文章目录
-
- 摘要
- [I. 引言](#I. 引言)
- [II. 协方差张量输入模型](#II. 协方差张量输入模型)
- [III. 用于二维 DOA 估计的张量化深度神经网络](#III. 用于二维 DOA 估计的张量化深度神经网络)
-
- [A. 张量神经层分解](#A. 张量神经层分解)
- [B. 用于二维 DOA 估计的张量前馈](#B. 用于二维 DOA 估计的张量前馈)
- [C. 用于网络训练的张量化反向传播](#C. 用于网络训练的张量化反向传播)
- [D. Tucker 秩序列的选择](#D. Tucker 秩序列的选择)
摘要
到达方向(DOA)估计使用深度神经网络时,在复杂环境中显示出很大的应用潜力。然而,传统基于矩阵的深度神经网络会把多维信号统计量向量化为过长输入,使神经层需要大量参数,并带来很高的训练计算开销。为解决这一问题,本文提出一种资源高效的张量化神经网络,用于深度张量二维 DOA 估计。在该网络中,与均匀矩形阵列(URA)对应的协方差张量被传播到隐藏状态张量,以封装关键的信号特征。为减少可训练参数数量,前馈传播被表述为逆 Tucker 分解,从而将参数压缩为逆 Tucker 因子。随后,本文设计有效的张量化反向传播过程来训练这些压缩参数,并通过贝叶斯优化调节 Tucker 秩序列,以保证网络性能。仿真结果表明,所提出的张量化深度神经网络优于对应的基于矩阵的网络。在 10 × 10 10\times10 10×10 URA 和 2 个源的场景中,所提出网络将训练参数数量减少超过 122,000 倍,因此训练速度更快、GPU 内存占用更低;同时,即使在非理想条件和变化场景下,也能保持相当的估计精度和角分辨率。
索引词: 深度神经网络、到达方向估计、张量化神经网络、Tucker 分解。
I. 引言
到达方向(DOA)估计已在雷达、声纳、声学和无线通信等领域得到广泛研究 2-6。过去几十年中,研究者提出了许多基于模型的 DOA 估计方法,例如多重信号分类(MUSIC)7 和基于旋转不变技术的信号参数估计(ESPRIT)8。随着现代应用环境日益复杂,经典基于模型的方法面临若干挑战:低信噪比(SNR)和有限快拍数会显著扭曲信号统计量;依赖不完备统计模型的子空间提取、稀疏恢复等传统方法,在这些条件下容易出现性能下降 11。虽然稀疏贝叶斯学习和相关矩阵重构等技术可用于缓解模型偏差 12, 13,但它们通常计算复杂度较高,并受系统资源限制而难以实现。
为在降低计算复杂度的同时增强困难条件下的鲁棒性,径向基函数(RBF)14、支持向量回归(SVR)15 等机器学习技术已被用于数据驱动的 DOA 估计。其中,深度神经网络成为重要研究方向 16-18。神经网络的训练过程计算量较大且依赖数据集,但该过程通常离线完成;一旦网络训练完成,DOA 估计只需前馈计算即可得到结果,避免了针对每个具体问题执行复杂优化。因此,神经网络尤其适合实际应用中的实时 DOA 估计。此外,通过合理设计训练策略,基于深度神经网络的方法可对阵列误差 19、源相干性 20、低 SNR 21 和网格失配 22 等问题表现出较强适应性,在特定场景下可能比 MUSIC、ESPRIT 和稀疏重构等基于模型的方法更稳健。
上述神经网络通常遵循矩阵处理框架:将输入向量化后与若干参数矩阵相乘以产生输出。对于能够进行二维 DOA 估计的多维传感器阵列,传统网络仍会把相应信号统计量向量化。这样得到的长向量输入需要训练数量成比例增长的参数,导致离线训练阶段负担很重。随着信号维度扩展,现有基于深度神经网络的 DOA 估计方法会出现训练速度慢和系统过载问题。因此,有必要为多维阵列信号处理设计资源高效的深度神经网络。
张量作为多路数据结构,已被用于建模阵列处理中的多维信号 24。典范多元分解(CPD)25、Tucker 分解 26 等张量分解技术可将张量统计量投影到若干低阶因子上,从而高效提取信号特征 27, 28。尤其是在 MIMO 雷达系统和多维阵列等场景中,基于张量的 DOA 估计方法已有应用 29-33。张量分析的优势也启发了张量化深度神经网络 34-37:通过将输入和隐藏状态张量化来捕获内在多路数据特征,并进一步建立张量分解与张量化神经层数据传播之间的代数关系,以实现网络压缩。
现有张量化神经层分解方法大体可分为两类。第一类方法将神经层参数或卷积核重新表示为张量,并直接分解为低阶因子,例如张量列车分解 38 和块项分解(BTD)39。这类方法能直接压缩参数,但输入和隐藏状态并不主动参与分解过程,因此张量分解与张量特征传播之间的联系较弱。第二类方法则将张量化神经层本身视为张量分解,使隐藏状态和神经层参数分别映射到分解后的核心张量与因子,从而提供更好的可解释性和更灵活的网络设计 40, 41。不过,这些方法多面向视觉数据分析,并不直接适合处理阵列信号统计量。对于 DOA 估计,神经层设计需要匹配独特的协方差张量结构,并处理与 DOA 损失函数反向传播、张量秩调节相关的具体问题。
本文提出一种用于二维 DOA 估计的张量化深度神经网络。该网络以信号协方差张量为输入,并将其传播到封装张量信号特征的隐藏状态张量。从协方差张量到隐藏状态张量的变换被表述为逆 Tucker 分解:非线性激活后的 Tucker 核张量作为隐藏状态张量,逆 Tucker 因子则包含压缩参数。为训练这些参数,本文基于紧凑张量化神经层设计,引入张量化前馈和反向传播过程;同时通过贝叶斯优化微调 Tucker 秩序列,以减少性能下降。分析表明,分解后的神经层参数量显著减少,从而加快训练并降低系统成本。仿真结果验证了所提出张量化神经网络在训练速度和计算效率方面优于传统基于矩阵的神经网络和基于模型的方法,同时保持有竞争力的估计性能。
本文贡献总结如下:
- 将协方差张量分解与紧凑神经层设计联系起来,把可训练参数压缩为张量分解因子,使张量信号特征能在基于张量模型的神经网络结构中高效传播,并输出二维 DOA。
- 提出与 DOA 损失函数相匹配的张量化前馈和反向传播过程,以有效训练压缩参数;同时微调张量秩序列,为张量化神经网络提供较优拓扑。
- 分析所提出张量化神经网络的参数压缩能力和计算复杂度,说明其可显著减少待训练参数数量,提高网络效率并降低系统成本。
- 展示训练后的张量化神经网络在不同场景下无需重新训练的适应性与泛化能力,尤其评估其在非理想信号、传播和阵列条件下的鲁棒性。
本文早期结果发表于会议论文 1。与会议版本相比,本文进一步揭示了神经层压缩与协方差张量分解之间的联系,给出网络压缩能力的理论分析,并更全面地说明网络训练过程。此外,本文提出 Tucker 秩选择方法以提升网络性能,并从多个角度通过更多仿真验证所提网络的鲁棒性。
本文其余部分组织如下。第二节推导协方差张量输入模型;第三节提出用于二维 DOA 估计的张量化深度神经网络结构;第四节分析参数压缩能力和计算复杂度;第五节给出实验结果;第六节总结全文。本文符号列于表 I。

TABLE I. 符号列表。
II. 协方差张量输入模型
如图 1 所示,考虑一个 M × N M\times N M×N 均匀矩形阵列(Uniform Rectangular Array, URA),其传感器位置集合为:
S = { ( x S , y S ) ∣ x S = 0 , M − 1 d , y S = 0 , N − 1 d } . (1) \mathcal{S} =\{(x_{\mathcal{S}},y_{\mathcal{S}})\mid x_{\mathcal{S}}=0,M-1d,\; y_{\mathcal{S}}=0,N-1d\}. \tag{1} S={(xS,yS)∣xS=0,M−1d,yS=0,N−1d}.(1)
其中, M M M 和 N N N 分别表示沿 x x x 轴和 y y y 轴的传感器数量, d d d 为阵元间距,等于信号波长的一半。假设有 K K K 个互不相关的远场窄带信号从方向 { ( θ k , ϕ k ) , k = 1 , 2 , ... , K } \{(\theta_k,\phi_k),k=1,2,\ldots,K\} {(θk,ϕk),k=1,2,...,K} 入射到 S \mathcal{S} S,其中 θ k ∈ 0 , π \theta_k\in0,\\pi θk∈0,π 和 ϕ k ∈ 0 , π \phi_k\in0,\\pi ϕk∈0,π 分别表示第 k k k 个源的方位角和俯仰角。
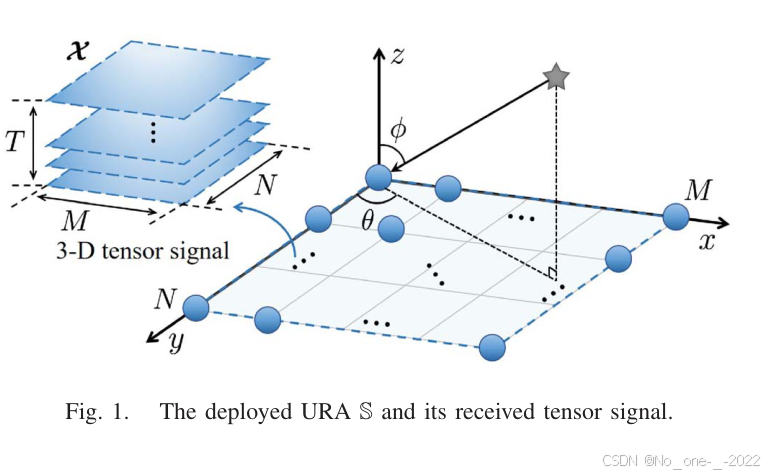
图 1. 部署的 URA S 及其接收张量信号。
URA 接收信号通常可写成矩阵形式 X = x ( 1 ) , x ( 2 ) , ... , x ( T ) ∈ C M N × T \mathbf{X}=\\mathbf{x}(1),\\mathbf{x}(2),\\ldots,\\mathbf{x}(T)\in\mathbb{C}^{MN\times T} X=x(1),x(2),...,x(T)∈CMN×T,其中第 t t t 个快照为:
x ( t ) = ∑ k = 1 K a ( μ k ) ⊗ b ( ν k ) s k ( t ) + n ( t ) ∈ C M N , ∀ t = 1 , 2 , ... , T . (2) \mathbf{x}(t) =\sum_{k=1}^{K} \left\\mathbf{a}(\\mu_k)\\otimes\\mathbf{b}(\\nu_k)\\rights_k(t) +\mathbf{n}(t) \in\mathbb{C}^{MN}, \quad \forall t=1,2,\ldots,T. \tag{2} x(t)=k=1∑Ka(μk)⊗b(νk)sk(t)+n(t)∈CMN,∀t=1,2,...,T.(2)
这里:
a ( μ k ) = 1 , e − j π μ k , ... , e − j π ( M − 1 ) μ k T ∈ C M , b ( ν k ) = 1 , e − j π ν k , ... , e − j π ( N − 1 ) ν k T ∈ C N (3) \begin{aligned} \mathbf{a}(\mu_k) &=\left1,e\^{-j\\pi\\mu_k},\\ldots,e\^{-j\\pi(M-1)\\mu_k}\\right^T \in\mathbb{C}^{M},\\ \mathbf{b}(\nu_k) &=\left1,e\^{-j\\pi\\nu_k},\\ldots,e\^{-j\\pi(N-1)\\nu_k}\\right^T \in\mathbb{C}^{N} \end{aligned} \tag{3} a(μk)b(νk)=1,e−jπμk,...,e−jπ(M−1)μkT∈CM,=1,e−jπνk,...,e−jπ(N−1)νkT∈CN(3)
分别表示 S \mathcal{S} S 沿 x x x 轴和 y y y 轴的导向向量,其中 μ k = sin ϕ k cos θ k \mu_k=\sin\phi_k\cos\theta_k μk=sinϕkcosθk, ν k = sin ϕ k sin θ k \nu_k=\sin\phi_k\sin\theta_k νk=sinϕksinθk。 s k ( t ) ∈ C s_k(t)\in\mathbb{C} sk(t)∈C 是第 t t t 个快照下第 k k k 个源的信号, n ( t ) ∼ C N ( 0 , σ n 2 I ) \mathbf{n}(t)\sim\mathcal{CN}(0,\sigma_n^2\mathbf{I}) n(t)∼CN(0,σn2I) 是独立同分布(i.i.d.)加性高斯白噪声向量, σ n 2 \sigma_n^2 σn2 为噪声功率, T T T 为快照数。
单快照向量 x ( t ) \mathbf{x}(t) x(t) 没有显式保留 URA 接收信号的二维结构,因此传统基于矩阵的信号模型无法保留多维信号特征。为了保留原始结构,本文直接将第 t t t 个快照建模为矩阵:
X ( t ) = ∑ k = 1 K a ( μ k ) ∘ b ( ν k ) s k ( t ) + N ( t ) ∈ C M × N , (4) \mathbf{X}(t) =\sum_{k=1}^{K} \left\\mathbf{a}(\\mu_k)\\circ\\mathbf{b}(\\nu_k)\\rights_k(t) +\mathbf{N}(t) \in\mathbb{C}^{M\times N}, \tag{4} X(t)=k=1∑Ka(μk)∘b(νk)sk(t)+N(t)∈CM×N,(4)
其中, N ( t ) ∼ C N ( 0 , σ n 2 I ) \mathbf{N}(t)\sim\mathcal{CN}(0,\sigma_n^2\mathbf{I}) N(t)∼CN(0,σn2I) 为 i.i.d. 加性高斯白噪声矩阵。进一步地,如图 1 所示,将总共 T T T 个快照沿时间维度连接,可构造三维张量:
X ≜ X ( 1 ) , X ( 2 ) , ... , X ( T ) × 3 = ∑ k = 1 K a ( μ k ) ∘ b ( ν k ) ∘ s k + N ∈ C M × N × T . (5) \begin{aligned} \boldsymbol{\mathcal{X}} &\triangleq \\mathbf{X}(1),\\mathbf{X}(2),\\ldots,\\mathbf{X}(T){\times 3}\\ &=\sum{k=1}^{K} \mathbf{a}(\mu_k)\circ\mathbf{b}(\nu_k)\circ\mathbf{s}_k +\boldsymbol{\mathcal{N}} \in\mathbb{C}^{M\times N\times T}. \end{aligned} \tag{5} X≜X(1),X(2),...,X(T)×3=k=1∑Ka(μk)∘b(νk)∘sk+N∈CM×N×T.(5)
其中, s k ≜ s k ( 1 ) , s k ( 2 ) , ... , s k ( T ) T ∈ C T \mathbf{s}k\triangleq s_k(1),s_k(2),\\ldots,s_k(T)^T\in\mathbb{C}^{T} sk≜sk(1),sk(2),...,sk(T)T∈CT 是第 k k k 个源的信号波形, N ≜ N ( 1 ) , N ( 2 ) , ... , N ( T ) × 3 \boldsymbol{\mathcal{N}}\triangleq\\mathbf{N}(1),\\mathbf{N}(2),\\ldots,\\mathbf{N}(T){\times 3} N≜N(1),N(2),...,N(T)×3 是加性高斯白噪声张量。
为了获得张量信号 X \boldsymbol{\mathcal{X}} X 的二阶统计量,推导四维协方差张量:
R ≜ E { X ( t ) ∘ X ∗ ( t ) } ∈ C M × N × M × N = ∑ k = 1 K σ k 2 a ( μ k ) ∘ b ( ν k ) ∘ a ∗ ( μ k ) ∘ b ∗ ( ν k ) + σ n 2 I . (6) \begin{aligned} \boldsymbol{\mathcal{R}} &\triangleq E\{\mathbf{X}(t)\circ\mathbf{X}^*(t)\} \in\mathbb{C}^{M\times N\times M\times N}\\ &=\sum_{k=1}^{K} \sigma_k^2\, \mathbf{a}(\mu_k)\circ\mathbf{b}(\nu_k) \circ\mathbf{a}^*(\mu_k)\circ\mathbf{b}^*(\nu_k) +\sigma_n^2\boldsymbol{\mathcal{I}}. \end{aligned} \tag{6} R≜E{X(t)∘X∗(t)}∈CM×N×M×N=k=1∑Kσk2a(μk)∘b(νk)∘a∗(μk)∘b∗(νk)+σn2I.(6)
其中, σ k 2 ≜ E { ∣ s k ( t ) ∣ 2 } \sigma_k^2\triangleq E\{|s_k(t)|^2\} σk2≜E{∣sk(t)∣2} 是第 k k k 个源信号的功率。这样,多维信号特征被保留在协方差张量 R \boldsymbol{\mathcal{R}} R 中,不确定的信号波形和噪声分量则由信号功率和噪声功率替代,随后可作为深度神经网络输入以恢复角度信息。
考虑到深度神经网络通常更高效地处理实值数据,本文将 R \boldsymbol{\mathcal{R}} R 的实部和虚部沿额外维度拼接,构造五维实值协方差张量:
Y = ℜ { R } , ℑ { R } × 5 ∈ R M × N × M × N × 2 , (7) \boldsymbol{\mathcal{Y}} =\left\\Re\\{\\boldsymbol{\\mathcal{R}}\\},\\Im\\{\\boldsymbol{\\mathcal{R}}\\}\\right_{\times 5} \in\mathbb{R}^{M\times N\times M\times N\times 2}, \tag{7} Y=ℜ{R},ℑ{R}×5∈RM×N×M×N×2,(7)
作为网络输入。在实际中,协方差张量 R \boldsymbol{\mathcal{R}} R 由如下估计替代:
R ^ = 1 T X × 3 X ∗ . (8) \widehat{\boldsymbol{\mathcal{R}}} =\frac{1}{T}\boldsymbol{\mathcal{X}}\times_3\boldsymbol{\mathcal{X}}^*. \tag{8} R =T1X×3X∗.(8)
也就是说, R ^ \widehat{\boldsymbol{\mathcal{R}}} R 是三维张量信号 X \boldsymbol{\mathcal{X}} X 与其共轭沿时间维度收缩后的平均值。
III. 用于二维 DOA 估计的张量化深度神经网络
本节建立用于参数压缩的张量化神经层分解原理,提出用于提取信号特征的张量化前馈过程,并设计用于训练压缩参数的反向传播过程。此外,本文还给出一种秩选择方法,以优化张量化神经网络拓扑。
A. 张量神经层分解
传统基于矩阵处理的深度神经网络 16-18 会将协方差矩阵 R ≜ E { x ( t ) x H ( t ) } ∈ C M N × M N \mathbf{R}\triangleq E\{\mathbf{x}(t)\mathbf{x}^H(t)\}\in\mathbb{C}^{MN\times MN} R≜E{x(t)xH(t)}∈CMN×MN 向量化为长输入向量 y = ℜ { v e c ( R ) } T , ℑ { v e c ( R ) } T T ∈ R 2 M 2 N 2 \mathbf{y}=\\Re\\{\\mathrm{vec}(\\mathbf{R})\\}\^T,\\Im\\{\\mathrm{vec}(\\mathbf{R})\\}\^T^T\in\mathbb{R}^{2M^2N^2} y=ℜ{vec(R)}T,ℑ{vec(R)}TT∈R2M2N2。随后,输入 y \mathbf{y} y 乘以参数矩阵 G 0 \mathbf{G}_0 G0,得到隐藏状态向量 h 1 = f 1 ( G 0 y ) \mathbf{h}_1=f_1(\mathbf{G}_0\mathbf{y}) h1=f1(G0y)。第一个隐藏状态向量继续通过参数矩阵 { G 1 , G 2 , ... , G L − 1 } \{\mathbf{G}_1,\mathbf{G}2,\ldots,\mathbf{G}{L-1}\} {G1,G2,...,GL−1} 传播,生成 L − 1 L-1 L−1 个隐藏状态向量 { h 2 , h 3 , ... , h L } \{\mathbf{h}_2,\mathbf{h}_3,\ldots,\mathbf{h}L\} {h2,h3,...,hL},即 h l = f l ( G l − 1 h l − 1 ) \mathbf{h}l=f_l(\mathbf{G}{l-1}\mathbf{h}{l-1}) hl=fl(Gl−1hl−1), ∀ l = 2 , 3 , ... , L \forall l=2,3,\ldots,L ∀l=2,3,...,L。其中, L L L 为网络深度, f l ( ⋅ ) f_l(\cdot) fl(⋅) 为第 l l l 层非线性激活函数。
为了避免上述向量化结构带来的大规模参数训练开销,本文采用张量化神经层(tensorization in deep neural layers),从协方差张量输入 Y \boldsymbol{\mathcal{Y}} Y 中提取张量隐藏状态。具体而言,为保持信号特征的五维张量结构,协方差张量 Y \boldsymbol{\mathcal{Y}} Y 被传播到五维隐藏状态张量 H 1 ∈ R I 1 , 1 × I 1 , 2 × I 1 , 3 × I 1 , 4 × I 1 , 5 \boldsymbol{\mathcal{H}}1\in\mathbb{R}^{I{1,1}\times I_{1,2}\times I_{1,3}\times I_{1,4}\times I_{1,5}} H1∈RI1,1×I1,2×I1,3×I1,4×I1,5。
本文将 Y \boldsymbol{\mathcal{Y}} Y 的 Tucker 分解表示为:
Y = G × 1 V 0 , 1 × 2 V 0 , 2 × 3 V 0 , 3 × 4 V 0 , 4 × 5 V 0 , 5 . (9) \boldsymbol{\mathcal{Y}} =\boldsymbol{\mathcal{G}} \times_1\mathbf{V}{0,1} \times_2\mathbf{V}{0,2} \times_3\mathbf{V}{0,3} \times_4\mathbf{V}{0,4} \times_5\mathbf{V}_{0,5}. \tag{9} Y=G×1V0,1×2V0,2×3V0,3×4V0,4×5V0,5.(9)
其中, G ∈ R I 1 , 1 × I 1 , 2 × I 1 , 3 × I 1 , 4 × I 1 , 5 \boldsymbol{\mathcal{G}}\in\mathbb{R}^{I_{1,1}\times I_{1,2}\times I_{1,3}\times I_{1,4}\times I_{1,5}} G∈RI1,1×I1,2×I1,3×I1,4×I1,5 是嵌入了所提取信号特征的五维核心张量, V 0 , 1 ∈ R M × I 1 , 1 \mathbf{V}{0,1}\in\mathbb{R}^{M\times I{1,1}} V0,1∈RM×I1,1、 V 0 , 2 ∈ R N × I 1 , 2 \mathbf{V}{0,2}\in\mathbb{R}^{N\times I{1,2}} V0,2∈RN×I1,2、 V 0 , 3 ∈ R M × I 1 , 3 \mathbf{V}{0,3}\in\mathbb{R}^{M\times I{1,3}} V0,3∈RM×I1,3、 V 0 , 4 ∈ R N × I 1 , 4 \mathbf{V}{0,4}\in\mathbb{R}^{N\times I{1,4}} V0,4∈RN×I1,4、 V 0 , 5 ∈ R 2 × I 1 , 5 \mathbf{V}{0,5}\in\mathbb{R}^{2\times I{1,5}} V0,5∈R2×I1,5 为 Tucker 因子矩阵, { I 1 , 1 , I 1 , 2 , ... , I 1 , 5 } \{I_{1,1},I_{1,2},\ldots,I_{1,5}\} {I1,1,I1,2,...,I1,5} 表示 Tucker 秩序列。
五个 Tucker 因子 { V 0 , 1 , V 0 , 2 , ... , V 0 , 5 } \{\mathbf{V}{0,1},\mathbf{V}{0,2},\ldots,\mathbf{V}_{0,5}\} {V0,1,V0,2,...,V0,5} 分别作为从 Y \boldsymbol{\mathcal{Y}} Y 到 G \boldsymbol{\mathcal{G}} G 的五个维度投影基。将隐藏状态张量 H 1 \boldsymbol{\mathcal{H}}_1 H1 设为经过非线性激活函数滤波后的 G \boldsymbol{\mathcal{G}} G,即 H 1 ≜ f 1 ( G ) \boldsymbol{\mathcal{H}}_1\triangleq f_1(\boldsymbol{\mathcal{G}}) H1≜f1(G),则从 Y \boldsymbol{\mathcal{Y}} Y 到 H 1 \boldsymbol{\mathcal{H}}_1 H1 的变换可写为如下逆 Tucker 分解:
H 1 = f 1 ( Y × 1 V 0 , 1 † × 2 V 0 , 2 † × 3 V 0 , 3 † × 4 V 0 , 4 † × 5 V 0 , 5 † ) . (10) \boldsymbol{\mathcal{H}}1 =f_1\left( \boldsymbol{\mathcal{Y}} \times_1\mathbf{V}^{\dagger}{0,1} \times_2\mathbf{V}^{\dagger}{0,2} \times_3\mathbf{V}^{\dagger}{0,3} \times_4\mathbf{V}^{\dagger}{0,4} \times_5\mathbf{V}^{\dagger}{0,5} \right). \tag{10} H1=f1(Y×1V0,1†×2V0,2†×3V0,3†×4V0,4†×5V0,5†).(10)
其中,逆 Tucker 因子矩阵 V 0 , 1 † ∈ R M × I 1 , 1 \mathbf{V}^{\dagger}{0,1}\in\mathbb{R}^{M\times I{1,1}} V0,1†∈RM×I1,1、 V 0 , 2 † ∈ R N × I 1 , 2 \mathbf{V}^{\dagger}{0,2}\in\mathbb{R}^{N\times I{1,2}} V0,2†∈RN×I1,2、 V 0 , 3 † ∈ R M × I 1 , 3 \mathbf{V}^{\dagger}{0,3}\in\mathbb{R}^{M\times I{1,3}} V0,3†∈RM×I1,3、 V 0 , 4 † ∈ R N × I 1 , 4 \mathbf{V}^{\dagger}{0,4}\in\mathbb{R}^{N\times I{1,4}} V0,4†∈RN×I1,4、 V 0 , 5 † ∈ R 2 × I 1 , 5 \mathbf{V}^{\dagger}{0,5}\in\mathbb{R}^{2\times I{1,5}} V0,5†∈R2×I1,5 包含第一神经层的压缩参数。
注:
H 1 \boldsymbol{\mathcal{H}}_1 H1 的来源。 这里的第一层隐藏状态张量不是由协方差张量简单拉平成向量后得到的,而是由输入协方差张量 Y \boldsymbol{\mathcal{Y}} Y 沿 5 个模态分别与 V 0 , 1 † , ... , V 0 , 5 † \mathbf{V}^{\dagger}{0,1},\ldots,\mathbf{V}^{\dagger}{0,5} V0,1†,...,V0,5† 做张量-矩阵乘积,再经过非线性激活函数 f 1 ( ⋅ ) f_1(\cdot) f1(⋅) 得到。它可以理解为网络从 URA 协方差张量中提取出的第一层张量特征。
五个 Tucker 因子是否学习得到。 式 (9) 中的 V 0 , 1 , ... , V 0 , 5 \mathbf{V}{0,1},\ldots,\mathbf{V}{0,5} V0,1,...,V0,5 用来说明 Tucker 分解视角;实际神经网络训练的是式 (10) 中的逆 Tucker 因子 V 0 , 1 † , ... , V 0 , 5 † \mathbf{V}^{\dagger}{0,1},\ldots,\mathbf{V}^{\dagger}{0,5} V0,1†,...,V0,5†。这些逆 Tucker 因子就是第一层张量化神经层的可训练参数,会通过后文的 Huber 损失和张量化反向传播更新。
秩和参数的区别。 I 1 , 1 , ... , I 1 , 5 I_{1,1},\ldots,I_{1,5} I1,1,...,I1,5 决定 H 1 \boldsymbol{\mathcal{H}}_1 H1 的尺寸,也决定压缩强度;它们是 Tucker 秩序列,属于网络拓扑超参数。论文后文用贝叶斯优化选择这些秩,而不是把它们当作普通权重用梯度下降训练。
输入元素数量并没有减少。 以文中的 8 × 8 8\times8 8×8 URA 示例为例,向量化协方差输入 y ∈ R 8192 \mathbf{y}\in\mathbb{R}^{8192} y∈R8192 与协方差张量输入 Y ∈ R 8 × 8 × 8 × 8 × 2 \boldsymbol{\mathcal{Y}}\in\mathbb{R}^{8\times8\times8\times8\times2} Y∈R8×8×8×8×2 的元素数量相同,因为 8 × 8 × 8 × 8 × 2 = 8192 8\times8\times8\times8\times2=8192 8×8×8×8×2=8192。张量化表示减少的不是输入数据量,而是神经层的可训练参数量:传统矩阵层需要一个大矩阵 G 0 ∈ R 8192 × 512 \mathbf{G}_0\in\mathbb{R}^{8192\times512} G0∈R8192×512,而张量化层用五个较小的逆 Tucker 因子矩阵来替代它。
每个张量化隐藏层的结构。 可以把一个张量化神经层理解为"沿 5 个模态分别做线性变换,再接一个非线性激活函数",即由五个逆 Tucker 因子矩阵和一个 f l ( ⋅ ) f_l(\cdot) fl(⋅) 共同完成。但它不是 5 个串联的普通全连接层,而是同一个张量层内部的 5 个模态投影。后续隐藏层同理,按 Y → H 1 → H 2 → ⋯ → H L \boldsymbol{\mathcal{Y}}\rightarrow\boldsymbol{\mathcal{H}}_1\rightarrow\boldsymbol{\mathcal{H}}_2\rightarrow\cdots\rightarrow\boldsymbol{\mathcal{H}}_L Y→H1→H2→⋯→HL 逐层前向传播。
隐藏状态不是直接训练参数。 H 1 , ... , H L \boldsymbol{\mathcal{H}}1,\ldots,\boldsymbol{\mathcal{H}}L H1,...,HL 是给定输入张量和当前网络参数后,前向计算得到的中间特征张量;真正通过反向传播训练更新的是各层的逆 Tucker 因子矩阵 V l − 1 , 1 † , ... , V l − 1 , 5 † \mathbf{V}^{\dagger}{l-1,1},\ldots,\mathbf{V}^{\dagger}{l-1,5} Vl−1,1†,...,Vl−1,5† 以及最后的输出层权重张量 W \boldsymbol{\mathcal{W}} W。
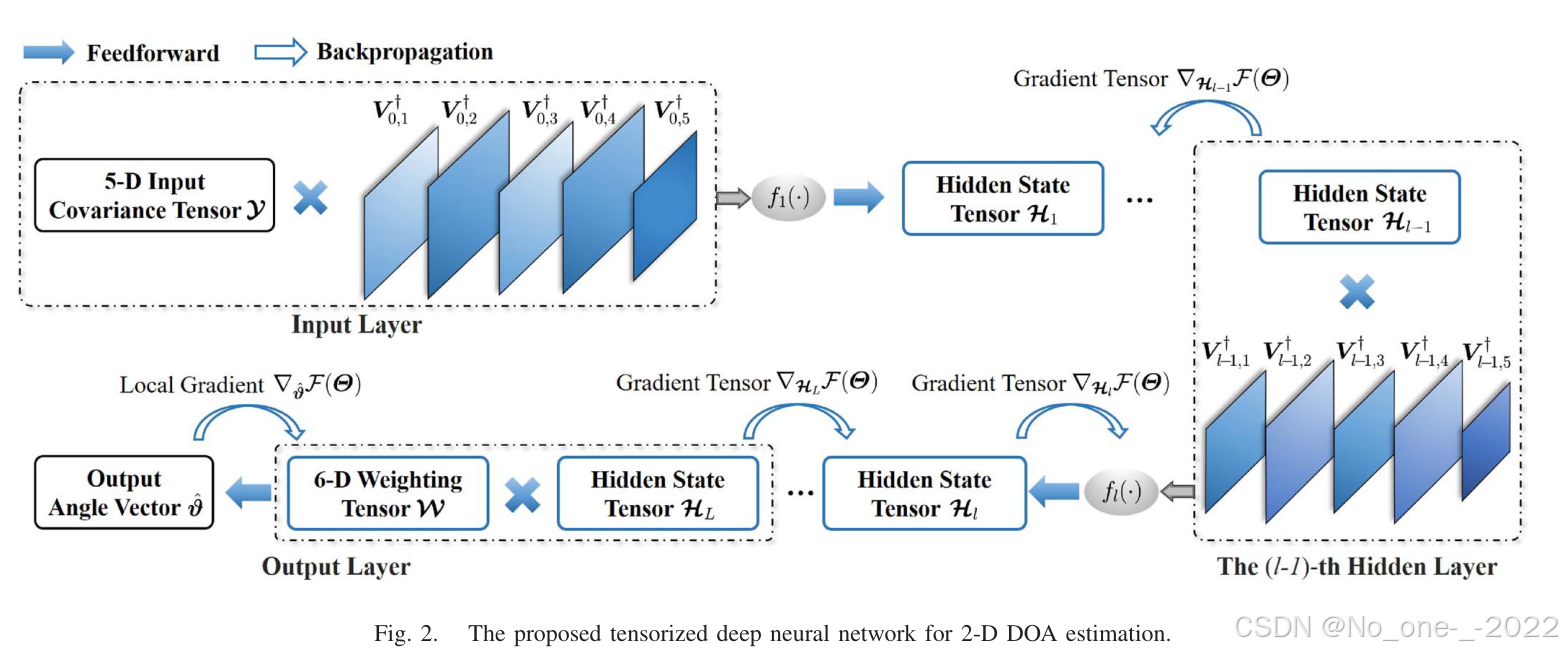
图 2. 用于二维 DOA 估计的所提张量化深度神经网络。
协方差张量 Y \boldsymbol{\mathcal{Y}} Y 与五个逆 Tucker 因子矩阵 { V 0 , h † , h = 1 , 2 , ... , 5 } \{\mathbf{V}^{\dagger}{0,h},h=1,2,\ldots,5\} {V0,h†,h=1,2,...,5} 之间的多线性张量-矩阵乘积可显著减少乘法次数。例如,对于 8 × 8 8\times8 8×8 URA,向量化协方差输入为 y ∈ R 8192 \mathbf{y}\in\mathbb{R}^{8192} y∈R8192,对应协方差张量输入为 Y ∈ R 8 × 8 × 8 × 8 × 2 \boldsymbol{\mathcal{Y}}\in\mathbb{R}^{8\times8\times8\times8\times2} Y∈R8×8×8×8×2。在基于矩阵的神经层中, y \mathbf{y} y 与参数矩阵 G 0 ∈ R 8192 × 512 \mathbf{G}0\in\mathbb{R}^{8192\times512} G0∈R8192×512 相乘得到 h 1 ∈ R 512 \mathbf{h}1\in\mathbb{R}^{512} h1∈R512; G 0 \mathbf{G}0 G0 中参数数量为 4,194,304,计算 h 1 \mathbf{h}1 h1 所需乘法次数也为 4,194,304。相反,张量化神经层计算 Y \boldsymbol{\mathcal{Y}} Y 与五个逆 Tucker 因子矩阵之间的张量-矩阵乘积,其中 V 0 , 1 † , V 0 , 2 † , V 0 , 3 † , V 0 , 4 † ∈ R 8 × 4 \mathbf{V}^{\dagger}{0,1},\mathbf{V}^{\dagger}{0,2},\mathbf{V}^{\dagger}{0,3},\mathbf{V}^{\dagger}{0,4}\in\mathbb{R}^{8\times4} V0,1†,V0,2†,V0,3†,V0,4†∈R8×4, V 0 , 5 † ∈ R 2 × 2 \mathbf{V}^{\dagger}{0,5}\in\mathbb{R}^{2\times2} V0,5†∈R2×2,得到隐藏状态张量 H 1 ∈ R 4 × 4 × 4 × 4 × 2 \boldsymbol{\mathcal{H}}_1\in\mathbb{R}^{4\times4\times4\times4\times2} H1∈R4×4×4×4×2。这些因子矩阵中的参数数量仅为 132 ≪ 4 , 194 , 304 132\ll4,194,304 132≪4,194,304,计算 H 1 \boldsymbol{\mathcal{H}}_1 H1 所需乘法次数为 550 , 144 ≪ 4 , 194 , 304 550,144\ll4,194,304 550,144≪4,194,304。这种紧凑参数表示有助于加快训练,并使信号特征传播的计算更高效。
B. 用于二维 DOA 估计的张量前馈
为了实现二维 DOA 估计,张量化前馈过程依次计算隐藏状态张量和输出。与式 (10) 中第一个隐藏状态张量 H 1 \boldsymbol{\mathcal{H}}1 H1 的推导类似,第 l l l 个隐藏状态张量 H l ∈ R I l , 1 × I l , 2 × I l , 3 × I l , 4 × I l , 5 \boldsymbol{\mathcal{H}}l\in\mathbb{R}^{I{l,1}\times I{l,2}\times I_{l,3}\times I_{l,4}\times I_{l,5}} Hl∈RIl,1×Il,2×Il,3×Il,4×Il,5 可由第 ( l − 1 ) (l-1) (l−1) 个隐藏状态张量 H l − 1 ∈ R I l − 1 , 1 × I l − 1 , 2 × I l − 1 , 3 × I l − 1 , 4 × I l − 1 , 5 \boldsymbol{\mathcal{H}}{l-1}\in\mathbb{R}^{I{l-1,1}\times I_{l-1,2}\times I_{l-1,3}\times I_{l-1,4}\times I_{l-1,5}} Hl−1∈RIl−1,1×Il−1,2×Il−1,3×Il−1,4×Il−1,5 的逆 Tucker 分解得到:
H l = f l ( H l − 1 × 1 V l − 1 , 1 † × 2 V l − 1 , 2 † × 3 V l − 1 , 3 † × 4 V l − 1 , 4 † × 5 V l − 1 , 5 † ) , ∀ l = 2 , 3 , ... , L . (11) \boldsymbol{\mathcal{H}}l =f_l\left( \boldsymbol{\mathcal{H}}{l-1} \times_1\mathbf{V}^{\dagger}{l-1,1} \times_2\mathbf{V}^{\dagger}{l-1,2} \times_3\mathbf{V}^{\dagger}{l-1,3} \times_4\mathbf{V}^{\dagger}{l-1,4} \times_5\mathbf{V}^{\dagger}_{l-1,5} \right), \quad \forall l=2,3,\ldots,L. \tag{11} Hl=fl(Hl−1×1Vl−1,1†×2Vl−1,2†×3Vl−1,3†×4Vl−1,4†×5Vl−1,5†),∀l=2,3,...,L.(11)
其中,逆 Tucker 因子矩阵 V l − 1 , h † ∈ R I l − 1 , h × I l , h \mathbf{V}^{\dagger}{l-1,h}\in\mathbb{R}^{I{l-1,h}\times I_{l,h}} Vl−1,h†∈RIl−1,h×Il,h( h = 1 , 2 , ... , 5 h=1,2,\ldots,5 h=1,2,...,5)包含第 l l l 个张量化神经层的压缩参数, f l ( ⋅ ) f_l(\cdot) fl(⋅) 为相应激活函数。
对于二维 DOA 估计,本文将张量化神经网络设计为回归求解器。第 L L L 个隐藏状态张量 H L \boldsymbol{\mathcal{H}}L HL 与六维输出层权重张量 W ∈ R I L , 1 × I L , 2 × I L , 3 × I L , 4 × I L , 5 × 2 K \boldsymbol{\mathcal{W}}\in\mathbb{R}^{I{L,1}\times I_{L,2}\times I_{L,3}\times I_{L,4}\times I_{L,5}\times 2K} W∈RIL,1×IL,2×IL,3×IL,4×IL,5×2K 进行收缩,以估计角度向量:
ϑ ≜ θ 1 , θ 2 , ... , θ K , ϕ 1 , ϕ 2 , ... , ϕ K T ∈ R 2 K . (12) \boldsymbol{\vartheta} \triangleq \\theta_1,\\theta_2,\\ldots,\\theta_K,\\phi_1,\\phi_2,\\ldots,\\phi_K^T \in\mathbb{R}^{2K}. \tag{12} ϑ≜θ1,θ2,...,θK,ϕ1,ϕ2,...,ϕKT∈R2K.(12)
为避免输出值落在有效视场之外,进一步采用 HardTanh 激活函数约束输出层,即估计角度向量 ϑ ^ ≜ θ \^ 1 , θ \^ 2 , ... , θ \^ K , ϕ \^ 1 , ϕ \^ 2 , ... , ϕ \^ K T \widehat{\boldsymbol{\vartheta}}\triangleq\\widehat{\\theta}_1,\\widehat{\\theta}_2,\\ldots,\\widehat{\\theta}_K,\\widehat{\\phi}_1,\\widehat{\\phi}_2,\\ldots,\\widehat{\\phi}_K^T ϑ ≜θ 1,θ 2,...,θ K,ϕ 1,ϕ 2,...,ϕ KT 为:
ϑ ^ = H a r d T a n h ( H L × 1 , 2 , 3 , 4 , 5 W ) = { 0 , H L × 1 , 2 , 3 , 4 , 5 W < 0 , π , H L × 1 , 2 , 3 , 4 , 5 W ≥ π , H L × 1 , 2 , 3 , 4 , 5 W , o t h e r w i s e . (13) \widehat{\boldsymbol{\vartheta}} =\mathrm{HardTanh}\left(\boldsymbol{\mathcal{H}}L\times{1,2,3,4,5}\boldsymbol{\mathcal{W}}\right) = \left\{ \begin{array}{ll} 0, & \boldsymbol{\mathcal{H}}L\times{1,2,3,4,5}\boldsymbol{\mathcal{W}}<0,\\ \pi, & \boldsymbol{\mathcal{H}}L\times{1,2,3,4,5}\boldsymbol{\mathcal{W}}\ge\pi,\\ \boldsymbol{\mathcal{H}}L\times{1,2,3,4,5}\boldsymbol{\mathcal{W}}, & \mathrm{otherwise}. \end{array} \right. \tag{13} ϑ =HardTanh(HL×1,2,3,4,5W)=⎩ ⎨ ⎧0,π,HL×1,2,3,4,5W,HL×1,2,3,4,5W<0,HL×1,2,3,4,5W≥π,otherwise.(13)
其中, θ ^ k \widehat{\theta}_k θ k 和 ϕ ^ k \widehat{\phi}_k ϕ k 分别表示第 k k k 个源的估计方位角和俯仰角。本文采用鲁棒且可微的 Huber 损失函数。关于可训练神经层参数集合:
注:
为什么张量收缩后得到向量。 这里并不是两个普通 5D 张量完全收缩。隐藏状态 H L \boldsymbol{\mathcal{H}}L HL 是 5D 张量,而输出层权重 W ∈ R I L , 1 × I L , 2 × I L , 3 × I L , 4 × I L , 5 × 2 K \boldsymbol{\mathcal{W}}\in\mathbb{R}^{I{L,1}\times I_{L,2}\times I_{L,3}\times I_{L,4}\times I_{L,5}\times 2K} W∈RIL,1×IL,2×IL,3×IL,4×IL,5×2K 是 6D 张量。收缩 × 1 , 2 , 3 , 4 , 5 \times_{1,2,3,4,5} ×1,2,3,4,5 只沿前 5 个维度求和,第 6 个维度 2 K 2K 2K 保留下来,因此结果是一个 2 K 2K 2K 维向量。
等价理解。 可以把 W \boldsymbol{\mathcal{W}} W 看成 2 K 2K 2K 个 5D 权重模板。每个模板都与 H L \boldsymbol{\mathcal{H}}_L HL 做一次内积,得到一个标量输出; 2 K 2K 2K 个标量排列起来,就得到 ϑ ^ ∈ R 2 K \widehat{\boldsymbol{\vartheta}}\in\mathbb{R}^{2K} ϑ ∈R2K,对应 K K K 个方位角和 K K K 个俯仰角。
和线性输出层的关系。 是的,这里的收缩本质上就是一个线性读出层。若把 H L \boldsymbol{\mathcal{H}}_L HL 展平成 v e c ( H L ) \mathrm{vec}(\boldsymbol{\mathcal{H}}_L) vec(HL),并把 W \boldsymbol{\mathcal{W}} W 的前 5 个维度展平成输出矩阵,则 H L × 1 , 2 , 3 , 4 , 5 W \boldsymbol{\mathcal{H}}L\times{1,2,3,4,5}\boldsymbol{\mathcal{W}} HL×1,2,3,4,5W 等价于普通全连接输出层 v e c ( H L ) T W o u t \mathrm{vec}(\boldsymbol{\mathcal{H}}L)^T\mathbf{W}{\mathrm{out}} vec(HL)TWout。论文保留张量收缩写法,是为了沿用前面张量特征的表示;式 (13) 中这个线性输出之后还接了 HardTanh,用来把角度限制在 0 , π 0,\\pi 0,π。需要注意的是,论文公式中没有显式写出 bias 项。
Θ = { V 0 , h † , V 1 , h † , ... , V L − 1 , h † , W , h = 1 , 2 , ... , 5 } (14) \boldsymbol{\Theta} =\left\{ \mathbf{V}^{\dagger}{0,h}, \mathbf{V}^{\dagger}{1,h}, \ldots, \mathbf{V}^{\dagger}_{L-1,h}, \boldsymbol{\mathcal{W}}, \;h=1,2,\ldots,5 \right\} \tag{14} Θ={V0,h†,V1,h†,...,VL−1,h†,W,h=1,2,...,5}(14)
的 Huber 损失定义为:
F ( Θ ) = { 1 4 K ∥ ϑ − ϑ ^ ∥ 2 2 , ∥ ϑ − ϑ ^ ∥ 1 / K ≤ γ , γ 2 K ( ∥ ϑ − ϑ ^ ∥ 1 − 1 2 γ ) , o t h e r w i s e . (15) F(\boldsymbol{\Theta}) = \left\{ \begin{array}{ll} \dfrac{1}{4K}\left\|\boldsymbol{\vartheta}-\widehat{\boldsymbol{\vartheta}}\right\|_2^2, & \left\|\boldsymbol{\vartheta}-\widehat{\boldsymbol{\vartheta}}\right\|_1/K\le\gamma,\\ \dfrac{\gamma}{2K} \left( \left\|\boldsymbol{\vartheta}-\widehat{\boldsymbol{\vartheta}}\right\|_1-\dfrac{1}{2}\gamma \right), & \mathrm{otherwise}. \end{array} \right. \tag{15} F(Θ)=⎩ ⎨ ⎧4K1 ϑ−ϑ 22,2Kγ( ϑ−ϑ 1−21γ), ϑ−ϑ 1/K≤γ,otherwise.(15)
其中, γ > 0 \gamma>0 γ>0 是在 MAE 和 MSE 之间切换计算的阈值。在实践中,一组输入协方差张量及其对应标签 { ( Y p , ϑ p ) , p = 1 , 2 , ... , P } \{(\boldsymbol{\mathcal{Y}}_p,\boldsymbol{\vartheta}_p),p=1,2,\ldots,P\} {(Yp,ϑp),p=1,2,...,P} 用于训练张量化深度神经网络,其中 P P P 表示训练样本数。相应 Huber 损失 { F p ( Θ ) , p = 1 , 2 , ... , P } \{F_p(\boldsymbol{\Theta}),p=1,2,\ldots,P\} {Fp(Θ),p=1,2,...,P} 的梯度用于在张量化反向传播中迭代更新参数。为简洁起见,后文省略下标 p p p。
C. 用于网络训练的张量化反向传播
为了训练张量化深度神经网络,每个样本的 Huber 损失被反向传播,以更新逆 Tucker 因子矩阵和输出层权重张量。第 k k k 个源估计方位角对应的局部梯度为:
∇ θ ^ k F ( Θ ) ≜ ∂ F ( Θ ) ∂ θ ^ k = ∂ F ( Θ ) ∂ ϑ ^ ∂ ϑ ^ ∂ θ ^ k = ∂ F ( Θ ) ∂ ϑ ^ e k , (16) \nabla_{\widehat{\theta}_k}F(\boldsymbol{\Theta}) \triangleq \frac{\partial F(\boldsymbol{\Theta})}{\partial \widehat{\theta}_k} = \frac{\partial F(\boldsymbol{\Theta})}{\partial\widehat{\boldsymbol{\vartheta}}} \frac{\partial\widehat{\boldsymbol{\vartheta}}}{\partial\widehat{\theta}_k} = \frac{\partial F(\boldsymbol{\Theta})}{\partial\widehat{\boldsymbol{\vartheta}}}\mathbf{e}_k, \tag{16} ∇θ kF(Θ)≜∂θ k∂F(Θ)=∂ϑ ∂F(Θ)∂θ k∂ϑ =∂ϑ ∂F(Θ)ek,(16)
其中, e k ∈ R 2 K \mathbf{e}_k\in\mathbb{R}^{2K} ek∈R2K 是除第 k k k 个元素为 1 1 1 外其余元素全为 0 0 0 的向量。于是, F ( Θ ) F(\boldsymbol{\Theta}) F(Θ) 关于输出层权重张量 W \boldsymbol{\mathcal{W}} W 中对应 θ ^ k \widehat{\theta}_k θ k 的切片的导数为:
∂ F ( Θ ) ∂ W ( ⋅ , ⋅ , ⋅ , ⋅ , ⋅ , k ) = ∂ F ( Θ ) ∂ θ ^ k ∂ θ ^ k ∂ W ( ⋅ , ⋅ , ⋅ , ⋅ , ⋅ , k ) = ∇ θ ^ k F ( Θ ) H L . (17) \frac{\partial F(\boldsymbol{\Theta})} {\partial \boldsymbol{\mathcal{W}}(\cdot,\cdot,\cdot,\cdot,\cdot,k)} = \frac{\partial F(\boldsymbol{\Theta})}{\partial\widehat{\theta}_k} \frac{\partial\widehat{\theta}k} {\partial \boldsymbol{\mathcal{W}}(\cdot,\cdot,\cdot,\cdot,\cdot,k)} = \nabla{\widehat{\theta}_k}F(\boldsymbol{\Theta})\boldsymbol{\mathcal{H}}_L. \tag{17} ∂W(⋅,⋅,⋅,⋅,⋅,k)∂F(Θ)=∂θ k∂F(Θ)∂W(⋅,⋅,⋅,⋅,⋅,k)∂θ k=∇θ kF(Θ)HL.(17)
类似地,第 k k k 个源估计俯仰角对应的局部梯度为:
∇ ϕ ^ k F ( Θ ) ≜ ∂ F ( Θ ) ∂ ϕ ^ k = ∂ F ( Θ ) ∂ ϑ ^ ∂ ϑ ^ ∂ ϕ ^ k = ∂ F ( Θ ) ∂ ϑ ^ e k + K . (18) \nabla_{\widehat{\phi}_k}F(\boldsymbol{\Theta}) \triangleq \frac{\partial F(\boldsymbol{\Theta})}{\partial \widehat{\phi}_k} = \frac{\partial F(\boldsymbol{\Theta})}{\partial\widehat{\boldsymbol{\vartheta}}} \frac{\partial\widehat{\boldsymbol{\vartheta}}}{\partial\widehat{\phi}k} = \frac{\partial F(\boldsymbol{\Theta})}{\partial\widehat{\boldsymbol{\vartheta}}}\mathbf{e}{k+K}. \tag{18} ∇ϕ kF(Θ)≜∂ϕ k∂F(Θ)=∂ϑ ∂F(Θ)∂ϕ k∂ϑ =∂ϑ ∂F(Θ)ek+K.(18)
相应地, F ( Θ ) F(\boldsymbol{\Theta}) F(Θ) 关于 ϕ ^ k \widehat{\phi}_k ϕ k 对应输出层权重张量切片的导数为:
∂ F ( Θ ) ∂ W ( ⋅ , ⋅ , ⋅ , ⋅ , ⋅ , K + k ) = ∇ ϕ ^ k F ( Θ ) H L . (19) \frac{\partial F(\boldsymbol{\Theta})} {\partial \boldsymbol{\mathcal{W}}(\cdot,\cdot,\cdot,\cdot,\cdot,K+k)} = \nabla_{\widehat{\phi}_k}F(\boldsymbol{\Theta})\boldsymbol{\mathcal{H}}_L. \tag{19} ∂W(⋅,⋅,⋅,⋅,⋅,K+k)∂F(Θ)=∇ϕ kF(Θ)HL.(19)
因此,在网络训练第 ( p + 1 ) (p+1) (p+1) 次迭代中,权重张量 W \boldsymbol{\mathcal{W}} W 更新为:
W ( p + 1 ) = W ( p ) − η ∂ F ( Θ ) ∂ W , (20) \boldsymbol{\mathcal{W}}^{(p+1)} =\boldsymbol{\mathcal{W}}^{(p)} -\eta\frac{\partial F(\boldsymbol{\Theta})}{\partial\boldsymbol{\mathcal{W}}}, \tag{20} W(p+1)=W(p)−η∂W∂F(Θ),(20)
其中, η > 0 \eta>0 η>0 表示学习率。更新输出层权重张量后, F ( Θ ) F(\boldsymbol{\Theta}) F(Θ) 关于输出角度向量 ϑ ^ \widehat{\boldsymbol{\vartheta}} ϑ 的局部梯度为:
∇ ϑ ^ F ( Θ ) ≜ ∇ θ \^ 1 F ( Θ ) , ... , ∇ θ \^ K F ( Θ ) , ∇ ϕ \^ 1 F ( Θ ) , ... , ∇ ϕ \^ K F ( Θ ) T ∈ R 2 K . (21) \nabla_{\widehat{\boldsymbol{\vartheta}}}F(\boldsymbol{\Theta}) \triangleq \left \\nabla_{\\widehat{\\theta}_1}F(\\boldsymbol{\\Theta}), \\ldots, \\nabla_{\\widehat{\\theta}_K}F(\\boldsymbol{\\Theta}), \\nabla_{\\widehat{\\phi}_1}F(\\boldsymbol{\\Theta}), \\ldots, \\nabla_{\\widehat{\\phi}_K}F(\\boldsymbol{\\Theta}) \\right^T \in\mathbb{R}^{2K}. \tag{21} ∇ϑ F(Θ)≜∇θ 1F(Θ),...,∇θ KF(Θ),∇ϕ 1F(Θ),...,∇ϕ KF(Θ)T∈R2K.(21)
该梯度继续反向传播到隐藏层。具体地, F ( Θ ) F(\boldsymbol{\Theta}) F(Θ) 关于第 L L L 个隐藏状态张量 H L \boldsymbol{\mathcal{H}}_L HL 的局部梯度为:
∇ H L F ( Θ ) ≜ ∂ F ( Θ ) ∂ H L = ∂ F ( Θ ) ∂ ϑ ^ ∂ ϑ ^ ∂ H L = W × 6 ∇ ϑ ^ F ( Θ ) . (22) \nabla_{\boldsymbol{\mathcal{H}}_L}F(\boldsymbol{\Theta}) \triangleq \frac{\partial F(\boldsymbol{\Theta})}{\partial\boldsymbol{\mathcal{H}}_L} = \frac{\partial F(\boldsymbol{\Theta})}{\partial\widehat{\boldsymbol{\vartheta}}} \frac{\partial\widehat{\boldsymbol{\vartheta}}}{\partial\boldsymbol{\mathcal{H}}L} = \boldsymbol{\mathcal{W}}\times_6\nabla{\widehat{\boldsymbol{\vartheta}}}F(\boldsymbol{\Theta}). \tag{22} ∇HLF(Θ)≜∂HL∂F(Θ)=∂ϑ ∂F(Θ)∂HL∂ϑ =W×6∇ϑ F(Θ).(22)
第 ( p + 1 ) (p+1) (p+1) 次迭代中,相应的逆 Tucker 因子矩阵 { V L − 1 , h † , h = 1 , 2 , ... , 5 } \{\mathbf{V}^{\dagger}_{L-1,h},h=1,2,\ldots,5\} {VL−1,h†,h=1,2,...,5} 更新为:
V L − 1 , h † ( p + 1 ) = V L − 1 , h † ( p ) − η ∂ F ( Θ ) ∂ V L − 1 , h † . (23) \mathbf{V}^{\dagger}{L-1,h}(p+1) = \mathbf{V}^{\dagger}{L-1,h}(p) -\eta \frac{\partial F(\boldsymbol{\Theta})} {\partial \mathbf{V}^{\dagger}_{L-1,h}}. \tag{23} VL−1,h†(p+1)=VL−1,h†(p)−η∂VL−1,h†∂F(Θ).(23)
在更新第 L L L 个隐藏层的逆 Tucker 因子矩阵后,其局部梯度张量 ∇ H L F ( Θ ) \nabla_{\boldsymbol{\mathcal{H}}L}F(\boldsymbol{\Theta}) ∇HLF(Θ) 被传播回第 ( L − 1 ) (L-1) (L−1) 层。更一般地,从 ∇ H l F ( Θ ) ∈ R I l , 1 × I l , 2 × I l , 3 × I l , 4 × I l , 5 \nabla{\boldsymbol{\mathcal{H}}l}F(\boldsymbol{\Theta})\in\mathbb{R}^{I{l,1}\times I_{l,2}\times I_{l,3}\times I_{l,4}\times I_{l,5}} ∇HlF(Θ)∈RIl,1×Il,2×Il,3×Il,4×Il,5 到 ∇ H l − 1 F ( Θ ) ∈ R I l − 1 , 1 × I l − 1 , 2 × I l − 1 , 3 × I l − 1 , 4 × I l − 1 , 5 \nabla_{\boldsymbol{\mathcal{H}}{l-1}}F(\boldsymbol{\Theta})\in\mathbb{R}^{I{l-1,1}\times I_{l-1,2}\times I_{l-1,3}\times I_{l-1,4}\times I_{l-1,5}} ∇Hl−1F(Θ)∈RIl−1,1×Il−1,2×Il−1,3×Il−1,4×Il−1,5 的反向传播定义为:
∇ H l − 1 F ( Θ ) = f l ′ ( H l − 1 × 1 V l − 1 , 1 † × 2 V l − 1 , 2 † ⋯ × 5 V l − 1 , 5 † ) ⊙ ∇ H l F ( Θ ) × 1 ( V l − 1 , 1 † ) T × 2 ( V l − 1 , 2 † ) T ⋯ × 5 ( V l − 1 , 5 † ) T , l = L , L − 1 , ... , 2. (24) \begin{aligned} \nabla_{\boldsymbol{\mathcal{H}}{l-1}}F(\boldsymbol{\Theta}) &= f_l'\left( \boldsymbol{\mathcal{H}}{l-1} \times_1\mathbf{V}^{\dagger}{l-1,1} \times_2\mathbf{V}^{\dagger}{l-1,2} \cdots \times_5\mathbf{V}^{\dagger}_{l-1,5} \right)\\ &\quad \odot \left \\nabla_{\\boldsymbol{\\mathcal{H}}_l}F(\\boldsymbol{\\Theta}) \\times_1(\\mathbf{V}\^{\\dagger}_{l-1,1})\^T \\times_2(\\mathbf{V}\^{\\dagger}_{l-1,2})\^T \\cdots \\times_5(\\mathbf{V}\^{\\dagger}_{l-1,5})\^T \\right, \quad l=L,L-1,\ldots,2. \end{aligned} \tag{24} ∇Hl−1F(Θ)=fl′(Hl−1×1Vl−1,1†×2Vl−1,2†⋯×5Vl−1,5†)⊙∇HlF(Θ)×1(Vl−1,1†)T×2(Vl−1,2†)T⋯×5(Vl−1,5†)T,l=L,L−1,...,2.(24)
算法 1 总结了用于 DOA 估计的张量化神经网络训练过程:输入为协方差张量及其角度标签 { ( Y p , ϑ p ) , p = 1 , 2 , ... , P } \{(\boldsymbol{\mathcal{Y}}p,\boldsymbol{\vartheta}p),p=1,2,\ldots,P\} {(Yp,ϑp),p=1,2,...,P},输出为参数集合 Θ = { V 0 , h † , V 1 , h † , ... , V L − 1 , h † , W , h = 1 , 2 , ... , 5 } \boldsymbol{\Theta}=\{\mathbf{V}^{\dagger}{0,h},\mathbf{V}^{\dagger}{1,h},\ldots,\mathbf{V}^{\dagger}_{L-1,h},\boldsymbol{\mathcal{W}},h=1,2,\ldots,5\} Θ={V0,h†,V1,h†,...,VL−1,h†,W,h=1,2,...,5}。其核心步骤包括按式 (10) 和式 (11) 前馈计算隐藏状态张量,按式 (13) 计算输出角度,按式 (15) 计算 Huber 损失,按式 (20) 更新输出权重张量,并按式 (22)-(24) 将梯度反向传播到各隐藏层。
相应地,利用局部梯度张量 ∇ H l − 1 F ( Θ ) \nabla_{\boldsymbol{\mathcal{H}}{l-1}}F(\boldsymbol{\Theta}) ∇Hl−1F(Θ) 可推导 F ( Θ ) F(\boldsymbol{\Theta}) F(Θ) 关于 V l − 2 , h † \mathbf{V}^{\dagger}{l-2,h} Vl−2,h† 的导数,从而更新逆 Tucker 因子矩阵 { V l − 2 , h † , h = 1 , 2 , ... , 5 } \{\mathbf{V}^{\dagger}_{l-2,h},h=1,2,\ldots,5\} {Vl−2,h†,h=1,2,...,5}:
V l − 2 , h † ( p + 1 ) = V l − 2 , h † ( p ) − η ∂ F ( Θ ) ∂ V l − 2 , h † . (25) \mathbf{V}^{\dagger}{l-2,h}(p+1) = \mathbf{V}^{\dagger}{l-2,h}(p) -\eta \frac{\partial F(\boldsymbol{\Theta})} {\partial \mathbf{V}^{\dagger}_{l-2,h}}. \tag{25} Vl−2,h†(p+1)=Vl−2,h†(p)−η∂Vl−2,h†∂F(Θ).(25)
处理完所有输入协方差张量样本并更新参数集合 Θ \boldsymbol{\Theta} Θ 后,张量化深度神经网络即完成二维 DOA 估计训练。
D. Tucker 秩序列的选择
Tucker 秩序列 χ T u c k e r ≜ { I 1 , h , I 2 , h , ... , I L , h , h = 1 , 2 , ... , 5 } \chi_{\mathrm{Tucker}}\triangleq\{I_{1,h},I_{2,h},\ldots,I_{L,h},h=1,2,\ldots,5\} χTucker≜{I1,h,I2,h,...,IL,h,h=1,2,...,5} 同时影响张量化深度神经网络的效率和性能。为减少性能下降,本文通过贝叶斯优化自动选择 Tucker 秩序列。令 Ξ ( χ T u c k e r ) \Xi(\chi_{\mathrm{Tucker}}) Ξ(χTucker) 表示基于交叉验证结果得到的 DOA 估计平均验证 MSE,则最优 Tucker 秩序列由下式确定:
χ T u c k e r o p t = arg min χ T u c k e r Ξ ( χ T u c k e r ) . (26) \chi_{\mathrm{Tucker}}^{\mathrm{opt}} =\arg\min_{\chi_{\mathrm{Tucker}}}\Xi(\chi_{\mathrm{Tucker}}). \tag{26} χTuckeropt=argχTuckerminΞ(χTucker).(26)
基于贝叶斯优化原理,式 (26) 可通过假设 Ξ ( χ T u c k e r ) \Xi(\chi_{\mathrm{Tucker}}) Ξ(χTucker) 的先验分布并持续更新新优化结果的后验分布来求解。Tucker 秩序列被视为张量化神经网络的超参数,其调节与学习率、批大小等典型超参数一并完成。