1.作者介绍
刘思佳,女,西安工程大学电子信息学院,2025级研究生
研究方向:近红外光谱纤维鉴别
电子邮件:1335759643@qq.com
胥乾信,西安工程大学电子信息学院,2025级研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:2692797728@qq.com
2.基于Grounded-SAM-2的动态场景目标检测
随着计算机视觉大模型的飞速发展,将"自然语言理解"与"像素级视频分割"相结合成为了新的研究热点。本文将深入浅出地介绍目前前沿的 Grounded-SAM-2 联合架构,并附上完整的动态场景目标追踪(单目标锁定)的实战代码。
Grounded-SAM-2 并非一个单一的黑盒模型,而是由两大顶级视觉基础大模型(Foundation Models)强强联合组成的端到端级联管线。其核心思想是:前端负责"看懂语言并找位置",后端负责"精准抠图并跨帧追踪"。
2.1 Grounded-SAM-2 整体框架
模型Grounded-SAM-2 = Grounding DINO + SAM 2,是一个串联式视频目标检测与跟踪流水线。
完整工作流程:
•首帧输入文本提示
•Grounding DINO 检测目标框
•SAM 2 根据框生成掩码
•SAM 2 在后续帧自动跟踪目标
•输出带掩码的视频结果
它的核心优势:
•文本驱动,无需标注
•零样本,开箱即用
•动态场景稳定跟踪
•支持任意物体检测
2.2 Grounding DINO:开放词汇目标定位
在传统的检测任务中(如 YOLO 系列),模型只能识别训练集内预设的类别。而 Grounding DINO 打破了这一限制,实现了开放词汇(Open-Vocabulary)的零样本检测。
•跨模态对齐:DINO 内部包含提取图像特征的视觉骨干网络(Swin Transformer)和提取文本特征的语言模型(BERT)。通过特征增强器(Feature Enhancer),它能在数学空间上将"文本描述"与"图像像素"对应起来。
•首帧感知:在动态视频处理中,Grounding DINO 仅在第一帧介入。用户输入文本提示词(Prompt,例如 "dog ."),模型即可在首帧瞬间输出目标高精度的候选边界框(Bounding Box)。
模型的框架图如下,框架结构分为五层:
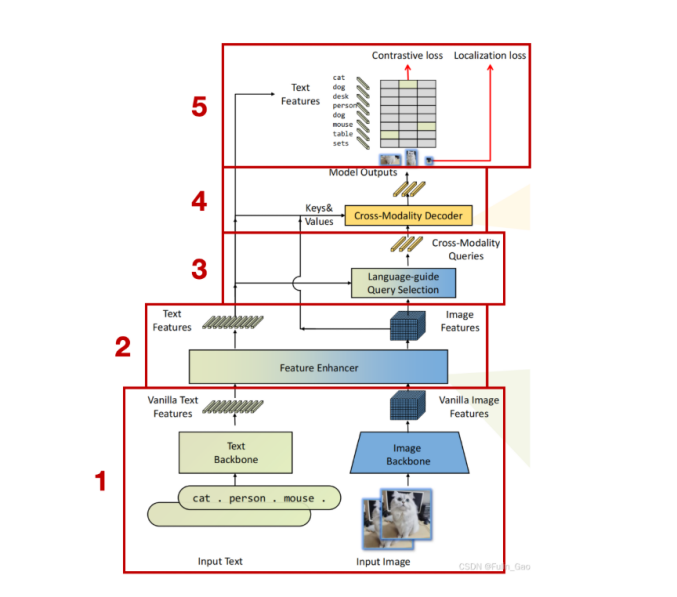
第1层:输入与基础特征提取
•模型的两个输入 :文本和图像
•文本骨干网络:把文字转换成 "文本特征向量",让模型理解说的是什么物体。
•图像骨干网络:把图片转换成 "图像特征向量",提取画面里的视觉信息。
第 2 层:特征增强
•对文本和图像特征进行增强处理,让文字描述和图像内容的关联更紧密,为后续的跨模态匹配做准备。 输出增强后的特征。
第 3 层:语言引导的查询选择
•用文本特征,从图像特征中筛选出和文字描述相关的视觉查询。 比如模型会根据 "dog" 这个词,从画面里挑出 "看起来像狗的区域" 作为候选目标。
第 4 层:
•跨模态解码器,接收来自第 3 层的跨模态查询,并结合文本和图像特征进行解码。 这些信息会被用来生成最终的目标检测结果。
第 5 层:输出与损失计算
•模型的最终结果,也就是需要的目标检测框(Bounding Box)。
•训练时用的两种损失函数 :
•对比损失:让模型学习 "文字和正确的物体特征更相似,和错误的物体特征更不相似"。
•定位损失:让模型把检测框的位置和大小预测得更准确
2.3 SAM 2:时空记忆与视频分割
SAM 2(Segment Anything Model 2)是 Meta 最新发布的统一图像与视频分割大模型。相比于第一代,它最大的突破在于引入了动态视频流的处理能力。
•接收 DINO 传来的边界框作为 Prompt,在首帧将粗糙的矩形框转化为像素级的精准遮罩(Mask)。
•时空记忆机制是连续追踪的核心。SAM 2 构建了一个记忆库(Memory Bank),用于存储目标在历史帧中的形状和特征。在处理后续帧时,通过记忆注意力机制(Memory Attention)持续回看历史状态。
正是依托这种时空记忆机制,即使目标在视频中发生了剧烈形变或遭到短暂物理遮挡,SAM 2 依然能够保持稳定的连续追踪,不会丢失目标。
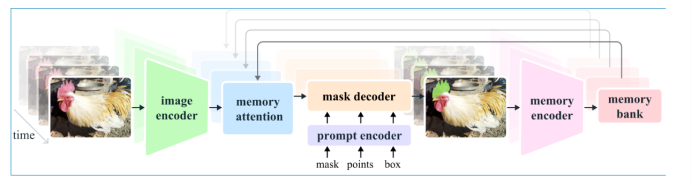
•视频帧输入与图像编码:image encoder:对每一帧视频图像,提取通用特征。把画面变成模型能理解的高维特征
•"提示 - 掩码" 生成阶段(首帧用):prompt encoder:接收用户给的 "提示" ,把这些提示变成特征,告诉模型 "我要分割的目标在哪"。 mask decoder:结合图像特征和提示特征,生成像素级的目标掩码。也就是把轮廓精确抠出来,得到精细分割结果。
•视频跟踪与记忆更新(后续帧用):memory encoder:把上一帧生成的掩码和图像特征,编码成"记忆特征",存起来。memory bank:存储所有历史帧的记忆特征。模型靠这些记忆,记住目标长什么样、怎么动。memory attention:在下一帧处理时,从 memory bank 里调取历史记忆,和当前帧的图像特征做注意力计算,从而知道 "这一帧里哪个是我之前跟踪的目标"。
•整个流程不断循环,每一帧的掩码都会被编码成记忆,传给下一帧,实现持续跟踪。
3.关于实验过程的介绍,完整实验代码,测试结果
3.1实验数据集与环境依赖配置
数据集介绍:
•模型预训练:加载基于 SA-V(5.1万视频)与 COCO(图文对)训练的基础权重,赋予模型零样本泛化能力。
•本地测试视频:一段 378 帧的生活场景自定义短视频(test_video.mp4),验证模型在未经微调情况下的工程鲁棒性。
环境依赖与软件包:本实验推荐在 Python 3.10+ 的环境下进行。核心依赖包如下:
•torch (建议 2.4 左右版本)
•transformers==4.35.0
•groundingdino, sam2 (官方源码安装)
•opencv-python (用于视频拆帧与最终 Alpha 混合渲染)
•hydra-core (动态加载模型配置文件)
3.2完整追踪与渲染代码实现
以下为实现视频拆帧、首帧定位、时空扩散计算以及生成带遮罩视频的完整 Python 源码,包含详细注释:
python
import os
os.environ["CUDA_VISIBLE_DEVICES"] = ""
import cv2
import torch
import numpy as np
class DummyDeviceProps:
major = 0
minor = 0
torch.cuda.get_device_properties = lambda x: DummyDeviceProps()
from groundingdino.util.inference import load_model, load_image, predict
import hydra
from hydra.core.global_hydra import GlobalHydra
from hydra.utils import instantiate
device = "cpu"
# 1. 加载 DINO 模型
dino_model = load_model(
"grounding_dino/groundingdino/config/GroundingDINO_SwinT_OGC.py",
"gdino_checkpoints/groundingdino_swint_ogc.pth",
device=device
)
# 2. 强力加载 SAM 2
GlobalHydra.instance().clear()
config_dir = os.path.abspath("sam2_configs")
if not os.path.exists(config_dir):
config_dir = os.path.abspath("sam2/configs")
with hydra.initialize_config_dir(config_dir=config_dir, version_base="1.2"):
my_overrides = ["++model._target_=sam2.sam2_video_predictor.SAM2VideoPredictor"]
try:
cfg = hydra.compose(config_name="sam2_hiera_b+.yaml", overrides=my_overrides)
except Exception:
cfg = hydra.compose(config_name="sam2/sam2_hiera_b+.yaml", overrides=my_overrides)
sam2_predictor = instantiate(cfg.model, _recursive_=True)
state_dict = torch.load("checkpoints/sam2_hiera_base_plus.pt", map_location="cpu")
if 'model' in state_dict:
state_dict = state_dict['model']
sam2_predictor.load_state_dict(state_dict, strict=True)
sam2_predictor.to(device)
sam2_predictor.eval()
# 3. 设置目标和视频
VIDEO_PATH = "test_video.mp4"
TEXT_PROMPT = "dog ."
OUTPUT_FRAMES_DIR = "./temp_frames"
os.makedirs(OUTPUT_FRAMES_DIR, exist_ok=True)
# 核心修复:每次运行自动清理历史图片残留
for f in os.listdir(OUTPUT_FRAMES_DIR):
if f.endswith(".jpg"):
os.remove(os.path.join(OUTPUT_FRAMES_DIR, f))
# 4. 视频拆帧
vidcap = cv2.VideoCapture(VIDEO_PATH)
fps = vidcap.get(cv2.CAP_PROP_FPS)
success, image = vidcap.read()
count = 0
while success:
cv2.imwrite(f"{OUTPUT_FRAMES_DIR}/{count:05d}.jpg", image)
success, image = vidcap.read()
count += 1
# 5. 首帧检测
first_frame_path = f"{OUTPUT_FRAMES_DIR}/00000.jpg"
image_source, image_tensor = load_image(first_frame_path)
boxes, logits, phrases = predict(
model=dino_model, image=image_tensor, caption=TEXT_PROMPT, box_threshold=0.3, text_threshold=0.25, device=device
)
# 6. 跨帧追踪
inference_state = sam2_predictor.init_state(video_path=OUTPUT_FRAMES_DIR)
for box in boxes:
h, w, _ = image_source.shape
box = box * torch.Tensor([w, h, w, h])
x1, y1, x2, y2 = box[0] - box[2] / 2, box[1] - box[3] / 2, box[0] + box[2] / 2, box[1] + box[3] / 2
sam2_predictor.add_new_points_or_box(
inference_state=inference_state, frame_idx=0, obj_id=1, box=torch.tensor([x1, y1, x2, y2], device=device)
)
video_segments = {}
for out_frame_idx, out_obj_ids, out_mask_logits in sam2_predictor.propagate_in_video(inference_state):
video_segments[out_frame_idx] = {
obj_id: (out_mask_logits[i] > 0.0).cpu().numpy() for i, obj_id in enumerate(out_obj_ids)
}
# 7. 渲染并导出视频
OUTPUT_VIDEO_PATH = "output_result.mp4"
sample_img = cv2.imread(f"{OUTPUT_FRAMES_DIR}/00000.jpg")
height, width, _ = sample_img.shape
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video_writer = cv2.VideoWriter(OUTPUT_VIDEO_PATH, fourcc, fps, (width, height))
for frame_idx in range(count):
frame_path = f"{OUTPUT_FRAMES_DIR}/{frame_idx:05d}.jpg"
frame_img = cv2.imread(frame_path)
if frame_idx in video_segments:
for obj_id, mask in video_segments[frame_idx].items():
mask = mask.squeeze()
green_mask = np.zeros_like(frame_img, dtype=np.uint8)
green_mask[mask] = [0, 255, 0]
frame_img = cv2.addWeighted(frame_img, 1.0, green_mask, 0.4, 0)
video_writer.write(frame_img)
video_writer.release()3.3测试结果分析
代码执行完毕后,系统将在根目录下生成 output_result.mp4 文件。
从结果可以观测到,系统仅通过首帧接收自然语言指令 "dog .",即可在后续的所有视频帧中生成半透明的绿色科幻遮罩。在狗发生奔跑转身、遭遇背景杂物局部遮挡时,遮罩边缘依然能够平滑、紧凑地贴合目标实体,完美验证SAM2时空特征记忆机制的鲁棒性。

- 参考链接
•Grounded-SAM-2 官方开源仓库:IDEA-Research/Grounded-SAM-2
•SAM 2 论文及官方介绍:Segment Anything Model 2 (Meta AI)
•Grounding DINO 学术论文:Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection