cuda reduce算子优化思路
reduce v0:基础朴素版本
__global__ void device_reduce_v0(float* d_x, float* d_y) {
const int tid = threadIdx.x;
float *x = &d_x[blockIdx.x * blockDim.x]; // 当前block所处理元素块的首地址
for (int offset = blockDim.x >> 1; offset > 0; offset >>= 1) {
if (tid < offset) {
x[tid] += x[tid + offset];
}
__syncthreads();
}
if (tid == 0) {
d_y[blockIdx.x] = x[0];
}
}步骤详解
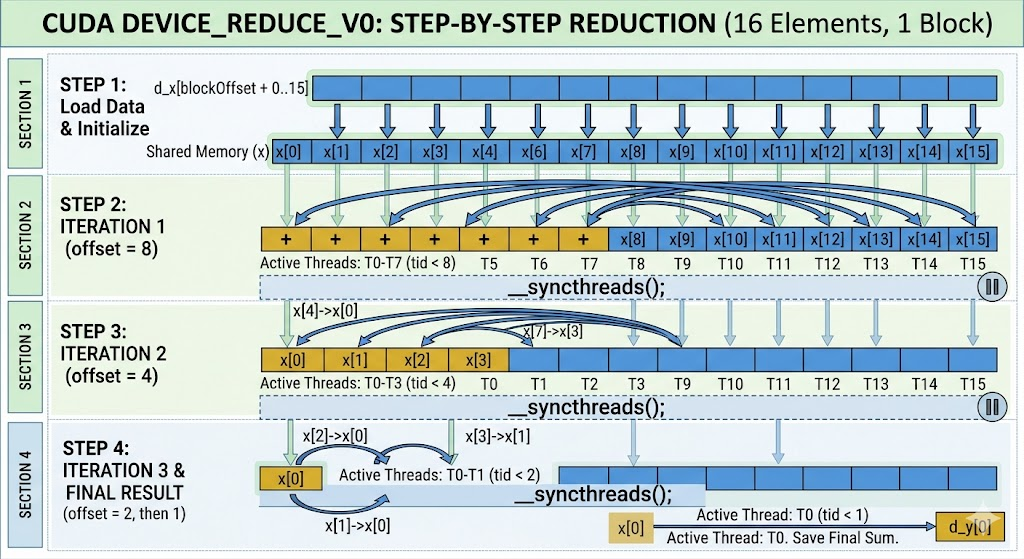
- 该图以一个包含 16 个元素的 Block 为例(blockDim.x = 16),展示了归约的四个主要步骤:
- 步骤 1:加载与初始化 (Load Data & Initialize)该 Block 中的 16 个线程(T0 到 T15)同时行动。它们从全局内存 d_x 的特定位置(由 blockIdx.x 决定)读取 16 个浮点数。这些数据被加载到共享内存(由数组指针 x 表示)中,从 x0 到 x15。
- 步骤 2:第一次迭代 (offset = 8)计算开始,步长 offset 为 8(16的一半)。只有前一半线程(T0 到 T7)是活跃的(满足 tid < 8)。计算: x0 += x8, x1 += x9, ..., x7 += x15。这 8 次加法是并行执行的。图中的弧形箭头表示数据合并的方向:例如,x8 的值被加到了 x0 中。关键: 计算完成后,所有线程在 __syncthreads() 处等待,确保数据已更新。
- 步骤 3:第二次迭代 (offset = 4)步长 offset 减半,变为 4。活跃线程数进一步减少,只有前 4 个线程(T0 到 T3)工作(满足 tid < 4)。计算: x0 += x4, x1 += x5, x2 += x6, x3 += x7。这 4 次加法并行执行。关键: 再次在 __syncthreads() 处进行线程同步。
- 步骤 4:最后迭代与结果保存 (offset = 2, then 1)迭代继续,offset 变为 2。T0 归约 x2 到 x0,T1 归约 x3 到 x1。同步。最后一次迭代,offset 变为 1。只有 T0 活跃。计算: x0 += x1。此时,整个 Block 的 16 个元素的和都累加到了 x0 中。保存结果: 只有 T0 执行最后一条指令,将 x0 的值写入全局内存 d y d_y dy 的对应位置。通过这种方式,原本需要 15 次顺序加法的过程,通过并行和分治,在 log 2 ( 16 ) = 4 \log_2(16)=4 log2(16)=4 轮计算内就完成了。
优化点
全局HBM访存
- 可以使用shared_memory进行优化
什么是 Warp Divergence?
- 当代码遇到分支结构(比如 if (tid < offset))时,问题就来了
- 如果 Warp 内的所有线程都满足条件(全部走 if),或者全都不满足(全部走 else),那么这个 Warp 就没有任何分化,所有线程步调一致,硬件效率达到 100%。
- 但是,如果 Warp 内的一部分线程满足条件,而另一部分不满足,就会发生 Warp Divergence。由于 SIMT 的限制,这一个音符(指令)不能同时唱两个调(两条路径)。硬件只能被迫串行化(Serialize)执行这两个分支:
- 第一步: 只有满足条件的线程被激活,执行 if 分支的指令。不满足条件的线程必须空转(Idle)/被禁用(Masked Out),干等着。
- 第二步: 第一步完成后,轮到不满足条件的线程被激活,执行 else 分支(或者跳过 if 后的代码)。之前满足条件的线程现在必须空转(Idle)等待。
举例说明
- 我们这里简化,假设一个 Warp 只有 8 个线程(实际上是 32 个,原理一致):
- 正常执行(Warp 0, T0-T7): 在加载数据阶段(Cycle 1),所有线程都需要加载。Warp 0 的全 8 个线程(全绿色)步调一致地完成了指令,效率 100%。
- 分化执行(Warp 1, T8-T15): 这也是一个由 8 个相邻线程组成的 Warp。
- 指令: if (tid < 8) { ... }
- 结果: Warp 1 内的所有线程(T8-T15)都不满足条件(tid >= 8)。
- 在这种极端情况下,硬件知道整个 Warp 的所有音符都不用唱,它们会一起飞快地跳过这个 if 块。虽然它们也在"等待"(灰色区域),但它们是一起等待,并没有产生分化路径,效率损失相对较小。
- 回到代码的陷阱:
在代码中,我们使用 if (tid < offset) 来控制。 - 当 offset = 8 时:Warp 0 全员活跃(满足条件),Warp 1 全员禁用(不满足)。没有发生内部 Divergence,但利用率低(Warp 1 空转)。
- 当 offset = 1 时(最后一次迭代):
Warp 0 内部:T0 满足条件(活跃),T1-T7 不满足(被禁用)。这就在 Warp 0 内部产生了严重的 Divergence。T0 执行加法指令时,T1-T7 必须干等着。GPU lanes 被浪费。
reduce_v1
template <const int BLOCK_SIZE>
__global__ void device_reduce_v1(float* d_x, float* d_y, const int N) {
const int tid = threadIdx.x;
const int bid = blockIdx.x;
const int n = bid * blockDim.x + tid;
__shared__ float s_y[BLOCK_SIZE];
s_y[tid] = (n < N) ? d_x[n] : 0.0; // 搬运global mem 到 shared mem
__syncthreads();
for (int offset = blockDim.x >> 1; offset > 0; offset >>= 1) {
if (tid < offset) {
s_y[tid] += s_y[tid + offset];
}
__syncthreads();
}
if (tid == 0) {
d_y[bid] = s_y[0];
}
}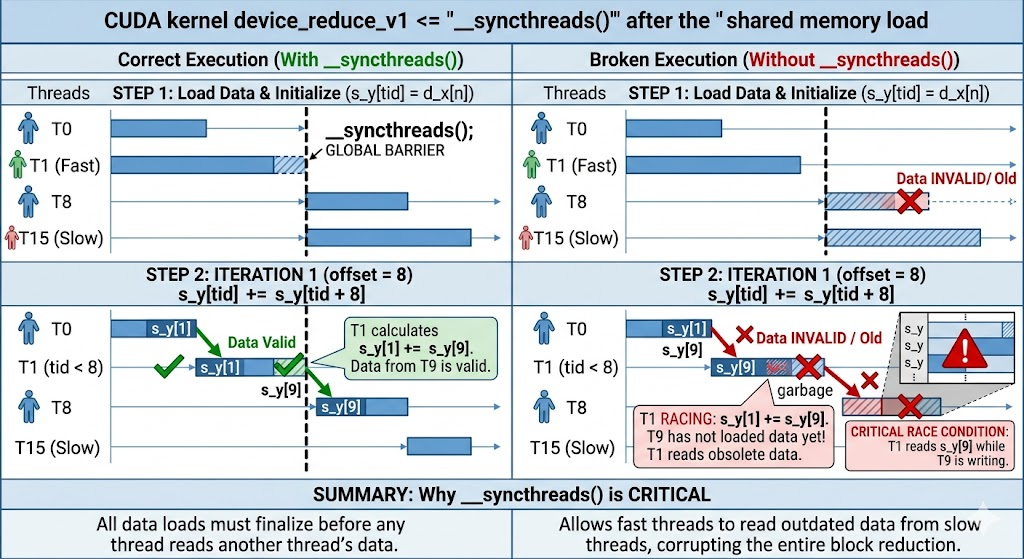
这个代码就是把HBM搬进shared_data中,其余没有什么区别的
reduce_v2
- reduce_v1是静态共享内存
- reduce_v2变成动态共享内存,优势如下

reduce_v3
__global__ void device_reduce_v3(float* d_x, float* d_y, const int N) {
const int tid = threadIdx.x;
const int bid = blockIdx.x;
const int n = bid * blockDim.x + tid;
extern __shared__ float s_y[]; // 动态共享内存
s_y[tid] = (n < N) ? d_x[n] : 0.0; // 搬运global mem 到 shared mem
__syncthreads();
for (int offset = blockDim.x >> 1; offset > 0; offset >>= 1) {
if (tid < offset) {
s_y[tid] += s_y[tid + offset];
}
__syncthreads();
}
if (tid == 0) {
atomicAdd(d_y, s_y[0]); // 原子函数,将取出*d_y,与s_y[0]求和后,再根据地址d_y写回去
// *d_y += s_y[0]; // 错误,因为d_y如果被多个线程同时读取,再写入时结果就会发生错误
}
}
template <const int BLOCK_SIZE>
void call_reduce_v2(float* d_x, float* d_y, float* h_y, const int N, float* sum) {
const int GRID_SIZE = CEIL(N, BLOCK_SIZE);
dim3 block_size(BLOCK_SIZE);
dim3 grid_size(GRID_SIZE);
device_reduce_v2<<<grid_size, block_size, sizeof(float) * BLOCK_SIZE>>>(d_x, d_y, N); // 使用(动态)共享内存
cudaMemcpy(h_y, d_y, sizeof(float) * GRID_SIZE, cudaMemcpyDeviceToHost);
cudaDeviceSynchronize();
// 在主机端需要再归约一遍
*sum = 0.0;
for (int i = 0; i < GRID_SIZE; i++) {
*sum += h_y[i];
}
}
template <const int BLOCK_SIZE>
void call_reduce_v3(float* d_x, float* d_y, float* h_y, const int N) {
const int GRID_SIZE = CEIL(N, BLOCK_SIZE);
dim3 block_size(BLOCK_SIZE);
dim3 grid_size(GRID_SIZE);
*h_y = 0.0; // host端d_y清零
cudaMemcpy(d_y, h_y, sizeof(float), cudaMemcpyHostToDevice); // 拷贝给d_y
device_reduce_v3<<<grid_size, block_size, sizeof(float) * BLOCK_SIZE>>>(d_x, d_y, N); // 使用(动态)共享内存
cudaMemcpy(h_y, d_y, sizeof(float), cudaMemcpyDeviceToHost); // 拷贝回h_y
cudaDeviceSynchronize();
}- 引入原子函数之后,在主机端就不用像之前那样在主机端再归约一遍了,这步性能提升比较多
reduce_v4
// reduce_v4:使用 warp shuffle
global void device_reduce_v4(float* d_x, float* d_y, const int N) {
shared float s_y32; // 仅需要32个,因为一个block最多1024个线程,最多1024/32=32个warp
int idx = blockDim.x * blockIdx.x + threadIdx.x;
int warpId = threadIdx.x / warpSize; // 当前线程属于哪个warp
int laneId = threadIdx.x % warpSize; // 当前线程是warp中的第几个线程
float val = (idx < N) ? d_x[idx] : 0.0f; // 搬运d_x[idx]到当前线程的寄存器中
#pragma unroll
for (int offset = warpSize >> 1; offset > 0; offset >>= 1) {
val += __shfl_down_sync(0xFFFFFFFF, val, offset); // 在一个warp里折半归约
}
if (laneId == 0) s_y[warpId] = val; // 每个warp里的第一个线程,负责将数据存储到shared mem中
__syncthreads();
if (warpId == 0) { // 使用每个block中的第一个warp对s_y进行最后的归约
int warpNum = blockDim.x / warpSize; // 每个block中的warp数量
val = (laneId < warpNum) ? s_y[laneId] : 0.0f;
for (int offset = warpSize >> 1; offset > 0; offset >>= 1) {
val += __shfl_down_sync(0xFFFFFFFF, val, offset);
}
if (laneId == 0) atomicAdd(d_y, val); // 使用此warp中的第一个线程,将结果累加到输出
}}
warp shuffle操作,寄存器操作,更快
看懂下面的指令,就可以理解reduce_v4了
A. __shfl_sync(mask, val, srcLane) (通用版)
作用:将 Warp 中 srcLane 编号线程的 val 值,复制给当前线程。
形象理解:你在查名单,你想看第 5 号人的作业,直接把他的作业拿过来看。
场景:需要从特定线程广播数据到所有其他线程。
__global__ void broadcast_example(float* d_output) {
int laneId = threadIdx.x % 32;
float val = 0.0f;
// 假设只有 lane 0 拥有有效数据
if (laneId == 0) {
val = 123.45f;
}
// 使用 __shfl_sync 将 lane 0 的 val 广播给所有线程
// 0xFFFFFFFF: mask,表示所有线程都参与
// val: 当前线程的 val
// 0: srcLane,表示要读取 lane 0 的数据
val = __shfl_sync(0xFFFFFFFF, val, 0);
// 此时,所有线程的 val 都变成了 123.45f
if (laneId == 5) {
printf("Thread %d received: %f\n", threadIdx.x, val);
}
}B. __shfl_up_sync(mask, val, delta) (向上移动)
作用:当前线程从其 laneID - delta 的线程那里获取 val。
形象理解:队列向前移动。第 10 号线程向第 5 号线程看齐(delta=5)。
场景:用于前缀和计算,或扫描(Scan)算法。
举例
在 CUDA 中,这段代码实现的是前缀和(Prefix Sum / Scan),而不是最终只有最后一个线程拿到总和的常规 Reduce。它的核心逻辑是:让每个线程都实时累加其左侧(Lane ID 较小)线程传递过来的数据。
假设一个 Warp 里有 32 个线程,它们的初始值 val 分别为 x 0 , x 1 , x 2 , ... , x 31 x_0, x_1, x_2, \dots, x_{31} x0,x1,x2,...,x31。我们以 Lane 0 到 Lane 3 这前 4 个线程为例,看看每一步发生了什么:
1. 初始状态
- Lane 0: x 0 x_0 x0
- Lane 1: x 1 x_1 x1
- Lane 2: x 2 x_2 x2
- Lane 3: x 3 x_3 x3
2. 第一步:delta = 1
val += __shfl_up_sync(0xFFFFFFFF, val, 1);
每个线程向左看 1 步,获取 Lane - 1 的值并加到自己身上。
- Lane 0: 减 1 越界,不拿值(加 0)。依然是 x 0 x_0 x0。
- Lane 1: 拿到 Lane 0 的值( x 0 x_0 x0)。val 变为 x 1 + x 0 x_1 + x_0 x1+x0。
- Lane 2: 拿到 Lane 1 的初始值( x 1 x_1 x1)。val 变为 x 2 + x 1 x_2 + x_1 x2+x1。
- Lane 3: 拿到 Lane 2 的初始值( x 2 x_2 x2)。val 变为 x 3 + x 2 x_3 + x_2 x3+x2。
当前状态:每个线程的 val 里包含了自己和前 1 个线程的和。
3. 第二步:delta = 2
val += __shfl_up_sync(0xFFFFFFFF, val, 2);
每个线程向左看 2 步,获取 Lane - 2 的值(注意:此时获取的是第一步累加后的新值)。
- Lane 0: 减 2 越界,不拿值。依然是 x 0 x_0 x0。
- Lane 1: 减 2 越界,不拿值。依然是 x 1 + x 0 x_1 + x_0 x1+x0。
- Lane 2: 拿到 Lane 0 的值( x 0 x_0 x0)。val 变为 ( x 2 + x 1 ) + x 0 (x_2 + x_1) + x_0 (x2+x1)+x0。
- Lane 3: 拿到 Lane 1 的值( x 1 + x 0 x_1 + x_0 x1+x0)。val 变为 ( x 3 + x 2 ) + ( x 1 + x 0 ) (x_3 + x_2) + (x_1 + x_0) (x3+x2)+(x1+x0)。
当前状态:每个线程的 val 里包含了自己和前 3 个线程的和(共 4 个元素的和)。
4. 第三步:delta = 4
val += __shfl_up_sync(0xFFFFFFFF, val, 4);
每个线程向左看 4 步,获取 Lane - 4 的新值。
- Lane 0 ~ 3: 减 4 全部越界,值不再改变。
- Lane 4: 拿到 Lane 0 的值( x 0 x_0 x0)。
- Lane 7: 拿到 Lane 3 的值( x 3 + x 2 + x 1 + x 0 x_3+x_2+x_1+x_0 x3+x2+x1+x0)。此时 Lane 7 成功汇聚了 x 0 ... x 7 x_0 \dots x_7 x0...x7 的总和。
当前状态:每个线程的 val 里包含了包含自己和前 7 个线程的和(共 8 个元素的和)。
5. 第四步 (delta = 8) 和 第五步 (delta = 16)
逻辑以此类推,通过翻倍的步长进行覆盖:
- delta = 8:Lane 8 ~ 15 拿到左边计算好的 8 个元素的和。此时 Lane 15 拥有 x 0 ... x 15 x_0 \dots x_{15} x0...x15 的总和。
- delta = 16:Lane 16 ~ 31 拿到左边计算好的 16 个元素的和。此时 Lane 31 拥有 x 0 ... x 31 x_0 \dots x_{31} x0...x31 的全 Warp 总和。
C. __shfl_down_sync(mask, val, delta) (向下移动)
作用:当前线程从其 laneID + delta 的线程那里获取 val。
形象理解:队列向后看。第 5 号线程获取第 10 号线程的数据。
场景:这就是归约(Reduction)中最常用的指令,用于将后面线程的值"收拢"到前面的线程。
__shfl_down_sync 与 __shfl_up_sync 刚好相反。它是向下(Lane ID 增大的方向)抓取数据。
当前线程会向右看,获取自身 Lane ID 加上 delta 的那个线程的数据。
1. 经典应用:Warp 内规约(Reduce Sum)
在求全 Warp 32 个线程的总和时,__shfl_down_sync 比 __shfl_up_sync 更常用。因为它可以让 Lane 0 直接拿到最终的总和,方便后续写入全局内存。
global void reduce_down_example(int *d_out, const int *d_in) {
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int val = d_intid;
// 从右侧距离 16, 8, 4, 2, 1 的线程抓取数据并累加
val += __shfl_down_sync(0xFFFFFFFF, val, 16);
val += __shfl_down_sync(0xFFFFFFFF, val, 8);
val += __shfl_down_sync(0xFFFFFFFF, val, 4);
val += __shfl_down_sync(0xFFFFFFFF, val, 2);
val += __shfl_down_sync(0xFFFFFFFF, val, 1);
// 最终,只有 Lane 0 拥有全 Warp 的总和
if (threadIdx.x % 32 == 0) {
atomicAdd(d_out, val);
}}
2. 每一步的图解说明
假设 Warp 内有 32 个线程,初始值分别为 x 0 , x 1 , ... , x 31 x_0, x_1, \dots, x_{31} x0,x1,...,x31。我们来看前几步是如何把右侧的数据"折叠"汇聚到左侧的。
第一步:delta = 16
每个线程(Lane i)加上自身右侧第 16 个线程(Lane i + 16)的值。
- Lane 0: 加上 Lane 16 的值 → v a l = x 0 + x 16 \rightarrow val = x_0 + x_{16} →val=x0+x16
- Lane 1: 加上 Lane 17 的值 → v a l = x 1 + x 17 \rightarrow val = x_1 + x_{17} →val=x1+x17
- ...
- Lane 15: 加上 Lane 31 的值 → v a l = x 15 + x 31 \rightarrow val = x_{15} + x_{31} →val=x15+x31
- Lane 16 ~ 31: 右侧加 16 越界,不拿值(保持原值不变)。
此时状态:Warp 后半段(1631)的数据,已经全部安全地累加到了前半段(015)中。
第二步:delta = 8
现在只需要关注前半段(0~15)。每个线程加上右侧第 8 个线程的值。
- Lane 0: 加上 Lane 8 的值(此时 Lane 8 已经是 x 8 + x 24 x_8 + x_{24} x8+x24)。
- 结果: v a l = ( x 0 + x 16 ) + ( x 8 + x 24 ) val = (x_0 + x_{16}) + (x_8 + x_{24}) val=(x0+x16)+(x8+x24)
- Lane 7: 加上 Lane 15 的值。
- 结果: v a l = ( x 7 + x 23 ) + ( x 15 + x 31 ) val = (x_7 + x_{23}) + (x_{15} + x_{31}) val=(x7+x23)+(x15+x31)
此时状态:前 8 个线程(0~7),已经各自保存了 4 个元素的和。
第三步到第五步:delta = 4, 2, 1
继续折叠:
- delta = 4:前 4 个线程(0~3)各自保存了 8 个元素的和。
- delta = 2:前 2 个线程(0~1)各自保存了 16 个元素的和。
- delta = 1:Lane 0 加上 Lane 1 的值(此时 Lane 1 拥有右侧 16 个元素的和)。
- 最终结果:Lane 0 完美收集了 x 0 + x 1 + ⋯ + x 31 x_0 + x_1 + \dots + x_{31} x0+x1+⋯+x31 的总和。
💡 核心区别对比
| 函数 | 抓取方向 | 越界线程 | 典型输出位置 | 适用场景 |
|---|---|---|---|---|
| __shfl_up_sync(..., delta) | 往左看(i - delta) | 左侧边界线程(小 ID)不变 | Lane 31 拿到总和 | 包含前缀和(Scan) |
| __shfl_down_sync(..., delta) | 往右看(i + delta) | 右侧边界线程(大 ID)不变 | Lane 0 拿到总和 | 规约求和(Reduce) |
如果需要了解如何利用 width 参数将 32 线程的 Warp 拆分成更小的子组(如 4 或 8 线程)独立进行 __shfl_down_sync 操作,请告诉我!
D. __shfl_xor_sync(mask, val, laneMask) (异或交换)
作用:当前线程与 laneID ^ laneMask 的线程交换数据。
形象理解:镜像对称交换。
场景:蝶式归约(Butterfly Reduction),在处理 FFT(快速傅里叶变换)时极其高效。
- mask: 通常传入 0xFFFFFFFF(32位全1),表示该 Warp 内所有线程都参与操作。如果只想让部分线程参与,可以设置位掩码。
- val: 你想分享出去的数据(必须在寄存器中)。
- delta / laneMask: 位移量或异或掩码。
__shfl_xor_sync 是洗牌指令中最强大的一个。它通过将当前线程的 Lane ID 与 laneMask 进行按位异或(XOR),来决定从哪个线程抓取数据。
它的最大优势是:只需要 5 步,就能让 Warp 内的全部 32 个线程同时拿到最终的总和,而不需要像 down 或 up 那样最后只在 Lane 0 或 Lane 31 才有结果。
- 经典应用:全 Warp 广播规约(All-Reduce)
如果你希望规约结束后,每一个线程都能直接使用总和进行下一步计算,用 __shfl_xor_sync 是最完美的。
global void reduce_xor_example(int *d_out, const int *d_in) {
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int val = d_intid;
// 掩码 1, 2, 4, 8, 16 对应二进制的某一位取反
val += __shfl_xor_sync(0xFFFFFFFF, val, 1);
val += __shfl_xor_sync(0xFFFFFFFF, val, 2);
val += __shfl_xor_sync(0xFFFFFFFF, val, 4);
val += __shfl_xor_sync(0xFFFFFFFF, val, 8);
val += __shfl_xor_sync(0xFFFFFFFF, val, 16);
// 此时,Warp 内的所有 32 个线程的 val 都是全 Warp 的总和!
// 我们可以让任意线程写入,或者所有线程直接用这个总和做后续计算
if (threadIdx.x % 32 == 0) {
atomicAdd(d_out, val);
}}
- 每一步的图解(蝴蝶交换网络)
按位异或的特点是:互相交换。如果线程 A 找 线程 B 拿数据,那么线程 B 在同一时刻也必然找 线程 A 拿数据。这就形成了一个两两交换的"蝴蝶网络"。
我们以 Lane 0 ~ Lane 3 这 4 个线程为例,看看它们两两之间是如何交换并配对的:
第一步:laneMask = 1(二进制 00001)
目标 Lane ID = 当前 Lane ID ^ 1(即把二进制最后一位取反):
- Lane 0 (00) ↔ \leftrightarrow ↔ Lane 1 (01) 互相交换值。
- Lane 0 结果: v a l = x 0 + x 1 val = x_0 + x_1 val=x0+x1
- Lane 1 结果: v a l = x 1 + x 0 val = x_1 + x_0 val=x1+x0
- Lane 2 (10) ↔ \leftrightarrow ↔ Lane 3 (11) 互相交换值。
- Lane 2 结果: v a l = x 2 + x 3 val = x_2 + x_3 val=x2+x3
- Lane 3 结果: v a l = x 3 + x 2 val = x_3 + x_2 val=x3+x2
当前状态:每相邻的 2 个线程,都同时拥有它们这两人的和。
第二步:laneMask = 2(二进制 00010)
目标 Lane ID = 当前 Lane ID ^ 2(即把二进制倒数第二位取反):
- Lane 0 (00) ↔ \leftrightarrow ↔ Lane 2 (10) 互相交换值(注意:此时交换的是第一步累加后的新值)。
- Lane 0 结果: ( x 0 + x 1 ) + ( x 2 + x 3 ) (x_0 + x_1) + (x_2 + x_3) (x0+x1)+(x2+x3)
- Lane 2 结果: ( x 2 + x 3 ) + ( x 0 + x 1 ) (x_2 + x_3) + (x_0 + x_1) (x2+x3)+(x0+x1)
- Lane 1 (01) ↔ \leftrightarrow ↔ Lane 3 (11) 互相交换值。
- Lane 1 结果: ( x 1 + x 0 ) + ( x 3 + x 2 ) (x_1 + x_0) + (x_3 + x_2) (x1+x0)+(x3+x2)
- Lane 3 结果: ( x 3 + x 2 ) + ( x 1 + x 0 ) (x_3 + x_2) + (x_1 + x_0) (x3+x2)+(x1+x0)
当前状态:这 4 个线程中的每一个线程,现在都同时拥有了 x 0 ... x 3 x_0 \dots x_3 x0...x3 的 4 项总和。
第三、四、五步:laneMask = 4, 8, 16
以此类推,扩散到更大的组进行两两对调:
- laneMask = 4:每 8 个线程的小组内互相交换,组内 8 个线程全部拿到该组的 8 项总和。
- laneMask = 8:每 16 个线程的小组内互相交换。
- laneMask = 16:前半 Warp(0~15)与后半 Warp(16~31)对应位置两两大交换。
最终状态:整个 Warp 的 32 个线程完全同步,所有人手里的 val 都变成了全 Warp 32 个元素的总和。
💡 核心指令终极对比
| 函数 | 数据流向 | 边界处理 | 最终哪个线程拿到了全 Warp 总和? |
|---|---|---|---|
| __shfl_up_sync | 单向靠拢(往左看) | 越界不拿值 | 只有 Lane 31(顺便生成了前缀和) |
| __shfl_down_sync | 单向靠拢(往右看) | 越界不拿值 | 只有 Lane 0(最适合标准的 Reduce) |
| __shfl_xor_sync | 双向对调(蝴蝶网络) | 绝不越界(都在 Warp 内) | 所有 32 个线程同时拥有 |
reduce_v5
增加向量化访存
__global__ void device_reduce_v5(float* d_x, float* d_y, const int N) {
__shared__ float s_y[32];
int idx = (blockDim.x * blockIdx.x + threadIdx.x) * 4; // 这里要乘以4
int warpId = threadIdx.x / warpSize; // 当前线程位于第几个warp
int laneId = threadIdx.x % warpSize; // 当前线程是warp中的第几个线程
float val = 0.0f;
if (idx < N) {
float4 tmp_x = FLOAT4(d_x[idx]);
val += tmp_x.x;
val += tmp_x.y;
val += tmp_x.z;
val += tmp_x.w;
}
#pragma unroll
for (int offset = warpSize >> 1; offset > 0; offset >>= 1) {
val += __shfl_down_sync(0xFFFFFFFF, val, offset);
}
if (laneId == 0) s_y[warpId] = val;
__syncthreads();
if (warpId == 0) {
int warpNum = blockDim.x / warpSize;
val = (laneId < warpNum) ? s_y[laneId] : 0.0f;
for (int offset = warpSize >> 1; offset > 0; offset >>= 1) {
val += __shfl_down_sync(0xFFFFFFFF, val, offset);
}
if (laneId == 0) atomicAdd(d_y, val);
}
}