循环的核心条件是
i和j均未超出对应字符串的有效长度,保证比对的字符是合法有效的 - 若当前
i和j指向的字符相等,两个指针同步向后移动一位,继续比对下一个字符 - 若当前字符不相等,匹配失败,
i回退到本趟匹配起始位置的下一个字符,j直接回退到子串起始位置 0,重新开始新一轮匹配 - 循环结束后,通过
j的值判断匹配结果:若j遍历完整个子串,说明匹配成功,返回起始下标;否则匹配失败,返回 - 1

BF 算法的核心缺陷十分明显:每次匹配失败后,主串指针i需要大量回退,造成了大量重复的字符比对操作,在数据量较大时,算法效率极低。 时间复杂度 :最坏情况下为O(n*m)(n 为主串长度,m 为子串长度)。
2.2 BF 算法实现
cpp
// BF暴力匹配算法实现
int BF_Search(const char* des, const char* sub) {
// 断言校验,确保传入的字符串指针非空,避免空指针访问
assert(des != nullptr);
assert(sub != nullptr);
int i = 0, j = 0;
int des_len = strlen(des);
int sub_len = strlen(sub);
// 循环条件:主串和子串指针均未越界
while (i < des_len && j < sub_len) {
if (des[i] == sub[j]) {
// 字符匹配,两个指针同时后移
i++;
j++;
} else {
// 匹配失败,i回退,j重置为0
i = i - j + 1;
j = 0;
}
}
// j遍历完子串,说明匹配成功
if (j == sub_len)
return i - j;
else
// 匹配失败
return -1;
}三、KMP 算法
3.1 KMP 算法思想
KMP 算法是对 BF 暴力算法的颠覆性优化 ,它的核心突破点在于:主串指针i永远不回退 ,仅通过调整子串指针j的位置完成匹配,彻底消除了重复比对的操作,将算法时间复杂度优化到O(n+m),在长文本匹配场景中优势极其显著。
KMP 算法的核心依托是next 数组 ,这个数组是针对子串预处理得到的,存储了子串中每个字符失配时,j应该回退的最优下标,无需让i回退重新匹配,直接跳过不可能成功的匹配位置。
3.2 为什么主串指针i可以不回退?
当匹配发生失败时,我们只需要关注子串失配位置之前的字符片段:

- 若该片段中存在最长相等的前缀和后缀 (左橙 = 右橙),
i的回退没有任何实际意义,这种回退必然会导致匹配失败,完全可以通过j跳转到 next 数组指定的位置替代 - 若该片段中不存在相等的前缀和后缀,那么
i无论如何回退,都无法完成匹配,因此i更没有回退的必要 - 综上,无论子串失配位置前是否存在相等前后缀,主串指针
i都可以保持不回退,这是 KMP 算法高效的核心逻辑。
3.3 KMP 算法实现
cpp
// KMP匹配算法实现
int KMP_Search(const char* des, const char* sub);
// 获取next数组
int* Get_Next(const char* sub);
int main() {
const char arr[] = "aaabccc";
const char brr[] = "abc";
// 调用KMP算法进行匹配
int res = KMP_Search(arr, brr);
if (res == -1)
cout << "匹配失败,未找到目标子串" << endl;
else
cout << "匹配成功,子串起始下标为:" << res << endl;
return 0;
}
int KMP_Search(const char* des, const char* sub) {
// 合法性校验
assert(des != nullptr);
assert(sub != nullptr);
int i = 0, j = 0;
int des_len = strlen(des);
int sub_len = strlen(sub);
// 为子串生成next数组,仅需计算一次
int* next = Get_Next(sub);
// 主循环匹配,i不回退
while (i < des_len && j < sub_len) {
// j=-1表示退无可退,或字符匹配成功,指针后移
if (j == -1 || des[i] == sub[j]) {
i++;
j++;
} else {
// 匹配失败,j根据next数组回退到最优位置
j = next[j];
}
}
// 释放动态申请的next数组内存,防止内存泄漏
free(next);
// 判断匹配结果
if (j == sub_len)
return i - j;
else
return -1;
}四、Next 数组
4.1 Next 数组定义
Next 数组是专门针对子串预处理生成的辅助数组,具备两个特征:
- 数组长度与子串的字符个数完全一致,一一对应子串的每一个位置
- 数组中存储的数值,代表子串在当前下标位置发生失配时,
j指针需要回退的最优下标位置
Next 数组的本质,是寻找子串中每个位置最长相等前缀和后缀的长度 ,这个长度决定了j的回退位置,能够最大程度减少无效匹配。
4.2 Next 数组求解
第一种:直接寻找最长相等前后缀(左橙 = 右橙),前缀长度即为对应位置的 next 值。
第二种:用已知求未知,这是代码实现的核心方法:利用已经计算完成的 next 值,推导下一个位置的 next 值。 核心规则:如果当前字符与回退位置的字符相同,说明前后缀可以延长一位,next 值 + 1;如果不同,则继续回退,直到找到匹配位置或退至 - 1。
4.3 Next 数组实现
cpp
// 生成子串对应的next数组
int* Get_Next(const char* sub) {
// 校验子串合法性
assert(sub != nullptr);
int len = strlen(sub);
// 动态分配内存,存储next数组
int* Next = (int*)malloc(len * sizeof(int));
// 内存分配失败,直接退出程序
if (Next == nullptr)
exit(EXIT_FAILURE);
// 手动初始化前两个位置的next值,固定规则
Next[0] = -1;
if (len > 1)
Next[1] = 0;
int j = 1;
int k = 0;
// 循环计算剩余位置的next值
while (j + 1 < len) {
// 回退到起点,或字符匹配,next值+1
if (k == -1 || sub[k] == sub[j]) {
Next[++j] = ++k;
} else {
// 不匹配,继续回退k
k = Next[k];
}
}
return Next;
}五、Nextval 数组
Nextval 数组是对 Next 数组的进阶优化,它解决了原始 Next 数组中存在的无意义回退问题,进一步减少 KMP 算法的匹配次数,让算法效率更高。
- 如果当前位置的字符,与它 Next 数组指向的回退位置字符不相同,说明本次回退是有价值的,直接将当前位置的 Next 值赋值给 Nextval
- 如果当前位置的字符,与它 Next 数组指向的回退位置字符相同,说明本次回退没有意义,匹配依然会失败,直接将回退位置的 Nextval 值赋值给当前位置
简单来说,Nextval 数组会跳过所有重复的、无意义的回退操作,让j指针一步到位跳转到最终的有效位置,避免了多余的字符比对,是 KMP 算法的终极优化形态。
六、算法总结
BF 算法 vs KMP 算法
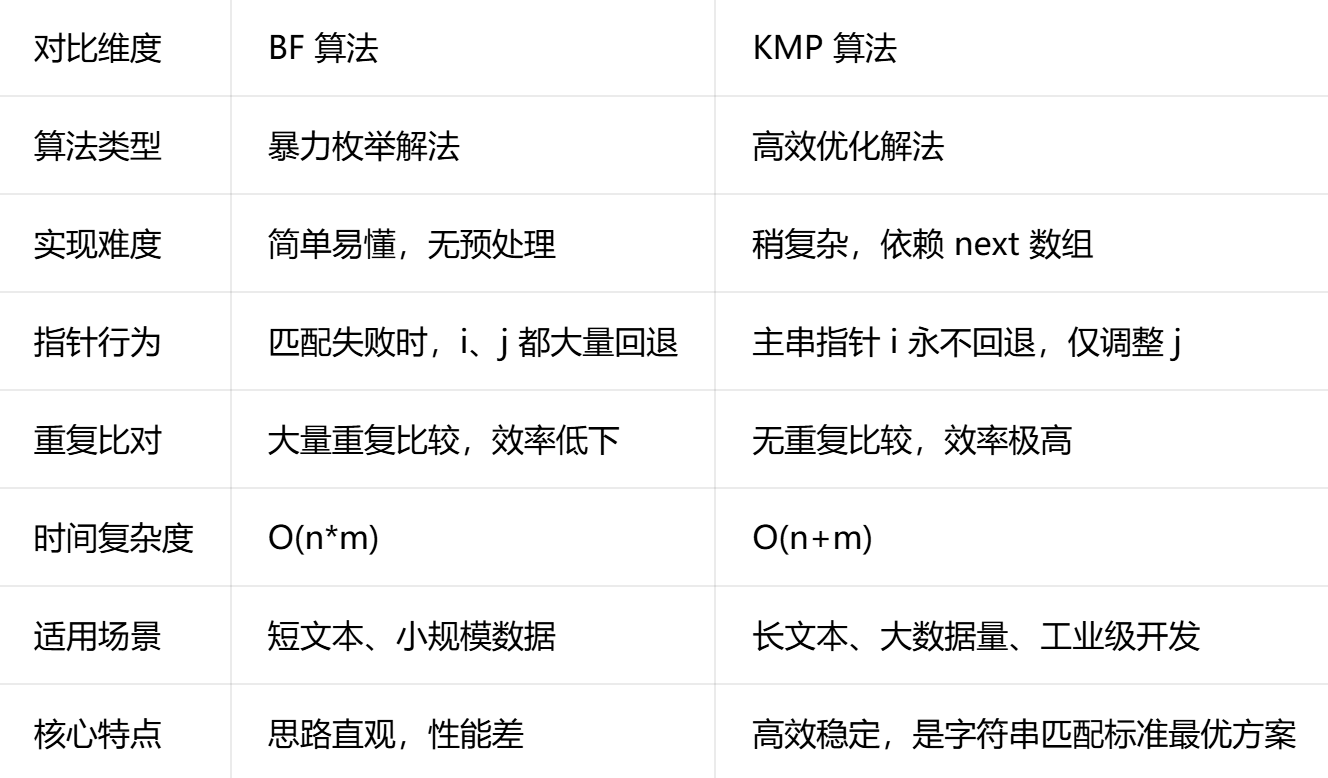
Next 数组 vs Nextval 数组