作者 :前阿里 P9 | 7年 CTO 高管实战复盘
专栏 :全领域技术架构选型避坑指南 https://blog.csdn.net/nanzhiwen666/category_13172229.html
标签 :
高并发高可用电商架构分布式系统架构设计避坑指南
一、前言:为什么写这篇文章?
作为一名经历过多次双十一、618 大促洗礼的架构师,我深刻体会到:电商交易系统的架构设计,不是"能不能做"的问题,而是"能不能扛住"的问题。
在阿里期间,我参与过日均 GMV 过百亿的交易平台架构设计;在后来的 CTO 岗位上,我也主导过从 0 到 1 搭建电商中台、风控中台、数据中台、AI 中台。这篇文章,是我 15 年一线实战经验的系统性总结,旨在帮你:看清电商交易架构的全貌,避开我踩过的那些坑。
本文核心内容
| 章节 | 主题 | 价值 |
|---|---|---|
| 第二章 | 架构全景图 | 建立全局认知 |
| 第三章 | 交易核心链路 | 理解下单全流程 |
| 第四章 | 秒杀系统专题 | 高并发终极挑战 |
| 第五章 | 多级缓存设计 | 性能优化核心 |
| 第六章 | 分布式事务 | 数据一致性保障 |
| 第七章 | 高可用保障体系 | 稳定性兜底 |
| 第八章 | 避坑总结 | 实战经验提炼 |
二、电商交易架构全景图
2.1 六层架构设计
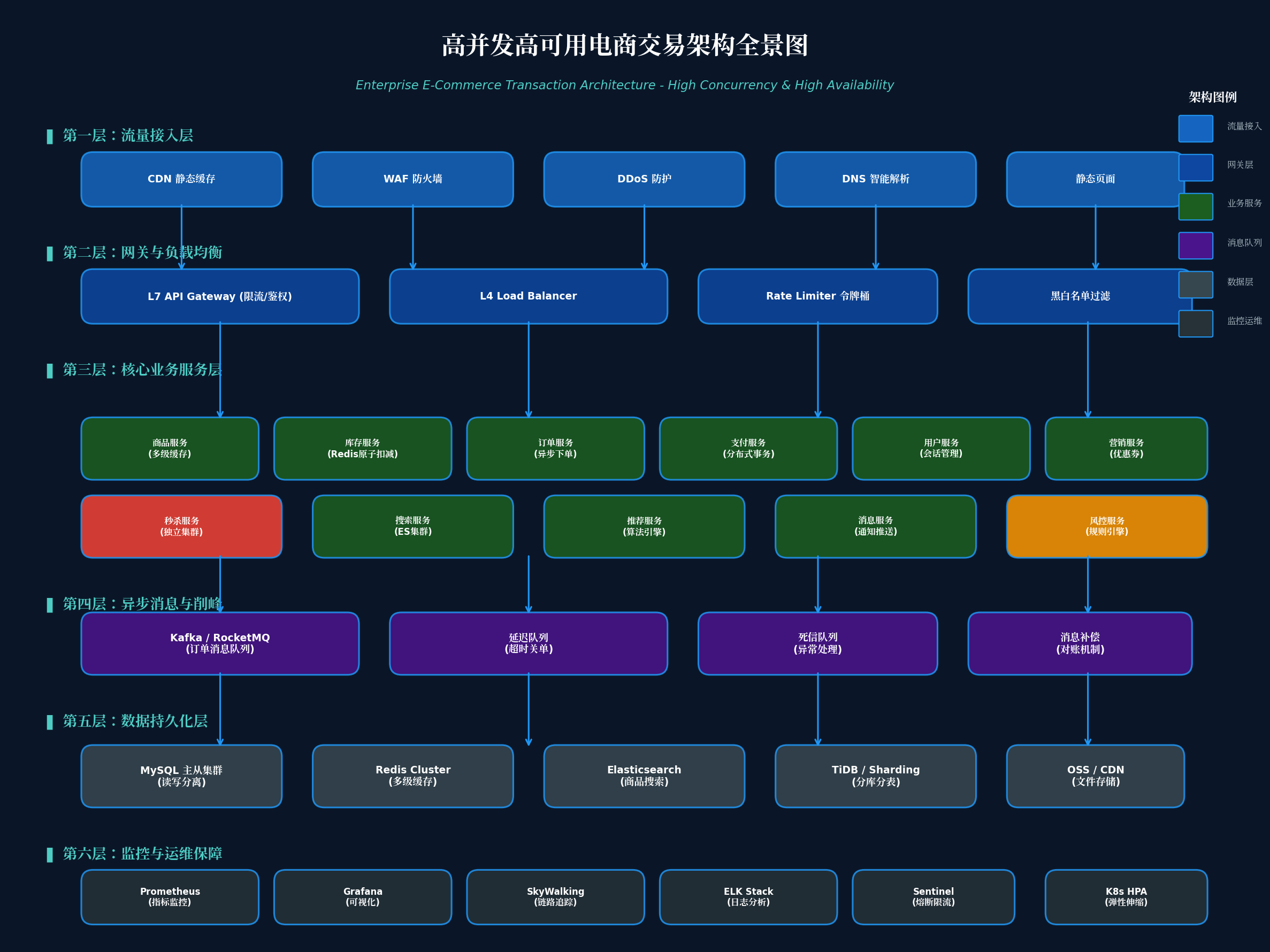
上图展示了一个企业级电商平台的完整架构,分为六个层次:
第一层:流量接入层
- CDN 静态缓存:商品详情页、图片、JS/CSS 静态资源全部走 CDN,减少源站压力
- WAF 防火墙:拦截 SQL 注入、XSS 攻击、CC 攻击
- DDoS 防护:应对流量型攻击,保障入口可用
- DNS 智能解析:就近接入、故障切换
避坑点:不要忽视 DNS 层面的容灾。某次大促,我们因为 DNS 服务商故障导致全站不可访问,后来引入了多 DNS 服务商备份方案。
第二层:网关与负载均衡
- L7 API Gateway:统一鉴权、限流、路由、日志
- L4 Load Balancer:TCP 层负载均衡,性能更高
- Rate Limiter:令牌桶/漏桶算法,防止流量洪峰
- 黑白名单:拦截恶意 IP、Bot 流量
避坑点:网关层不要做太多业务逻辑,否则会成为性能瓶颈。我们曾把订单校验逻辑放在网关,导致网关 CPU 飙升,后来下沉到业务服务。
第三层:核心业务服务层
- 商品服务:多级缓存、商品搜索
- 库存服务:Redis 原子扣减、库存预热
- 订单服务:异步下单、订单状态机
- 支付服务:分布式事务、支付回调幂等
- 秒杀服务:独立集群、独立域名、独立数据库
避坑点:秒杀服务必须独立部署!我曾见过把秒杀和正常交易混在一起的架构,结果秒杀流量把正常交易也拖垮了。
第四层:异步消息与削峰
- RocketMQ / Kafka:订单消息队列、削峰填谷
- 延迟队列:超时关单、自动退款
- 死信队列:异常订单处理
- 消息补偿:对账机制、消息重试
第五层:数据持久化层
- MySQL 主从集群:读写分离、分库分表
- Redis Cluster:多级缓存、分布式锁
- Elasticsearch:商品搜索、日志检索
- TiDB / ShardingSphere:NewSQL 方案
第六层:监控与运维保障
- Prometheus + Grafana:指标监控与可视化
- SkyWalking:分布式链路追踪
- Sentinel:熔断限流
- K8s HPA:弹性伸缩
三、电商交易核心链路详解
3.1 从浏览到支付的完整流程
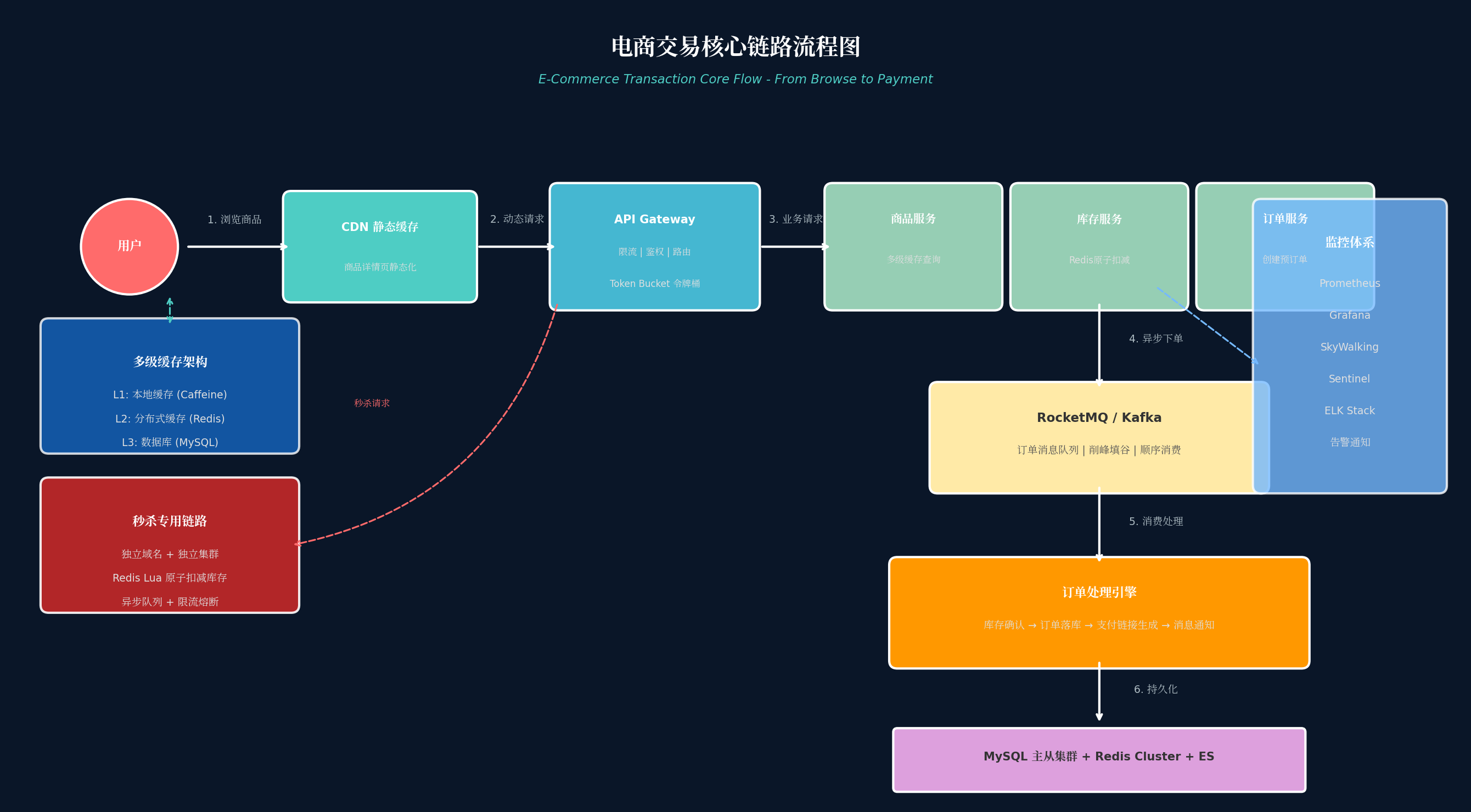
阶段一:商品浏览(读多写少)
用户 → CDN → 商品服务 → L1本地缓存 → L2 Redis → L3 MySQL核心策略:
- 商品详情页 99% 流量走 CDN 静态缓存
- 价格、库存等动态数据走多级缓存
- 读请求尽量不打到数据库
阶段二:下单(写操作,核心环节)
用户 → API Gateway → 订单服务 → Redis 预扣库存 → MQ 异步下单 → 订单处理引擎 → MySQL核心策略:
- 库存预扣:Redis 原子操作扣减库存,快速响应
- 异步下单:订单创建走 MQ,削峰填谷
- 预订单:先创建预订单,支付成功后再转为正式订单
阶段三:支付(分布式事务)
支付请求 → 支付服务 → 第三方支付 → 回调 → 订单状态更新 → 库存确认 → 消息通知核心策略:
- 支付回调幂等:同一笔支付多次回调只处理一次
- 超时关单:15 分钟未支付自动关单,释放库存
- 对账机制:每日与支付渠道对账,确保数据一致
3.2 关键代码:库存预扣 Redis Lua 脚本
lua
-- 库存原子扣减脚本
local stock = redis.call('get', KEYS[1])
if tonumber(stock) > 0 then
redis.call('decr', KEYS[1])
redis.call('sadd', KEYS[2], ARGV[1]) -- 记录已购用户,防重复购买
return 1 -- 扣减成功
else
return 0 -- 库存不足
end为什么用 Lua?
- Redis 单线程执行 Lua 脚本,保证原子性
- 避免"先查后扣"的并发超卖问题
- 性能极高,单机 Redis 可达 10万+ QPS
四、秒杀系统专题:高并发的终极挑战
4.1 秒杀系统的五层防御体系
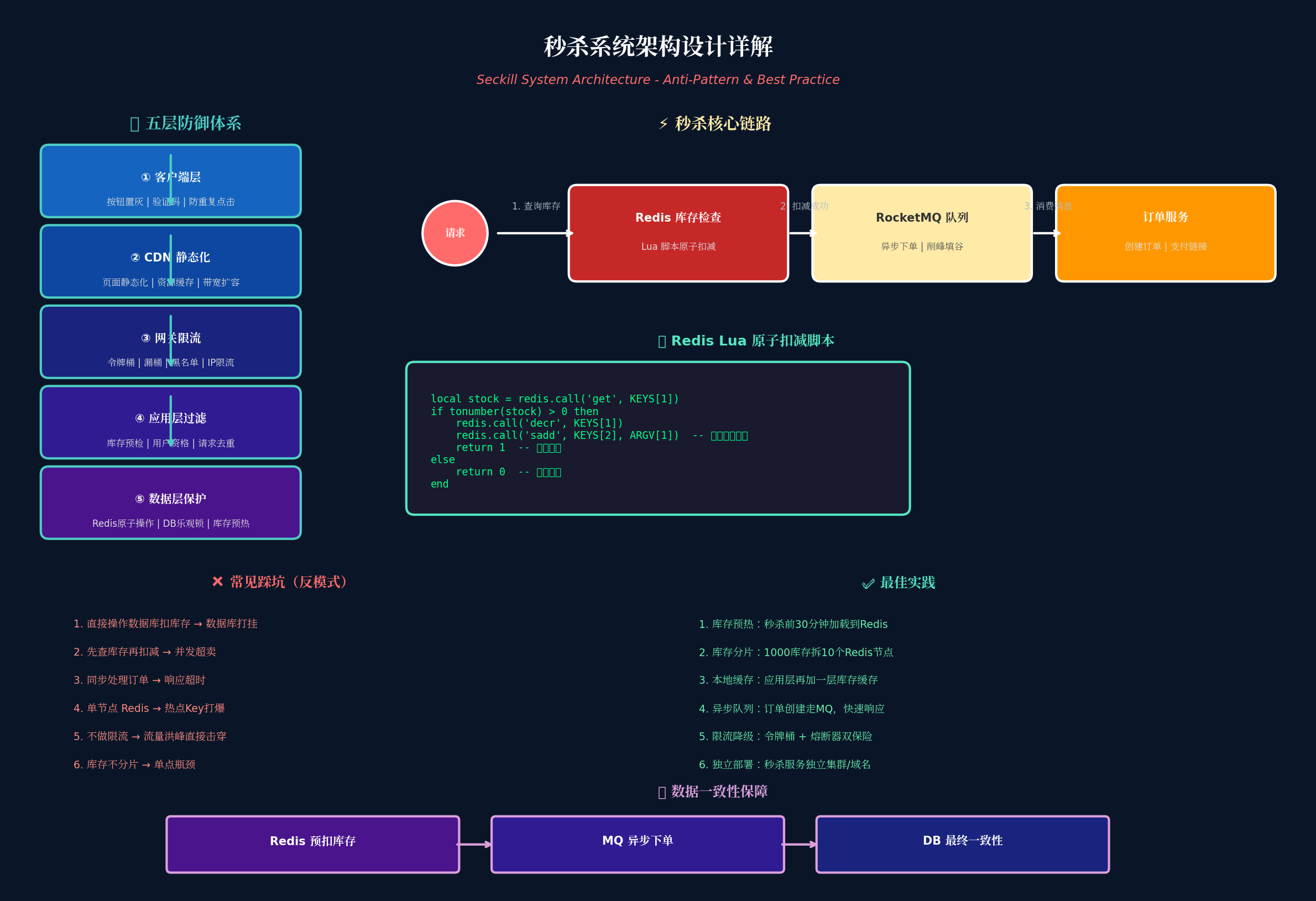
第一层:客户端层
- 按钮置灰:秒杀未开始,按钮不可点击
- 验证码:防止机器刷单(简单数学题、滑动验证)
- 防重复点击:1 秒内只能点击一次
第二层:CDN 静态化
- 秒杀页面完全静态化,走 CDN 缓存
- 秒杀倒计时由服务端动态推送
- 提前租借 CDN 带宽
第三层:网关限流
- 令牌桶算法:控制通过的请求数量
- 漏桶算法:平滑突发流量
- IP 限流:单 IP 限制访问频率
第四层:应用层过滤
- 库存预检:Redis 快速判断库存是否充足
- 用户资格校验:是否登录、是否有购买资格
- 请求去重:同一用户多次请求只处理一次
第五层:数据层保护
- Redis 原子操作:Lua 脚本扣减库存
- 数据库乐观锁:版本号机制防止超卖
- 库存预热:秒杀前 30 分钟加载到 Redis
4.2 秒杀核心链路
用户请求 → Redis 库存检查(Lua原子扣减) → 扣减成功 → RocketMQ 队列 → 订单服务 → 创建订单
↓
扣减失败 → 返回"已售罄"4.3 常见踩坑(反模式)
| 反模式 | 后果 | 正确做法 |
|---|---|---|
| 直接操作数据库扣库存 | 数据库被打挂 | Redis 预扣 + 异步落库 |
| 先查库存再扣减 | 并发超卖 | Lua 原子脚本 |
| 同步处理订单 | 响应超时 | MQ 异步下单 |
| 单节点 Redis | 热点 Key 打爆 | Redis Cluster 分片 |
| 不做限流 | 流量洪峰击穿 | 令牌桶 + 熔断器 |
| 库存不分片 | 单点瓶颈 | 库存分片到多个 Redis 节点 |
4.4 最佳实践
- 库存预热:秒杀前 30 分钟将库存加载到 Redis
- 库存分片:1000 库存拆成 10 份,分布在 10 个 Redis 节点
- 本地缓存:应用层再加一层库存缓存,减少 Redis 压力
- 异步队列:订单创建走 MQ,快速响应用户
- 限流降级:令牌桶 + 熔断器双保险
- 独立部署:秒杀服务独立集群、独立域名、独立数据库
五、多级缓存架构设计
5.1 三级缓存架构
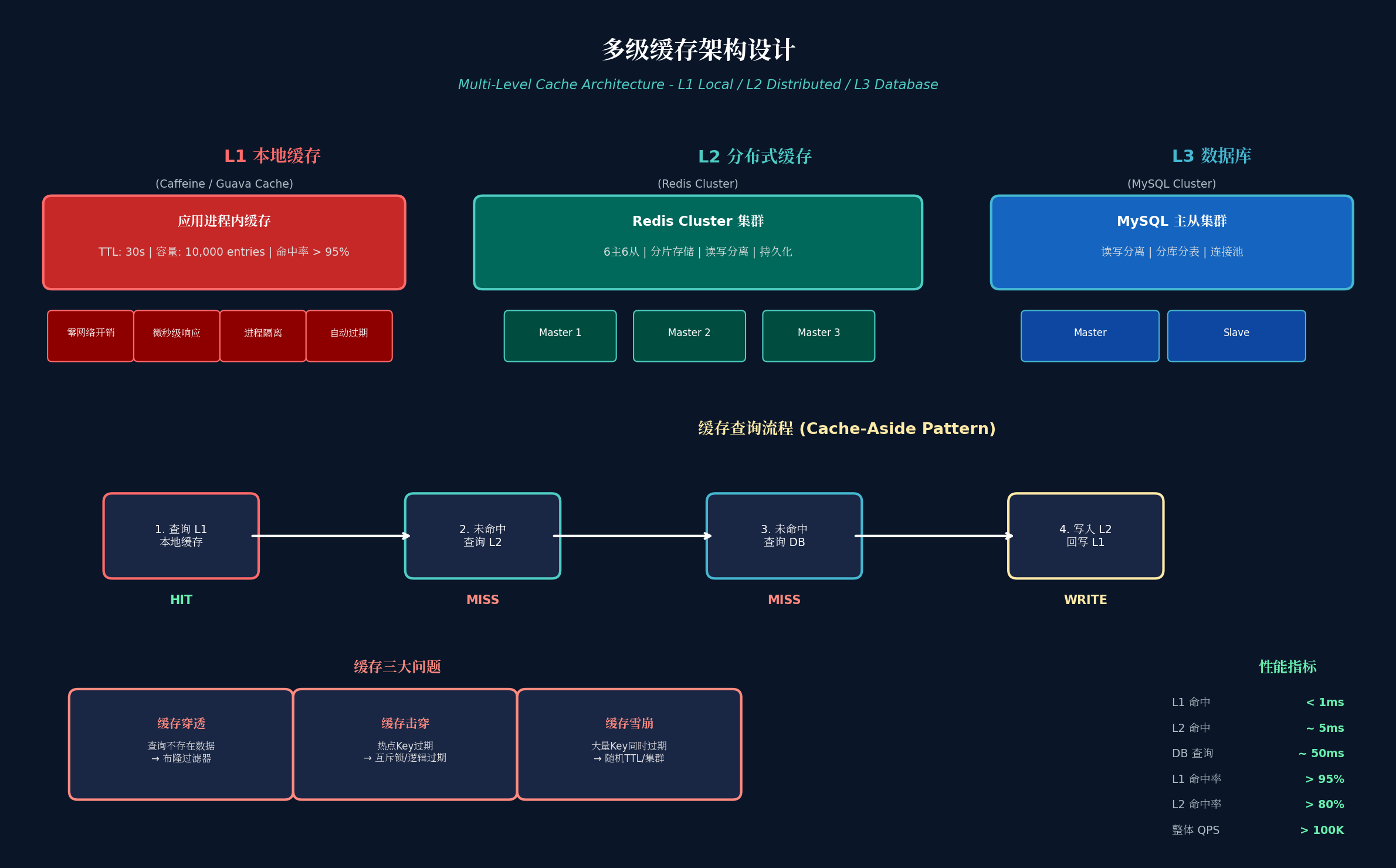
L1:本地缓存(Caffeine / Guava Cache)
- 位置:应用进程内
- TTL:30 秒
- 容量:10,000 entries
- 命中率:> 95%
- 响应时间:< 1ms
适用场景:热点商品、用户信息、配置数据
L2:分布式缓存(Redis Cluster)
- 架构:6 主 6 从,分片存储
- 特性:读写分离、持久化、高可用
- 响应时间:~ 5ms
适用场景:商品详情、库存数据、会话信息
L3:数据库(MySQL Cluster)
- 架构:主从复制、读写分离
- 优化:分库分表、连接池
- 响应时间:~ 50ms
5.2 缓存查询流程(Cache-Aside Pattern)
1. 查询 L1 本地缓存 → HIT? 返回 : 继续
2. 查询 L2 Redis → HIT? 写入 L1 并返回 : 继续
3. 查询 L3 数据库 → 写入 L2 和 L1 → 返回5.3 缓存三大问题及解决方案
问题一:缓存穿透
- 现象:查询不存在的数据,每次都要查数据库
- 解决方案:布隆过滤器(Bloom Filter)
java
// Guava BloomFilter 示例
BloomFilter<String> bloomFilter = BloomFilter.create(
Funnels.stringFunnel(Charset.defaultCharset()),
1000000, // 预期数据量
0.01 // 误判率
);
// 查询前先用布隆过滤器判断
if (!bloomFilter.mightContain(key)) {
return null; // 一定不存在,直接返回
}问题二:缓存击穿
- 现象:热点 Key 过期,大量请求同时打到数据库
- 解决方案:互斥锁 / 逻辑过期
java
// 互斥锁方案
public String getHotData(String key) {
String value = redis.get(key);
if (value == null) {
// 获取分布式锁
if (redis.setnx(lockKey, "1", 10)) {
try {
value = db.query(key); // 查数据库
redis.set(key, value, 3600); // 写入缓存
} finally {
redis.del(lockKey); // 释放锁
}
} else {
Thread.sleep(100); // 等待后重试
return getHotData(key);
}
}
return value;
}问题三:缓存雪崩
- 现象:大量 Key 同时过期,数据库压力剧增
- 解决方案 :
- 随机 TTL:
expire = base + random(0, 300) - 集群部署:多节点分散压力
- 熔断降级:数据库压力过大时降级返回默认数据
- 随机 TTL:
六、分布式事务解决方案
6.1 四种方案对比
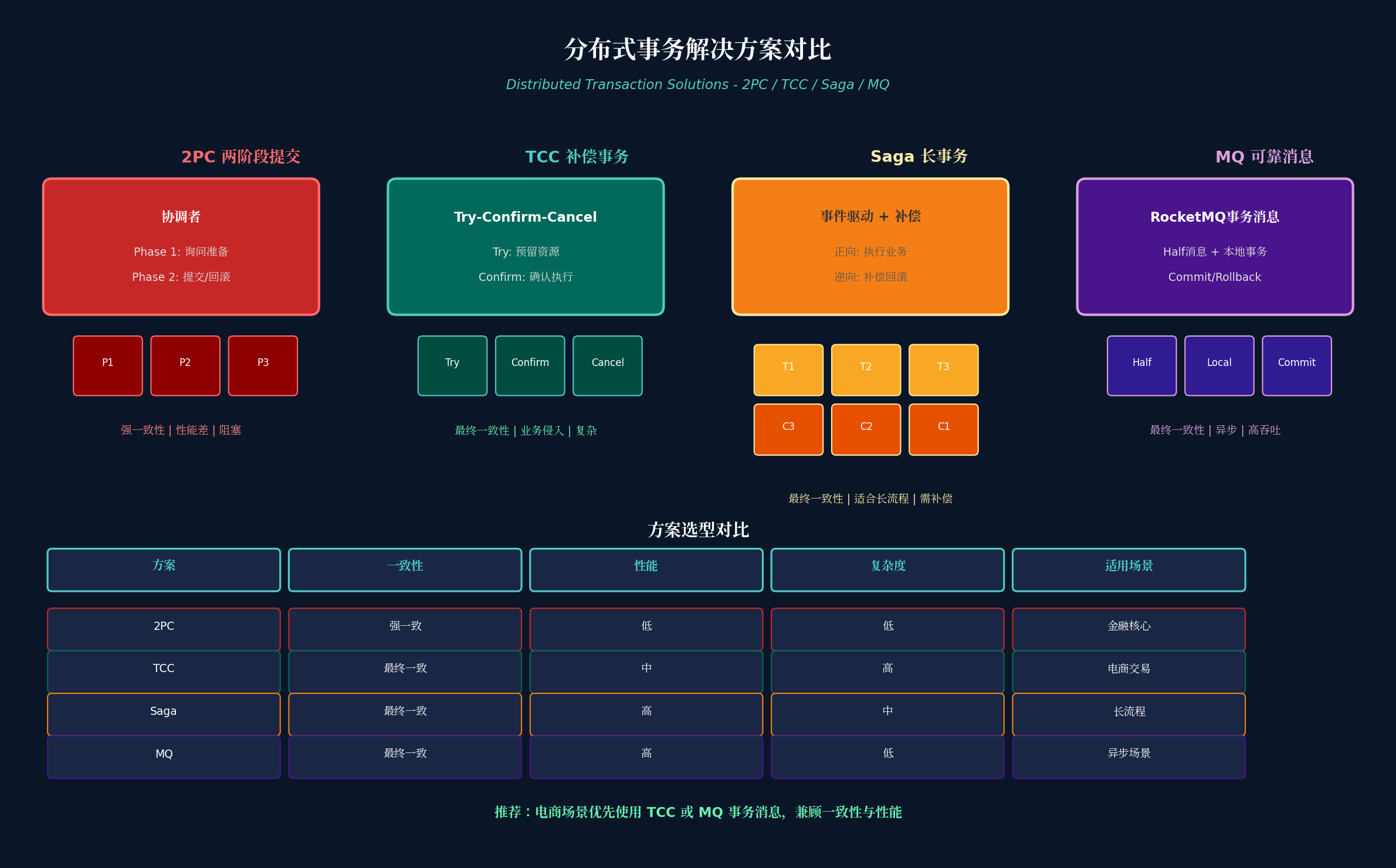
方案一:2PC(两阶段提交)
- 原理:协调者询问所有参与者是否准备就绪,再统一提交或回滚
- 优点:强一致性
- 缺点:同步阻塞、性能差、单点故障
- 适用:金融核心系统
方案二:TCC(Try-Confirm-Cancel)
- 原理 :
- Try:预留资源(如冻结库存)
- Confirm:确认执行(扣减库存)
- Cancel:取消释放(解冻库存)
- 优点:最终一致性、性能较好
- 缺点:业务侵入性强、实现复杂
- 适用:电商交易、库存扣减
java
// TCC 示例:库存服务
public interface InventoryTccService {
@TwoPhaseBusinessAction(name = "deductInventory")
boolean tryDeduct(@BusinessActionContextParameter(paramName = "skuId") String skuId,
@BusinessActionContextParameter(paramName = "count") int count);
boolean confirm(BusinessActionContext context);
boolean cancel(BusinessActionContext context);
}方案三:Saga(长事务)
- 原理:事件驱动,正向执行业务,失败时逆向补偿
- 优点:适合长流程、高性能
- 缺点:需要编写补偿逻辑
- 适用:订单流程、物流跟踪
方案四:MQ 可靠消息
- 原理 :
- 发送 Half 消息(预消息)
- 执行本地事务
- 提交或回滚 Half 消息
- 消费者消费消息执行业务
- 优点:最终一致性、异步、高吞吐
- 缺点:需要消息幂等处理
- 适用:异步场景、通知推送
java
// RocketMQ 事务消息示例
TransactionMQProducer producer = new TransactionMQProducer("order_group");
producer.setTransactionListener(new TransactionListener() {
@Override
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
try {
// 执行本地事务:创建订单
orderService.createOrder((Order) arg);
return LocalTransactionState.COMMIT_MESSAGE;
} catch (Exception e) {
return LocalTransactionState.ROLLBACK_MESSAGE;
}
}
@Override
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
// 回查本地事务状态
Order order = orderService.getOrder(msg.getKeys());
return order != null ?
LocalTransactionState.COMMIT_MESSAGE :
LocalTransactionState.ROLLBACK_MESSAGE;
}
});6.2 电商场景推荐
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 库存扣减 | TCC | 需要预留资源,可回滚 |
| 订单创建 | MQ 事务消息 | 异步处理,高吞吐 |
| 支付回调 | 幂等 + 对账 | 保证最终一致性 |
| 积分扣减 | Saga | 长流程,需要补偿 |
七、高可用保障体系
7.1 三大支柱
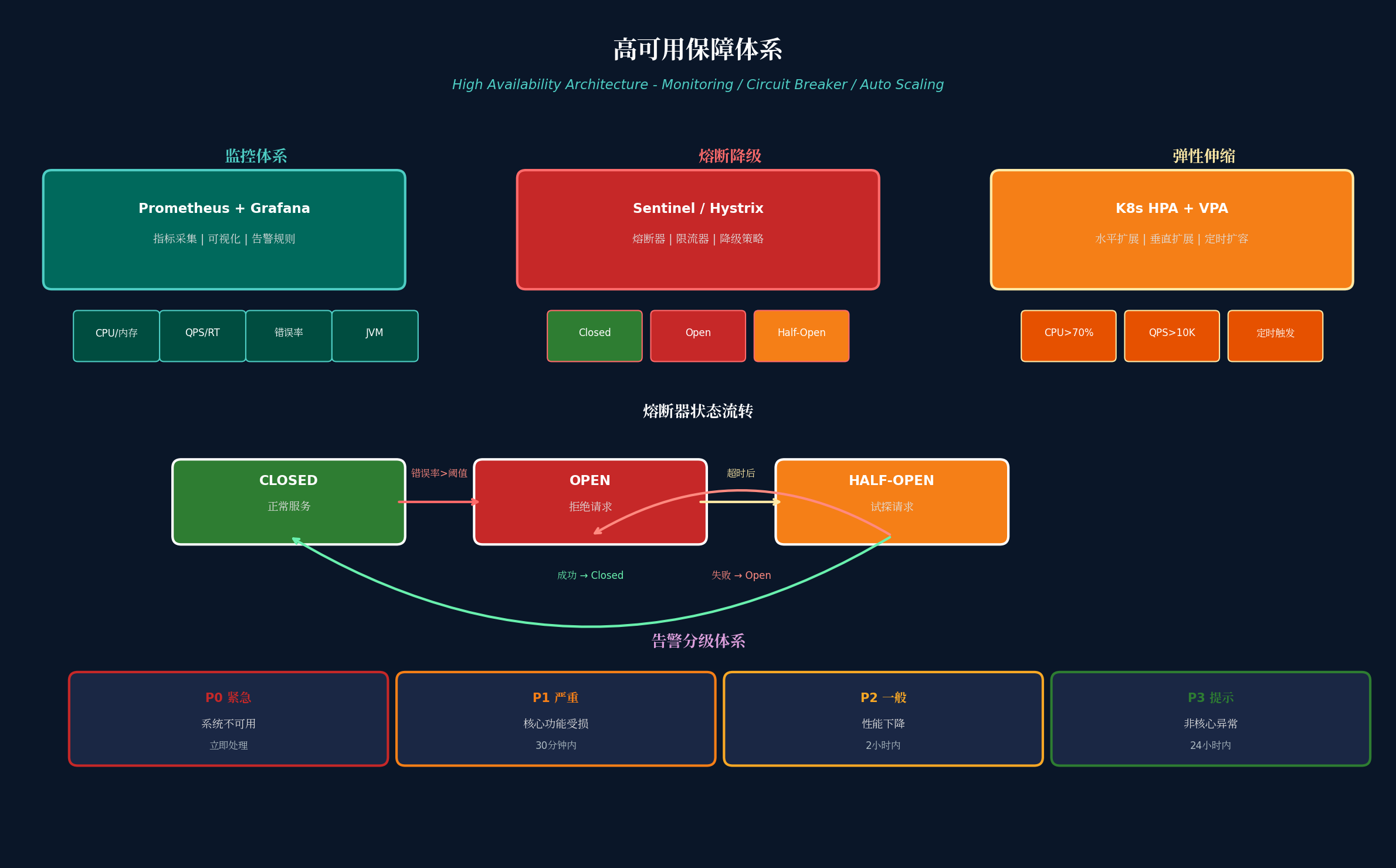
支柱一:监控体系(Prometheus + Grafana)
监控维度:
- 基础设施层:CPU、内存、磁盘、网络
- 应用层:QPS、RT、错误率、JVM
- 业务层:订单量、支付成功率、库存扣减成功率
- 链路层:SkyWalking 分布式追踪
告警规则示例:
yaml
# Prometheus 告警规则
groups:
- name: ecommerce_alerts
rules:
- alert: HighErrorRate
expr: rate(http_requests_total{status=~"5.."}[5m]) > 0.01
for: 2m
labels:
severity: P1
annotations:
summary: "错误率超过 1%"
- alert: HighLatency
expr: histogram_quantile(0.99, rate(http_request_duration_seconds_bucket[5m])) > 0.5
for: 3m
labels:
severity: P2
annotations:
summary: "P99 延迟超过 500ms"支柱二:熔断降级(Sentinel)
熔断器三种状态:
- Closed(关闭):正常服务,监控错误率
- Open(打开):错误率超过阈值,拒绝请求
- Half-Open(半开):超时后放行少量请求试探
java
// Sentinel 熔断规则
DegradeRule rule = new DegradeRule();
rule.setResource("orderService");
rule.setGrade(CircuitBreakerStrategy.ERROR_RATIO); // 错误率策略
rule.setCount(0.5); // 错误率阈值 50%
rule.setTimeWindow(30); // 熔断时长 30 秒
rule.setMinRequestAmount(10); // 最小请求数
DegradeRuleManager.loadRules(Collections.singletonList(rule));支柱三:弹性伸缩(K8s HPA)
伸缩策略:
- 水平扩展(HPA):根据 CPU/内存/QPS 自动扩缩 Pod
- 垂直扩展(VPA):自动调整 Pod 资源配额
- 定时扩容:大促前提前扩容
yaml
# K8s HPA 配置
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: order-service-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: order-service
minReplicas: 10
maxReplicas: 100
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Pods
pods:
metric:
name: http_requests_per_second
target:
type: AverageValue
averageValue: "10000"7.2 告警分级体系
| 级别 | 定义 | 响应时间 | 示例 |
|---|---|---|---|
| P0 紧急 | 系统不可用 | 立即处理 | 数据库宕机、全站 500 |
| P1 严重 | 核心功能受损 | 30 分钟内 | 支付失败率 > 5% |
| P2 一般 | 性能下降 | 2 小时内 | P99 延迟 > 1s |
| P3 提示 | 非核心异常 | 24 小时内 | 日志异常、监控缺失 |
八、避坑总结:15 年实战经验提炼
8.1 架构设计十大原则
- 不要过度设计:适合的才是最好的,不要盲目追求微服务
- 缓存为王:能缓存的绝不查数据库
- 异步解耦:同步改异步,降低系统耦合
- 限流降级:宁可拒绝部分请求,也不让系统崩溃
- 独立部署:秒杀、大促活动独立集群
- 数据隔离:核心数据和非核心数据分开存储
- 幂等设计:所有接口都要考虑幂等性
- 监控先行:上线前监控、告警必须到位
- 灰度发布:新功能先灰度,再全量
- 容灾演练:定期演练故障恢复,不要等出事了再后悔
8.2 常见坑点速查表
| 坑点 | 症状 | 解决方案 |
|---|---|---|
| 单点 Redis | 热点 Key 导致节点 CPU 100% | Redis Cluster 分片 + 本地缓存 |
| 数据库连接池耗尽 | 大量请求超时 | 连接池监控 + 熔断降级 |
| 消息队列堆积 | 消费延迟,订单处理缓慢 | 增加消费者 + 消息分区 |
| 分布式锁失效 | 并发超卖 | RedLock + Lua 原子脚本 |
| 缓存雪崩 | 大量请求打到数据库 | 随机 TTL + 熔断器 |
| 接口幂等缺失 | 重复下单、重复支付 | 唯一索引 + Token 机制 |
| 日志打印过多 | GC 频繁,系统卡顿 | 异步日志 + 日志级别控制 |
| 全表扫描 | 数据库 CPU 飙升 | 索引优化 + 分页查询 |
| 循环依赖 | 服务启动失败 | 依赖梳理 + 异步初始化 |
| 配置硬编码 | 线上改配置需要发版 | 配置中心(Nacos/Apollo) |
8.3 性能指标参考
| 指标 | 目标值 | 说明 |
|---|---|---|
| 首页加载时间 | < 1s | 首屏渲染 |
| 商品详情页 | < 500ms | 含缓存命中 |
| 下单接口 | < 200ms | 异步处理 |
| 支付接口 | < 300ms | 含第三方支付 |
| 系统可用性 | 99.99% | 全年宕机 < 1 小时 |
| 订单创建 QPS | > 10,000 | 单商品秒杀 |
| 库存扣减 QPS | > 50,000 | Redis 原子操作 |
| 数据库 QPS | < 5,000 | 读写分离后 |
九、结语
电商交易系统的架构设计,本质上是一场**"攻防博弈"**:
- 攻:业务增长、流量洪峰、恶意攻击
- 防:缓存、限流、降级、熔断、监控
没有完美的架构,只有不断演进的架构。京东、淘宝的方案也是经过无数次大促洗礼才逐步完善的。
记住这句话:
架构设计如行军打仗,知己知彼,百战不殆。了解业务特点,预判系统瓶颈,提前做好准备,你的电商系统也能稳如泰山!
附录:推荐阅读
如果这篇文章对你有帮助,欢迎点赞、收藏、转发!
关注我,获取更多企业级架构实战干货。
本文首发于 CSDN,转载请注明出处。