从一个反直觉的面试题说起
你有没有见过这种面试题?面试官拿出一段代码,让你说出会输出什么,然后你自信满满地写下答案,结果面试官摇摇头说:"错了,回去好好补补基础。"
javascript
showName();
console.log(myName);
var myName = 'DMYX';
function showName(){
console.log('函数showName被执行了');
}要是你以前没见过变量提升,大概率会觉得:这不是应该报错吗?showName 还没定义就调用了,myName 也是先打印后赋值。
但实际运行起来,结果是这样的:
javascript
函数showName被执行了
undefined是不是感觉 JavaScript 偷偷把代码顺序改了?就像你在餐厅排队,突然有个人插了队,而且还理直气壮地说:"我本来就应该在这儿。"
别急,这不是什么玄学。这事儿背后有个正经名字,叫变量提升(Hoisting)。而且更重要的是------你的代码其实一行都没被移动。

变量提升不是"物理移动",是"内存分配"
以前你可能听过这种解释:"变量提升就是把变量声明移到代码最前面。"
这话不能说全错,但容易让人误解------好像 JavaScript 引擎真的会去修改你的源代码,把 var myName 那行剪切粘贴到文件顶部似的。
实际上不是这样的。你的代码在文件里的位置,一个字节都没变。变量提升发生在编译阶段,是 JavaScript 引擎在内存里做的手脚。
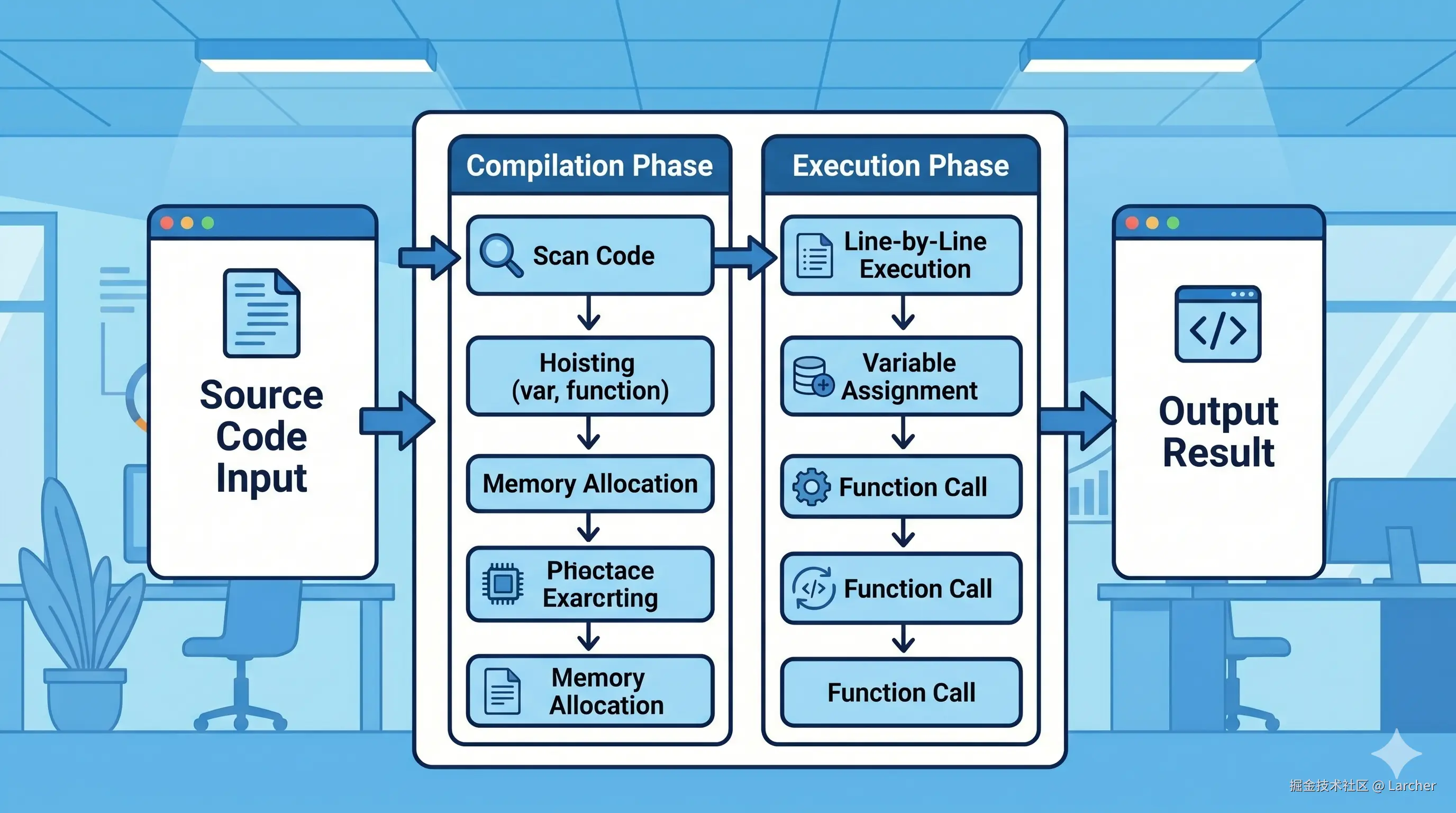
JS 代码是怎么运行的?
以前你可能觉得 JS 就是一行一行按顺序执行的。但实际上,JS 代码的执行分为两个阶段:
- 编译阶段:JS 引擎(比如 Chrome 的 V8)快速扫描一遍代码,做一些准备工作
- 执行阶段:真正一行一行跑代码
变量提升,就是发生在编译阶段的事情。
举个例子,这段代码:
javascript
console.log(myname);
var myname = 'DMYX';
function showName(){
console.log('代码被执行了');
}
showName();在编译阶段,JS 引擎会做这么几件事:
- 遇到
var myname,就在内存里创建一个叫myname的变量,默认值是undefined - 遇到
function showName(),就在内存里创建一个叫showName的变量,直接把整个函数对象存进去 - 赋值操作(
myname = 'DMYX')和函数调用(showName())这些,编译阶段统统不管
所以到了执行阶段,内存里已经准备好了这些东西。当执行到第一行 console.log(myname) 的时候,myname 已经存在了,值是 undefined,所以不会报错,而是打印 undefined。
函数声明 vs 函数表达式:谁先"上位"?
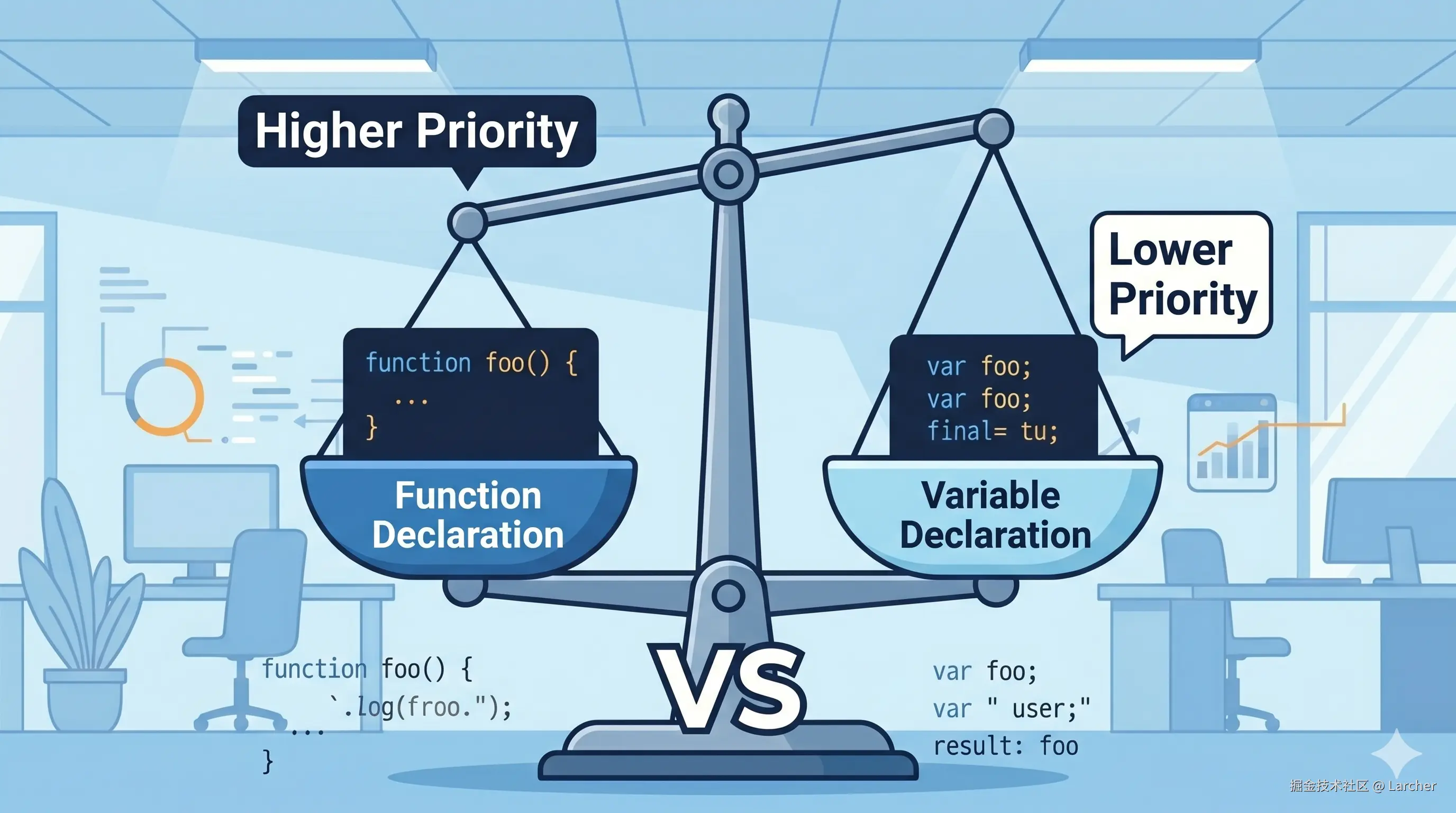
现在问题来了:如果一个名字既是函数名又是变量名,谁先提升?
看这段代码:
javascript
console.log(foo);
foo();
var foo = '我是变量';
function foo() {
console.log('我是函数');
}
console.log(foo);你觉得会输出什么?
答案是:
csharp
[Function: foo]
我是函数
我是变量为什么?因为函数声明的提升优先级比变量声明更高。
在编译阶段,JS 引擎先处理函数声明,把 foo 指向函数对象。然后遇到 var foo,发现 foo 已经存在了,就不会再重新赋值为 undefined 了。
所以第一个 console.log(foo) 打印的是函数。然后调用 foo() 执行函数,打印"我是函数"。
到了执行阶段,遇到 var foo = '我是变量',这时候才会把 foo 重新赋值为字符串。所以最后一个 console.log(foo) 打印"我是变量"。
这就好比在公司里,你本来是个经理(函数声明),结果有个新人来报到,职位也是经理(变量声明)。老板一看,你已经是经理了,就不会让新人顶替你。但如果老板后来给你调岗了(赋值操作),那你就变成新职位了。
那如果是函数表达式呢?情况就不一样了:
javascript
console.log(add(1, 2));
var add = function(a, b){
return a + b;
}这段代码会报错:TypeError: add is not a function。
为什么?因为函数表达式本质上是一个赋值操作。编译阶段只会提升 var add,把它初始化为 undefined,而不会管右边的函数。所以到执行阶段,add 还是 undefined,调用它自然会报错。
这就好比你在公司里宣布"我要招聘一个经理"(变量声明),但人还没来(没赋值),你就让他干活,当然会出问题。
let/const 的反击:暂时性死区(TDZ)
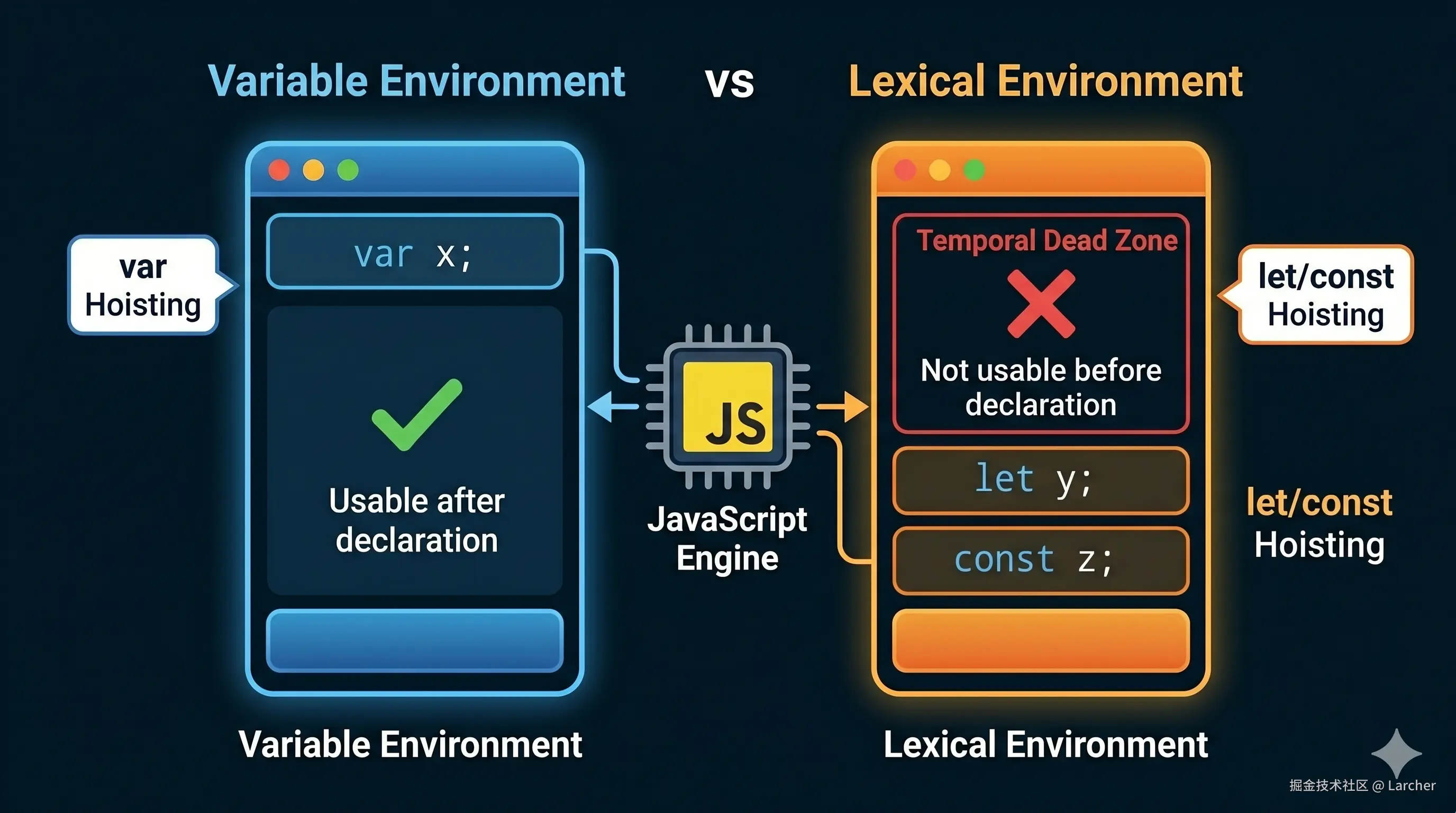
ES6 出来之后,let 和 const 来了,它们带来了一个新东西叫暂时性死区(Temporal Dead Zone,简称 TDZ)。
有人说:"let 和 const 没有变量提升。"
这话其实不准确。准确来说,let 和 const 也会被提升,但它们的内存空间是在词法环境 里,而不是变量环境里。而且在声明之前,这些变量处于"不可用"状态,只要你敢用,就报错。
看这段代码:
javascript
console.log(myname); // 报错:ReferenceError: myname is not defined
let myname = 'DMYX';用 let 声明的变量,在声明之前访问会直接报错,而不是返回 undefined。这就是暂时性死区在起作用。
为什么要这么设计?因为变量提升虽然方便,但也容易写出混乱的代码。你可能在不知不觉中用到了还没赋值的变量,导致 bug。
let 和 const 的暂时性死区,就是为了让你养成"先声明,后使用"的好习惯。
总结:如何写出不被"提升"坑的代码
好了,讲了这么多,你可能会问:"既然变量提升这么容易坑人,那我该怎么写代码才能避免?"
给你几个建议:
-
尽量用 let/const,少用 var:这是最直接的办法。let 和 const 的块级作用域和暂时性死区,能帮你避免很多提升带来的问题。
-
养成"先声明,后使用"的习惯:不管有没有提升,把变量声明放在作用域顶部,代码会更清晰。
-
函数声明优先,函数表达式谨慎用:如果你想让函数能在声明前调用,就用函数声明;如果你想避免提升,就用函数表达式。
-
别在条件判断里声明函数:不同浏览器对这种情况的处理可能不一样,容易出兼容性问题。
变量提升就像 JavaScript 里的一个"隐藏机制",不懂的时候觉得是玄学,懂了之后发现其实是 JS 引擎在帮你做一些准备工作。
但现代 JavaScript 开发中,我们其实很少再去依赖变量提升了。有了 let/const,有了更好的编码规范,我们完全可以写出更清晰、更易维护的代码。
最后想问你一个问题:你在项目里遇到过变量提升带来的 bug 吗?如果有,欢迎在评论区分享你的故事。